自动驾驶环境感知技术正在经历快速迭代,过往研究主要增强自动驾驶车辆自身的感知能力.单车智能感知主要依赖车辆搭载的传感器来感知周围环境,如摄相机、雷达和激光雷达等[1 ] .尽管这些传感器可以提供丰富的信息,但由于受到范围、分辨率和视野盲区等限制,仍然存在一些局限性,尤其是在如交叉口、环岛和人车混杂路段等复杂场景下,这些局限性可能会威胁到自动驾驶系统的安全性[2 ] .受限于单车智能感知的固有局限性,研究重心逐渐由单车智能感知向车路协同感知转移,多传感器、多智能体的协同感知技术的重要性日益突显.引入路端感知系统不仅增强了对道路环境的理解,还提供了冗余信息以降低漏检、误检,拓展了车辆端的感知范围与精度,从而为自动驾驶系统的安全性提供了重要支持[1 ,3 ] .
自动驾驶场景的协同感知需要实时采集和处理来自多端的海量传感器数据,包括但不限于图像、激光雷达点云、毫米波雷达信号等.这些数据不仅需要在车辆内部进行处理,还需要与其他车辆端和路端单元进行通信共享,以实现协同配合的区域感知.根据数据协同共享的不同时期,现有协同感知方法可分为3种协同机制[1 ] :早期数据级协同、中期特征级协同、后期目标级协同.3种协同机制都可以有效扩展单车感知的范围和视场.
早期数据协同强调原始数据的共享,可以充分互补并深度整合不同来源的原始信息,但面临数据噪声混杂、高通信带宽需求等挑战[1 ] .Arnold等[2 ] 融合不同位置的路端传感器数据,传送到融合系统形成区域点云描述,由融合系统的检测模型得到目标边界框,利用CARLA模拟器[4 ] 仿真验证.Chen等[5 ] 基于点云数据设计车辆间协同感知模型,拓展了单车感知范围,证明了车辆间传递点云数据的可行性.
中期特征级协同强调对数据的语义特征提取与融合.已有研究提出基于点云特征的协同感知框架和协同空间特征融合方法[6 -7 ] ,前者实现数据压缩并适用于边缘计算,后者根据语义信息设定特征图权重指导特征融合,提高了检测精度和检测范围.
后期目标级协同主要关注输出层信息的共享与协作.各检测网络模型独立且仅共享检测结果,实现高效计算资源利用.这种协同机制在资源管理和带宽利用方面表现出色,但其输出数据可能受噪声干扰、不完整或只反映部分信息,影响整体感知效果.
综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性.
1 双流特征提取网络的车路协同设计
1.1 协同场景建模
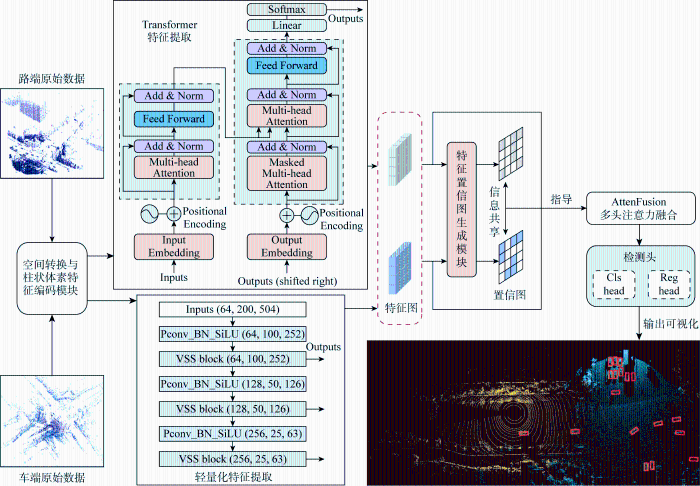
如图1 所示,车路协同感知场景中存在路侧智能设备与自动驾驶车辆两类平台,分别可获取车端感知数据V 和路端感知数据R. 提出的特征提取网络记为X ,经过特征提取后的车端特征表示为x v ,路端特征表示为x r ,(x v , x r )=X (V , R )且提取的特征对多源数据间的融合具有较好的适应性. 融合路端设备特征后的车端特征表示为F ,F =Fusion(x v , x r ),其中Fusion表示多特征融合网络.车路间特征传递的高效通信模型,在一定通信带宽的限制下,尽可能获得最优感知效果.
图1
图1
协同感知场景示意图
Fig.1
Example of collaborative perception scene
1.2 模型整体框架
针对车路协同检测的场景将特征提取网络分为车端和路端两部分,二者特征提取部分的模型相互独立,设计了基于车路协同的3D目标检测框架结构,如图2 所示,其工作流程为:车端和路端的原始数据经过坐标系转换、柱状体素特征编码[12 ] 等处理转换,得到鸟瞰视图(BEV)空间下转换展平的伪图像编码信息,以便更充分地进行特征提取与特征融合.经过不同特征提取后,网络相互独立,分别输出对应的多尺度特征信息.对时空统一的特征图进行区域评分,将评分高的区域作为关键感知信息参与通信共享,用以指导补充其他交通参与者因稀疏、遮挡、感知能力受限造成的信息缺失.在评分指导下利用多头自注意力机制将信息共享的特征图进行融合,检测头输出预测结果,并可视化渲染.这些模块共同构成一个综合的目标检测系统,实现车辆与道路环境的协同感知.
图2
图2
车路协同检测框架整体结构
Fig.2
Overall structure of vehicle road collaborative detection framework
1.3 车-路双流特征提取网络
提出车-路双流特征提取网络,将特征提取网络拆分,根据车路端平台的特点分别设计.
1.3.1 路端特征提取
基于路端设备较强的计算能力以及较为丰富的感知数据,采用Transformer架构处理数据间的关联性,以获取深层的数据关系[13 ] , 见图2特征提取模块.其中,Input Embedding为输入嵌入层模块;Positional Encoding为位置信息添加模块;Multi-head Attention为多头自注意力模块;Add & Norm为包含残差连接和层归一化的网络处理模块;Feed Forward为前馈神经网络模块;Output Embedding为输出嵌入模块;Masked Multi-head Attention为带掩码的多头注意力模块;Linear为线性化模块.Transformer结构中虚线框分别对应编码器与解码器,Embedding部分将输入伪图像拆分转换为向量矩阵表示,通过Positional Encoding添加位置信息,传递至Multi-head Attention模块计算多头注意力权重,经Feed Forward模块非线性变换提取特征与Add & Norm模块加权归一化处理,以稳定训练过程;解码后由Linear进行全连接层简化处理,Softmax函数输出概率分布.Transformer核心是自注意力(Self-Attention)机制,计算公式为
(1) $\operatorname{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}}{\sqrt{d}}\right) \boldsymbol{V}$
式中:Attention()为自注意力函数;softmax()为柔性最大值函数,将输入映射为0~1之间的实数;(Q , K , V )分别表示查询、键值和值的矩阵;d 为向量维度,通过平方根实现归一化.
多头自注意力在自注意力机制的基础上引入了多个注意力头,每个头可以学习不同的注意力权重,从而提高模型对不同特征和信息的捕获能力,进一步提升模型的表征学习效果,其计算方式为
(2) $\operatorname{MultiHead}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{Concat}\left(\boldsymbol{h}_{1}, \cdots, \boldsymbol{h}_{n}\right) \boldsymbol{W}$
(3) $\boldsymbol{h}_{i}=\operatorname{Attention}\left(\boldsymbol{Q} \boldsymbol{W}_{i}^{Q}, \boldsymbol{K} \boldsymbol{W}_{i}^{\boldsymbol{K}}, \boldsymbol{V} \boldsymbol{W}_{i}^{\boldsymbol{V}}\right)$
式中:MultiHead()为多头自注意力函数;h 表示注意力头(head);Concat()为连接函数,可将多个自注意力在某个维度上叠加;W 是对连接输出的线性变换矩阵.
参考Swin-Transformer进行结构分层,利用不同尺寸窗口捕获不同范围特征,每个窗口非重叠均匀划分伪图像,有助于处理伪图像中的局部和全局信息,对于理解复杂道路环境和交通场景十分有益.为保持高效计算且引入跨窗口连接,采用了交替窗口分区方法,在连续的多层感知机(MLP)模块之间交替使用两种分区配置[14 ] .为了减少信息丢失,在不同阶段之间的下采样层采用线性层和逆残差模块进行联合构筑.
1.3.2 车载端特征提取
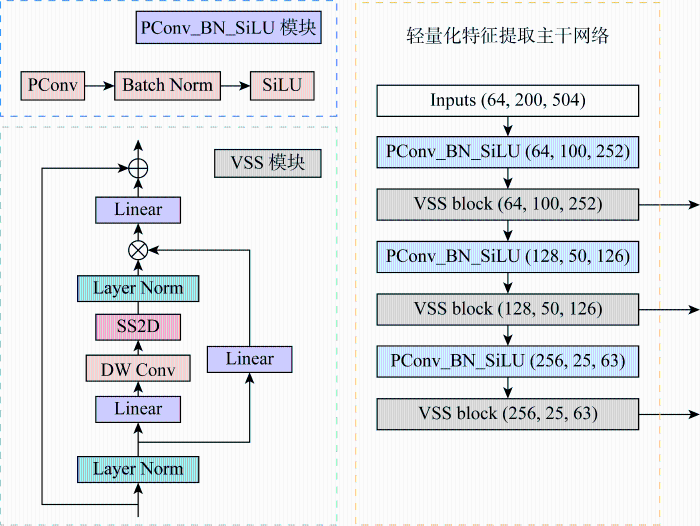
车载计算资源通常有限,受限于功耗、空间和散热等因素,因此提出一种轻量化特征提取网络,如图3 所示.图中:PConv_BN_SiLU 为轻量化的卷积特征提取模块,其中PConv为部分卷积模块;Batch Norm为批量归一化模块;SiLU 为激活函数模块.VSS Block 为特征提取模块,其中Layer Norm为归一化模块;DW Conv为深度可分离卷积模块;SS2D为空间立体降维模块.
图3
图3
车端轻量化特征提取主干网络设计
Fig.3
Design of lightweight feature extraction backbone network for vehicle-side
网络使用部分卷积PConv代替传统卷积Conv2d,在输入通道的一部分上应用卷积滤波器,同时保留剩余通道不变,再与被卷积部分重新拼接到一起,从而提供更有效的空间特征提取[15 ] .参考Mamba架构对BasicBlock模块进行优化,引入VSS模块[16 ] .此模块包含两个主要分支,一个用于处理通道信息,另一个用于处理空间信息.第一个分支通过线性层和激活函数处理输入,第二个分支通过深度可分离卷积和激活函数进行处理,两个分支的输出通过元素级相加的方式合并,形成模块的最终输出.此结构使网络更有效地捕获伪图像中的复杂细节和更广泛的语义上下文.
1.4 特征通信共享
解决单车在自动驾驶感知中遇到的遮挡和视距问题,需要通过车路间多智能体和多视角的合作.受限于实际通信速率与带宽的压力,需要协同系统高效地使用有限的通信资源,提取并传递关键的感知信息,针对性通信共享以互补感知能力.
车路协同检测框架中特征通信部分参考Where2comm[8 ] 的思想.分析车路端的特征图判断某个检测区域是否存在目标,为各空间区域分配一个置信度评分,评分反映该区域存在目标物体的概率.依据感兴趣区域的评分,构建反映感知空间内区域重要性的概率分布图,即置信图[17 ] .基于区域置信图的特征共享方式,优先关注置信度高的区域,减少对背景区域的关注,节省通信带宽和计算资源,后续实验部分证明此特征共享方法的优势.
1.5 特征融合与检测头
特征融合以各端感知的特征向量为节点,连接不同交通参与者在相同空间位置下的特征向量.多头自注意力机制得到的不同区域权重,用于共享信息与本地感知特征融合,增强感知水平较高的特征在融合中的优势,整合表达了来自多个参与者的观测信息,以多角度获取环境细节的丰富性和多样性.
检测头网络利用融合特征预测目标的类别和位置,类别预测分支输出各锚框内目标存在的分数和概率,边界框回归分支负责预测目标的精确位置、3D偏移量和航向角等信息,实现精确的目标检测.
2 实验验证
2.1 实验环境配置与参数
在Ubuntu 20.04.6系统搭建实验平台进行算法的训练和验证,实验环境CPU为Intel i9-13900KS,GPU为NVIDIA GeForce RTX 4090,开发环境为Python 3.8,深度学习框架选用Pytorch 1.13.1,GPU加速架构 CUDA版本11.8,神经网络加速cuDNN版本8.0.
实验测试得到模型在30轮训练后结果指标稳定,因此设置训练轮数为30.为保证算法比较的一致性,当训练、验证实验涉及到相关参数时,均参考以下指标:神经网络优化器为SGD,采用余弦退火学习率衰减算法,设置初始学习率为0.001,最终学习率为1×10-5 ,动量为0.937,批量大小为6,权重衰减率为 0.000 5.
2.2 数据集
DAIR-V2X是一个用于车-路协作3D物体检测的真实世界大规模数据集[18 ] .数据集包含车端数据和路端数据,各端包含多种传感器类型的数据,如摄相机图像和激光雷达点云.实验在DAIR-V2X车路协同数据集上进行训练和验证,选取激光雷达数据作为模型输入.
2.3 实验结果与分析
2.3.1 双流特征提取网络实验
为保证实验的一致性,输入和输出的特征图尺寸保持相同,为200像素×504像素,输出不同尺度特征图的通道数分别为64、128和256,对不同特征提取主干网络的效果进行分析.表1 展示了本文分流特征提取方法与车端、路端模型共用主干方法的对比结果.采用平均精度(average precision,AP)作为精度评价指标,分别设置IoU(intersection over union)阈值为0.3、0.5、0.7评估综合检测效果.此外,还通过模型大小与模型中浮点运算操作总数(GFLOPs)评估模型规模与计算复杂度.
相较于车端和路端都使用轻量化模型的方法,本文方法在检测精度方面具有明显优势.轻量化单主干模型中FasterNet的AP30为63.10%,AP50为57.25%,AP70为38.75%,具有轻量化模型中最好的检测效果.在保持车端参数量处于相似水平的情况下,本文方法较FasterNet精度分别提升了9.25百分点、10.42百分点、14.99百分点.可见对模型进行拆分后,路端大规模网络对检测效果有明显的改善作用.相较于车端和路端都使用大规模模型的方法,本文方法在保持检测效果大致相同的情况下具有更低的模型规模.在大规模单主干模型中,Swin-Transformer的表现结果最佳,AP30为71.17%,AP50为66.36%,AP70为52.44%,与本文方法对比有1个百分点左右的差距,本方法在路端特征提取网络略微增加了模型大小与计算量,但车载端特征提取网络大幅缩减.由结果综合分析,本方法在模型规模和检测效果间取得了较好的平衡.
表2 为车端轻量化特征提取网络的消融实验结果,可以看出引入PConv结构后AP30和AP50有所提升,AP70略有下降,是因为应用部分卷积PConv结构可以提高模型在较宽松IoU阈值下的性能,但信息损失会在更严格的IoU阈值下表现为性能下降.模型还使用了Mamba-VSS技术.从结果来看,所有IoU阈值下的性能都有显著提升,AP30和AP50表明Mamba-VSS技术对于提高模型的检测精度非常有效.模型大小从13.5 MB减小到了8.1 MB,表明Mamba-VSS有助于减少模型大小.
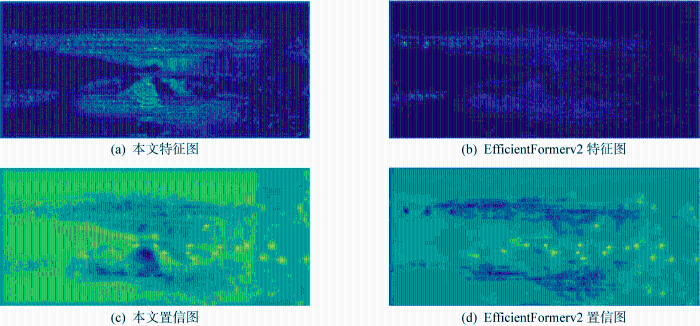
图4(a) 和4(b) 展示了轻量化主干网络类别中不同模型的车端特征图,可看到所提出的特征提取主干网络对整体特征提取能力更强,模型对目标特征的关注度更高.图4(c) 和4(d) 展示了不同模型的车端置信图,可以看出本文算法对目标的捕捉能力更强,且能够抑制非目标区域的置信度.
图4
图4
车端特征图和置信图可视化对比
Fig.4
Visual comparison between feature and confidence graphs from vehicle
2.3.2 协同感知模型对比实验
表3 进一步对比分析不同的协同感知模型[18 ⇓ ⇓ -21 ] ,不考虑额外的数据、特征和模型压缩,通信量按字节计算,以2为底的对数表示,通信量计算公式[8 ] 为
(4) $C=1 \mathrm{~b}\left(\left\|M_{\mathrm{rv}}^{(k)}\right\|_{0} D \times 32 / 8\right)$
式中:‖M r v ( k ) 0 为需要传输的总空间网格;D 对应各特征通道维度,乘以32作为float32数据类型,除以8作为度量字节;k 为通信轮次;下标rv表示路端信息共享车端.
表3 展示了不同协同感知方法在数据集中的检测效果.相较于不协同的方法[18 ] ,车路协同方法均取得了更高的检测精度,表明车路协同能够有效提高自动驾驶的全面感知能力.目标级协同方法Late Fusion的AP50为53.12%,与特征级协同方法相近,但在更高IoU阈值情况下,此类方法在车路端的目标位置、大小、航向角等检测结果的融合上存在更多误差.本文方法AP50、AP70比先前最佳方法提高了4.13百分点和4.96百分点,且在特征协同方法中参考区域置信图的通信策略,仅对所需部分区域特征传递,通信率较低.
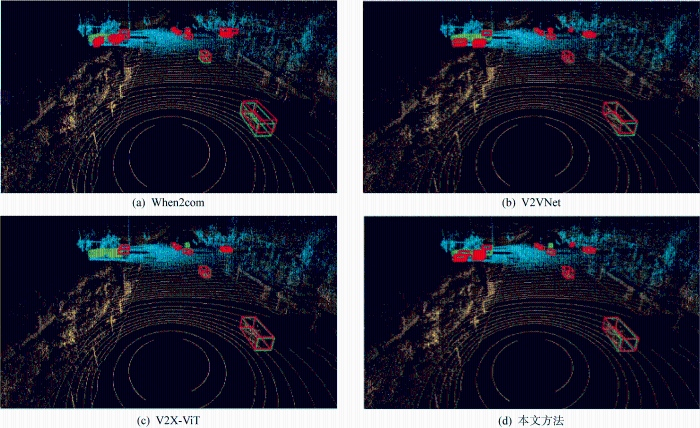
图5 和图6 分别为3D视角和BEV视角下协同感知结果.为了清晰展现车端和路端感知区域,图中分别用黄色、蓝色对车路端的点云数据进行可视化着色;绿色框表示实际目标位置,红色框表示网络检测结果.车端点云在右侧区域较为稀疏甚至消失,表明由于遮挡和距离无法有效感知远处的目标.右侧区域路端的点云稠密,车辆可与路端感知协同交互实现该区域目标的超视距感知.When2com[9 ] 可检测到大部分目标,但检测朝向存在较多偏转.V2X-ViT[20 ] 对路端的协同较差,路端区域的目标出现较多漏检.结果显示本方法的检测准确率更高,漏检率更低,大部分的目标都能被正确检测到,且检测框与标注框的匹配度更高,表明本文模型对车辆的形状、方向具备更好的检测能力.
图5
图5
3D视角下不同协同框架的感知结果比较
Fig.5
Comparison of perception results of different collaborative frameworks in 3D view
图6
图6
BEV视角下不同协同框架的感知结果比较
Fig.6
Comparison of perception results of different collaborative frameworks in BEV view
3 结语
本文提出基于双流异构网络的车路协同检测方法,针对车路端感知场景的特点,分别针对车端和路端设计不同的网络结构,以适应各自的计算能力和感知需求.通过空间置信图和基于需求的通信共享方式优化车路端的协同感知的部署,为处理复杂交通环境中的感知问题提供了新思路.在真实世界数据集的车路协同感知场景下进行测试,检测结果与可视化分析表明,该方法在提高遮挡目标的识别率、远距离目标的感知能力等方面都具有一定优势;相较于现有的感知方法,该方法能够有效提升车路协同感知系统的整体性能.
参考文献
View Option
[1]
伊笑莹 , 芮一康 , 冉斌 , 等 . 车路协同感知技术研究进展及展望
[J]. 中国工程科学 2024 , 26 (1 ): 178 -189 .
DOI:10.15302/J-SSCAE-2024.01.016
[本文引用: 4]
近年来,我国自动驾驶研究逐步从聚焦于单车智能技术向车路协同技术转变,为智能交通产业发展带来了重大机遇;我国在车路协同感知领域的研究虽处于起步阶段,但注重技术推动,未来发展前景广阔。本文致力于深入探讨车路协同感知技术的发展动态,梳理了车路协同感知基础支撑技术的特性和发展现状,厘清了车路协同感知技术的研究进展,探讨了其技术发展趋势,并针对推动车路协同感知技术发展提出了一系列建议。研究表明,车路协同感知技术正朝着多源数据融合方向发展,主要集中在纯视觉协同感知技术优化、激光雷达点云处理技术升级、多传感器时空信息匹配与数据融合技术发展以及车路协同感知技术标准体系构建等方面。为进一步促进我国车路协同自动驾驶产业的迅速成长,研究建议,加大对多模态车路协同感知技术的研发投入、深化行业间的合作、制定统一的感知数据处理技术标准并加速技术应用普及,以期推动我国在全球自动驾驶竞争中赢得主动,推动自动驾驶行业稳定持续发展。
YI Xiaoying RUI Yikang RAN Bin et al Vehicle-infrastructure cooperative sensing: Progress and prospect
[J]. Strategic Study of CAE 2024 , 26 (1 ): 178 -189 .
DOI:10.15302/J-SSCAE-2024.01.016
[本文引用: 4]
Recently, the autonomous driving industry in China has been gradually shifting its focus from individual-vehicle intelligence to vehicle‒infrastructure cooperation. This shift has brought significant opportunities for the intelligent transportation industry. Although research on vehicle‒infrastructure cooperative sensing is still in its early stage in China, it shows a strong dedication to technological innovation, indicating significant potentials for future growth. This study examines the development status of vehicle‒infrastructure cooperative sensing and thoroughly explores the characteristics and status of core technologies that support vehicle‒infrastructure cooperative sensing. It discusses ongoing advancements in this field, investigates future technology trends, and proposes a range of recommendations for further development. Research indicates that vehicle‒infrastructure cooperative sensing is evolving toward the integration of multi-source data. Presently, its development directions mainly focus on the optimization of pure visual cooperative sensing, upgrades in LiDAR point cloud processing, advancements in multi-sensor spatiotemporal information matching and data fusion, as well as the establishment of a standards system for vehicle‒infrastructure cooperative sensing technologies. To further boost the rapid growth of vehicle‒infrastructure cooperation in China, increasing investment in the research and development of relevant technologies is advised. Enhancing partnerships among different industry sectors, establishing unified standards for processing perception data, and expediting the broad application of these technologies are also key recommendations. These strategies aim to position China advantageously in the global market of autonomous driving, contributing to the sustainable development of the industry.
[2]
ARNOLD E DIANATI M DE TEMPLE R et al Cooperative perception for 3D object detection in driving scenarios using infrastructure sensors
[J]. IEEE Transactions on Intelligent Transportation Systems 2022 , 23 (3 ): 1852 -1864 .
[本文引用: 3]
[3]
张毅 , 姚丹亚 , 李力 , 等 . 智能车路协同系统关键技术与应用
[J]. 交通运输系统工程与信息 2021 , 21 (5 ): 40 -51 .
[本文引用: 1]
ZHANG Yi YAO Danya LI Li et al Technologies and applications for intelligent vehicle-infrastructure cooperation systems
[J]. Journal of Transportation Systems Engineering and Information Technology 2021 , 21 (5 ): 40 -51 .
[本文引用: 1]
[4]
DOSOVITSKIY A ROS G CODERVILLA F et al CARLA: An open urban driving simulator
[C]//1st Conference on Robot Learning . Mountain View , USA : CoRL , 2017 : 5550767 .
[本文引用: 1]
[5]
CHEN Q TANG S H YANG Q et al Cooper: Cooperative perception for connected autonomous vehicles based on 3D point clouds
[C]//2019 IEEE 39th International Conference on Distributed Computing Systems . Dallas, TX , USA : IEEE , 2019 : 514 -524 .
[本文引用: 2]
[6]
CHEN Q F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds
[DB/OL]. (2019-09-13 )[2024-06-10 ]. https://arxiv.org/abs/1909.06459.
URL
[本文引用: 2]
[7]
GUO J D CARRILLO D TANG S H et al CoFF: Cooperative spatial feature fusion for 3-D object detection on autonomous vehicles
[J]. IEEE Internet of Things Journal 2021 , 8 (14 ): 11078 -11087 .
[本文引用: 2]
[8]
HU Y FANG S LEI Z et al Communication-efficient collaborative perception via spatial confidence maps
[C]//36th Corference on Neural Information Processing Systems . New Orleans , USA : NIPS , 2022 : 4874 -4886 .
[本文引用: 3]
[9]
LIU Y C TIAN J J GLASER N et al When2com: Multi-agent perception via communication graph grouping
[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle, WA , USA : IEEE , 2020 : 4105 -4114 .
[本文引用: 2]
[10]
WANG J Y ZENG Y GONG Y Collaborative 3D object detection for automatic vehicle systems via learnable communications
[DB/OL]. (2022-05-24 ) [2024-06-10 ]. https://arxiv.org/abs/2205.11849v1.
URL
[本文引用: 1]
[11]
王秉路 , 靳杨 , 张磊 , 等 . 基于多传感器融合的协同感知方法
[J]. 雷达学报 2024 , 13 (1 ): 87 -96 .
[本文引用: 1]
WANG Binglu JIN Yang ZHANG Lei et al Collaborative perception method based on multisensor fusion
[J]. Journal of Radars 2024 , 13 (1 ): 87 -96 .
[本文引用: 1]
[12]
LANG A H VORA S CAESAR H et al PointPillars: Fast encoders for object detection from point clouds
[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach, CA , USA : IEEE , 2019 : 12689 -12697 .
[本文引用: 1]
[13]
DOSOVITSKIY A BEYER L KOLESNIKOV A et al An image is worth 16×16 words: Transformers for image recognition at scale
[DB/OL]. (2020-10-22 )[2024-06-10 ]. https://arxiv.org/abs/2010.11929.
URL
[本文引用: 1]
[14]
LIU Z LIN Y T CAO Y et al Swin transformer: Hierarchical vision transformer using shifted windows
[C]//2021 IEEE/CVF International Conference on Computer Vision . Montreal, QC , Canada : IEEE , 2021 : 9992 -10002 .
[本文引用: 1]
[15]
CHEN J R KAO S H HE H et al Run, don’t walk: Chasing higher FLOPS for faster neural networks
[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver, BC , Canada : IEEE , 2023 : 12021 -12031 .
[本文引用: 1]
[16]
GU A DAO T Mamba: Linear-time sequence modeling with selective state spaces
[DB/OL]. (2023-12-01 )[2024-06-10 ]. https://arxiv.org/abs/2312.00752v2.
URL
[本文引用: 1]
[17]
上海交通大学 . 基于空间置信度图的多轮多模态多智能体的协同感知方法: CN 202211076556.X [P]. 2022-12-13[2024-06-10].
[本文引用: 1]
[18]
YU H B LUO Y Z SHU M et al DAIR-V2X: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection
[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans, LA , USA : IEEE , 2022 : 21329 -21338 .
[本文引用: 3]
[19]
WANG T H MANIVASAGAM S LIANG M et al V2VNet: Vehicle-to-Vehicle communication for joint perception and prediction [M]//Computer Vision-ECCV 2020. Cham : Springer , 2020 : 605 -621 .
[本文引用: 1]
[20]
XU R S XIANG H TU Z Z et al V2X-ViT: Vehicle-to-Everything cooperative perception with Vision Transformer [M]//Computer Vision-ECCV 2022. Cham : Springer , 2022 : 107 -124 .
[本文引用: 2]
[21]
MEHR E JOURDAN A THOME N et al DiscoNet: Shapes learning on disconnected manifolds for 3D editing
[C]//2019 IEEE/CVF International Conference on Computer Vision . Seoul : IEEE , 2019 : 3473 -3482 .
[本文引用: 1]
车路协同感知技术研究进展及展望
4
2024
... 自动驾驶环境感知技术正在经历快速迭代,过往研究主要增强自动驾驶车辆自身的感知能力.单车智能感知主要依赖车辆搭载的传感器来感知周围环境,如摄相机、雷达和激光雷达等[1 ] .尽管这些传感器可以提供丰富的信息,但由于受到范围、分辨率和视野盲区等限制,仍然存在一些局限性,尤其是在如交叉口、环岛和人车混杂路段等复杂场景下,这些局限性可能会威胁到自动驾驶系统的安全性[2 ] .受限于单车智能感知的固有局限性,研究重心逐渐由单车智能感知向车路协同感知转移,多传感器、多智能体的协同感知技术的重要性日益突显.引入路端感知系统不仅增强了对道路环境的理解,还提供了冗余信息以降低漏检、误检,拓展了车辆端的感知范围与精度,从而为自动驾驶系统的安全性提供了重要支持[1 ,3 ] . ...
... [1 ,3 ]. ...
... 自动驾驶场景的协同感知需要实时采集和处理来自多端的海量传感器数据,包括但不限于图像、激光雷达点云、毫米波雷达信号等.这些数据不仅需要在车辆内部进行处理,还需要与其他车辆端和路端单元进行通信共享,以实现协同配合的区域感知.根据数据协同共享的不同时期,现有协同感知方法可分为3种协同机制[1 ] :早期数据级协同、中期特征级协同、后期目标级协同.3种协同机制都可以有效扩展单车感知的范围和视场. ...
... 早期数据协同强调原始数据的共享,可以充分互补并深度整合不同来源的原始信息,但面临数据噪声混杂、高通信带宽需求等挑战[1 ] .Arnold等[2 ] 融合不同位置的路端传感器数据,传送到融合系统形成区域点云描述,由融合系统的检测模型得到目标边界框,利用CARLA模拟器[4 ] 仿真验证.Chen等[5 ] 基于点云数据设计车辆间协同感知模型,拓展了单车感知范围,证明了车辆间传递点云数据的可行性. ...
Vehicle-infrastructure cooperative sensing: Progress and prospect
4
2024
... 自动驾驶环境感知技术正在经历快速迭代,过往研究主要增强自动驾驶车辆自身的感知能力.单车智能感知主要依赖车辆搭载的传感器来感知周围环境,如摄相机、雷达和激光雷达等[1 ] .尽管这些传感器可以提供丰富的信息,但由于受到范围、分辨率和视野盲区等限制,仍然存在一些局限性,尤其是在如交叉口、环岛和人车混杂路段等复杂场景下,这些局限性可能会威胁到自动驾驶系统的安全性[2 ] .受限于单车智能感知的固有局限性,研究重心逐渐由单车智能感知向车路协同感知转移,多传感器、多智能体的协同感知技术的重要性日益突显.引入路端感知系统不仅增强了对道路环境的理解,还提供了冗余信息以降低漏检、误检,拓展了车辆端的感知范围与精度,从而为自动驾驶系统的安全性提供了重要支持[1 ,3 ] . ...
... [1 ,3 ]. ...
... 自动驾驶场景的协同感知需要实时采集和处理来自多端的海量传感器数据,包括但不限于图像、激光雷达点云、毫米波雷达信号等.这些数据不仅需要在车辆内部进行处理,还需要与其他车辆端和路端单元进行通信共享,以实现协同配合的区域感知.根据数据协同共享的不同时期,现有协同感知方法可分为3种协同机制[1 ] :早期数据级协同、中期特征级协同、后期目标级协同.3种协同机制都可以有效扩展单车感知的范围和视场. ...
... 早期数据协同强调原始数据的共享,可以充分互补并深度整合不同来源的原始信息,但面临数据噪声混杂、高通信带宽需求等挑战[1 ] .Arnold等[2 ] 融合不同位置的路端传感器数据,传送到融合系统形成区域点云描述,由融合系统的检测模型得到目标边界框,利用CARLA模拟器[4 ] 仿真验证.Chen等[5 ] 基于点云数据设计车辆间协同感知模型,拓展了单车感知范围,证明了车辆间传递点云数据的可行性. ...
Cooperative perception for 3D object detection in driving scenarios using infrastructure sensors
3
2022
... 自动驾驶环境感知技术正在经历快速迭代,过往研究主要增强自动驾驶车辆自身的感知能力.单车智能感知主要依赖车辆搭载的传感器来感知周围环境,如摄相机、雷达和激光雷达等[1 ] .尽管这些传感器可以提供丰富的信息,但由于受到范围、分辨率和视野盲区等限制,仍然存在一些局限性,尤其是在如交叉口、环岛和人车混杂路段等复杂场景下,这些局限性可能会威胁到自动驾驶系统的安全性[2 ] .受限于单车智能感知的固有局限性,研究重心逐渐由单车智能感知向车路协同感知转移,多传感器、多智能体的协同感知技术的重要性日益突显.引入路端感知系统不仅增强了对道路环境的理解,还提供了冗余信息以降低漏检、误检,拓展了车辆端的感知范围与精度,从而为自动驾驶系统的安全性提供了重要支持[1 ,3 ] . ...
... 早期数据协同强调原始数据的共享,可以充分互补并深度整合不同来源的原始信息,但面临数据噪声混杂、高通信带宽需求等挑战[1 ] .Arnold等[2 ] 融合不同位置的路端传感器数据,传送到融合系统形成区域点云描述,由融合系统的检测模型得到目标边界框,利用CARLA模拟器[4 ] 仿真验证.Chen等[5 ] 基于点云数据设计车辆间协同感知模型,拓展了单车感知范围,证明了车辆间传递点云数据的可行性. ...
... 综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性. ...
智能车路协同系统关键技术与应用
1
2021
... 自动驾驶环境感知技术正在经历快速迭代,过往研究主要增强自动驾驶车辆自身的感知能力.单车智能感知主要依赖车辆搭载的传感器来感知周围环境,如摄相机、雷达和激光雷达等[1 ] .尽管这些传感器可以提供丰富的信息,但由于受到范围、分辨率和视野盲区等限制,仍然存在一些局限性,尤其是在如交叉口、环岛和人车混杂路段等复杂场景下,这些局限性可能会威胁到自动驾驶系统的安全性[2 ] .受限于单车智能感知的固有局限性,研究重心逐渐由单车智能感知向车路协同感知转移,多传感器、多智能体的协同感知技术的重要性日益突显.引入路端感知系统不仅增强了对道路环境的理解,还提供了冗余信息以降低漏检、误检,拓展了车辆端的感知范围与精度,从而为自动驾驶系统的安全性提供了重要支持[1 ,3 ] . ...
Technologies and applications for intelligent vehicle-infrastructure cooperation systems
1
2021
... 自动驾驶环境感知技术正在经历快速迭代,过往研究主要增强自动驾驶车辆自身的感知能力.单车智能感知主要依赖车辆搭载的传感器来感知周围环境,如摄相机、雷达和激光雷达等[1 ] .尽管这些传感器可以提供丰富的信息,但由于受到范围、分辨率和视野盲区等限制,仍然存在一些局限性,尤其是在如交叉口、环岛和人车混杂路段等复杂场景下,这些局限性可能会威胁到自动驾驶系统的安全性[2 ] .受限于单车智能感知的固有局限性,研究重心逐渐由单车智能感知向车路协同感知转移,多传感器、多智能体的协同感知技术的重要性日益突显.引入路端感知系统不仅增强了对道路环境的理解,还提供了冗余信息以降低漏检、误检,拓展了车辆端的感知范围与精度,从而为自动驾驶系统的安全性提供了重要支持[1 ,3 ] . ...
CARLA: An open urban driving simulator
1
2017
... 早期数据协同强调原始数据的共享,可以充分互补并深度整合不同来源的原始信息,但面临数据噪声混杂、高通信带宽需求等挑战[1 ] .Arnold等[2 ] 融合不同位置的路端传感器数据,传送到融合系统形成区域点云描述,由融合系统的检测模型得到目标边界框,利用CARLA模拟器[4 ] 仿真验证.Chen等[5 ] 基于点云数据设计车辆间协同感知模型,拓展了单车感知范围,证明了车辆间传递点云数据的可行性. ...
Cooper: Cooperative perception for connected autonomous vehicles based on 3D point clouds
2
2019
... 早期数据协同强调原始数据的共享,可以充分互补并深度整合不同来源的原始信息,但面临数据噪声混杂、高通信带宽需求等挑战[1 ] .Arnold等[2 ] 融合不同位置的路端传感器数据,传送到融合系统形成区域点云描述,由融合系统的检测模型得到目标边界框,利用CARLA模拟器[4 ] 仿真验证.Chen等[5 ] 基于点云数据设计车辆间协同感知模型,拓展了单车感知范围,证明了车辆间传递点云数据的可行性. ...
... 综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性. ...
F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds
2
... 中期特征级协同强调对数据的语义特征提取与融合.已有研究提出基于点云特征的协同感知框架和协同空间特征融合方法[6 -7 ] ,前者实现数据压缩并适用于边缘计算,后者根据语义信息设定特征图权重指导特征融合,提高了检测精度和检测范围. ...
... 综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性. ...
CoFF: Cooperative spatial feature fusion for 3-D object detection on autonomous vehicles
2
2021
... 中期特征级协同强调对数据的语义特征提取与融合.已有研究提出基于点云特征的协同感知框架和协同空间特征融合方法[6 -7 ] ,前者实现数据压缩并适用于边缘计算,后者根据语义信息设定特征图权重指导特征融合,提高了检测精度和检测范围. ...
... 综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性. ...
Communication-efficient collaborative perception via spatial confidence maps
3
2022
... 综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性. ...
... 车路协同检测框架中特征通信部分参考Where2comm[8 ] 的思想.分析车路端的特征图判断某个检测区域是否存在目标,为各空间区域分配一个置信度评分,评分反映该区域存在目标物体的概率.依据感兴趣区域的评分,构建反映感知空间内区域重要性的概率分布图,即置信图[17 ] .基于区域置信图的特征共享方式,优先关注置信度高的区域,减少对背景区域的关注,节省通信带宽和计算资源,后续实验部分证明此特征共享方法的优势. ...
... 表3 进一步对比分析不同的协同感知模型[18 ⇓ ⇓ -21 ] ,不考虑额外的数据、特征和模型压缩,通信量按字节计算,以2为底的对数表示,通信量计算公式[8 ] 为 ...
When2com: Multi-agent perception via communication graph grouping
2
2020
... 综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性. ...
... 图5 和图6 分别为3D视角和BEV视角下协同感知结果.为了清晰展现车端和路端感知区域,图中分别用黄色、蓝色对车路端的点云数据进行可视化着色;绿色框表示实际目标位置,红色框表示网络检测结果.车端点云在右侧区域较为稀疏甚至消失,表明由于遮挡和距离无法有效感知远处的目标.右侧区域路端的点云稠密,车辆可与路端感知协同交互实现该区域目标的超视距感知.When2com[9 ] 可检测到大部分目标,但检测朝向存在较多偏转.V2X-ViT[20 ] 对路端的协同较差,路端区域的目标出现较多漏检.结果显示本方法的检测准确率更高,漏检率更低,大部分的目标都能被正确检测到,且检测框与标注框的匹配度更高,表明本文模型对车辆的形状、方向具备更好的检测能力. ...
Collaborative 3D object detection for automatic vehicle systems via learnable communications
1
... 综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性. ...
基于多传感器融合的协同感知方法
1
2024
... 综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性. ...
Collaborative perception method based on multisensor fusion
1
2024
... 综上,现有协同感知方法如Cooper、F-Cooper、Where2comm等[2 ,5 ⇓ ⇓ ⇓ ⇓ ⇓ -11 ] ,忽略了车路间的情况差异,没有区分网络结构对不同来源的数据进行特征提取,产生了资源浪费与部署压力,导致在协同感知的测试中车端部署存在较大难度.路端感知设备通常固定在特定位置,拥有较为稳定的计算资源,而车载处理器则需要在有限的计算能力和能源消耗下完成复杂的感知、规划和控制任务.针对此问题深入研究,根据实际场景部署的难度,探索基于双流特征提取网络的车路协同检测方法,以适应对应平台的计算能力,提高车路协同感知系统的准确性和可靠性. ...
PointPillars: Fast encoders for object detection from point clouds
1
2019
... 针对车路协同检测的场景将特征提取网络分为车端和路端两部分,二者特征提取部分的模型相互独立,设计了基于车路协同的3D目标检测框架结构,如图2 所示,其工作流程为:车端和路端的原始数据经过坐标系转换、柱状体素特征编码[12 ] 等处理转换,得到鸟瞰视图(BEV)空间下转换展平的伪图像编码信息,以便更充分地进行特征提取与特征融合.经过不同特征提取后,网络相互独立,分别输出对应的多尺度特征信息.对时空统一的特征图进行区域评分,将评分高的区域作为关键感知信息参与通信共享,用以指导补充其他交通参与者因稀疏、遮挡、感知能力受限造成的信息缺失.在评分指导下利用多头自注意力机制将信息共享的特征图进行融合,检测头输出预测结果,并可视化渲染.这些模块共同构成一个综合的目标检测系统,实现车辆与道路环境的协同感知. ...
An image is worth 16×16 words: Transformers for image recognition at scale
1
... 基于路端设备较强的计算能力以及较为丰富的感知数据,采用Transformer架构处理数据间的关联性,以获取深层的数据关系[13 ] , 见图2特征提取模块.其中,Input Embedding为输入嵌入层模块;Positional Encoding为位置信息添加模块;Multi-head Attention为多头自注意力模块;Add & Norm为包含残差连接和层归一化的网络处理模块;Feed Forward为前馈神经网络模块;Output Embedding为输出嵌入模块;Masked Multi-head Attention为带掩码的多头注意力模块;Linear为线性化模块.Transformer结构中虚线框分别对应编码器与解码器,Embedding部分将输入伪图像拆分转换为向量矩阵表示,通过Positional Encoding添加位置信息,传递至Multi-head Attention模块计算多头注意力权重,经Feed Forward模块非线性变换提取特征与Add & Norm模块加权归一化处理,以稳定训练过程;解码后由Linear进行全连接层简化处理,Softmax函数输出概率分布.Transformer核心是自注意力(Self-Attention)机制,计算公式为 ...
Swin transformer: Hierarchical vision transformer using shifted windows
1
2021
... 参考Swin-Transformer进行结构分层,利用不同尺寸窗口捕获不同范围特征,每个窗口非重叠均匀划分伪图像,有助于处理伪图像中的局部和全局信息,对于理解复杂道路环境和交通场景十分有益.为保持高效计算且引入跨窗口连接,采用了交替窗口分区方法,在连续的多层感知机(MLP)模块之间交替使用两种分区配置[14 ] .为了减少信息丢失,在不同阶段之间的下采样层采用线性层和逆残差模块进行联合构筑. ...
Run, don’t walk: Chasing higher FLOPS for faster neural networks
1
2023
... 网络使用部分卷积PConv代替传统卷积Conv2d,在输入通道的一部分上应用卷积滤波器,同时保留剩余通道不变,再与被卷积部分重新拼接到一起,从而提供更有效的空间特征提取[15 ] .参考Mamba架构对BasicBlock模块进行优化,引入VSS模块[16 ] .此模块包含两个主要分支,一个用于处理通道信息,另一个用于处理空间信息.第一个分支通过线性层和激活函数处理输入,第二个分支通过深度可分离卷积和激活函数进行处理,两个分支的输出通过元素级相加的方式合并,形成模块的最终输出.此结构使网络更有效地捕获伪图像中的复杂细节和更广泛的语义上下文. ...
Mamba: Linear-time sequence modeling with selective state spaces
1
... 网络使用部分卷积PConv代替传统卷积Conv2d,在输入通道的一部分上应用卷积滤波器,同时保留剩余通道不变,再与被卷积部分重新拼接到一起,从而提供更有效的空间特征提取[15 ] .参考Mamba架构对BasicBlock模块进行优化,引入VSS模块[16 ] .此模块包含两个主要分支,一个用于处理通道信息,另一个用于处理空间信息.第一个分支通过线性层和激活函数处理输入,第二个分支通过深度可分离卷积和激活函数进行处理,两个分支的输出通过元素级相加的方式合并,形成模块的最终输出.此结构使网络更有效地捕获伪图像中的复杂细节和更广泛的语义上下文. ...
1
... 车路协同检测框架中特征通信部分参考Where2comm[8 ] 的思想.分析车路端的特征图判断某个检测区域是否存在目标,为各空间区域分配一个置信度评分,评分反映该区域存在目标物体的概率.依据感兴趣区域的评分,构建反映感知空间内区域重要性的概率分布图,即置信图[17 ] .基于区域置信图的特征共享方式,优先关注置信度高的区域,减少对背景区域的关注,节省通信带宽和计算资源,后续实验部分证明此特征共享方法的优势. ...
DAIR-V2X: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection
3
2022
... DAIR-V2X是一个用于车-路协作3D物体检测的真实世界大规模数据集[18 ] .数据集包含车端数据和路端数据,各端包含多种传感器类型的数据,如摄相机图像和激光雷达点云.实验在DAIR-V2X车路协同数据集上进行训练和验证,选取激光雷达数据作为模型输入. ...
... 表3 进一步对比分析不同的协同感知模型[18 ⇓ ⇓ -21 ] ,不考虑额外的数据、特征和模型压缩,通信量按字节计算,以2为底的对数表示,通信量计算公式[8 ] 为 ...
... 表3 展示了不同协同感知方法在数据集中的检测效果.相较于不协同的方法[18 ] ,车路协同方法均取得了更高的检测精度,表明车路协同能够有效提高自动驾驶的全面感知能力.目标级协同方法Late Fusion的AP50为53.12%,与特征级协同方法相近,但在更高IoU阈值情况下,此类方法在车路端的目标位置、大小、航向角等检测结果的融合上存在更多误差.本文方法AP50、AP70比先前最佳方法提高了4.13百分点和4.96百分点,且在特征协同方法中参考区域置信图的通信策略,仅对所需部分区域特征传递,通信率较低. ...
1
2020
... 表3 进一步对比分析不同的协同感知模型[18 ⇓ ⇓ -21 ] ,不考虑额外的数据、特征和模型压缩,通信量按字节计算,以2为底的对数表示,通信量计算公式[8 ] 为 ...
2
2022
... 表3 进一步对比分析不同的协同感知模型[18 ⇓ ⇓ -21 ] ,不考虑额外的数据、特征和模型压缩,通信量按字节计算,以2为底的对数表示,通信量计算公式[8 ] 为 ...
... 图5 和图6 分别为3D视角和BEV视角下协同感知结果.为了清晰展现车端和路端感知区域,图中分别用黄色、蓝色对车路端的点云数据进行可视化着色;绿色框表示实际目标位置,红色框表示网络检测结果.车端点云在右侧区域较为稀疏甚至消失,表明由于遮挡和距离无法有效感知远处的目标.右侧区域路端的点云稠密,车辆可与路端感知协同交互实现该区域目标的超视距感知.When2com[9 ] 可检测到大部分目标,但检测朝向存在较多偏转.V2X-ViT[20 ] 对路端的协同较差,路端区域的目标出现较多漏检.结果显示本方法的检测准确率更高,漏检率更低,大部分的目标都能被正确检测到,且检测框与标注框的匹配度更高,表明本文模型对车辆的形状、方向具备更好的检测能力. ...
DiscoNet: Shapes learning on disconnected manifolds for 3D editing
1
2019
... 表3 进一步对比分析不同的协同感知模型[18 ⇓ ⇓ -21 ] ,不考虑额外的数据、特征和模型压缩,通信量按字节计算,以2为底的对数表示,通信量计算公式[8 ] 为 ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}