上海交通大学学报 ›› 2021, Vol. 55 ›› Issue (9): 1158-1168.doi: 10.16183/j.cnki.jsjtu.2019.307
所属专题: 《上海交通大学学报》2021年12期专题汇总专辑; 《上海交通大学学报》2021年“自动化技术、计算机技术”专题
张峻宁1, 苏群星2( ), 王成3, 徐超4, 李一宁5
), 王成3, 徐超4, 李一宁5
收稿日期:2019-10-23
出版日期:2021-09-28
发布日期:2021-10-08
通讯作者:
苏群星
E-mail:LPZ20101796@qq.com
作者简介:张峻宁(1992-),男,四川省巴中市人,博士生,主要从事深度学习,SLAM技术,计算机视觉与模式识别研究
基金资助:
ZHANG Junning1, SU Qunxing2(), WANG Cheng3, XU Chao4, LI Yining5
Received:2019-10-23
Online:2021-09-28
Published:2021-10-08
Contact:
SU Qunxing
E-mail:LPZ20101796@qq.com
摘要:
语义标签的人工标注成本高,耗时长,基于域自适应的非监督语义分割是非常必要的.针对间隙大的场景或像素易限制模型训练、降低语义分割精度的问题,通过分阶段训练和可解释蒙版消除大间隙图片和像素的干扰,提出了一种改进变换网络的域自适应语义分割网络(DA-SSN).首先,针对部分源图到目标图的域间隙大、网络模型训练困难的问题,利用训练损失阈值划分大间隙的源图数据集,提出一种分阶段的变换网络训练策略,在保证小间隙源图的语义对齐基础上,提高了大间隙源图的变换质量.然后,为了进一步缩小源图中部分像素与目标图域间间隙,提出一种可解释蒙版.通过预测每个像素在源图域和目标图域之间的间隙缩小置信度,忽略对应像素的训练损失,以消除大间隙像素对其他像素语义对齐的影响,使得模型训练只关注高置信度像素的域间隙.结果表明,所提算法相比于原始的域自适应语义分割网络的分割精度更高.与其他流行算法的结果相比,所提方法获得了更高质量的语义对齐,表明了所提方法精度高的优势.
中图分类号:
张峻宁, 苏群星, 王成, 徐超, 李一宁. 一种改进变换网络的域自适应语义分割网络[J]. 上海交通大学学报, 2021, 55(9): 1158-1168.
ZHANG Junning, SU Qunxing, WANG Cheng, XU Chao, LI Yining. A Domain Adaptive Semantic Segmentation Network Based on Improved Transformation Network[J]. Journal of Shanghai Jiao Tong University, 2021, 55(9): 1158-1168.

图1
域自适应语义分割的框架
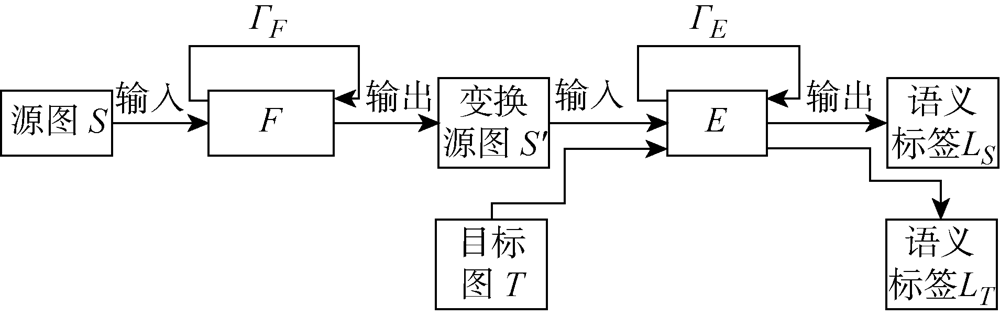

图2
蒙版网络结构

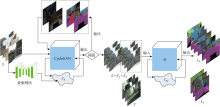
图3
本文算法框架图

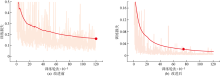
图4
模型改进前后的训练损失

表1
分阶段训练前后的性能对比
| 方法 | 训练损失 | 平均交并比 |
|---|---|---|
| 原始方法 | 0.383 | 41.3 |
| D2 | 0.339 | 42.1 |
表2
不同阈值的模型性能变化
| 方法 | 损失阈值ϑ | 平均交并比 |
|---|---|---|
| D2 | 0.38 | 41.4 |
| 0.36 | 41.6 | |
| 0.34 | 42.0 | |
| 0.32 | 42.1 | |
| 0.30 | 41.9 |

图5
蒙版可视化及目标图和源图生成图
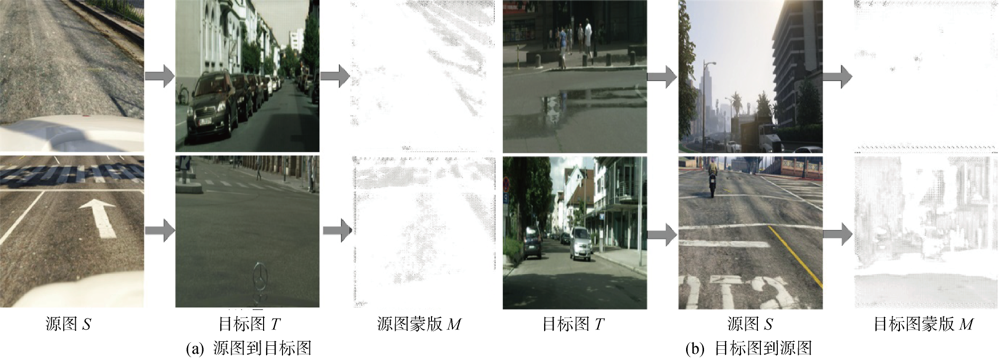
表3
MaskNet应用前后的模型性能对比
| 方法 | 域间间隙 | 平均交并比 |
|---|---|---|
| 原始方法 | 0.383 | 41.3 |
| D3 | 0.015 | 42.2 |
| 本文方法 | 0.006 | 42.4 |

图6
源图的变换效果比较


图7
不同算法的语义分割结果可视化

表4
不同算法在GTA5→Cityscapes数据集上的语义分割结果比较
| 网络 | 算法 | road | sidewalk | Building | wall | fence | pole | t-light | t-sign | wegetation | terrain |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepLab v2[ | Cycada | 85.2 | 37.2 | 76.5 | 21.8 | 15.0 | 23.8 | 22.9 | 21.5 | 80.5 | 31.3 |
| DCAN | 82.3 | 26.7 | 77.4 | 23.7 | 20.5 | 20.4 | 30.3 | 15.9 | 80.9 | 25.4 | |
| CLAN | 88.0 | 30.6 | 79.2 | 23.4 | 20.5 | 26.1 | 23.0 | 14.8 | 81.6 | 34.5 | |
| BLD | 89.2 | 40.9 | 81.2 | 29.1 | 19.2 | 14.2 | 29.0 | 19.6 | 83.7 | 35.9 | |
| 本文 | 90.9 | 42.3 | 82.1 | 30.8 | 18.5 | 16.7 | 31.5 | 20.8 | 85.9 | 33.7 | |
| Resnet[ | Cycada | 86.7 | 35.6 | 80.1 | 19.8 | 17.5 | 38.0 | 39.9 | 41.5 | 82.7 | 27.9 |
| DCAN | 85.0 | 30.8 | 81.3 | 25.8 | 21.2 | 22.2 | 25.4 | 26.6 | 83.4 | 36.7 | |
| CLAN | 87.0 | 27.1 | 79.6 | 27.3 | 23.3 | 28.3 | 35.5 | 24.2 | 83.6 | 27.4 | |
| BLD | 91.0 | 44.7 | 84.2 | 34.6 | 27.6 | 30.2 | 36.0 | 36.0 | 85.0 | 43.6 | |
| 本文 | 92.2 | 42.3 | 83.5 | 36.2 | 28.0 | 31.8 | 36.7 | 36.2 | 85.7 | 44.6 | |
| 网络 | 算法 | sky | person | rider | car | truck | bus | train | motorbike | bicycle | mIoU |
| DeepLab v2[ | Cycada | 60.7 | 50.5 | 9.0 | 76.9 | 17.1 | 28.2 | 4.5 | 9.8 | 0 | 35.4 |
| DCAN | 69.5 | 52.6 | 11.1 | 79.6 | 24.9 | 21.2 | 1.30 | 17.0 | 6.70 | 36.2 | |
| CLAN | 72.0 | 45.8 | 7.9 | 80.5 | 26.6 | 29.9 | 0.0 | 10.7 | 0.0 | 36.6 | |
| BLD | 80.7 | 54.7 | 23.3 | 82.7 | 25.8 | 28.0 | 2.3 | 25.7 | 19.9 | 41.3 | |
| 本文 | 83.3 | 55.9 | 23.6 | 82.1 | 27.7 | 29.4 | 2.2 | 26.8 | 21.2 | 42.4 | |
| Resnet[ | Cycada | 73.6 | 64.9 | 19 | 65.0 | 12.0 | 28.6 | 4.5 | 31.1 | 42.0 | 42.7 |
| DCAN | 76.2 | 58.9 | 24.9 | 80.7 | 29.5 | 42.9 | 2.50 | 26.9 | 11.6 | 41.7 | |
| CLAN | 74.2 | 58.6 | 28.0 | 76.2 | 33.1 | 36.7 | 6.7 | 31.9 | 31.4 | 43.2 | |
| BLD | 83.0 | 58.6 | 31.6 | 83.3 | 35.3 | 49.7 | 3.3 | 28.8 | 35.6 | 48.5 | |
| 本文 | 81.2 | 59.8 | 32.7 | 84.1 | 36.3 | 49.9 | 3.0 | 30.7 | 37.4 | 49.1 |
| [1] | AKHAWAJI R, SEDKY M, SOLIMAN A H. Illegal parking detection using Gaussian mixture model and Kalman filter[C]// 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA). Piscataway, NJ, USA: IEEE, 2017: 840-847. |
| [2] | GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 2414-2423. |
| [3] | LI C, WAND M. Combining Markov random fields and convolutional neural networks for image synconfproc[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 2479-2486. |
| [4] | DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]// 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2005: 886-893. |
| [5] | GHOSH A, BHATTACHARYA B, CHOWDHURY S B R. SAD-GAN: Synthetic autonomous driving using generative adversarial networks[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 1-5. |
| [6] | MATHIEU M, COUPRIE C, LECUN Y. Deep multi-scale video prediction beyond mean square error[J]. Statistics, 2015, 3(1):834-848. |
| [7] |
XUE Y, XU T, ZHANG H, et al. SegAN: adversarial network with multi-scale L_1 loss for medical image segmentation[J]. Neuroinformatics, 2018, 16(3/4):383-392.
doi: 10.1007/s12021-018-9377-x URL |
| [8] | JONATHAN L, SHELHAMER E, DARRELL T, et al. Fully convolutional networks for semantic segmentation[J]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3431-3440. |
| [9] | LI Y S, LU Y, NUNO V. Bidirectional learning for domain adaptation of semantic segmentation[C]// Proceedings of the Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019: 6929-6938. |
| [10] | AZADI S, FISHER M, KIM V, et al. Multi-content GAN for fewshot font style transfer [C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. |
| [11] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4):834-848.
doi: 10.1109/TPAMI.2017.2699184 URL |
| [12] |
NIU Z J, LIU W, ZHAO J Y, et al. DeepLab-based spatial feature extraction for hyperspectral image classification[J]. IEEE Geoscience and Remote Sensing Letters, 2019, 16(2):251-255.
doi: 10.1109/LGRS.2018.2871507 URL |
| [13] | CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// Computer Vision-ECCV 2018. Amsterdam: Springer International Publishing, 2018: 1-12. |
| [14] | ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]// 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2017: 2242-2251. |
| [15] | JUDY H, TAESUNG P. Cycada: Cycle-consistent adversarial domain adaptation[C]// Proceedings of the 35th International Conference on Machine Learning (ICML). Vienna, Austria: IEEE, 2017: 1-9. |
| [16] | HOFFMAN J, WANG D Q, YU F, et al. FCNs in the wild: Pixel-level adversarial and constraint-based adaptation[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 1-10. |
| [17] | ZHANG Y, DAVID P, GONG B Q. Curriculum domain adaptation for semantic segmentation of urban scenes[C]// 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2017: 2039-2049. |
| [18] | TSAI Y H, HUNG W C, SCHULTER S, et al. Learning to adapt structured output space for semantic segmentation[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2018: 7472-7481. |
| [19] | SALEH F S, ALIAKBARIAN M S, SALZMANN M, et al. Effective use of synthetic data for urban scene semantic segmentation[C]// Computer Vision-ECCV 2018. Amsterdam: Springer International Publishing, 2018: 86-103. |
| [20] | LIU M Y, BREUEL T, KAUTZ J. Unsupervised image-to-image translation networks[C]// In Advances in Neural Information Processing Systems 2017. Long Beach, CA, USA: IEEE, 2017: 700-708. |
| [21] | HUANG X, LIU M Y, BELONGIE S, et al. Multimodal unsupervised image-to-image translation[C]// Computer Vision-ECCV 2018. Amsterdam: Springer International Publishing, 2018: 179-196. |
| [22] | WU Z X, HAN X T, LIN Y L, et al. DCAN: Dual channel-wise alignment networks for unsupervised scene adaptation[C]// Computer Vision-ECCV 2018. Amsterdam: Springer International Publishing, 2018: 1-12. |
| [23] | ZHOU T H, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video[C]// Computer Vision and Pattern Recognition (CVPR). Honolulu, Hawaii, USA: IEEE, 2017: 6612-6619. |
| [24] | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 770-778. |
| [25] | RICHTER S R, VINEET V, ROTH S, et al. Playing for data: Ground truth from computer games[C]// Computer Vision-ECCV 2016. Amsterdam: Springer International Publishing, 2016: 102-118. |
| [26] | CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 3213-3223. |
| [27] | LUO Y W, ZHENG L, GUAN T, et al. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2019: 2502-2511. |
| [28] | ZOU Y, YU Z D, VIJAYA KUMAR B V K, et al. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training[C]// Computer Vision-ECCV 2018. Amsterdam: Springer International Publishing, 2018: 297-313. |
| [1] | 武光利, 郭振洲, 李雷霆, 王成祥. 融合FCN和LSTM的视频异常事件检测[J]. 上海交通大学学报, 2021, 55(5): 607-614. |
| [2] | 蒋兴浩, 赵泽宇, 许可. 基于视觉的飞行器智能目标检测对抗攻击技术[J]. 空天防御, 2021, 4(1): 8-13. |
| [3] | 马波,周越. 一种新的多视角人脸跟踪算法[J]. 上海交通大学学报(自然版), 2010, 44(07): 902-0906. |
| [4] | 应俊豪,张秀彬. 矿石颗粒尺度分布的双圆算法[J]. 上海交通大学学报(自然版), 2010, 44(03): 384-0388. |
| 阅读次数 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
全文 824
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
摘要 836
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||