

固定翼飞行器通常需要一定的滑跑距离才能保证安全着陆.在没有跑道的情况下,固定翼无人机(unmanned aerial vehicle, UAV)需要借助滑橇、降落伞、拦阻网或者气囊等方式回收.这些降落方式对降落场地有一定要求,一定程度上限制了固定翼无人机的应用场合.栖落机动是鸟类常见的机动飞行动作之一.该机动动作利用失速后随时间变化的粘性和压力阻力来实现鸟的快速减速,以在目标地点着陆.Berg等[1]观察到鸽子可以从空中直接降落到栖木上,在降落过程中,挥动平面角度使身体向上倾斜,以加速更多空气向前,从而减缓鸟类的速度.研究者借鉴鸟类的降落方式,提出无人机栖落机动的概念.将栖落机动应用于固定翼无人机的降落,可以减少降落场地的限制,实现固定翼无人机在小范围空间内的降落.因此,无人机栖落机动的研究具有重要的价值和意义.
近年来,无人机栖落机动研究在航空领域和控制领域引起越来越多关注,并取得了一定的研究成果.Roberts等[2]将局部线性时变控制器应用于固定翼无人机上,并利用实验评估了栖落机动过程中的可控性.Moore等[3]基于线性二次调节器树的非线性反馈控制,在阵风等重大干扰下实现固定翼无人机落点精确的栖落机动.Roderick等[4]采取闭环平衡控制方法研究飞行器栖落机动飞行范围以及参数变化范围的最大化区域.Fletcher等[5]证明了深度强化学习在固定翼飞行器栖落机动控制方面的可行性.然而,上述研究大多未考虑真实环境中未知干扰的存在.在实际飞行中,无人机会面临不同风况的外部干扰,因此在理论模型环境中得到的控制策略与在真实环境中的运行存在一定差异,需要研究风扰下栖落机动的控制策略设计方法.由此,感知风扰的能力对于真实环境中栖落机动的实现具有重要意义.近些年,已有一些研究者对风的预测感知技术进行了探索.赵辉等[6]提出一种基于反向传播神经网络的组合风速预测方法;黄勇东等[7]提出一种基于小波包分解和改进差分算法的人工神经网络组合模型,有效地对风速进行单步预测.传统的风速预测都依赖大量历史环境数据,关系复杂且训练成本高;而考虑到飞行器的飞行状态与风扰之间存在一定的动力学关系,利用这一优势,可使预测模型的复杂度降低,缩短训练时间.
由此,本文提出一种风扰下无人机栖落机动控制的综合设计方法,将模仿深度强化学习和稀疏辨识方法相结合,实现风速预测和风扰下的栖落机动控制.针对风扰下的栖落机动控制问题,首先采用域随机化方法建立包含多种风况的栖落机动训练环境.接着,利用历史数据和候选函数库,离线学习各个风况下栖落机动系统的稀疏模型.然后,在具有多种风况的栖落机动系统训练环境中,训练基于模仿深度强化学习的栖落机动控制策略,增加稀疏模型辨识得到的风况信息作为神经网络的输入信号,得到风扰下的栖落机动控制策略.最后,对风扰下栖落机动控制过程进行仿真,验证了所提栖落机动控制策略的有效性.
1 栖落机动动力学模型与问题描述
根据栖落机动的特点,并为了简化问题,考虑无人机栖落机动的纵向运动,不考虑侧倾、偏航和侧滑动力学,假设横向运动对纵向运动方程无影响.在气流坐标系下的栖落机动系统的纵向动力学方程和运动学方程[8]如下:
式中:v为固定翼无人机的飞行速度;T为发动机推力;α为迎角;θ为俯仰角;D、L分别为无人机所有阻力和升力 ;m为无人机的质量;g为重力加速度;q为俯仰角速度;M为空气动力矩;Iy为俯仰转动惯量;x为无人机的水平位置;h为垂直高度;μ为航迹倾斜角.
针对栖落机动的应用场景,因为栖落过程经历的时间很短,所以将在此过程中的风扰设置为恒值风速vw.则风扰下固定翼无人机纵向运动的气动力和力矩方程[9]如下:
式中:ρ为空气密度;S为固定翼无人机的空气动力面积;CL、CD分别为升力、阻力系数;CM为力矩系数.其中CL和CD可由平板模型方法得到与α之间的表达式[10]为
假设固定翼无人机装有全动水平尾翼,能够帮助无人机在低速飞行的状态下获得较大的控制力矩[11],则空气动力矩系数的表达式为
式中:Se为升降舵的表面积;le为升降舵空气动力重心到无人机质心的距离;δe为升降舵偏转角.
在栖落机动纵向动力学模型中设置控制输入U为
本文研究的栖落机动任务为从原点附近位置,结合推力和升降舵偏转控制,将固定翼飞行器降落在给定坐标的目标点附近.
2 风扰下的栖落机动控制策略设计
2.1 控制策略设计
首先,在深度强化学习仿真环境中,利用域随机化方法来模拟随机风扰环境.然后,以栖落参考轨迹数据作为训练数据进行模仿学习,将模仿学习得到的策略网络权重共享给深度强化学习算法中的行动器网络,以提升学习效率.接着,在深度强化学习网络中,结合栖落机动目标设置目标函数,行动器网络与评判器网络根据目标函数进行权值更新,直至学习的策略满足栖落机动要求.随后,引入含控制的非线性动力学稀疏辨识(sparse identification of nonlinear dynamics with control, SINDYc)方法,通过采集飞行过程中无人机的状态信息来辨识风况信息;深度强化学习算法根据辨识到的风况信息得到适用于当前风扰下的栖落机动控制策略.
2.2 域随机化
为模拟现实中的风扰环境,需要在强化学习环境中加入模型的不确定性.在使用域随机化模拟风扰环境过程中,域随机化前通常需要构建一个接近真实环境的模拟器,将模拟器建模为一组具有可调潜变量的马尔可夫决策过程,这些可调潜变量所对应的就是物理参数如风速.然后通过校准进一步改进模拟模型以更接近物理系统.这些步骤确保通过域随机化生成的随机模拟器可以模拟现实中的风扰环境.域随机化的基本思想是在尽可能模仿真实环境的情况下训练智能体,让智能体经历不同域之间的变化来训练学习的策略,使得该策略对建模的不确定性和误差具有鲁棒性.如果经过训练的策略能够在多个域中保持良好的性能,那么该策略在转移到现实世界时可能会表现得更好.然而,稳健的策略学习并不是通过适应特定环境来实现精确控制,而是优化了策略在广泛条件下的平均性能.采用域随机化的方法应用于强化学习环境的动力学模型,得到目标函数表达式如下:
式中:E为在策略p得到的期望值回报;η为动力学参数,受风况影响; p为不同风况下动力学模型的概率分布;τ为无人机在策略π下的运动轨迹;γ为折扣因子;r为栖落机动的奖励函数;t为时间;k为求期望过程中的索引.
最大化上述目标函数面临的一项挑战是风况的变化会导致状态S的领域偏移.即在数据仿真期间,由于风的影响,无人机栖落系统在不同风速下的实际飞行轨迹会有所不同.由于环境中的风况会发生改变,栖落机动系统中状态
图1
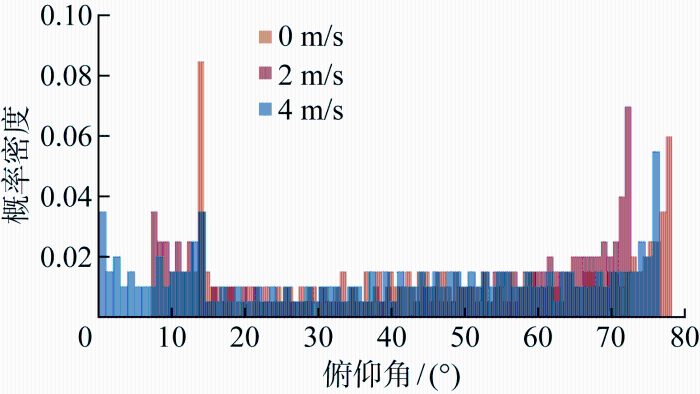
2.3 栖落机动风况信息辨识
2.2 节分析了风扰对于栖落机动控制的影响,体现了在无风条件和实际风环境下的栖落机动控制差异,突显了风况信息的辨识对栖落机动控制的实现具有重要意义.本节主要研究无人机所处环境的风况信息辨识方法,基于辨识得到的风况信息结合模仿深度强化学习(imitation deep reinforcement learning, IDRL)设计栖落机动控制策略.
Brunton等[12]最初研究了不带控制的非线性动力学稀疏辨识(sparse identification of nonlinear dynamics, SINDY)方法,利用稀疏性技术和机器学习的进步,从测量数据中辨识动力系统方程.在此基础上,该团队将SINDY算法扩展到包含外部输入和反馈控制,即SINDYc算法.在本文中,带有控制输入的栖落机动系统的表达式如下:
式中:$\boldsymbol{x}(t)$为时间t时栖落机动系统的状态量,在SINDYc算法中设置为[v α q θ]T;$\boldsymbol{u}(t)$为时间t时栖落机动系统的控制量,具体为
在SINDYc中,以Δt=0.01 s为采样时间,并基于IDRL算法得到的随机控制序列获得训练数据,用于辨识式(7)中的$ f(\cdot) $函数.收集得到栖落机动系统的状态变量$\boldsymbol{x}(t)$和控制输入$\boldsymbol{u}(t)$的序列数据以形成矩阵$\boldsymbol{\chi} \in \mathbf{R}^{n \times m}$和$\boldsymbol{U} \in \mathbf{R}^{n \times u_{m}}$,分别由状态和控制的n个采样值组成,即
式中:$\boldsymbol{x}_{n} 、 \boldsymbol{u}_{n} $分别为第n个采样时间下的状态向量和控制向量.状态导数的采样值也遵循相同的存储结构,通过数值微分计算状态导数,具体表达式如下:
栖落机动系统的候选函数库设置为
式中:1表示元素为1的列向量;χ⊗U定义为χ和U中分量的所有乘积的组合.结合上述公式,设置SINDYc方法中栖落机动系统的稀疏模型结构和稀疏回归问题的目标函数分别为
式中:$\theta_{j}(\boldsymbol{x})$为候选函数库$\Theta(\boldsymbol{x}) $中第j列的候选函数;$\xi_{k, j} $为第k个状态的第j个候选函数$\theta_{j}(\boldsymbol{x})$的加权系数;ηk是第k个状态的稀疏性加权系数.
利用LASSO回归算法求解得到稀疏因子$\xi_{k}$,并存储在稀疏矩阵$\boldsymbol{\Xi}$中,具体表现形式如下:
则包含风况信息的栖落机动系统辨识模型方程表示为
根据稀疏因子ξk的值域变化可辨识得到无人机当前所处的风况信息.
结合式(4),在预先了解物理系统的关联结构信息后,设置对应的候选函数库,加快辨识算法的收敛速度,具体的栖落机动系统候选函数库设置为
得到栖落机动系统的SINDYc算法示意图如图2所示.
图2
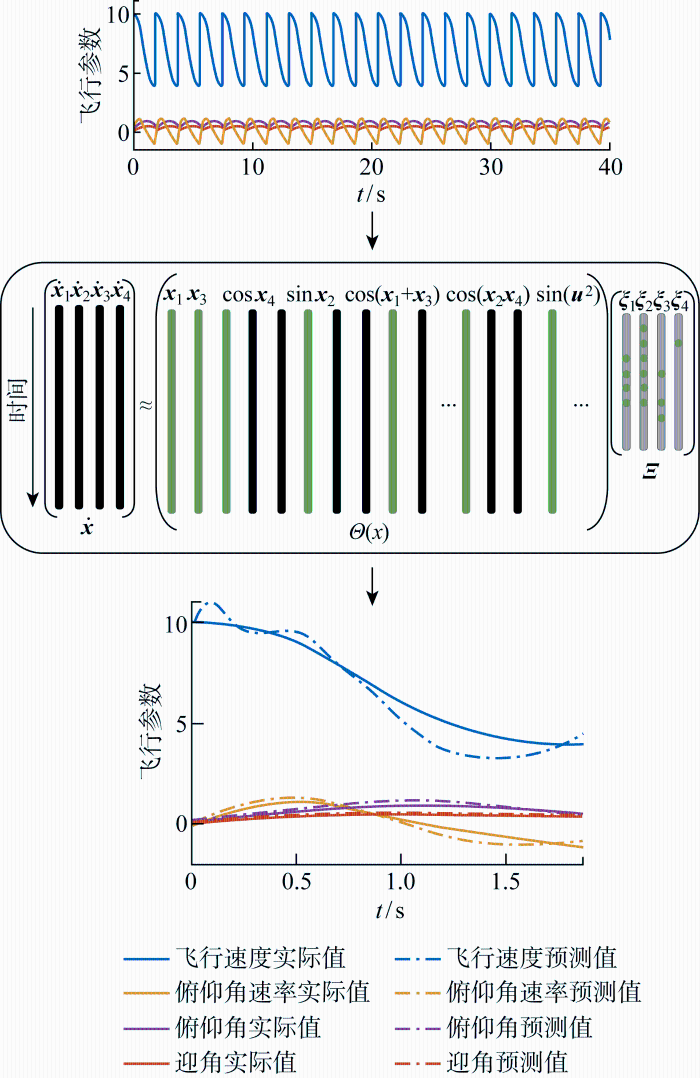
采用SINDYc方法进行风况辨识,输入无人机在不同风况下的栖落机动的状态历史数据,通过建立的函数库学习构建稀疏模型结构,在算法成功收敛后能够正确辨识出无人机所在环境的风况.
2.4 基于SINDYc与强化学习的栖落机动控制策略设计
本节在成功辨识外部风况信息的基础上,设计基于SINDYc和强化学习的栖落机动控制策略.将固定翼无人机栖落机动看作一个可重复的分幕式任务, 在IDRL基本算法的基础上结合搭建不同训练环境的域随机化方法与能辨识不同风况信息的SINDYc方法,以训练得到栖落机动控制策略.
在外部风扰动影响下的栖落机动控制策略的学习算法分为3个阶段,如图3所示.在第1阶段中,由专家数据和外部向量Zt作为输入和标签,训练模仿策略,其中专家数据由高斯伪谱优化软件生成的轨迹得到.经过数据处理,最终得到的专家数据格式为[st at rt st+1Zt I],其中变量st、 st+1为t与t+1时刻无人机的状态量集合,变量at为t时刻无人机的动作量集合,变量rt为t时刻时状态量与动作量相关的奖励值,变量I为分幕式任务中每一幕的终止信号,外部向量Zt表示影响栖落机动飞行的风况信息.对得到的专家数据做优先经验回放的非均匀抽样,抽样得到的数据用于策略网络的更新,其策略网络的结构如图4(a)所示,包含1个输入层、2个隐藏层、以及1个输出层,训练好的策略网络将当前时刻的栖落机动的状态和外部风况信息作为输入,输出得到当前时刻的栖落机动动作值.图中:ReLU、TanH为激活函数.
图3
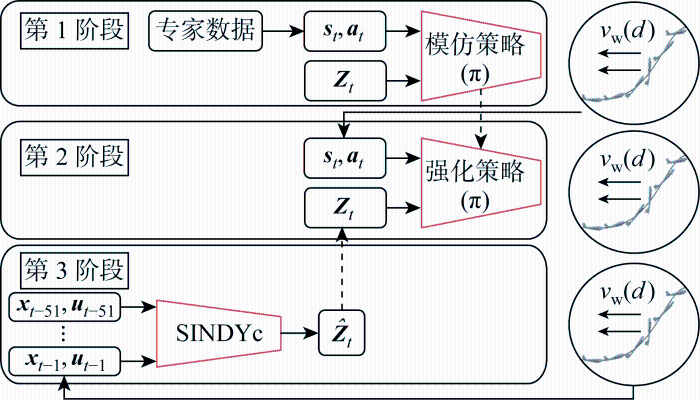
图3
基于SINDYc的栖落机动控制策略框架
Fig.3
Framework of agile landing control strategy based on SINDYc
图4
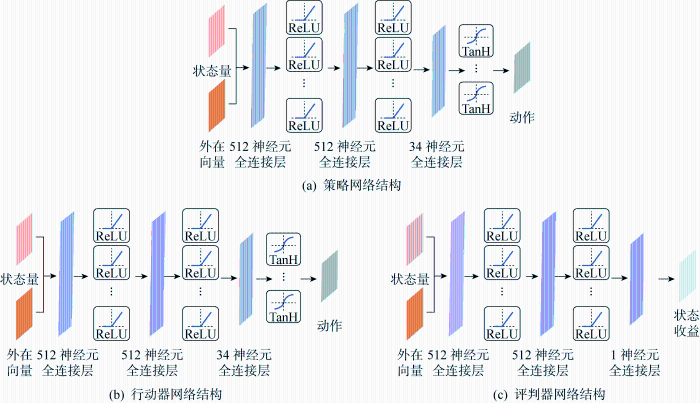
图4
风扰下栖落机动的网络结构
Fig.4
Network architecture for agile landing with wind disturbance
式中:
图5
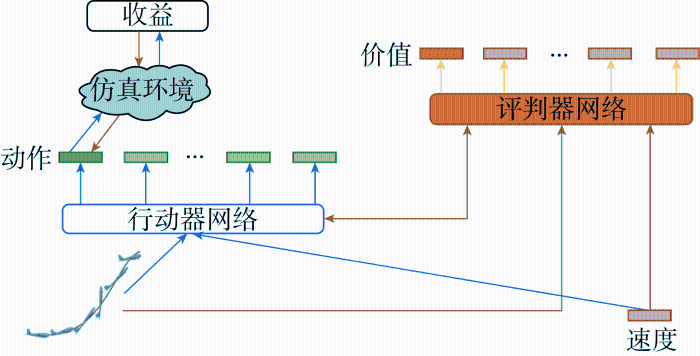
同时利用评判器评估当前状态的收益v(st)和当前动作的收益q(st, at),直至采集到所需的批量大小.行动器和评判器网络根据批量经验数据,计算得到损失函数,更新自身网络参数,通过行动器和评判器不断交互学习,直到学习的策略满足无人机栖落机动的要求.利用PPO算法可以实现多次小批量更新网络参数,进而优化策略网络,提升策略学习效率.
第3阶段根据无人机栖落过程的历史数据,基于SINDYc的方法辨识栖落机动系统所处的风况环境信息,并将辨识得到的环境信息作为强化学习阶段中行动器网络和评判器网络的输入信号.这很好地结合了SINDYc方法的应用与模仿深度学习,改进了IDRL.其具体的流程为:以Δt=0.01 s为采样时间,并基于IDRL算法得到的随机控制序列获得各个风况下的训练数据.SINDYc方法根据得到的采样数据,训练出在各个风况下的栖落机动稀疏模型.在训练和测试阶段,将飞行状态数据和各个栖落机动稀疏模型预测的状态数据进行对比配对,得出所处的风况环境信息
3 风扰下栖落机动控制仿真验证
为验证风扰下栖落机动控制策略的有效性,进行仿真实验研究.固定翼无人机栖落机动强化学习环境中的动力学方程如式(4)所示.在域随机化设计的仿真环境中,不同风况条件设置为不同风速的恒定逆向风干扰,设置风速值为0、2、4 m/s这3种情况.仿真中设置栖落机动每一幕的初始时间t0=0 s,初始状态量
表1 固定翼无人机的几何参数
Tab.1
| 参数 | 数值 |
|---|---|
| m/kg | 0.8 |
| 气动弦长, c/m | 0.25 |
| 翼展, b/m | 1.0 |
| Iy/(kg·m2) | 0.1 |
| 机翼面积, Swing/m2 | 0.25 |
| Se/m2 | 0.054 |
| le/m | 0.235 |
| g/(m·s-2) | 9.8 |
| ρ/(kg·m-3) | 1.225 |
表2 状态及控制量约束参数
Tab.2
| 参数 | 数值 |
|---|---|
| 最大速度, vmax/(m·s-1) | 25 |
| 最大航迹倾斜角, μmax/rad | π/4 |
| 最大迎角, αmax/rad | π/2 |
| 最大俯仰角, θmax/rad | π/2 |
| 最大俯仰角速度, qmax/(rad·s-1) | 3.5 |
| 最大终点俯仰角, θf/rad | π/6 |
| 最大位移, xmax/m | 15 |
| 最大终点高度, hmax/m | 5 |
| 最大升降舵偏转角, δe,max/rad | π/3 |
| T | 3.7698 |
| 终点预设速度, vf/(m·s-1) | 3.5 |
| 终点预设位移, xf/m | 12.3 |
| 终点预设高度, hf/m | 3.5 |
| 终点速度容许误差, σv/(m·s-1) | 0.5 |
| 终点位移容许误差, σx/m | 0.1 |
| 终点高度容许误差, σh/m | 0.1 |
根据栖落机动系统的参数设置,在SINDYc算法中,系统的时间步长为1 ms,模型的时间步长为0.01 s,控制输入每10个系统时间步确定1次,并且在此期间所应用的控制保持恒定,稀疏性加权系数η选取为(10-5, 10-4, 10-5, 10-5).图6表示利用迎角数据稀疏辨识的过程,其中结合预测效果,确定不同风况下的SINDYc稀疏模型,并在强化学习栖落机动策略时进行模型调用,对比验证以确定当前环境的风况信息.SINDYc模型的预测精度如图7所示,根据该图可评估稀疏模型的预测效果.图中:Δα为模型预测迎角变化与实际值的误差.图7展示了栖落机动稀疏模型训练结束后,各个稀疏模型所预测的迎角变化曲线和实际风况环境下的迎角变化曲线的差异.由于不同风速产生的迎角变化误差值存在差异,所以SINDYc能够根据不同风速对应的迎角变化误差来有效辨识当前无人机所处的风况环境.
图6
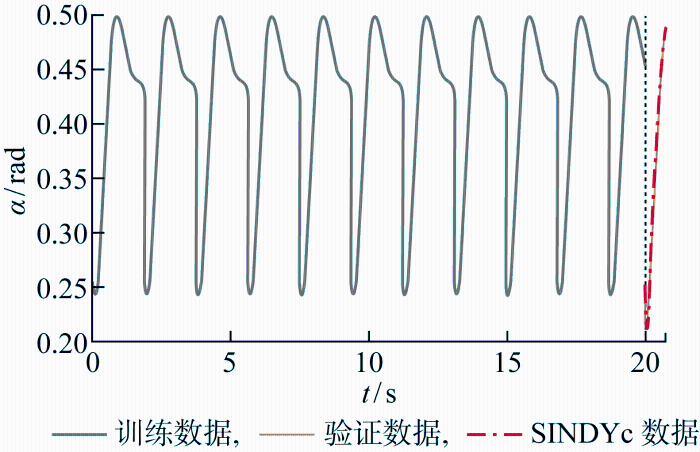
图6
训练和验证阶段的迎角数据序列
Fig.6
Sequence of angle of attack data in training and validation phases
图7

在模仿学习阶段,采用高斯伪谱法进行轨迹规划,在每种环境风况下均生成6条成功的栖落轨迹,将每条成功轨迹采样200个离散点作为专家样本输入,每种风况环境的样本量为 1 200 个.结合式(17)得到每个时刻状态所对应的最佳动作的奖励值,转化得到模仿学习的专家数据样本,用于策略学习.在深度强化学习阶段,采样频率设置为0.01 s,回合数设置为 40 000,通过与仿真环境的交互获取当前状态下各个动作的奖励值,持续生成高奖励值的学习样本,优化强化学习网络参数,提升智能体的性能.
图8为模仿学习和深度强化学习两阶段的奖励函数变化曲线图.如图8(a)所示,在模仿学习阶段,在专家数据的学习过程中,策略学习的平均价值函数稳定在750,证明了策略网络学习的有效性.在强化学习中,奖励值的变化代表了当前强化学习训练效果的好坏以及能否得到成功的栖落机动控制策略.图8(b)展示了IDRL和RL两种算法在学习过程中平均奖励的变化情况.图中蓝色曲线代表IDRL算法的平均奖励变化,而红色曲线代表RL算法的平均奖励变化.由图可见,RL方法在早期阶段需要对状态动作空间进行大量探索.尽管在后期阶段RL算法能够收敛,但其收敛结果常常陷入局部最优解.相较之下,IDRL算法通过引入模仿学习进行预训练,大大加快了学习进程.具体表现为IDRL在 20 000 回合后便收敛到奖励值较高的策略.这表明IDRL算法在减少探索时间的同时,能够快速找到比RL更优的策略,从而实现更高的平均奖励.图8(c)表示仅使用IDRL和将域随机化、SINDYc与IDRL相结合的算法学习过程中的平均奖励变化.由图可知,若仅采用IDRL的控制策略,在面对外部风扰动时,栖落机动系统在各个域内所获得的平均奖励明显偏低,难以得到成功的栖落机动策略;而使用改进后的IDRL控制策略在训练幕数达到 25 000 幕以上时,IDRL算法就已经收敛到奖励值较高的策略.在采用IDRL训练完成后,测试集幕数取为 1 000,完成栖落机动的成功率可以达到96.9%.在测试集中,将初始时刻状态集扩展到未曾学习的范围,扩展后的下限值为
上限值为
图8

图9
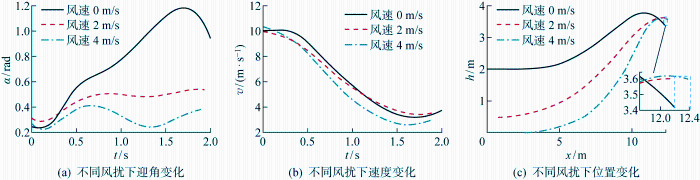
通过上面的仿真验证可以发现,IDRL在风扰下栖落机动控制方面有很大优势,使飞行器能够成功地栖落在目标点附近.然而在飞行控制方面,IDRL并没有得以广泛应用,应用最广的依然是传统的PID控制.比较分析二者发现,在应对风扰下的飞行控制时,IDRL具有更强的适应性和泛化能力,无需精确的系统模型,能够通过端到端学习直接从传感器数据到动作的映射,在复杂的风扰环境下自主学习控制策略.相比之下,PID控制虽然简单且稳定,但适应性有限且依赖于精确的系统模型和环境参数调整,因此在应对风扰下的飞行控制中可能表现较差.但是IDRL面临训练时间长、不稳定性等问题,这是其暂时得不到广泛应用的重要原因之一.
4 结论
提出一种综合设计方法,用于在风扰环境下实现无人机的栖落机动控制.该方法通过结合深度强化学习和稀疏辨识方法,来实现风速预测和风扰下的栖落机动控制.
(1) 针对现实飞行环境中存在不确定风扰动的情况,在深度强化学习训练中引入域随机化方法能够解决单一环境训练策略应用的局限性,并提升在不同环境条件下栖落机动控制策略的鲁棒性.深度强化学习与域随机化结合训练得到的栖落机动控制策略提升了策略在不同环境条件下的平均性能.
(2) 采用SINDYc可实现不同风环境下的栖落机动模型辨识,在飞行过程中进行实时状态监测并与SINDYc模型状态预测结果比对,可精准获得当前飞行位置的风况信息.
(3) 风况辨识模型的引入可以使得训练策略根据所得风况信息进行栖落机动控制策略的调整,成功实现风扰下的栖落机动控制.而且,在仿真验证阶段将初始条件扩展到学习中未使用的范围时,所设计的栖落机动控制策略仍然表现出良好的性能.
参考文献
Wing and body kinematics of takeoff and landing flight in the pigeon (Columba livia)
[J].
DOI:10.1242/jeb.038109
PMID:20435815
[本文引用: 1]

Takeoff and landing are critical phases in a flight. To better understand the functional importance of the kinematic adjustments birds use to execute these flight modes, we studied the wing and body movements of pigeons (Columba livia) during short-distance free-flights between two perches. The greatest accelerations were observed during the second wingbeat of takeoff. The wings were responsible for the majority of acceleration during takeoff and landing, with the legs contributing only one-quarter of the acceleration. Parameters relating to aerodynamic power output such as downstroke amplitude, wingbeat frequency and downstroke velocity were all greatest during takeoff flight and decreased with each successive takeoff wingbeat. This pattern indicates that downstroke velocity must be greater for accelerating flight to increase the amount of air accelerated by the wings. Pigeons used multiple mechanisms to adjust thrust and drag to accelerate during takeoff and decelerate during landing. Body angle, tail angle and wing plane angles all shifted from more horizontal orientations during takeoff to near-vertical orientations during landing, thereby reducing drag during takeoff and increasing drag during landing. The stroke plane was tilted steeply downward throughout takeoff (increasing from -60+/-5 deg. to -47+/-1 deg.), supporting our hypothesis that a downward-tilted stroke plane pushes more air rearward to accelerate the bird forward. Similarly, the stroke plane tilted upward during landing (increasing from -1+/-2 deg. to 17+/-7 deg.), implying that an upward-tilted stroke plane pushes more air forward to slow the bird down. Rotations of the stroke plane, wing planes and tail were all strongly correlated with rotation of the body angle, suggesting that pigeons are able to redirect aerodynamic force and shift between flight modes through modulation of body angle alone.
On the controllability of fixed-wing perching
[C]
Robust post-stall perching with a simple fixed-wing glider using LQR-Trees
[J].
Bird-inspired dynamic grasping and perching in arboreal environments
[J].
Reinforcement learning for a perched landing in the presence of wind
[C]
基于CEEMDAN-PE和QGA-BP的短期风速预测
[J].
Short-term wind speed prediction based on CEEMDAN-PE and QGA-BP
[J].
基于小波包分解和改进差分算法的神经网络短期风速预测方法
[J].
Short-term wind speed forecast method based on WPD-IDE-NN
[J].
变体无人机栖落机动建模与轨迹优化
[J].
Modeling and trajectory optimization of perching maneuvers for morphing UAV
[J].
基于深度强化学习的无人机栖落机动控制策略设计
[J].
Design of UAV perching maneuver control strategy based on deep reinforcement learning
[J].
Experiments in fixed-wing UAV perching
[C]
Disturbance compensation based piecewise linear control design for perching maneuvers
[J].
Discovering governing equations from data by sparse identification of nonlinear dynamical systems
[J].
DOI:10.1073/pnas.1517384113
PMID:27035946
[本文引用: 1]
Extracting governing equations from data is a central challenge in many diverse areas of science and engineering. Data are abundant whereas models often remain elusive, as in climate science, neuroscience, ecology, finance, and epidemiology, to name only a few examples. In this work, we combine sparsity-promoting techniques and machine learning with nonlinear dynamical systems to discover governing equations from noisy measurement data. The only assumption about the structure of the model is that there are only a few important terms that govern the dynamics, so that the equations are sparse in the space of possible functions; this assumption holds for many physical systems in an appropriate basis. In particular, we use sparse regression to determine the fewest terms in the dynamic governing equations required to accurately represent the data. This results in parsimonious models that balance accuracy with model complexity to avoid overfitting. We demonstrate the algorithm on a wide range of problems, from simple canonical systems, including linear and nonlinear oscillators and the chaotic Lorenz system, to the fluid vortex shedding behind an obstacle. The fluid example illustrates the ability of this method to discover the underlying dynamics of a system that took experts in the community nearly 30 years to resolve. We also show that this method generalizes to parameterized systems and systems that are time-varying or have external forcing.
The surprising effectiveness of ppo in cooperative multi-agent games
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}