为确保用电服务质量,及时解决用户用电诉求,电力客服中心的规模不断壮大,作为电力企业与客户沟通的重要桥梁,发挥着越来越重要的作用[1 ] .话务量表示单位时间发生呼叫的次数,与用户数量、用户通信的频繁程度相关.目前,电力客服中心话务量预测管理应用主要依靠历史经验,因无法适应现代供电服务体系下复杂的服务场景,造成话务服务人力资源利用不合理.精准的话务量预测作为电力客户服务工作的基础和前提,引起了行业和学术界越来越多的关注[2 -3 ] .
定性与定量预测是话务量预测研究领域的两大主要分类.定性预测的方法通常指直观判断法或专家评估法,该方法的预测精度在很大程度上由预测专家的经验和技巧决定,具有较大的主观性,难以指导具体安排;定量预测的方法是话务量预测的热门课题,国内外有诸多研究机构都在积极研究分析话务量预测模型,也取得了阶段性成果,传统的方法包括惯性预测[4 ] 、Kalman滤波[5 -6 ] 、灰色预测[7 -8 ] 等.其中,惯性预测和Kalman滤波相对简单,但难以满足现阶段话务量的复杂变化.
随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性.
在深度学习网络中,CNN在预测任务中具有卓越的特征学习和表示能力,通过多层卷积和池化操作,自动学习数据的高级特征和表示[17 -18 ] .Adaboost算法具有较强的集成学习能力[19 -20 ] ,可通过加权组合多个弱分类器,提高整体模型的准确性,同时在训练过程中采用自适应学习策略,减少过拟合风险,但该算法对噪声和异常值较敏感,且在训练过程中计算复杂度较高.尽管已经提出了一些集成学习方法,但如何更好地将不同模型集成起来,以获得更强大的预测性能仍是亟待解决的问题.通过集成多个CNN模型增加模型的鲁棒性,减少对异常值的敏感性,提高预测准确性,同时通过多模型的组合,集成CNN缓解过拟合问题,提高模型的泛化能力.
为此,本文提出一种基于Adaboost-CNN和增值服务修正的电网短期话务量预测方法.首先,采用孤立森林算法进行异常数据识别,建立拉格朗日插值函数对异常数据或缺失数据进行修补;其次,通过特征分析确定影响话务量变化的因子,将影响因子作为网络输入;然后,构建集成多个CNN网络的Adaboost回归预测模型;最后,考虑供电服务系统增值服务及训练误差的概率分布进行预测值调整,得到最终预测结果.
1 数据预处理
受系统自身精度、传输过程丢失、人工录入失误等主观或客观因素影响,获得的数据通常会在某些字段出现缺失值或异常值,所以对异常数据进行合理的修正有利于提高预测精度.为此,需要对话务量数据进行预处理,包含话务量异常数据识别和异常数据修补两个环节.
1.1 基于孤立森林算法的异常数据识别
孤立森林算法常被用于异常数据识别和检测[21 ] ,算法步骤如下:
从含T 个值的话务量数据集X 中随机选取特征,构成特征空间.在所选取特征的值域内随机选择一个值作为随机分割值,构建多棵孤立树,计算每个数据点的异常得分值,即
(1) s (x , N )= 2 - E ( h ( x ) ) C ( N )
式中:x 为数据点;N 为构建单棵孤立树的训练样本个数;h (x )为路径长度,即分离数据点x 所需要的分割值个数;E (h (x ))为数据点x 在所有孤立树中的路径长度的期望;C (N )为树的平均路径长度,
(2) C (N )=2H (N -1)- 2 ( N - 1 ) N
式中:H ( )为调和函数,且H ( ) ≈ ln( )+0.577 2.
(3) s (x , n )= 2 E ( H ( x ) ) C ( N )
s (x , n )通常取值范围在[0,1]之间,s (x , n )越接近1表示数据点越异常,若s (x , n )大于0.9,即认为该点为异常数据并予以修正,以避免其对预测模型结果产生不良影响.
1.2 基于拉格朗日插值的异常数据修补
拉格朗日插值[22 ] 是一种多项式插值方法,通过已有数据点信息,构建一个多项式函数来估计缺失或异常值.通过已知电网客服话务量数据建立拉格朗日插值函数,利用相邻正常数据拟合多项式来获得近似值进行缺失值补充:
(4) xl →y =a 0 +a 1 x +a 2 x 1 2 n -1 xn -1 →yl
式中:l 为该异常时刻话务量数据x 的时序;y 为拉格朗日插值函数;yl 为该异常时刻的话务数据;n 为数据点.
插值多项式y =a 0 +a 1 x +a 2 x 1 2 an -1 xn -1 构造过程如下:
取异常数据前后共一年的n 个数据点(x 0 , y 0 ), (x 1 , y 1 ), (x 2 , y 2 ), …, (xn -1 , yn -1 ),作n 个n -1次多项式pj (x ),其中
(5) pj (x )= ∏ i = 1 , i ≠ j n - 1 x - x i x j - x i
(6) y' = ∑ j = 0 n - 1 j pj (x)
式中:y' 为修正后的话务量数据,基于拉格朗日插值的异常数据修补可有效恢复缺失或异常值,从而使得数据集更加完整和准确.
2 基于层次分析法的影响因子分析
话务系统的动态因受多种因素影响而呈现非线性变化,全面、系统地分析电网传统业务话务量的影响因素有利于提高话务量预测准确性,为此基于层次分析法[23 ] 进行话务量的影响因子分析.
各因素对话务量的影响程度,根据专家经验初次量化文字信息如表1 所示.其中,有数值的信息不做初步量化处理.
考虑减少各因素对话务量影响程度的主观判断,利用层次分析法在专家经验基础上进一步定性、定量分析,首先构造比较矩阵
(7) $\boldsymbol{A}=\left(a_{u z}\right)_{d \times d}$
式中:auz 为u 因素相对z 因素对话务量影响程度的强弱;d 为量化指标的数量.
其次,进行一致性检验,计算一致性指标和一致性比率如下:
(8) I C = λ - d d - 1
(9) $r_{\mathrm{C}}=I_{\mathrm{C}} / I_{\mathrm{R}}$
式中:λ 为比较矩阵A 的最大特征根;I R 为基准一致性指标. 当r C <0. 1时,则进行下一步,否则对比较矩阵A 进行修正.
最后,对最大特征值所对应的特征向量进行归一化,得到最终量化的信息.通过层次分析法,可系统性地评估不同因素对话务量的重要性.
3 基于Adaboost-CNN的预测模型
3.1 Adaboost回归预测模型
Adaboost回归预测是一种集成学习算法,能处理复杂的非线性关系和噪声数据,在解决回归问题时具有一定优势.假设一个数据集D 由m 个样本组成,D ={(p 1 , q 1 ), (p 2 , q 2 ), …, (pm , qm )},样本数据有d 个特征.Adaboost回归预测算法流程如下.
首先,初始化权重,将每个训练样本的权重初始化为相等值,通常为1/m ,在样本分布Dist(p )和数据集D 的基础上训练弱回归器,计算回归器ht 在训练集的最大误差
(10) Et =max q i - h t ( p i )
其次,根据所求的Et ,计算ht 对每个样本的相对误差,平方误差计算方法如下:
(11) eti =(qi -ht (pi ))2 / E t 2
(12) et = ∑ m i = 1 i (pi )eti
(3) $w_{t}=e_{t} /\left(1-e_{t}\right)$
(14) Distt +1 (pi )= D i s t t ( p i ) Z t w t 1 - e t i
(15) Distt +1 (pi )= D i s t t ( p i ) Z t w t 1 - e t i
若未满足精度要求或达到最大迭代次数则返回至式(11).
(16) H (p )= ∑ m i = 1 1 w t ∑ m i = 1 l n 1 w t
式中:f (p )为wt ht (p )的中位数,即所有弱回归器加权输出结果的中位数.通过选择中位数而非平均值,可提高模型的鲁棒性,使其对异常值和噪声数据更具抵抗力.
3.2 CNN回归预测模型
CNN是一种具有局部连接、权重共享等特性的深层前馈神经网络,一般由卷积层、汇聚层和全连接层交叉堆叠而成,卷积层计算公式如下:
(17) C t l ∑ p ∈ N b C b l - 1 ⊗ w b , t l + b b , t l
式中:C t l l 个卷积层的第t 个特征图;$\otimes$为卷积计算;Nb 为卷积层的特征图集;w b , t l l 层的第b 个特征图与第l 层的第t 个特征图间的权重;b b , t l l 层的第b 个特征图与第l 层的第t 个特征图间的偏置;f ( )为激活函数,一般选择tanh函数.
池化是对前一层输出序列尺寸缩小的过程,按池化方法通常可分为最大池化和平均池化.其中,前者取最大的特征,后者取特征均值,池化层计算方法如下:
(18) C t l β t l C t l - 1 b t l
式中:β t l l 层的第 t 个特征图的权重系数;v ( )为池化函数.
经卷积层和池化层处理后,全连接层对所有输入特征信息进行组合, 全连接层计算方式为
(19) C t l ∑ p ∈ l - 1 w i , t l C b l - 1 + b t l
3.3 计及增值服务的预测结果修正
随着新型电力系统的发展,各种增值业务和新型业务剧增,原始话务数据传统业务话务占据绝大部分,而仅依靠历史话务数据进行预测无法适应现代供电服务中较复杂的增值业务场景,故考虑利用增值服务进行预测结果修正.利用非参数估计的方法得到电网客服增值服务各类型历史话务的概率分布如下:
(20) r (g )= 1 φ ∑ i = 1 φ h (g-gτ )
式中:τ =1, 2, 3, 4, 5, 6分别对应6种类型增值服务,即配电项目运维、应急抢修、三相不平衡治理、分布式光伏安装、电动汽车充电站设施安装和其他增值服务;r (g )为电网客服增值服务历史话务的概率分布函数;gτ 为电网客服第τ 类增值服务历史话务数据;g 为增值服务历史话务的概率分布函数的自变量;φ 为电网客服增值服务历史话务总数量;Kh ( )为高斯核函数,h =0. 5为平滑参数.
(21) O N = ∫ 0 + ∞
(22) $O=O^{\prime}+O_{\mathrm{N}}$
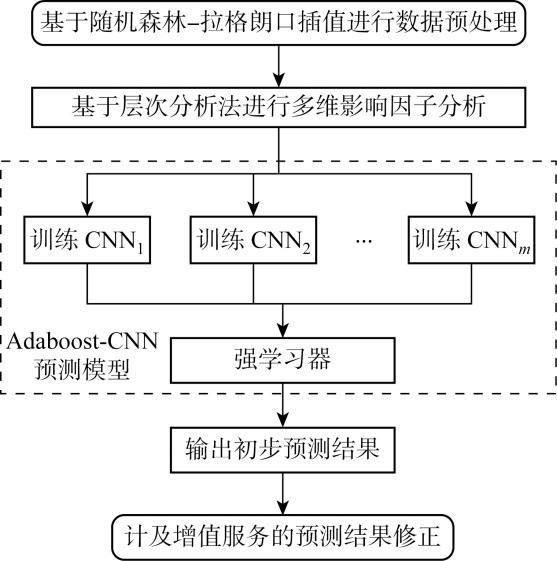
综上所述,得出基于Adaboost-CNN和增值服务修正的电网客服话务量预测方法,其流程如图1 所示.
图1
图1
电网客服话务量预测流程
Fig.1
Traffic prediction process of power grid customer service
4 算例分析
以南方某省的电力客服中心在2022年1月1日至2023年3月7日期间的话务量数据为实例数据集,采样周期为1 h,话务数据共 10 344 条.
4.1 异常数据识别结果
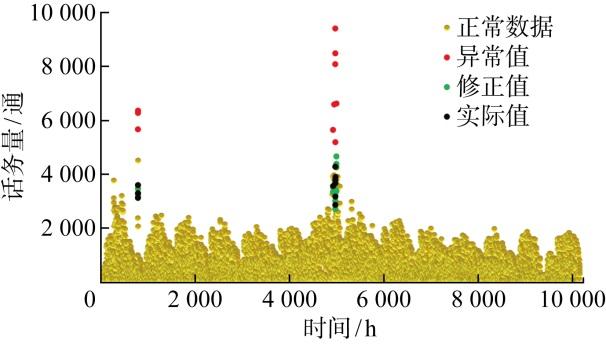
话务系统自动采集的数据不可避免存在异常值,采用所提数据预处理方法对话务量数据进行异常识别及修正,结果如图2 所示,为验证所提数据预处理方法的有效性,将其与传统方法得到的异常数据识别及修正准确率进行对比,如表2 所示.
图2
图2
异常数据识别和修正结果
Fig.2
Recognition results of abnormal data
由上述图表可知,识别出来的异常点明显“离群”,孤立森林算法可有效检测出话务数据中的异常值,且异常数据识别准确率为100%,识别准确率高于其他方法.这是由于该算法通过构建孤立树来划分数据,正常样本通常可以被更早地划分到叶子节点,而异常样本则需要更多的划分才能到达叶子节点,异常数据点往往在孤立树中的路径长度较短,而正常数据点的路径长度较长.孤立森林不依赖于数据的分布假设,可以处理包括复杂数据在内的各种类型的数据分布.
此外,所提异常数据修正的平均准确率最高,修正后的数据与真实值吻合程度较高,能较好地还原真实数据的规律,这是由于拉格朗日插值能捕捉到数据点之间的潜在关联,在修正异常数据时具有较高的精度.
4.2 话务量影响因子分析
根据第2节所提话务量影响因子分析方法,选取7个参数进行分析,结果如表3 所示.由表可知,最高温、雷电、停电事件和节假日对电网客服话务有着重要影响.夏季最高温度对负荷增大和故障增多具有重要影响;雷电天气易引发电力设备故障、线路短路或电力中断等问题;停电事件本身会直接导致人们对电网客服的联系和咨询; 节假日会导致用电负荷向商业区居民区转移. 这些因素都与话务的变化有着直接或间接的影响,将其作为模型的输入有利于提高对电网客服话务量的预测精度.
4.3 预测结果分析
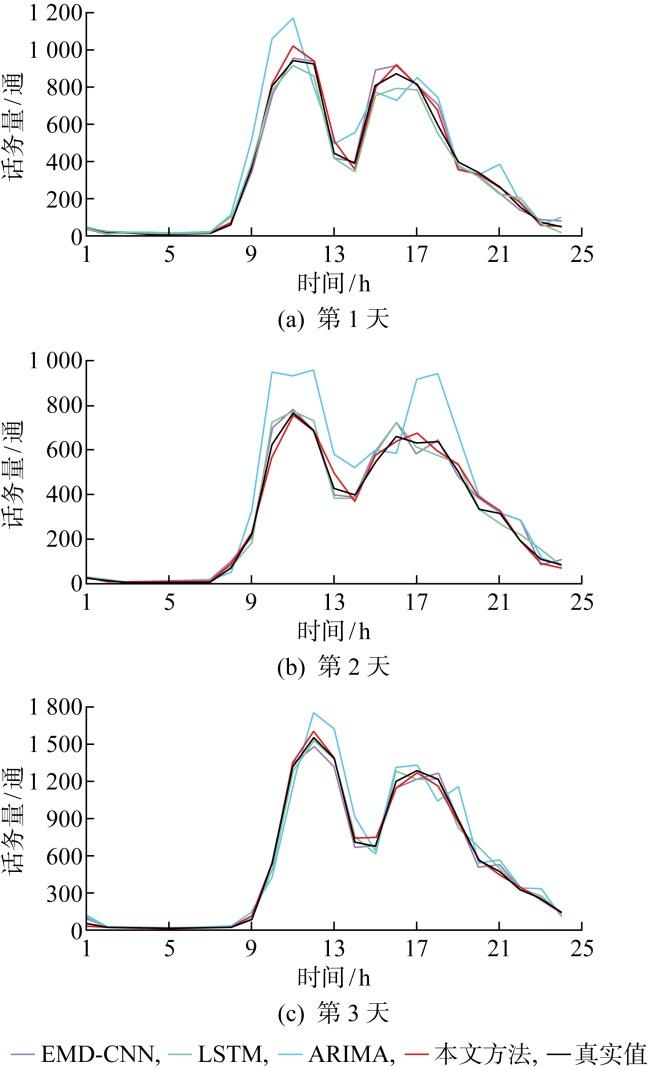
为验证所提预测方法的有效性和优越性,以2022年1月1日至2023年2月28日的话务数据为训练集,3月1日至3月7日的话务数据为测试集,将经验模态分解(empirical mode decomposition, EMD)-CNN、整合移动平均自回归模型(autoregressive integrated moving average model,ARIMA)、LSTM(回归)3种方法与所提方法进行对比.本算例使用的CNN网络参数为2个卷积层、2个池化层和1个全连接层,2个卷积层的卷积核大小为 2×2,卷积核个数分别为8、16个;2个池化层的池化窗口大小均为2×2,步长为2;全连接层的神经元个数为120.LSTM参数为:网络层数为3,隐含层节点个数为10.预测结果对比如图3 所示,预测误差对比如表4 所示,表中e MAE 和e MAPE 分别为平均绝对误差和平均绝对百分误差.
图3
图3
连续3 d预测结果对比
Fig.3
Comparison of prediction results for three days
由表4 和图3 可知,所提预测方法相较其他模型具有更高的预测准确率.在单一神经网络中,LSTM和CNN具有较高的识预测准确率,平均预测准确率超过80%,这是由于LSTM和CNN为深度学习网络,网络的特征提取能力较浅层神经网络更强;组合预测模型的预测准确率优于单一模型,单一模型对特定类型的数据或情况更敏感,而组合模型因能平衡不同模型的优势和劣势而提高鲁棒性.集成学习能通过组合多个学习器的预测结果,减少单个学习器的错误和偏差.集成学习的结果通常比单个学习器更准确,特别是在面对复杂问题和大规模数据时,通过集成CNN构建Adaboost可以保留两者的优点进一步提高网络的学习能力和鲁棒性,同时,通过话务影响因子的分析,可避免无关信息对神经网络的干扰,从而提升预测准确率.
5 结论
提出一种基于Adaboost-CNN和增值服务修正的电网短期话务量预测模型,通过实例分析,验证该方法的有效性和优越性,并得出以下结论:
(1) 提出孤立森林算法-拉格朗日插值进行数据预处理,能有效识别异常数据并进行修正.
(2) 采用层次分析法对话务量影响因子进行分析,为电网话务量的准确预测提供可靠的因子输入.
(3) 通过集成多个CNN构建Adaboost模型,克服传统集成学习方法学习深度浅的问题,可以综合利用其优势,提高预测的准确性、鲁棒性和泛化能力.
参考文献
View Option
[1]
谭刚 , 陈聿 , 彭云竹 . 融合领域特征知识图谱的电网客服问答系统
[J]. 计算机工程与应用 2020 , 56 (3 ): 232 -239 .
DOI:10.3778/j.issn.1002-8331.1907-0385
[本文引用: 1]
知识图谱(KG)是实现领域问答系统的关键技术之一,能够降低客服成本,推进客户自助服务的智能化,具有较大的商用价值和研究意义。针对基于KG问答系统中存在的中文问题表达模糊、线上服务运维成本高的问题,融合领域特征知识图谱的电网客服问答系统(HDKG-QA),其能基于LSTM模型识别实体/断言,基于主题比较的语义增强方法准确寻找外部知识,使用启发式规则优化答案候选集,并定期根据ILP求解器设置全局KG的更新策略。HDKG-QA能够达到较高的实体/断言识别准确率,自动将领域知识映射为本地KG,快速实现服务知识库的在线更新,达到以较低的响应延迟实现高准确率的回答。根据国网重庆市电力公司信息通信分公司的实际客服问答数据集对本系统进行验证,实验结果表明通过引入LSTM和语义增强方法,问答系统的准确率提高了17%;基于启发式规则的优化答案排序策略将准确率提高了8%;通过引入ILP求解器,在保障同样准确率的情况下,问答响应延迟降低了9%。
TAN Gang CHEN Yu PENG Yunzhu Hybrid domain feature knowledge graph smart question answering system
[J]. Computer Engineering and Applications 2020 , 56 (3 ): 232 -239 .
DOI:10.3778/j.issn.1002-8331.1907-0385
[本文引用: 1]
Knowledge Graph(KG) is one of the key technologies for implementing an intelligent Question Answering system(QA). It can reduce customer service costs and enhance their self-service capabilities. It has a lot of commercial values and research meanings. To reduce the fuzzy of Chinese language questions and the high cost of online service operation and maintenance in a KG based QA, a smart grid customer service Question Answering system(HDKG-QA) is proposed. It is based on the hybrid domain feature of KG. It first identifies the entity based on a LSTM model. Then it proposes a semantic enhancement method based on the topic comparison to accurately find the external knowledge. It uses heuristic rules to get the optimal answer. Periodically, it updates the global KG according to the result of ILP solver. HDKG-QA can achieve high entity/predication recognition accuracy. It automatically maps domain knowledge to the local KG, and updates online KG. It can achieve high quality response with low response delay. The system is verified by the actual Q&A dataset in the State Grid Chongqing Electric Power Corporation, the experimental results show that the accuracy of the QA is improved by 17%. Through introducing LSTM and semantic enhancement methods, the heuristic rules and the sorting strategy can increase the accuracy by 8%. The Q&A response latency can be reduced by 9% with the same accuracy by introducing the ILP solver.
[2]
李玮 , 李树国 , 喻玮 . 基于停电事件分析的区域性话务峰涌预测
[J]. 自动化技术与应用 2024 , 43 (4 ): 9 -13 .
[本文引用: 1]
LI Wei LI Shuguo YU Wei Prediction of regional traffic rush based on blackout event analysis
[J]. Techniques of Automation and Applications 2024 , 43 (4 ): 9 -13 .
[本文引用: 1]
[3]
彭渤 . 呼叫中心排班优化研究—以电力公司呼叫中心为例 [D]. 天津 : 天津大学 , 2020 .
[本文引用: 1]
PENG Bo Study on scheduling optimization of call center—Take the call center of Power Company as an example [D]. Tianjin : Tianjin University , 2020 .
[本文引用: 1]
[4]
XIAO X P DUAN H M WEN J H A novel car-following inertia gray model and its application in forecasting short-term traffic flow
[J]. Applied Mathematical Modelling 2020 , 87 : 546 -570 .
[本文引用: 1]
[5]
孙同川 , 王振岭 , 孙建设 , 等 . 基于Kalman滤波的原子时算法研究
[J]. 计算机测量与控制 2023 , 31 (3 ): 294 -299 .
[本文引用: 1]
SUN Tongchuan WANG Zhenling SUN Jianshe et al Research on atomic time algorithm based on Kalman filter
[J]. Computer Measurement & Control 2023 , 31 (3 ): 294 -299 .
[本文引用: 1]
[6]
SONG Y WANG H R Real-time adjustment way of reservoir schedule forecasting projects based on improved variable oblivion factor least square arithmetic coupling Kalman filters
[J]. Energy Reports 2022 , 8 : 555 -562 .
[本文引用: 1]
[7]
秦艳辉 , 马晓磊 , 吴鑫 , 等 . 基于灰色滚动预测模型的多接口变换器功率直接控制方法
[J]. 工业仪表与自动化装置 2023 (1 ): 62 -66 .
[本文引用: 1]
QIN Yanhui MA Xiaolei WU Xin et al Direct power control method of multi interface converter based on grey rolling prediction model
[J]. Industrial Instrumentation & Automation 2023 (1 ): 62 -66 .
[本文引用: 1]
[8]
LI Y BAI X LIU B Forecasting clean energy generation volume in China with a novel fractional Time-Delay polynomial discrete grey model
[J]. Energy and Buildings 2022 , 271 : 112305 .
[本文引用: 1]
[9]
万安平 , 杨洁 , 缪徐 , 等 . 基于注意力机制与神经网络的热电联产锅炉负荷预测
[J]. 上海交通大学学报 2023 , 57 (3 ): 316 -325 .
DOI:10.16183/j.cnki.jsjtu.2021.346
[本文引用: 1]
热电联产机组的锅炉负荷准确预测对电厂生产管理及调度有直接作用.基于注意力机制和深度卷积-长短期记忆网络原理,提出一种新的热电联产长期负荷预测模型,该模型以锅炉出口蒸汽流量(负荷)历史数据和多维负荷影响因素为输入,对负荷进行长期预测.利用Pearson相关系数判定对原始数据进行筛选;将处理后的数据经卷积层进行特征提取和进一步降维,通过长短期记忆层进行拟合,并采取注意力机制对权值进行优化,实现对负荷的精准预测.以浙江桐乡电厂实测数据为例进行验证,结果表明所提方法的平均绝对百分比误差小于1%,能够实现锅炉负荷的精准预测,智能算法在热电联产领域的应用具有一定的借鉴意义.
WAN Anping YANG Jie MIAO Xu et al Boiler load forecasting of CHP plant based on attention mechanism and deep neural network
[J]. Journal of Shanghai Jiao Tong University 2023 , 57 (3 ): 316 -325 .
[本文引用: 1]
[10]
HAN R JIA Z H QIN X Z et al Application of support vector machine to mobile communications in telephone traffic load of monthly busy hour prediction
[C]// 2009 Fifth International Conference on Natural Computation Tianjian,China : IEEE , 2009 : 349 -353 .
[本文引用: 1]
[11]
赵龙 , 周源 , 李飞 , 等 . 基于XGBoost算法的坐席话务量预测
[J]. 现代信息科技 2021 , 5 (22 ): 86 -88 .
[本文引用: 1]
ZHAO Long ZHOU Yuan LI Fei et al Call center seat telephone-traffic volume prediction based on XGBoost algorithm
[J]. Modern Information Technology 2021 , 5 (22 ): 86 -88 .
[本文引用: 1]
[12]
JALAL M E HOSSEINI M KARLSSON S Forecasting incoming call volumes in call centers with recurrent Neural Networks
[J]. Journal of Business Research 2016 , 69 (11 ): 4811 -4814 .
[本文引用: 1]
[13]
黄雪婷 . 基于SARIMA和CNN-LSTM组合模型的呼叫中心日话务量预测研究 [D]. 南京 : 南京邮电大学 , 2022 .
[本文引用: 1]
HUANG Xueting Research on call center daily traffic prediction based on SARIMA and CNN-LSTM combination model [D]. Nanjing : Nanjing University of Posts and Telecommunications , 2022 .
[本文引用: 1]
[14]
林珊 , 王红 , 齐林海 , 等 . 基于条件生成对抗网络的短期负荷预测
[J]. 电力系统自动化 2021 , 45 (11 ): 52 -60 .
[本文引用: 1]
LIN Shan WANG Hong QI Linhai et al Short-term load forecasting based on conditional generative adversarial network
[J]. Automation of Electric Power Systems 2021 , 45 (11 ): 52 -60 .
[本文引用: 1]
[15]
谢小瑜 , 周俊煌 , 张勇军 , 等 . 基于W-BiLSTM的可再生能源超短期发电功率预测方法
[J]. 电力系统自动化 2021 , 45 (8 ): 175 -184 .
[本文引用: 1]
XIE Xiaoyu ZHOU Junhuang ZHANG Yongjun et al W-BiLSTM based ultra-short-term generation power prediction method of renewable energy
[J]. Automation of Electric Power Systems 2021 , 45 (8 ): 175 -184 .
[本文引用: 1]
[16]
龙干 , 黄媚 , 方力谦 , 等 . 基于改进多元宇宙算法优化ELM的短期电力负荷预测
[J]. 电力系统保护与控制 2022 , 50 (19 ): 99 -106 .
[本文引用: 1]
LONG Gan HUANG Mei FANG Liqian et al Short-term power load forecasting based on an improved multi-verse optimizer algorithm optimized extreme learning machine
[J]. Power System Protection and Control 2022 , 50 (19 ): 99 -106 .
[本文引用: 1]
[17]
曾国治 , 魏子清 , 岳宝 , 等 . 基于CNN-RNN组合模型的办公建筑能耗预测
[J]. 上海交通大学学报 2022 , 56 (9 ): 1256 -1261 .
DOI:10.16183/j.cnki.jsjtu.2021.192
[本文引用: 1]
为准确反映办公建筑的运行特性,利用卷积神经网络(CNN)良好的特征提取能力与循环神经网络(RNN)良好的时序学习能力,提出用于预测办公建筑能耗的CNN-RNN组合模型,并对应设计了适用于深度学习模型的二维矩阵数据输入结构.案例分析结果表明,相较于简单循环神经网络和长短期记忆网络,CNN-RNN组合模型的预测精度与计算效率均显著提升,模型泛化性好.
ZENG Guozhi WEI Ziqing YUE Bao et al Energy consumption prediction of office buildings based on CNN-RNN combined model
[J]. Journal of Shanghai Jiao Tong University 2022 , 56 (9 ): 1256 -1261 .
[本文引用: 1]
[18]
WANG Q BU S Q HE Z Y et al Toward the prediction level of situation awareness for electric power systems using CNN-LSTM network
[J]. IEEE Transactions on Industrial Informatics 2021 , 17 (10 ): 6951 -6961 .
[本文引用: 1]
[19]
朱吉然 , 张帝 , 张志丹 , 等 . 基于AHP和BP-Adaboost 的低压电力用户价值评价方法
[J]. 电力科学与技术学报 2022 , 37 (5 ): 155 -163 .
[本文引用: 1]
ZHU Jiran ZHANG Di ZHANG Zhidan et al A value evaluation method of power user based on AHP and BP-Adaboost algorithms
[J]. Journal of Electric Power Science and Technology 2022 , 37 (5 ): 155 -163 .
[本文引用: 1]
[20]
游文霞 , 申坤 , 杨楠 , 等 . 基于AdaBoost集成学习的窃电检测研究
[J]. 电力系统保护与控制 2020 , 48 (19 ): 151 -159 .
[本文引用: 1]
YOU Wenxia SHEN Kun YANG Nan et al Research on electricity theft detection based on AdaBoost ensemble learning
[J]. Power System Protection and Control 2020 , 48 (19 ): 151 -159 .
[本文引用: 1]
[21]
李国成 , 陆俊 , 王赟 , 等 . 基于Bagging二次加权集成的孤立森林窃电检测算法
[J]. 电力系统自动化 2022 , 46 (2 ): 92 -100 .
[本文引用: 1]
LI Guocheng LU Jun WANG Yun et al Isolated-forest electricity theft detection algorithm based on Bagging secondary weighted ensemble
[J]. Automation of Electric Power Systems 2022 , 46 (2 ): 92 -100 .
[本文引用: 1]
[22]
杨少瑜 , 黄国栋 , 林星宇 , 等 . 基于拉格朗日插值法的概率建模方法及其在概率潮流分析中的应用
[J]. 现代电力 2021 , 38 (4 ): 378 -385 .
[本文引用: 1]
YANG Shaoyu HUANG Guodong LIN Xingyu et al A Lagrange interpolation based probabilistic modeling method and its application in probabilistic power flow analysis
[J]. Modern Electric Power 2021 , 38 (4 ): 378 -385 .
[本文引用: 1]
[23]
马莉 , 陈应雨 , 田钉荣 , 等 . 基于改进层次分析法的多级电压暂降严重程度评估
[J]. 电力系统保护与控制 2023 , 51 (17 ): 49 -57 .
[本文引用: 1]
MA Li CHEN Yingyu TIAN Dingrong et al Severity evaluation of multistage voltage sag based on an improved analytic hierarchy process
[J]. Power System Protection and Control 2023 , 51 (17 ): 49 -57 .
[本文引用: 1]
融合领域特征知识图谱的电网客服问答系统
1
2020
... 为确保用电服务质量,及时解决用户用电诉求,电力客服中心的规模不断壮大,作为电力企业与客户沟通的重要桥梁,发挥着越来越重要的作用[1 ] .话务量表示单位时间发生呼叫的次数,与用户数量、用户通信的频繁程度相关.目前,电力客服中心话务量预测管理应用主要依靠历史经验,因无法适应现代供电服务体系下复杂的服务场景,造成话务服务人力资源利用不合理.精准的话务量预测作为电力客户服务工作的基础和前提,引起了行业和学术界越来越多的关注[2 -3 ] . ...
Hybrid domain feature knowledge graph smart question answering system
1
2020
... 为确保用电服务质量,及时解决用户用电诉求,电力客服中心的规模不断壮大,作为电力企业与客户沟通的重要桥梁,发挥着越来越重要的作用[1 ] .话务量表示单位时间发生呼叫的次数,与用户数量、用户通信的频繁程度相关.目前,电力客服中心话务量预测管理应用主要依靠历史经验,因无法适应现代供电服务体系下复杂的服务场景,造成话务服务人力资源利用不合理.精准的话务量预测作为电力客户服务工作的基础和前提,引起了行业和学术界越来越多的关注[2 -3 ] . ...
基于停电事件分析的区域性话务峰涌预测
1
2024
... 为确保用电服务质量,及时解决用户用电诉求,电力客服中心的规模不断壮大,作为电力企业与客户沟通的重要桥梁,发挥着越来越重要的作用[1 ] .话务量表示单位时间发生呼叫的次数,与用户数量、用户通信的频繁程度相关.目前,电力客服中心话务量预测管理应用主要依靠历史经验,因无法适应现代供电服务体系下复杂的服务场景,造成话务服务人力资源利用不合理.精准的话务量预测作为电力客户服务工作的基础和前提,引起了行业和学术界越来越多的关注[2 -3 ] . ...
Prediction of regional traffic rush based on blackout event analysis
1
2024
... 为确保用电服务质量,及时解决用户用电诉求,电力客服中心的规模不断壮大,作为电力企业与客户沟通的重要桥梁,发挥着越来越重要的作用[1 ] .话务量表示单位时间发生呼叫的次数,与用户数量、用户通信的频繁程度相关.目前,电力客服中心话务量预测管理应用主要依靠历史经验,因无法适应现代供电服务体系下复杂的服务场景,造成话务服务人力资源利用不合理.精准的话务量预测作为电力客户服务工作的基础和前提,引起了行业和学术界越来越多的关注[2 -3 ] . ...
1
2020
... 为确保用电服务质量,及时解决用户用电诉求,电力客服中心的规模不断壮大,作为电力企业与客户沟通的重要桥梁,发挥着越来越重要的作用[1 ] .话务量表示单位时间发生呼叫的次数,与用户数量、用户通信的频繁程度相关.目前,电力客服中心话务量预测管理应用主要依靠历史经验,因无法适应现代供电服务体系下复杂的服务场景,造成话务服务人力资源利用不合理.精准的话务量预测作为电力客户服务工作的基础和前提,引起了行业和学术界越来越多的关注[2 -3 ] . ...
1
2020
... 为确保用电服务质量,及时解决用户用电诉求,电力客服中心的规模不断壮大,作为电力企业与客户沟通的重要桥梁,发挥着越来越重要的作用[1 ] .话务量表示单位时间发生呼叫的次数,与用户数量、用户通信的频繁程度相关.目前,电力客服中心话务量预测管理应用主要依靠历史经验,因无法适应现代供电服务体系下复杂的服务场景,造成话务服务人力资源利用不合理.精准的话务量预测作为电力客户服务工作的基础和前提,引起了行业和学术界越来越多的关注[2 -3 ] . ...
A novel car-following inertia gray model and its application in forecasting short-term traffic flow
1
2020
... 定性与定量预测是话务量预测研究领域的两大主要分类.定性预测的方法通常指直观判断法或专家评估法,该方法的预测精度在很大程度上由预测专家的经验和技巧决定,具有较大的主观性,难以指导具体安排;定量预测的方法是话务量预测的热门课题,国内外有诸多研究机构都在积极研究分析话务量预测模型,也取得了阶段性成果,传统的方法包括惯性预测[4 ] 、Kalman滤波[5 -6 ] 、灰色预测[7 -8 ] 等.其中,惯性预测和Kalman滤波相对简单,但难以满足现阶段话务量的复杂变化. ...
基于Kalman滤波的原子时算法研究
1
2023
... 定性与定量预测是话务量预测研究领域的两大主要分类.定性预测的方法通常指直观判断法或专家评估法,该方法的预测精度在很大程度上由预测专家的经验和技巧决定,具有较大的主观性,难以指导具体安排;定量预测的方法是话务量预测的热门课题,国内外有诸多研究机构都在积极研究分析话务量预测模型,也取得了阶段性成果,传统的方法包括惯性预测[4 ] 、Kalman滤波[5 -6 ] 、灰色预测[7 -8 ] 等.其中,惯性预测和Kalman滤波相对简单,但难以满足现阶段话务量的复杂变化. ...
Research on atomic time algorithm based on Kalman filter
1
2023
... 定性与定量预测是话务量预测研究领域的两大主要分类.定性预测的方法通常指直观判断法或专家评估法,该方法的预测精度在很大程度上由预测专家的经验和技巧决定,具有较大的主观性,难以指导具体安排;定量预测的方法是话务量预测的热门课题,国内外有诸多研究机构都在积极研究分析话务量预测模型,也取得了阶段性成果,传统的方法包括惯性预测[4 ] 、Kalman滤波[5 -6 ] 、灰色预测[7 -8 ] 等.其中,惯性预测和Kalman滤波相对简单,但难以满足现阶段话务量的复杂变化. ...
Real-time adjustment way of reservoir schedule forecasting projects based on improved variable oblivion factor least square arithmetic coupling Kalman filters
1
2022
... 定性与定量预测是话务量预测研究领域的两大主要分类.定性预测的方法通常指直观判断法或专家评估法,该方法的预测精度在很大程度上由预测专家的经验和技巧决定,具有较大的主观性,难以指导具体安排;定量预测的方法是话务量预测的热门课题,国内外有诸多研究机构都在积极研究分析话务量预测模型,也取得了阶段性成果,传统的方法包括惯性预测[4 ] 、Kalman滤波[5 -6 ] 、灰色预测[7 -8 ] 等.其中,惯性预测和Kalman滤波相对简单,但难以满足现阶段话务量的复杂变化. ...
基于灰色滚动预测模型的多接口变换器功率直接控制方法
1
2023
... 定性与定量预测是话务量预测研究领域的两大主要分类.定性预测的方法通常指直观判断法或专家评估法,该方法的预测精度在很大程度上由预测专家的经验和技巧决定,具有较大的主观性,难以指导具体安排;定量预测的方法是话务量预测的热门课题,国内外有诸多研究机构都在积极研究分析话务量预测模型,也取得了阶段性成果,传统的方法包括惯性预测[4 ] 、Kalman滤波[5 -6 ] 、灰色预测[7 -8 ] 等.其中,惯性预测和Kalman滤波相对简单,但难以满足现阶段话务量的复杂变化. ...
Direct power control method of multi interface converter based on grey rolling prediction model
1
2023
... 定性与定量预测是话务量预测研究领域的两大主要分类.定性预测的方法通常指直观判断法或专家评估法,该方法的预测精度在很大程度上由预测专家的经验和技巧决定,具有较大的主观性,难以指导具体安排;定量预测的方法是话务量预测的热门课题,国内外有诸多研究机构都在积极研究分析话务量预测模型,也取得了阶段性成果,传统的方法包括惯性预测[4 ] 、Kalman滤波[5 -6 ] 、灰色预测[7 -8 ] 等.其中,惯性预测和Kalman滤波相对简单,但难以满足现阶段话务量的复杂变化. ...
Forecasting clean energy generation volume in China with a novel fractional Time-Delay polynomial discrete grey model
1
2022
... 定性与定量预测是话务量预测研究领域的两大主要分类.定性预测的方法通常指直观判断法或专家评估法,该方法的预测精度在很大程度上由预测专家的经验和技巧决定,具有较大的主观性,难以指导具体安排;定量预测的方法是话务量预测的热门课题,国内外有诸多研究机构都在积极研究分析话务量预测模型,也取得了阶段性成果,传统的方法包括惯性预测[4 ] 、Kalman滤波[5 -6 ] 、灰色预测[7 -8 ] 等.其中,惯性预测和Kalman滤波相对简单,但难以满足现阶段话务量的复杂变化. ...
基于注意力机制与神经网络的热电联产锅炉负荷预测
1
2023
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
Boiler load forecasting of CHP plant based on attention mechanism and deep neural network
1
2023
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
Application of support vector machine to mobile communications in telephone traffic load of monthly busy hour prediction
1
2009
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
基于XGBoost算法的坐席话务量预测
1
2021
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
Call center seat telephone-traffic volume prediction based on XGBoost algorithm
1
2021
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
Forecasting incoming call volumes in call centers with recurrent Neural Networks
1
2016
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
1
2022
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
1
2022
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
基于条件生成对抗网络的短期负荷预测
1
2021
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
Short-term load forecasting based on conditional generative adversarial network
1
2021
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
基于W-BiLSTM的可再生能源超短期发电功率预测方法
1
2021
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
W-BiLSTM based ultra-short-term generation power prediction method of renewable energy
1
2021
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
基于改进多元宇宙算法优化ELM的短期电力负荷预测
1
2022
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
Short-term power load forecasting based on an improved multi-verse optimizer algorithm optimized extreme learning machine
1
2022
... 随着科学技术的发展,机器学习广泛应用于预测领域,且取得了较好的预测效果[9 ] .该类预测模型通过经验或数据来改进算法的研究,旨在通过算法让机器从大量历史数据中学习规律, 自动发现模式并用于预测.Han等[10 ] 将反向传播神经网络(back propagation neural network,BPNN)应用于电力呼叫中心话务量预测,结果表明对于未来较长一段时间内的话务量,BPNN的预测效果优于指数平滑法;赵龙等[11 ] 提出一种基于极端梯度提升算法(eXtreme gradient boosting, XGBoost)的坐席话务量预测方法;Jalal等[12 ] 构建了一个3层的循环神经网络,对伊朗某呼叫中心 15 min时段话务量进行预测,取得了较好的预测效果;黄雪婷[13 ] 提出基于自回归差分移动平均模型和卷积神经网络(convolutional neural network, CNN)-长短期记忆(long short-term memory, LSTM)网络组合模型的呼叫中心日话务量预测方法,该方法能显著提升整个预测周期内的预测准确性和稳定性.在预测模型上,近来研究偏向于采用深度学习等智能算法,如条件生成对抗网络[14 ] 、LSTM[15 ] 、极限学习机(extreme learning machine, ELM)[16 ] 及上述算法的组合形式等.一方面,以上方法缺乏精细化的预测步骤,无法有效捕捉电网客户服务话务量的复杂模式和变化趋势;另一方面,电网客户服务话务量受到用户行为、气象条件、节假日等诸多因素影响,现有方法可能无法充分考虑这些因素之间的复杂关系,从而影响了预测模型的全面性和准确性. ...
基于CNN-RNN组合模型的办公建筑能耗预测
1
2022
... 在深度学习网络中,CNN在预测任务中具有卓越的特征学习和表示能力,通过多层卷积和池化操作,自动学习数据的高级特征和表示[17 -18 ] .Adaboost算法具有较强的集成学习能力[19 -20 ] ,可通过加权组合多个弱分类器,提高整体模型的准确性,同时在训练过程中采用自适应学习策略,减少过拟合风险,但该算法对噪声和异常值较敏感,且在训练过程中计算复杂度较高.尽管已经提出了一些集成学习方法,但如何更好地将不同模型集成起来,以获得更强大的预测性能仍是亟待解决的问题.通过集成多个CNN模型增加模型的鲁棒性,减少对异常值的敏感性,提高预测准确性,同时通过多模型的组合,集成CNN缓解过拟合问题,提高模型的泛化能力. ...
Energy consumption prediction of office buildings based on CNN-RNN combined model
1
2022
... 在深度学习网络中,CNN在预测任务中具有卓越的特征学习和表示能力,通过多层卷积和池化操作,自动学习数据的高级特征和表示[17 -18 ] .Adaboost算法具有较强的集成学习能力[19 -20 ] ,可通过加权组合多个弱分类器,提高整体模型的准确性,同时在训练过程中采用自适应学习策略,减少过拟合风险,但该算法对噪声和异常值较敏感,且在训练过程中计算复杂度较高.尽管已经提出了一些集成学习方法,但如何更好地将不同模型集成起来,以获得更强大的预测性能仍是亟待解决的问题.通过集成多个CNN模型增加模型的鲁棒性,减少对异常值的敏感性,提高预测准确性,同时通过多模型的组合,集成CNN缓解过拟合问题,提高模型的泛化能力. ...
Toward the prediction level of situation awareness for electric power systems using CNN-LSTM network
1
2021
... 在深度学习网络中,CNN在预测任务中具有卓越的特征学习和表示能力,通过多层卷积和池化操作,自动学习数据的高级特征和表示[17 -18 ] .Adaboost算法具有较强的集成学习能力[19 -20 ] ,可通过加权组合多个弱分类器,提高整体模型的准确性,同时在训练过程中采用自适应学习策略,减少过拟合风险,但该算法对噪声和异常值较敏感,且在训练过程中计算复杂度较高.尽管已经提出了一些集成学习方法,但如何更好地将不同模型集成起来,以获得更强大的预测性能仍是亟待解决的问题.通过集成多个CNN模型增加模型的鲁棒性,减少对异常值的敏感性,提高预测准确性,同时通过多模型的组合,集成CNN缓解过拟合问题,提高模型的泛化能力. ...
基于AHP和BP-Adaboost 的低压电力用户价值评价方法
1
2022
... 在深度学习网络中,CNN在预测任务中具有卓越的特征学习和表示能力,通过多层卷积和池化操作,自动学习数据的高级特征和表示[17 -18 ] .Adaboost算法具有较强的集成学习能力[19 -20 ] ,可通过加权组合多个弱分类器,提高整体模型的准确性,同时在训练过程中采用自适应学习策略,减少过拟合风险,但该算法对噪声和异常值较敏感,且在训练过程中计算复杂度较高.尽管已经提出了一些集成学习方法,但如何更好地将不同模型集成起来,以获得更强大的预测性能仍是亟待解决的问题.通过集成多个CNN模型增加模型的鲁棒性,减少对异常值的敏感性,提高预测准确性,同时通过多模型的组合,集成CNN缓解过拟合问题,提高模型的泛化能力. ...
A value evaluation method of power user based on AHP and BP-Adaboost algorithms
1
2022
... 在深度学习网络中,CNN在预测任务中具有卓越的特征学习和表示能力,通过多层卷积和池化操作,自动学习数据的高级特征和表示[17 -18 ] .Adaboost算法具有较强的集成学习能力[19 -20 ] ,可通过加权组合多个弱分类器,提高整体模型的准确性,同时在训练过程中采用自适应学习策略,减少过拟合风险,但该算法对噪声和异常值较敏感,且在训练过程中计算复杂度较高.尽管已经提出了一些集成学习方法,但如何更好地将不同模型集成起来,以获得更强大的预测性能仍是亟待解决的问题.通过集成多个CNN模型增加模型的鲁棒性,减少对异常值的敏感性,提高预测准确性,同时通过多模型的组合,集成CNN缓解过拟合问题,提高模型的泛化能力. ...
基于AdaBoost集成学习的窃电检测研究
1
2020
... 在深度学习网络中,CNN在预测任务中具有卓越的特征学习和表示能力,通过多层卷积和池化操作,自动学习数据的高级特征和表示[17 -18 ] .Adaboost算法具有较强的集成学习能力[19 -20 ] ,可通过加权组合多个弱分类器,提高整体模型的准确性,同时在训练过程中采用自适应学习策略,减少过拟合风险,但该算法对噪声和异常值较敏感,且在训练过程中计算复杂度较高.尽管已经提出了一些集成学习方法,但如何更好地将不同模型集成起来,以获得更强大的预测性能仍是亟待解决的问题.通过集成多个CNN模型增加模型的鲁棒性,减少对异常值的敏感性,提高预测准确性,同时通过多模型的组合,集成CNN缓解过拟合问题,提高模型的泛化能力. ...
Research on electricity theft detection based on AdaBoost ensemble learning
1
2020
... 在深度学习网络中,CNN在预测任务中具有卓越的特征学习和表示能力,通过多层卷积和池化操作,自动学习数据的高级特征和表示[17 -18 ] .Adaboost算法具有较强的集成学习能力[19 -20 ] ,可通过加权组合多个弱分类器,提高整体模型的准确性,同时在训练过程中采用自适应学习策略,减少过拟合风险,但该算法对噪声和异常值较敏感,且在训练过程中计算复杂度较高.尽管已经提出了一些集成学习方法,但如何更好地将不同模型集成起来,以获得更强大的预测性能仍是亟待解决的问题.通过集成多个CNN模型增加模型的鲁棒性,减少对异常值的敏感性,提高预测准确性,同时通过多模型的组合,集成CNN缓解过拟合问题,提高模型的泛化能力. ...
基于Bagging二次加权集成的孤立森林窃电检测算法
1
2022
... 孤立森林算法常被用于异常数据识别和检测[21 ] ,算法步骤如下: ...
Isolated-forest electricity theft detection algorithm based on Bagging secondary weighted ensemble
1
2022
... 孤立森林算法常被用于异常数据识别和检测[21 ] ,算法步骤如下: ...
基于拉格朗日插值法的概率建模方法及其在概率潮流分析中的应用
1
2021
... 拉格朗日插值[22 ] 是一种多项式插值方法,通过已有数据点信息,构建一个多项式函数来估计缺失或异常值.通过已知电网客服话务量数据建立拉格朗日插值函数,利用相邻正常数据拟合多项式来获得近似值进行缺失值补充: ...
A Lagrange interpolation based probabilistic modeling method and its application in probabilistic power flow analysis
1
2021
... 拉格朗日插值[22 ] 是一种多项式插值方法,通过已有数据点信息,构建一个多项式函数来估计缺失或异常值.通过已知电网客服话务量数据建立拉格朗日插值函数,利用相邻正常数据拟合多项式来获得近似值进行缺失值补充: ...
基于改进层次分析法的多级电压暂降严重程度评估
1
2023
... 话务系统的动态因受多种因素影响而呈现非线性变化,全面、系统地分析电网传统业务话务量的影响因素有利于提高话务量预测准确性,为此基于层次分析法[23 ] 进行话务量的影响因子分析. ...
Severity evaluation of multistage voltage sag based on an improved analytic hierarchy process
1
2023
... 话务系统的动态因受多种因素影响而呈现非线性变化,全面、系统地分析电网传统业务话务量的影响因素有利于提高话务量预测准确性,为此基于层次分析法[23 ] 进行话务量的影响因子分析. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}