上海交通大学学报 ›› 2022, Vol. 56 ›› Issue (11): 1554-1560.doi: 10.16183/j.cnki.jsjtu.2021.079
• 电子信息与电气工程 • 上一篇
韩明月, 王英林( )
)
收稿日期:2021-03-16
出版日期:2022-11-28
发布日期:2022-12-02
通讯作者:
王英林
E-mail:wang.yinglin@shufe.edu.cn
作者简介:韩明月(1995-),女,河南省周口市人,博士生,从事自然语言生成、文本因果推理研究.
HAN Mingyue, WANG Yinglin()
Received:2021-03-16
Online:2022-11-28
Published:2022-12-02
Contact:
WANG Yinglin
E-mail:wang.yinglin@shufe.edu.cn
摘要:
自然语言处理中的语法错误纠正 (GEC) 任务存在着低资源性的问题,学习GEC模型需要耗费大量的标注成本以及训练成本.对此,采用从掩码式序列到序列的预训练语言生成模型 (MASS) 中的迁移学习方式,充分利用预训练模型已提取的语言特征,在GEC的标注数据上微调模型,结合特定的前处理、后处理方法改善GEC模型的表现,从而提出一种新的GEC系统(MASS-GEC).在两个公开的GEC任务中评估该系统,在有限的资源下,与当前GEC系统相比,达到了更好的效果.具体地,在CoNLL14 数据集上,该系统在强调查准率的指标F0.5上表现分数为57.9;在JFLEG数据集上,该系统在基于系统输出纠正结果与参考纠正结果n元语法重合度的评估指标GLEU上表现分数为59.1.该方法为GEC任务低资源问题的解决提供了新视角,即从自监督预训练语言模型中,利用适用于GEC任务的文本特征,辅助解决GEC问题.
中图分类号:
韩明月, 王英林. 基于预训练语言模型的语法错误纠正方法[J]. 上海交通大学学报, 2022, 56(11): 1554-1560.
HAN Mingyue, WANG Yinglin. Grammatical Error Correction by Transferring Learning Based on Pre-Trained Language Model[J]. Journal of Shanghai Jiao Tong University, 2022, 56(11): 1554-1560.
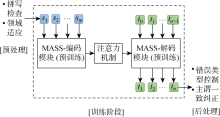
图1
基于 MASS 的GEC系统整体框架
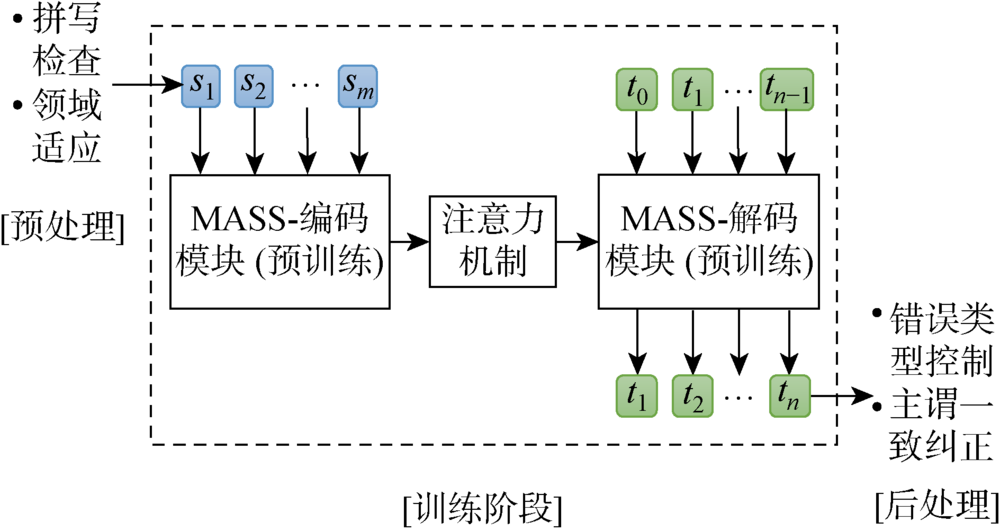
表1
不同的GEC系统结果对比
| 来源 | 时间 | 方法 | 合成语料 数据量/条 | CoNLL14的F0.5指标 | JFLEG的GLEU指标 | |||
|---|---|---|---|---|---|---|---|---|
| 单模型 | 集成模型 | 单模型 | 集成模型 | |||||
| 文献[9] | 2014 | SMT+LM | - | 37.3 | - | - | - | |
| 文献[28] | 2018 | CNN Seq2Seq | - | 46.4 | 54.8 | 51.3 | 57.5 | |
| 文献[6] | 2018 | Transformer Seq2Seq | - | - | 55.8 | - | 59.9 | |
| 文献[29] | 2018 | SMT + NMT+ LM | - | - | 56.3 | - | 61.5 | |
| 文献[7] | 2019 | Copy-Transformer | 3.02×106 | 59.8 | 61.2 | - | 61.0 | |
| 文献[4] | 2019 | BERT序列标注 | 3.02×106 | 59.7 | 61.2 | 60.3 | 61.0 | |
| 文献[30] | 2019 | Transformer +迭代纠正 | 1.7×109 | 56.8 | 60.4 | 61.6 | 63.3 | |
| 本文 | 2020 | MASS-GEC1 | - | 57.5 | - | 58.0 | - | |
| 本文 | 2020 | MASS-GEC2 | - | 56.1 | - | 59.1 | - | |
表2
MASS-GEC系统的消融实验结果
| GEC系统 | CoNLL14 | JFLEG | |||
|---|---|---|---|---|---|
| P | R | F0.5 | GLEU | ||
| MASS-GEC2 | 60.1 | 39.9 | 54.6 | 59.1 | |
| MASS-GEC1 | 67.7 | 36.6 | 57.9 | 58.0 | |
| -主谓一致纠正 | 67.5 | 36.0 | 57.5 | 58.0 | |
| -错误类型控制 | 62.1 | 38.0 | 55.1 | 57.7 | |
| -微调 | 51.6 | 5.2 | 18.5 | 50.4 | |
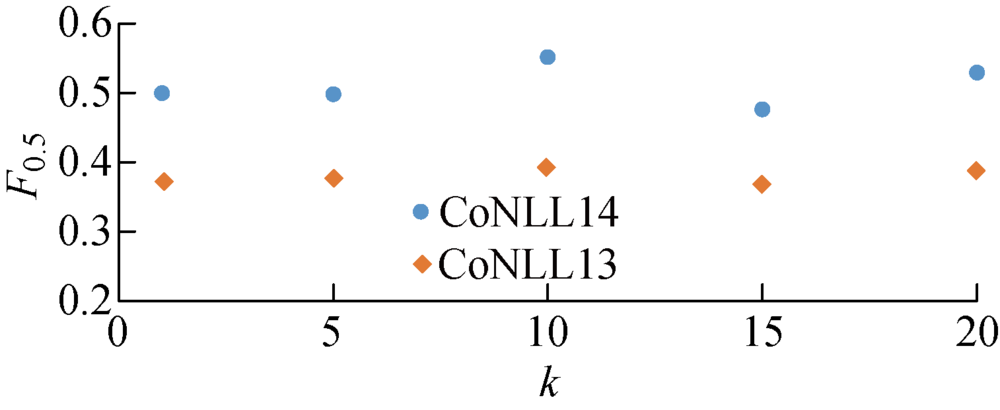
图2
不同领域适应规模下MASS-GEC系统的表现
| [1] | NG H T, WU S M, WU Y, et al. The CoNLL-2013 shared task on grammatical error correction[C]∥Proceedings of the Seventeenth Conference on Computational Natural Language Learning: Shared Task. Sofia, Bulgaria: Association for Computational Linguistics, 2013: 1-12. |
| [2] | NG H T, WU S M, BRISCOE T, et al. The CoNLL-2014 shared task on grammatical error correction[C]∥Proceedings of the Eighteenth Conference on Computational Natural Language Learning: Shared Task. Baltimore, Maryland, USA: Association for Computational Linguistics, 2014: 1-14. |
| [3] | WU J C, YEN T H, CHANG J, et al. NTHU at the CoNLL-2014 shared task[C]∥Proceedings of the Eighteenth Conference on Computational Natural Language Learning: Shared Task. Baltimore, Maryland, USA: Association for Computational Linguistics, 2014: 91-95. |
| [4] | AWASTHI A, SARAWAGI S, GOYAL R, et al. Parallel iterative edit models for local sequence transduction[C]∥Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: Association for Computational Linguistics, 2019: 4251-4261. |
| [5] | OMELIANCHUK K, ATRASEVYCH V, CHERNODUB A, et al. GECToR-grammatical error correction: Tag, not rewrite[C]∥Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications. Seattle, WA, USA: Association for Computational Linguistics, 2020: 163-170. |
| [6] | JUNCZYS-DOWMUNT M, GRUNDKIEWICZ R, GUHA S, et al. Approaching neural grammatical error correction as a low-resource machine translation task[C]∥Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. New Orleans, Louisiana, USA: Association for Computational Linguistics, 2018: 595-606. |
| [7] | ZHAO W, WANG L, SHEN K W, et al. Improving grammatical error correction via pre-training a copy-augmented architecture with unlabeled data[C]∥Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Minneapolis, Minnesota, USA: Association for Computational Linguistics, 2019: 156-165. |
| [8] | FLACHS S, LACROIX O, SØGAARD A. Noisy channel for low resource grammatical error correction[C]∥Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications. Florence, Italy: Association for Computational Linguistics, 2019: 191-196. |
| [9] | FELICE M, YUAN Z, ANDERSEN Ø E, et al. Grammatical error correction using hybrid systems and type filtering[C]∥Proceedings of the Eighteenth Conference on Computational Natural Language Learning: Shared Task. Baltimore, Maryland, USA: Association for Computational Linguistics, 2014: 15-24. |
| [10] |
LIU Z R, LIU Y. Exploiting unlabeled data for neural grammatical error detection[J]. Journal of Computer Science and Technology, 2017, 32(4): 758-767.
doi: 10.1007/s11390-017-1757-4 URL |
| [11] | GRUNDKIEWICZ R, JUNCZYS-DOWMUNT M, HEAFIELD K. Neural grammatical error correction systems with unsupervised pre-training on synthetic data[C]∥Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications. Florence, Italy: Association for Computational Linguistics, 2019: 252-263. |
| [12] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]∥Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Minneapolis, Minnesota, USA: Association for Computational Linguistics, 2019: 4171-4186. |
| [13] | LIU Y H, OTT M, GOYAL N, et al. RoBERTa: A robustly optimized BERT pretraining approach[EB/OL]. (2019-07-26) [2021-03-16]. https:∥arxiv.org/abs/1907.11692. |
| [14] | SONG K T, TAN X, QIN T, et al. MASS: Masked sequence to sequence pre-training for language generation[C]∥Proceedings of the 36th International Conference on Machine Learning. Los Angeles, USA: PMLR, 2019: 5926-5936. |
| [15] | DAHLMEIER D, NG H T, WU S M. Building a large annotated corpus of learner English: The NUS corpus of learner English[C]∥Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. Atlanta, Georgia, USA: Association for Computational Linguistics, 2013: 22-31. |
| [16] | TAJIRI T, KOMACHI M, MATSUMOTO Y. Tense and aspect error correction for ESL learners using global context[C]∥Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju Island, Korea: Association for Computational Linguistics, 2012: 198-202. |
| [17] | YANNAKOUDAKIS H, BRISCOE T, MEDLOCK B. A new dataset and method for automatically grading ESOL texts[C]∥Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies. Portland, Oregon, USA: Association for Computational Linguistics, 2011: 180-189. |
| [18] | BRYANT C, FELICE M, ANDERSEN Ø E, et al. The BEA-2019 shared task on grammatical error correction[C]∥Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications. Florence, Italy: Association for Computational Linguistics, 2019: 52-75. |
| [19] | GE T, WEI F R, ZHOU M. Fluency boost learning and inference for neural grammatical error correction[C]∥Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: Association for Computational Linguistics, 2018: 1055-1065. |
| [20] | XIE Z, GENTHIAL G, XIE S, et al. Noising and denoising natural language: Diverse backtranslation for grammar correction[C]∥Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. New Orleans, Louisiana, USA: Association for Computational Linguistics, 2018: 619-628. |
| [21] | CHOLLAMPATT S, WANG W Q, NG H T. Cross-sentence grammatical error correction[C]∥Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019: 435-445. |
| [22] | KANEKO M, HOTATE K, KATSUMATA S, et al. TMU transformer system using BERT for re-ranking at BEA 2019 grammatical error correction on restricted track[C]∥Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications. Florence, Italy: Association for Computational Linguistics, 2019: 207-212. |
| [23] | ALIKANIOTIS D, RAHEJA V. The unreasonable effectiveness of transformer language models in grammatical error correction[C]∥Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications. Florence, Italy: Association for Computational Linguistics, 2019: 127-133. |
| [24] | KANEKO M, MITA M, KIYONO S, et al. Encoder-decoder models can benefit from pre-trained masked language models in grammatical error correction[C]∥Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Seattle, Washington, USA: Association for Computational Linguistics, 2020: 4248-4254. |
| [25] | CHOE Y J, HAM J, PARK K, et al. A neural grammatical error correction system built on better pre-training and sequential transfer learning[C]∥Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications. Florence, Italy: Association for Computational Linguistics, 2019: 213-227. |
| [26] | NAPOLES C, SAKAGUCHI K, TETREAULT J. JFLEG: A fluency corpus and benchmark for grammatical error correction[C]∥Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Valencia, Spain: Association for Computational Linguistics, 2017: 229-234. |
| [27] | KIYONO S, SUZUKI J, MITA M, et al. An empirical study of incorporating pseudo data into grammatical error correction[C]∥Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: Association for Computational Linguistics, 2019: 1236-1242. |
| [28] | CHOLLAMPATT S, NG H T. A multilayer convolutional encoder-decoder neural network for grammatical error correction[C]∥Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI Press, 2018: 5755-5762. |
| [29] | GRUNDKIEWICZ R, JUNCZYS-DOWMUNT M. Near human-level performance in grammatical error correction with hybrid machine translation[C]∥Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. New Orleans, Louisiana, USA: Association for Computational Linguistics, 2018: 284-290. |
| [30] | LICHTARGE J, ALBERTI C, KUMAR S, et al. Corpora generation for grammatical error correction[C]∥Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Minneapolis, Minnesota, USA: Association for Computational Linguistics, 2019: 3291-3301. |
| [1] | 张靖宜, 贺光辉, 代洲, 刘亚东. 融入BERT的企业年报命名实体识别方法[J]. 上海交通大学学报, 2021, 55(2): 117-123. |
| [2] | 韩明月, 王英林. 基于预训练语言模型的语法错误纠正方法(网络首发)[J]. 上海交通大学学报, 0, (): 0-. |
| 阅读次数 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
全文 708
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
摘要 1060
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||