Journal of Shanghai Jiao Tong University ›› 2024, Vol. 58 ›› Issue (5): 776-782.doi: 10.16183/j.cnki.jsjtu.2022.224
• New Type Power System and the Integrated Energy • Previous Articles
LI Cuiming( ), WANG Hua, XU Longer, WANG Long
), WANG Hua, XU Longer, WANG Long
Received:2022-06-17
Revised:2022-07-30
Accepted:2022-10-17
Online:2024-05-28
Published:2024-06-17
CLC Number:
LI Cuiming, WANG Hua, XU Longer, WANG Long. Road Recognition Method of Photovoltaic Plant Based on Improved DeepLabv3+[J]. Journal of Shanghai Jiao Tong University, 2024, 58(5): 776-782.
Add to citation manager EndNote|Ris|BibTeX
URL: https://xuebao.sjtu.edu.cn/EN/10.16183/j.cnki.jsjtu.2022.224
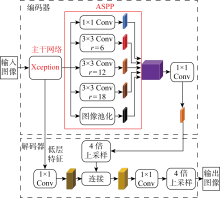
Fig.1
Network structure of DeepLabv3+ basic model
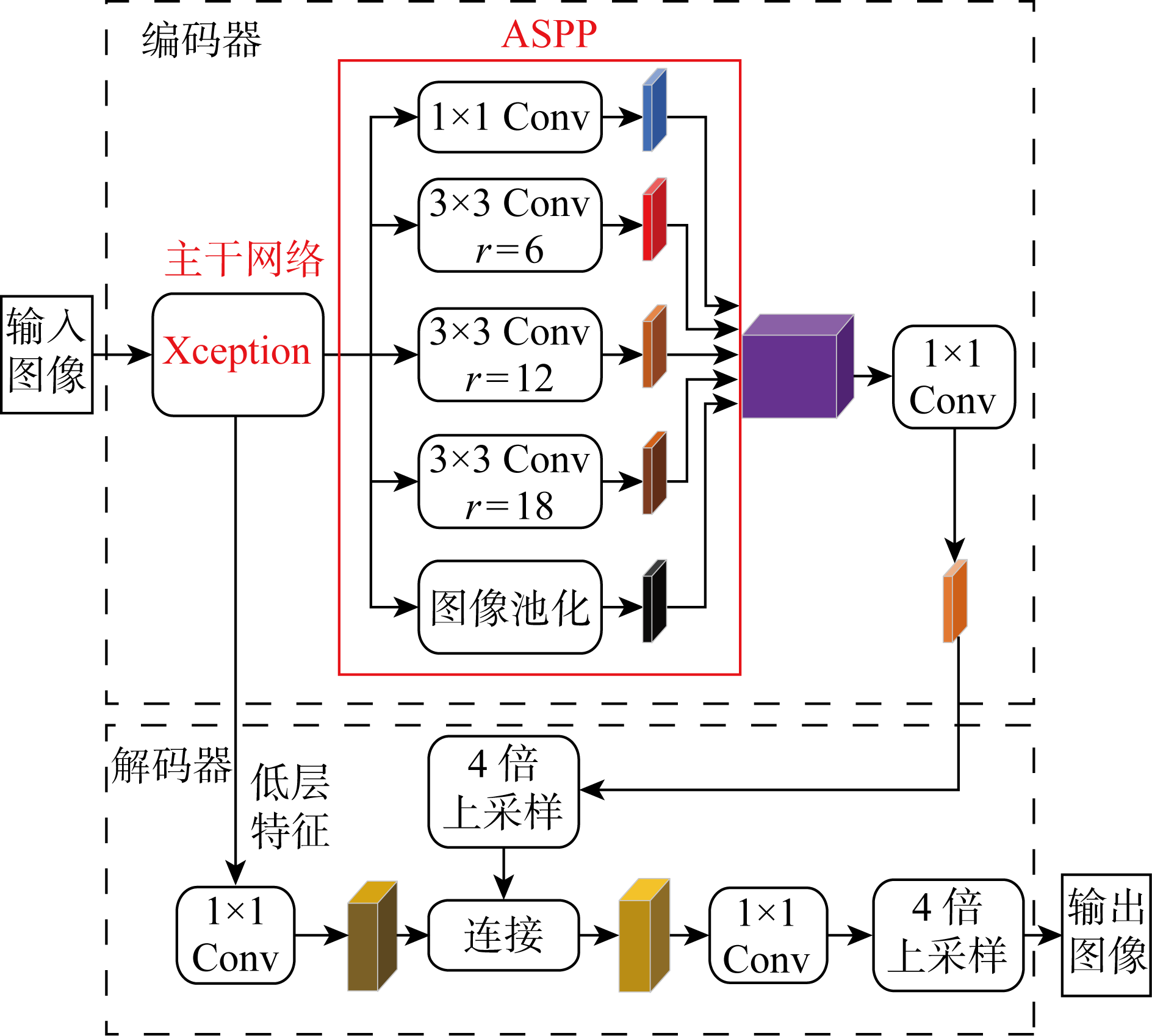
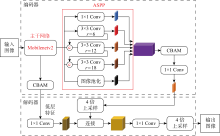
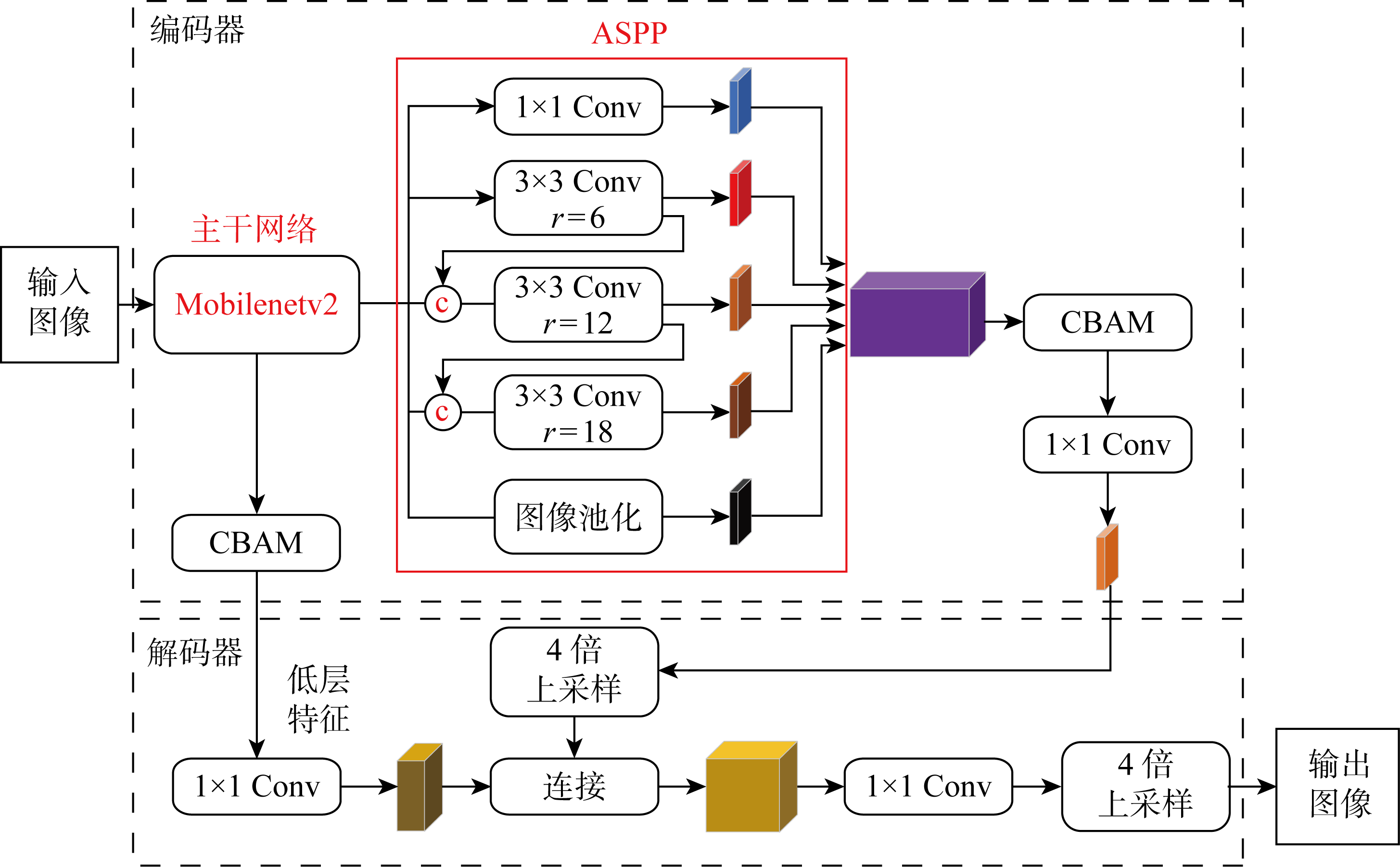
Fig.2
Network structure of improved DeepLabv3+ model
Tab.1
Network structure of optimized MobileNetv2
| 输入 | 网络层 | 输出步长 | t | c | n | s | r |
|---|---|---|---|---|---|---|---|
| 224×224×3 | conv2d | 2 | — | 32 | 1 | 2 | 1 |
| 112×112×32 | bottleneck | 2 | 1 | 16 | 1 | 1 | 1 |
| 112×112×16 | bottleneck | 4 | 6 | 24 | 2 | 2 | 1 |
| 56×56×24 | bottleneck | 8 | 6 | 32 | 3 | 2 | 1 |
| 28×28×32 | bottleneck | 16 | 6 | 64 | 4 | 2 | 1 |
| 28×28×64 | bottleneck | 16 | 6 | 96 | 3 | 1 | 1 |
| 14×14×96 | bottleneck | 16 | 6 | 160 | 3 | 1 | 2 |
| 7×7×160 | bottleneck | 16 | 6 | 320 | 1 | 1 | 4 |
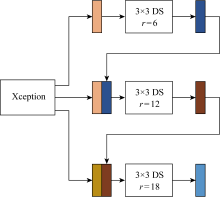
Fig.3
Empty depth separable convolution of different-sensory field fusion
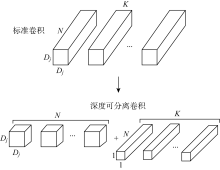
Fig.4
Standard convolution and depthwise separable convolution
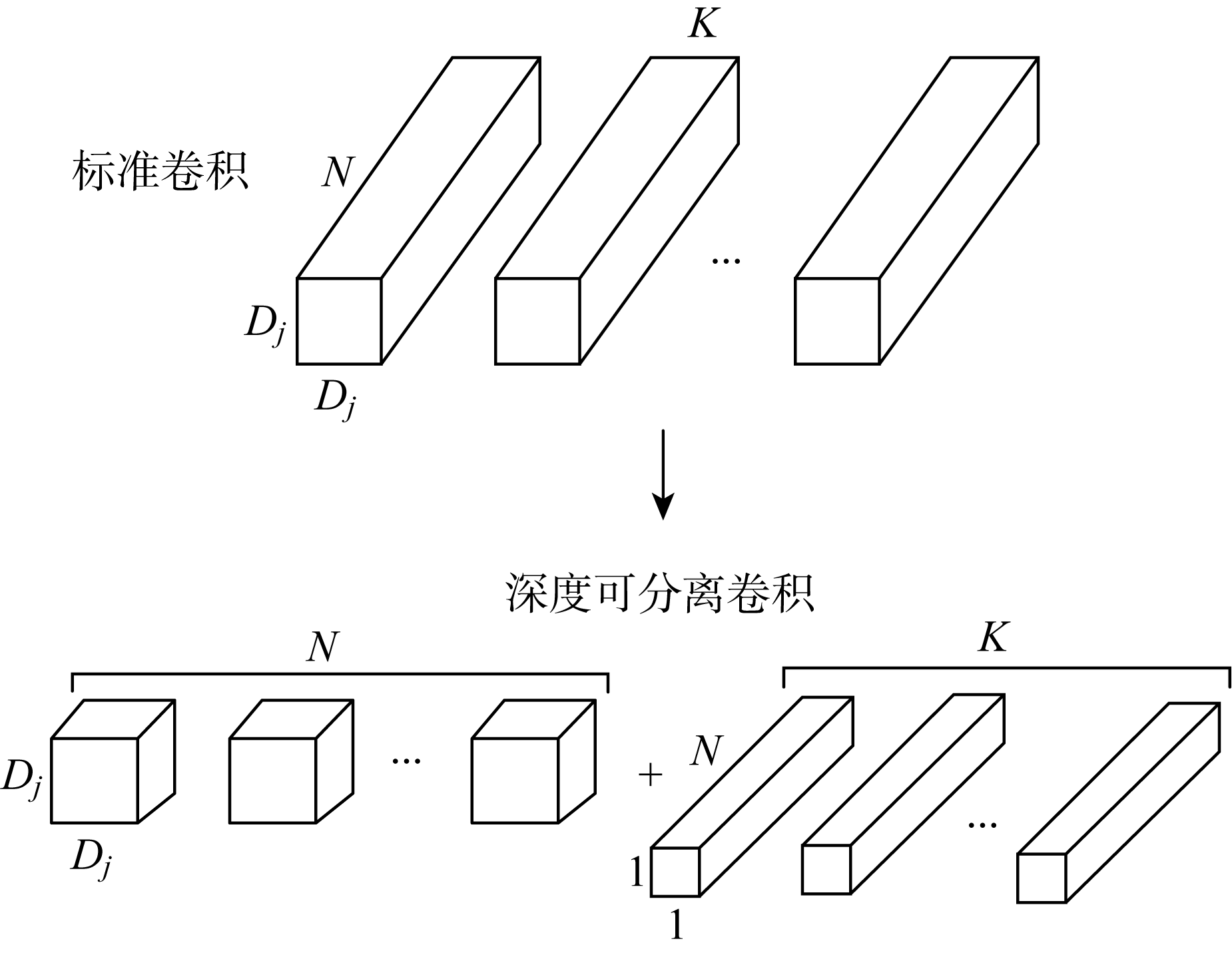
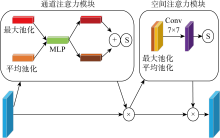
Fig.5
Structure of CBAM
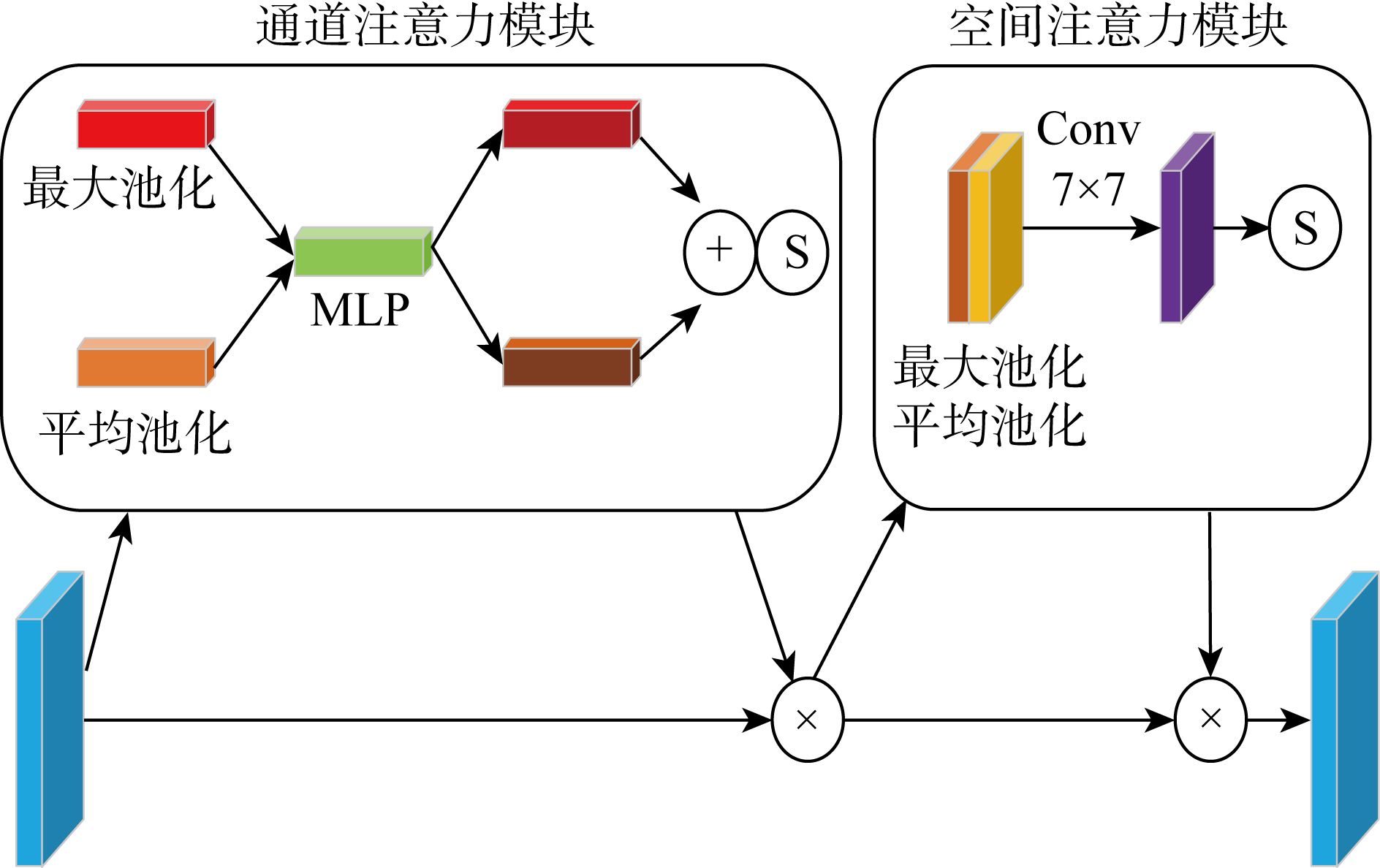
Fig.6
Curve of loss change
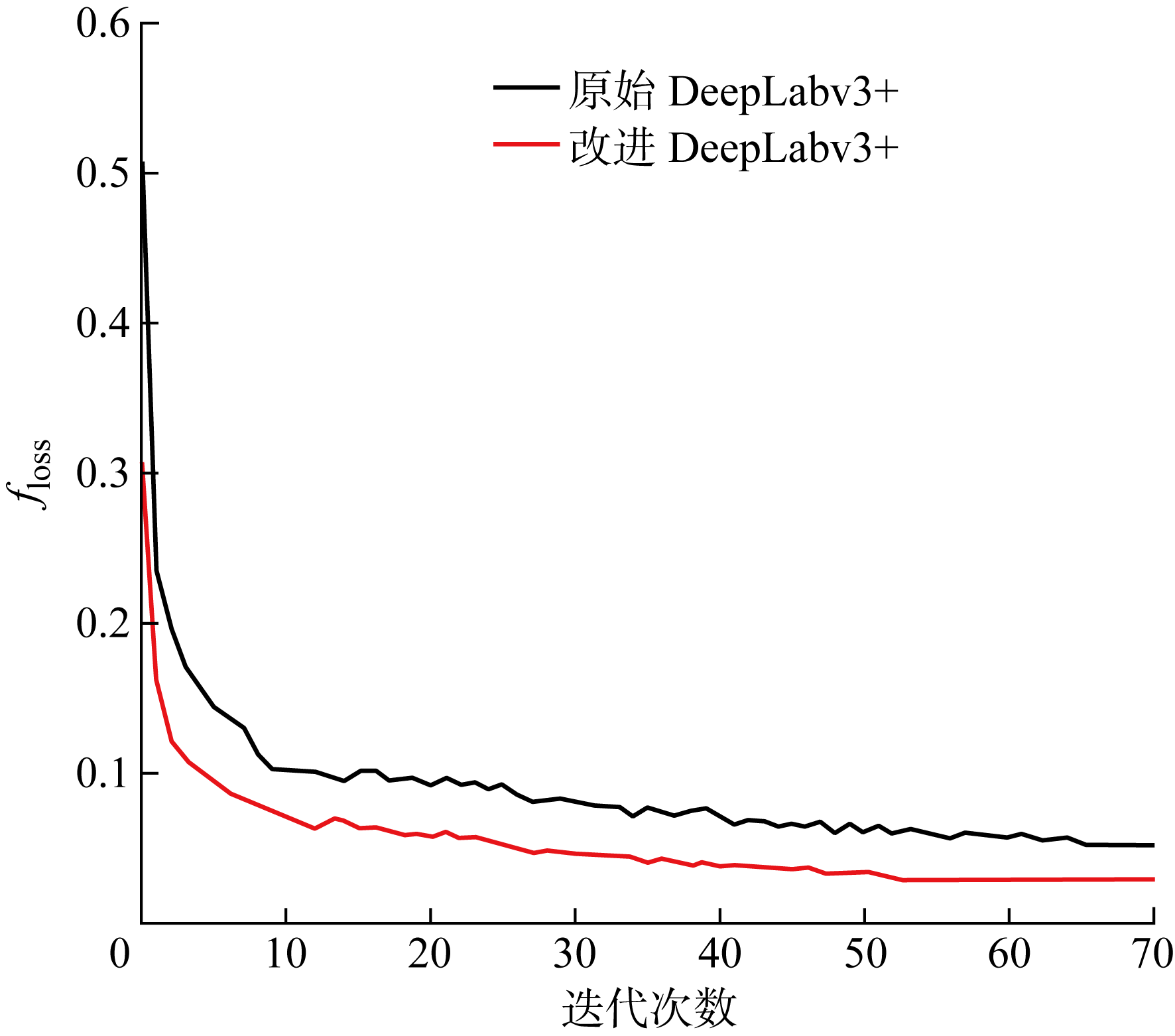

Fig.7
Comparison of segmentation effect between improved DeepLabv3+ model and basic model

Tab.2
Comparison of precision, number of parameters, and inference time of different models
| 模型 | MPA/% | MIoU/% | 单张图片 推理时间/ms | 总参数量× 10-6 |
|---|---|---|---|---|
| SegNet | 93.84 | 91.42 | 121 | 14.86 |
| UNet | 94.73 | 92.05 | 125 | 17.30 |
| 原始Deeplabv3+ | 96.27 | 93.48 | 156 | 41.25 |
| 改进Deeplabv3+ | 98.06 | 95.92 | 112 | 2.28 |
| [1] |
KONG H, AUDIBERT J Y, PONCE J. General road detection from a single image[J]. IEEE Transactions on Image Processing, 2010, 19(8): 2211-2220.
doi: 10.1109/TIP.2010.2045715 pmid: 20371404 |
| [2] | 方浩, 贾睿, 卢嘉鹏. 基于颜色和纹理特征的道路图像分割[J]. 北京理工大学学报, 2010, 30(8): 934-939. |
| FANG Hao, JIA Rui, LU Jiapeng. Segmentation of full vision images based on colour and texture features[J]. Transactions of Beijing Institute of Technology, 2010, 30(8): 934-939. | |
| [3] | 吴骅跃, 段里仁. 基于RGB熵和改进区域生长的非结构化道路识别方法[J]. 吉林大学学报(工学版), 2019, 49(3): 727-735. |
| WU Huayue, DUAN Liren. Unstructured road detection method based on RGB entropy and improved region growing[J]. Journal of Jilin University (Engineering and Technology Edition), 2019, 49(3): 727-735. | |
| [4] |
SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651.
doi: 10.1109/TPAMI.2016.2572683 pmid: 27244717 |
| [5] |
BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
doi: 10.1109/TPAMI.2016.2644615 pmid: 28060704 |
| [6] | RONNEBERGER O, FISCHER P, BROX T. UNet: Convolutional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham, Switzerland: Springer, 2015: 234-241. |
| [7] | ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 6230-6239. |
| [8] | CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer, 2018: 833-851. |
| [9] | CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. (2017-01-01) [2021-04-08]. https://arxiv.org/abs/1706.05587. |
| [10] | CHOLLET F. Xception: Deep learning with depthwise separable convolutions[C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 1251-1258. |
| [11] | BAHETI B, INNANI S, GAJRE S, et al. Semantic scene segmentation in unstructured environment with modified DeepLabV3+[J]. Pattern Recognition Letters, 2020, 138: 223-229. |
| [12] | LIU R R, HE D Z. Semantic segmentation based on Deeplabv3+ and attention mechanism[C]// 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference. Chongqing, China: IEEE, 2021: 255-259. |
| [13] | SANDLER M, HOWARD A, ZHU M L, et al.MobileNetV2: Inverted residuals and linear bottle-necks[C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake, USA: IEEE, 2018: 4510-4520. |
| [14] | HOWARD A G, ZHU M L, CHEN B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[EB/OL]. (2017-04-17)[2021-04-08]. https://arxiv.org/abs/1704.04861. |
| [15] | WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]// Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer, 2018: 3-19. |
| [1] | GU Xinghai顾星海),HUA Bao(花 豹),LIU Yahui(刘亚辉),SUN Xuemin(孙学民),BAO Jinsong∗(鲍劲松). Semantic Entity Recognition and Relation Construction Method for Assembly Process Document [J]. J Shanghai Jiaotong Univ Sci, 2024, 29(3): 537-556. |
| [2] | ZHANG Yanjun(张彦军), WANG Biyun(王碧云),CAI Yunze (蔡云泽). Multi-Channel Based on Attention Network for Infrared Small Target Detection [J]. J Shanghai Jiaotong Univ Sci, 2024, 29(3): 414-427. |
| [3] | CHEN Haolan, JIN Bingying, LIU Yadong, QIAN Qinglin, WANG Peng, CHEN Yanxia, YU Xijuan, YAN Yingjie. Fault Detection in Power Distribution Systems Based on Gated Recurrent Attention Network [J]. Journal of Shanghai Jiao Tong University, 2024, 58(3): 295-303. |
| [4] | ZENG Zhirian(曾志贤),CAO Jianjun*(曹建军),WENG Nianfeng(翁年凤),YUAN Zhen(袁震),YU Xu(余旭). Cross-Modal Entity Resolution for Image and Text Integrating Global and Fine-Grained Joint Attention Mechanism [J]. J Shanghai Jiaotong Univ Sci, 2023, 28(6): 728-737. |
| [5] | GAO Tao, WEN Yuanbo, CHEN Ting, ZHANG Jing. A Single Image Deraining Algorithm Based on Swin Transformer [J]. Journal of Shanghai Jiao Tong University, 2023, 57(5): 613-623. |
| [6] | WAN Anping, YANG Jie, MIAO Xu, CHEN Ting, ZUO Qiang, LI Ke. Boiler Load Forecasting of CHP Plant Based on Attention Mechanism and Deep Neural Network [J]. Journal of Shanghai Jiao Tong University, 2023, 57(3): 316-325. |
| [7] | LI Cuiming, WANG Ning, ZHANG Chen. Hierarchical Mission Planning for Cleaning Photovoltaic Panels Based on Improved Genetic Algorithm [J]. Journal of Shanghai Jiao Tong University, 2021, 55(9): 1169-1174. |
| [8] | YUAN Ming, LIU Qun, SUN Haichao, TAN Hongsheng. A Heterogeneous Network Representation Method Based on Variational Inference and Meta-Path Decomposition [J]. Journal of Shanghai Jiao Tong University, 2021, 55(5): 586-597. |
| [9] | CAI Yunze, ZHANG Yanjun. Infrared Dim and Small Target Detection Based on Dual-Channel Feature-Enhancement Integrated Attention Network [J]. Air & Space Defense, 2021, 4(4): 14-22. |
| [10] | ZHANG Jingyi, HE Guanghui, DAI Zhou, LIU Yadong. Named Entity Recognition of Enterprise Annual Report Integrated with BERT [J]. Journal of Shanghai Jiao Tong University, 2021, 55(2): 117-123. |
| [11] | LI Zhiqiang, BAO Jinsong, LIU Tianyuan, WANG Jiacheng . Judging the Normativity of PAF Based on TFN and NAN [J]. Journal of Shanghai Jiao Tong University(Science), 2020, 25(5): 569-577. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||