Journal of Shanghai Jiao Tong University ›› 2023, Vol. 57 ›› Issue (5): 613-623.doi: 10.16183/j.cnki.jsjtu.2022.032
Special Issue: 《上海交通大学学报》2023年“电子信息与电气工程”专题
• Electronic Information and Electrical Engineering • Previous Articles Next Articles
GAO Tao1, WEN Yuanbo1( ), CHEN Ting1, ZHANG Jing2
), CHEN Ting1, ZHANG Jing2
Received:2022-02-14
Revised:2022-03-20
Accepted:2022-04-28
Online:2023-05-28
Published:2023-06-02
Contact:
WEN Yuanbo
E-mail:wyb@chd.edu.cn.
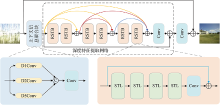
Fig.1
Single image deraining network based on Swin Transformer
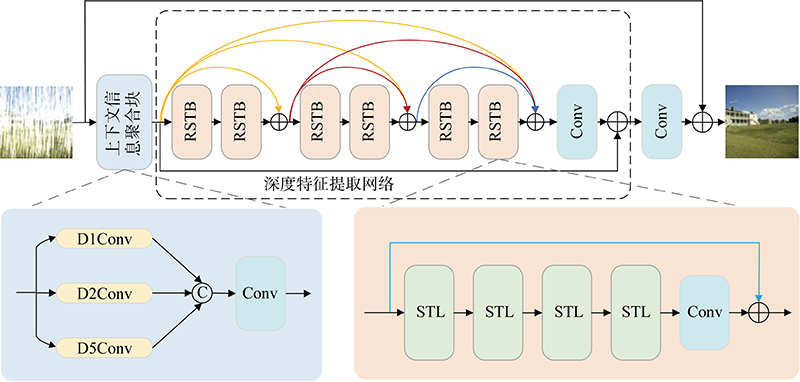
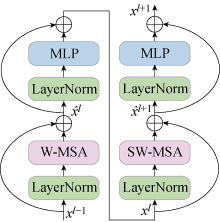
Fig.2
Main layer of Swin Transformer
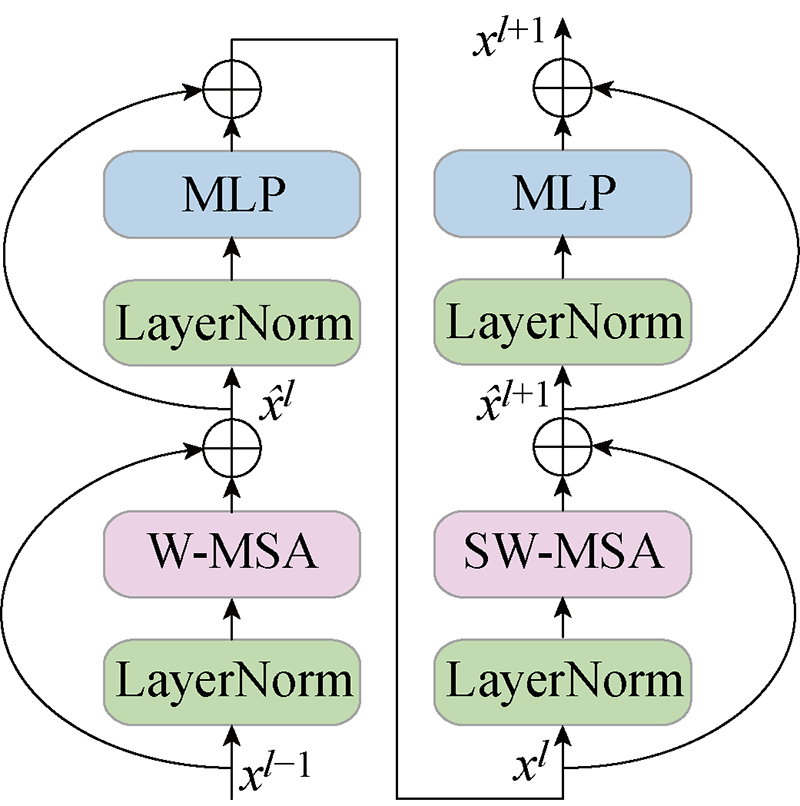
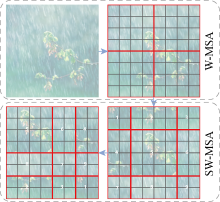
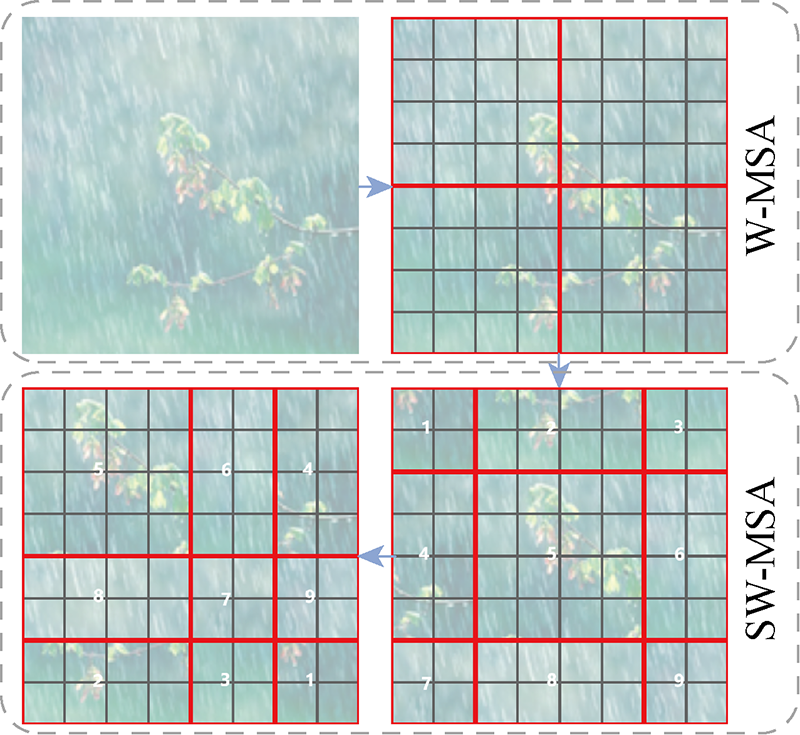
Fig.3
Diagram of relocating shifted windows
Tab.1
Partition and rename of single image deraining datasets
| 数据集 | 训练样本对 | 测试样本对 | 重命名 |
|---|---|---|---|
| Rain14000[ | 11 200 | 2 800 | Test2800 |
| Rain800[ | 700 | 100 | Test100 |
| Rain100H[ | 1 800 | 100 | Rain100H |
| Rain100L[ | 0 | 100 | Rain100L |
| Rain1200[ | 0 | 1 200 | Test1200 |
| Rain12[ | 12 | 0 | — |
Tab.2
Comparative results of network components ablation study on Test1200[12] dataset
| 网络组成 | 组合方式 | ||||||
|---|---|---|---|---|---|---|---|
| 输入层 | 单卷积 | √ | √ | √ | √ | √ | × |
| CGB | × | × | × | × | × | √ | |
| 特征提取网络 | ResNet | √ | × | × | × | × | × |
| STB | × | √ | √ | √ | √ | √ | |
| RSTB | × | × | √ | √ | √ | √ | |
| DRSTB | × | × | × | √ | √ | √ | |
| DRST | × | × | × | × | √ | √ | |
| 输出层 | 单卷积 | √ | √ | √ | √ | √ | √ |
| PSNR/dB | 25.41 | 27.35 | 28.94 | 30.27 | 32.15 | 34.83 | |
| SSIM | 0.846 | 0.882 | 0.886 | 0.904 | 0.912 | 0.924 | |
Tab.3
Comparative results of loss functions ablation study on Test1200[12] dataset
| 损失函数 | PSNR/dB | SSIM |
|---|---|---|
| MSE | 29.57 | 0.884 |
| Edge | 29.24 | 0.891 |
| SSIM | 30.68 | 0.903 |
| (MSE, SSIM) | 32.79 | 0.916 |
| (Edge, SSIM) | 34.83 | 0.924 |
Tab.4
Comparative results of different methods on synthetic datasets[28-29,10,12]
| 算法 | Test100[ | Rain100H[ | Rain100L[ | Test2800[ | Test1200[ | 平均 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB (G/%) | SSIM (G/%) | ||||||
| DerainNet[ | 22.77 | 0.810 | 14.92 | 0.592 | 27.03 | 0.884 | 24.31 | 0.861 | 23.38 | 0.835 | 22.48 (45.6)↑ | 0.796 (17.3)↑ | |||||
| SEMI[ | 22.35 | 0.788 | 16.56 | 0.486 | 25.03 | 0.842 | 24.43 | 0.782 | 26.05 | 0.822 | 22.88 (43.9)↑ | 0.744 (25.5)↑ | |||||
| DIDMDN[ | 22.56 | 0.818 | 17.35 | 0.524 | 25.23 | 0.741 | 28.13 | 0.867 | 29.65 | 0.901 | 24.58 (34.0)↑ | 0.770 (21.3)↑ | |||||
| UMRL[ | 24.41 | 0.829 | 26.01 | 0.832 | 29.18 | 0.923 | 29.97 | 0.905 | 30.55 | 0.910 | 28.02 (17.5)↑ | 0.880 (6.14)↑ | |||||
| RESCAN[ | 25.00 | 0.835 | 26.36 | 0.786 | 29.80 | 0.881 | 31.29 | 0.904 | 30.51 | 0.882 | 28.59 (15.1)↑ | 0.857 (8.98)↑ | |||||
| PReNet[ | 24.81 | 0.851 | 26.77 | 0.858 | 32.44 | 0.950 | 31.75 | 0.916 | 31.36 | 0.911 | 29.42 (11.9)↑ | 0.897 (4.12)↑ | |||||
| MSPFN[ | 27.50 | 0.876 | 28.66 | 0.860 | 32.40 | 0.933 | 32.82 | 0.930 | 32.39 | 0.916 | 30.75 (7.06)↑ | 0.903 (3.43)↑ | |||||
| MPRNet[ | 30.27 | 0.897 | 30.41 | 0.890 | 36.40 | 0.965 | 33.64 | 0.938 | 32.91 | 0.916 | 32.73 (0.58)↑ | 0.921 (1.41)↑ | |||||
| 本文算法 | 28.28 | 0.913 | 30.22 | 0.904 | 37.53 | 0.979 | 33.76 | 0.952 | 34.83 | 0.924 | 32.92 | 0.934 | |||||

Fig.4
Visual comparative results of other methods[14??-17] and proposed method on synthetic rainy images[10,12,27-28]

Tab.5
Quantitative comparative results of different methods on natural dataset[30]
| 算法 | NIQE | SSEQ |
|---|---|---|
| RESCAN[ | 5.066 | 24.18 |
| PReNet[ | 5.025 | 20.76 |
| MSPFN[ | 4.961 | 22.29 |
| MPRNet[ | 5.166 | 22.05 |
| 本文算法 | 4.946 | 18.93 |
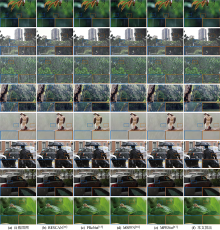
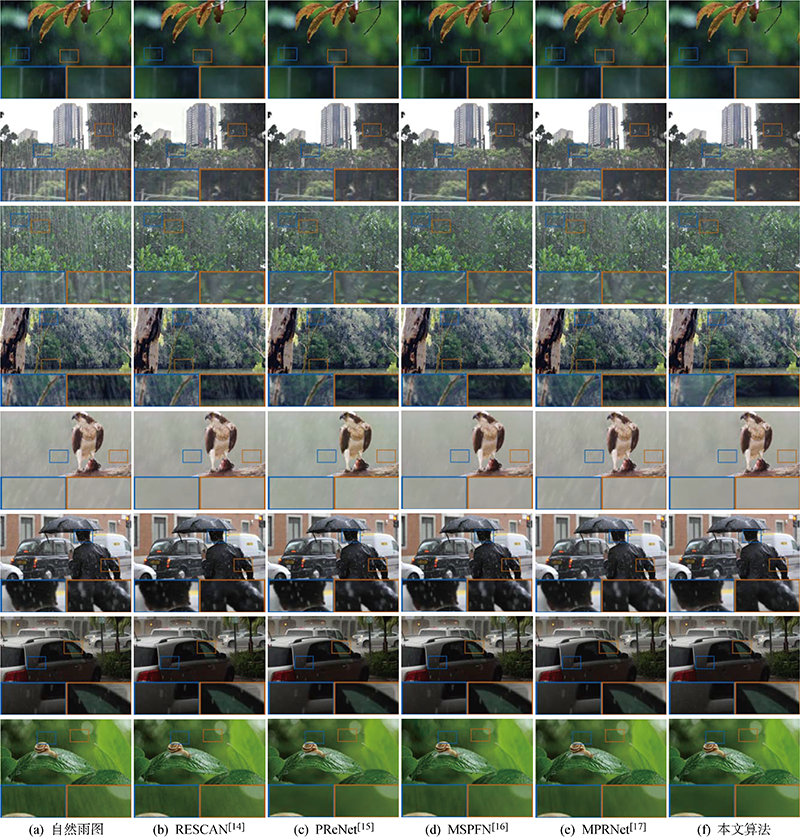
Fig.5
Visual comparison of other methods[14??-17] and proposed method on natural rainy images[30]
Tab.6
Efficiency comparative results of processing images by different methods
| 算法 | 参数量×10-6 | 浮点运算 次数×10-9 | 平均耗时/s |
|---|---|---|---|
| MSPFN[ | 15.82 | 37.86 | 0.045 |
| MPRNet[ | 3.637 | 8.841 | 0.048 |
| 本文算法 | 2.381 | 9.688 | 0.033 |
| [1] | 陈舒曼, 陈玮, 尹钟. 单幅图像去雨算法研究现状及展望[J]. 计算机应用研究, 2022, 39(1): 9-17. |
| CHEN Shuman, CHEN Wei, YIN Zhong. Research status and prospect of single image rain removal algorithm[J]. Application Research of Computers, 2022, 39(1): 9-17. | |
| [2] | DENG S, WEI M, WANG J, et al. Detail-recovery image deraining via context aggregation networks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2020: 14560-14569. |
| [3] | HE K, GKIOXARI G, DOLLÁR P, et al. Mask RCNN[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 2961-2969. |
| [4] | 王春波, 张卫东, 张文渊, 等. 复杂交通环境中车辆的视觉检测[J]. 上海交通大学学报, 2000, 34(12): 1680-1682. |
| WANG Chunbo, ZHANG Weidong, ZHANG Wen-yuan, et al. Vision-based vehicles detection in complex traffic scenes[J]. Journal of Shanghai Jiao Tong University, 2000, 34(12): 1680-1682. | |
| [5] |
YANG W, TAN R T, WANG S, et al. Single image deraining: From model-based to data-driven and beyond[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 43(11): 4059-4077.
doi: 10.1109/TPAMI.2020.2995190 URL |
| [6] | ZHENG X, LIAO Y, GUO W, et al. Single-image-based rain and snow removal using multi-guided filter[C]//International Conference on Neural Information Processing. Daegu, South Korea: APNNS, 2013: 258-265. |
| [7] |
KANG L, LIN C, FU Y. Automatic single-image-based rain streaks removal via image decomposition[J]. IEEE Transactions on Image Processing, 2011, 21(4): 1742-1755.
doi: 10.1109/TIP.2011.2179057 URL |
| [8] | LUO Y, XU Y, JI H. Removing rain from a single image via discriminative sparse coding[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 3397-3405. |
| [9] | LI Y, TAN R T, GUO X, et al. Rain streak removal using layer priors[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016: 2736-2744. |
| [10] |
FU X, HUANG J, DING X, et al. Clearing the skies: A deep network architecture for single-image rain removal[J]. IEEE Transactions on Image Processing, 2017, 26(6): 2944-2956.
doi: 10.1109/TIP.2017.2691802 pmid: 28410108 |
| [11] | WEI W, MENG D, ZHAO Q, et al. Semi-supervised transfer learning for image rain removal[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019: 3877-3886. |
| [12] | ZHANG H, PATEL V M. Density-aware single image deraining using a multi-stream dense network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 695-704. |
| [13] | YASARLA R, PATEL V M. Uncertainty guided multi-scale residual learning-using a cycle spinning CNN for single image de-raining[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019: 8405-8414. |
| [14] | LI X, WU J, LIN Z, et al. Recurrent squeeze-and-excitation context aggregation net for single image deraining[C]//Proceedings of the European Conference on Computer Vision. Salt Lake City, UT, USA: IEEE, 2018: 254-269. |
| [15] | REN D, ZUO W, HU Q, et al. Progressive image deraining networks: A better and simpler baseline[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019: 3937-3946. |
| [16] | JIANG K, WANG Z, YI P, et al. Multi-scale progressive fusion network for single image deraining[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE. 2020: 8346-8355. |
| [17] | ZAMIR S W, ARORA A, KHAN S, et al. Multi-stage progressive image restoration[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Kuala Lumpur, Malaysia: IEEE, 2021: 14821-14831. |
| [18] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems. Long Beach, CA, USA: NIPS, 2017: 5998-6008. |
| [19] | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: Hierarchical vision Transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021: 10012-10022. |
| [20] | XIAO T, DOLLAR P, SINGH M, et al. Early convolutions help transformers see better[C]//Thirty-Fifth Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2021: 34. |
| [21] | YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[C]//International Conference on Leaning Representations. Caribe Hilton, San Juan, Puerto Rico: OpenReview. net, 2016: 1-13. |
| [22] | WANG P, CHEN P, YUAN Y, et al. Understanding convolution for semantic segmentation[C]//2018 IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe, NV, USA: IEEE, 2018: 1451-1460. |
| [23] | LIANG J, CAO J, SUN G, et al. SwinIR: Image restoration using swin transformer[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021: 1833-1844. |
| [24] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016: 770-778. |
| [25] | HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Venice, Italy: IEEE, 2017: 4700-4708. |
| [26] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
doi: 10.1109/tip.2003.819861 pmid: 15376593 |
| [27] |
KAMGAR-PARSI B, ROSENFELD A. Optimally isotropic Laplacian operator[J]. IEEE Transactions on Image Processing, 1999, 8(10): 1467-1472.
doi: 10.1109/83.791975 URL |
| [28] |
ZHANG H, SINDAGI V, PATEL V M. Image de-raining using a conditional generative adversarial network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 30(11): 3943-3956.
doi: 10.1109/TCSVT.76 URL |
| [29] | YANG W, TAN R T, FENG J, et al. Deep joint rain detection and removal from a single image[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Venice, Italy: IEEE, 2017: 1357-1366. |
| [30] |
FU X, LIANG B, HUANG Y, et al. Lightweight pyramid networks for image deraining[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 31(6): 1794-1807.
doi: 10.1109/TNNLS.5962385 URL |
| [31] |
HUYNH-THU Q, GHANBARI M. Scope of validity of PSNR in image/video quality assessment[J]. Electronics Letters, 2008, 44(13): 800-801.
doi: 10.1049/el:20080522 URL |
| [32] |
MITTAL A, SOUNDARARAJAN R, BOVIK A C. Making a “completely blind” image quality analyzer[J]. IEEE Signal Processing Letters, 2012, 20(3): 209-212.
doi: 10.1109/LSP.2012.2227726 URL |
| [33] |
LIU L, LIU B, HUANG H, et al. No-reference image quality assessment based on spatial and spectral entropies[J]. Signal Processing: Image Communication, 2014, 29(8): 856-863.
doi: 10.1016/j.image.2014.06.006 URL |
| [1] | ZHANG Junning, SU Qunxing, WANG Cheng, XU Chao, LI Yining. A Domain Adaptive Semantic Segmentation Network Based on Improved Transformation Network [J]. Journal of Shanghai Jiao Tong University, 2021, 55(9): 1158-1168. |
| [2] | WU Guangli, GUO Zhenzhou, LI Leiting, WANG Chengxiang. Video Abnormal Detection Combining FCN with LSTM [J]. Journal of Shanghai Jiao Tong University, 2021, 55(5): 607-614. |
| [3] | ZHAN Zhu (占竹), ZHANG Wenjun (张文俊), CHEN Xia (陈霞), WANG Jun (汪军) . Objective Evaluation of Fabric Flatness Grade Based on Convolutional Neural Network [J]. J Shanghai Jiaotong Univ Sci, 2021, 26(4): 503-510. |
| [4] | JIANG Xinghao, ZHAO Zheyu, XU Ke . Adversarial Attack Technology for Vision-Based Aircraft Intelligent Object Detection [J]. Air & Space Defense, 2021, 4(1): 8-13. |
| [5] | WANG Xiuping1,2,BAI Ruilin1,LIU Ziteng1. A Novel Approach for Determining Intrinsic Parameters of Camera Using Two Parallelograms [J]. Journal of Shanghai Jiaotong University, 2015, 49(03): 366-370. |
| [6] | MA Bo,ZHOU Yue. A New Multi-view Face Tracking Algorithm [J]. Journal of Shanghai Jiaotong University, 2010, 44(07): 902-0906. |
| [7] | YING Junhao,ZHANG Xiubin. A Double Circle Algorithm for Particle Size Distribution of Ores [J]. Journal of Shanghai Jiaotong University, 2010, 44(03): 384-0388. |
| Viewed | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
Full text 526
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
Abstract 614
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||