上海交通大学学报 ›› 2021, Vol. 55 ›› Issue (5): 575-585.doi: 10.16183/j.cnki.jsjtu.2019.277
所属专题: 《上海交通大学学报》2021年12期专题汇总专辑; 《上海交通大学学报》2021年“自动化技术、计算机技术”专题
李鹏, 阮晓钢, 朱晓庆( ), 柴洁, 任顶奇, 刘鹏飞
), 柴洁, 任顶奇, 刘鹏飞
收稿日期:2019-09-26
出版日期:2021-05-28
发布日期:2021-06-01
通讯作者:
朱晓庆
E-mail:alex.zhuxq@bjut.edu.cn
作者简介:李 鹏(1992-),男,河北省廊坊市人,博士生,主要研究方向为机器人导航.
基金资助:
LI Peng, RUAN Xiaogang, ZHU Xiaoqing(), CHAI Jie, REN Dingqi, LIU Pengfei
Received:2019-09-26
Online:2021-05-28
Published:2021-06-01
Contact:
ZHU Xiaoqing
E-mail:alex.zhuxq@bjut.edu.cn
摘要:
针对移动机器人在分布式环境中的导航问题,提出一种基于深度强化学习的区域化视觉导航方法.首先,根据分布式环境特征,在不同区域内独立学习控制策略,同时构建区域化模型, 实现导航过程中控制策略的切换和结合.然后,为使机器人具有更好的目标导向行为,在区域导航子模块中增加奖励预测任务,并结合经验池回放奖励序列.最后,在原有探索策略的基础上添加景深约束,防止因碰撞导致的遍历停滞.结果表明: 奖励预测和景深避障的应用有助于提升导航性能.在多区域环境测试过程中,区域化模型在训练时间和所获奖励上展现出单一模型不具备的优势,表明其能更好地应对大范围导航.此外,实验在第一人称视角的3D环境下进行,状态是部分可观察的,利于实际应用.
中图分类号:
李鹏, 阮晓钢, 朱晓庆, 柴洁, 任顶奇, 刘鹏飞. 基于深度强化学习的区域化视觉导航方法[J]. 上海交通大学学报, 2021, 55(5): 575-585.
LI Peng, RUAN Xiaogang, ZHU Xiaoqing, CHAI Jie, REN Dingqi, LIU Pengfei. A Regionalization Vision Navigation Method Based on Deep Reinforcement Learning[J]. Journal of Shanghai Jiao Tong University, 2021, 55(5): 575-585.
图1
DQN模型
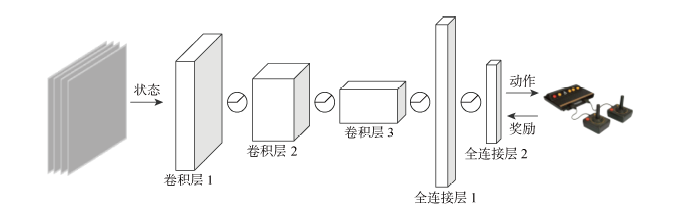
图2
DRQN模型
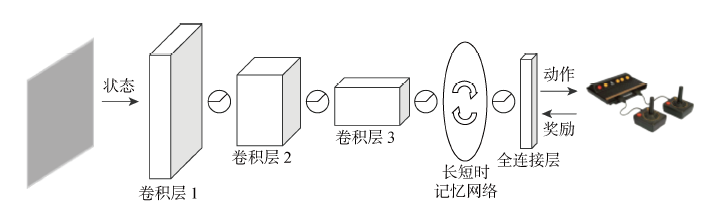
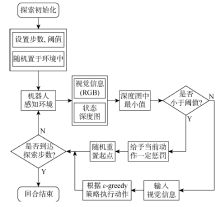
图3
探索流程
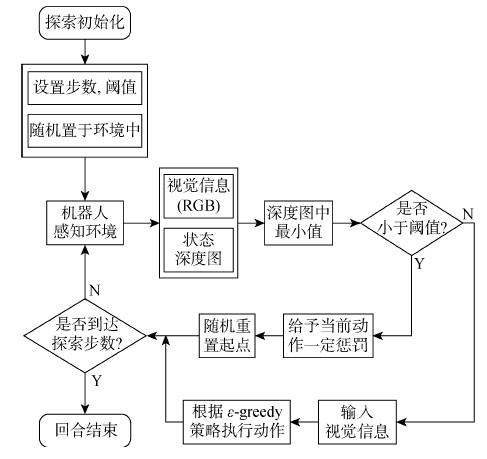
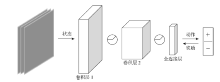
图4
奖励预测模型
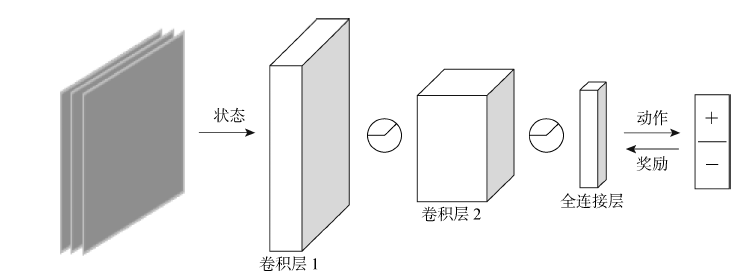
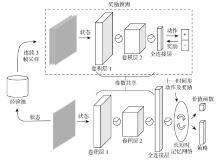
图5
区域导航子模块
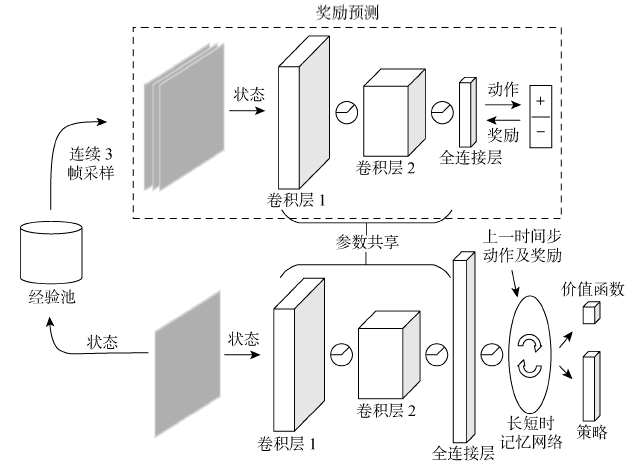
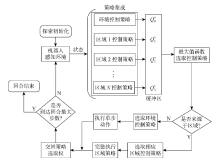
图6
多区域导航流程
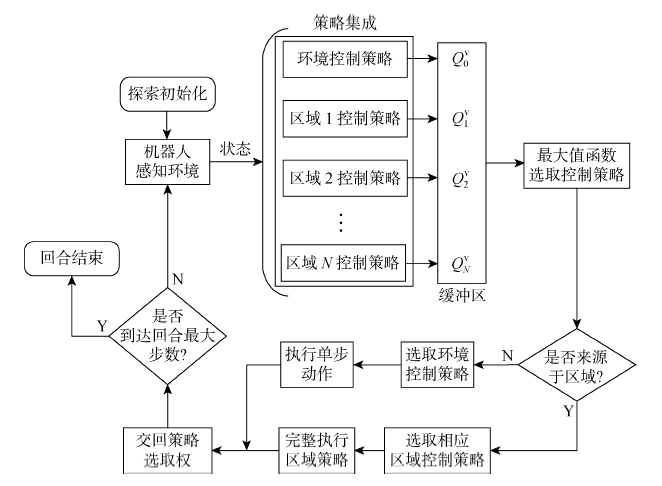
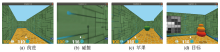
图7
仿真环境运行画面
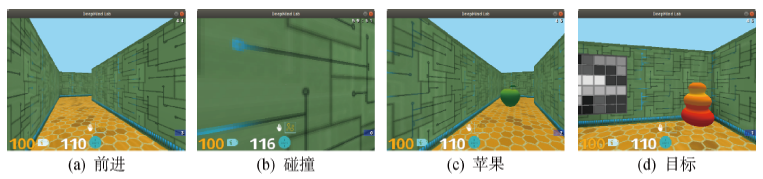
图8
测试环境
表1
神经网络参数
| 网络部分 | 动作选取 | 奖励预测 |
|---|---|---|
| 卷积层1 | 16, 8, 4 | 16, 8, 4 |
| 卷积层2 | 32, 4, 2 | 32, 4, 2 |
| 全连接层 | 256 | 128 |
| LSTM | 256 | 无 |
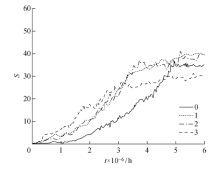
图9
不同阈值实验结果
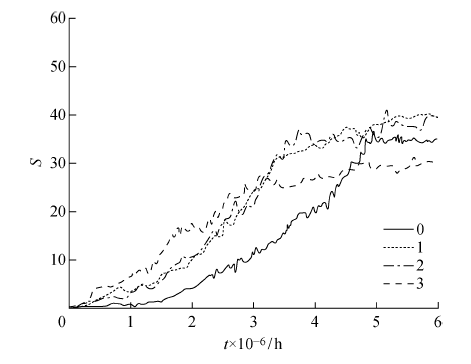

图10
探索方法实验结果
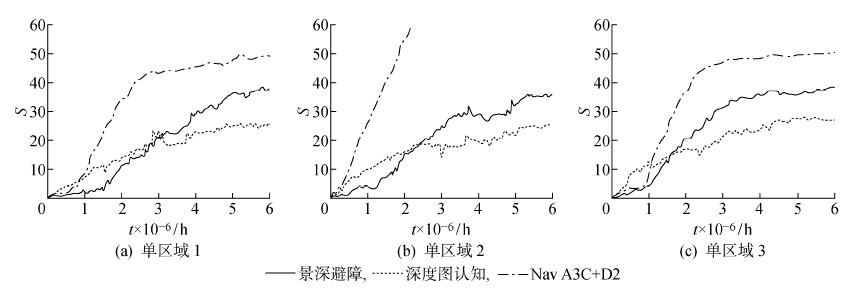

图11
奖励预测实验结果


图12
价值函数-时间图
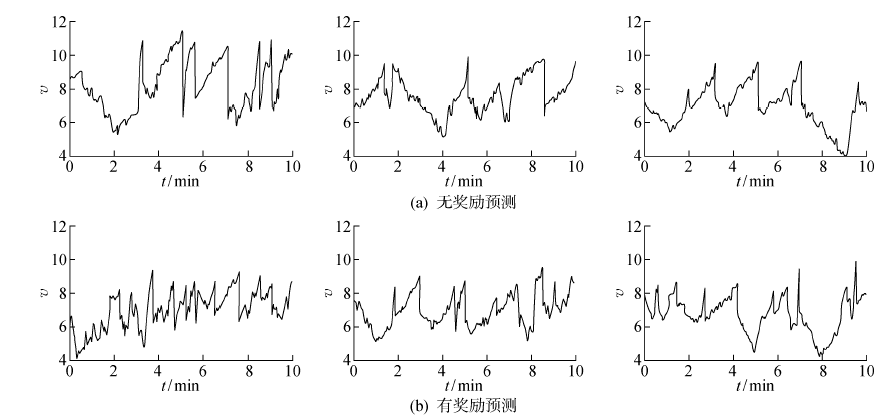

图13
单区域导航实验结果
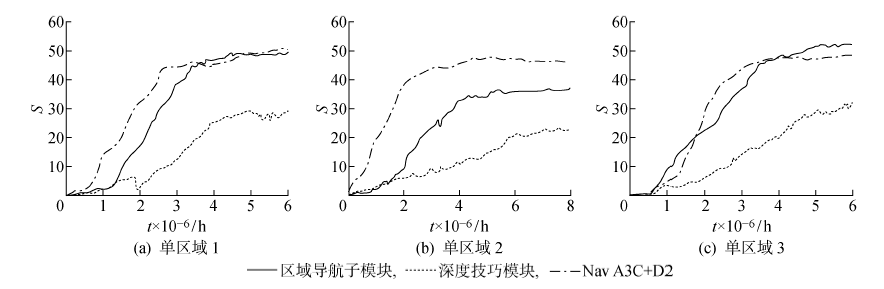

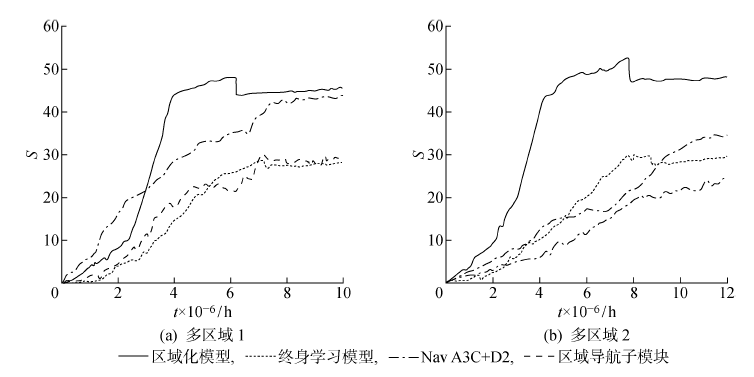
图14
多区域导航实验结果
| [1] | 徐德. 室内移动式服务机器人的感知、定位与控制[M]. 北京: 科学出版社, 2008. |
| XU De. Perception, positioning and control of indoor mobile service robot[M]. Beijing: Science Press, 2008. | |
| [2] |
STEFFENACH H A, WITTER M, MOSER M B, et al. Spatial memory in the rat requires the dorsola-teral band of the entorhinal cortex[J]. Neuron, 2005, 45(2):301-313.
doi: 10.1016/j.neuron.2004.12.044 URL |
| [3] | ARULKUMARAN K, DEISENROTH M, BRUNDAGE M, et al. A brief survey of deep reinforcement learning, (2017-09-28)[2019-08-20]. https://arxiv.org/pdf/1708.05866.pdf |
| [4] | MIROWSKI P, PASCANU R, VIOLA F, et al. Learning to navigate in complex environments,(2017-01-13)[2019-08-13]. https://arxiv.org/pdf/1611.03673.pdf |
| [5] | ZHU Y, MOTTAGHI P, KOLVE E, et al. Target-driven visual navigation in indoor scenes using deep reinforcement learning [C]//IEEE International Conference on Robotics and Automation. Singapore: IEEE, 2017, 3357-3364. |
| [6] | JADERBERG M, MNIH V, CZARNECKI W M, et al. Reinforcement learning with unsupervised auxiliary tasks[EB/OL]. (2016-11-16)[2019-04-20]. https://arxiv.org/pdf/1611.05397.pdf |
| [7] | OH J, CHOCKALINGAM V, SATINDER P, et al. Control of memory, active perception, and action in minecraft[EB/OL]. (2016-05-30)[2019-05-07]. https://arxiv.org/pdf/1605.09128.pdf |
| [8] | 黄健, 严胜刚. 基于区域划分自适应粒子群优化的超短基线定位算法[J]. 控制与决策, 2019, 9(34):2023-2030. |
| HUANG Jian, YAN Shenggang. Ultra-short baseline positioning algorithm based on region-division adaptive particle swarm optimization[J]. Control and Decision, 2019, 9(34):2023-2030. | |
| [9] | 张俊, 田慧敏. 一种基于边指针搜索及区域划分的三角剖分算法[J]. 自动化学报, 2021, 47(1):100-107. |
| ZHANG Jun, TIAN Huimin. A triangulation algorithm based on edge-pointer search and region-division[J]. Acta Automatica Sinica, 2021, 47(1):100-107. | |
| [10] |
RUAN X G, REN D Q, ZHU X Q, et al. Optimized data association based on Gaussian mixture model[J]. IEEE Access, 2020, 8:2590-2598.
doi: 10.1109/Access.6287639 URL |
| [11] | 朱续涛, 何晓斌, 刘悦, 等. 一种简易的脑片图像的半自动区域划分及细胞计数方法[J]. 波谱学杂志, 2018, 2(35):133-140. |
| ZHU Xutao, HE Xiaobin, LIU Yue, et al. A Convenient semi-automatic method for analyzing brain sections: Registration, segmentation and cell counting[J]. Chinese Journal of Magnetic Resonance, 2018, 2(35):133-140. | |
| [12] | KULKARNI T D, SAEEDI A, GAUTAM S, et al. Deep successor reinforcement learning, (2016-06-08)[2019-05-21]. https://arxiv.org/pdf/1606.02396.pdf |
| [13] |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540):529-533.
doi: 10.1038/nature14236 URL |
| [14] | SHIH H H, SHAO H C, PING T W, et al. Distributed deep reinforcement learning based indoor visual navigation [C]//2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Madrid, Spain: IEEE, 2018: 2531-2537. |
| [15] | TESSLER C, GIVONY S, ZAHAVY T, et al. A deep hierarchical approach to lifelong learning in minecraft, (2016-11-30)[2019-06-05]. https://arxiv.org/pdf/1604.07255.pdf |
| [16] | HAUSKNECHT M, STONE P. Deep recurrent Q-learning for partially observable MDPs[EB/OL].(2017-01-11)[2019-05-17]. https://arxiv.org/pdf/1507.06527.pdf |
| [17] | RIEDMILLER M. Neural fitted Q iteration—First experiences with a data efficient neural reinforcement learning method [C]//16th European Conference on Machine Learning. Berlin, Germany: Springer-Verlag, 2005: 279-292. |
| [18] | LANGE S, RIEDMILLER M, VOIGTLANDER A. Autonomous reinforcement learning on raw visual input data in a real world application [C]//The 2012 International Joint Conference on Neural Networks. Brisbane, Australia: IEEE, 2012: 1-8. |
| [19] | GU S X, LILLICRAP T, SUTSKEVER I, et al. Continuous Deep Q-learning with model-based acceleration [C]//33rd International Conference on Machine Learning. USA: International Machine Learning Society, 2016: 4135-4148. |
| [20] |
KAELBLING L P, LITTMAN M L, CASSANDRA A R. Planning and acting in partially observable stochastic domains[J]. Artificial Intelligence, 1998, 101(1/2):99-134.
doi: 10.1016/S0004-3702(98)00023-X URL |
| [21] |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780.
doi: 10.1162/neco.1997.9.8.1735 URL |
| [22] | BEATTIE C, LEIBO J Z, TEPLYASHIN D, et al. Deepmind lab, (2016-12-13)[2018-12-30]. https://arxiv.org/pdf/1612.03801.pdf |
| [23] |
GERS F A, SCHMIDHUBER J, CUMMINS F. Learning to forget: Continual prediction with LSTM[J]. Neural Computation, 2000, 12(10):2451-2471.
doi: 10.1162/089976600300015015 URL |
| [24] | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous method for deep reinforcement learning [C]//33rd International Conference on Machine Learning. USA: International Machine Learning Society, 2016: 2850-2869. |
| [25] | LEI T, MING L. Towards cognitive exploration through deep reinforcement learning for mobile robots [EB/OL]. (2016-10-06)[2019-06-12]. https://arxiv.org/pdf/1610.01733.pdf |
| [1] | . 触觉辅助导航车辆:增强盲区和透明物体场景中的障碍物检测[J]. J Shanghai Jiaotong Univ Sci, 2026, 31(1): 167-175. |
| [2] | . 融合鸟瞰图特征的模仿与强化学习自动驾驶规划方法[J]. J Shanghai Jiaotong Univ Sci, 2026, 31(1): 154-166. |
| [3] | 陈实, 杨林森, 刘艺洪, 罗欢, 臧天磊, 周步祥. 小样本数据驱动模式下的新建微电网优化调度策略[J]. 上海交通大学学报, 2025, 59(6): 732-745. |
| [4] | 王志博, 呼卫军, 马先龙, 全家乐, 周皓宇. 感知驱动控制的无人机拦截碰撞技术[J]. 空天防御, 2025, 8(4): 78-84. |
| [5] | 周文杰, 付昱龙, 郭相科, 戚玉涛, 张海宾. 基于博弈树与数字平行战场的空战决策方法[J]. 空天防御, 2025, 8(3): 50-58. |
| [6] | 刘雁行, 乔如妤, 梁楠, 陈宇, 于凯, 吴汉霄. 基于负荷准线和深度强化学习的含电动汽车集群系统新能源消纳策略[J]. 上海交通大学学报, 2025, 59(10): 1464-1475. |
| [7] | 杨映荷, 魏汉迪, 范迪夏, 李昂. 基于高斯过程回归和深度强化学习的水下扑翼推进性能寻优方法[J]. 上海交通大学学报, 2025, 59(1): 70-78. |
| [8] | 周毅, 周良才, 史迪, 赵小英, 闪鑫. 基于安全深度强化学习的电网有功频率协同优化控制[J]. 上海交通大学学报, 2024, 58(5): 682-692. |
| [9] | 董玉博1, 崔涛1, 周禹帆1, 宋勋2, 祝月2, 董鹏1. 基于长周期极坐标系追击问题的多智能体强化学习奖赏函数设计方法[J]. J Shanghai Jiaotong Univ Sci, 2024, 29(4): 646-655. |
| [10] | 李舒逸, 李旻哲, 敬忠良. 动态环境下基于改进DQN的多智能体路径规划方法[J]. J Shanghai Jiaotong Univ Sci, 2024, 29(4): 601-612. |
| [11] | 苗镇华1, 黄文焘2, 张依恋3, 范勤勤1. 基于深度强化学习的多模态多目标多机器人任务分配算法[J]. J Shanghai Jiaotong Univ Sci, 2024, 29(3): 377-387. |
| [12] | 全家乐, 马先龙, 沈昱恒. 基于近端策略动态优化的多智能体编队方法[J]. 空天防御, 2024, 7(2): 52-62. |
| [13] | 张威振, 何真, 汤张帆. 风扰下无人机栖落机动的强化学习控制设计[J]. 上海交通大学学报, 2024, 58(11): 1753-1761. |
| [14] | 马驰, 张国群, 孙俊格, 吕广喆, 张涛. 基于深度强化学习的综合电子系统重构方法[J]. 空天防御, 2024, 7(1): 63-70. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||