上海交通大学学报 ›› 2021, Vol. 55 ›› Issue (5): 598-606.doi: 10.16183/j.cnki.jsjtu.2020.011
所属专题: 《上海交通大学学报》2021年12期专题汇总专辑; 《上海交通大学学报》2021年“自动化技术、计算机技术”专题
吴金娥1, 王若愚2, 段倩倩1( ), 李国强1,2, 琚长江2
), 李国强1,2, 琚长江2
收稿日期:2020-01-08
出版日期:2021-05-28
发布日期:2021-06-01
通讯作者:
段倩倩
E-mail:dqq1019@163.com
作者简介:吴金娥(1995-),女,安徽省芜湖市人,硕士生,现主要从事数据异常检测研究.
基金资助:
WU Jin’e1, WANG Ruoyu2, DUAN Qianqian1(), LI Guoqiang1,2, JÜ Changjiang2
Received:2020-01-08
Online:2021-05-28
Published:2021-06-01
Contact:
DUAN Qianqian
E-mail:dqq1019@163.com
摘要:
针对无数据标签的群数据异常检测问题,提出在无监督模式下利用k最近邻(kNN)算法检测群数据异常.为减少由于异常值与正常值之间相互干扰而产生的漏报和误报,提出用反向k近邻(RkNN)算法对异常群数据进行反向过滤. 反向k近邻算法首先将统计距离作为不同群数据间的相似性度量,再用kNN算法求得每个集群的异常得分,并获得初始异常,最后使用RkNN算法对初始异常进行过滤.实验结果证明,所提算法能有效减少漏报和误报,且具有较高的异常检测率和良好的稳定性.
中图分类号:
吴金娥, 王若愚, 段倩倩, 李国强, 琚长江. 基于反向k近邻过滤异常的群数据异常检测[J]. 上海交通大学学报, 2021, 55(5): 598-606.
WU Jin’e, WANG Ruoyu, DUAN Qianqian, LI Guoqiang, JÜ Changjiang. Collective Data Anomaly Detection Based on Reverse k-Nearest Neighbor Filtering[J]. Journal of Shanghai Jiao Tong University, 2021, 55(5): 598-606.
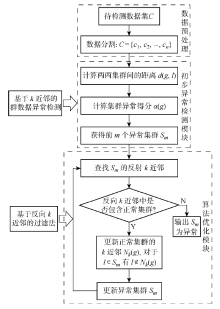
图1
模型建立流程图
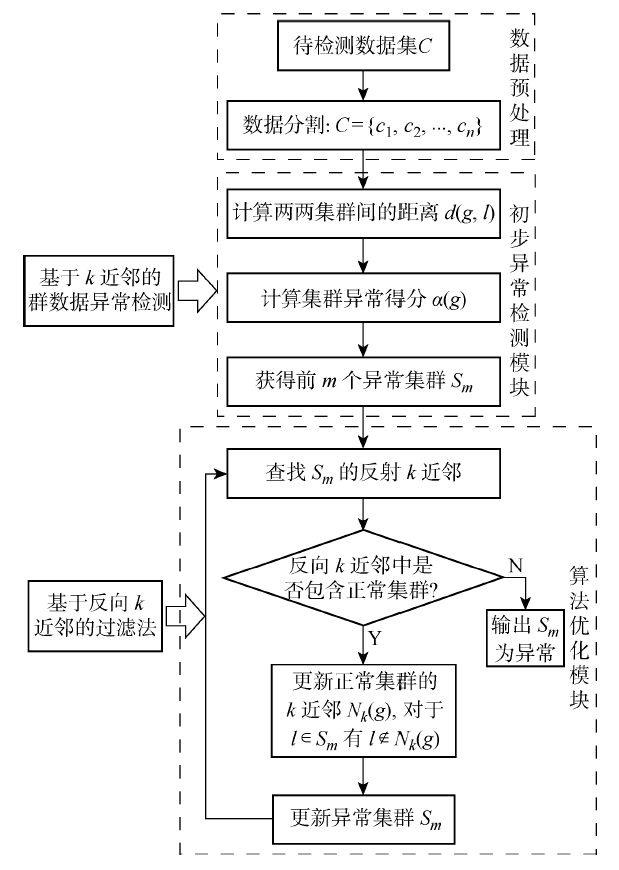
图2
日交易数据分布直方图(第156天)
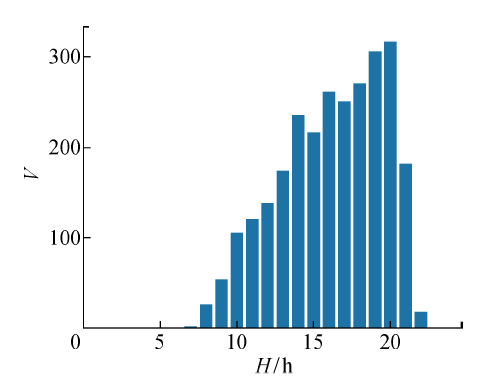

图3
数据集介绍
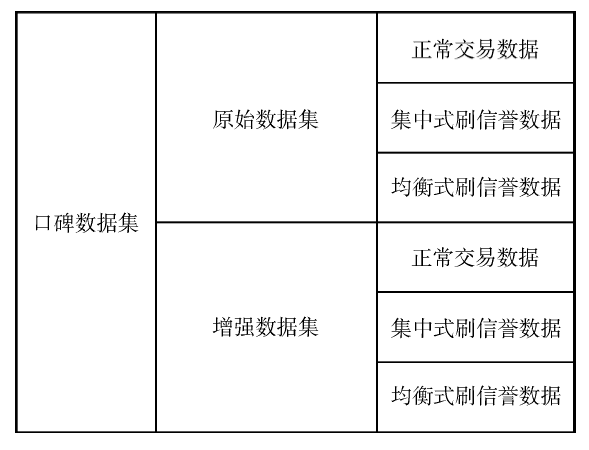

图4
k值对检测结果的影响
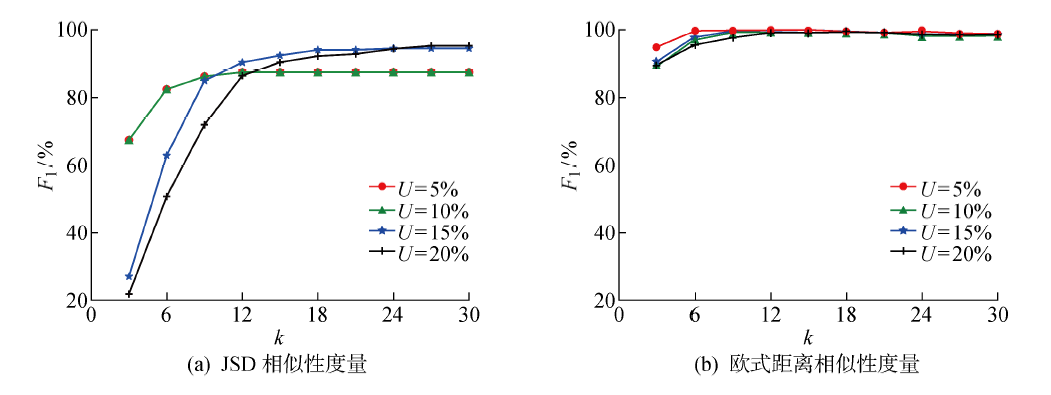

图5
反向过滤干扰值法在原始数据集下实验结果
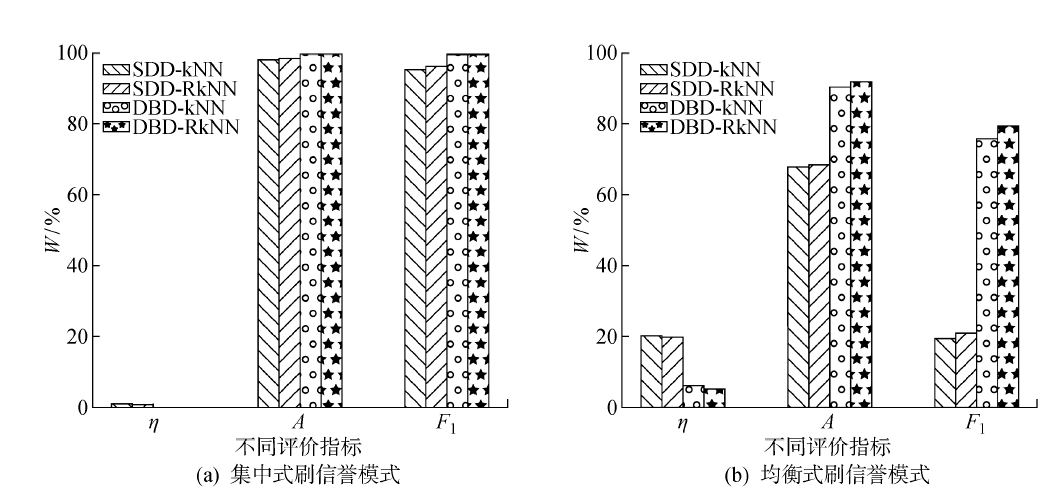

图6
反向过滤干扰值法在增强数据集下实验结果
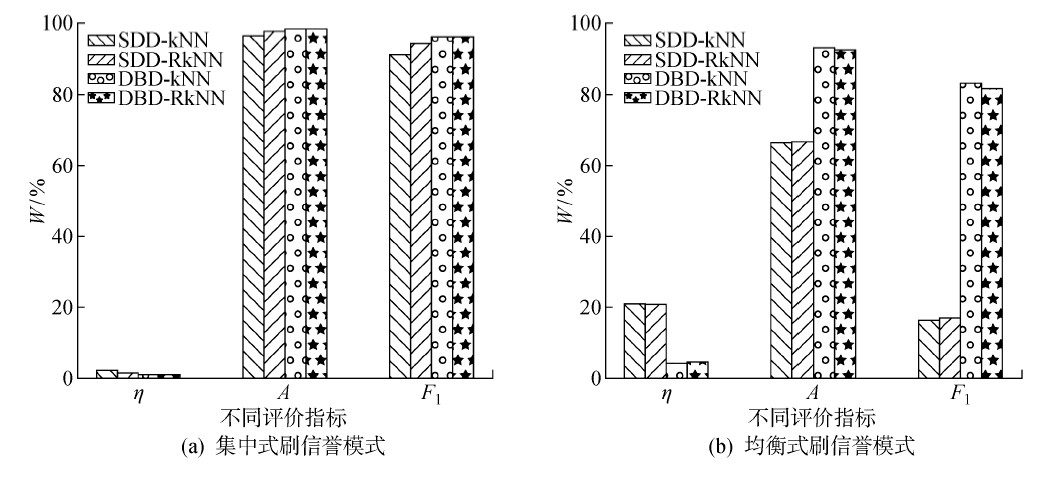
表1
原始数据集下的算法性能对比
| 模式 | 算法名称 | 一阶直方图 | 二阶直方图 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P/% | R/% | F1/% | t/ms | P/% | R/% | F1/% | t/ms | ||||
| 集中式刷信誉 | SDD-RkNN | 96.30 | 96.30 | 96.30 | 4542.80 | 97.23 | 97.23 | 97.23 | 1612.45 | ||
| DBD-RkNN | 99.69 | 99.69 | 99.69 | 2325.97 | 91.69 | 91.69 | 91.69 | 762.44 | |||
| DSDD-E | 78.84 | 99.69 | 87.99 | 1507.32 | 65.06 | 96.92 | 77.71 | 491.29 | |||
| 均衡式刷信誉 | SDD-RkNN | 20.92 | 20.92 | 20.92 | 4401.57 | 80.92 | 80.92 | 80.92 | 1517.24 | ||
| DBD-RkNN | 79.38 | 79.38 | 79.38 | 2265.98 | 69.84 | 69.84 | 69.84 | 718.89 | |||
| DSDD-E | 23.78 | 13.54 | 17.25 | 1400.54 | 54.67 | 80.31 | 64.52 | 494.79 | |||
表2
增强数据集下的算法性能对比
| 模式 | 算法名称 | 一阶直方图 | 二阶直方图 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P/% | R/% | F1/% | t/ms | P/% | R/% | F1/% | t/ms | ||||
| 集中式刷信誉 | SDD-RkNN | 94.46 | 94.46 | 94.46 | 9671.67 | 88.00 | 88.00 | 88.00 | 2108.75 | ||
| DBD-RkNN | 96.30 | 96.30 | 96.30 | 4637.67 | 74.77 | 74.77 | 74.77 | 995.40 | |||
| DSDD-E | 75.17 | 100.00 | 85.70 | 2140.21 | 49.14 | 91.38 | 63.90 | 565.68 | |||
| 均衡式刷信誉 | SDD-RkNN | 16.92 | 16.92 | 16.92 | 10356.19 | 79.69 | 79.69 | 79.69 | 1940.85 | ||
| DBD-RkNN | 81.85 | 81.85 | 81.85 | 4913.40 | 58.46 | 58.46 | 58.46 | 898.06 | |||
| DSDD-E | 23.35 | 13.84 | 17.38 | 2280.15 | 53.77 | 75.08 | 60.98 | 550.01 | |||

图7
不同异常概率下,3种算法的稳定性对比

| [1] | MEHROTRA K G, MOHAN C K, HUANG H M. Anomaly detection principles and algorithms[M]. Switzerland: Springer International Publishing, 2017. |
| [2] | TIMČENKO V, GAJIN S. Ensemble classifiers for supervised anomaly based network intrusion detection [C]//2017 13th IEEE International Conference on Intelligent Computer Communication and Processing (ICCP). Piscataway, NJ, USA: IEEE, 2017: 13-19. |
| [3] | HUSSAIN B, DU Q H, REN P Y. Semi-supervised learning based big data-driven anomaly detection in mobile wireless networks[J]. China Communications, 2018, 15(4):41-57. |
| [4] | MILLER D J, KESIDIS G, QIU Z C. Unsupervised parsimonious cluster-based anomaly detection (PCAD) [C]//2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP). Piscataway, NJ, USA: IEEE, 2018: 1-6. |
| [5] | CHANDOLA V, BANERJEE A, KUMAR V. Anomaly detection[J]. ACM Computing Surveys, 2009, 41(3):1-58. |
| [6] |
TAO X T, LI G Q, SUN D, et al. A game-theoretic model and analysis of data exchange protocols for Internet of Things in clouds[J]. Future Generation Computer Systems, 2017, 76:582-589.
doi: 10.1016/j.future.2016.12.030 URL |
| [7] |
EDGEWORTH F Y. On discordant observations[J]. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 1887, 23(143):364-375.
doi: 10.1080/14786448708628471 URL |
| [8] |
KNORR E M, NG R T, TUCAKOV V. Distance-based outliers: Algorithms and applications[J]. The VLDB Journal, 2000, 8(3/4):237-253.
doi: 10.1007/s007780050006 URL |
| [9] | LEE J G, HAN J W, LI X L. Trajectory outlier detection: A partition-and-detect framework [C]//2008 IEEE 24th International Conference on Data Engineering. Piscataway, NJ, USA: IEEE, 2008: 140-149. |
| [10] | LUAN F J, ZHANG Y T, CAO K Y, et al. Based local density trajectory outlier detection with partition-and-detect framework [C]//2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD). Piscataway, NJ, USA: IEEE, 2017: 1708-1714. |
| [11] |
DJENOURI Y, BELHADI A, LIN J C, et al. Adapted K-nearest neighbors for detecting anomalies on spatio-temporal traffic flow[J]. IEEE Access, 2019, 7:10015-10027.
doi: 10.1109/Access.6287639 URL |
| [12] | 毛江云, 吴昊, 孙未未. 路网空间下基于马尔可夫决策过程的异常车辆轨迹检测算法[J]. 计算机学报, 2018, 41(8):1928-1942. |
| MAO Jiangyun, WU Hao, SUN Weiwei. Vehicle trajectory anomaly detection in road network via Markov decision process[J]. Chinese Journal of Computers, 2018, 41(8):1928-1942. | |
| [13] | WANG R Y, SUN D, LI G Q, et al. Statistical detection of collective data Fraud [C]//International Conference on Multimedia and Expo. London, UK: IEEE, 2020. |
| [14] |
KULLBACK S, LEIBLER R A. On information and sufficiency[J]. Annals of Mathematical Statistics, 1951, 22(1):79-86.
doi: 10.1214/aoms/1177729694 URL |
| [15] | SALEM O, NAÏT-ABDESSELAM F, MEHAOUA A. Anomaly detection in network traffic using Jensen-Shannon divergence [C]//2012 IEEE International Conference on Communications (ICC). Piscataway, NJ, USA: IEEE, 2012: 5200-5204. |
| [16] |
COVER T, HART P. Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory, 1967, 13(1):21-27.
doi: 10.1109/TIT.1967.1053964 URL |
| [17] | WOHLKINGER W, ALDOMA A, RUSU R B, et al. 3DNet: Large-scale object class recognition from CAD models [C]//2012 IEEE International Conference on Robotics and Automation. Piscataway, NJ, USA: IEEE, 2012: 5384-5391. |
| [18] | AGGARWAL C C. Proximity-based outlier detection[M]// Outlier Analysis. Switzerland: Springer International Publishing, 2016: 111-147. |
| [19] | 陈瑜. 离群点检测算法研究[D]. 兰州: 兰州大学, 2018. |
| CHEN Yu. Research on the outliers detection algorithm[D]. Lanzhou: Lanzhou University, 2018. |
| [1] | 王晓倩, 周羽生, 毛源军, 李彬, 周文晴, 苏盛. 基于神经网络分位数的分布式光伏发电功率异常识别方法[J]. 上海交通大学学报, 2025, 59(6): 836-844. |
| [2] | 刘建欣, 潘如如, 周建. 基于欠完备字典重构的无监督织物疵点检测方法[J]. 上海交通大学学报, 2025, 59(2): 283-292. |
| [3] | . 基于双流自编码器的无监督动作识别[J]. J Shanghai Jiaotong Univ Sci, 2025, 30(2): 330-336. |
| [4] | 张晟嘉, 林天成, 徐奕, . 利用软伪标签促进无监督领域自适应与课程学习[J]. J Shanghai Jiaotong Univ Sci, 2023, 28(6): 703-716. |
| [5] | 陈培芝1,2, 郭逸凡1, 王大寒1,2, 陈金铃1,3,4. Dlung:无监督少镜头差异呼吸运动建模[J]. J Shanghai Jiaotong Univ Sci, 2023, 28(4): 536-. |
| [6] | 张建, 胡小锋, 张亚辉. 基于自步学习的刀具加工过程监测数据异常检测方法[J]. 上海交通大学学报, 2023, 57(10): 1346-1354. |
| [7] | 许勇, 蔡云泽, 宋林. 基于数据驱动的核电设备状态评估研究综述[J]. 上海交通大学学报, 2022, 56(3): 267-278. |
| [8] | 李钰, 杨道勇, 刘玲亚, 王易因. 利用生成对抗网络实现水下图像增强[J]. 上海交通大学学报, 2022, 56(2): 134-142. |
| [9] | 武光利, 郭振洲, 李雷霆, 王成祥. 融合FCN和LSTM的视频异常事件检测[J]. 上海交通大学学报, 2021, 55(5): 607-614. |
| [10] | 姜宇迪, 胡晖, 殷跃红. 基于无监督迁移学习的电梯制动器剩余寿命预测[J]. 上海交通大学学报, 2021, 55(11): 1408-1416. |
| [11] | 李宇翀, 魏东, 罗兴国, 钱叶魁, 刘凤荣. 基于多元增量分析的全网络在线异常检测方法[J]. 上海交通大学学报, 2016, 50(9): 1368-1375. |
| [12] | 郝圣桥,许黎明,沈伟,王建楼. 电液伺服阀状态在线特征提取和异常检测方法 [J]. 上海交通大学学报(自然版), 2010, 44(12): 1747-1752. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||