上海交通大学学报 ›› 2025, Vol. 59 ›› Issue (1): 70-78.doi: 10.16183/j.cnki.jsjtu.2023.188
杨映荷1, 魏汉迪1,2( ), 范迪夏3, 李昂3
), 范迪夏3, 李昂3
收稿日期:2023-05-11
修回日期:2023-06-14
接受日期:2023-06-19
出版日期:2025-01-28
发布日期:2025-02-06
通讯作者:
魏汉迪,助理研究员;E-mail: 作者简介:杨映荷(2001—),硕士生,主要研究方向为流体智能控制.
基金资助:
YANG Yinghe1, WEI Handi1,2(), FAN Dixia3, LI Ang3
Received:2023-05-11
Revised:2023-06-14
Accepted:2023-06-19
Online:2025-01-28
Published:2025-02-06
摘要:
为了克服水下工作环境的复杂多变性,以及扑翼运动本身存在控制难度高、变量多、非线性特征显著等问题,提出一种直接探索环境并选取相应最优扑翼推进运动参数的寻优方法.采用拉丁超采样技术获取多维扑翼参数在实际水池中的数据样本,并基于该数据使用高斯过程回归(GPR)算法建立泛化工作环境的非参数模型.在不同推进性能需求下,采用深度强化学习(DRL)中的TD3算法并以奖励最大化为目标,训练得出连续区间内多参数动作最优组合解.实验结果表明,该GPR-TD3方法可以习得实验环境下扑翼推进的全定义域内最优解,包括最大速度和最大效率,并且该最优解可以在GPR中以二维形式直观验证其准确性.同时,针对任意给出的推进速度要求值,在290组真实样本前提下,新算法能够给出误差范围为0.23%~6.68%的推荐动作组合解,为真实应用提供参考.
中图分类号:
杨映荷, 魏汉迪, 范迪夏, 李昂. 基于高斯过程回归和深度强化学习的水下扑翼推进性能寻优方法[J]. 上海交通大学学报, 2025, 59(1): 70-78.
YANG Yinghe, WEI Handi, FAN Dixia, LI Ang. Optimization Method of Underwater Flapping Foil Propulsion Performance Based on Gaussian Process Regression and Deep Reinforcement Learning[J]. Journal of Shanghai Jiao Tong University, 2025, 59(1): 70-78.
表1
变量区间范围
| 参数 | 下边界 | 上边界 |
|---|---|---|
| 横荡(首摇)频率,f/Hz | 0.5 | 0.7 |
| 首摇运动幅值,z0/(°) | 25 | 55 |
| 横荡运动幅值,y0/mm | 20 | 65 |
| 运动相位差,ϕ/rad | 0.52 | 5.76 |
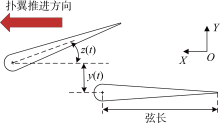
图1
扑翼耦合运动示意图

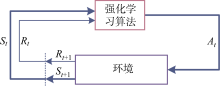
图2
强化学习算法框架简图

表2
GPR常用核函数
| 核函数 | 函数关系式 |
|---|---|
| Matern 3/2 | k(xi, xj|θ)=σ2exp |
| Matern 5/2 | k(xi, xj|θ)=σ2 |
| ARD Matern 3/2 | k(xi, xj|θ)=σ2(1+ |
| ARD Matern 5/2 | k(xi, xj|θ)=σ2 |
| Squared exponential | k(xi, xj|θ)=σ2exp |
| Absolute exponential | k(xi, xj|θ)=σ2exp |
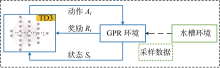
图3
GPR-TD3方法整体流程图

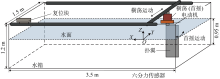
图4
扑翼推进装置布置示意图

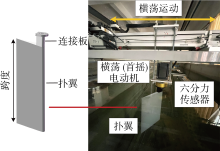
图5
扑翼三维示意图

表3
联合运动参数与扑翼推进速度的GPR算法参数
| 核函数 | Ls | Nl | On | M | R | P |
|---|---|---|---|---|---|---|
| Matern 3/2 | 0.000 688 | 71 523 | 16 | 2.128 | 3.108 | 0.864 |
| Matern 5/2 | 0.000 562 | 11 281 | 12 | 12.597 | 16.011 | 0.640 |
| ARD Matern 3/2 | [2.385 7.976 6.998 4.158] | 39 948 | 1 | 2.128 | 3.108 | 0.864 |
| ARD Matern 5/2 | [5.088 1.123 8.345 5.086] | 32 307 | 18 | 12.597 | 16.011 | 0.640 |
| Squared exponential | 0.008 38 | 19 108 | 7 | 1.274 | 1.516 | 0.956 |
| Absolute exponential | 0.007 72 | 32 667 | 100 | 1.006 | 1.832 | 0.957 |
表4
联合运动参数与扑翼推进效率的GPR算法参数
| 核函数 | Ls | Nl | On | M | R | P |
|---|---|---|---|---|---|---|
| Matern 3/2 | 0.689 | 11 820 | 13 | 0.010 9 | 0.014 6 | -0.645 |
| Matern 5/2 | 0.946 | 79 233 | 3 | 0.010 9 | 0.014 7 | -0.621 |
| Squared exponential | 0.001 12 | 39 666 | 2 | 0.010 9 | 0.014 6 | 0.250 |
| Absolute exponential | 0.043 3 | 46 725 | 5 | 0.010 9 | 0.014 7 | -0.931 |

图6
推进速度平均奖励曲线和推进效率最优奖励曲线


图7
推进速度动作收敛位置及对应GPR二维等高线图

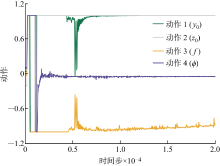
图8
推进效率动作收敛位置
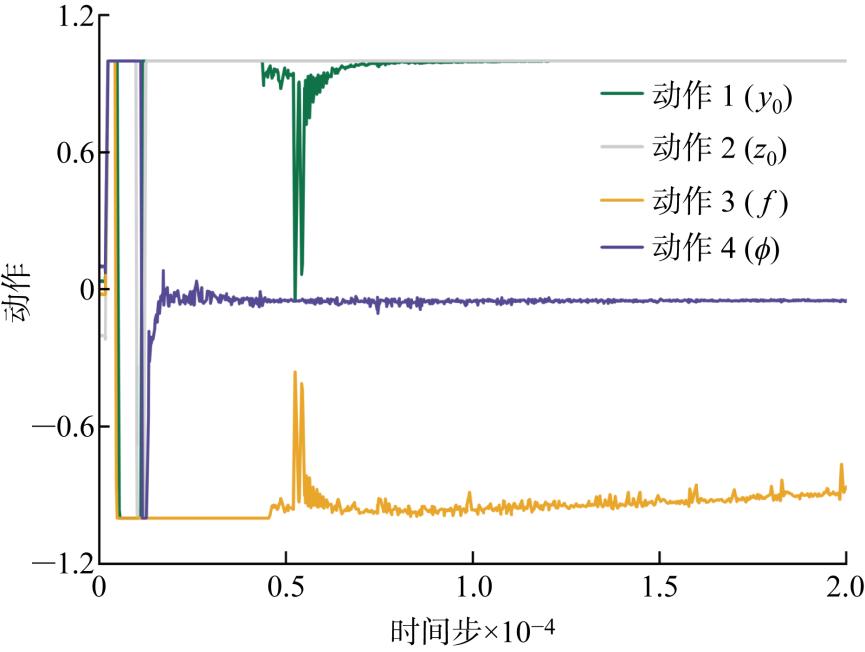
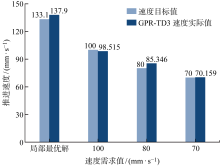
图9
速度目标值与GPR-TD3速度实际值对比结果

表5
传统TD3算法与GPR-TD3方法所需样本数量及习得动作
| 类别 | 传统强化学习样本数量 | GPR-TD3样本数量 | 动作向量 |
|---|---|---|---|
| 推进速度局部最优 | 9 200 | 290 | [ |
| 推进效率局部最优 | 6 200 | 290 | [ |
| 推进速度100 mm/s | 5 300 | 290 | [ |
| 推进速度80 mm/s | 5 900 | 290 | [ |
| 推进速度70 mm/s | 4 300 | 290 | [ |
| [1] | MANNAM N, KRISHNANKUTTY P, VIJAYAKUMARAN H, et al. Experimental and numerical study of penguin mode flapping foil propulsion system for ships[J]. Journal of Bionic Engineering, 2017, 14(4): 770-780. |
| [2] | WU X, ZHANG X, TIAN X, et al. A review on fluid dynamics of flapping foils[J]. Ocean Engineering, 2020, 195: 106712. |
| [3] | ASHRAF M A, YOUNG J, LAI J C A, et al. Oscillation frequency and amplitude effects on plunging airfoil propulsion and flow periodicity[J]. AIAA Journal, 2012, 50(11): 2308-2324. |
| [4] | KHALID M, AKHTAR I, IMTIAZ H, et al. On the hydrodynamics and nonlinear interaction between fish in tandem configuration[J]. Ocean Engineering, 2018, 157: 108-120. |
| [5] | DAS A, SHUKLA R K, GOVARDHAN R N. Existence of a sharp transition in the peak propulsive efficiency of a low-Re pitching foil[J]. Journal of Fluid Mechanics, 2016, 800: 307-326. |
| [6] | MACKOWSKI A W, WILLIAMSON C H K. Direct measurement of thrust and efficiency of an airfoil undergoing pure pitching[J]. Journal of Fluid Mechanics, 2015, 765: 524-543. |
| [7] | AMIRALAEI M R, ALIGHANBARI H, HASHEMI S M. An investigation into the effects of unsteady parameters on the aerodynamics of a low Reynolds number pitching airfoil[J]. Journal of Fluids and Structures, 2010, 26(6): 979-993. |
| [8] | SCOTT F, HERKE H, DAVID M. Addressing function approximation error in actor-critic methods[C]// Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018: 1587-1596. |
| [9] | THAKOR M, KUMAR G, DAS D, et al. Investigation of asymmetrically pitching airfoil at high reduced frequency[J]. Physics of Fluids, 2020, 32(5): 053607. |
| [10] | CHENG M, JIAO L, YAN P, et al. Prediction of surface residual stress in end milling with Gaussian process regression[J]. Measurement, 2021, 178(11): 109333. |
| [11] | GARNIER P, VIQUERAT J, RABAULT J, et al. A review on deep reinforcement learning for fluid mechanics[J]. Computers & Fluids, 2021, 225: 104973. |
| [1] | 周毅, 周良才, 史迪, 赵小英, 闪鑫. 基于安全深度强化学习的电网有功频率协同优化控制[J]. 上海交通大学学报, 2024, 58(5): 682-692. |
| [2] | 崔显, 陈自强. 基于ECM和SGPR的高鲁棒性锂离子电池健康状态估计方法[J]. 上海交通大学学报, 2024, 58(5): 747-759. |
| [3] | 董玉博1, 崔涛1, 周禹帆1, 宋勋2, 祝月2, 董鹏1. 基于长周期极坐标系追击问题的多智能体强化学习奖赏函数设计方法[J]. J Shanghai Jiaotong Univ Sci, 2024, 29(4): 646-655. |
| [4] | 李舒逸, 李旻哲, 敬忠良. 动态环境下基于改进DQN的多智能体路径规划方法[J]. J Shanghai Jiaotong Univ Sci, 2024, 29(4): 601-612. |
| [5] | 苗镇华1, 黄文焘2, 张依恋3, 范勤勤1. 基于深度强化学习的多模态多目标多机器人任务分配算法[J]. J Shanghai Jiaotong Univ Sci, 2024, 29(3): 377-387. |
| [6] | 全家乐, 马先龙, 沈昱恒. 基于近端策略动态优化的多智能体编队方法[J]. 空天防御, 2024, 7(2): 52-62. |
| [7] | 朱浩然, 陈自强, 杨德庆. 基于差分热伏安法和高斯过程回归的锂离子电池健康状态估计[J]. 上海交通大学学报, 2024, 58(12): 1925-1934. |
| [8] | 张威振, 何真, 汤张帆. 风扰下无人机栖落机动的强化学习控制设计[J]. 上海交通大学学报, 2024, 58(11): 1753-1761. |
| [9] | 马驰, 张国群, 孙俊格, 吕广喆, 张涛. 基于深度强化学习的综合电子系统重构方法[J]. 空天防御, 2024, 7(1): 63-70. |
| [10] | 王子垚, 郭凤祥, 陈俐. 基于外推高斯过程回归方法的发动机排放预测[J]. 上海交通大学学报, 2022, 56(5): 604-610. |
| [11] | 李鹏, 阮晓钢, 朱晓庆, 柴洁, 任顶奇, 刘鹏飞. 基于深度强化学习的区域化视觉导航方法[J]. 上海交通大学学报, 2021, 55(5): 575-585. |
| [12] | 何德峰, 彭彬彬, 顾煜佳, 余世明. 基于高斯过程回归的车辆巡航系统学习预测控制[J]. 上海交通大学学报, 2020, 54(9): 904-909. |
| [13] | 刘健,陈自强,黄德扬,郑昌文,周诗尧,姜余. 基于等压差充电时间的锂离子电池寿命预测[J]. 上海交通大学学报, 2019, 53(9): 1058-1065. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||