Journal of Shanghai Jiao Tong University ›› 2025, Vol. 59 ›› Issue (1): 70-78.doi: 10.16183/j.cnki.jsjtu.2023.188
• Naval Architecture, Ocean and Civil Engineering • Previous Articles Next Articles
YANG Yinghe1, WEI Handi1,2( ), FAN Dixia3, LI Ang3
), FAN Dixia3, LI Ang3
Received:2023-05-11
Revised:2023-06-14
Accepted:2023-06-19
Online:2025-01-28
Published:2025-02-06
CLC Number:
YANG Yinghe, WEI Handi, FAN Dixia, LI Ang. Optimization Method of Underwater Flapping Foil Propulsion Performance Based on Gaussian Process Regression and Deep Reinforcement Learning[J]. Journal of Shanghai Jiao Tong University, 2025, 59(1): 70-78.
Add to citation manager EndNote|Ris|BibTeX
URL: https://xuebao.sjtu.edu.cn/EN/10.16183/j.cnki.jsjtu.2023.188
Tab.1
Range of variable intervals
| 参数 | 下边界 | 上边界 |
|---|---|---|
| 横荡(首摇)频率,f/Hz | 0.5 | 0.7 |
| 首摇运动幅值,z0/(°) | 25 | 55 |
| 横荡运动幅值,y0/mm | 20 | 65 |
| 运动相位差,ϕ/rad | 0.52 | 5.76 |
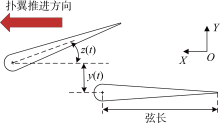
Fig.1
Illustration of flapping foil coupling motion

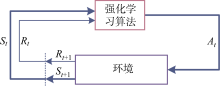
Fig.2
Sketch of framework of reinforcement learning algorithm

Tab.2
Common kernel functions for GPR
| 核函数 | 函数关系式 |
|---|---|
| Matern 3/2 | k(xi, xj|θ)=σ2exp |
| Matern 5/2 | k(xi, xj|θ)=σ2 |
| ARD Matern 3/2 | k(xi, xj|θ)=σ2(1+ |
| ARD Matern 5/2 | k(xi, xj|θ)=σ2 |
| Squared exponential | k(xi, xj|θ)=σ2exp |
| Absolute exponential | k(xi, xj|θ)=σ2exp |
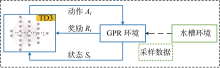
Fig.3
Overall flow chart of GPR-TD3 method

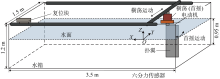
Fig.4
Layout of flapping foil propulsion device

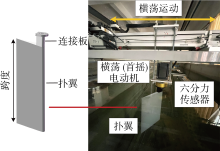
Fig.5
Three-dimensional diagram of flapping foil

Tab.3
GPR model parameters of motion parameters and flapping foil propulsion speed
| 核函数 | Ls | Nl | On | M | R | P |
|---|---|---|---|---|---|---|
| Matern 3/2 | 0.000 688 | 71 523 | 16 | 2.128 | 3.108 | 0.864 |
| Matern 5/2 | 0.000 562 | 11 281 | 12 | 12.597 | 16.011 | 0.640 |
| ARD Matern 3/2 | [2.385 7.976 6.998 4.158] | 39 948 | 1 | 2.128 | 3.108 | 0.864 |
| ARD Matern 5/2 | [5.088 1.123 8.345 5.086] | 32 307 | 18 | 12.597 | 16.011 | 0.640 |
| Squared exponential | 0.008 38 | 19 108 | 7 | 1.274 | 1.516 | 0.956 |
| Absolute exponential | 0.007 72 | 32 667 | 100 | 1.006 | 1.832 | 0.957 |
Tab.4
GPR model parameters of motion parameters and flapping foil propulsion efficiency
| 核函数 | Ls | Nl | On | M | R | P |
|---|---|---|---|---|---|---|
| Matern 3/2 | 0.689 | 11 820 | 13 | 0.010 9 | 0.014 6 | -0.645 |
| Matern 5/2 | 0.946 | 79 233 | 3 | 0.010 9 | 0.014 7 | -0.621 |
| Squared exponential | 0.001 12 | 39 666 | 2 | 0.010 9 | 0.014 6 | 0.250 |
| Absolute exponential | 0.043 3 | 46 725 | 5 | 0.010 9 | 0.014 7 | -0.931 |

Fig.6
Average reward curve for propulsion speed and optimal reward curves for propulsion efficiency


Fig.7
Convergence position of propulsion velocity action and corresponding GPR 2D contour map

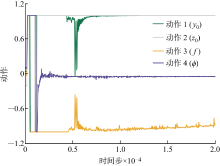
Fig.8
Convergence position of propulsion efficiency action
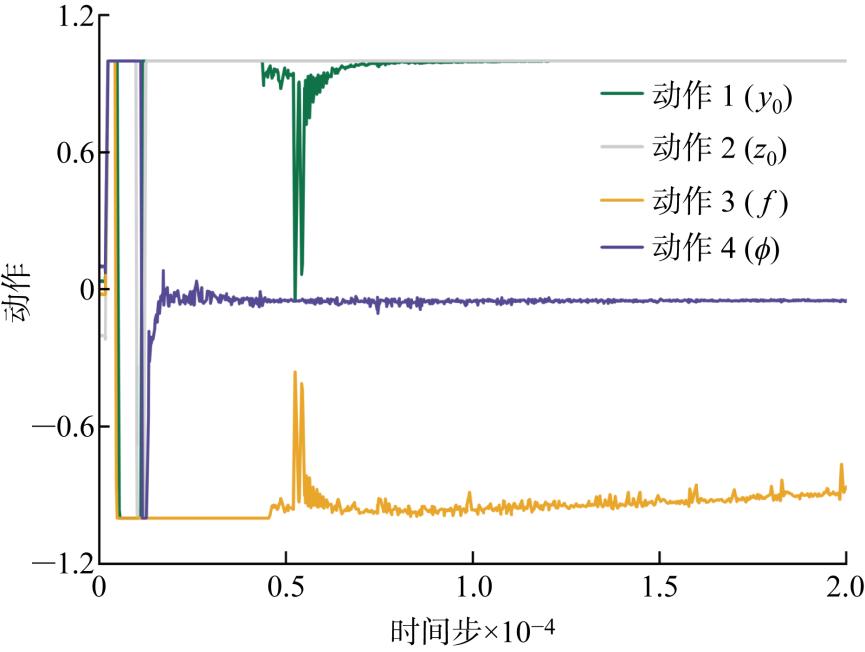
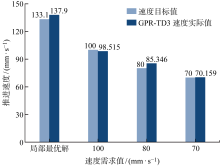
Fig.9
Comparison of speed target value and actual value of GPR-TD3 speed

Tab.5
Number of samples and learned actions required by traditional reinforcement learning and GPR-TD3 methods
| 类别 | 传统强化学习样本数量 | GPR-TD3样本数量 | 动作向量 |
|---|---|---|---|
| 推进速度局部最优 | 9 200 | 290 | [ |
| 推进效率局部最优 | 6 200 | 290 | [ |
| 推进速度100 mm/s | 5 300 | 290 | [ |
| 推进速度80 mm/s | 5 900 | 290 | [ |
| 推进速度70 mm/s | 4 300 | 290 | [ |
| [1] | MANNAM N, KRISHNANKUTTY P, VIJAYAKUMARAN H, et al. Experimental and numerical study of penguin mode flapping foil propulsion system for ships[J]. Journal of Bionic Engineering, 2017, 14(4): 770-780. |
| [2] | WU X, ZHANG X, TIAN X, et al. A review on fluid dynamics of flapping foils[J]. Ocean Engineering, 2020, 195: 106712. |
| [3] | ASHRAF M A, YOUNG J, LAI J C A, et al. Oscillation frequency and amplitude effects on plunging airfoil propulsion and flow periodicity[J]. AIAA Journal, 2012, 50(11): 2308-2324. |
| [4] | KHALID M, AKHTAR I, IMTIAZ H, et al. On the hydrodynamics and nonlinear interaction between fish in tandem configuration[J]. Ocean Engineering, 2018, 157: 108-120. |
| [5] | DAS A, SHUKLA R K, GOVARDHAN R N. Existence of a sharp transition in the peak propulsive efficiency of a low-Re pitching foil[J]. Journal of Fluid Mechanics, 2016, 800: 307-326. |
| [6] | MACKOWSKI A W, WILLIAMSON C H K. Direct measurement of thrust and efficiency of an airfoil undergoing pure pitching[J]. Journal of Fluid Mechanics, 2015, 765: 524-543. |
| [7] | AMIRALAEI M R, ALIGHANBARI H, HASHEMI S M. An investigation into the effects of unsteady parameters on the aerodynamics of a low Reynolds number pitching airfoil[J]. Journal of Fluids and Structures, 2010, 26(6): 979-993. |
| [8] | SCOTT F, HERKE H, DAVID M. Addressing function approximation error in actor-critic methods[C]// Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018: 1587-1596. |
| [9] | THAKOR M, KUMAR G, DAS D, et al. Investigation of asymmetrically pitching airfoil at high reduced frequency[J]. Physics of Fluids, 2020, 32(5): 053607. |
| [10] | CHENG M, JIAO L, YAN P, et al. Prediction of surface residual stress in end milling with Gaussian process regression[J]. Measurement, 2021, 178(11): 109333. |
| [11] | GARNIER P, VIQUERAT J, RABAULT J, et al. A review on deep reinforcement learning for fluid mechanics[J]. Computers & Fluids, 2021, 225: 104973. |
| [1] | DONG Yubo1 (董玉博), CUI Tao1 (崔涛), ZHOU Yufan1 (周禹帆), SONG Xun2 (宋勋), ZHU Yue2 (祝月), DONG Peng1∗ (董鹏). Reward Function Design Method for Long Episode Pursuit Tasks Under Polar Coordinate in Multi-Agent Reinforcement Learning [J]. J Shanghai Jiaotong Univ Sci, 2024, 29(4): 646-655. |
| [2] | ZHU Haoran, CHEN Ziqiang, YANG Deqing. State of Health Estimation of Li-Ion Batteries Based on Differential Thermal Voltammetry and Gaussian Process Regression [J]. Journal of Shanghai Jiao Tong University, 2024, 58(12): 1925-1934. |
| [3] | WANG Ziyao, GUO Fengxiang, CHEN Li. Engine Emission Prediction Based on Extrapolated Gaussian Process Regression Method [J]. Journal of Shanghai Jiao Tong University, 2022, 56(5): 604-610. |
| [4] | JI Xiukun (冀秀坤), HAI Jintao (海金涛), LUO Wenguang (罗文广), LIN Cuixia (林翠霞), XIONG Yu(熊 禹), OU Zengkai (殴增开), WEN Jiayan(文家燕). Obstacle Avoidance in Multi-Agent Formation Process Based on Deep Reinforcement Learning [J]. J Shanghai Jiaotong Univ Sci, 2021, 26(5): 680-685. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||