

高附加值零件需要进行过程监控来保证其加工质量,而加工过程监测数据在采集过程中由于传感器、采集和传输设备受环境影响大,导致数据中存在异常值[1].这些异常数据与真实数据有显著差异,而刀具加工监测异常数据直接影响刀具剩余寿命预测的准确性.
数据异常检测算法主要分为有监督和无监督算法.其中监督或者半监督的方法通过带标签的正常数据和异常数据来训练分类模型.尚文利等[2]利用堆叠自编码(SAE)神经网络对工艺数据进行特征降维,然后设计长短期记忆(LSTM)神经网络来进行异常检测.夏英等[3]提出一种融合了新型统计方法和双向卷积LSTM异常检测方法,能够处理多维时序数据.孙滢涛等[4]对电力数据时间序列进行多域特征提取,并采用相关向量机和支持向量数据描述进行特征选择降维和异常检测.傅世元等[5]提出一种基于元学习动态选择集成的电力调度数据异常检测方法.有监督的异常检测依赖于已知的异常样本,但在加工监控过程中,首先实际生产加工的零件型号、使用的刀具多变,有异常标签的数据样本难以获取,其次异常信号的来源复杂,无法获取完备的异常数据来训练异常检测模型.
与有监督的算法不同,无监督异常检测方法从数据样本的统计规律[6]和样本间的距离[7]出发.吴蕊等[8]结合数据对象的密集度与最大近邻半径, 优化K-means初始聚类中心, 在电力数据异常检测上取得了优异的效果.吴金娥等[9]提出采用反向k近邻算法实现异常数据检测.陈砚桥等[10]基于密度的聚类算法(DBSCAN)实现了多源数据异常检测.宋丽娜等[11]将局部异常因子(LOF)算法与互补集成经验模态分解(CEEMD)法进行结合,识别监测数据的异常值.王峰等[12]针对电力调度数据异常,提出基于对数区间隔离的检测方法.王燕晋等[13]基于孤立森林算法提出了一种电力用户数据异常快速识别方法.然而基于聚类的异常检测结果依赖聚类的效果[14].在实际加工监测过程中,采集的加工监测数据随刀具的剩余寿命减少而变化,导致正常和异常数据难以区分.
针对刀具加工监测异常数据无标签和加工监测数据随刀具性能衰退而变化,考虑刀具加工剩余寿命因素,提出基于多层感知机模型的预测偏差来实现异常数据样本的检测.在多层感知机的训练过程中采用高斯分布来拟合训练样本损失,并融合自步学习框架来提升模型对正常样本的筛选能力.最终将异常筛选前后的数据用于铣刀剩余寿命预测中,来验证异常数据检测的重要性和有效性.
1 相关技术
1.1 多层感知机
多层感知机包含输入层、输出层以及多个隐藏层.相邻层之间的神经元节点进行全连接,即上一层的每个神经元都与下一层的所有神经元连接,同时同一层的神经元节点没有连接.前一层的输出通过激活函数与下一层的输入进行关联.
多层感知机模型的训练包含两个部分,分别是前向传递和反向传播.前向传递过程中,训练样本数据从输入层输入,通过一个或者多个全连接层,每两个神经元之间的参数包含一个权重,从而对输入的数据进行拟合,最后通过输出层将数据进行输出.反向传播过程则由输出值与样本的真实值构建损失函数,通过反向传播的梯度下降算法对模型的参数进行更新,当模型的损失函数降到最小值时,多层感知机模型就能够拟合样本特征.第I层到第J层神经元的前向传递和反向传播过程如下:
式中:l表示第I层神经元的个数;wij表示第I层第i个神经元和第J层第j个神经元之间的权重;xi表示第I层第i个神经元的输入;yj表示第J层第j个神经元的输入;φ表示激活函数;t表示迭代次数;α为梯度下降的学习率;ε(t)为多层感知机的输出和真实值之间的损失函数.
1.2 自步学习
传统机器学习方法的目标函数如下所示,要求出使得目标函数最小的权重值:
式中:xi为第i个样本;yi为第i个样本的标签值;wt、wt-1分别为第t和第t-1次迭代过程中模型的权重;m为样本个数.
不同于传统的机器学习,自步学习在每一次的迭代过程中会倾向于从所有样本中选择具有较小训练误差的样本,然后更新模型参数.因此在每一次的迭代过程中,并不是所有的样本都参与了模型参数的更新.自步学习在传统机器学习的目标函数中引入了二分变量vi,该变量用于表征每个样本是否被选择参与训练,其目标函数改写为
式中:λ为样本难易程度的筛选阈值.当损失值f(xi, yi; wt-1)<λ时,vi取1,而当损失值f(xi, yi; wt-1)≥λ时,vi取0.自步学习中λ的选取往往需要人为给定,本文通过高斯分布来拟合训练样本的误差,从而自适应地选取λ,将高于阈值的样本作为异常样本.
2 融合高斯分布和自步学习的多维数据异常检测
2.1 异常检测模型建立
刀具的性能状态需通过加工监测信号间接反映,并且随着刀具的磨损程度增加刀具的剩余寿命会降低[17].
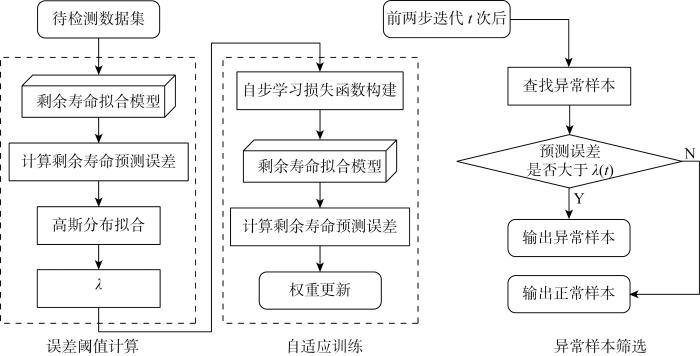
首先针对刀具监测信号无异常数据标签问题,将监测信号和刀具剩余寿命进行关联,建立多层感知机模型对两者进行拟合,以监测信号为输入,以刀具剩余寿命为输出.加工过程的异常数据受外界干扰与真实数据存在差异,无法反映刀具加工过程的真实状态,剩余寿命的预测误差会大于正常数据.其次,采用全量样本训练多层感知机模型会引入异常样本,因此,在多层感知机模型每一步的训练迭代过程中,引入自步学习框架,选择预测误差小的样本来更新模型权重,防止异常样本的干扰.针对自步学习的步长大小难以确定的问题,提出利用高斯分布来设置误差阈值作为自步学习的步长.最后,模型收敛后,利用最后一次计算的误差阈值以及更新完成的多层感知机模型来对所有样本进行筛选.图1展示了异常检测方法的流程.
图1
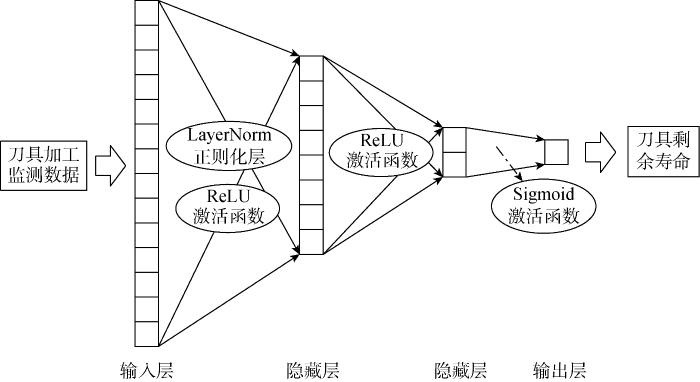
多层感知机的实现包含输入层、两个隐藏层以及输出层,每一层之间通过激活函数相连.其中第1个隐藏层、第2个隐藏层的输出通过ReLU激活函数连接,输出层后连接Sigmoid激活函数,最终输出刀具的剩余寿命值.为了防止模型过拟合,在第1个隐藏层后连接一个LayerNorm正则化层.剩余寿命预测模型各层结构如图2所示.模型的损失函数为均方差函数:
式中:yi、
图2
模型迭代过程中主要包括两个部分:
(1) 误差阈值计算.将所有样本通过异常检测模型预测的剩余寿命与真实值比较,基于高斯分布拟合误差分布,进而获取误差阈值,作为自步学习的步长参数.
(2) 自适应训练.使用误差阈值计算得到的结果代入自步学习的λ参数中,建立自步学习损失函数,通过梯度下降算法对模型进行权重更新,学习正常样本的数据特征.
最后当训练迭代结束时,以最后一次迭代得到的误差阈值为标准,将样本划分为正常样本和异常样本.
2.2 模型训练过程
2.2.1 基于高斯分布的误差阈值计算
剩余寿命预测模型回归加工监测数据的特征,通过式(5)计算得到预测值和真实值的误差的平方数来衡量回归精度,理想情况下加工监测数据经过剩余寿命预测模型计算后得到的误差为0,但数据样本的质量问题使得模型始终存在一定的误差.误差越大发生的概率越小,误差越小发生的概率越大,且对于大部分正常样本,其误差维持在一个较小的水平.选择高斯分布来映射预测误差平方和数据的准确率,高斯分布定义随机变量X服从一个数学期望为u、方差为σ的正态分布,记为N(u, σ2).高斯分布概率密度函数p(x)为
误差平方越接近0时数据的分散程度越小,映射后的数据正常的概率越大.为了满足映射关系取高斯分布概率密度函数对称轴的右半轴为实际的映射对象.其中期望大小为0,标准差通过样本标准差s来估计:
2.2.2 基于自步学习的自适应训练方法
建立其优化函数如下:
自步学习的步长大小记为λ,等于式(7)计算得到的k,表示样本难易程度的筛选阈值.训练过程主要分为两步,第1步是v值的计算,第2步是w值的更新.v值的计算需要先固定w权重值,通过对比预测误差和λ的关系进行确定,当样本通过剩余寿命预测模型后得到误差小于λ时,上述优化函数取v=1时达到最小.最终可以得到每个数据样本对应的v值.v=0则该样本不参与训练,v=1则该样本参与训练:
同理,w权重的更新过程需要固定v值,采用梯度下降法进行更新:
当完成t次迭代训练后,取λt作为误差筛选阈值k,将所有样本的预测误差与k进行对比,大于等于k的样本归为异常样本.结合上述融合高斯分布的误差阈值的自步学习迭代过程得到算法如下.

算法 基于自步学习的刀具加工过程监测数据异常检测算法.
输入 待检测的样本集D(xi,yi),1≤i≤m训练迭代次数epochs,学习率α,样本批次大小batchsize,多层感知机模型M(w,b),样本权重向量V.
输出 多层感知机模型M(w,b)和误差阈值k.
步骤1 随机初始化网络权重w、b和样本权重V=Im;
步骤2foreach t in epochs do;
步骤3 建立误差集合E(ei), 1≤i≤m;
步骤4foreach (xi,yi) in D do;
步骤5 多层感知机模型前馈计算,得到预测值
步骤6 计算误差ei,加入E: ei(
步骤7end;
步骤8 根据高斯分布计算误差阈值:
k=λ=3
步骤9foreach batch(xi,yi) in D do;
步骤10 多层感知机模型前馈计算,得到预测值batch(
步骤11 计算误差batch(ei);
步骤12 ① 固定模型权重,更新样本权重Vbatch;
步骤13 if ei<λ then;
步骤14vi=1;
步骤15 else;
步骤16vi=0;
步骤17 end;
步骤18 ② 固定样本权重,更新模型权重
wt=wt-1-α
步骤19 end;
步骤20 end;
步骤21 获得异常样本的误差筛选阈值: k=λt=epochs.

3 实验及其结果分析
3.1 数据集介绍
选用数据采集自某汽轮机厂的汽轮机转子轮槽铣削加工过程,一共使用了15把J1型精铣刀.在轮槽加工过程中,采用PCI-2AE采集声发射信号,采样的频率为1 MHz.
上述加工过程产生的样本数据集一共包含了170条轮槽的加工监控数据,每条轮槽的加工持续时间内能得到 10000 条数据记录,每条数据记录涵盖14种AE属性信息:上升时间、计数、能量、幅值、平均频率、均方根值、平均信号电平、峰值频率、反算频率、初始频率、信号强度、绝对能量、中心频率、峰频.将每条轮槽的 10000 条AE数据进行均值化后得到14个维度的特征向量,每个特征向量作为一个数据样本,一共包含170个数据样本,对应于170条轮槽.AE信号能表征精刀加工过程的健康情况,反映刀具的剩余使用寿命,因此,每个数据样本均会对应一个刀具剩余使用寿命,与加工刀具的实际加工情况有关,如表1所示.
表1 汽轮机轮槽铣削加工刀具使用情况
Tab.1
| 铣刀编号 | 轮槽编号 | 铣刀编号 | 轮槽编号 | 铣刀编号 | 轮槽编号 |
|---|---|---|---|---|---|
| 1 | 1~13 | 6 | 65~75 | 11 | 119~128 |
| 2 | 14~26 | 7 | 76~86 | 12 | 129~139 |
| 3 | 27~38 | 8 | 87~96 | 13 | 140~149 |
| 4 | 39~50 | 9 | 97~107 | 14 | 150~159 |
| 5 | 51~64 | 10 | 108~118 | 15 | 160~170 |
汽轮机转子轮槽产品成本高、质量要求严格,加工过程复杂.刀具剩余寿命预测影响换刀决策时间,对于保证加工质量和生产效率具有重要意义[20].使用采用高斯径向基核的支持向量回归机算法作为验证算法,该算法能够通过核函数实现高维空间的非线性映射,同时具有较好的鲁棒性,适用于加工过程的刀具剩余寿命预测.
将编号为13、14、15号精铣刀作为测试集,编号为1~12号的刀具作为训练集,对训练集进行异常样本的检测和剔除,然后参与刀具剩余寿命预测模型的训练,最后通过测试集的预测结果对比数据异常检测前后效果.
3.2 实验结果评价指标介绍
汽轮机轮槽铣刀监测数据在实际生产加工中采集得到,没有区分样本正常和异常的标签值,但每个样本都具有相应的刀具剩余寿命.因此通过对比异常检测前后,支持向量回归机在测试集上刀具剩余寿命预测的表现来反映所提出的数据异常检测算法的有效性.平均绝对误差(MAE)、均方根误差(RMSE)被广泛用于回归问题中,采用上述两种指标表示模型预测效果的优劣.
(1) 平均绝对误差反映实际预测误差的大小,其计算公式如下:
(2) 均方根误差的作用是衡量预测值与真实值之间的偏差大小,其计算公式如下:
3.3 实验分析
首先建立第2章的多层感知机模型,输入层大小为14,对应样本的14个维度.第1层隐藏层大小为8,第2层隐藏层大小为2,输出层大小为1,对应刀具的剩余寿命值.然后对15把刀中编号为1~12的铣刀加工监测数据样本进行训练,训练轮次为500次.由于模型权重参数是随机初始化的,所以选取了5次不同的随机种子下异常检测模型训练的结果.
在异常检测模型剔除异常数据样本后,将剩余正常样本用于训练支持向量回归机,其中80%作为训练集,20%作为验证集,进行刀具的剩余寿命预测回归.采用网格搜索法搜索支持向量回归机的最佳参数,其中惩罚系数C的取值范围为 [1:1:10],γ取值范围为[0.001:0.001:0.01,0.01:0.01:0.1,0.1:0.1:1:1].最后将测试样本的预测结果进行对比,得到不同异常检测算法的性能.
表2 不同系数下的测试结果
Tab.2
| 实验编号 | β=1.5 | β=2.0 | β=2.5 | β=3.0 | β=3.5 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RSME | MAE | RSME | MAE | RSME | MAE | RSME | MAE | RSME | |||||
| 1 | 1.386 | 1.608 | 1.138 | 1.334 | 1.169 | 1.417 | 1.013 | 1.223 | 1.315 | 1.572 | ||||
| 2 | 1.125 | 1.303 | 1.286 | 1.533 | 1.214 | 1.391 | 1.122 | 1.365 | 1.424 | 1.630 | ||||
| 3 | 1.170 | 1.410 | 1.333 | 1.513 | 1.431 | 1.738 | 1.122 | 1.365 | 1.424 | 1.630 | ||||
| 4 | 1.170 | 1.410 | 1.214 | 1.391 | 1.431 | 1.738 | 1.122 | 1.365 | 1.459 | 1.674 | ||||
| 5 | 1.232 | 1.388 | 1.305 | 1.679 | 1.214 | 1.391 | 0.965 | 1.202 | 1.424 | 1.630 | ||||
| 平均值 | 1.216 6 | 1.423 8 | 1.255 2 | 1.490 0 | 1.291 8 | 1.535 0 | 1.068 9 | 1.304 0 | 1.409 2 | 1.627 2 | ||||
图3
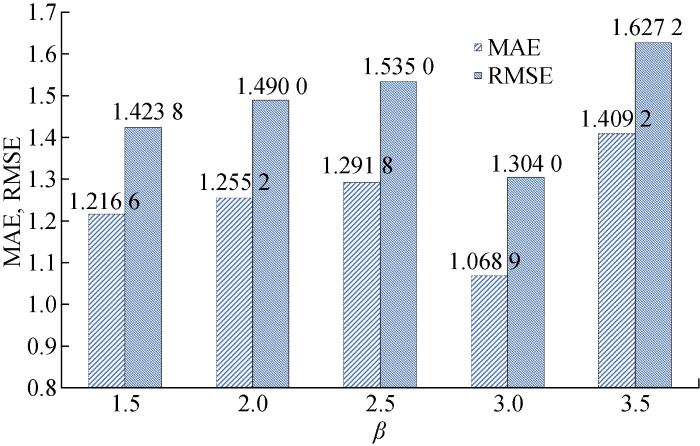
从实验结果可以看出,不同系数的取值会对测试集最终预测结果产生影响.其中在β=3.0时,经过异常样本检测和剔除后测试集预测结果最佳,验证了3σ方法的有效性.表3显示在最佳系数取值下,5组实验检测出的异常样本,在剔除异常样本之后,剩余样本在测试集上获得的平均测试结果MAE值为1.069,RMSE值为1.304.
表3 多随机种子下异常检测方法结果
Tab.3
| 实验编号 | MAE | RMSE | 异常样本 数量/个 | 异常样本 编号 |
|---|---|---|---|---|
| 1 | 1.013 | 1.223 | 3 | 10、43、107 |
| 2 | 1.122 | 1.365 | 3 | 9、10、11 |
| 3 | 1.122 | 1.365 | 3 | 9、10、11 |
| 4 | 1.122 | 1.365 | 3 | 9、10、11 |
| 5 | 0.965 | 1.202 | 3 | 10、11、12 |
| 平均值 | 1.069 | 1.304 | ||
| 标准差 | 0.067 | 0.075 | ||
| 优化比/% | 26.284 | 28.194 |
取实验编号5得到训练过程中λ、模型预测平均损失值(MSE)、m随t变化的曲线如图4所示.
图4
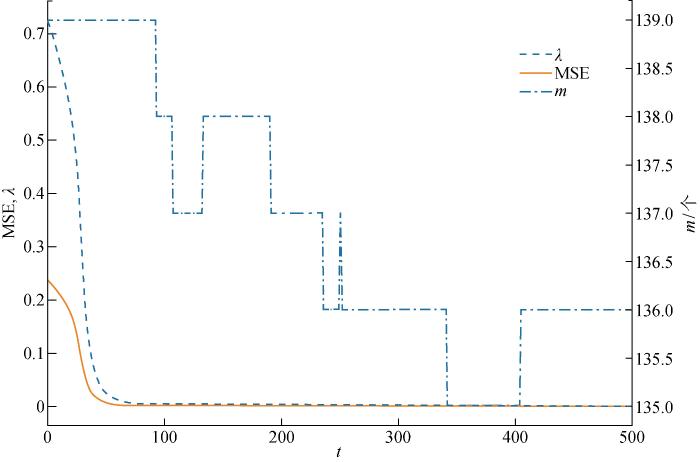
在训练过程中,λ始终大于MSE,其中e超过λ的样本即会被归为异常样本,不参与此轮模型权重的训练.在训练初始阶段,模型对于训练样本的拟合程度较差,因此,训练样本的MSE较大,计算得到的λ也较大.随着训练次数的增加,模型渐渐收敛,大部分样本都能够被模型进行拟合,此时,仍然e>λ的样本数量渐渐稳定.最终选取训练结束后,将e与此时λ进行比较来确定异常样本.
为了对照所提出的异常检测模型的有效性,选取了其他5种异常检测算法.局部异常因子(LOF)算法是一种基于密度的异常检测算法,通过计算数据样本周围样本的局部密度以及自身所在位置的密度来衡量样本的异常程度.DBSCAN是一种基于密度的聚类算法,可以在数据空间中发现噪声点.孤立森林根据数据点被孤立的难易程度将噪声点和正常点进行区分.K均值法是应用广泛的基于距离的聚类算法.一分类支持向量机(One-Class SVM)与本文方法均为基于分类的异常检测方法[14],其利用核函数将数据样本拟合到一个超平面上,远离超平面上的样本为异常样本.此外增加了随机抽样方法,随机选取3个样本作为异常样本,其余作为正常样本,与本文方法进行对比.不同的方法对比结果如表4所示.分别从4个指标维度进行比较,分别是测试集的MAE、RMSE、MAE相较于全量训练集得到的提升比例(MAE’)、RMSE相较于全量训练得到的提升比例(RMSE’).
表4 不同异常检测算法对比结果
Tab.4
| 方法 | MAE | RMSE | MAE’/ % | RMSE’/ % |
|---|---|---|---|---|
| 未筛选 | 1.45 | 1.816 | — | — |
| 本文方法 | 1.069±0.067 | 1.304±0.075 | 26.28 | 28.19 |
| LOF | 1.219 | 1.486 | 15.93 | 18.17 |
| DBSCAN | 1.693 | 2.137 | -16.76 | -17.68 |
| 孤立森林 | 1.263 | 1.527 | 12.90 | 15.91 |
| K均值 | 1.844 | 2.215 | -27.17 | -21.97 |
| One-Class SVM | 1.28 | 1.605 | 11.72 | 11.62 |
| 随机采样 | 1.485±0.327 | 1.877±0.456 | -2.41 | -3.37 |
本文方法获得的测试集预测结果平均值在MAE上的提升比例为26.28%,在RMSE上提升比例为28.19%,优于其他方法的结果.在其他的异常检测算法中,LOF取得了次优的结果,在MAE和RMSE上的提升比例分别为15.93%和18.17%,LOF能通过衡量样本间的聚集程度来判断离群点,鲁棒性较好.孤立森林的提升比例与LOF方法近似,在MAE和RMSE上的提升比例分别为12.90%和15.91%.One-Class SVM在MAE和RMSE上的提升比例分别为11.72%和11.62%,差于前3种方法.两种基于聚类的方法得到的MAE提升比例和RMSE提升比例均为负数.聚类算法受限于聚类结果,而刀具加工过程监测数据受刀具性能衰退而变化,因此基于聚类的异常检测方法难以准确区分正常和异常样本.随机采样法是样本选择中一个比较常见的方法,该方法便于操作,但不同的随机采样过程得到的结果差异很大.从表中结果看到,随机采样的MAE和RMSE的标准差分别达到了0.327和0.456.图5直观地显示了各个算法在测试集上指标的提升比例.
图5
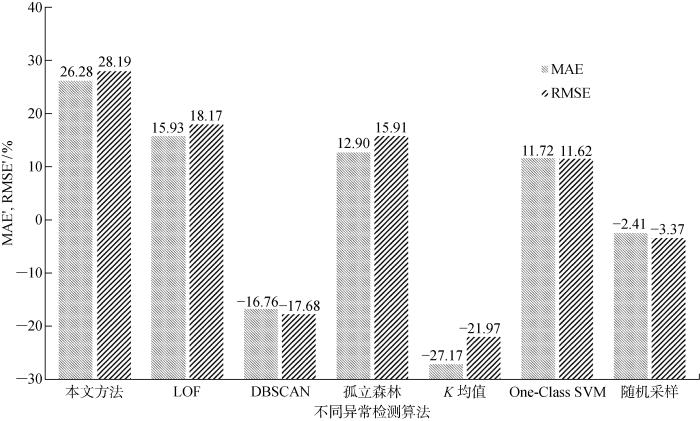
图5
测试集预测结果在不同异常检测算法应用前后提升比例
Fig.5
Optimized percentage of test set prediction results before and after application of different anomaly detection algorithms
4 结语
本文面向刀具加工过程监测,基于高斯分布和自步学习框架提出一种数据异常检测方法.利用多层感知机模型学习监测数据样本的整体特征,分离监测数据集中的异常数据.在模型的更新过程中,用模型预测误差来拟合高斯分布,并设定误差阈值,同时结合自步学习框架,优选高质量数据样本参与权重的更新.最终训练结束后通过多层感知机模型的预测误差有效检测异常数据样本.
通过与多种异常检测算法的对比实验可见,融合高斯分布和自步学习框架的数据异常检测方法能够有效地区分加工监测数据中的异常样本.多层感知机模型通过高斯分布计算样本误差阈值,与自步学习框架结合,针对性地选取样本对模型权重进行更新,保证模型具备对异常样本的判别能力.综合上述分析和实验结论,本文所提出的面向刀具加工监测数据的异常检测方法相比其他方法能更适用于刀具加工监测数据样本的异常检测.
参考文献
基于SAE-LSTM的工艺数据异常检测方法
[J].
DOI:10.12263/DZXB.20180015
[本文引用: 1]

为解决工业网络安全防护中工艺数据异常检测误报率较高的问题,本文提出一种基于时间序列的异常检测方法.该方法对工艺数据进行相关性分析、向量映射等处理,再采用堆叠自编码神经网络(SAE)对工艺数据特征进行降维,根据工艺数据在传输序列间的相互关联性,设计基于长短期记忆神经网络(LSTM)的异常检测模型,最后进行工艺数据异常检测仿真实验验证分析.实验结果表明,基于时间序列的异常检测模型能有效提高工艺数据异常检测准确率,并且误报率要低于传统隐马尔可夫异常检测模型,同时获得较好的异常检测实时性.
An anomaly detection method of process data based on SAE-LSTM
[J].
DOI:10.12263/DZXB.20180015
[本文引用: 1]
In order to solve the problem of high false alarm rate of abnormal detection of process data in industrial network security protection, this paper proposes an anomaly detection method based on time series. In this method, the process data is analyzed by association analysis and vector mapping, and the stacked auto-encoder neural network (SAE) is used to reduce the dimension of process data features. According to the correlation of process data in the transmission sequence, an anomaly detection model based on long and short term memory neural network (LSTM) is designed. Finally, the simulation analysis of abnormal detection of process data is carried out. The experimental results show that the anomaly detection model based on time series can greatly improve the accuracy of process data anomaly detection, and the false positive rate is lower than the traditional hidden Markov anomaly detection model, and at the same time get better real-time performance of anomaly detection.
融合统计方法和双向卷积LSTM的多维时序数据异常检测
[J].
Multi-dimensional time series data anomaly detection fusing statistical methods and bidirectional convolutional LSTM
[J].
基于多域特征提取的电力数据异常检测方法
[J].
Power data anomaly detection algorithm based on multi-domain feature extraction
[J].
基于元学习动态选择集成的电力调度数据异常检测方法
[J].
Anomaly detection for power dispatching data based on meta-learning dynamic ensemble selection
[J].
基于改进K-means的电力数据异常检测算法
[J].
Anomaly detection algorithm based on improved K-means for electric power data
[J].
基于反向k近邻过滤异常的群数据异常检测
[J].
Collective data anomaly detection based on reverse k-nearest neighbor filtering
[J].
基于DBSCAN的智能机舱多源数据异常检测方法
[J].
Intelligent engine room multi-source data detecting method based on DBSCAN cluster algorithm
[J].
基于LOF与CEEMD的城镇取用水监测数据异常值识别
[J].
Outlier identification of urban water intake monitoring data based on LOF and CEEMD
[J].
一种基于对数区间隔离森林的电力调度数据异常检测集成算法
[J].
An anomaly detection ensemble algorithm for power dispatching data based on log-interval isolation
[J].
基于孤立森林算法的电力用户数据异常快速识别研究
[J].
Research on fast identification of power user data abnormal based on isolation forest algorithm
[J].
异常检测方法及其应用综述
[J].
Anomaly detection and its application
[J].
基于多通道融合及贝叶斯理论的刀具剩余寿命预测方法
[J].
DOI:10.3901/JME.2021.13.214
[本文引用: 1]
刀具监测及可用剩余寿命(RUL)预测对降本增效及保证加工质量意义重大。针对单一传感器预测精度波动大、数据利用率低、可靠性低等问题,提出一种多通道信号融合及贝叶斯更新的刀具剩余寿命预测方法。通过计算多通道信号所提取特征的时间序列与对应时间矢量的斯皮尔曼等级相关系数对特征时序做单调性排序,取单调性得分高的特征用主成分分析进行融合并构建健康因子作为观测数据,基于贝叶斯理论及马尔科夫链蒙特卡洛采样估计退化模型参数,并随着时间推进及监测数据序贯可获,实时在线更新退化模型参数以逐渐逼近刀具磨损退化趋势,同时对每时刻剩余寿命进行迭代估计。所提方法可避免基于深度学习方法需要依赖大量全寿命数据离线训练预测模型且模型对新预测任务适应性有限的局限性。用PHM2010公开数据挑战赛中三槽球头硬质合金铣刀切削不锈钢过程磨损全寿命数据集验证了方法有效性。
A multi-channel signal fusion and Bayesian theory based method for tool remaining useful life prediction
[J].
DOI:10.3901/JME.2021.13.214
[本文引用: 1]
Tool monitoring and remaining useful life (RUL) prediction are significant for reducing costs and ensuring processing quality. Aiming at the problems of single-sensor prediction accuracy fluctuations, low data utilization, and low reliability, a multi-channel signal fusion and Bayesian update tool remaining life prediction method is proposed. By calculating the time series of the features extracted from the multi-channel signal and the Spearman rank correlation coefficient of the corresponding time vector, the feature time is monotonically ranked. Features with a high monotonicity score are fused using principal component analysis and the health factors are constructed as observation data based on Bayesian theory and Markov chain Monte Carlo sampling to estimate the degradation model parameters, and as time progresses and monitoring data is available sequentially, the degradation model parameters are updated online in real time to gradually approach the trend of tool wear degradation. The remaining life of each moment is estimated iteratively. The proposed method can avoid the limitation that deep learning-based methods need to rely on many full-life data to train the prediction model offline and the model has limited adaptability to new prediction tasks. Validate with the full life data set of the three-slot ball-end carbide milling cutter for cutting stainless steel in the open data challenge.
GNSS变形监测时间序列的改进型3σ粗差探测方法
[J].
An improved 3σ gross error detection method for GNSS deformation monitoring time series
[J].
基于小波分析的大坝变形观测数据的趋势分量提取
[J].
Abstracting trend component of dam observation data based on wavelet analysis
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}