

模型驱动方法需要搭建故障电路模型[7-8],对于不同故障类型需重新进行仿真,且存在个别类型难以仿真的缺点,因此不进行重点讨论.数据驱动方法则根据数据推导波形和事件类别之间的关系,具有较强的自适应性,在配电网故障辨识这一小样本学习任务中,只需减少方法的数据依赖性即可.现有数据驱动方法无法处理上述场景的原因主要在于模型表达能力和对数据需求量之间的矛盾.文献[9]中使用 Logistic 算法识别配电网故障,但实验中使用的数据量较大,算法拟合能力也不强,只能用于二分类任务;文献[10]中首先利用局部特征尺度分解法构造波形时频矩阵,再利用支持向量机(SVM)区分时频矩阵的奇异谱,从而区分故障类别,该方法同样未考虑小样本学习问题,且不具备迁移能力;文献[11]中使用小波分解滤除波形中的谐波和非周期分量,将剩余的工频信息作为输入训练神经网络,从而判断故障短路相,由于模型只使用工频信息,所以对于暂态故障识别效果较差,且模型对数据需求仍然较大.综上所述,在现有数据驱动方法中,高复杂度模型的表达能力较强,能处理多种类型故障,但对数据需求量较高;而简单模型则牺牲部分表达能力以减少对训练样本的需求.
配电网故障辨识任务中的波形数据本质为时间序列,对于时序数据,需要考虑不同时刻间的相关性,而自然语言处理领域有较多关于序列相关性建模的研究[12⇓-14],其中门控循环网络(GRU)能更好地捕捉时间序列中的长距离依赖,即较大时间间隔的时刻间相关关系,因此受到广泛关注.不仅如此,近些年提出的模拟人类认知的视觉注意力机制[15]同样能有效降低数据依赖度.尽管上述方法在其他领域中一定程度上解决了模型数据需求量过大的问题,但在配电网故障辨识中还未得到充分应用.配电网故障辨识任务中波形数据独有的特征,如数据具备周期性、信息密度小、不同相的电压电流波形间存在对应关系等,使得针对这一场景的特定开发和改进策略成为关键.
针对上述问题,提出一种基于门控循环注意力网络(GRAN)的配电网故障辨识方法,该模型基于注意力机制捕捉波形中的关键信息,从而降低对训练数据的需求,同时借助循环神经网络的结构存储波形记忆,有效处理序列数据.具体实现思路如下:对于关注的信息,利用非线性映射获得对应的权重向量,通过加权运算实现关键区域提取;对于波形序列信息,传递不同阶段的隐含层信息作为记忆,该记忆信息和当前阶段的输入共同决定当前阶段的输出.基于仿真数据和实际数据的实验均表明,该方法明显优于其余几种常用的分类模型,为配电网故障辨识研究提供了一种全新的思路.
1 模型框架
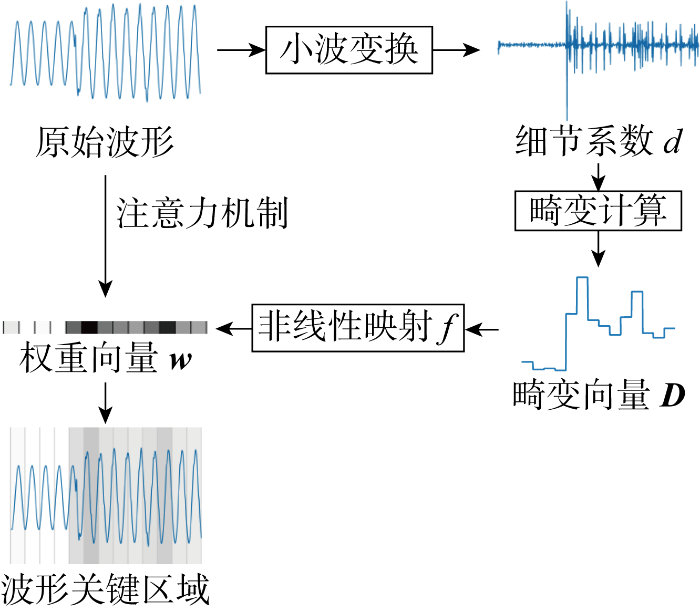
1.1 基于注意力机制的关键区域提取
配电网故障波形辨识存在关键区域,即人类在认知波形时往往会关注波形发生变化的周期和其中故障出现或消失的时刻.由于上述注意力机制,人类能够凭借少量样本学习波形中的重点特征,实现故障类型辨识.利用数学模型引入这一注意力机制,提取波形关键区域,减少训练样本量需求.
注意力机制可以被视为一种加权运算[15]:
式中:xin、xout∈Rn×c分别为输入特征和输出特征,其中n为特征维度,c为通道数;w∈Rn为权重向量;算符表示逐元素相乘.对于被重点关注的特征维度i,其对应权重wi幅值远大于其余维度.
式中:Tl为特征维度集合;Norm为归一化操作.综合上述等式,可以获得波形关键区域提取框架,如图1所示.
图1
1.2 门控循环网络
式中:zt、rt分别为更新门和重置门的输出;Wz、Uz分别为更新门中当前阶段输入xt和前一阶段隐含层状态ht-1对应的权重;Wr、Ur分别为重置门中当前阶段输入xt和前一阶段隐含层状态ht-1对应的权重;σ为sigmoid激活函数.
更新门和重置门的输出本质是一种控制信号,其中重置门决定是否重置之前存储的隐含层信息,计算表达式为
式中:h't为当前阶段候选隐含层信息,即人类认知中的短期记忆;Wh、Uh分别为候选状态更新时当前阶段输入xt和前一阶段隐含层状态ht-1对应的权重;tanh为双曲正切激活函数;☉为逐位相乘操作.
而更新门决定如何更新当前阶段的隐含层信息,即长期记忆和短期记忆所占权重,计算表达式为
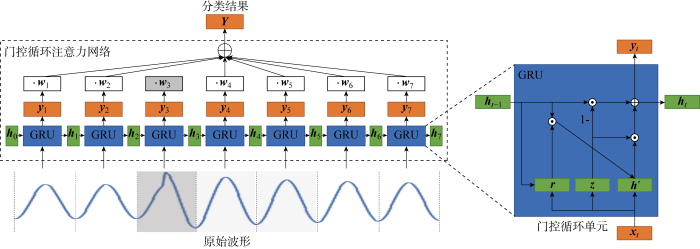
1.3 基于GRAN的故障类别判别
对于配电网中的一次异常事件,其故障类别需要综合三相电压、电流波形进行判断.首先讨论单一波形中的信息处理,单一波形中包含多个周期,且每个周期内包含不同的信息.基于单个周期的类别预测可由当前阶段的隐含层信息表示:
式中:yt∈RK为第t个周期内波形对应的预测概率,即yt, k∈[0,1]为该周期内波形属于第k个类别的概率,K为类别数;Wo为当前阶段隐含层信息ht对应的权重矩阵;σs为softmax函数.
由于单一波形中包含多个周期,所以需要综合考虑各周期对应的预测概率.在1.2节中提取了波形关键区域,获得了各周期对应的权重向量,因此将两者结合,如图2所示,获得最终的预测概率:
式中:Y∈RK为最终事件预测概率,即Yk∈[0,1]为该波形属于第k个类别的概率;wt∈R为基于注意力的第t个周期对应的权重;T为周期总数.
图2
前文讨论了基于单一波形的故障类别判别,下面考虑多波形,即三相电压、电流条件下的信息综合.通常情况下,配电网瞬时性故障类别根据故障相电流进行判断[5],但发生多相故障时,综合考虑多相电流波形更为合理.此外,由于模型的输入为故障点处的测量波形,此时的电压波形同样能帮助判断故障类型.首先考虑单相故障,单相故障条件下的相关波形为故障相电压U、电流I,利用GRAN分别对两组波形进行运算即可获得单波形下的类别预测概率YU、YI∈RK,其中YU为基于故障相电压波形的类别预测概率,YI为基于故障相电流波形的类别预测概率,此时电压、电流波形使用的网络参数各自独立.最终概率YE为两组概率YU、YI的平均值.对于多相故障或故障相未知的情况,需要综合考虑三相电压、电流波形.对于配电网故障,不同相对应的权重取决于该相故障严重程度,而这一指标往往与该相电流最大幅值相关[20].因此,利用注意力机制可以求得三相波形对应的权重向量并获得最终预测概率:
式中:
训练时直接使用交叉熵作为误差函数L,利用误差反向传播即可更新各个部分的权重矩阵,从而获得最佳权重,组成最佳预测模型.
式中:YE、
2 数据采集
考虑到数据完备性和真实性,采集的数据分为两部分:仿真数据和实际数据.使用仿真数据的目的在于获得各种工况下的数据,由于实际数据较少,所以必须利用仿真获取;使用实际数据的目的在于验证模型性能,由于仿真数据和实际数据存在偏差,所以有必要在两种数据下同时进行测试.
2.1 仿真系统
在电磁暂态仿真软件PSCAD/EMTDC中搭建配电网10 kV架空线路仿真系统,该系统基于IEEE 13节点模型[21],系统结构如图3所示,并采用非直接接地方式.其中,系统频率为50 Hz,采样频率为 4 096 Hz,采样长度为16个周波.仿真事件类型包含瞬时性故障、永久性故障和暂态干扰3种.仿真中随机选取参数以模拟各种条件下的配电网故障数据.变化参数包含噪声强度、短路电阻、故障起始角、故障位置、故障距离、故障电弧参数、负载参数、线路参数.此外,各种子类型均考虑在内,如不同故障相数(单相接地、相间、多相接地)和不同暂态干扰类型(负载变化、电容器投切).仿真数据中瞬时性故障、永久性故障和暂态干扰事件各120起,共计360起.
图3
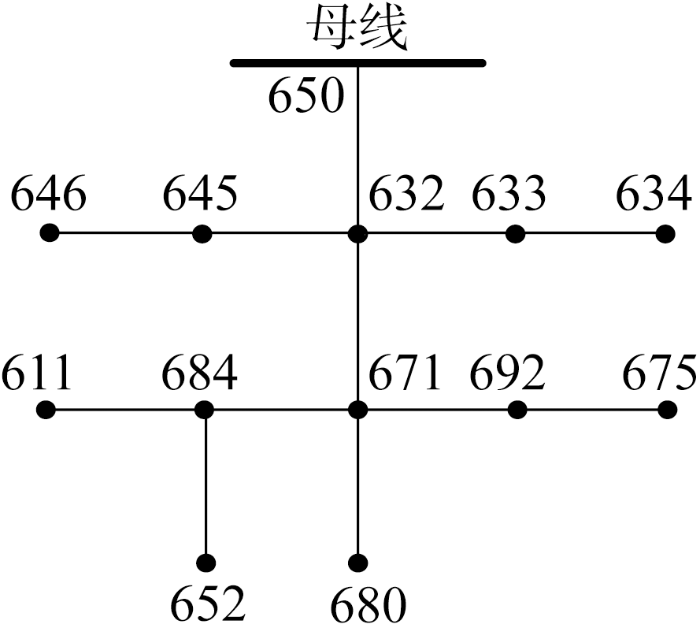
图3
配电网10 kV架空线路模型
Fig.3
Overhead line model in a 10 kV-class power distribution system
具体参数和条件设置如下.
(1) 噪声级别:仿真中使用不同信噪比的白噪声.
(2) 电弧模型和参数:采用Kizilcay的电弧模型模拟瞬时故障,该模型下的电弧公式可写为
式中:τ为任意时刻;g(τ)为电弧电导率;if(τ)为电弧电流;uf(τ)为电弧电压;ct为电弧时间常数;uo为特征电弧电压;ro为特征电弧阻抗.各参数对应的取值范围为ct=0.2~0.4 ms,uo=300~4 000 V,ro=0.01~0.015 Ω.每次仿真随机设定上述参数值.
(3) 故障电阻、起始角和距离:短路电路中除电弧以外还设置了其他的故障电阻.每次仿真时随机选定故障电阻设定值、故障起始角设定值以及故障距离设定值.
(4) 故障位置、电容投切位置和负载变化位置:每次仿真随机选定故障位置、电容投切位置以及负载变化位置.
(5) 线路参数(单位长度电阻、电感和电容)与负载参数(有功功率和无功功率):每次仿真随机选定线路参数设置值以及负载参数设置值.
2.2 实验数据
整个数据集包含4种类型的设备:避雷器、变压器柔性电缆、变压器肘型头和架空线.其中故障原因包含雷击引起避雷器本体炸裂击穿、避雷器上引线触碰横担、接地故障引起变压器柔性电缆烧毁、接地故障引起变压器肘型头绝缘击穿、架空线树线矛盾.除了展示波形,还给出各种事件类型对应的数量:避雷器故障有24起,变压器柔性电缆故障有18起,变压器肘型头故障有61起,架空线故障有22起,共计125起.
图4

3 实验验证
将GRAN模型同另外3种常用的分类器: SVM、梯度提升决策树(GBDT)、CNN进行比较,以体现本文方法的优越性.
3.1 实验数据说明
使用仿真数据和实际数据进行实验,每种实验进行20次,每次随机划分训练集、验证集和测试集,划分比例为3∶1∶1,以消除事件类型分布的影响.输入波形数据首先经过小波去噪以及幅值归一化处理.门控循环单元数量与周期数一致,对于仿真数据和实际数据而言均为16,每一阶段输入特征维度等于单周期采样点数,对于仿真数据和实际数据而言均为82.模型训练在训练集中进行,超参数确定在验证集中进行,最终性能测试在测试集中进行.
实验中使用的评价指标说明如下:分类任务需要综合考虑准确率p和召回率r,两者的调和平均数即F1分数[23]通常作为模型评价指标.其定义如下:p为模型判断为正的样本中分类正确率,r为实际正样本中模型对应的检出率.对于多分类问题,平均F1分数取各类别F1分数的平均值.
3.2 对比其他模型
图5
各模型实现细节如下:SVM模型在MATLAB环境中进行,使用工具为libsvm软件包[26],SVM类型为C分类,核函数选择多项式函数,核函数中的gamma值和惩罚因子通过交叉验证确定.GBDT在python环境中进行,使用工具为xgboost软件包[27],每棵随机采样的特征的占比(colsample_bytree)参数为0.7,最小子节点权重为3,学习率(eta)为0.1.SVM方法参考文献[16],首先利用3层db4小波基函数对波形进行分解,提取近似系数和细节系数的每个周期内最大幅值作为输入特征向量,由于存在多组波形,所以将每个波形的输入特征向量拼接得到最终输入特征.CNN在python环境中进行,使用tensorflow框架,其结构参数如下:假设采样总长度为N,则输入层尺寸为(1,N,6).对于基于实际数据的实验,由于训练数据较少,所以使用了基于仿真数据的预训练网络.
表中事件类别说明如下:仿真类别1、2、3分布代表暂态故障、永久性故障和暂态干扰,实验类别1、2、3、4分别代表避雷器故障、变压器柔性电缆故障、变压器肘型头故障和架空线树线矛盾.首先对比不同模型的F1分数(见表1),可以看到,GRU的分类准确率优于其余3种模型.这是因为GRU考虑了不同阶段的输入之间的关系,对不同周期间的相关性进行有效建模.而其余几种模型只是单纯将不同周期内的特征视作不同输入属性.其次,相比于SVM和GBDT,GRU和CNN在实际数据上的表现更好,这是因为后两个模型使用了基于仿真数据的预训练网络.预训练网络中保留的权重对应特征提取层,通过较多的仿真数据可以获得较好的特征提取效果,再通过实际数据微调网络参数就可以大大降低模型的数据依赖性.
表1 不同模型F1分数对比
Tab.1
| 模型 | 仿真类别 | 平均值 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | |||||||
| GRU | 0.902 | 0.941 | 0.887 | 0.910 | |||||
| SVM | 0.810 | 0.841 | 0.815 | 0.822 | |||||
| GBDT | 0.832 | 0.869 | 0.844 | 0.848 | |||||
| CNN | 0.871 | 0.890 | 0.867 | 0.876 | |||||
| 模型 | 实验类别 | 平均值 | |||||||
| 1 | 2 | 3 | 4 | ||||||
| GRU | 0.862 | 0.871 | 0.854 | 0.831 | 0.855 | ||||
| SVM | 0.720 | 0.704 | 0.731 | 0.719 | 0.719 | ||||
| GBDT | 0.762 | 0.774 | 0.785 | 0.747 | 0.767 | ||||
| CNN | 0.790 | 0.807 | 0.820 | 0.787 | 0.801 | ||||
其次,对比不同模型的平均F1分数分布情况(见图6),这一结果体现了模型的性能稳定性,即事件类型分布对模型性能的影响程度.可以看到,所提方法最适合在配网故障辨识这一场景中使用.这是因为GRAN的分类准确率在平均值附近波动,较为稳定.相比之下,SVM和GBDT的准确率整体水平较低,无法应用于实际场景中,CNN参数量高、数据需求大,其准确率受数据类型分布影响大.
图6
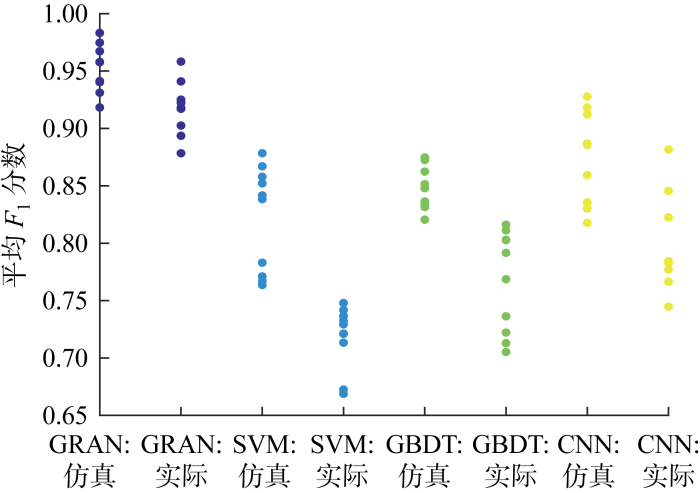
3.3 注意力机制对应的性能提升
对比GRU和所提GRAN.GRAN训练流程如下:首先,利用3层dB4小波基函数对原始波形进行分解,利用最后一层细节系数计算畸变向量,再利用两层全连接神经网络对畸变向量进行映射获得权重向量;然后,将波形输入GRAN输出类型预测结果.由于单起事件中存在三相电压、三相电流共6组波形,所以需要对每组波形进行上述运算,再对每组波形预测概率进行加权平均.需要说明的是,每组波形使用不同的网络参数,即本次实验一共训练6个GRAN,分别用于处理三相电压和三相电流数据.同时,由于实际数据量太小,利用真实数据进行实验时使用的是基于仿真数据的预训练模型.对每个波形而言,畸变向量到权重向量的非线性映射拟合采用两层全连接神经网络,两层隐含层神经元个数均为周期数.对于每个事件而言,电流幅值向量到三相权重向量的非线性映射拟合采用两层全连接神经网络,两层隐含层神经元个数均为相数.这里畸变向量到权重向量的非线性映射在同类型波形间共享,电流幅值向量到三相权重向量的非线性映射在所有事件中共享.
表2给出GRAN和GRU的性能,仿真类别1、2、3分布代表暂态故障、永久性故障和暂态干扰,实验类别1、2、3、4分别代表避雷器故障、变压器柔性电缆故障、变压器肘型头故障和架空线树线矛盾.可以看到,该模型适用于仿真数据和实际数据中的各种事件类型,即具备良好的泛化性能.同时,注意力机制使得模型相较于GRU性能进一步提升.
表2 本文所提模型在不同事件类别下的F1分数
Tab.2
| 模型 | 仿真类别 | 平均值 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | |||||||
| GRAN | 0.940 | 0.977 | 0.930 | 0.949 | |||||
| GRU | 0.902 | 0.941 | 0.887 | 0.910 | |||||
| 模型 | 实验类别 | 平均值 | |||||||
| 1 | 2 | 3 | 4 | ||||||
| GRAN | 0.921 | 0.940 | 0.901 | 0.897 | 0.915 | ||||
| GRU | 0.862 | 0.871 | 0.854 | 0.831 | 0.855 | ||||
以基于单波形的故障类别判别为例,在综合各周期预测概率阶段,注意力机制使得畸变较为严重的周期对应的权重更高,这导致最终预测结果主要参考畸变较为严重的周期.这一基于领域知识的机制有效提高了预测准确率.这里称畸变较为严重的周期为关键周期,其余周期为非关键周期.不同类型故障在非关键周期差异不大,因此预测概率趋近于各类别均匀分布.但在关键周期,通过波形特征能很好地判断故障类型,此时预测概率集中分布在目标类别.赋予关键周期预测结果更高的权重,使得最终综合预测结果更加准确.另外,由于关键周期对应权重更高,误差反向传播时,GRU参数更新主要在关键周期对应的阶段进行.这一现象可近似看作截取关键周期波形数据训练网络,数据维度下降,模型对数据需求量相应减少.上述分析基于单波形条件下的故障类别判别,对于多波形条件下的故障类别判别,所提模型同样利用注意力机制确定了主要故障相,最终预测结果也主要参考主要故障相下的电压、电流信息.此外,作为所提框架的基础,GRU能够有效处理序列数据,建立起不同阶段间的依赖关系,对提升准确率同样起到关键作用.上述实验结果及分析表明,该模型为解决配电网故障识别中小样本学习这一关键问题提供了一种全新且有效的思路.
4 结语
在配电网故障辨识任务中,样本收集困难,降低模型数据需求量成为研究关键.GRAN借助注意力机制和循环神经网络结构有效提取序列中的关键信息,进而准确识别配电网故障类型.其中,注意力机制本质是一种加权运算,通过输入关注信息经由非线性映射获得权重向量;循环神经网络则是通过传递隐含层状态,建立起不同阶段输入、输出之间的关系,进而有效处理序列信息.基于仿真数据和实际数据的实验表明,该方法在配电网不同设备故障识别任务中准确率明显优于其余几种常用分类方法,推进了配电网智能化进程.
参考文献
基于智能控制终端的主动配电网故障处理方法
[J].
Research on fault processing of active power distribution network based on intelligent control terminal
[J].
数据驱动的配电开关设备交互式诊断平台
[J].
DOI:10.12067/ATEEE1810004
[本文引用: 1]

高效和准确的设备缺陷诊断有助于提升配电网运行可靠性和安全性。受益于信息化建设,配电设备到货抽检、型式试验、在线监测等环节积累了大量检测大数据,奠定了数据挖掘和智能诊断的基础。为了满足配电设备智能运维需求,本文提出了一种大数据驱动的配电开关设备故障交互式诊断方法。利用设备的物理模型、历史故障诊断结果、在线监测数据以及仿真结果,所提方法挖掘故障表征与潜在缺陷间的关联关系,并训练贝叶斯网络,实现设备缺陷推理。进一步,根据试验人员的反馈调整诊断结果,提出设备故障的交互式诊断方法,通过动态修正推理模型,提升检测准确性。实际案例测试说明所提方法的有效性。
Data-driven and interactive fault diagnosis of distribution switches
[J].
输配电设备泛在电力物联网建设思路与发展趋势
[J].
Construction ideas and development trends of transmission and distribution equipment of the ubiquitous power internet of things
[J].
配电线路早期故障辨识方法
[J].
Detection method of incipient faults of power distribution lines
[J].
Detection of incipient faults in distribution under-ground cables
[J].DOI:10.1109/TPWRD.2010.2041373 URL [本文引用: 3]
基于暂态波形相关性的配电网故障定位方法
[J].
Fault location method for distribution network based on transient waveform correlation
[J].
Synchronous waveform measurements to locate transient events and incipient faults in power distribution networks
[J].DOI:10.1109/TSG.2021.3081017 URL [本文引用: 2]
Model-based general arcing fault detection in medium-voltage distribution lines
[J].DOI:10.1109/TPWRD.2016.2518738 URL [本文引用: 1]
Logistic分类算法下的配电网故障识别技术研究
[J].
Research on fault identification technology of distribution network based on Logistic classification
[J].
基于LCD-Hilbert谱奇异值和多级支持向量机的配电网故障识别方法
[J].
Identification method of distribution network faults based on singular value of LCD-Hilbert spectrums and multilevel SVM
[J].
基于小波神经网络的配电网故障类型识别
[J].
Fault type identification in distribution network based on wavelet neural network
[J].
融合FCN和LSTM的视频异常事件检测
[J].
DOI:10.16183/j.cnki.jsjtu.2020.120
[本文引用: 1]
针对传统视频异常检测模型的缺点,提出一种融合全卷积神经(FCN)网络和长短期记忆(LSTM)网络的网络结构.该网络结构可以进行像素级预测,并能精确定位异常区域.首先,利用卷积神经网络提取视频帧不同深度的图像特征;然后,把不同的图像特征分别输入记忆网络分析时间序列的语义信息,并通过残差结构融合图像特征和语义信息;同时,采用跳级结构集成多模态下的融合特征并进行上采样,最终获得与原视频帧大小相同的预测图.所提网络结构模型在加州大学圣地亚哥分校(UCSD)异常检测数据集的ped 2子集和明尼苏达大学(UMN)人群活动数据集上进行测试,均取得了较好的结果.在UCSD上的等错误率低至6.6%,曲线下面积达到了98.2%, F<sub>1</sub>分数达到了94.96%;在UMN上的等错误率低至7.1%,曲线下面积达到了93.7%,F<sub>1</sub>分数达到了94.46%.
Video abnormal detection combining FCN with LSTM
[J].
基于特征金字塔卷积循环神经网络的故障诊断方法
[J].
DOI:10.16183/j.cnki.jsjtu.2021.001
[本文引用: 1]
变工况、变载荷设备部件不同故障的特征在信号中所占比例和位置不固定,且包括大量不同场景下的原始振动信号的多尺度复杂性.对此,提出一种基于特征金字塔网络(FPN)的卷积循环神经网络(CRNN)滚动轴承故障诊断方法.利用卷积神经网络(CNN)框架,并联CNN的卷积层和循环神经网络(RNN)中的长短时记忆(LSTM)层,形成新的CRNN,以充分利用CNN对空间域信息和RNN对时域信息的学习能力;在每一层中权值共享,减少网络参数;利用FPN构建全新特征图,输入一维信号和堆叠后形成的二维信号,对传感器采集的信号进行特征提取,实现故障诊断.利用行星齿轮箱进行故障试验,并进行5折交叉验证,该方法的诊断准确率平均值为99.20%,比基本神经网络模型至少高3.62%,表明该方法诊断精度高、鲁棒性强;利用凯斯西储大学轴承数据集进行验证,证明该方法具有良好的泛用性;利用t-SNE方法对模型的特征学习效果进行可视化分析,结果表明不同故障类别特征具有良好的聚类效果.
A fault diagnosis method based on feature pyramid CRNN network
[J].
基于长短期记忆神经网络的板裂纹损伤检测方法
[J].
DOI:10.16183/j.cnki.jsjtu.2020.095
[本文引用: 1]
针对板不同位置裂纹损伤的智能分类问题,提出了一种基于长短期记忆(LSTM)神经网络的板裂纹损伤检测方法.采用Abaqus二次开发建立板裂纹损伤模型,计算高斯白噪声激励下板的加速度响应,并通过数据扩充方法生成数据集,同时考虑了噪声对损伤检测的影响.建立基于LSTM的板裂纹智能检测模型,直接将板的加速度响应作为输入,不需要额外的损伤特征提取,并以最小预测误差为目标,选择模型的超参数,优化模型配置.与多层感知机模型和基于小波包变换的多层感知机模型进行对比表明,本文提出的LSTM模型在板裂纹损伤检测中具有更高的损伤定位精度和更好的适用性.
Method for plate crack damage detection based on long short-term memory neural network
[J].
DOI:10.16183/j.cnki.jsjtu.2020.095
[本文引用: 1]
Aimed at the problem of intelligent classification of crack damage in different positions of the plate, a method for plate crack damage detection based on long short-term memory (LSTM) neural network is proposed. The Abaqus secondary development is used to build the plate crack damage model and calculate the acceleration response of the plate under Gaussian white noise excitation. The data set is generated by data augmentation, and the influence of noise on damage detection is considered. An intelligent crack detection model based on LSTM is established, which directly takes the acceleration response of the plate as the input and does not require additional damage feature extraction. With the goal of minimizing prediction error, the hyperparameter of the model is selected and the model configuration is optimized. The comparison of the multi-layer perceptron model and the multi-layer perceptron model based on wavelet packet transform shows that the LSTM model proposed in this paper has a higher damage location accuracy and a better applicability in plate crack detection.
Attention is all you need
[C]//
Incipient fault identification in power distribution systems via human-level concept learning
[J].DOI:10.1109/TSG.5165411 URL [本文引用: 2]
A novel connectionist system for unconstrained handwriting recognition
[J].
Long short-term memory
[J].
DOI:10.1162/neco.1997.9.8.1735
PMID:9377276
[本文引用: 1]
Learning to store information over extended time intervals by recurrent backpropagation takes a very long time, mostly because of insufficient, decaying error backflow. We briefly review Hochreiter's (1991) analysis of this problem, then address it by introducing a novel, efficient, gradient-based method called long short-term memory (LSTM). Truncating the gradient where this does not do harm, LSTM can learn to bridge minimal time lags in excess of 1000 discrete-time steps by enforcing constant error flow through constant error carousels within special units. Multiplicative gate units learn to open and close access to the constant error flow. LSTM is local in space and time; its computational complexity per time step and weight is O(1). Our experiments with artificial data involve local, distributed, real-valued, and noisy pattern representations. In comparisons with real-time recurrent learning, back propagation through time, recurrent cascade correlation, Elman nets, and neural sequence chunking, LSTM leads to many more successful runs, and learns much faster. LSTM also solves complex, artificial long-time-lag tasks that have never been solved by previous recurrent network algorithms.
Learning phrase representations using RNN encoder-decoder for statistical machine translation
[EB/OL]. (
Waveform characteristics of underground cable failures
[C]//
Incipient faults monitoring in underground medium voltage cables of distribution systems based on a two-step strategy
[J].DOI:10.1109/TPWRD.61 URL [本文引用: 1]
新型配电网线路PMU装置的研制
[J].
Development of novel PMU device for distribution network lines
[J].
LightGBM: A highly efficient gradient boosting decision tree
[C]//
ImageNet classification with deep convolutional neural networks
[J].
DOI:10.1145/3065386
URL
[本文引用: 1]
We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes. On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0%, respectively, which is considerably better than the previous state-of-the-art. The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully connected layers with a final 1000-way softmax. To make training faster, we used non-saturating neurons and a very efficient GPU implementation of the convolution operation. To reduce overfitting in the fully connected layers we employed a recently developed regularization method called \"dropout\" that proved to be very effective. We also entered a variant of this model in the ILSVRC-2012 competition and achieved a winning top-5 test error rate of 15.3%, compared to 26.2% achieved by the second-best entry.
LIBSVM: A library for support vector machines
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}