

在航空领域,飞机在机场滑行时的安全避障至关重要.为此,机场部署场面监视雷达和多点定位系统用于获取目标信息.这些系统获取的目标信息被发送给塔台管制员,再由管制员通过语音与飞行员交流.但这种方法使得飞行员获取的场面目标信息滞后且不够直观,严重影响飞行员对场面情况的判断.为增强航空器对周围环境的感知能力,空中客车公司和波音公司已开展基于机器视觉的智能辅助驾驶系统研究与验证[1].该系统通过机载视觉传感器,扩大飞行员视野,增加低能见度下的可视距离,自动检测飞机滑行过程中的潜在威胁目标,为飞行员提供直观可视的辅助决策信息.
机场场景中目标多样、尺寸差异大,如飞机、特种车辆和机务工作人员等,机载平台计算资源有限,为机载视觉辅助驾驶系统中的场面目标检测带来诸多挑战.因此,针对民用航空器可视导航的目标检测需求,开展多尺度、轻量化的场面目标检测技术研究具有重要意义.
多尺度目标检测算法,旨在解决不同大小、不同远近目标在图像中的提取问题[2].为了解决该问题,学者提出两类多尺度目标检测方法.一类方法通过构建多尺度的特征图来检测不同尺度的目标,如Faster R-CNN的双层网络结构[3]、SSD网络中的不同尺度锚框[4]等.另一类方法是利用金字塔结构,如特征金字塔网络(feature pyramid networks,FPN)[5]、BiFPN[6],来生成多尺度的特征图,如YOLOv3的三尺度预测[7]、RetinaNet的FPN[8]等.韩松臣等[9]通过结合Faster-RCNN和PANet特征融合网络提高了小目标检测能力.黄国新等[10]则改进了SSD算法,使用更深的ResNet-50[11]骨干网络和额外特征层,以增强对多尺度目标的检测.这些方法在小目标、多尺度目标等方面取得了较好的检测效果,但存在计算量大、实时性较差的问题.
轻量化目标检测算法,主要用于移动设备和嵌入式系统等硬件资源受限的场景,着重降低算法的计算复杂度和内存占用.近年来,随着深度学习的发展,提出了许多轻量化的卷积模块,如GSConv[12]、深度可分离卷积[13]、空洞卷积[14]以及轻量化的网络结构,如ShuffleNet[15]、MobileNet、SqueezeNet、Slim Neck[12]等.这些模块和网络通过设计高效的结构和计算单元,在保持较高检测性能的同时,降低了模型的参数和计算量.此外,针对目标检测任务,也有学者提出一些轻量化的目标检测算法,例如 MobileNet-SSDv2[16]、YOLOv4[17]、YOLOv5s[18]等.Yan等[19]采用YOLOv5s框架实现了场面目标的快速检测,但在检测工作人员和特种车辆等小型目标时效果不佳.在算力受限的情况下,解决快速多尺度目标检测问题仍然极具挑战性.
针对机载视觉传感器获取机场场面这种大场景中不同远近、不同尺寸的飞机、特种车辆和机务工作人员等目标的快速检测问题,本文提出一种轻量化设计的多尺度YOLOv5s目标检测(multi-scale object detection-YOLOv5s,MSD-YOLOv5s)算法.设计双向特征金字塔(bidirectional feature pyramid network,BIFPN)和坐标(coordinate attention,CA)注意力机制的融合CA-BIFPN网络,改善多尺度检测性能.通过设计的轻量化解耦检测头和尺寸更敏感的EIoU损失函数,提高网络对多尺度目标的定位效率,进而实现机载计算平台算力受限情况下的多尺度目标检测.
1 YOLOv5s目标检测框架及研究思路
作为单阶段目标检测算法的典型代表,YOLO系列算法从YOLOv1至YOLOv9的改进版本在多尺度高效目标检测方面的性能不断提升.YOLOv5s是一种轻量化设计的YOLO网络结构,其模型结构和计算复杂度相对较小.YOLOv5s网络主要由骨干网络、颈部和检测头组成.骨干网络采用CSP-Darknet53[17]卷积神经网络,以降低模型的复杂度和计算开销.颈部采用FPN和特征融合结构[20],通过在网络中建立跨层连接,实现对来自底层和顶层的特征信息的有效利用,从而提高多尺度目标的检测能力.检测头负责在骨干网络提取特征的基础上进行目标检测,通常由一系列卷积层和全连接层组成,用于生成目标的位置和类别信息.YOLOv5s还利用预定义的锚框来指导网络对目标位置的预测,并根据与实际目标的匹配程度来计算损失函数,以优化模型参数.
YOLOv5s通过简化网络结构、引入特征金字塔网络和优化锚框等方式,在保持高精度条件下实现了推理速度的提升,具有在资源受限环境下广泛应用的潜力.因此,基于YOLOv5s基础框架模型开展场面多尺度目标检测,研究思路及实验流程如图1所示.主要由4个部分组成:①数据采集与预处理,构建多尺度场面图像数据集,用于模型训练、测试和实验评估;②将提出的4点改进与YOLOv5s结合,得到改进后的MSD-YOLOv5s目标检测算法;③在构建的数据集上,对改进后的MSD-YOLOv5s目标检测算法与经典多尺度目标检测算法进行可行性实验、消融实验和对比实验;④整理和分析实验数据,并得出实验结论.
图1
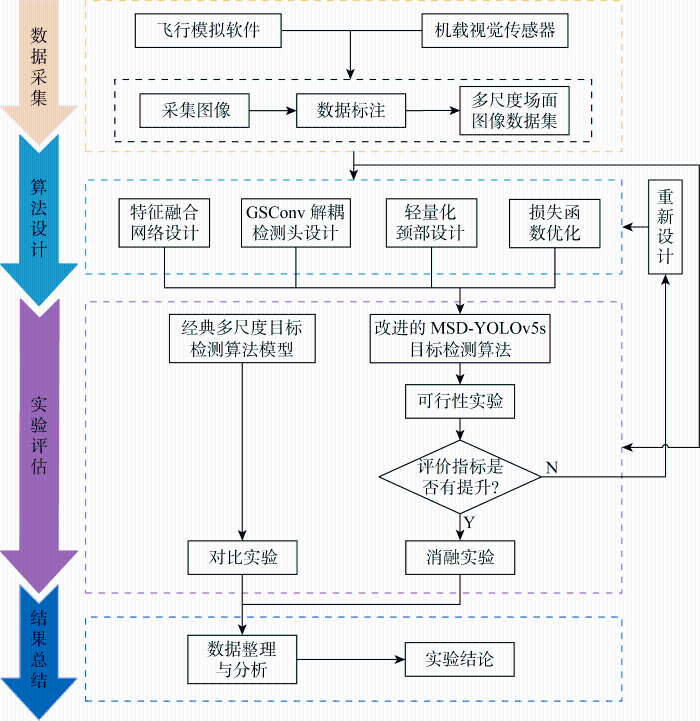
2 轻量化多尺度YOLOv5s目标检测算法(MSD-YOLOv5s)
机场场面中飞机、特种车辆和机务工作人员等目标尺寸差异大,飞机滑行中目标的距离变化大,导致图像中目标尺度范围更大,超出常规多尺度目标检测的能力范围.为此,分别在特征融合网络、颈部和检测头等结构对YOLOv5s进行轻量化设计,并扩大目标尺度范围的适应性,提出一种轻量化多尺度目标检测网络MSD-YOLOv5s.
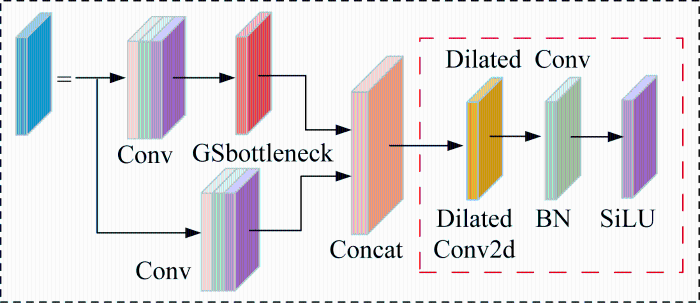
所提MSD-YOLOv5s网络结构如图2所示,在原YOLOv5s网络模型上进行3处模型改进和1处损失函数优化:①结合CA注意力机制与BIFPN网络优势,设计CA-BIFPN特征融合网络,通过多层特征的有效融合,增强小尺度目标的特征提取和定位;②将检测头的回归和分类任务解耦,设计基于GSConv的解耦检测头,提高模型对各尺度目标的分类精度,同时不显著增加解耦网络的参数量;③减少特征图的通道数,实现颈部轻量化设计,引入改进后的Slim-Neck结构来提高模型的计算效率;④引入EIoU损失函数,用于提升收敛速度和精度,进而提升多尺度目标检测性能.图2中:Conv表示卷积;C3表示瓶颈层;SPPF表示快速空间金字塔池化;Unsample表示上采样;Concat表示特征图拼接;Conv2d表示二维卷积;GSDetector表示基于GSConv的解耦检测头;Dilated Conv表示空洞卷积;GSbottleneck表示瓶颈层;BN表示批归一化;SiLU表示激活函数;VoV-GSCSP为跨级部分网络模块.
图2
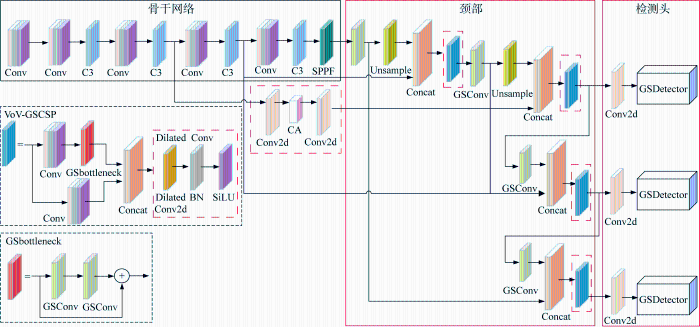
该网络处理图像的主要过程为:首先,将输入图像送入骨干网络,提取不同尺度的特征;然后,通过CA-BIFPN特征融合网络对提取特征进行上下采样和跨尺度连接操作,完成多层次融合;最后,将融合特征送入轻量化解耦检测头,生成目标的类别、位置和置信度等检测结果.
2.1 CA-BIFPN特征融合网络
场面目标中,相对近距离的飞机尺度大,特种车辆和机务工作人员等目标尺度小,同一场景中的多个目标尺度差异很大,易受背景的干扰,特征提取较为困难.因此,为增强小目标的特征提取能力,对YOLOv5s的特征融合部分进行改进,引入双向特征传播和多层特征融合机制的BIFPN结构,结合CA注意力机制设计CA-BIFPN网络,实现多层特征有效融合,进而增强多尺度目标的检测能力.
如图3(a)所示,BIFPN采用双向特征金字塔网络结构,通过多层级的特征融合和动态的特征权重分配,可提高目标检测的准确率和效率.图中:P为层,下标表示层数.通过跨层特征融合可有效融合多尺度特征信息,但对融合少量特征的节点进行了枝减,造成对细节的感知能力不足,对于小尺度目标特征提取性能不佳.为此,将CA注意力机制引入底层特征融合阶段,如图3(b)所示.前后通过两个1×1卷积,设置CA注意力机制输入和输出的通道数均为256,保证特征图传输过程中前后端网络通道数匹配.将位置信息嵌入到通道中的CA注意力机制,并将其应用于特征融合的底层部分,以加强小尺度目标位置信息与整体特征的关联程度,同时提升图像中重要信息的特征融合能力.
图3
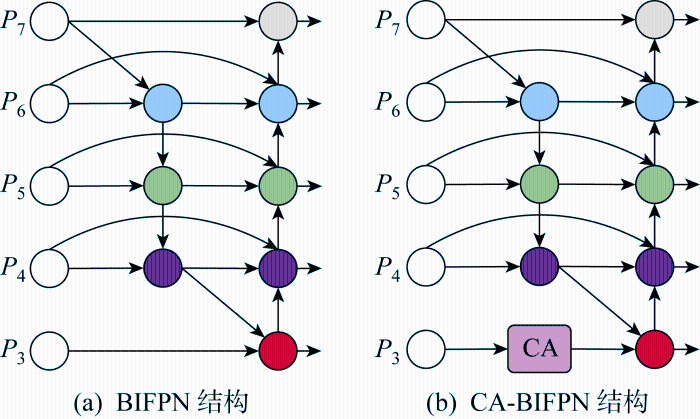
CA注意力机制将输入特征图在水平和垂直两个方向分别进行全局平均池化,获得在水平和垂直两个方向的特征图,从而避免单一全局平均池化导致无法保留位置信息的问题.采用输入特征张量使用池化核来编码水平和垂直方向的特征,高度为h的第c通道的输出zc(h)和宽度为w的第c通道的输出zc(w)分别如下:
式中:Hk、Wk分别为池化核的高和宽;xc(h,i)为水平方向第c通道上高度为h宽度为i的特征,0≤i<Wk;xc(j,w)为垂直方向上第c通道上高度为j宽度为w的特征,0≤j<Hk.
融合CA-BIFPN和CA注意力机制所设计的CA-BIFPN网络模块可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息.然后,将生成的特征图分别编码为一对方向感知和位置敏感的特征图,以加强模型对多尺度目标的特征融合能力以及对目标位置的关注.
2.2 GSConv解耦检测头
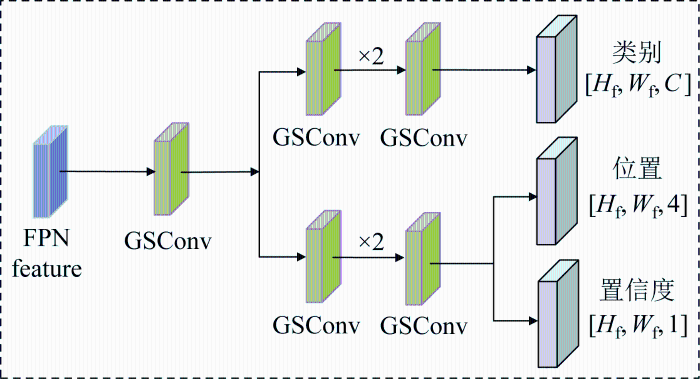
机场场面图像中经常出现大尺度和小尺度目标同时出现在同一场景的情况,造成目标的定位和分类困难.YOLOv5s采用分类和定位任务合并处理的耦合检测头,难以处理该情况.为此,设计解耦检测头GSDetector,将分类和定位任务单独优化处理,增强模型对不同尺度目标的定位和分类精度.
YOLOv5s采用的卷积耦合检测头通过减少卷积层的数量和复杂度,降低了计算成本,提高了检测速度,却牺牲了一部分小目标的检测精度.采用解耦检测头,将目标位置和类别信息分别提取出来,通过不同网络分支分别学习,最后再进行融合.这种设计有助于减少参数量和计算复杂度,增强模型的泛化能力和鲁棒性.但是,解耦的设计会造成参数量和计算量增加,难以在机载计算平台上直接使用.为此,结合标准卷积和深度可分离卷积(depthwise separable convolution,DSC)的特点,设计GSConv的轻量化解耦检测头,称为GSDetector,以适应机载计算平台计算量需求.如图4所示,GSDetector由分类支路和回归支路组成.其中,分类支路负责对检测框内的目标进行分类,确定目标所属类别.回归支路负责对目标框的位置和尺寸进行回归预测.图中:FPN feature表示特征金字塔生成的特征图;Hf、Wf分别为特征图的高度和宽度;C、4、1分别对应C类别、4坐标值和1置信度.GSConv卷积模块通过打乱重组操作,有效将标准卷积信息融入DSC中,降低计算量的同时保持接近标准卷积的输出效果.GSDetector可在保持分类和定位精度的前提下,减轻解耦导致的参数量增长问题.
图4
2.3 跨级部分网络轻量化颈部
YOLOv5s网络具有良好的整体检测效率,但其网络颈部由计算量较大的标准卷积模块和C3模块组成,网络参数和计算复杂度较大.为进一步减少网络的计算复杂度,采用由空洞卷积改进的Slim-Neck(dilated convolutions slim-neck,DC Slim-Neck)进行颈部网络的轻量化优化.
Slim-Neck结构使用跨级部分网络模块VoV-GSCSP,包括GSbottleneck模块和多个标准卷积模块.GSbottleneck模块由GSConv卷积组成,多个标准卷积模块相互堆叠连接,计算复杂度较高,难以适应机载计算平台实时性要求.空洞卷积通过引入一个称为“扩张率”的超参数,减少计算参数,同时增加模型感受野,可让网络模型捕获更丰富的多尺度上下文信息.如图5所示,采用空洞卷积代替VoV-GSCSP 中的标准卷积,以降低颈部网络的参数量和计算复杂度,提升推理速度.DC Slim-Neck将主干网络学习到的特征进行快速多尺度融合,减少模型的计算量,提高网络整体的检测速度.
图5
2.4 损失函数优化
YOLOv5s采用的CIoU损失函数将目标长和宽联合作为一个惩罚项,造成目标回归框的长和宽不敏感,导致模型对长宽尺度差异大的目标数据集训练时不易收敛,以及导致算法对场面目标中的飞机、特种车辆和机务工作人员长宽尺度差异大的目标检测性能下降.采用EIoU损失函数将纵横比的损失项拆分成预测框的宽和高,用以提升模型对长宽尺度差异大的目标的收敛速度和精度.该损失函数包含3个部分:重叠损失LR、中心距离损失Ldis和宽高损失Lasp.前两部分延续CIoU中的方法, 宽高损失依据目标框与预测框的宽度和高度之差来计算:
式中:R为目标框与预测框重叠区域面积与它们并集区域的面积之比;hc、wc别为真实边界框最小外接矩形的宽度和高度;wp、hp分别为预测框的宽度和高度;hg、wg分别为实际框的宽度和高度;ρ为两点之间的欧氏距离;b、bg分别为预测框和真实框的中心点坐标.
3 实验数据与结果分析
3.1 机场场面多尺度目标图像数据集构建
目前,尚未检索到国内外公开的机场场面目标检测数据集.为了评估算法性能,构建超过 10 000 帧场面多尺度目标图像的数据集,图像主要来源于飞行模拟软件视景图像和机载视觉传感器实际拍摄图像等.数据集包含飞机滑行全过程和全场景的多尺度目标图像.数据集中的典型图像和标注如图6所示.
图6

图6
机场场面目标数据集的典型图像和标注示例
Fig.6
Typical image and annotation examples from airfield object dataset
图7
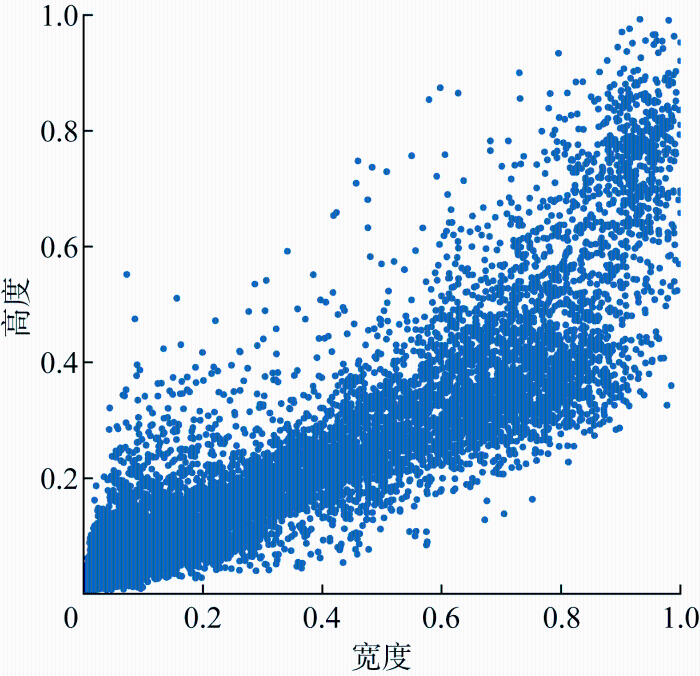
图7
自建数据集目标尺寸归一化分布
Fig.7
Normalized statistic of self-built datasets object size
3.2 实验环境
实验硬件平台配置为CPU 11th Gen Intel(R) Core(TM) i7-11700、GPU NVIDIA GeForce RTX 3070(8 GB)、内存64 GB,该配置与实际的机载计算平台相当.开发环境为Pytorch 1.11.0.采用 CUDA11.3 作为GPU运行支持库.在YOLOv5s第7代版本基础上开发算法.
算法评估指标主要包括:R=0.5条件下的均值平均精度(mean average precision,mAP)、参数量、计算量(floating point operations,FLOPs)、帧率(frame per second,FPS)等.
自建数据集中80%用于训练,20%用于测试.训练迭代次数为300次,批次大小设置为32,初始学习率设置为0.01,训练动量设置为0.937,梯度下降算法为余弦退火算法.
3.3 实验结果分析
3.3.1 多尺度目标检测效果对比实验
为验证所提算法对不同尺度目标的检测效果,将提出算法与原YOLOv5s进行对比.
图8所示为3种尺度目标的mAP对比结果,所提算法对小目标的检测精度提升3.1个百分点,中目标检测精度提升3.7个百分点,大目标检测精度提升2.2个百分点.所提算法在3种尺度目标上的检测精度均有明显提升.
图8
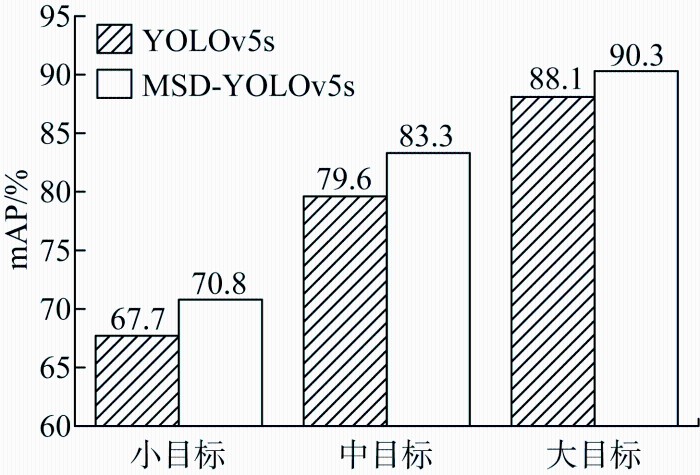
图8
YOLOv5s与MSD-YOLOv5s不同尺度目标检测对比
Fig.8
Comparison of objects detection at different scales between YOLOv5s and MSD-YOLOv5s
图9展示了YOLOv5s和所提算法在正常光照、低光照、遮挡、特殊天气条件下的多尺度目标检测可视化结果.在这4个典型检测场景中,所提算法的检测结果较YOLOv5s更为全面,特别是能检测到YOLOv5s漏检的远处机务工作人员、特种车辆等小目标.由此可见,对于同一幅画面,所提算法在保证大尺寸飞机时,在特种车辆和机务工作人员等小目标上的检出率更高.由此可见,所提算法提高了多尺度目标的检测能力.
图9

图9
YOLOv5s与MSD-YOLOv5s多尺度目标推理对比
Fig.9
Comparison of multi-scale object inference between YOLOv5s and MSD-YOLOv5s
3.3.2 GSConv解耦检测头验证
为验证GSDetector的有效性,将使用耦合检测头的YOLOv5s、使用普通解耦检测头的YOLOv5s(记作YOLOv5s-D)和基于GSConv设计的解耦检测头(记作YOLOv5s-GSD)分别进行训练和测试,实验结果如表1所示.采用GSDetector的YOLOv5s在mAP基本保持不变的情况下,较YOLOv5s-D参数量和计算量均下降约20%,FPS提高51.6%.实验证明,GSDetector在提高模型精度的同时,一定程度降低了解耦造成的参数量增强,对于多尺度目标检测速度提升有明显作用.
表1 轻量化解耦头对比
Tab.1
| 名称 | mAP/% | 参数量/MB | 计算量/GB | FPS/(帧·s-1) |
|---|---|---|---|---|
| YOLOv5s | 67.21 | 7.1 | 15.8 | 84 |
| YOLOv5s-D | 69.10 | 14.3 | 56.2 | 31 |
| YOLOv5s-GSD | 69.00 | 11.2 | 45.3 | 47 |
3.3.3 轻量化颈部验证
以YOLOv5s为基准,分别引入GSDetector、Slim-Neck模块和DC Slim-Neck,得到YOLOv5s-GSD、YOLOv5s-GSD-SN、YOLOv5s-GSD-DCSN网络,实验结果如表2所示.YOLOv5s-GSD-SN的mAP下降0.8个百分点,FPS提高51%.YOLOv5s-GSD-DCSN的mAP仅下降0.2个百分点,FPS提高51%.实验证明DC Slim-Neck模块可在精度无明显下降的前提下,较大程度地提高模型的计算效率.
表2 轻量化颈部对比
Tab.2
| 名称 | mAP/% | 参数 量/MB | 计算 量/GB | FPS/ (帧·s-1) |
|---|---|---|---|---|
| YOLOv5s-GSD | 69.0 | 11.2 | 45.3 | 47 |
| YOLOv5s-GSD-SN | 68.2 | 9.7 | 33.7 | 71 |
| YOLOv5s-GSD-DCSN | 68.8 | 9.7 | 33.7 | 71 |
3.3.4 消融实验
针对特征融合网络CA-BIFPN、解耦检测头GSDetector、轻量化颈部DC Slim-Neck、EIoU损失函数进行消融实验,实验结果如表3所示.
表3 消融实验对比
Tab.3
| 方法 | mAP/% | 参数量/MB | 计算量/GB | FPS/ (帧·s-1) |
|---|---|---|---|---|
| YOLOv5s | 67.21 | 7.1 | 15.8 | 84 |
| +CA-BIFPN | 68.49 | 7.2 | 16.2 | 75 |
| +GSDetector | 70.95 | 12.3 | 43.7 | 47 |
| +DC Slim-Neck | 70.93 | 9.8 | 30.1 | 71 |
| +EIoU | 71.40 | 9.8 | 30.2 | 71 |
引入CA-BIFPN网络后,mAP提升1.28个百分点;解耦检测头GSDetector的使用,将各个目标的分类任务和定位任务相互独立,检测精度提高了2.46个百分点,证明了GSDetector的有效性;DC Slim-Neck颈部的轻量化设计在保证精度没有明显损失的前提下,参数量下降 2.5 MB,计算量下降13.6 GB,FPS提高超过50%,证明了DC Slim-Neck的有效性;引入EIoU损失函数后,模型精度略微提升0.47个百分点,但对图9中小目标的检测,体现出优越性.总体上,随着各改进措施的加入,mAP不断提升,参数量、计算量均在交替下降;虽然FPS较原始算法略有下降,但仍然维持在71帧/s的水平.可见,所提算法的各项改进措施有效,提升了多尺度目标检测的综合性能.
3.3.5 典型算法对比
为验证所提算法的检测性能,与经典目标检测算法RetinaNet[8]、Faster R-CNN[3]和SSD[4],以及典型多尺度目标检测算法YOLOv6[22]、YOLOv7[23]、YOLOv8[24]和YOLOX[25]等进行对比.将不同算法在构建的场面多尺度目标检测数据集上分别进行训练和测试实验,记录mAP、参数量、计算量和帧率,如表4所示.相较于其他主流目标检测模型,所提算法达到最高的检测精度,参数量与最低的RetinaNet和YOLOX差异不大,计算量较远原YOLOv5s下降约50%,但较其他算法有明显优势.由此可见,所提算法在场面多尺度目标的检测速度和精度方面保持了较为均衡的性能,在保证较高检测精度的前提下具有较好的实时性.
表4 典型算法对比
Tab.4
4 结语
针对民机可视导航中的场面目标尺度变化大和机载计算平台算力受限的问题,提出一种改进YOLOv5s的轻量化多尺度目标检测算法MSD-YOLOv5s,能够实现机场场面多尺度目标的高精度检测,且计算复杂度较低,在机载计算平台条件下具有较好的实时性.另外,构建了飞行模拟软件实景图像、机载视觉传感器实际拍摄图像和网络搜集图像组成的多尺度目标图像数据集,各尺度目标分布均衡,总数量超过1万帧,可有效应用于机载视觉传感器机场场面目标检测模型训练、测试和评估.
以YOLOv5s为基础,由特征融合网络CA-BIFPN、GSConv解耦检测头、轻量化颈部和EIoU损失函数等组成的4项改进措施使提出算法在构建的场面目标图像数据集上的mAP不断提升;同时,参数量和计算量交替下降,mAP达到71.40%,检测速度达到71帧/s;多尺度目标的检测结果稳定,在保持飞机等大尺度目标能够正确检测的同时,对远处机务工作人员、特种车辆等小尺度目标仍能保持正确分类和定位.
参考文献
Airbus demonstrates the first fully automatic vision-based take-off
[EB/OL]. (
多尺度目标检测的深度学习研究综述
[J].
Deep learning for multi-scale object detection: A survey
[J].
Faster R-CNN: Towards real-time object detection with region proposal networks
[J].
DOI:10.1109/TPAMI.2016.2577031
PMID:27295650
[本文引用: 3]

State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet [1] and Fast R-CNN [2] have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection. We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features-using the recently popular terminology of neural networks with 'attention' mechanisms, the RPN component tells the unified network where to look. For the very deep VGG-16 model [3], our detection system has a frame rate of 5 fps (including all steps) on a GPU, while achieving state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image. In ILSVRC and COCO 2015 competitions, Faster R-CNN and RPN are the foundations of the 1st-place winning entries in several tracks. Code has been made publicly available.
SSD: single shot MultiBox detector
[C]
Feature pyramid networks for object detection
[C]
EfficientDet: Scalable and efficient object detection
[C]
YOLOv3: An incremental improvement
[DB/OL]. (
Focal loss for dense object detection
[J].
基于改进Faster-RCNN的机场场面小目标物体检测算法
[J].
Small target detection in airport scene via modified faster-RCNN
[J].
改进SSD的机场场面多尺度目标检测算法
[J].
DOI:10.3778/j.issn.1002-8331.2010-0110
[本文引用: 1]
针对现有基于深度学习的通用目标检测方法对机场场面环境目标尺度差别大,特别是小目标难以检测到的问题,提出了一个基于SSD算法并结合特征金字塔融合网络的多尺度目标检测算法。该算法采用了更深的ResNet-50作为骨干网络,并单独设计了六层额外特征层。使用特征金字塔网络进行特征融合,以获得更鲁棒的语义信息。使用Soft-NMS以解决存在的漏检情况,调整先验框的尺度比以更好地检测小目标。通过在机场场面数据集实验表明,该改进算法能够在推断速度为32?frame/s的情况下,取得86.31%的mAP,对比其他先进的检测器,达到领先水平。
Improved SSD-based multi-scale object detection algorithm in airport surface
[J].
DOI:10.3778/j.issn.1002-8331.2010-0110
[本文引用: 1]
Aiming at the problem that the existing general object detection method based on deep learning is difficult to detect the airport scene environment object with large scale difference, especially small targets are difficult to detect. This paper proposes a multi-scale object detection algorithm based on SSD algorithm combined with feature pyramid fusion network. The algorithm first uses ResNet-50 as the backbone network, and separately designs six additional feature layers. Secondly, the feature pyramid network is used for feature fusion to obtain more robust semantic information. Finally, Soft-NMS is used to solve the missing detection situation, and the scale ratio of the prior frame is adjusted to better detect small objects. Experiments on the airport surface dataset show that the improved algorithm can achieve 86.31% mAP when the inferred speed is 32?frame/s, which is at the leading level compared with other advanced detectors.
Deep residual learning for image recognition
[C]
Slim-neck by GSConv: A lightweight-design for real-time detector architectures
[J].
Xception: Deep learning with depthwise separable convolutions
[C]
Multi-scale dilated convolution network based depth estimation in intelligent transportation systems
[J].
ShuffleNet: An extremely efficient convolutional neural network for mobile devices
[C]
Mobilenet-SSDv2: An improved object detection model for embedded systems
[C]
YOLOv4: Optimal speed and accuracy of object detection
[DB/OL]. (
YOLOv5
[EB/OL]. (
Multi-target detection in airport scene based on Yolov5
[C]
Path aggregation network for instance segmentation
[C]
Microsoft COCO: Common objects in context
[C]
A novel finetuned YOLOv6 transfer learning model for real-time object detection
[J].
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
[C]
An improved YOLOv8 to detect moving objects
[J].
Uncertainty-aware accurate insulator fault detection based on an improved YOLOX model
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}