Journal of Shanghai Jiao Tong University ›› 2021, Vol. 55 ›› Issue (5): 598-606.doi: 10.16183/j.cnki.jsjtu.2020.011
Special Issue: 《上海交通大学学报》2021年12期专题汇总专辑; 《上海交通大学学报》2021年“自动化技术、计算机技术”专题
Previous Articles Next Articles
WU Jin’e1, WANG Ruoyu2, DUAN Qianqian1( ), LI Guoqiang1,2, JÜ Changjiang2
), LI Guoqiang1,2, JÜ Changjiang2
Received:2020-01-08
Online:2021-05-28
Published:2021-06-01
Contact:
DUAN Qianqian
E-mail:dqq1019@163.com
CLC Number:
WU Jin’e, WANG Ruoyu, DUAN Qianqian, LI Guoqiang, JÜ Changjiang. Collective Data Anomaly Detection Based on Reverse k-Nearest Neighbor Filtering[J]. Journal of Shanghai Jiao Tong University, 2021, 55(5): 598-606.
Add to citation manager EndNote|Ris|BibTeX
URL: https://xuebao.sjtu.edu.cn/EN/10.16183/j.cnki.jsjtu.2020.011
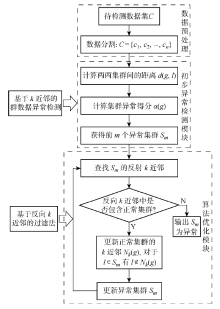
Fig.1
Flow chart of model establishment
Fig.2
Distribution histogram of daily trading data (156th day )

Fig.3
Data set introduction
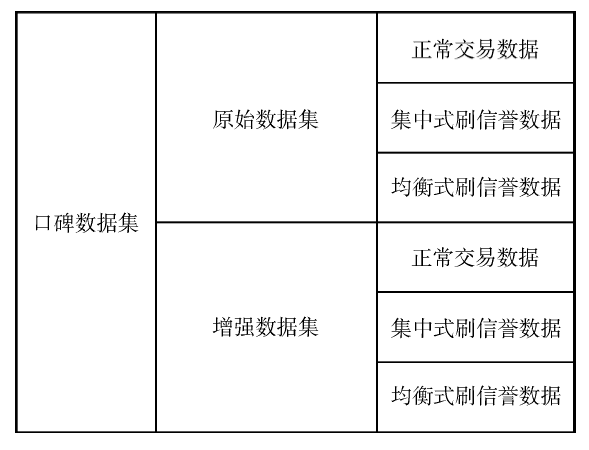

Fig.4
Influence of k values on test results
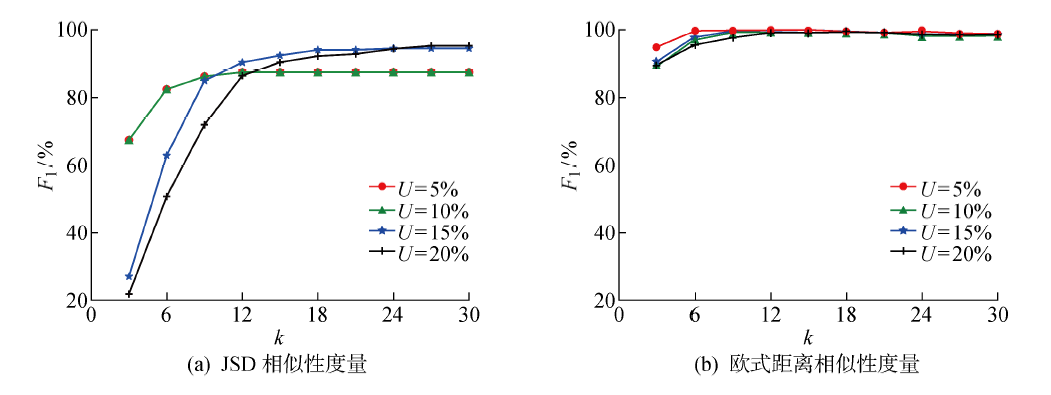

Fig.5
Experimental results of reverse filtering interference value method in original data set
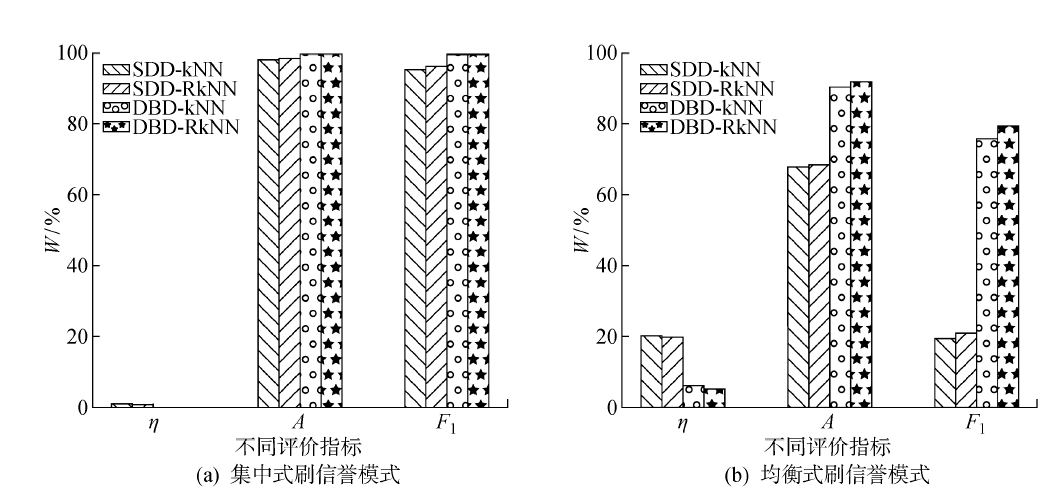

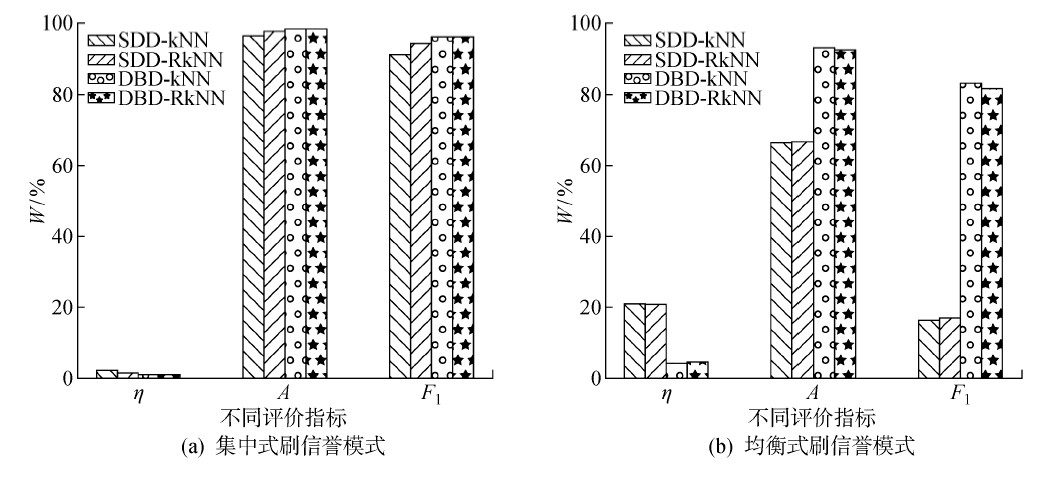
Fig.6
Experimental results of reverse filtering interference value method in enhanced data set
Tab.1
Comparison of algorithm performance in raw data set
| 模式 | 算法名称 | 一阶直方图 | 二阶直方图 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P/% | R/% | F1/% | t/ms | P/% | R/% | F1/% | t/ms | ||||
| 集中式刷信誉 | SDD-RkNN | 96.30 | 96.30 | 96.30 | 4542.80 | 97.23 | 97.23 | 97.23 | 1612.45 | ||
| DBD-RkNN | 99.69 | 99.69 | 99.69 | 2325.97 | 91.69 | 91.69 | 91.69 | 762.44 | |||
| DSDD-E | 78.84 | 99.69 | 87.99 | 1507.32 | 65.06 | 96.92 | 77.71 | 491.29 | |||
| 均衡式刷信誉 | SDD-RkNN | 20.92 | 20.92 | 20.92 | 4401.57 | 80.92 | 80.92 | 80.92 | 1517.24 | ||
| DBD-RkNN | 79.38 | 79.38 | 79.38 | 2265.98 | 69.84 | 69.84 | 69.84 | 718.89 | |||
| DSDD-E | 23.78 | 13.54 | 17.25 | 1400.54 | 54.67 | 80.31 | 64.52 | 494.79 | |||
Tab.2
Comparison of algorithm performance in enhanced data set
| 模式 | 算法名称 | 一阶直方图 | 二阶直方图 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P/% | R/% | F1/% | t/ms | P/% | R/% | F1/% | t/ms | ||||
| 集中式刷信誉 | SDD-RkNN | 94.46 | 94.46 | 94.46 | 9671.67 | 88.00 | 88.00 | 88.00 | 2108.75 | ||
| DBD-RkNN | 96.30 | 96.30 | 96.30 | 4637.67 | 74.77 | 74.77 | 74.77 | 995.40 | |||
| DSDD-E | 75.17 | 100.00 | 85.70 | 2140.21 | 49.14 | 91.38 | 63.90 | 565.68 | |||
| 均衡式刷信誉 | SDD-RkNN | 16.92 | 16.92 | 16.92 | 10356.19 | 79.69 | 79.69 | 79.69 | 1940.85 | ||
| DBD-RkNN | 81.85 | 81.85 | 81.85 | 4913.40 | 58.46 | 58.46 | 58.46 | 898.06 | |||
| DSDD-E | 23.35 | 13.84 | 17.38 | 2280.15 | 53.77 | 75.08 | 60.98 | 550.01 | |||

Fig.7
Comparison of stability of three algorithms under different anomaly probabilities

| [1] | MEHROTRA K G, MOHAN C K, HUANG H M. Anomaly detection principles and algorithms[M]. Switzerland: Springer International Publishing, 2017. |
| [2] | TIMČENKO V, GAJIN S. Ensemble classifiers for supervised anomaly based network intrusion detection [C]//2017 13th IEEE International Conference on Intelligent Computer Communication and Processing (ICCP). Piscataway, NJ, USA: IEEE, 2017: 13-19. |
| [3] | HUSSAIN B, DU Q H, REN P Y. Semi-supervised learning based big data-driven anomaly detection in mobile wireless networks[J]. China Communications, 2018, 15(4):41-57. |
| [4] | MILLER D J, KESIDIS G, QIU Z C. Unsupervised parsimonious cluster-based anomaly detection (PCAD) [C]//2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP). Piscataway, NJ, USA: IEEE, 2018: 1-6. |
| [5] | CHANDOLA V, BANERJEE A, KUMAR V. Anomaly detection[J]. ACM Computing Surveys, 2009, 41(3):1-58. |
| [6] |
TAO X T, LI G Q, SUN D, et al. A game-theoretic model and analysis of data exchange protocols for Internet of Things in clouds[J]. Future Generation Computer Systems, 2017, 76:582-589.
doi: 10.1016/j.future.2016.12.030 URL |
| [7] |
EDGEWORTH F Y. On discordant observations[J]. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 1887, 23(143):364-375.
doi: 10.1080/14786448708628471 URL |
| [8] |
KNORR E M, NG R T, TUCAKOV V. Distance-based outliers: Algorithms and applications[J]. The VLDB Journal, 2000, 8(3/4):237-253.
doi: 10.1007/s007780050006 URL |
| [9] | LEE J G, HAN J W, LI X L. Trajectory outlier detection: A partition-and-detect framework [C]//2008 IEEE 24th International Conference on Data Engineering. Piscataway, NJ, USA: IEEE, 2008: 140-149. |
| [10] | LUAN F J, ZHANG Y T, CAO K Y, et al. Based local density trajectory outlier detection with partition-and-detect framework [C]//2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD). Piscataway, NJ, USA: IEEE, 2017: 1708-1714. |
| [11] |
DJENOURI Y, BELHADI A, LIN J C, et al. Adapted K-nearest neighbors for detecting anomalies on spatio-temporal traffic flow[J]. IEEE Access, 2019, 7:10015-10027.
doi: 10.1109/Access.6287639 URL |
| [12] | 毛江云, 吴昊, 孙未未. 路网空间下基于马尔可夫决策过程的异常车辆轨迹检测算法[J]. 计算机学报, 2018, 41(8):1928-1942. |
| MAO Jiangyun, WU Hao, SUN Weiwei. Vehicle trajectory anomaly detection in road network via Markov decision process[J]. Chinese Journal of Computers, 2018, 41(8):1928-1942. | |
| [13] | WANG R Y, SUN D, LI G Q, et al. Statistical detection of collective data Fraud [C]//International Conference on Multimedia and Expo. London, UK: IEEE, 2020. |
| [14] |
KULLBACK S, LEIBLER R A. On information and sufficiency[J]. Annals of Mathematical Statistics, 1951, 22(1):79-86.
doi: 10.1214/aoms/1177729694 URL |
| [15] | SALEM O, NAÏT-ABDESSELAM F, MEHAOUA A. Anomaly detection in network traffic using Jensen-Shannon divergence [C]//2012 IEEE International Conference on Communications (ICC). Piscataway, NJ, USA: IEEE, 2012: 5200-5204. |
| [16] |
COVER T, HART P. Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory, 1967, 13(1):21-27.
doi: 10.1109/TIT.1967.1053964 URL |
| [17] | WOHLKINGER W, ALDOMA A, RUSU R B, et al. 3DNet: Large-scale object class recognition from CAD models [C]//2012 IEEE International Conference on Robotics and Automation. Piscataway, NJ, USA: IEEE, 2012: 5384-5391. |
| [18] | AGGARWAL C C. Proximity-based outlier detection[M]// Outlier Analysis. Switzerland: Springer International Publishing, 2016: 111-147. |
| [19] | 陈瑜. 离群点检测算法研究[D]. 兰州: 兰州大学, 2018. |
| CHEN Yu. Research on the outliers detection algorithm[D]. Lanzhou: Lanzhou University, 2018. |
| [1] | Wang Gang, Guan Yaonan, Li Dewei. Two-Stream Auto-Encoder Network for Unsupervised Skeleton-Based Action Recognition [J]. J Shanghai Jiaotong Univ Sci, 2025, 30(2): 330-336. |
| [2] | LIU Jianxin, PAN Ruru, ZHOU Jian. Unsupervised Fabric Defect Detection Based on Under-Complete Dictionary Reconstruction [J]. Journal of Shanghai Jiao Tong University, 2025, 59(2): 283-292. |
| [3] | ZHANG Shengjia(张晟嘉), LIN Tiancheng(林天成), XU Yi(徐奕). Boosting Unsupervised Domain Adaptation with Soft Pseudo-Label and Curriculum Learning [J]. J Shanghai Jiaotong Univ Sci, 2023, 28(6): 703-716. |
| [4] | CHEN Peizhi1,2* (陈培芝), GUO Yifan1 (郭逸凡),WANG Dahan1,2 (王大寒), CHEN Chinling1,3,4* (陈金铃). Dlung: Unsupervised Few-Shot Diffeomorphic Respiratory Motion Modeling [J]. J Shanghai Jiaotong Univ Sci, 2023, 28(4): 536-. |
| [5] | LI Yu, YANG Daoyong, LIU Lingya, WANG Yiyin. Underwater Image Enhancement Based on Generative Adversarial Networks [J]. Journal of Shanghai Jiao Tong University, 2022, 56(2): 134-142. |
| [6] | WU Guangli, GUO Zhenzhou, LI Leiting, WANG Chengxiang. Video Abnormal Detection Combining FCN with LSTM [J]. Journal of Shanghai Jiao Tong University, 2021, 55(5): 607-614. |
| [7] | WU Ying (吴莹), LOU Lin (娄琳), WANG Jun (汪军). Global Fabric Defect Detection Based on Unsupervised Characterization [J]. J Shanghai Jiaotong Univ Sci, 2021, 26(2): 231-238. |
| [8] | JIANG Yudi, HU Hui, YIN Yuehong. Unsupervised Transfer Learning for Remaining Useful Life Prediction of Elevator Brake [J]. Journal of Shanghai Jiao Tong University, 2021, 55(11): 1408-1416. |
| [9] | HU Jing* (胡静), LUO Yiyuan (罗宜元). Integration of Learning Algorithm on Fuzzy Min-Max Neural Networks [J]. Journal of Shanghai Jiao Tong University (Science), 2017, 22(6): 733-741. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||