近年来,目标识别在机器人3D场景感知与导航、无人驾驶、增强现实等重要领域应用广泛.在“工业4.0”和《中国制造2025》的背景下,制造业向智能制造转型升级,物流业面临着结构调整、产业优化、降本增效等挑战,也迎来了信息技术、智能物流、市场升级等发展机遇,工厂智能化已成为不可逆转的发展趋势.无人驾驶工业车辆是智能制造系统的重要组成部分,广泛应用于仓储环境中,用于实现托盘的自动搬运.由于障碍物较多、光照不均、搬运累计误差和人工干预等因素的影响,无人驾驶工业车辆在实际托盘搬运过程中存在低效、错误搬运等问题.托盘识别属于无人驾驶工业车辆的关键技术[1 ] ,对提高货物搬运效率有重要影响,如何实现精准高效的托盘识别是目前亟待解决的问题.
目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] .
快速点特征直方图(FPFH)[21 ] 具有描述性强、特征维度低、计算速度快等特点,在识别精度和计算效率之间实现了很好的平衡[22 ] ,且FPFH作为托盘自身的几何特征,不需要添加任何标记,在复杂的仓储环境中对遮挡具有鲁棒性.Huang等[23 ] 结合CAD模型,使用FPFH特征描述符和支持向量机(SVM)分类器完成对常规工业部件的检测;王斐等[24 ] 使用FPFH特征描述符识别焊件并估计其姿态,引导机器人完成智能柔性的焊接操作;Liu等[25 ] 提出了一种结合FPFH特征和贪婪投影三角剖分的点云配准算法,提高配准精度;Li等[26 ] 将FPFH特征与最近点迭代(ICP)算法相结合,提高点云配准效率和精度.以上基于FPFH特征的研究均存在以下不足:在进行特征提取时忽略了物体的颜色信息;计算FPFH特征描述符时采用手动多次调试的方法以取得相对较好的邻域,缺乏邻域半径的选取标准.
针对以上问题,提出一种基于自适应颜色快速点特征直方图(ACFPFH)的托盘识别方法,包括点云预处理、关键点检测、特征提取、特征匹配与误匹配点对剔除等步骤.特征提取过程中,融合托盘点云的HSV颜色特征和FPFH几何特征,并在计算FPFH特征描述符时基于邻域特征熵函数最小准则自适应选择最优邻域半径,得到ACFPFH特征描述符.该方法克服了传统特征提取方法邻域选择随意、低效的问题,有效提升了托盘识别精度及速度.
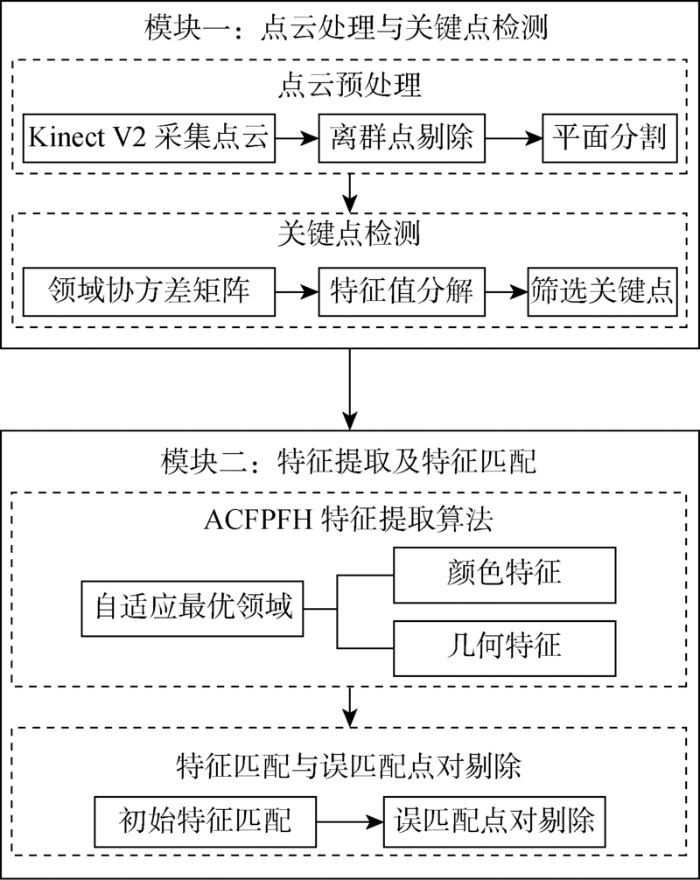
1 托盘识别方法总述
为了提高仓储环境中无人驾驶工业车辆的智能化水平,提出一种基于ACFPFH特征描述符的托盘识别方法,具体流程如图1 所示.该方法包含以下4个主要步骤.
图1
图1
目标识别算法流程图
Fig.1
Flow chart of object recognition algorithm
(1) 点云预处理.通过Kinect V2传感器采集托盘模板点云与场景点云,利用统计滤波剔除场景点云中的离群点,采用随机采样一致性(RANSAC)算法对场景点云中的地面及墙面进行分割.
(2) 关键点检测.利用内部形状签名(ISS)算法对托盘模板点云及平面分割后的场景点云提取关键点,计算点云邻域协方差矩阵及对应特征值,将特征值满足特定关系的点定义为关键点.
(3) ACFPFH特征提取.引入邻域特征熵函数,确定自适应最优邻域半径,计算托盘模板点云与场景点云关键点的ACFPFH特征描述符.
(4) 特征匹配与误匹配点对剔除.将模板点云与场景点云中的ACFPFH特征描述符进行匹配,建立模板点云与场景点云关键点之间的对应关系,得到初始匹配点对;基于RANSAC算法,剔除不满足变换关系的匹配点对,保留正确匹配点对,完成托盘识别.
2 点云处理与关键点检测
2.1 点云离群点剔除
由于Kinect V2传感器的硬件设计、外界环境干扰等因素的影响,采集到的原始点云分布不均匀,会导致托盘识别精度大大降低,所以需要剔除原始场景点云Q SO 中的离群点,如图2 所示.点云中任意点P i 到 其 邻 域 点 P i k ( k = 1 , 2 , … , m )
(1) f ( d i ) = 1 2 π σ e x p - ( d i - μ ) 2 2 σ 2
式中: d i P i μ 和σ 分别为d i P i P i k d i d i μ ±σ ,则认为点P i
图2
图2
原始场景点云及离群点剔除示意图
Fig.2
Point cloud of original scene and schematic diagram of outlier elimination
2.2 点云平面分割
在仓储环境中,Kinect V2传感器采集到的场景点云包含大量地面及墙面上的冗余信息,会降低计算效率.因此,需要进行平面分割剔除场景点云中的墙面及地面,如图3 所示.具体分割过程如下:①在点云中随机选取3点,构建初始平面模型A x + B y + C z + D = 0 ( A , B , C , D 为 常 数 ) ; Pi 到初始平面的距离(Di )以及Pi 点坐标与初始平面法向量之间的角度(β i ) ,若距离D i D ε ) 且角度β i β ε ) ,则认为点P i
图3
图3
场景点云平面分割示意图
Fig.3
Schematic diagram of plane segmentation of scene point cloud
2.3 点云关键点检测
托盘模板点云(Q M )和预处理后的场景点云(Q S )数据量大,会降低特征提取及匹配效率,因此需要提取点云关键点,即保留特征明显的点,减少点云数量.内部形状描述子(ISS)算法具有较好可重复性,效率较高,因此本文采用ISS算法进行关键点检测,具体步骤如下.
(1) 对点云Q M 、Q S 中的任意一点P i 进 行 半 径 搜 索 , 得 到 邻 域 点 P i k ( k = 1 , 2 , … , m ) , 计 算 邻 域 点 到 P i
(2) ω i k = 1 ‖ P i k L - P i L ‖
(3) C i = ∑ k = 1 m ω i k ( P i k L - P - i L ) ( P i k L - P - i L ) T ∑ k = 1 m ω i k
式中: P i L P i P i k L P i k P - i L P i P - i L = 1 m ∑ k = 1 m P i k L .
(3) 对协方差矩阵C i { λ 1 i , λ 2 i , λ 3 i }
(4) 设置阈值κ 1 和κ 2 ,将满足下式的点定义为关键点:
(4) λ 2 λ 1 < κ 1 ⋂ λ 3 λ 2 < κ 2
式中:κ 1 和κ 2 为0~1之间的常数,最后得到托盘模板点云关键点集Q MK 和场景点云关键点集Q SK .
3 ACFPFH特征提取及匹配
3.1 ACFPFH特征提取算法
3.1.1 自适应最优邻域估计
在对关键点进行特征提取之前,首先需要计算特征提取的自适应最优邻域半径(r opt ),具体步骤如下:①设置邻域搜索的半径范围[r min , r max ]以及变化间隔Δr ;②计算不同邻域半径对应的协方差矩阵Ci 及特征值λ 1 ,λ 2 ,λ 3 ;③计算不同邻域半径对应的邻域特征熵函数(E e );④基于邻域特征熵函数E e 最小准则计算得到最优邻域半径r opt .
根据特征值λ 1 , λ 2 , λ 3 , [27 ] ,如表1 所示.
构建点P i
(5) L λ = λ 1 - λ 2 λ 1 P λ = λ 2 - λ 3 λ 1 S λ = λ 3 / λ 1
式中: L λ + P λ + S λ = 1 L λ P λ S λ P i [28 ] ,即
(6) E n = - L λ l n ( L λ ) - P λ l n ( P λ ) - S λ l n ( S λ )
根据变量不确定性越小、信息熵越小的香农熵理论[29 ] ,可以得出,局部邻域信息熵值E n 越小,点Pi 维度特征的不确定性越小,即Pi 属于某种维度特征的概率越大,该邻域半径下的局部数据点的空间分布特性越相近,邻域半径越趋于最优.因此,可以根据邻域熵函数最小准则获取点云自适应最优邻域半径:
(7) r e - o p t = a r g m i n E n
式中:r e-opt 是E n 取最小值的变量值.然而,依据式(6)和式(7)得到的最优邻域半径r e-opt 是基于点云某种维度特征明显的假设,对于点Pi 属于某个特征维度的概率略大于其他两个维度的情况,此时估计出的邻域不一定最优.由表1 可知,点云数据点邻域协方差矩阵的特征值直接反映了该点邻域范围内邻域点的维度分布特性,为了避免对点云进行假设,提高最优邻域的估计精度,本文直接根据特征值构建邻域特征熵函数,即
(8) E e = - e 1 l n ( e 1 ) - e 2 l n ( e 2 ) - e 3 l n ( e 3 )
式中:e j = λ j ∑ λ j λ j E e
(9) r o p t = a r g m i n ( E e )
因此,对于不同的邻域半径,当E e 取最小值时,对应的邻域半径为最优邻域半径.
3.1.2 ACFPFH特征描述符构建
首先是颜色特征.Kinect V2传感器采集得到的点云数据包含待测目标的坐标及颜色信息.三维点云的RGB颜色空间是一种不均匀的颜色空间,两种颜色之间的知觉差异(色差)不能表示为该颜色空间中两点间的距离,因此不适用于特征相似度的检测.HSV颜色空间是一种基于感知的颜色模型,相比RGB空间,具有更强的识别能力,更符合人类的视觉特征[30 ] .本文选用HSV颜色空间来进行特征提取,其中H表示点云的色调,即所处的光谱颜色的位置,S表示点云的饱和度,V表示点云色彩的明度.提取HSV颜色空间的3个颜色分量来表示点云中每个关键点P F i
V = m a x { R , G , B } S = 0 , V = 0 m a x { R , G , B } - m i n { R , G , B } m a x { R , G , B } , 其 他 H = 0 , S = 0 60 ( G - B ) / ( S V ) , S ≠ 0 且 V = R 60 × [ 2 + ( B - R ) / ( S V ) ] , S ≠ 0 且 V = G 60 × [ 4 + ( R - G ) / ( S V ) ] , 其 他
式中:红色、绿色、蓝色分别对应的强度值R , G , B 的取值范围均为[0255];H 的取值范围为[0360];S 的取值范围为[01];V 的取值范围为[0255].
其次是几何特征.FPFH通过统计点云查询点与邻域点之间的法线关系形成直方图,从而描述点云的几何特征,计算步骤如下.
(1) 基于自适应最优邻域半径r opt ,寻找关键点P F i P q )的邻域点P q j
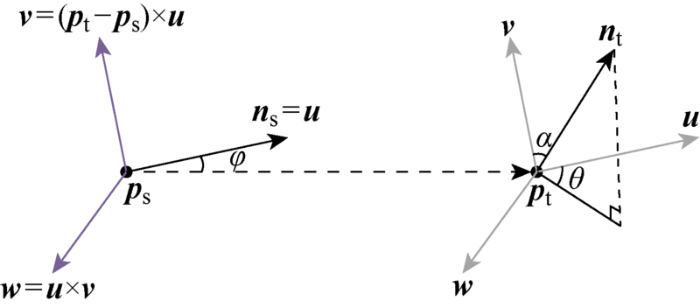
(2) 基于关键点P F i 与 任 一 邻 域 点 P q j , p s 和p t ,并建立局部坐标系uvw ,示意图如4所示,定义为
(10) u = n s v = ( p t - p s ) × u w = u × v
(3) 计算关键点P F i P q j 图4 ),得到关键点P F i
(11) α = v · n t φ = u · ( p t - p s ) / d θ = a r c t a n ( w · n t , u · n t )
图4
图4
局部坐标系uvw 示意图
Fig.4
Schematic diagram of local coordinate system
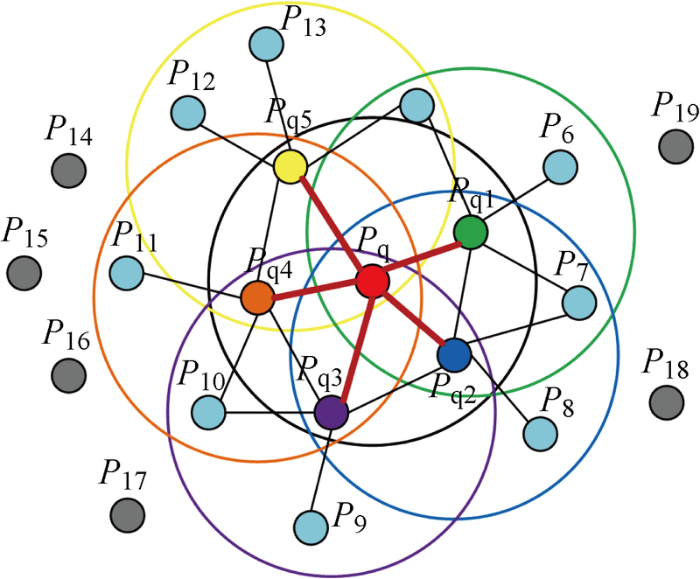
(4) 基于r opt 重新确定每个邻域点P q j 的 最 优 邻 域 , 计 算 邻 域 点 P q j V S P F H ( P q j ) P F i V F P F H ( P F i )
(12) V F P F H ( P F i ) = V S P F H ( P F i ) + 1 k ∑ i = 1 k 1 ω V S P F H ( P q j )
式中:V S P F H P F i P F i
图5
图5
FPFH邻域影响范围示意图
Fig.5
Neighborhood influence range of FPFH
(5) 将(α , φ , θ )每个维度分成11个区间,在每个维度上统计落在这11个区间上点的个数,将3个维度进行叠加,得到33维几何特征向量.
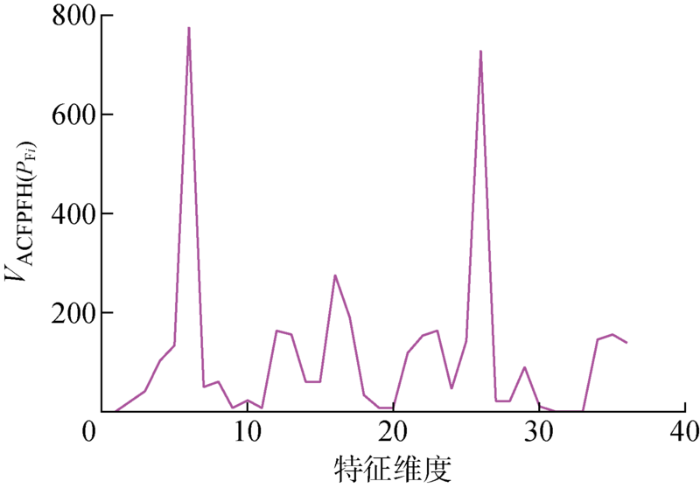
最后是ACFPFH特征描述符.将3维的HSV颜色特征与33维的FPFH几何特征如下式所示进行叠加,得到36维的ACFPFH特征描述符,具体如图6 所示.
(13) V A C F P F H ( P F i ) = V H S V ( P F i ) + V F P F H ( P F i )
式中:V A C F P F H P F i P F i V H S V ( P F i ) 为 关 键 点 P F i
图6
图6
V A C F P F H ( P F i )
Fig.6
Schematic of V A C F P F H ( P F i )
3.2 特征匹配与误匹配点对剔除
3.2.1 特征匹配
对于托盘模板点云Q M 与场景点云Q S 中关键点的ACFPFH特征描述符集合 F M ={f i M F S ={f i S f M 和f S 满足最近邻距离比的匹配规则,即
(14) ‖ f S - f M ‖ ‖ f S - f M ' < d t h
式中:f S 为F S 中的任意特征描述符;f M 和f 'M 为F M 中与f S 最近及次近的特征描述符;d th 为最近与次近距离比的阈值,是0~1之间的常数.则其对应的点对属于匹配点对集合E ={Q MP , Q SP },其中,Q MP 与Q SP 分别为托盘模板点云及场景点云中对应的特征匹配点.基于最近邻距离比的特征匹配,F M 中的一个特征描述符在F S 中最多只有一个与之对应的特征描述符.
3.2.2 误匹配点对剔除
由于匹配点对中存在错误匹配点对,会造成识别错误,所以利用RANSAC算法剔除误匹配点对,具体过程如下:从匹配点对集合E 中随机选取3对对应的关键点点对,求解托盘模板点云及场景点云中对应的特征匹配点Q MP 与Q SP 的旋转矩阵(R )和平移矩阵(T );计算特征匹配点对之间的欧氏距离,即
(15) D ( R , T ) = ‖ L Q S P - ( R × L Q M P + T ) ‖
式中: L QSP 与L QMP 分别为Q SP 与Q MP 的三维坐标向量.
设定阈值ε , 如 果 D ( R , T ) < ε , 图7 所示.
图7
图7
特征匹配与误匹配点对剔除
Fig.7
Feature matching and elimination of mismatching point pairs
4 案例分析
4.1 实验过程
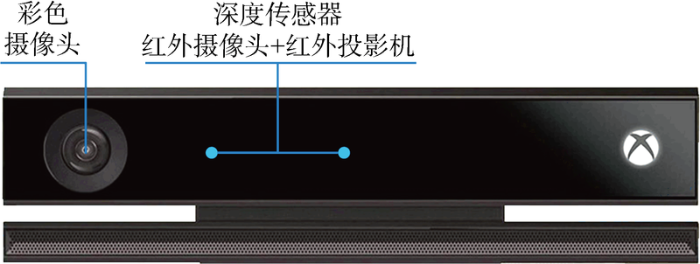
为验证基于ACFPFH的托盘识别方法的有效性,采用基于飞行时间(TOF)原理的Kinect V2传感器采集点云数据进行结果对比分析.Kinect V2是一款可同时获得彩色图像和深度图像的3D传感器,彩色图像分辨率为 1 920 像素×1 080 像素,深度图像分辨率为512像素×424像素.Kinect V2共有3个摄像头,从左至右依次为RGB彩色摄像头、红外摄像头和红外投影机,其中红外摄像头和红外投影机共同构成深度传感器,深度传感器采用飞行时间差原理进行测距.Kinect V2结构示意图如图8 所示,其水平视场为70°,垂直视场为60°,有效测距范围为0.5~4.5 m.
图8
图8
Kinect V2结构示意图
Fig.8
Schematic diagram of structure of Kinect V2
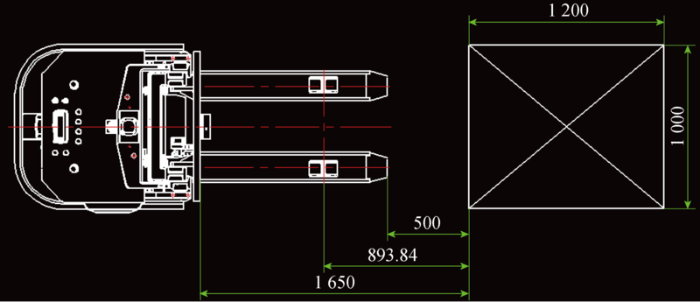
将Kinect V2传感器安装在叉车货叉架的顶部(见图9 ),传感器随着货叉一起上下移动,为了能拍摄到地面或货架上的托盘,将Kinect V2传感器的摄像头向下微微倾斜10°.叉车的货叉长度一般为 1 150 mm,根据工厂实际操作情况,将货叉顶端与托盘前端面的距离设置为500 mm以便叉车进行位置调整,保证货叉与托盘前端面垂直且传感器中心与托盘中心在一条线上,托盘具体放置情况如图10 所示.白天正常环境光照射条件下,将托盘放置在空旷的平整地面上,在PC端采集点云数据,采用平面分割算法分割并剔除地面及墙面点云,将剩余点云作为托盘模板点云.在托盘上放置纸箱,Kinect V2传感器保持同样的距离采集包含托盘的场景点云数据.
图9
图9
Kinect V2传感器安装位置示意图
Fig.9
Diagram of Kinect V2 sensor installation position
图10
图10
点云数据采集距离示意图(mm)
Fig.10
Schematic diagram of acquisition of point cloud data distance (mm)
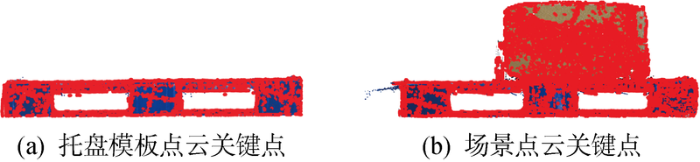
采用Kinect V2传感器获取场景的彩色图像,如图11 所示,采集到地托盘模板点云与场景点云如图12 所示,托盘为蓝色川字塑料托盘,尺寸为 1 200 mm×1 000 mm×150 mm.对场景点云进行预处理,根据先验知识可得场景点云地面法向量为[0 1 0],墙面法向量为[0 0 1],设置距离阈值Dε =0.02 m,角度阈值βε =5°,对预处理后的场景点云进行平面分割,结果如图13 所示.对托盘模板点云以及平面分割后的场景点云进行半径为 0.008 5 m 的半径搜索,考虑到识别精度与效率的平衡,将关键点数控制在 10 000 左右,设置ISS阈值κ 1 =0. 7,κ 2 =0. 5,完成关键点检测,托盘模板点云点的数量从 14 554 减少至 7 479,场景点云点的数量从 17 948 减少至 9 665,结果如图14 所示.其中,红色点为关键点.
图11
图11
原始场景的彩色图像
Fig.11
Color image of original scene
图12
图12
托盘模板点云及原始场景点云
Fig.12
Pallet template point cloud and original scene point cloud
图13
图13
场景点云预处理
Fig.13
Preprocessing of scene point cloud
图14
图14
托盘模板点云及场景点云关键点
Fig.14
Key points of pallet template point cloud and original scene point cloud
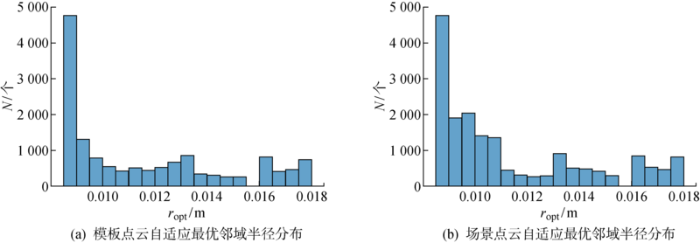
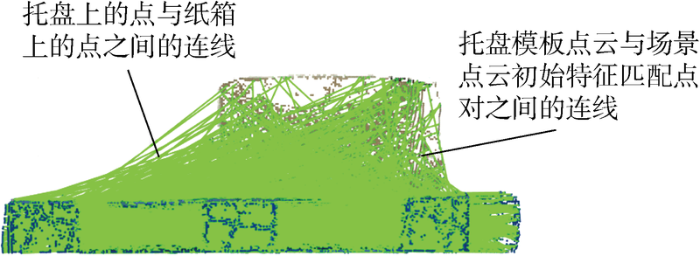
为了计算关键点的ACFPFH特征值,首先需要求解点云中每个点的自适应邻域半径,Kinect V2传感器采集到的点云数据两个采样点之间的间隔为7 mm,因此设置半径范围r min =0.008 5 m, r max =0.018 m, Δr =0.000 5 m,基于邻域特征熵函数最小准则,得到每个点的自适应最优邻域半径.托盘模板点云与场景点云自适应最优邻域半径分布情况如图15 所示.图中:N 为r opt 取不同值时对应的点数.由图可见,点的最优邻域半径集中于给定的最小邻域半径,有利于提高托盘识别效率.提取托盘模板点云与场景点云关键点的HSV颜色分量,基于自适应最优邻域半径计算几何特征,二者叠加得到关键点的ACFPFH特征值.设置最近邻距离比率阈值d th =0.75,完成托盘模板点云与场景点云的特征匹配,得到初始匹配点对,匹配结果如图16 所示,托盘模板点云与场景点云中的对应点对用绿色线段相连,托盘上的点与纸箱上的点之间的连线代表错误匹配点对,利用RANSAC算法进行误匹配点对剔除,设置迭代次数为 1 000 次.将场景点云中的正确匹配点作为托盘识别结果,如图17 所示,红色点为场景点云的正确匹配点,代表从场景点云中识别出的托盘.
图15
图15
点云r opt 分布情况
Fig.15
Distribution of r opt of point cloud
图16
图16
特征匹配结果
Fig.16
Result of feature matching
图17
图17
场景点云中的托盘识别结果
Fig.17
Pallet recognition result in scene point cloud
4.2 实验结果分析
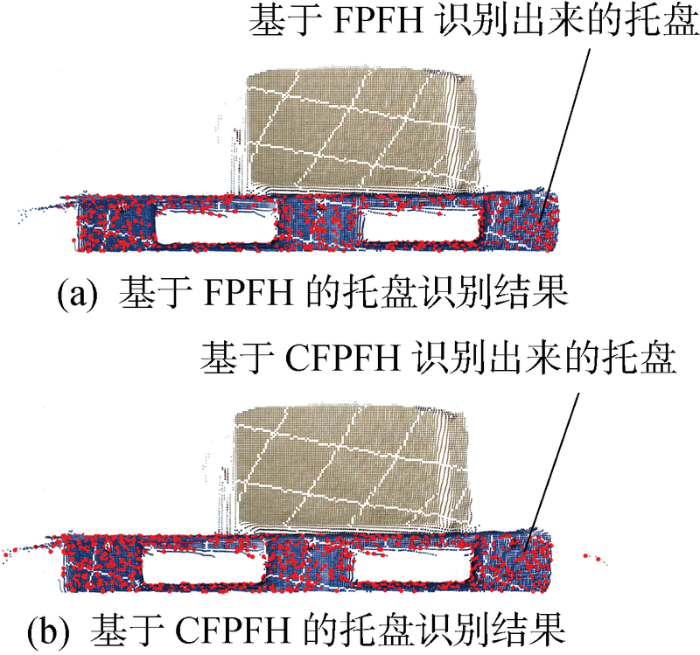
图18 为固定半径的FPFH、CFPFH的托盘识别结果(红色点),结合图17 及表2 可以看出,基于ACFPFH的托盘识别得到的正确匹配点数量更多,正确匹配点之间的平均距离间隔更小,点云分布更稠密,且正确匹配点对数量达到初始匹配点对数量的10%以上,能正确表示完整托盘[31 ] .表中:r 为邻域半径.匹配点间的平均距离间隔可近似理解为所有k 个邻域点间的平均距离的平均值,以k =5为例.
图18
图18
不同特征描述符在场景点云中的托盘识别结果
Fig.18
Pallet recognition results of different feature descriptors in scene point cloud
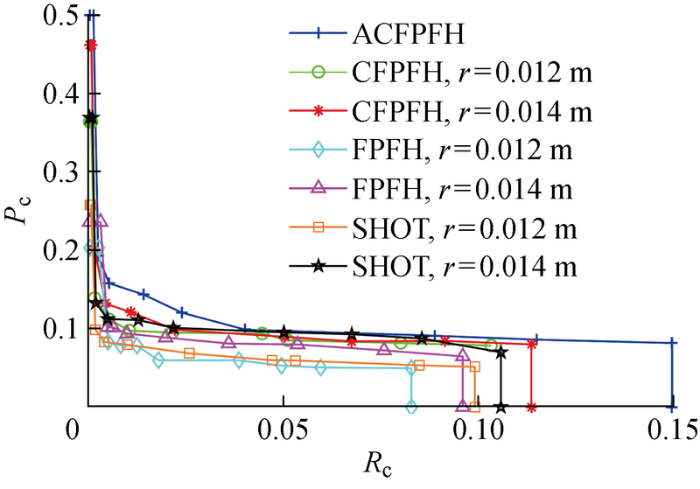
针对本文提出的ACFPFH特征描述符,采用召回率精度曲线及特征提取时间验证其性能优劣,召回率(R c )及精度(P c )定义为
(16) P c = Q C M / Q P F R c = Q C M / Q S M P
式中: Q CM 为正确匹配点对数量,即误匹配点对剔除后得到的匹配点对数量;Q PF 为模板点云关键点数量;Q SMP 为特征匹配之后得到的初始特征匹配点对数量.通过改变特征匹配阶段的阈值d th 可获得多个召回率及对应的精度,从而得到特征描述子的PR曲线.方向直方图签名(SHOT)特征描述符是目前最常用且性能较优的特征描述符[32 ] .因此,将ACFPFH特征描述符与固定半径的FPFH、CFPFH以及SHOT特征描述符做对比,选取的特征匹配阶段的阈值集合为d th ={0.2, 0.4, 0.6, 0.75, 0.85, 0.925, 0.95, 0.975, 1.0},得到不同特征描述符对应的托盘识别P -R 曲线,如图19 所示.取d th =0.75对不同特征描述符的精度进行比较,如表3 所示.表中:P FD 为其他特征描述符的精度.进一步分析场景点云的特征提取所需时间,比较特征描述符的性能,如表4 所示.表中:t FD 为其他特征描述符所用的运行时间.
图19
图19
不同特征描述符的P -R 曲线
Fig.19
Curves of P -R of different feature descriptors
传统的SHOT、FPFH等特征描述符只描述了托盘的几何特征,忽略了托盘的颜色信息,因此托盘的识别精度较低;CFPFH特征描述符计算了托盘的HSV颜色特征,提高了托盘的识别精度,但其邻域半径要依靠复杂低效的人工调试方法获得,且获得的邻域半径并不适用于所有的点云关键点,较大的邻域半径导致关键点的邻域点过多,降低特征提取速度.ACFPFH特征描述符不仅增加了颜色信息,且根据邻域特征熵方法为每个关键点自适应选择最优邻域半径,使得点云关键点的特征描述符在具有较高识别精度的同时,特征提取用时也减少了.
在P -R 曲线图中,曲线越靠近右上方,特征描述符的性能越好.由图19 可见,与固定半径的SHOT、FPFH、CFPFH特征描述符相比,ACFPFH特征描述符具有最优性能.ACFPFH特征描述符在特征提取时自适应确定最优邻域半径,由表3 和表4 可知,d th =0.75时,与邻域半径为0.012 m的SHOT特征描述符相比,托盘识别精度提高了44.67%,特征提取用时减少了28.26%;与邻域半径为0.012 m的FPFH特征描述符相比,托盘识别精度提高了83.74%,特征提取用时减少了35.55%;与邻域半径为0.012 m的CFPFH特征描述符相比,托盘识别精度提高了47.17%,特征提取用时减少了43.49%.由于Kinect V2传感器成本较低,所以其在仓储环境中的应用较为广泛,但Kinect V2传感器采集的点云密度不高,故本文基于SHOT、FPFH、CFPFH、ACFPFH特征描述符得到的托盘识别精度普遍在0.05-0.5范围内,考虑到托盘体积大、叉取灵活,基于ACFPFH特征描述符的托盘识别方法得到的精度符合仓储环境中对托盘的识别要求.
与传统的通过手动多次调试以取得相对较好邻域半径的特征提取方法相比,本文提出的ACFPFH方法能够根据点云分布情况自适应地选择邻域范围的大小,克服了邻域选择随意、低效的问题,有效提升了特征描述符的性能,加快了运算速度,并能够运用到托盘识别当中,对实际的仓储作业具有指导作用.
5 结语
为了提高仓储环境中托盘识别算法的精度与计算经济性,本文提出了一种基于ACFPFH特征描述符的托盘识别方法,包括点云预处理、关键点检测、ACFPFH特征提取、特征匹配及误匹配点对剔除等步骤.该方法克服了现有托盘识别方法低效耗时、鲁棒性差、特征提取时邻域半径选择随意的缺点,通过与固定半径的SHOT、FPFH、CFPFH特征描述符作对比,验证了ACFPFH特征描述符的优越性.进一步获取识别到的托盘的位姿信息,将其反馈给无人驾驶工业车辆的运动系统,可以实现托盘的自动高效叉取,有助于构建智能化工厂.未来将探索在不同光照、包含货架及多种托盘的场景中提高托盘识别算法的精度及速度的方法.
参考文献
View Option
[2]
王伟男 , 杨朝红 . 基于图像处理技术的目标识别方法综述
[J]. 电脑与信息技术 2019 , 27 (6 ): 9 -15 .
[本文引用: 1]
WANG Weinan YANG Chaohong . A survey of target recognition methods based on image processing technology
[J]. Computer and Information Technology 2019 , 27 (6 ): 9 -15 .
[本文引用: 1]
[3]
郝雯 , 王映辉 , 宁小娟 , 等 . 面向点云的三维物体识别方法综述
[J]. 计算机科学 2017 , 44 (9 ): 11 -16 .
DOI:10.11896/j.issn.1002-137X.2017.09.002
[本文引用: 1]
随着三维扫描技术的快速发展,获取各类场景的点云数据已经非常简单快捷;加之点云数据具备不受光照、阴影、纹理的影响等优势,基于点云的三维物体识别已成为计算机视觉领域的研究热点。首先,对近年来面向点云数据的三维物体识别方法进行归纳和总结;然后,对已有方法的优势及缺点进行分析;最后,指出点云物体识别中所面临的挑战及进一步的研究方向。
HAO Wen WANG Yinghui NING Xiaojuan , et al Survey of 3D object recognition for point clouds
[J]. Computer Science 2017 , 44 (9 ): 11 -16 .
DOI:10.11896/j.issn.1002-137X.2017.09.002
[本文引用: 1]
With the rapid development of 3D scanning technology,it is convenient to obtain point clouds of different scenes.Since point clouds are not influenced by light,shadows and textures,recognizing 3D object from scene point clouds has become a research hotspot of computer vision.This paper first summarized the 3D object recognition methods from point clouds in recent years.Then the advantages and disadvantages of the existing methods were discussed.Finally,the challenges and further research directions of object recognition were pointed out.
[4]
GARCÍA-PULIDO J A PAJARES G DORMIDO S , et al Recognition of a landing platform for unmanned aerial vehicles by using computer vision-based techniques
[J]. Expert Systems With Applications 2017 , 76 : 152 -165 .
DOI:10.1016/j.eswa.2017.01.017
URL
[本文引用: 1]
[5]
CHEN J M CHEN L P . Multi-dimensional color image recognition and mining based on feature mining algorithm
[J]. Automatic Control and Computer Sciences 2021 , 55 (2 ): 195 -201 .
DOI:10.3103/S0146411621020048
[本文引用: 1]
[6]
SEIDENARI L SERRA G BAGDANOV A D , et al Local pyramidal descriptors for image recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence 2014 , 36 (5 ): 1033 -1040 .
DOI:10.1109/TPAMI.2013.232
PMID:26353235
[本文引用: 1]
In this paper, we present a novel method to improve the flexibility of descriptor matching for image recognition by using local multiresolution pyramids in feature space. We propose that image patches be represented at multiple levels of descriptor detail and that these levels be defined in terms of local spatial pooling resolution. Preserving multiple levels of detail in local descriptors is a way of hedging one's bets on which levels will most relevant for matching during learning and recognition. We introduce the Pyramid SIFT (P-SIFT) descriptor and show that its use in four state-of-the-art image recognition pipelines improves accuracy and yields state-of-the-art results. Our technique is applicable independently of spatial pyramid matching and we show that spatial pyramids can be combined with local pyramids to obtain further improvement. We achieve state-of-the-art results on Caltech-101 (80.1%) and Caltech-256 (52.6%) when compared to other approaches based on SIFT features over intensity images. Our technique is efficient and is extremely easy to integrate into image recognition pipelines.
[7]
CHEN G PENG R WANG Z C , et al Pallet recognition and localization method for vision guided forklift
[C]// 2012 8th International Conference on Wireless Communications , Networking and Mobile Computing Shanghai, China : IEEE , 2012 : 1 -4 .
[本文引用: 1]
[8]
SYU J L LI H T CHIANG J S , et al A computer vision assisted system for autonomous forklift vehicles in real factory environment
[J]. Multimedia Tools and Applications 2017 , 76 (18 ): 18387 -18407 .
DOI:10.1007/s11042-016-4123-6
URL
[本文引用: 1]
[9]
LI T J HUANG B LI C , et al Application of convolution neural network object detection algorithm in logistics warehouse
[J]. The Journal of Engineering 2019 , 2019 (23 ): 9053 -9058 .
DOI:10.1049/tje2.v2019.23
URL
[本文引用: 1]
[10]
SHAO Y P WANG K DU S C , et al High definition metrology enabled three dimensional discontinuous surface filtering by extended tetrolet transform
[J]. Journal of Manufacturing Systems 2018 , 49 : 75 -92 .
DOI:10.1016/j.jmsy.2018.09.002
URL
[本文引用: 1]
[11]
SHAO Y P DU S C TANG H T . An extended bi-dimensional empirical wavelet transform based filtering approach for engineering surface separation using high definition metrology
[J]. Measurement 2021 , 178 : 109259.
[本文引用: 1]
[12]
武文汉 , 杨明 , 王冰 , 等 . 一种基于轮廓匹配的仓储机器人托盘检测方法
[J]. 上海交通大学学报 2019 , 53 (2 ): 197 -202 .
[本文引用: 1]
WU Wenhan YANG Ming WANG Bing , et al Pallet detection based on contour matching for warehouse robots
[J]. Journal of Shanghai Jiao Tong University 2019 , 53 (2 ): 197 -202 .
[本文引用: 1]
[13]
XIAO J H LU H M ZHANG L L , et al Pallet recognition and localization using an RGB-D camera
[J]. International Journal of Advanced Robotic Systems 2017 , 14 (6 ): 172988141773779.
[本文引用: 1]
[14]
VARGA R COSTEA A NEDEVSCHI S . Improved autonomous load handling with stereo cameras
[C]// 2015 IEEE International Conference on Intelligent Computer Communication and Processing Cluj-Napoca, Romania : IEEE , 2015 : 251 -256 .
[本文引用: 1]
[15]
VARGA R NEDEVSCHI S . Robust pallet detection for automated logistics operations
[C]// Proceedings of the 11th Joint Conference on Computer Vision , Imaging and Computer Graphics Theory and Applications Rome, Italy : SCITEPRESS-Science and Technology Publications , 2016 : 470 -477 .
[本文引用: 1]
[16]
吴登禄 , 曹文希 , 朱颖 . 基于三维点云和图像边缘的托盘检测技术研究
[J]. 自动化与信息工程 2019 , 40 (3 ): 40 -42 .
[本文引用: 1]
WU Denglu CAO Wenxi ZHU Ying . Research on pallet detection technology based on 3D point cloud and image edge features
[J]. Automation & Information Engineering 2019 , 40 (3 ): 40 -42 .
[本文引用: 1]
[17]
李洋洋 , 史历程 , 万卫兵 , 等 . 基于卷积神经网络的三维物体检测方法
[J]. 上海交通大学学报 2018 , 52 (1 ): 7 -12 .
[本文引用: 1]
LI Yangyang SHI Licheng WAN Weibing , et al A convolutional neural network-based method for 3D object detection
[J]. Journal of Shanghai Jiao Tong University 2018 , 52 (1 ): 7 -12 .
[本文引用: 1]
[18]
TERABAYASHI K TAKASHIMA I SUZUKI Y , et al Easy acquisition of range image dataset for object detection using retroreflective markers and a time-of-flight camera: An application to detection of forklift pallets
[C]// Proceedings of the Seventh Asia International Symposium on Mechatronics Hangzhou, China : Springer Singapore , 2020 : 1001 -1005 .
[本文引用: 1]
[19]
郭裕兰 , 鲁敏 , 谭志国 , 等 . 距离图像局部特征提取方法综述
[J]. 模式识别与人工智能 2012 , 25 (5 ): 783 -791 .
[本文引用: 1]
基于距离图像的三维目标识别是计算机视觉领域的研究热点,而局部特征提取则是实现遮挡和复杂场景下三维目标识别的关键。文中首先介绍距离图像及其表示形式,详细分析法向量、曲率和形状索引等微分几何属性。进而将局部特征检测方法分类为固定尺度和自适应尺度方法,将局部特征描述方法分类为基于深度信息、基于点云空间分布和基于几何属性分布的方法,并对各种具体算法进行阐述、分析和定性评价。最后对现有方法进行归纳总结,并指出所面临的挑战及进一步研究的方向。
GUO Yulan LU Min TAN Zhiguo , et al Survey of local feature extraction on range images
[J]. Pattern Recognition and Artificial Intelligence 2012 , 25 (5 ): 783 -791 .
[本文引用: 1]
Three dimensional (3D) object recognition is a hot research topic in computer vision. Local feature extraction is a key stage for 3D object recognition with the presence of occlusion and clutter. Firstly, range images and their representations are described. The differential geometric attributes are introduced, including the surface normal, the curvature and the shape index. Then, the local feature detection methods are classified into fixed scale method and adaptive scale method. And the local feature description methods are classified into depth value based, point spatial distribution based and geometric attributes distribution based methods. These methods with their merits and demerits are described. Finally, the existing methods are summarized and several challenges and future research directions are pointed out.
[20]
PRAKHYA S M LIN J CHANDRASEKHAR V , et al 3DHoPD: A fast low-dimensional 3-D descriptor
[J]. IEEE Robotics and Automation Letters 2017 , 2 (3 ): 1472 -1479 .
DOI:10.1109/LRA.2017.2667721
URL
[本文引用: 1]
[21]
RUSU R B BLODOW N BEETZ M . Fast point feature histograms (FPFH) for 3D registration
[C]// 2009 IEEE International Conference on Robotics and Automation Kobe, Japan : IEEE , 2009 : 3212 -3217 .
[本文引用: 1]
[22]
GUO Y L BENNAMOUN M SOHEL F , et al A comprehensive performance evaluation of 3D local feature descriptors
[J]. International Journal of Computer Vision 2016 , 116 (1 ): 66 -89 .
DOI:10.1007/s11263-015-0824-y
URL
[本文引用: 1]
[23]
HUANG J YOU S Y . Detecting objects in scene point cloud: A combinational approach
[C]// 2013 International Conference on 3D Vision-3DV 2013 Seattle, WA, USA : IEEE , 2013 : 175 -182 .
[本文引用: 1]
[24]
王斐 , 梁宸 , 韩晓光 , 等 . 基于焊件识别与位姿估计的焊接机器人视觉引导
[J]. 控制与决策 2020 , 35 (8 ): 1873 -1878 .
[本文引用: 1]
WANG Fei LIANG Chen HAN Xiaoguang , et al Visual guidance of welding robot based on weldment recognition and pose estimation
[J]. Control and Decision 2020 , 35 (8 ): 1873 -1878 .
[本文引用: 1]
[25]
LIU J BAI D CHEN L . 3-D point cloud registration algorithm based on greedy projection triangulation
[J]. Applied Sciences 2018 , 8 (10 ): 1776 .
DOI:10.3390/app8101776
URL
[本文引用: 1]
To address the registration problem in current machine vision, a new three-dimensional (3-D) point cloud registration algorithm that combines fast point feature histograms (FPFH) and greedy projection triangulation is proposed. First, the feature information is comprehensively described using FPFH feature description and the local correlation of the feature information is established using greedy projection triangulation. Thereafter, the sample consensus initial alignment method is applied for initial transformation to implement initial registration. By adjusting the initial attitude between the two cloud points, the improved initial registration values can be obtained. Finally, the iterative closest point method is used to obtain a precise conversion relationship; thus, accurate registration is completed. Specific registration experiments on simple target objects and complex target objects have been performed. The registration speed increased by 1.1% and the registration accuracy increased by 27.3% to 50% in the experiment on target object. The experimental results show that the accuracy and speed of registration have been improved and the efficient registration of the target object has successfully been performed using the greedy projection triangulation, which significantly improves the efficiency of matching feature points in machine vision.
[26]
LI P WANG J ZHAO Y D , et al Improved algorithm for point cloud registration based on fast point feature histograms
[J]. Journal of Applied Remote Sensing 2016 , 10 : 045024.
[本文引用: 1]
[27]
NAPOLI A GLASS S WARD C , et al Performance analysis of a generalized motion capture system using microsoft kinect 2.0
[J]. Biomedical Signal Processing and Control 2017 , 38 : 265 -280 .
DOI:10.1016/j.bspc.2017.06.006
URL
[本文引用: 1]
[28]
DEMANTKE J MALLET C DAVID N , et al Dimensionality based scale selection in 3D LIDAR point clouds
[C]// ISPRS Workshop Laser Scanning Calgary, Canada : Copernicus Gesellschaft Mbh , 2011 : 97 -102 .
[本文引用: 1]
[29]
WEINMANN M JUTZI B MALLET C . Semantic 3D scene interpretation: A framework combining optimal neighborhood size selection with relevant features
[J]. Photogrammetry , Remote Sensing and Spatial Information Sciences 2014 , 2 (3 ): 181 -188 .
[本文引用: 1]
[30]
王红雨 , 尹午荣 , 汪梁 , 等 . 基于HSV颜色空间的快速边缘提取算法
[J]. 上海交通大学学报 2019 , 53 (7 ): 765 -772 .
[本文引用: 1]
WANG Hongyu YIN Wurong WANG Liang , et al Fast edge extraction algorithm based on HSV color space
[J]. Journal of Shanghai Jiao Tong University 2019 , 53 (7 ): 765 -772
[本文引用: 1]
[31]
熊风光 , 蔡晋茹 , 况立群 , 等 . 三维点云模型中特征点描述子及其匹配算法研究
[J]. 小型微型计算机系统 2017 , 38 (3 ): 640 -644 .
[本文引用: 1]
XIONG Fengguang CAI Jinru KUANG Liqun , et al Study on descriptor and matching algorithm of feature point in 3D point cloud
[J]. Journal of Chinese Computer Systems 2017 , 38 (3 ): 640 -644 .
[本文引用: 1]
[32]
唐敏杰 , 赵欢 , 丁汉 . 二进制点云局部特征描述子研究
[J]. 机械工程学报 2021 , 57 (2 ): 219 -229 .
DOI:10.3901/JME.2021.02.219
[本文引用: 1]
基于点云局部特征描述的三维目标识别是机器人视觉领域一个具有重要研究价值且富有挑战性的研究方向。尽管目前已有大量三维特征描述子的相关研究工作,但它们大多数采用浮点数,对计算和存储的开销很大,并且鉴别力较弱,鲁棒性不强。鉴于此,从点对特征出发,提出一种鉴别力高,鲁棒性强,结构紧凑,计算迅速的高性能点云局部描述算法—二进制点对特征直方图(Binarized histogram of point pair features,B-HPPF)。对模型进行降采样,根据点位置与点法线信息,计算局部邻域中点对的七个特征;利用其将局部点对集划分为若干区域,并对每一区域进行信息提取;通过轮换比较各信息量的大小将特征进行二进制编码;将每一区域的二进制子特征串联组合生成最终的二进制描述子B-HPPF。所提出的B-HPPF描述子在多个公开数据集上进行测试,并与经典的描述算法进行对比,结果表明,所提出的方法在鉴别力、鲁棒性、紧凑性和计算效率等方面获得了优越的综合性能。此外,B-HPPF的实用性也在目标识别数据集上得以进一步验证。
TANG Minjie ZHAO Huan DING Han . Research on binarized local feature descriptors of point clouds
[J]. Journal of Mechanical Engineering 2021 , 57 (2 ): 219 -229 .
DOI:10.3901/JME.2021.02.219
[本文引用: 1]
3D object recognition based on local feature description of point cloud is a challenging problem in the robotic. Although a large number of three-dimensional feature descriptors have been proposed, most of them use floating-point numbers, which are expensive for calculation and storage. In view of this, a high-performance three-dimensional local descriptor is proposed called binarized histogram of point-pair feature(B-HPPF). After downsampling the model, based on the point position and point normal information, extract seven features of each point pair in the local neighborhood; use these features to divide the local point pair set into several regions and information is ex-tracted. The features are binary-coded by comparing the size of the corresponding information. The binary sub-features of each region are combined in series to generate a final binary B-HPPF description. The B-HPPF descriptors are tested on a number of public datasets and compared with classical description algorithms. The results show that it is optimally balanced in terms of discriminative power, robustness, compactness and computational effi-ciency. Moerover, B-HPPF is applied to the target identification data set to verify its practicability.
Pose estimation and object tracking using 2D images
1
2017
... 近年来,目标识别在机器人3D场景感知与导航、无人驾驶、增强现实等重要领域应用广泛.在“工业4.0”和《中国制造2025》的背景下,制造业向智能制造转型升级,物流业面临着结构调整、产业优化、降本增效等挑战,也迎来了信息技术、智能物流、市场升级等发展机遇,工厂智能化已成为不可逆转的发展趋势.无人驾驶工业车辆是智能制造系统的重要组成部分,广泛应用于仓储环境中,用于实现托盘的自动搬运.由于障碍物较多、光照不均、搬运累计误差和人工干预等因素的影响,无人驾驶工业车辆在实际托盘搬运过程中存在低效、错误搬运等问题.托盘识别属于无人驾驶工业车辆的关键技术[1 ] ,对提高货物搬运效率有重要影响,如何实现精准高效的托盘识别是目前亟待解决的问题. ...
基于图像处理技术的目标识别方法综述
1
2019
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
基于图像处理技术的目标识别方法综述
1
2019
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
面向点云的三维物体识别方法综述
1
2017
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
面向点云的三维物体识别方法综述
1
2017
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Recognition of a landing platform for unmanned aerial vehicles by using computer vision-based techniques
1
2017
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Multi-dimensional color image recognition and mining based on feature mining algorithm
1
2021
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Local pyramidal descriptors for image recognition
1
2014
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Pallet recognition and localization method for vision guided forklift
1
2012
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
A computer vision assisted system for autonomous forklift vehicles in real factory environment
1
2017
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Application of convolution neural network object detection algorithm in logistics warehouse
1
2019
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
High definition metrology enabled three dimensional discontinuous surface filtering by extended tetrolet transform
1
2018
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
An extended bi-dimensional empirical wavelet transform based filtering approach for engineering surface separation using high definition metrology
1
2021
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
一种基于轮廓匹配的仓储机器人托盘检测方法
1
2019
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
一种基于轮廓匹配的仓储机器人托盘检测方法
1
2019
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Pallet recognition and localization using an RGB-D camera
1
2017
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Improved autonomous load handling with stereo cameras
1
2015
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Robust pallet detection for automated logistics operations
1
2016
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
基于三维点云和图像边缘的托盘检测技术研究
1
2019
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
基于三维点云和图像边缘的托盘检测技术研究
1
2019
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
基于卷积神经网络的三维物体检测方法
1
2018
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
基于卷积神经网络的三维物体检测方法
1
2018
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Easy acquisition of range image dataset for object detection using retroreflective markers and a time-of-flight camera: An application to detection of forklift pallets
1
2020
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
距离图像局部特征提取方法综述
1
2012
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
距离图像局部特征提取方法综述
1
2012
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
3DHoPD: A fast low-dimensional 3-D descriptor
1
2017
... 目标识别的方法主要包括基于图像[2 ] 和基于点云[3 ] 两种.基于图像的物体识别已经有很多研究成果[4 ⇓ -6 ] ,具体到托盘识别,Chen等[7 ] 将颜色空间YUV和HSV中的V分量作为阈值从图像中区分背景和托盘;Syu等[8 ] 使用叉车上的单目视觉系统,利用自适应结构特征和方向加权重叠比进行托盘检测;Li等[9 ] 对采集到的图像进行手动标记,采用改进的单次多盒探测器的目标检测算法提高了托盘检测的效率和精度.以上基于二维图像的托盘识别理论研究已经十分成熟,但是二维图像的成像过程是从三维空间映射到二维空间,这个过程会丢失大量信息,基于二维图像的目标识别已无法满足人类对于高度自动化的要求.随着测量技术与深度传感器的发展,物体检测已从传统的单点和片段测量迈向高稠密点云和全轮廓测量[10 -11 ] ,三维点云数据的每个测量点真实记录了物体的几何和空间属性,因此基于点云的目标识别方法逐渐成为当前的研究热点.文献[12 -13 ]利用托盘点云轮廓特征进行目标与模板的匹配,实现托盘检测;Varga等[14 -15 ] 在采用托盘边缘特征和滑动窗口检测托盘的基础上,引入灰度图像特征描述符提高托盘检测精度,但不适用于遮挡或者复杂场景问题.吴登禄等[16 ] 提出了一种结合图像局部纹理和3D点云曲率信息的点云匹配技术实现托盘识别与定位,但随着托盘与叉车距离增大,识别精度会大大降低.李洋洋等[17 ] 将物体点云转化为深度图像,利用卷积网络提取特征,提高图像识别率,但该方法需要大量的数据样本进行训练,训练时间较长.Terabayashi等[18 ] 使用一种基于深度图像数据集的目标检测方法,通过在托盘上放置反光标记,实现对托盘边界框的定位,这种方法要求对所有托盘都添加反光标记,耗费大量时间和人力成本.郭裕兰等[19 ] 归纳总结了现有的局部特征检测方法,提出特征描述性与计算效率的矛盾是目前特征提取工作面临的较大挑战.因此,利用托盘自身特征构建一个具有强鲁棒性和强描述性的特征描述符是有效处理三维点云数据的重要保证[20 ] . ...
Fast point feature histograms (FPFH) for 3D registration
1
2009
... 快速点特征直方图(FPFH)[21 ] 具有描述性强、特征维度低、计算速度快等特点,在识别精度和计算效率之间实现了很好的平衡[22 ] ,且FPFH作为托盘自身的几何特征,不需要添加任何标记,在复杂的仓储环境中对遮挡具有鲁棒性.Huang等[23 ] 结合CAD模型,使用FPFH特征描述符和支持向量机(SVM)分类器完成对常规工业部件的检测;王斐等[24 ] 使用FPFH特征描述符识别焊件并估计其姿态,引导机器人完成智能柔性的焊接操作;Liu等[25 ] 提出了一种结合FPFH特征和贪婪投影三角剖分的点云配准算法,提高配准精度;Li等[26 ] 将FPFH特征与最近点迭代(ICP)算法相结合,提高点云配准效率和精度.以上基于FPFH特征的研究均存在以下不足:在进行特征提取时忽略了物体的颜色信息;计算FPFH特征描述符时采用手动多次调试的方法以取得相对较好的邻域,缺乏邻域半径的选取标准. ...
A comprehensive performance evaluation of 3D local feature descriptors
1
2016
... 快速点特征直方图(FPFH)[21 ] 具有描述性强、特征维度低、计算速度快等特点,在识别精度和计算效率之间实现了很好的平衡[22 ] ,且FPFH作为托盘自身的几何特征,不需要添加任何标记,在复杂的仓储环境中对遮挡具有鲁棒性.Huang等[23 ] 结合CAD模型,使用FPFH特征描述符和支持向量机(SVM)分类器完成对常规工业部件的检测;王斐等[24 ] 使用FPFH特征描述符识别焊件并估计其姿态,引导机器人完成智能柔性的焊接操作;Liu等[25 ] 提出了一种结合FPFH特征和贪婪投影三角剖分的点云配准算法,提高配准精度;Li等[26 ] 将FPFH特征与最近点迭代(ICP)算法相结合,提高点云配准效率和精度.以上基于FPFH特征的研究均存在以下不足:在进行特征提取时忽略了物体的颜色信息;计算FPFH特征描述符时采用手动多次调试的方法以取得相对较好的邻域,缺乏邻域半径的选取标准. ...
Detecting objects in scene point cloud: A combinational approach
1
2013
... 快速点特征直方图(FPFH)[21 ] 具有描述性强、特征维度低、计算速度快等特点,在识别精度和计算效率之间实现了很好的平衡[22 ] ,且FPFH作为托盘自身的几何特征,不需要添加任何标记,在复杂的仓储环境中对遮挡具有鲁棒性.Huang等[23 ] 结合CAD模型,使用FPFH特征描述符和支持向量机(SVM)分类器完成对常规工业部件的检测;王斐等[24 ] 使用FPFH特征描述符识别焊件并估计其姿态,引导机器人完成智能柔性的焊接操作;Liu等[25 ] 提出了一种结合FPFH特征和贪婪投影三角剖分的点云配准算法,提高配准精度;Li等[26 ] 将FPFH特征与最近点迭代(ICP)算法相结合,提高点云配准效率和精度.以上基于FPFH特征的研究均存在以下不足:在进行特征提取时忽略了物体的颜色信息;计算FPFH特征描述符时采用手动多次调试的方法以取得相对较好的邻域,缺乏邻域半径的选取标准. ...
基于焊件识别与位姿估计的焊接机器人视觉引导
1
2020
... 快速点特征直方图(FPFH)[21 ] 具有描述性强、特征维度低、计算速度快等特点,在识别精度和计算效率之间实现了很好的平衡[22 ] ,且FPFH作为托盘自身的几何特征,不需要添加任何标记,在复杂的仓储环境中对遮挡具有鲁棒性.Huang等[23 ] 结合CAD模型,使用FPFH特征描述符和支持向量机(SVM)分类器完成对常规工业部件的检测;王斐等[24 ] 使用FPFH特征描述符识别焊件并估计其姿态,引导机器人完成智能柔性的焊接操作;Liu等[25 ] 提出了一种结合FPFH特征和贪婪投影三角剖分的点云配准算法,提高配准精度;Li等[26 ] 将FPFH特征与最近点迭代(ICP)算法相结合,提高点云配准效率和精度.以上基于FPFH特征的研究均存在以下不足:在进行特征提取时忽略了物体的颜色信息;计算FPFH特征描述符时采用手动多次调试的方法以取得相对较好的邻域,缺乏邻域半径的选取标准. ...
基于焊件识别与位姿估计的焊接机器人视觉引导
1
2020
... 快速点特征直方图(FPFH)[21 ] 具有描述性强、特征维度低、计算速度快等特点,在识别精度和计算效率之间实现了很好的平衡[22 ] ,且FPFH作为托盘自身的几何特征,不需要添加任何标记,在复杂的仓储环境中对遮挡具有鲁棒性.Huang等[23 ] 结合CAD模型,使用FPFH特征描述符和支持向量机(SVM)分类器完成对常规工业部件的检测;王斐等[24 ] 使用FPFH特征描述符识别焊件并估计其姿态,引导机器人完成智能柔性的焊接操作;Liu等[25 ] 提出了一种结合FPFH特征和贪婪投影三角剖分的点云配准算法,提高配准精度;Li等[26 ] 将FPFH特征与最近点迭代(ICP)算法相结合,提高点云配准效率和精度.以上基于FPFH特征的研究均存在以下不足:在进行特征提取时忽略了物体的颜色信息;计算FPFH特征描述符时采用手动多次调试的方法以取得相对较好的邻域,缺乏邻域半径的选取标准. ...
3-D point cloud registration algorithm based on greedy projection triangulation
1
2018
... 快速点特征直方图(FPFH)[21 ] 具有描述性强、特征维度低、计算速度快等特点,在识别精度和计算效率之间实现了很好的平衡[22 ] ,且FPFH作为托盘自身的几何特征,不需要添加任何标记,在复杂的仓储环境中对遮挡具有鲁棒性.Huang等[23 ] 结合CAD模型,使用FPFH特征描述符和支持向量机(SVM)分类器完成对常规工业部件的检测;王斐等[24 ] 使用FPFH特征描述符识别焊件并估计其姿态,引导机器人完成智能柔性的焊接操作;Liu等[25 ] 提出了一种结合FPFH特征和贪婪投影三角剖分的点云配准算法,提高配准精度;Li等[26 ] 将FPFH特征与最近点迭代(ICP)算法相结合,提高点云配准效率和精度.以上基于FPFH特征的研究均存在以下不足:在进行特征提取时忽略了物体的颜色信息;计算FPFH特征描述符时采用手动多次调试的方法以取得相对较好的邻域,缺乏邻域半径的选取标准. ...
Improved algorithm for point cloud registration based on fast point feature histograms
1
2016
... 快速点特征直方图(FPFH)[21 ] 具有描述性强、特征维度低、计算速度快等特点,在识别精度和计算效率之间实现了很好的平衡[22 ] ,且FPFH作为托盘自身的几何特征,不需要添加任何标记,在复杂的仓储环境中对遮挡具有鲁棒性.Huang等[23 ] 结合CAD模型,使用FPFH特征描述符和支持向量机(SVM)分类器完成对常规工业部件的检测;王斐等[24 ] 使用FPFH特征描述符识别焊件并估计其姿态,引导机器人完成智能柔性的焊接操作;Liu等[25 ] 提出了一种结合FPFH特征和贪婪投影三角剖分的点云配准算法,提高配准精度;Li等[26 ] 将FPFH特征与最近点迭代(ICP)算法相结合,提高点云配准效率和精度.以上基于FPFH特征的研究均存在以下不足:在进行特征提取时忽略了物体的颜色信息;计算FPFH特征描述符时采用手动多次调试的方法以取得相对较好的邻域,缺乏邻域半径的选取标准. ...
Performance analysis of a generalized motion capture system using microsoft kinect 2.0
1
2017
... 根据特征值 λ 1 , λ 2 , λ 3 , [27 ] ,如表1 所示. ...
Dimensionality based scale selection in 3D LIDAR point clouds
1
2011
... 式中: L λ + P λ + S λ = 1 ,因此可将 L λ , P λ , S λ 分别视为点 P i 属于3个维度特征的概率.根据信息熵理论建立局部邻域熵函数[28 ] ,即 ...
Semantic 3D scene interpretation: A framework combining optimal neighborhood size selection with relevant features
1
2014
... 根据变量不确定性越小、信息熵越小的香农熵理论[29 ] ,可以得出,局部邻域信息熵值E n 越小,点Pi 维度特征的不确定性越小,即Pi 属于某种维度特征的概率越大,该邻域半径下的局部数据点的空间分布特性越相近,邻域半径越趋于最优.因此,可以根据邻域熵函数最小准则获取点云自适应最优邻域半径: ...
基于HSV颜色空间的快速边缘提取算法
1
2019
... 首先是颜色特征.Kinect V2传感器采集得到的点云数据包含待测目标的坐标及颜色信息.三维点云的RGB颜色空间是一种不均匀的颜色空间,两种颜色之间的知觉差异(色差)不能表示为该颜色空间中两点间的距离,因此不适用于特征相似度的检测.HSV颜色空间是一种基于感知的颜色模型,相比RGB空间,具有更强的识别能力,更符合人类的视觉特征[30 ] .本文选用HSV颜色空间来进行特征提取,其中H表示点云的色调,即所处的光谱颜色的位置,S表示点云的饱和度,V表示点云色彩的明度.提取HSV颜色空间的3个颜色分量来表示点云中每个关键点P F i
基于HSV颜色空间的快速边缘提取算法
1
2019
... 首先是颜色特征.Kinect V2传感器采集得到的点云数据包含待测目标的坐标及颜色信息.三维点云的RGB颜色空间是一种不均匀的颜色空间,两种颜色之间的知觉差异(色差)不能表示为该颜色空间中两点间的距离,因此不适用于特征相似度的检测.HSV颜色空间是一种基于感知的颜色模型,相比RGB空间,具有更强的识别能力,更符合人类的视觉特征[30 ] .本文选用HSV颜色空间来进行特征提取,其中H表示点云的色调,即所处的光谱颜色的位置,S表示点云的饱和度,V表示点云色彩的明度.提取HSV颜色空间的3个颜色分量来表示点云中每个关键点P F i
三维点云模型中特征点描述子及其匹配算法研究
1
2017
... 图18 为固定半径的FPFH、CFPFH的托盘识别结果(红色点),结合图17 及表2 可以看出,基于ACFPFH的托盘识别得到的正确匹配点数量更多,正确匹配点之间的平均距离间隔更小,点云分布更稠密,且正确匹配点对数量达到初始匹配点对数量的10%以上,能正确表示完整托盘[31 ] .表中:r 为邻域半径.匹配点间的平均距离间隔可近似理解为所有k 个邻域点间的平均距离的平均值,以k =5为例. ...
三维点云模型中特征点描述子及其匹配算法研究
1
2017
... 图18 为固定半径的FPFH、CFPFH的托盘识别结果(红色点),结合图17 及表2 可以看出,基于ACFPFH的托盘识别得到的正确匹配点数量更多,正确匹配点之间的平均距离间隔更小,点云分布更稠密,且正确匹配点对数量达到初始匹配点对数量的10%以上,能正确表示完整托盘[31 ] .表中:r 为邻域半径.匹配点间的平均距离间隔可近似理解为所有k 个邻域点间的平均距离的平均值,以k =5为例. ...
二进制点云局部特征描述子研究
1
2021
... 式中: Q CM 为正确匹配点对数量,即误匹配点对剔除后得到的匹配点对数量;Q PF 为模板点云关键点数量;Q SMP 为特征匹配之后得到的初始特征匹配点对数量.通过改变特征匹配阶段的阈值d th 可获得多个召回率及对应的精度,从而得到特征描述子的PR曲线.方向直方图签名(SHOT)特征描述符是目前最常用且性能较优的特征描述符[32 ] .因此,将ACFPFH特征描述符与固定半径的FPFH、CFPFH以及SHOT特征描述符做对比,选取的特征匹配阶段的阈值集合为d th ={0.2, 0.4, 0.6, 0.75, 0.85, 0.925, 0.95, 0.975, 1.0},得到不同特征描述符对应的托盘识别P -R 曲线,如图19 所示.取d th =0.75对不同特征描述符的精度进行比较,如表3 所示.表中:P FD 为其他特征描述符的精度.进一步分析场景点云的特征提取所需时间,比较特征描述符的性能,如表4 所示.表中:t FD 为其他特征描述符所用的运行时间. ...
二进制点云局部特征描述子研究
1
2021
... 式中: Q CM 为正确匹配点对数量,即误匹配点对剔除后得到的匹配点对数量;Q PF 为模板点云关键点数量;Q SMP 为特征匹配之后得到的初始特征匹配点对数量.通过改变特征匹配阶段的阈值d th 可获得多个召回率及对应的精度,从而得到特征描述子的PR曲线.方向直方图签名(SHOT)特征描述符是目前最常用且性能较优的特征描述符[32 ] .因此,将ACFPFH特征描述符与固定半径的FPFH、CFPFH以及SHOT特征描述符做对比,选取的特征匹配阶段的阈值集合为d th ={0.2, 0.4, 0.6, 0.75, 0.85, 0.925, 0.95, 0.975, 1.0},得到不同特征描述符对应的托盘识别P -R 曲线,如图19 所示.取d th =0.75对不同特征描述符的精度进行比较,如表3 所示.表中:P FD 为其他特征描述符的精度.进一步分析场景点云的特征提取所需时间,比较特征描述符的性能,如表4 所示.表中:t FD 为其他特征描述符所用的运行时间. ...












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}