多飞行器协同编队在军用与民用领域均具有广泛应用,近年来受到较多关注[1 -2 ] .飞行器编队控制的主要目标是令多架飞行器在飞行过程中满足一定的相对位置约束.针对多飞行器编队控制,国内外诸多学者已开展了较为深入的研究.
一致性是指多智能体系统(multi-agent system, MAS)就某一行为达成一致的现象,一致性理论是编队控制重要的理论基础.基于一致性理论的编队控制律中,“领导-跟随”架构通过“领导者”决定编队整体的运动轨迹,而控制“跟随者”按照期望队形跟随“领导者”运动,是一种较为典型的编队控制架构.一些文献通过构造关于空间位置的一致性误差,并在误差中引入期望队形中“跟随者”与“领导者”之间的相对位置信息,达到基于一致性控制的编队控制[3 ] .文献[4 ]中针对多无人机系统构造了引入期望相对位置的一致性误差,给出一种滑模控制律,通过使一致性误差收敛实现了编队控制.文献[5 ]中综合考虑多无人机编队控制与避碰问题,在位置一致性控制律中通过引入辅助变量保证各无人机间能够保持安全距离.
基于一致性理论的分布式状态观测器(distributed state observer, DSO)是使“跟随者”估计“领导者”状态的重要工具.文献[6 -7 ]中分别设计了有限时间收敛与固定时间收敛的DSO,使“跟随者”能够估计出“领导者”的状态.然而大多数分布式状态观测器在观测“领导者”多个阶次的状态时,需要“跟随者”获取其邻居关于“领导者”每个阶次状态的观测值.当MAS规模较大或“领导者”状态阶次较多时,观测器需要传输大量的数据才能实现观测.而当“领导者”的高阶信息不可测量时,DSO则无法对“领导者”所有阶次的状态进行估计.因此,本文使用分布式扩张状态观测器(distributed extended state observer, DESO),使“跟随者”只需获取邻居节点关于“领导者”位置的观测值即可同时完成对“领导者”位置和速度的估计.
另外,大部分基于位置一致性的编队控制律仅在惯性空间中定义位置一致性误差与期望相对位置,此时生成的队形在惯性空间中往往是定常的,编队只能在空间中平移运动[8 -9 ] .鉴于此,本文在“领导者”速度坐标系中定义相对位置向量,以此描述期望队形,并借助DESO使“跟随者”获取或估计出“领导者”的位置与速度,从而使期望队形在惯性空间中的方向始终与虚拟领导者速度方向保持一致.
1 数学模型
1.1 飞行器群通信模型
通过代数图论描述飞行器群中各飞行器之间的通信关系.对于含有N 个节点的有向图G ,令VG ={1, …, N }与EG ⊆VG ×VG 分别代表图G 的节点集合与边集合. 借助图G 的邻接矩阵W =[wij ] i , j = 1 N [10 ] . 当节点i 能够收到节点j 发送的信息时,两节点之间存在一条由节点j 指向节点i 的边,即(i , j )∈EG ,且wij =1;否则wij =0. 图G 的度矩阵记为D =diag{di } i = 1 N di =∑ j = 1 N wij ;图G 的拉普拉斯矩阵为L =D -W.
将由N 架飞行器组成的网络等效为包括N 个节点的图G ,第i 架飞行器对应节点i ,并使用邻接矩阵W 描述各飞行器间的通信关系. 此外,考虑一个虚拟领导者,记为节点0,飞行器网络中仅有部分节点可以获取虚拟领导者的信息. 定义矩阵W 0 =diag{wi 0 } i = 1 N i 可以获取节点0的信息时,wi 0 =1,否则wi 0 =0. 从节点0到任意节点i 之间总存在一条路径,则可以给出如下引理.
引理1 [11 ] 对于有向图G 的拉普拉斯矩阵$\boldsymbol{L} \in \boldsymbol{R}^{N \times N}$与矩阵$\boldsymbol{W}_{i 0} $,当图G 是连通图并且$\boldsymbol{W}_{i 0} \neq \mathbf{0}_{N \times N}$时,$\boldsymbol{H}=\boldsymbol{L}+\boldsymbol{W}_{0}$为正定矩阵.
引理2 [12 ] 当矩阵$\boldsymbol{A} \in \mathbb{R}^{N \times N} $为Hurwitz矩阵时,存在对称正定矩阵M
1.2 飞行器运动学建模
通过控制飞行器的质心运动以实现编队控制.首先定义坐标系OXYZ 为惯性坐标系,用以描述节点i ,i =0, …, N 的质心位置pi =[xi yi zi ]T . 对于节点i ,定义坐标系O 1 i X1 i Y1 i Z1 i O 1 i i 质心固联,并与坐标系OXYZ 平行. 进而定义坐标系O 2 i X2 i Y2 i Z2 i i 的速度坐标系,O 2 i X2 i Y2 i Z2 i O 1 i X1 i Y1 i Z1 i ψi 与θi 所得,其中θi 与ψi 分别为节点i 的弹道倾角与弹道偏角;O 2 i X2 i i 速度方向相同,O 2 i Y2 i O 2 i Z2 i O 2 i X2 i O 2 i Y2 i
(1) $\left.\begin{array}{l}\begin{array}{l}\dot{\boldsymbol{p}}_{i}=\boldsymbol{v}_{i}= \\\quad\left[V_{i} \cos \theta_{i} \cos \psi_{i} \quad V_{i} \sin \theta_{i}-V_{i} \cos \theta_{i} \sin \psi_{i}\right]^{\mathrm{T}} \\\dot{V}_{i}=a_{V, i}-g \sin \theta_{i} \\\dot{\theta}_{i}=V_{i}^{-1}\left(a_{\theta, i}-g \cos \theta_{i}\right) \\\dot{\psi}_{i}=-\left(V_{i} \cos \theta_{i}\right)^{-1} a_{\psi, i}\end{array}\end{array}\right\}$
式中:Vi 为节点i 的速度.记$ \boldsymbol{u}_{i}=\left[\begin{array}{lll}a_{V, i} & a_{\theta, i} & a_{\psi, i}\end{array}\right]^{\mathrm{T}}$,$\boldsymbol{u}_{i}$为节点i 定义在坐标系O 2 i X2 i Y2 i Z2 i
假设1[13 ] 节点0的加速度有限,即存在$\delta_{0} \in \boldsymbol{\mathbb{R}}_{+}$,满足$\delta_{0}=\sup _{t>=0}\left\|\dot{v}_{0}\right\|_{2}^{2}$.
1.3 控制目标
编队控制的目标是通过设计飞行器群中节点i 的控制加速度矢量ui ,使各节点组成期望的队形,并按照期望队形跟随虚拟领导者飞行. 通过相对位置矢量集合$\left\{\boldsymbol{r}_{i} \in \boldsymbol{\mathbb{R} }^{3}\right\}$描述期望队形,ri 为期望队形中节点i 与节点0的相对位置在坐标系O 20 X 20 Y 20 Z 20 中的投影. 期望队形中节点i 在坐标系OXYZ 中的位置p c, i
(2) $\left.\begin{array}{l}\boldsymbol{p}_{\mathrm{c}, i}=\boldsymbol{p}_{0}+\boldsymbol{R}\left(\theta_{0}, \psi_{0}\right) \boldsymbol{r}_{i} \\\boldsymbol{R}\left(\theta_{0}, \psi_{0}\right)= \\\quad\left[\begin{array}{ccc}\cos \psi_{0} \cos \theta_{0} & -\cos \psi_{0} \sin \theta_{0} & \sin \psi_{0} \\\sin \theta_{0} & \cos \theta_{0} & 0 \\-\sin \psi_{0} \cos \theta_{0} & \sin \psi_{0} \sin \theta_{0} & \cos \psi_{0}\end{array}\right]\end{array}\right\}$
式中:R (θi ,ψi )为从坐标系O 2 i X2 i Y2 i Z2 i i =0,…,N 到OXYZ 坐标系的旋转矩阵. 至此,本文的控制目标可以表示为l i m t → ∞ p i - p c , i δ ,其中δ 是与控制律相关的正常数.
2 控制律设计与稳定性分析
2.1 分布式扩张状态观测器
定义p ^ i v ^ i i 对节点0位置p 0 和速度v 0 的观测值,观测器的结构为
(3) $\left.\begin{array}{l}\frac{\mathrm{d}}{\mathrm{~d} t} \hat{\boldsymbol{p}}_{i}=-k_{0,1} \varepsilon_{p, i}+\hat{\boldsymbol{v}}_{i}, \quad \frac{\mathrm{~d}}{\mathrm{~d} t} \hat{\boldsymbol{v}}_{i}=-k_{0,2} \varepsilon_{p, i} \\\varepsilon_{p, i}=\sum_{j=1}^{N} w_{i j}\left(\hat{\boldsymbol{p}}_{i}-\hat{\boldsymbol{p}}_{j}\right)+w_{i 0}\left(\hat{\boldsymbol{p}}_{i}-\boldsymbol{p}_{0}\right)\end{array}\right\}$
式中:正常数k 0,1 与k 0,2 为反馈增益;εp , i p ^ i . 定义ε ~ p ε ~ T p , 1 ε ~ T p , N T ,ε ~ v ε ~ T v , 1 ε ~ T v , N T ,ε ~ p , i p ^ i - p 0 ,ε ~ v , i v ^ i - v 0 ,其中ε ~ p , i ε ~ v , i i 的位置观测误差与速度观测误差,定义ε ~ ε ~ T p ε ~ T v T . 根据图论知识可知εp =[ε T p , 1 ε T p , N T =(H ⊗I 3 )ε ~ p . 根据式(3)可知各观测误差是全局最终一致有界的,证明如下.
ε ~ ε ~ / dt =A ε ~ - B (1N v · 0 ) ,其中A 与B 可表示为
(4) $\left.\begin{array}{rl}\boldsymbol{A} & =\left[\begin{array}{cc}-k_{0,1}\left(\boldsymbol{H} \otimes \boldsymbol{I}_{3}\right) & \boldsymbol{I}_{3 N} \\-k_{0,2}\left(\boldsymbol{H} \otimes \boldsymbol{I}_{3}\right) & \mathbf{0}_{3 N \times 3 N}\end{array}\right] \\\boldsymbol{B} & =\left[\begin{array}{c}\mathbf{0}_{3 N \times 3 N} \\\boldsymbol{I}_{3 N}\end{array}\right]\end{array}\right\}$
根据引理1,可知H 为正定矩阵,并记ΛH =diag{λH ,1 ,…,λH , N H 的特征值对角矩阵. 当4k 0,2 / k 0,1 2 λH , i λH , j A 为Hurwitz矩阵,证明如下.
H 可相似对角化为H =P H - 1 ΛH PH ,因此对于任意λ ∈C,存在:
(5) $\begin{array}{l}\lambda \boldsymbol{I}_{6 N}-\boldsymbol{A}= \\{\left[\begin{array}{cc}\lambda \boldsymbol{P}_{\boldsymbol{H}}^{-1} \boldsymbol{P}_{\boldsymbol{H}}+k_{0,1} \boldsymbol{P}_{\boldsymbol{H}}^{-1} \boldsymbol{\Lambda}_{\boldsymbol{H}} \boldsymbol{P}_{\boldsymbol{H}} & -\boldsymbol{P}_{\boldsymbol{H}}^{-1} \boldsymbol{P}_{\boldsymbol{H}} \\k_{0,2} \boldsymbol{P}_{\boldsymbol{H}}^{-1} \boldsymbol{\Lambda}_{\boldsymbol{H}} \boldsymbol{P}_{\boldsymbol{H}} & \lambda \boldsymbol{P}_{\boldsymbol{H}}^{-1} \boldsymbol{P}_{\boldsymbol{H}}\end{array}\right] \otimes \boldsymbol{I}_{3}=} \\{\left[\left(\boldsymbol{I}_{2} \otimes \boldsymbol{P}_{\boldsymbol{H}}^{-1}\right) \overline{\boldsymbol{A}}\left(\boldsymbol{I}_{2} \otimes \boldsymbol{P}_{\boldsymbol{H}}\right)\right] \otimes \boldsymbol{I}_{3}} \\\overline{\boldsymbol{A}}=\left[\begin{array}{cc}\lambda \boldsymbol{I}_{N}+k_{0,1} \boldsymbol{\Lambda}_{\boldsymbol{H}} & -\boldsymbol{I}_{N} \\k_{0,2} \boldsymbol{\Lambda}_{\boldsymbol{H}} & \lambda \boldsymbol{I}_{N}\end{array}\right]\end{array}$
A ¯ λ 2 IN +λk 0,1 ΛH +k 0,2 ΛH )=∏ i = 1 N ( λ 2 +k 0,1 λλH , i k 0,2 λH , i
其解为二次方程 λ 2 +k 0,1 λλH , i k 0,2 λH , i i =1,…,N 的解. 对于任意λH , i . 对于λH , i
λ 0 =(k 0,2 / 2)(-λH , i r Δ θ Δ / 2))
其中r Δ exp (iθ Δ )=λH , i λH , i k 0,2 / k 0,1 2 ) . 因4k 0,2 / k 0,1 2 λH , i λ 0 )<0,故A 的特征值实部均小于0,A 为 Hurwitz 矩阵.
根据引理2,对于任意正常数k 0 ,存在正定对称矩阵M 满足MA +A T M =-k 0 I 6 N .Q 0 =1 2 ε ~ T M ε ~
(6) $\begin{aligned}\dot{Q}_{0} & =-\frac{k_{0}}{2} \widetilde{\boldsymbol{\varepsilon}}^{\mathrm{T}} \widetilde{\boldsymbol{\varepsilon}}-\widetilde{\boldsymbol{\varepsilon}}^{\mathrm{T}} \boldsymbol{M B}\left(\mathbf{1}_{N} \otimes \dot{\boldsymbol{v}}_{0}\right) \leqslant \\& -\frac{k_{0}}{2 \bar{\lambda}_{M}} \widetilde{\boldsymbol{\varepsilon}}^{\mathrm{T}} \boldsymbol{M} \widetilde{\boldsymbol{\varepsilon}}+\frac{k_{0}}{2 \bar{\lambda}_{\boldsymbol{M}}} \frac{1}{2} \widetilde{\boldsymbol{\varepsilon}}^{\mathrm{T}} \boldsymbol{M} \widetilde{\boldsymbol{\varepsilon}}+ \\& \frac{2 \bar{\lambda}_{\boldsymbol{M}}}{k_{0}} \frac{1}{2}\left(\boldsymbol{B}\left(\mathbf{1}_{N} \otimes \dot{\boldsymbol{v}}_{0}\right)\right)^{\mathrm{T}} \boldsymbol{M}\left(\boldsymbol{B}\left(\mathbf{1}_{N} \otimes \dot{\boldsymbol{v}}_{0}\right)\right) \leqslant \\& -\frac{k_{0}}{2 \bar{\lambda}_{M}} \widetilde{\boldsymbol{\varepsilon}}^{\mathrm{T}} \boldsymbol{M} \widetilde{\boldsymbol{\varepsilon}}+\frac{k_{0}}{4 \bar{\lambda}_{\boldsymbol{M}}} \widetilde{\boldsymbol{\varepsilon}}^{\mathrm{T}} \boldsymbol{M} \widetilde{\boldsymbol{\varepsilon}}+\frac{N}{k_{0}} \bar{\lambda}_{M} \bar{\lambda}_{\boldsymbol{B}^{\mathrm{T}} \boldsymbol{M \boldsymbol { B }}}\left\|\dot{\boldsymbol{v}}_{0}\right\|_{2}^{2} \leqslant \\& -\frac{k_{0}}{2 \bar{\lambda}_{\boldsymbol{M}}} Q_{0}+\frac{N}{k_{0}} \bar{\lambda}_{M} \bar{\lambda}_{\boldsymbol{B}^{\mathrm{T}}} \boldsymbol{M B}^{\boldsymbol{\delta}} \delta_{0}\end{aligned}$
可知Q 0 是最终一致有界的,即观测误差ε ~ p ε ~ v
2.2 位置跟踪控制律设计
首先基于2.1节中得到的观测值p ^ i ri ,将节点i 的期望位置p c, i p c, i p ^ i r ~ i r ~ i R (θ ^ i ψ ^ i ) ri 的滤波值,即d r ~ i / dt =-k 1,2 εr , i εr , i εr , i r ~ i - R (θ ^ i ψ ^ i ) ri ,θ ^ i ψ ^ i i v ^ i . 记v ^ i v ^ x , i v ^ y , i v ^ z , i T ,则 θ ^ i ψ ^ i i
其中V ^ i v ^ i . 然后将虚拟速度指令v c, i
其中εp , i pi -p c, i i 实际位置与其期望位置之间的跟踪误差.
然后求取实际控制加速度ui . 式(1)中的动力学部分可改写为v · i R (θi ,ψi )ui -[0 g 0]T ,同时注意到R (θi ,ψi )R T (θi ,ψi )=I 3 . 故将ui 设计为
(7) $\boldsymbol{u}_{i}=\boldsymbol{R}^{\mathrm{T}}\left(\theta_{i}, \psi_{i}\right)\left(-k_{2,1} \boldsymbol{\varepsilon}_{\mu, i}+\frac{\mathrm{d}}{\mathrm{~d} t} \widetilde{\boldsymbol{v}}_{i}+\left[\begin{array}{lll}0 & g & 0\end{array}\right]^{\mathrm{T}}\right)$
式中:εμ , i vi -v ~ c , i i 实际速度与滤波后期望速度之间的跟踪误差;v ~ i v c, i d d t v ~ i k 2,2 εv , i εv , i v ~ i - v c, i k 1,1 、k 2,1 与k 2,2 均为正常数.
在该位置跟踪控制律下,对于节点i 而言,跟踪误差εp , i εμ , i εr , i εv , i
设Q 3 =Q 1,1 +Q 1,2 +(k 1,1 k 2,1 )-1 Q 2,1 +2(k 1,1 k 2,2 )-1 Q 2,2 .Q 3 对时间求导:
可见Q 3 是最终一致有界的.进一步考虑本文的控制目标,可以推知:
(9) $\begin{aligned}\left\|\boldsymbol{p}_{i}-\boldsymbol{p}_{\mathrm{c}, i}\right\|= & \| \boldsymbol{\varepsilon}_{p, i}+\widetilde{\boldsymbol{\varepsilon}}_{p, i}+\boldsymbol{\varepsilon}_{r, i}+ \\& \left(\boldsymbol{R}\left(\hat{\theta}_{i}, \hat{\psi}_{i}\right)-\boldsymbol{R}\left(\theta_{0}, \psi_{0}\right)\right) \boldsymbol{r}_{i} \| \leqslant \\& \left\|\boldsymbol{\varepsilon}_{p, i}\right\|+\left\|\widetilde{\boldsymbol{\varepsilon}}_{p, i}\right\|+\left\|\boldsymbol{\varepsilon}_{r, i}\right\|+ \\& \left\|\left(\boldsymbol{R}\left(\hat{\theta}_{i}, \hat{\psi}_{i}\right)-\boldsymbol{R}\left(\theta_{0}, \psi_{0}\right)\right) \boldsymbol{r}_{i}\right\|\end{aligned}$
据前文分析可知,位置跟踪误差εp , i ε ~ p , i εr , i ε ~ v , i $ \|\left(\boldsymbol{R}\left(\hat{\theta}_{i}, \hat{\psi}_{i}\right)-\right. \left.\boldsymbol{R}\left(\theta_{0}, \psi_{0}\right)\right) r_{i} \|$ . 则推知$ \left\|\boldsymbol{p}_{i}-\boldsymbol{p}_{\mathrm{c}, i}\right\| $
3 仿真验证
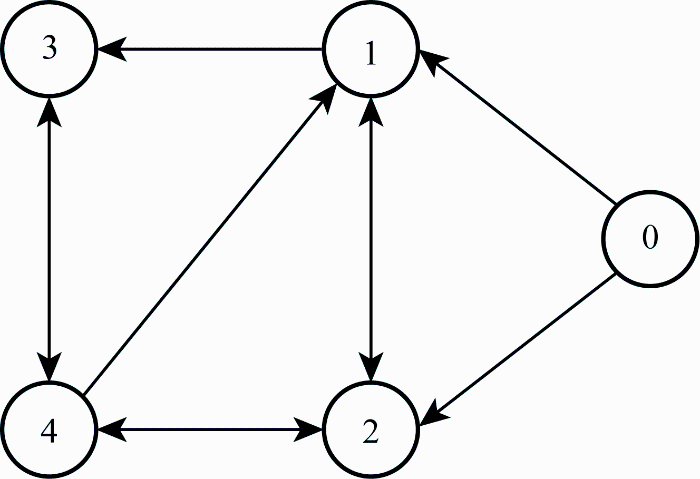
考虑由4架飞行器与1个虚拟领导者组成的网络,其通信关系如图1 所示,图中由节点j 指向节点i 的实线代表节点j 可向i 发送信息. 虚拟领导者的运动轨迹设置为V 0 =100 m/s,θ 0 =0. 05× sin[0. 05(t -0. 5)] rad,ψ 0 =0. 4sin[0. 1(t -2. 5)]-0. 79 rad. 虚拟领导者初始位置为p 0 (0)=[50 150 50]T m.期望队形中的相对位置向量设为r 1 =[70 0 0]T m,r 2 =[0 0 -70]T m,r 3 =[-70 0 0]T m以及r 4 =[0 0 70]T m.分布式观测器与位置跟踪控制律中的参数设置为k 0,1 =400,k 0,2 =80,k 1,1 =k 2,1 =0. 5以及k 2,2 =80. 各飞行器初始运动状态如表1 所示. 将本文中飞行器期望位置 p c, i 8 -9 ]中期望位置定义方法进行对比仿真.根据文献[8 ],p c, i p c, i p 0 +ri .
图1
图1
飞行器群通信拓扑
Fig.1
Communication topology of flight vehicles
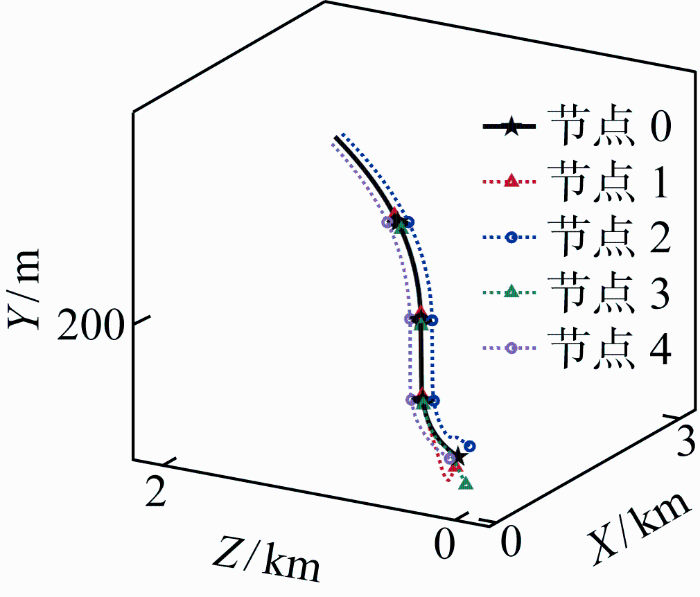
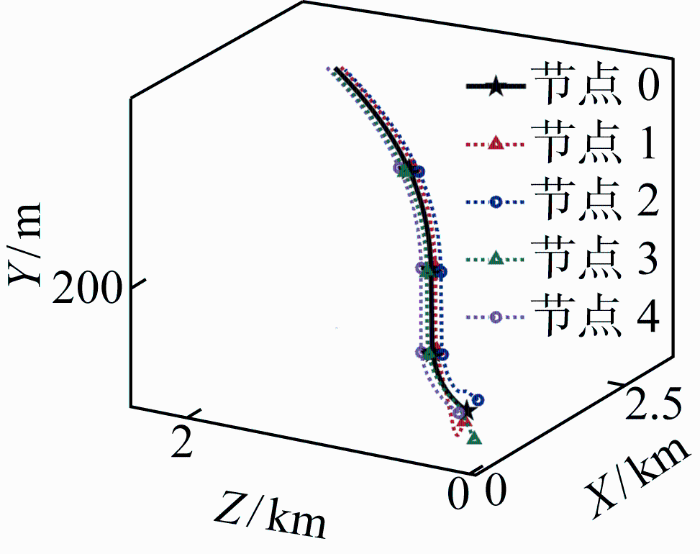
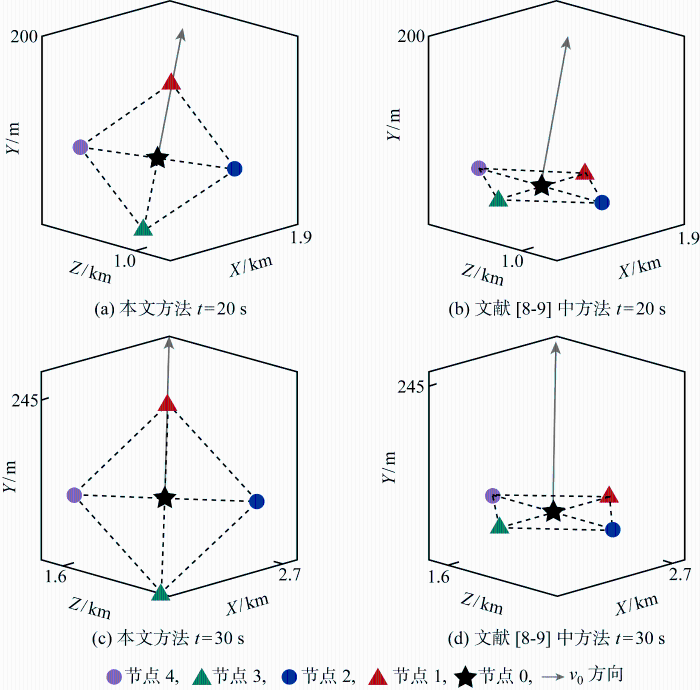
在本文控制方法作用下,各飞行器与虚拟领导者的运动轨迹如图2 所示;按照文献[8 -9 ]方法计算飞行器期望位置并使用本文的位置跟踪控制律时,各飞行器与虚拟领导者的运动轨迹如图3 所示.在第20 s与第30 s时飞行器的相对位置如图4 所示.图中,文献[8 -9 ]中的方法虽使各飞行器跟随领导者飞行,但队形只能在空间中平移运动;而本文方法使队形方向始终与领导者速度方向保持一致.
图2
图2
飞行器轨迹(本文方法)
Fig.2
Trajectories of flight vehicles (method proposed)
图3
图3
飞行器轨迹(文献[8 -9 ]方法)
Fig.3
Trajectories of flight vehicles (method in references [8 -9 ])
图4
图4
t =20 s与t =30 s的编队构型
Fig.4
Formation at t =20 s and t =30 s
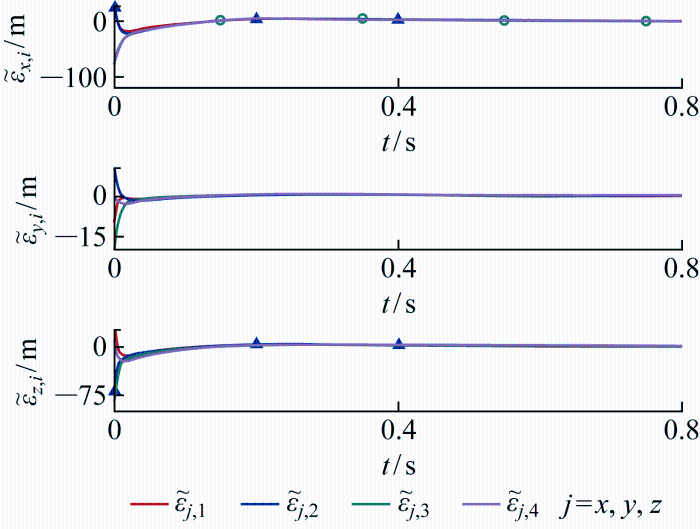
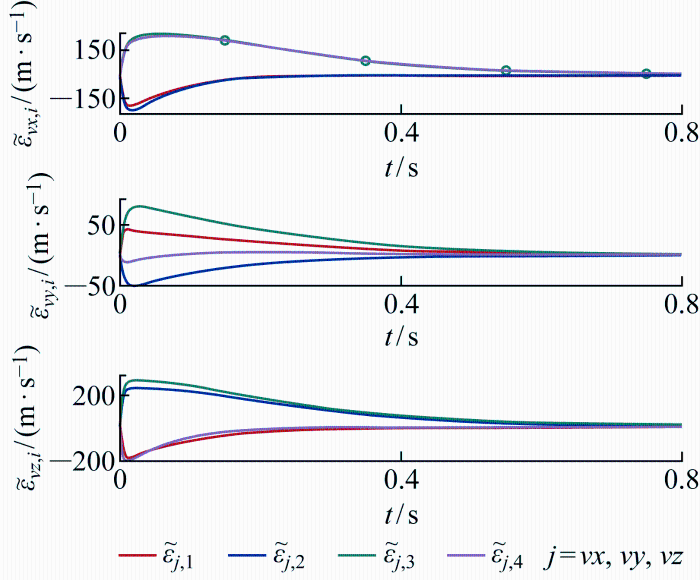
将位置观测误差与速度观测误差分别表示为ε ~ p , i ε ~ x , i ε ~ y , i ε ~ z , i T 与ε ~ v , i ε ~ v x , i ε ~ v y , i ε ~ v z , i T ,ε ~ p , i 图5 所示,ε ~ v , i 图6 所示. 可见位置观测误差ε ~ p , i εp , i ε ~ v , i ε ~ p , i
图5
图5
位置观测误差
Fig.5
Position observation errors
图6
图6
速度观测误差
Fig.6
Velocity observation errors
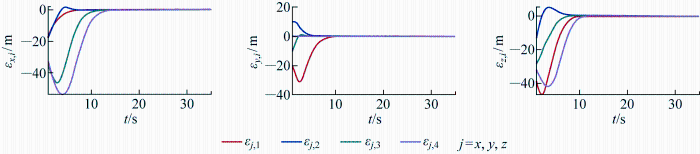
将位置跟踪误差表示为εp , i εx , i εy , i εz , i T ,各飞行器位置跟踪误差如图7 所示,可见位置误差是最终一致有界的,各飞行器可以通过跟踪期望位置完成编队控制任务.
图7
图7
位置跟踪误差
Fig.7
Position tracking errors
4 结语
本文研究一种基于分布式观测器的飞行器编队控制方法,首先给出分布式状态观测器,使各飞行器观测出虚拟领导者的位置;然后基于观测结果与期望队形计算出各飞行器的期望位置,并通过给出的位置跟踪控制律使飞行器跟踪期望位置,从而实现编队控制.数值仿真验证了所提编队控制方法的有效性.
参考文献
View Option
[1]
OH K K PARK M C AHN H S A survey of multi-agent formation control
[J]. Automatica 2015 , 53 : 424 -440 .
[本文引用: 1]
[2]
LI G F ZUO Z Y Robust leader-follower cooperative guidance under false-data injection attacks
[J]. IEEE Transactions on Aerospace and Electronic Systems 2023 , 59 (4 ): 4511 -4524 .
[本文引用: 1]
[3]
叶帅 , 蒋国平 , 周映江 , 等 . 基于事件触发的多无人机固定时间编队控制
[J]. 系统仿真学报 2021 , 33 (10 ): 2420 -2431 .
DOI:10.16182/j.issn1004731x.joss.20-0613
[本文引用: 1]
为解决四旋翼无人机编队控制问题,提出基于事件触发的多四旋翼无人机系统固定时间编队控制算法。针对无人机的姿态环控制,选取切换的固定时间滑模面,使得当系统状态在滑模面上时,系统能够在固定时间到达平衡点。当系统状态不在滑模面上时,设计固定时间滑模控制器,使得不在滑模面上的系统状态,能够在固定时间内到达滑模面。针对无人机的位置环控制,研究了事件驱动下的固定时间编队控制策略。分析表明:位置控制器最短触发时间间隔是一个有限的值,证明系统不存在Zeno现象。通过数值仿真验证了所提控制算法的有效性。
YE Shuai JIANG Guoping ZHOU Yingjiang et al Fixed-time event-triggered formation control for multiple UAVs
[J]. Journal of System Simulation 2021 , 33 (10 ): 2420 -2431 .
DOI:10.16182/j.issn1004731x.joss.20-0613
[本文引用: 1]
To solve the quadrotor UAV formation control problem, an event-triggered fixed time formation control algorithm of multi quadrotor UAV system is studied. For the attitude loop control problem of UAV, <em>the switching fixed time sliding surface is selected to make the system reach the equilibrium point in a fixed time when the system state is on the sliding surface.</em> A<em> fixed-time sliding mode controller is designed so that the system state which is not on the sliding surface can reach the sliding surface within a fixed time.</em> In view of the position loop control problem of UAV, <em>the event-driven fixed time formation control strategy is studied</em>. <em>It is analyzed that the shortest trigger time interval of position controller is a finite value and there is no Zeno phenomenon</em>. The effectiveness of the proposed control algorithm is verified by numerical simulations.
[4]
王君 , 李昂 . 多无人机编队递归非奇异终端滑模容错控制
[J]. 信息与控制 2024 , 53 (1 ): 71 -85 .
[本文引用: 1]
WANG Jun LI Ang Recursive non-singular terminal sliding mode fault-tolerant control of multi-UAV formation
[J]. Information and Control 2024 , 53 (1 ): 71 -85 .
[本文引用: 1]
[5]
PARK B S YOO S J Time-varying formation control with moving obstacle avoidance for input-saturated quadrotors with external disturbances
[J]. IEEE Transactions on Systems , Man , and Cybernetics: Systems 2024 , 54 (5 ): 3270 -3282 .
[本文引用: 1]
[6]
WANG Q DONG X W WANG B H et al Finite-time observer-based H ∞ fault-tolerant output formation tracking control for heterogeneous nonlinear multi-agent systems
[J]. IEEE Transactions on Network Science and Engineering 2023 , 10 (4 ): 1822 -1834 .
[本文引用: 1]
[7]
MA X DAI K R ZOU Y et al Fixed-time anti-saturation grouped cooperative guidance law with state estimations of multiple maneuvering targets
[J]. Journal of the Franklin Institute 2023 , 360 (8 ): 5524 -5547 .
[本文引用: 1]
[8]
LI G F WANG X Z ZUO Z Y et al Fault-tolerant formation control for leader-follower flight vehicles under malicious attacks
[J]. IEEE Transactions on Intelligent Vehicles 2024 (99 ): 1 -15 .
[本文引用: 7]
[9]
WU X WEI C S CHEN T Y et al On novel distributed fixed-time formation tracking of multiple hypersonic flight vehicles with collision avoidance
[J]. Aerospace Science and Technology 2023 , 141 : 108517 .
[本文引用: 6]
[10]
LI G F WU Y J Adaptive cooperative guidance with seeker-less followers: A position coordination-based framework
[J]. ISA Transactions 2023 , 143 : 168 -176 .
DOI:10.1016/j.isatra.2023.09.024
PMID:37793970
[本文引用: 1]
This paper addresses the problem of cooperative guidance for multiple flight vehicles, comprising a leader and seeker-less followers. All the flight vehicles are required to hit the target simultaneously at a desired impact time, even though the target information is unavailable to the followers. To achieve this, a fixed-time convergent guidance law is proposed for the leader, incorporating impact time control. We introduce an adaptive cooperative guidance strategy for the seeker-less followers through coordinated position location relative to the leader. The simulation results validate the effectiveness satisfactorily coinciding with the theoretical analysis.Copyright © 2023 ISA. Published by Elsevier Ltd. All rights reserved.
[11]
PENG Z H JIANG Y WANG J Event-triggered dynamic surface control of an underactuated autonomous surface vehicle for target enclosing
[J]. IEEE Transactions on Industrial Electronics 2021 , 68 (4 ): 3402 -3412 .
[本文引用: 1]
[12]
LI D Y MA G F XU Y et al Layered affine formation control of networked uncertain systems: A fully distributed approach over directed graphs
[J]. IEEE Transactions on Cybernetics 2021 , 51 (12 ): 6119 -6130 .
[本文引用: 1]
[13]
LI G F LÜ J H ZHU G L et al Distributed observer-based cooperative guidance with appointed impact time and collision avoidance
[J]. Journal of the Franklin Institute 2021 , 358 (14 ): 6976 -6993 .
[本文引用: 1]
A survey of multi-agent formation control
1
2015
... 多飞行器协同编队在军用与民用领域均具有广泛应用,近年来受到较多关注[1 -2 ] .飞行器编队控制的主要目标是令多架飞行器在飞行过程中满足一定的相对位置约束.针对多飞行器编队控制,国内外诸多学者已开展了较为深入的研究. ...
Robust leader-follower cooperative guidance under false-data injection attacks
1
2023
... 多飞行器协同编队在军用与民用领域均具有广泛应用,近年来受到较多关注[1 -2 ] .飞行器编队控制的主要目标是令多架飞行器在飞行过程中满足一定的相对位置约束.针对多飞行器编队控制,国内外诸多学者已开展了较为深入的研究. ...
基于事件触发的多无人机固定时间编队控制
1
2021
... 一致性是指多智能体系统(multi-agent system, MAS)就某一行为达成一致的现象,一致性理论是编队控制重要的理论基础.基于一致性理论的编队控制律中,“领导-跟随”架构通过“领导者”决定编队整体的运动轨迹,而控制“跟随者”按照期望队形跟随“领导者”运动,是一种较为典型的编队控制架构.一些文献通过构造关于空间位置的一致性误差,并在误差中引入期望队形中“跟随者”与“领导者”之间的相对位置信息,达到基于一致性控制的编队控制[3 ] .文献[4 ]中针对多无人机系统构造了引入期望相对位置的一致性误差,给出一种滑模控制律,通过使一致性误差收敛实现了编队控制.文献[5 ]中综合考虑多无人机编队控制与避碰问题,在位置一致性控制律中通过引入辅助变量保证各无人机间能够保持安全距离. ...
Fixed-time event-triggered formation control for multiple UAVs
1
2021
... 一致性是指多智能体系统(multi-agent system, MAS)就某一行为达成一致的现象,一致性理论是编队控制重要的理论基础.基于一致性理论的编队控制律中,“领导-跟随”架构通过“领导者”决定编队整体的运动轨迹,而控制“跟随者”按照期望队形跟随“领导者”运动,是一种较为典型的编队控制架构.一些文献通过构造关于空间位置的一致性误差,并在误差中引入期望队形中“跟随者”与“领导者”之间的相对位置信息,达到基于一致性控制的编队控制[3 ] .文献[4 ]中针对多无人机系统构造了引入期望相对位置的一致性误差,给出一种滑模控制律,通过使一致性误差收敛实现了编队控制.文献[5 ]中综合考虑多无人机编队控制与避碰问题,在位置一致性控制律中通过引入辅助变量保证各无人机间能够保持安全距离. ...
多无人机编队递归非奇异终端滑模容错控制
1
2024
... 一致性是指多智能体系统(multi-agent system, MAS)就某一行为达成一致的现象,一致性理论是编队控制重要的理论基础.基于一致性理论的编队控制律中,“领导-跟随”架构通过“领导者”决定编队整体的运动轨迹,而控制“跟随者”按照期望队形跟随“领导者”运动,是一种较为典型的编队控制架构.一些文献通过构造关于空间位置的一致性误差,并在误差中引入期望队形中“跟随者”与“领导者”之间的相对位置信息,达到基于一致性控制的编队控制[3 ] .文献[4 ]中针对多无人机系统构造了引入期望相对位置的一致性误差,给出一种滑模控制律,通过使一致性误差收敛实现了编队控制.文献[5 ]中综合考虑多无人机编队控制与避碰问题,在位置一致性控制律中通过引入辅助变量保证各无人机间能够保持安全距离. ...
Recursive non-singular terminal sliding mode fault-tolerant control of multi-UAV formation
1
2024
... 一致性是指多智能体系统(multi-agent system, MAS)就某一行为达成一致的现象,一致性理论是编队控制重要的理论基础.基于一致性理论的编队控制律中,“领导-跟随”架构通过“领导者”决定编队整体的运动轨迹,而控制“跟随者”按照期望队形跟随“领导者”运动,是一种较为典型的编队控制架构.一些文献通过构造关于空间位置的一致性误差,并在误差中引入期望队形中“跟随者”与“领导者”之间的相对位置信息,达到基于一致性控制的编队控制[3 ] .文献[4 ]中针对多无人机系统构造了引入期望相对位置的一致性误差,给出一种滑模控制律,通过使一致性误差收敛实现了编队控制.文献[5 ]中综合考虑多无人机编队控制与避碰问题,在位置一致性控制律中通过引入辅助变量保证各无人机间能够保持安全距离. ...
Time-varying formation control with moving obstacle avoidance for input-saturated quadrotors with external disturbances
1
2024
... 一致性是指多智能体系统(multi-agent system, MAS)就某一行为达成一致的现象,一致性理论是编队控制重要的理论基础.基于一致性理论的编队控制律中,“领导-跟随”架构通过“领导者”决定编队整体的运动轨迹,而控制“跟随者”按照期望队形跟随“领导者”运动,是一种较为典型的编队控制架构.一些文献通过构造关于空间位置的一致性误差,并在误差中引入期望队形中“跟随者”与“领导者”之间的相对位置信息,达到基于一致性控制的编队控制[3 ] .文献[4 ]中针对多无人机系统构造了引入期望相对位置的一致性误差,给出一种滑模控制律,通过使一致性误差收敛实现了编队控制.文献[5 ]中综合考虑多无人机编队控制与避碰问题,在位置一致性控制律中通过引入辅助变量保证各无人机间能够保持安全距离. ...
Finite-time observer-based H ∞ fault-tolerant output formation tracking control for heterogeneous nonlinear multi-agent systems
1
2023
... 基于一致性理论的分布式状态观测器(distributed state observer, DSO)是使“跟随者”估计“领导者”状态的重要工具.文献[6 -7 ]中分别设计了有限时间收敛与固定时间收敛的DSO,使“跟随者”能够估计出“领导者”的状态.然而大多数分布式状态观测器在观测“领导者”多个阶次的状态时,需要“跟随者”获取其邻居关于“领导者”每个阶次状态的观测值.当MAS规模较大或“领导者”状态阶次较多时,观测器需要传输大量的数据才能实现观测.而当“领导者”的高阶信息不可测量时,DSO则无法对“领导者”所有阶次的状态进行估计.因此,本文使用分布式扩张状态观测器(distributed extended state observer, DESO),使“跟随者”只需获取邻居节点关于“领导者”位置的观测值即可同时完成对“领导者”位置和速度的估计. ...
Fixed-time anti-saturation grouped cooperative guidance law with state estimations of multiple maneuvering targets
1
2023
... 基于一致性理论的分布式状态观测器(distributed state observer, DSO)是使“跟随者”估计“领导者”状态的重要工具.文献[6 -7 ]中分别设计了有限时间收敛与固定时间收敛的DSO,使“跟随者”能够估计出“领导者”的状态.然而大多数分布式状态观测器在观测“领导者”多个阶次的状态时,需要“跟随者”获取其邻居关于“领导者”每个阶次状态的观测值.当MAS规模较大或“领导者”状态阶次较多时,观测器需要传输大量的数据才能实现观测.而当“领导者”的高阶信息不可测量时,DSO则无法对“领导者”所有阶次的状态进行估计.因此,本文使用分布式扩张状态观测器(distributed extended state observer, DESO),使“跟随者”只需获取邻居节点关于“领导者”位置的观测值即可同时完成对“领导者”位置和速度的估计. ...
Fault-tolerant formation control for leader-follower flight vehicles under malicious attacks
7
2024
... 另外,大部分基于位置一致性的编队控制律仅在惯性空间中定义位置一致性误差与期望相对位置,此时生成的队形在惯性空间中往往是定常的,编队只能在空间中平移运动[8 -9 ] .鉴于此,本文在“领导者”速度坐标系中定义相对位置向量,以此描述期望队形,并借助DESO使“跟随者”获取或估计出“领导者”的位置与速度,从而使期望队形在惯性空间中的方向始终与虚拟领导者速度方向保持一致. ...
... 考虑由4架飞行器与1个虚拟领导者组成的网络,其通信关系如图1 所示,图中由节点j 指向节点i 的实线代表节点j 可向i 发送信息. 虚拟领导者的运动轨迹设置为V 0 =100 m/s,θ 0 =0. 05× sin[0. 05(t -0. 5)] rad,ψ 0 =0. 4sin[0. 1(t -2. 5)]-0. 79 rad. 虚拟领导者初始位置为p 0 (0)=[50 150 50]T m.期望队形中的相对位置向量设为r 1 =[70 0 0]T m,r 2 =[0 0 -70]T m,r 3 =[-70 0 0]T m以及r 4 =[0 0 70]T m.分布式观测器与位置跟踪控制律中的参数设置为k 0,1 =400,k 0,2 =80,k 1,1 =k 2,1 =0. 5以及k 2,2 =80. 各飞行器初始运动状态如表1 所示. 将本文中飞行器期望位置 p c, i 8 -9 ]中期望位置定义方法进行对比仿真.根据文献[8 ],p c, i p c, i p 0 +ri . ...
... ]中期望位置定义方法进行对比仿真.根据文献[8 ],p c, i p c, i p 0 +ri . ...
... 在本文控制方法作用下,各飞行器与虚拟领导者的运动轨迹如图2 所示;按照文献[8 -9 ]方法计算飞行器期望位置并使用本文的位置跟踪控制律时,各飞行器与虚拟领导者的运动轨迹如图3 所示.在第20 s与第30 s时飞行器的相对位置如图4 所示.图中,文献[8 -9 ]中的方法虽使各飞行器跟随领导者飞行,但队形只能在空间中平移运动;而本文方法使队形方向始终与领导者速度方向保持一致. ...
... 所示.图中,文献[8 -9 ]中的方法虽使各飞行器跟随领导者飞行,但队形只能在空间中平移运动;而本文方法使队形方向始终与领导者速度方向保持一致. ...
... 飞行器轨迹(文献[
8 -
9 ]方法)
Trajectories of flight vehicles (method in references [<xref ref-type="bibr" rid="b8">8</xref>-<xref ref-type="bibr" rid="b9">9</xref>]) Fig.3 ![]()
10.16183/j.cnki.jsjtu.2024.205.F0004 图4 <i>t</i>=20 s与<i>t</i>=30 s的编队构型 Formation at <i>t</i>=20 s and <i>t</i>=30 s Fig.4 ![]()
将位置观测误差与速度观测误差分别表示为 ε ~ p , i ε ~ x , i ε ~ y , i ε ~ z , i T 与 ε ~ v , i ε ~ v x , i ε ~ v y , i ε ~ v z , i T , ε ~ p , i 图5 所示, ε ~ v , i 图6 所示. 可见位置观测误差 ε ~ p , i εp , i ε ~ v , i ε ~ p , i
... Trajectories of flight vehicles (method in references [
8 -
9 ])
Fig.3 ![]()
10.16183/j.cnki.jsjtu.2024.205.F0004 图4 <i>t</i>=20 s与<i>t</i>=30 s的编队构型 Formation at <i>t</i>=20 s and <i>t</i>=30 s Fig.4 ![]()
将位置观测误差与速度观测误差分别表示为 ε ~ p , i ε ~ x , i ε ~ y , i ε ~ z , i T 与 ε ~ v , i ε ~ v x , i ε ~ v y , i ε ~ v z , i T , ε ~ p , i 图5 所示, ε ~ v , i 图6 所示. 可见位置观测误差 ε ~ p , i εp , i ε ~ v , i ε ~ p , i
On novel distributed fixed-time formation tracking of multiple hypersonic flight vehicles with collision avoidance
6
2023
... 另外,大部分基于位置一致性的编队控制律仅在惯性空间中定义位置一致性误差与期望相对位置,此时生成的队形在惯性空间中往往是定常的,编队只能在空间中平移运动[8 -9 ] .鉴于此,本文在“领导者”速度坐标系中定义相对位置向量,以此描述期望队形,并借助DESO使“跟随者”获取或估计出“领导者”的位置与速度,从而使期望队形在惯性空间中的方向始终与虚拟领导者速度方向保持一致. ...
... 考虑由4架飞行器与1个虚拟领导者组成的网络,其通信关系如图1 所示,图中由节点j 指向节点i 的实线代表节点j 可向i 发送信息. 虚拟领导者的运动轨迹设置为V 0 =100 m/s,θ 0 =0. 05× sin[0. 05(t -0. 5)] rad,ψ 0 =0. 4sin[0. 1(t -2. 5)]-0. 79 rad. 虚拟领导者初始位置为p 0 (0)=[50 150 50]T m.期望队形中的相对位置向量设为r 1 =[70 0 0]T m,r 2 =[0 0 -70]T m,r 3 =[-70 0 0]T m以及r 4 =[0 0 70]T m.分布式观测器与位置跟踪控制律中的参数设置为k 0,1 =400,k 0,2 =80,k 1,1 =k 2,1 =0. 5以及k 2,2 =80. 各飞行器初始运动状态如表1 所示. 将本文中飞行器期望位置 p c, i 8 -9 ]中期望位置定义方法进行对比仿真.根据文献[8 ],p c, i p c, i p 0 +ri . ...
... 在本文控制方法作用下,各飞行器与虚拟领导者的运动轨迹如图2 所示;按照文献[8 -9 ]方法计算飞行器期望位置并使用本文的位置跟踪控制律时,各飞行器与虚拟领导者的运动轨迹如图3 所示.在第20 s与第30 s时飞行器的相对位置如图4 所示.图中,文献[8 -9 ]中的方法虽使各飞行器跟随领导者飞行,但队形只能在空间中平移运动;而本文方法使队形方向始终与领导者速度方向保持一致. ...
... -9 ]中的方法虽使各飞行器跟随领导者飞行,但队形只能在空间中平移运动;而本文方法使队形方向始终与领导者速度方向保持一致. ...
... -
9 ]方法)
Trajectories of flight vehicles (method in references [<xref ref-type="bibr" rid="b8">8</xref>-<xref ref-type="bibr" rid="b9">9</xref>]) Fig.3 ![]()
10.16183/j.cnki.jsjtu.2024.205.F0004 图4 <i>t</i>=20 s与<i>t</i>=30 s的编队构型 Formation at <i>t</i>=20 s and <i>t</i>=30 s Fig.4 ![]()
将位置观测误差与速度观测误差分别表示为 ε ~ p , i ε ~ x , i ε ~ y , i ε ~ z , i T 与 ε ~ v , i ε ~ v x , i ε ~ v y , i ε ~ v z , i T , ε ~ p , i 图5 所示, ε ~ v , i 图6 所示. 可见位置观测误差 ε ~ p , i εp , i ε ~ v , i ε ~ p , i
... -
9 ])
Fig.3 ![]()
10.16183/j.cnki.jsjtu.2024.205.F0004 图4 <i>t</i>=20 s与<i>t</i>=30 s的编队构型 Formation at <i>t</i>=20 s and <i>t</i>=30 s Fig.4 ![]()
将位置观测误差与速度观测误差分别表示为 ε ~ p , i ε ~ x , i ε ~ y , i ε ~ z , i T 与 ε ~ v , i ε ~ v x , i ε ~ v y , i ε ~ v z , i T , ε ~ p , i 图5 所示, ε ~ v , i 图6 所示. 可见位置观测误差 ε ~ p , i εp , i ε ~ v , i ε ~ p , i
Adaptive cooperative guidance with seeker-less followers: A position coordination-based framework
1
2023
... 通过代数图论描述飞行器群中各飞行器之间的通信关系.对于含有N 个节点的有向图G ,令VG ={1, …, N }与EG ⊆VG ×VG 分别代表图G 的节点集合与边集合. 借助图G 的邻接矩阵W =[wij ] i , j = 1 N [10 ] . 当节点i 能够收到节点j 发送的信息时,两节点之间存在一条由节点j 指向节点i 的边,即(i , j )∈EG ,且wij =1;否则wij =0. 图G 的度矩阵记为D =diag{di } i = 1 N di = ∑ j = 1 N wij ;图G 的拉普拉斯矩阵为L =D -W. ...
Event-triggered dynamic surface control of an underactuated autonomous surface vehicle for target enclosing
1
2021
... 引理1 [11 ] 对于有向图G 的拉普拉斯矩阵$\boldsymbol{L} \in \boldsymbol{R}^{N \times N}$与矩阵$\boldsymbol{W}_{i 0} $,当图G 是连通图并且$\boldsymbol{W}_{i 0} \neq \mathbf{0}_{N \times N}$时,$\boldsymbol{H}=\boldsymbol{L}+\boldsymbol{W}_{0}$为正定矩阵. ...
Layered affine formation control of networked uncertain systems: A fully distributed approach over directed graphs
1
2021
... 引理2 [12 ] 当矩阵$\boldsymbol{A} \in \mathbb{R}^{N \times N} $为Hurwitz矩阵时,存在对称正定矩阵M
Distributed observer-based cooperative guidance with appointed impact time and collision avoidance
1
2021
... 假设1[13 ] 节点0的加速度有限,即存在$\delta_{0} \in \boldsymbol{\mathbb{R}}_{+}$,满足$\delta_{0}=\sup _{t>=0}\left\|\dot{v}_{0}\right\|_{2}^{2}$. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}