

目前已有的单图像去雨算法主要分为模型驱动和数据驱动两类[5].在基于模型驱动的算法中,传统的滤波器[6]、字典学习[7]、稀疏编码[8]和高斯混合模型[9]等算法无法适应雨痕的多样性,从而导致去雨后的图像中残留大量雨痕.随着深度学习技术的发展,基于数据驱动的单图像去雨方法相比传统方法表现出更大优势.Fu等[10]将雨图分解为基础层和细节层,利用卷积神经网络 (Convolutional Neural Network, CNN) 去除细节层的雨痕,最后与增强后的基础层相加得到去雨图像.Wei等[11]利用有监督的合成雨图训练网络的同时加入无监督的自然雨图,从而提升网络在自然雨图上的泛化性能.Zhang等[12]基于雨痕的密度信息提出一种多流密集连接网络对雨痕进行去除.Yasarla等[13]利用不确定性引导的多尺度残差网络检测雨痕,再通过循环旋转机制得到去雨图像.Li等[14]将压缩激励机制和空洞卷积引入图像去雨网络,利用雨图的上下文信息去除雨痕.Ren等[15]提出一种循环渐进的单图像去雨基线网络,该网络在减小模型参数的同时能够提高去雨图像的质量.Jiang等[16]将不同分辨率尺度的雨图送入网络进行训练,并提出一种多尺度特征融合策略来得到去雨图像.Zamir等[17]将图像去雨分为多个阶段的子任务,利用编解码器网络学习特征,最后通过专门的恢复网络输出去雨图像.但是,现有的深度学习单图像去雨算法多是基于具有平移不变性和局部敏感性的CNN实现,并未有效利用雨图的全局性信息和像素间的长距离依赖关系,从而导致去雨后的图像损失部分细节和结构信息.
为有效解决上述问题以及充分利用雨图的全局性信息,受自注意力网络Transformer[18]的启发,本文提出一种基于窗口自注意力网络 (Swin Transformer) 的单图像去雨算法.该算法的网络输入层是一个上下文信息聚合块 (Context aGgregating Block, CGB),其采用并行多尺度空洞卷积来融合多个感受野的信息,从而在初始阶段使算法适应雨痕分布的多样性.深度特征提取网络利用CNN学习雨图的局部特征,同时利用Transformer学习全局性特征和像素点间的长距离依赖关系,从而获得更加准确的语义表达.此外,为保证去雨图像更加接近无雨图像和人眼的视觉特点,提出一种同时约束图像边缘和区域相似度的综合损失函数.
1 自注意力网络
Transformer是一种由编码器和解码器组成的深度神经网络,主要由多头自注意力机制 (Multi-head Self-Attention, MSA) 和多层感知机 (Multi-Layer Perceptron, MLP) 组成,其输入与输出都是向量.对于输入向量X0∈RN×D,其中N代表向量的个数,D代表向量的维度.在自然语言处理中,X0是句中单词的词符或字符序列.在计算机视觉中,X0则是图像的像素点序列.Transformer的关键在于自注意力机制强化特征学习,可以表示为
式中:Q,K,V分别为查询向量、键向量和值向量;dK为K的维度;B为可学习位置编码;SoftMax为激活函数;SA为单头自注意力计算结果.同时Q,K,V满足:
式中:PQ,PK,PV分别为Q,K,V的权重矩阵.Transformer利用MSA将多个自注意力的结果进行拼接,
式中:W0为权重矩阵;n为MSA自注意力头的个数;Concat代表按通道维度拼接特征图.之后,引入残差连接并进行标准化,
式中:
式中:X1为Transformer层的输出.
近年来Transformer在目标检测和图像分类等领域表现出巨大优势[19].相比CNN,Transformer能够有效提取图像全局性信息和建立像素点间长距离依赖关系,从而可利用较小的网络参数媲美甚至超越CNN的表现.但由于单图像去雨问题输入的分辨率往往很高,而经典Transformer中MSA的计算复杂度与分辨率呈平方关系,严重限制其在单图像去雨这类像素级计算机视觉任务中的应用.
2 本文算法
本文提出的基于窗口自注意力网络的单图像去雨算法的主要结构如图1所示.图中:RSTB为残差窗口自注意力网络块 (Residual Swin Transformer Block, RSTB);Conv为卷积层;D1、D2、D5分别表示该卷积层的扩张因子设置为1、2、5;©表示Concat操作;STL为窗口自注意力网络层 (Swin Transformer Layer, STL).该算法的主要流程为:雨图首先通过适应雨痕分布多样性的CGB进入网络,再通过由CNN和Transformer构成的密集残差窗口自注意力网络 (Dense Residual Swin Transformer, DRST) 来提取深度特征, 最后通过一个引入全局残差的卷积层输出去雨图像.
图1

图1
基于窗口自注意力网络的单图像去雨网络结构
Fig.1
Single image deraining network based on Swin Transformer
2.1 上下文信息聚合块
式中:k为卷积核的大小;d为扩张因子.
本文算法在网络输入层设计一种上下文信息聚合模块CGB,该模块利用空洞卷积扩大感受野来提取不同范围的雨痕分布信息.CGB根据文献[22]中采用扩张因子分别为1,2,5的并行空洞卷积,并将得到的雨图特征进行拼接,最后经过一个1×1卷积来融合特征,从而令算法具有适应不同雨痕分布的能力.因此,CGB一方面将输入雨图映射到高维空间,稳化网络训练过程的同时提高去雨效果;另一方面利用不同扩张因子的空洞卷积来自适应雨痕分布信息,提高网络对雨痕的泛化能力.CGB可以表示为
式中:x为输入雨图;Wk×k, d表示该层卷积核大小为k,扩张因子为d.
2.2 深度特征提取网络
2.2.1 窗口自注意力网络
随着对视觉Transformer的研究,Liu等[19]提出Swin Transformer,并在图像超分等领域[23]表现出良好的性能,如图2所示是其主要结构.图中:
图2
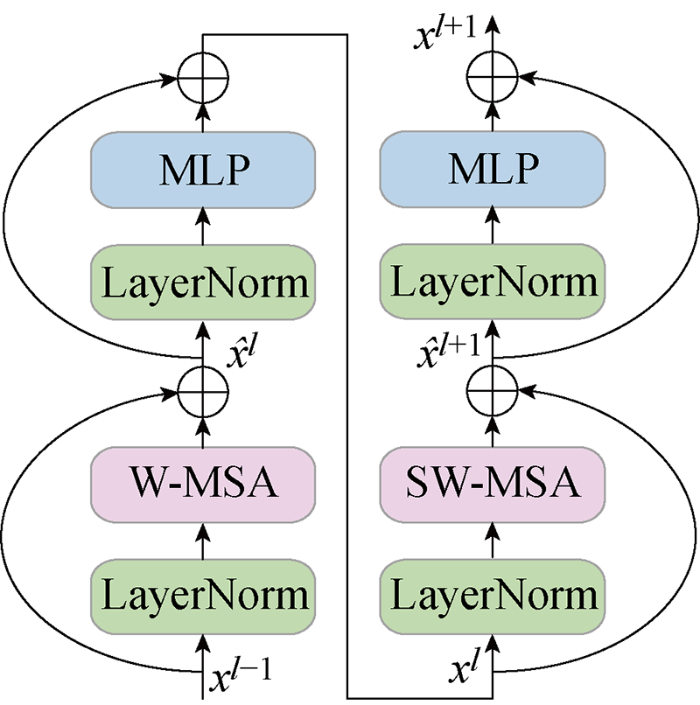
W-MSA存在的问题是其只在每个分割开的窗口内计算自注意力,不同窗口间未进行信息融合和传递.因此,在W-MSA之后使用移位窗口自注意力 (Shifted Window based on Multi-head Self-Attention, SW-MSA),即将原W-MSA中分割的窗口分别沿直角坐标的两个方向移动半个窗口大小的距离,从而实现相邻窗口间的信息交互.在实际操作中,SW-MSA是将前述窗口移位后得到的大小不一致的分割窗口进行重组,从而保证每个窗口的大小与原W-MSA窗口的大小一致,最后再使用掩膜隔绝不相邻区域来避免特征混淆.SW-MSA对移位窗口的重组示意图如图3所示.
图3
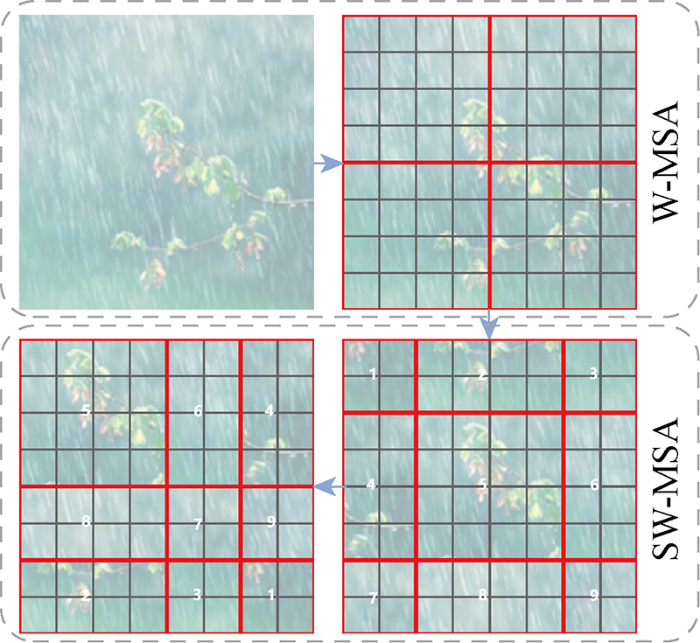
W-MSA的特征图经SW-MSA移位由原来的4个窗口变为9个窗口,且9个窗口的大小不完全一致,不利于后续计算.因此,SW-MSA继续将编号分别为 (6, 4),(8, 2) 和 (7, 9, 3, 1) 的小窗口合并,从而得到新的4个与W-MSA大小一致的窗口,再分别在每个窗口中计算自注意力即可实现不同窗口间信息的交互.因此,STL必须成对存在,可以表示为
式中:Xl-1为输入;Xl,Xl+1分别为第1个STL和第2个STL的输出;
2.2.2 密集残差窗口自注意力网络
式中:Xi为RSTB的输入;Xi+1为RSTB的输出;m为RSTB中STL的个数.但是由于多个串联的RSTB无法促进特征信息在不同网络层间的流动,因此本文算法在多个串联的RSTB之间间隔地引入密集连接[25]构建密集残差窗口自注意力网络块 (Dense Residual Swin Transformer Block, DRSTB) 来充分融合不同深度的高低级特征,DRSTB中某一阶段的输出可以表示为
DRSTB的末端引入残差卷积来强化特征学习构成密集残差窗口自注意力网络DRST,从而DRST的末端可以表示为
式中:Xin为DRST中最后一个DRSTB的输入;Xout为DRST的输出.最后通过全局残差卷积输出去雨图像,则本文算法的整体可以表示如下:
式中:y为输出去雨图像.
2.3 损失函数
式中:Δ(·)为拉普拉斯滤波操作[27];ε=0.001,为维稳常数.
SSIM损失利用图像的区域性特点,分别从亮度、对比度和结构3个角度来综合评价两幅图像的相似程度,其数学形式为
式中:μy,
根据文献[26]中K1=0.01,K2=0.03;L为图像像素点的灰度范围,一般取值1或255.由于SSIM的值越大表明两图像的相似度越高,所以在训练网络时将最大化SSIM转换为最小化SSIM损失:
进而本文提出的综合损失函数Loss可以表示为
式中:根据文献[16]中β的值取0.05.
3 实验结果分析
为验证本文算法的有效性,实验在6个合成雨图数据集和1个自然雨图数据集上进行.合成雨图数据集分别为:文献[10]中提供的Rain14000,其中存在14种不同大小和方向的雨痕,分为 12 600 对训练图像和 1 400 对测试图像;文献[28]中提供的数据集Rain800,其中包括700对训练图像和100对测试图像;文献[29]中提供的两个数据集Rain100H和Rain100L,前者包括5种不同的雨痕,训练图像对和测试图像对分别为 1 800 和100,而后者仅存在一种雨痕,训练图像和测试图像对分别为200和100;文献[12]中提供的Rain1200,其中包括3种雨密度不同的雨痕,分为 12 000 对训练图像和 1 200 对测试图像;文献[9]中提供的Rain12,其中包含12对雨图和无雨图像.自然雨图数据集由文献[30]提供,其中包括300张自然雨图.
3.1 数据集设置
表1 单图像去雨数据集的划分与重命名
Tab.1
3.2 实验环境与训练设置
本文所有的实验均在Windows操作系统下进行,CPU为Intel(R) Xeon(R) Gold 5218,GPU为双NVDIA Quadro RTX 4000,深度学习框架为Pytorch 1.7.上下文信息聚合输入块CGB输入卷积核大小为3×3,空洞率分别为1, 2, 5,特征图的通道数为32.深度特征提取网络DRST包含3个DRSTB和一个残差卷积,每一个DRSTB包括2个RSTB,每个RSTB包括4个STL和一个残差卷积.其中卷积核的大小为3×3,W-MSA和SW-MSA的自注意力窗口大小为8×8,自注意力头的个数为6,中间特征图的通道数为96,激活函数LeakyReLU的泄漏值设为0.2.本文算法的训练次数为200,每次参与训练的图像为16对,大小为64像素×64像素.梯度优化算法AdamW的初始学习率为0.001,在训练过程中当训练次数为90, 130和160时学习率分别降为之前的20%.
3.3 消融实验
3.3.1 网络组成
为验证本文算法相比其他网络组成进行单图像去雨的优势,消融实验针对不同网络组成的去雨结果进行分析.主要包括:浅层特征提取模块选用CGB与单卷积;深度特征提取网络部分首先选用骨干网络残差网络 (Residual Network, ResNet)[24] 与Swin Transformer;其次选用在成对的STL末端引入残差卷积的RSTB与未引入的STB;之后选用在间隔的RSTB引入密集连接的的DRSTB与未引入的RSTB;最后对比在DRSTB末端是否引入全局残差卷积对最终去雨图像质量的影响.网络组成消融实验的对比结果如表2所示,图像质量评价指标选择峰值信噪比 (Peak Signal of Noise Ratio, PSNR)[31] 和SSIM,其值越大表明去雨图像质量越高.
表2 测试数据集Test1200[12]上的网络组成消融实验对比结果
Tab.2
| 网络组成 | 组合方式 | ||||||
|---|---|---|---|---|---|---|---|
| 输入层 | 单卷积 | √ | √ | √ | √ | √ | × |
| CGB | × | × | × | × | × | √ | |
| 特征提取网络 | ResNet | √ | × | × | × | × | × |
| STB | × | √ | √ | √ | √ | √ | |
| RSTB | × | × | √ | √ | √ | √ | |
| DRSTB | × | × | × | √ | √ | √ | |
| DRST | × | × | × | × | √ | √ | |
| 输出层 | 单卷积 | √ | √ | √ | √ | √ | √ |
| PSNR/dB | 25.41 | 27.35 | 28.94 | 30.27 | 32.15 | 34.83 | |
| SSIM | 0.846 | 0.882 | 0.886 | 0.904 | 0.912 | 0.924 | |
由表2可知,在同一训练条件下,骨干网络Swin Transformer相比ResNet在PSNR和SSIM上分别提升1.94 dB和4.26%,这表明Swin Transformer相比ResNet能更好地去除雨痕.当在STB和DRSTB末端引入残差卷积后,网络的去雨图质量在PSNR上分别提升1.59 dB和1.88 dB,这证明本文利用Swin Transformer和CNN结合学习雨图全局性特征和局部特征相比Swin Transformer单独使用更加具有优势.本文算法在深度特征提取网络中引入密集连接,实验表明密集连接使网络去雨图像质量在PSNR和SSIM上分别提升1.33 dB和2.03%.在网络输入层,实验表明CGB相比单卷积能使网络产生更好的表现,具体在PSNR上提升2.68 dB,在SSIM上提升1.32%.因此,实验证明本文算法网络结构的设计是合理的.
3.3.2 损失函数
表3 测试数据集Test1200[12]上的损失函数消融实验对比结果
Tab.3
| 损失函数 | PSNR/dB | SSIM |
|---|---|---|
| MSE | 29.57 | 0.884 |
| Edge | 29.24 | 0.891 |
| SSIM | 30.68 | 0.903 |
| (MSE, SSIM) | 32.79 | 0.916 |
| (Edge, SSIM) | 34.83 | 0.924 |
实验表明,由Edge和SSIM综合损失训练的网络性能与单独使用MSE, Edge和SSIM相比,在PSNR指标上分别上升5.26,5.59,4.15 dB,在SSIM指标上分别上升4.52%,3.70%,2.33%.同时比现有算法常用的MSE与SSIM综合损失在PSNR和SSIM指标上分别提升2.04 dB和0.87%.因此,本文提出的综合损失函数能够很好地保持图像细节和结构信息,相比其他常用损失函数具有更好的表现.
3.4 算法性能对比
3.4.1 合成雨图
表4 不同算法在合成雨图测试数据集[28-29,10,12]上的定量对比结果
Tab.4
| 算法 | Test100[28] | Rain100H[29] | Rain100L[29] | Test2800[10] | Test1200[12] | 平均 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB (G/%) | SSIM (G/%) | ||||||
| DerainNet[10] | 22.77 | 0.810 | 14.92 | 0.592 | 27.03 | 0.884 | 24.31 | 0.861 | 23.38 | 0.835 | 22.48 (45.6)↑ | 0.796 (17.3)↑ | |||||
| SEMI[11] | 22.35 | 0.788 | 16.56 | 0.486 | 25.03 | 0.842 | 24.43 | 0.782 | 26.05 | 0.822 | 22.88 (43.9)↑ | 0.744 (25.5)↑ | |||||
| DIDMDN[12] | 22.56 | 0.818 | 17.35 | 0.524 | 25.23 | 0.741 | 28.13 | 0.867 | 29.65 | 0.901 | 24.58 (34.0)↑ | 0.770 (21.3)↑ | |||||
| UMRL[13] | 24.41 | 0.829 | 26.01 | 0.832 | 29.18 | 0.923 | 29.97 | 0.905 | 30.55 | 0.910 | 28.02 (17.5)↑ | 0.880 (6.14)↑ | |||||
| RESCAN[14] | 25.00 | 0.835 | 26.36 | 0.786 | 29.80 | 0.881 | 31.29 | 0.904 | 30.51 | 0.882 | 28.59 (15.1)↑ | 0.857 (8.98)↑ | |||||
| PReNet[15] | 24.81 | 0.851 | 26.77 | 0.858 | 32.44 | 0.950 | 31.75 | 0.916 | 31.36 | 0.911 | 29.42 (11.9)↑ | 0.897 (4.12)↑ | |||||
| MSPFN[16] | 27.50 | 0.876 | 28.66 | 0.860 | 32.40 | 0.933 | 32.82 | 0.930 | 32.39 | 0.916 | 30.75 (7.06)↑ | 0.903 (3.43)↑ | |||||
| MPRNet[17] | 30.27 | 0.897 | 30.41 | 0.890 | 36.40 | 0.965 | 33.64 | 0.938 | 32.91 | 0.916 | 32.73 (0.58)↑ | 0.921 (1.41)↑ | |||||
| 本文算法 | 28.28 | 0.913 | 30.22 | 0.904 | 37.53 | 0.979 | 33.76 | 0.952 | 34.83 | 0.924 | 32.92 | 0.934 | |||||
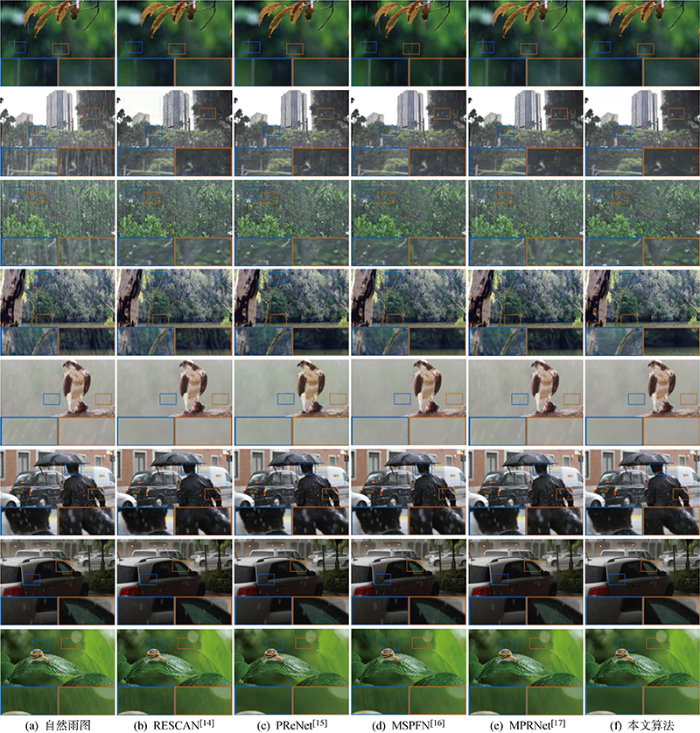
实验表明,本文算法相比其他8个算法在测试数据集Test100[28],Rain100H[29],Rain100L[29],Test2800[10]和Test1200[12]上的平均PSNR和SSIM分别提高0.19~10.44 dB,1.41%~25.5%.具体而言,本文算法在5个测试数据集上的PSNR均获得提升或接近最好,尤其是SSIM均获得明显提升,分别为1.71%~12.7%,1.57%~52.7%,1.45%~10.7%,1.49%~10.6%和0.87%~12.4%.同时,本文算法的合成雨图去雨效果与RESCAN[14],PReNet[15],MSPFN[16]和MPRNet[17]算法的视觉对比结果如图4所示.从图中可以发现,本文算法在雨痕分布密集的第2幅和分布稀疏的第3幅雨图上都有良好的表现,而其他算法如PReNet[15]无法有效适应分布不同的雨痕.进一步发现,本文算法在第7幅雨图上准确区分雨痕和背景信息,相比其他算法更加彻底地去除雨痕.另外,其他算法在第2幅雨图上使马腿产生不同程度的虚化,而本文算法可以很好地保持图像细节信息,从而令去雨图像更加接近无雨图像.因此,本文算法相比其他算法能彻底去除分布不同的雨痕,得到的去雨图像细节更加丰富.
图4

3.4.2 自然雨图
表5 不同算法在自然雨图数据集[30]上的定量对比结果
Tab.5
图5
3.4.3 算法效率
表6 不同算法处理图像的效率对比结果
Tab.6
4 结语
针对现有的单图像去雨算法未有效利用雨图的全局性信息,进而导致去雨图像损失部分细节和结构信息的问题,提出一种基于Swin Transformer的单图像去雨算法.首先,该算法利用并行多尺度空洞卷积作为输入层来适应不同雨痕的分布多样性.其次,将Swin Transformer引入单图像去雨研究,并结合卷积神经网络来提取局部信息和全局性信息,进而强化特征学习.此外,在深度特征提取网络中引入密集连接和全局残差卷积,从而实现不同抽象级特征的充分融合与信息交流.最后,提出一种新的综合损失函数,其可以同时约束去雨图像与无雨图像间的边缘和区域相似性,从而进一步提高去雨图像的质量.在未来研究中,本文作者将继续深入研究雨图局部信息与全局性信息的特点,从而进一步设计出更高效的单图像去雨网络.
参考文献
单幅图像去雨算法研究现状及展望
[J].
Research status and prospect of single image rain removal algorithm
[J].
Detail-recovery image deraining via context aggregation networks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Mask RCNN[C]//Proceedings of the IEEE International Conference on Computer Vision
复杂交通环境中车辆的视觉检测
[J].
Vision-based vehicles detection in complex traffic scenes
[J].
Single image deraining: From model-based to data-driven and beyond
[J].DOI:10.1109/TPAMI.2020.2995190 URL [本文引用: 1]
Single-image-based rain and snow removal using multi-guided filter[C]//International Conference on Neural Information Processing
Automatic single-image-based rain streaks removal via image decomposition
[J].DOI:10.1109/TIP.2011.2179057 URL [本文引用: 1]
Removing rain from a single image via discriminative sparse coding[C]//Proceedings of the IEEE International Conference on Computer Vision
Rain streak removal using layer priors
[C]//
Clearing the skies: A deep network architecture for single-image rain removal
[J].
DOI:10.1109/TIP.2017.2691802
PMID:28410108
[本文引用: 12]

We introduce a deep network architecture called DerainNet for removing rain streaks from an image. Based on the deep convolutional neural network (CNN), we directly learn the mapping relationship between rainy and clean image detail layers from data. Because we do not possess the ground truth corresponding to real-world rainy images, we synthesize images with rain for training. In contrast to other common strategies that increase depth or breadth of the network, we use image processing domain knowledge to modify the objective function and improve deraining with a modestly sized CNN. Specifically, we train our DerainNet on the detail (high-pass) layer rather than in the image domain. Though DerainNet is trained on synthetic data, we find that the learned network translates very effectively to real-world images for testing. Moreover, we augment the CNN framework with image enhancement to improve the visual results. Compared with the state-of-the-art single image de-raining methods, our method has improved rain removal and much faster computation time after network training.
Semi-supervised transfer learning for image rain removal[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Density-aware single image deraining using a multi-stream dense network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Uncertainty guided multi-scale residual learning-using a cycle spinning CNN for single image de-raining[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Recurrent squeeze-and-excitation context aggregation net for single image deraining[C]//Proceedings of the European Conference on Computer Vision
Progressive image deraining networks: A better and simpler baseline[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Multi-scale progressive fusion network for single image deraining[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Multi-stage progressive image restoration[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Attention is all you need[C]//Advances in Neural Information Processing Systems
Swin Transformer: Hierarchical vision Transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision
Early convolutions help transformers see better[C]//Thirty-Fifth Conference on Neural Information Processing Systems
Multi-scale context aggregation by dilated convolutions[C]//International Conference on Leaning Representations
Understanding convolution for semantic segmentation[C]//2018 IEEE Winter Conference on Applications of Computer Vision
SwinIR: Image restoration using swin transformer[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision
Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Densely connected convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Image quality assessment: From error visibility to structural similarity
[J].
DOI:10.1109/tip.2003.819861
PMID:15376593
[本文引用: 3]
Objective methods for assessing perceptual image quality traditionally attempted to quantify the visibility of errors (differences) between a distorted image and a reference image using a variety of known properties of the human visual system. Under the assumption that human visual perception is highly adapted for extracting structural information from a scene, we introduce an alternative complementary framework for quality assessment based on the degradation of structural information. As a specific example of this concept, we develop a Structural Similarity Index and demonstrate its promise through a set of intuitive examples, as well as comparison to both subjective ratings and state-of-the-art objective methods on a database of images compressed with JPEG and JPEG2000.
Optimally isotropic Laplacian operator
[J].DOI:10.1109/83.791975 URL [本文引用: 3]
Image de-raining using a conditional generative adversarial network
[J].DOI:10.1109/TCSVT.76 URL [本文引用: 9]
Deep joint rain detection and removal from a single image[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Lightweight pyramid networks for image deraining
[J].DOI:10.1109/TNNLS.5962385 URL [本文引用: 5]
Scope of validity of PSNR in image/video quality assessment
[J].DOI:10.1049/el:20080522 URL [本文引用: 1]
Making a “completely blind” image quality analyzer
[J].DOI:10.1109/LSP.2012.2227726 URL [本文引用: 1]
No-reference image quality assessment based on spatial and spectral entropies
[J].DOI:10.1016/j.image.2014.06.006 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}