

为了保证着舰的安全性,目前着舰作业中设置有多名着舰信号官(landing signal officer,LSO)向飞行员发出指令,引导其安全着舰.着舰信号官通常在位于甲板着舰区后部左舷的着舰信号官工作站中,通过无线电、灯光等方式引导舰载机飞行员完成一系列精准操作.在着舰的最后阶段,舰载机航迹偏差、尾钩故障、损坏等原因可能导致尾钩挂不上拦阻索,如果着舰信号官认为舰载机超出着舰安全边界或拉制失败,则飞行员必须快速执行逃逸复飞操作.舰载机着舰是强实时、高动态下的高复杂度作业,在某些情况下存在着舰信号官不能及时发出正确的引导指令或飞行员来不及执行指令的可能.因此,通过自动化、智能化的方式协助着舰信号官进行高效、可靠的拉制状态识别,尽早形成并发出引导指令,有助于提高着舰引导的效率及安全性.
拉制状态识别可通过基于力学传感器的侵入式和基于视觉信息的非侵入式两种方式实现.侵入式识别虽然实现思路简单,但需要对装备进行改造升级,影响现役装备的可靠性,且时敏性差.与之相比,基于视觉信息的非侵入式识别对现役装备影响小,具有较好的实时性甚至超前性,可行性较强.另外,影响舰载机着舰拉制状态的多种因素,包括舰载机着舰点、尾钩与拦阻索的几何构型、舰载机姿态及航速等都可以通过视觉信息进行有效识别和量化.
基于视觉信息的舰载机阻拦拉制状态的识别涉及多种舰面关键目标,包括阻拦索和舰载机尾钩等,因此对舰面关键目标的准确识别是实现阻拦拉制状态识别的基础.此外,舰载机尾钩与阻拦索啮合区域相对于整张图像的面积比例较小,因此阻拦拉制状态视觉识别可归为小目标识别问题.
针对舰面复杂场景下的目标识别问题,一些学者对传统目标识别算法和模型进行了优化改进.汪丁等[7]提出一种舰面多目标识别算法,在YOLOv4-tiny中引入卷积注意力和空间金字塔池化结构,并改用Mish激活函数提升泛化能力.范加利等[8]提出一种舰面多尺度目标识别算法,通过构建多尺度区域建议网络提取特征,使用K-means聚类算法生成锚框.朱兴动等[9]提出适用于舰面目标识别的改进YOLOv3算法,使用聚类算法确定先验锚框的尺寸和宽高比等参数,并在输出网络中改进函数的参数设定.针对小目标识别问题,目前已有多种提升识别性能的方法.一种方法是利用特征上下文信息,例如Xu等[10]提出一种基于双模块特征提取的学习网络,该网络增加了感受野的多样性,融合了网络中间层的多尺度特征.另一种方法是利用多尺度特性,例如Lin等[11]提出的特征金字塔网络,使用具有横向连接的架构,通过生成多尺寸图片并提取多尺度的特征进行识别.此外,改进锚点框设计也是提升识别性能的关键,例如Zhang等[12]通过合锚点框检测和关键点检测,优化了锚点探测器的性能.优化损失函数亦能提高小目标识别性能,例如Guo等[13]提出一种基于边界的度量指标,测量物体类别之间的空间相邻程度,并通过量化空间邻接项比率消除目标尺寸引入的偏差,从而优化小目标的损失计算过程.
从已有研究可以看出,采用深度学习模型进行小目标识别能显著提高识别精度.然而,目前缺乏针对舰面相关场景中目标识别任务的公共数据集.因此,有必要构建专用数据集进行模型训练与评估.另外,实际着舰作业中,受海上复杂天气、能见度及数据采集手段等因素影响,舰载机着舰拉制状态识别具有数据采集质量低、难度高以及啮合区域尺度小、纹理特征弱等难点,现有基于深度学习的目标识别方法难以直接满足舰载机尾钩及其与拦阻索啮合状态识别的需求.因此,有必要结合舰面目标及拉制状态识别问题的特点,有针对性地对模型进行优化和改进.
本文主要研究基于视觉信息的舰载机拉制状态识别,通过对舰载机尾钩及其与拦阻索的啮合状态的识别实现拉制状态的判定.设计了包含特征增强(feature enhancement,FE)和多尺度特征融合(multi-scale feature fusion,MSFF)的识别模型,通过特征增强模块,提高模型对小目标的特征表征能力,抑制复杂环境中的干扰目标特征;通过多尺度特征融合模块,实现低层空间信息和高层语义信息的有效融合,优化目标的识别性能.此外,构建了舰载机尾钩识别任务和钩索啮合状态识别任务的虚实融合数据集,验证了所提方法的有效性.
1 本文模型
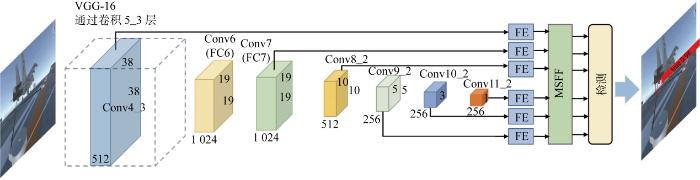
模型采用VGG-16作为骨干网络,并根据识别任务的特点设计了特征增强及融合模块,模型架构如图1所示.骨干网络学习到的6个特征图分别输入FE模块,通过注意力机制自适应增强特征图对关键信息的表征能力.增强后的特征图输入MSFF模块,进行深层和浅层特征的融合并保留底层细节和高层语义信息,以提高模型对于小目标的识别精度.融合后的特征图输入到检测层,由检测层输出识别结果、位置及置信度.
图1
1.1 基于注意力机制的特征增强
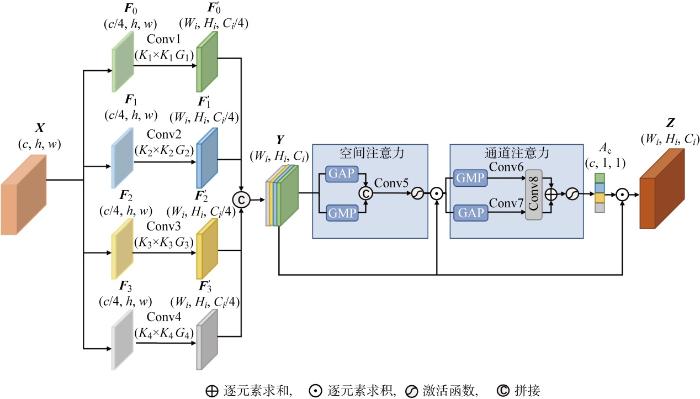
特征增强模块结构如图2所示,输入特征图为X(c, w, h),c、h、w分别为通道数、高度和宽度,Ci、Hi、Wi (i=0, 1, 2, 3)分别为输出特征图的通道数、高度和宽度,Kj和Gj (j=1, 2, 3, 4)分别为卷积核大小和步长.在该模块中,首先将输入的特征图沿通道维度分成4部分,分割后的特征图表示为Fi.特征图Fi通过多尺度卷积核生成不同空间分辨率的特征图 F'i,多尺度卷积核的大小分别为1、3、5、7.其中,卷积核大小为1和3的卷积在图中表示为“Conv1”和“Conv2”.为了提高运算效率,采用一种替代策略,将卷积核大小为5和7的卷积替换为大小为3、空洞率分别为2和3的空洞卷积,在图中表示为“Conv3”和“Conv4”.输出的特征图定义如下:
式中:Wk×k, s, d表示大小为k、步长为s、空洞率为d的卷积核.卷积后的特征图经过通道维度上的拼接形成新的特征图
式中:Concat表示拼接.之后,通过空间注意力激励或抑制特征图Y不同空间位置上的信息.将特征图Y沿通道维度进行全局平均池化(global average pooling, GAP)和全局最大池化(global max pooling, GMP),聚合通道信息后形成两个二维空间特征图Ya、Ym.再将两个空间特征图经过拼接、卷积生成空间特征向量.空间注意力的计算方式为
式中:σ表示sigmoid激活函数.输出的空间特征图再利用通道注意力生成一维通道特征图.具体地,采用GAP和GMP两种池化将特征图沿空间维度聚合后生成两个通道特征Y'a、Y'm,对两个通道特征分别进行卷积,并经过一个共享的卷积生成两个新特征,通过特征合并获得通道特征向量.通道注意力计算方式为
式中:δ为ReLU函数;W1、W2为两个输入通道数为C、输出通道数为C/16的1×1卷积;W3为输入通道数为C/16、输出通道数为C的1×1卷积.得到空间与通道特征向量后,将其与特征图Y相乘得到特征图
图2
从上述计算过程不难看出,最终的特征图Z融合了两种注意力机制的优点,通过训练可以自适应地激励或抑制不同维度上的信息.通过对比图3中的热图,可以观察到特征增强前后的显著差异.结果表明,在应用本文FE模块进行特征增强后,关键目标信息更加突出,同时抑制了背景的响应.
图3

图3
特征增强前后的热图对比
Fig.3
Comparison of heat map before and after feature enhancement
图4展示了嵌入FE模块前后的骨干网络多层输出特征图的对比结果.上半部分为原始骨干网络学习到的特征图,下半部分为嵌入FE模块后学习到的特征图.从对比结果中可以看出,在嵌入FE模块之前的特征图中,目标与背景之间的差异相对较小,目标区域没有得到很好的突出.在嵌入FE模块后的特征图中目标与背景之间的差异得到了显著的增强,特征图中的目标区域更加清晰、明显,与背景区域形成了更加明显的对比.
图4
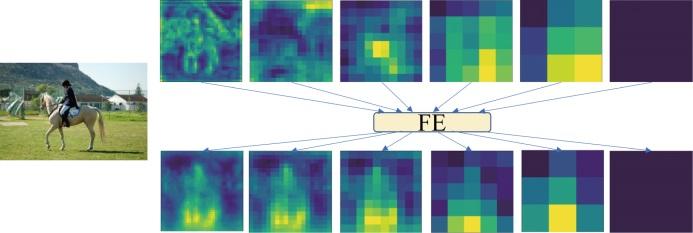
图4
特征增强前后的特征图对比
Fig.4
Comparison of feature maps before and after feature enhancement
1.2 多尺度特征融合
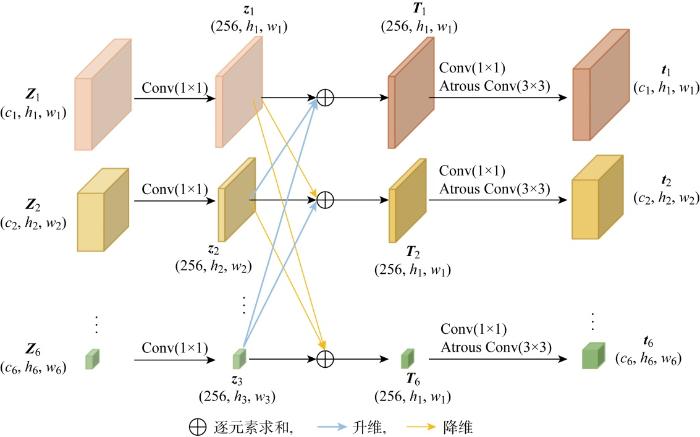
多尺度特征融合模块的结构如图5所示,其中Atrous Conv表示空洞卷积.该模块接收所有FE模块中输出的6个特征图作为输入,每个特征图的维度表示为(wn, hn, cn).首先通过1×1卷积将所有特征图的通道维度统一为256,卷积后的特征图记为zn (n=0,1,…,6).然后通过采样或池化操作,使特征图zn生成多尺度上下文信息,并将该信息映射到其余5个尺度的特征图.对于z1,利用自适应平均池化将其缩小到6个尺度的特征图,输出的特征定义为
式中:downscale函数表示自适应平均池化操作;α(z1)指相应尺度的特征图.对于z6,特征融合模块将其上采样为6个尺度的特征图,输出的特征定义为
式中:upsample函数表示反卷积;β(z6)指该尺度下的特征图.对于z2、z3、z4、z5,特征融合模块同时采用downscale和upsample将其采样至6个尺度,输出特征定义为
最后,将具有相同维度的特征相加,再通过卷积将融合后的特征图还原成原始的通道数和尺度.新生成的融合特征图定义为
式中:W1×1, 1表示大小为1、步长为1的卷积核;W2×2, 1, 2表示大小为2、步长为1、空洞率为2的空洞卷积核.
图5
2 实验
2.1 数据集构建
为了验证所提方法,通过可视仿真构建了舰载机着舰数据集.为简化计算,将舰载机视为一个质点,不考虑其外观形状,并忽略甲板风、空气涡流等环境影响因素.基于以上假设,可建立如下质点模型[14]:
式中:x、y和z为舰载机的三维坐标;v为舰载机速度;γ为爬升角;ψ为航向角;μ为滚转角;nx为水平过载;nz为纵向过载;g为重力加速度.
利用着舰模型生成的航迹坐标,结合Unity 3D仿真引擎,构建舰载机着舰作业可视仿真平台.基于该平台生成了舰载机尾钩识别数据集和钩索啮合状态识别数据集,评估所提方法在舰载机着舰拉制识别任务中的性能.
2.1.1 舰载机尾钩识别数据集
舰载机尾钩识别数据集(CATHR-DET)主要用于评估所提方法在舰载机尾钩识别任务上的性能.该数据集由真实和可视仿真两类样本构成,对数据集中包含舰载机尾钩的样本,通过人工方式标注出尾钩的边界框.真实样本来自通过公开渠道收集的多型舰载机的着舰作业视频、图片,在考虑光照、视角、背景等方面多样性的基础上,对收集到的原始图像进行成像质量、目标尺寸等方面的筛选,共计400张彩色图像,尺寸统一为 1 300 像素×600像素.针对仿真样本,首先对舰载机着舰作业进行可视建模和仿真,然后从仿真场景中获取图像样本.仿真样本涵盖了不同颜色、纹理特征的尾钩,晴天、阴天、雨天3种气象条件以及亮光、暗场两种光照条件,不同环境条件下的样本数量如表1所示,不同光照条件下的样本实例如图6所示.仿真样本共计 3 600 张彩色图像,尺寸统一为 1 300 像素×600像素.舰载机尾钩数据集的部分样本实例如图7所示,其中晴天、阴天和雨天为仿真样本,实景为真实样本,下同.
表1 CATHR-DET数据集的仿真样本数量
Tab.1
| 因素 | 类别 | 样本数量 |
|---|---|---|
| 气象条件 | 晴天 | 1600 |
| 阴天 | 1000 | |
| 雨天 | 1000 | |
| 光照条件 | 亮场 | 2300 |
| 暗场 | 1300 |
图6

图7

2.1.2 钩索啮合状态识别数据集
表2 HCESI-DET数据集的仿真样本数量
Tab.2
| 因素 | 类别 | 样本数量 |
|---|---|---|
| 气象条件 | 晴天 | 2400 |
| 阴天 | 1000 | |
| 雨天 | 800 | |
| 光照条件 | 亮场 | 2200 |
| 暗场 | 2000 |
图8

2.2 实验设置
实验选用精度(P)、召回率(R)、F值作为模型识别性能评估指标,计算如下:
式中:NTP、NFP、NFN分别表示预测为正的正样本、预测为正的负样本、预测为负的正样本.此外,实验还选取了常用的平均精度均值(mean average precision, mAP)、帧频(frames per second, FPS)作为模型目标识别性能的评价指标.
2.3 实验结果与分析
2.3.1 性能评估
本文方法与基线方法在两个自构数据集上的性能对比实验结果如表3和表4所示.由表3可见,所提方法在CATHR-DET数据集上的识别精度低于最优算法SSD512,但小目标识别的召回率和综合指标F值均取得最优.由表4可见,所提方法在HCESI-DET数据集上的3个评价指标均取得最优.针对模型的识别性能,从表3和表4可以看出,所提方法在两个数据集上均取得最优性能.相较于SSD300、SSD512和DSSD等方法,本文算法在识别精度上有明显提升,证明了FE模块和MSFF模块在两个识别任务上的有效性. 相较于RetinaNet、 YOLOv3, 所提算法在识别精度上具有明显优势,虽然检测帧率下降,但单张图片的识别时间仍小于飞行员的反应时间,能够满足实时识别的要求.
表3 CATHR-DET数据集实验结果对比
Tab.3
| 方法 | 分类 | 检测 | ||||
|---|---|---|---|---|---|---|
| P/% | R/% | F/% | mAP/% | FPS/(帧·s-1) | ||
| SSD300 | 77.8 | 33.2 | 46.5 | 56.6 | 57.1 | |
| SSD512 | 93.2 | 27.2 | 42.1 | 62.2 | 31.2 | |
| RetinaNet | 67.7 | 79.5 | 73.1 | 65.2 | 33.2 | |
| YOLOv3 | 67.2 | 80.5 | 73.3 | 74.2 | 41.2 | |
| DSSD | 84.2 | 53.8 | 65.6 | 73.5 | 19.7 | |
| 本文方法 | 84.4 | 81.1 | 82.4 | 76.8 | 26.8 | |
表4 HCESI-DET数据集实验结果对比
Tab.4
| 方法 | 分类 | 检测 | ||||
|---|---|---|---|---|---|---|
| P/% | R/% | F/% | mAP/% | FPS/(帧·s-1) | ||
| SSD300 | 67.2 | 22.2 | 33.4 | 54.1 | 57.1 | |
| SSD512 | 66.3 | 38.4 | 42.5 | 58.5 | 31.2 | |
| RetinaNet | 61.8 | 60.5 | 61.1 | 59.3 | 33.2 | |
| YOLOv3 | 61.1 | 71.4 | 65.8 | 61.4 | 41.2 | |
| DSSD | 64.2 | 32.2 | 42.9 | 57.1 | 19.7 | |
| 本文方法 | 72.4 | 71.9 | 72.3 | 64.2 | 26.8 | |
图9

图9
本文方法在自构数据集上的结果
Fig.9
Results of method proposed in self-constructed datasets
此外,为了证明算法对小目标识别的有效性和通用性,对比了SSD算法与本文改进算法在VOC (visual object classes)数据集上的小目标识别结果,对比结果如表5所示.其中,4个类别分别为鸟(bird)、瓶子(bottle)、船(boat)和椅子(chair).由识别结果的对比可以看出,改进算法对小目标识别的准确率优于其他算法,验证了所提算法在小目标识别上的有效性.
表5 在VOC小目标数据集上的平均精度对比
Tab.5
| 方法 | 平均精度/% | |||
|---|---|---|---|---|
| 鸟 | 瓶子 | 船 | 椅子 | |
| SSD300 | 70.3 | 45.3 | 63.2 | 54.3 |
| SSD512 | 74.4 | 50.1 | 70.3 | 57.1 |
| RetinaNet | 75.8 | 54.8 | 71.5 | 59.2 |
| YOLOv3 | 78.3 | 57.2 | 70.9 | 60.2 |
| DSSD | 79.8 | 53.9 | 67.5 | 58.2 |
| 本文 | 80.3 | 59.2 | 75.4 | 61.5 |
2.3.2 消融实验
为验证本文设计的FE模块和MSFF模块的有效性,在VOC数据集上对所提算法进行消融实验,定量分析了两个模块对模型识别精度的影响.实验的基线方法为SSD算法,实验结果如表6所示.
表6 VOC数据集上的的消融实验结果
Tab.6
| 基线算法 | FE | MSFF | mAP/% | FPS/(帧·s-1) |
|---|---|---|---|---|
| √ | 64.7 | 55.2 | ||
| √ | √ | 66.2 | 28.4 | |
| √ | √ | 66.8 | 43.8 | |
| √ | √ | √ | 67.1 | 26.6 |
注:√表示模型中包含此模块或算法.
由表6可知,通过在基线算法中引入FE模块,模型平均精度提升了1.5百分点,帧率下降了26.8 帧/s;通过引入MSFF模块,模型平均精度提升了2.1百分点,帧率下降了11.4 帧/s;同时引入 MSFF 模块和FE模块,模型平均精度则提升了2.4百分点,帧率下降了28.6 帧/s.
3 基于可穿戴增强现实设备的着舰拉制状态识别原型系统
针对舰载机阻拦着舰引导任务中LSO的工作场景,设计和构建了基于可穿戴增强现实设备的着舰拉制状态识别半实物原型系统.该系统的设计和设备实物图如图10所示,包括增强现实眼镜、边缘计算盒以及着舰作业视频显示屏.
图10

图10
着舰拉制状态识别原型系统设备实拍图
Fig.10
Design and equipment of arrested landing state awareness system
增强现实眼镜既是数据采集终端又提供用户交互界面,边缘计算盒用于部署采用本文方法离线训练的识别模型,增强现实眼镜与边缘计算盒之间可通过Wi-Fi或有线的方式进行通信.拉制状态识别的结果(如尾钩识别与钩锁啮合状态识别的结果及置信度)和决策提示信息(如正常着舰、逃逸、复飞等)通过增强现实眼镜的光学组件叠加到参与着舰引导作业的LSO视场中,实现高效、即时人机交互与协同.
4 结语
研究基于视觉信息的舰载机阻拦着舰拉制状态识别,通过对舰载机尾钩及其与拦阻索的啮合状态识别实现拉制状态判定.针对舰载机着舰作业场景中小尺寸目标的识别任务,设计了基于自适应特征增强和融合的识别模型,通过引入特征增强模块和多尺度特征融合模块,更好地捕捉图像中的关键目标信息,有效提高了对识别目标的表征能力,提升了模型对小目标的识别性能.在自构的虚实融合着舰作业数据集上,评估了方法在舰载机尾钩识别任务和钩索啮合状态识别任务上的性能,结果证明本文方法在舰载机着舰拉制状态识别任务上的有效性.同时设计研发了面向着舰引导与指控作业场景的基于可穿戴增强现实设备的着舰拉制状态识别系统.未来将继续在算法的效率方面进行优化,扩展到更复杂的任务中,设计面向舰载机着舰态势识别与引导的人机协同的学习与决策计算框架,实现基于混合增强智能的舰载机着舰可信引导决策.
参考文献
一种面向航空母舰甲板运动状态预估的鲁棒学习模型
[J].
A robust learning model for deck motion prediction of aircraft carrier
[J].
基于强化学习的舰载机保障作业实时调度方法
[J].
Real-time scheduling for carrier-borne aircraft support operations: A reinforcement learning approach
[J].
面向航空母舰电子显灵板的多智能体建模技术研究进展
[J].
Research progress of multi-agent technology for aircraft carrier electronic display panel
[J].
基于Frenet标架下三维元胞自动机的航母舰载机集群运动建模
[J].
Shipboard aircraft swarm modeling using a 3D cellular automata model under the frenet frame
[J].
基于深度强化学习的舰载机动态避障方法
[J].
Dynamic obstacle avoidance method for carrier aircraft based on deep reinforcement learning
[J].
基于改进YOLOv4-tiny的舰面多目标检测算法
[J].
Multi-target detection algorithm for ship surface based on improved YOLOv4-tiny
[J].
基于Faster R-CNN的航母舰面多尺度目标检测算法
[J].
DOI:10.12305/j.issn.1001-506X.2022.01.06
[本文引用: 1]

针对航母舰面复杂的多尺度目标检测环境, 且现有算法对牵引车、人员等小目标检测性能不佳的问题, 提出一种改进快速区域卷积神经网络(faster region convolutional neural netuorks, Faster R-CNN)的舰面多尺度目标检测算法。基于多尺度特征层提取了不同尺度的区域建议网络, 提高了算法对不同尺度目标尤其是对小目标的检测性能。基于K-means聚类算法生成了适合于舰面目标数据集的先验框尺寸, 进一步提升了算法的性能。实验表明, 所提算法有效地提升了不同尺度目标的检测性能,尤其是对小目标的检测效果, 并对所提算法进行了消融实验, 最后与不同算法的性能进行了对比, 所提算法检测准确率取得了最优水平。
Multi-scale object detection algorithm for aircraft carrier surface based on Faster R-CNN
[J].
DOI:10.12305/j.issn.1001-506X.2022.01.06
[本文引用: 1]
Aiming at the complex multi-scale object detection environment on the aircraft carrier surface, and the poor performance of existing algorithms for small objects such as tractors and personnel, an improved faster region convolutional neural netuorks(Faster R-CNN) aircraft carrier surface multi-scale object detection algorithm is proposed. Based on the multi-scale feature layer, the region proposal network of different scales is extracted, which improves the detection performance of the algorithm for objects of different scales, especially small objects. Based on the K-means clustering algorithm, a prior box suitable for the aircraft carrier surface object dataset is generated, which further improves the performance of the algorithm. Experiments show that the proposed algorithm effectively improves the detection performance for different scales of objects, especially the detection effect of small objects, and conducts ablation experiments on the improved algorithm. Finally, the performance of different algorithms is compared, which shows that the detection accuracy of the proposed algorithm achieveds the optimal level.
复杂场景下基于增强YOLOv3的舰面多目标检测
[J].
DOI:10.3778/j.issn.1002-8331.2012-0411
[本文引用: 1]
针对舰面场景复杂、目标相互遮挡导致检测率较低等问题,在YOLOv3算法基础上提出了适用于舰面目标检测的增强YOLOv3算法。在输入网络中加入融合的数据增强策略对图像进行色域变换、裁剪、遮挡等操作,设计了多种类图片选取、变换及组合方式来丰富样本信息;针对舰面目标尺寸的特点,利用K-means算法重新设计与检测目标相匹配的先验锚框并分配至对应的预测尺度,以加速模型收敛;在输出网络中通过线性函数对Soft-NMS算法的高斯软阈值函数参数设定进行了改进,以适应不同密集度下的抑制需要,提高网络检测能力。通过将增强的目标检测算法在目标数据集上进行实验对比,其结果显示,在5类舰面目标识别的精确率和召回率分别提高了1.4%和10.3%,平均准确率值(mAP)达到了95.24%,检测速度达到21.5?frame/s,有效解决了复杂场景下的舰面多目标检测问题。
Multitarget detection based on enhanced YOLOv3 in complex scenarios
[J].
DOI:10.3778/j.issn.1002-8331.2012-0411
[本文引用: 1]
Aiming at the low detection rate caused by complex shipboard scenes and mutual occlusion of targets, an enhanced YOLOv3 algorithm suitable for shipboard target detection is proposed based on the YOLOv3 algorithm. The integrated data augmentation strategy is added to the input network to carry out gamut transformation, clipping, shielding and other operations on the image, and then a variety of image selection, transformation and combination methods are designed to enrich the sample information. According to the characteristics of the target size on ship surface, K-means algorithm is used to redesign the prior box matching the detection target and allocate it to the corresponding prediction scale. In the output network, the parameter setting of Gauss soft threshold function of Soft-NMS algorithm is improved by linear function to meet the need of suppression under different densities. Through enhanced detection algorithm in the target data set on experimental comparison, the results show that five types of ship surface target are identified, and precision rate and recall rate are increased by 1.4% and 10.3% respectively, and the average accuracy value(mAP) reaches 95.24%, and then detection speed is 21.5 frame/s, which effectively solves the complicated situations of ship surface much target detection problem.
MSF-net: Multi-scale feature learning network for classification of surface defects of multifarious sizes
[J].
Feature pyramid networks for object detection
[C]//
Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection
[C]//
Small object sensitive segmentation of urban street scene with spatial adjacency between object classes
[J].
AdaBoost-PSO-LSTM网络实时预测机动轨迹
[J].
DOI:10.12305/j.issn.1001-506X.2021.06.23
[本文引用: 1]
针对自主空战中轨迹预测难以同时保持高预测精度和短预测时间的问题, 提出一种自适应增强的粒子群优化长短期记忆网络预测方法。首先,建立三自由度无人机动力学模型, 解决机动轨迹的数据来源问题。其次,分析长短期记忆网络, 并引入在线预测的滑动模块输入矩阵, 利用粒子群优化算法代替传统基于时间的反向传播算法进行网络内部权值更新; 同时为解决优化算法非定向性问题, 提出数据共享方法。然后,为进一步提高预测精度, 采用自适应增强算法搭建外框架, 通过控制弱预测器的数量平衡预测精度与预测时间。最后, 在一段变化较为频繁的轨迹进行预测, 与5种神经网络预测方法进行比较, 结果表明所提方法能够较好地满足精度和时间要求。
Real time prediction of maneuver trajectory for AdaBoost-PSO-LSTM network
[J].
DOI:10.12305/j.issn.1001-506X.2021.06.23
[本文引用: 1]
To solve the problem that trajectory prediction is difficult to maintain high prediction accuracy and short prediction time in autonomous air combat, an AdaBoost particle swarm optimization for long and short term memory network prediction method is proposed. Firstly, the dynamic model of unmanned aerial vehicle with three degrees of freedom is established to solve the problem of data source of maneuver trajectory. Secondly, the long and short term memory network is analyzed, and the sliding module input matrix of online prediction is introduced. Particle swarm optimization algorithm is used to replace the traditional back propagation algorithm through time to update the internal weights of the network. Meanwhile, in order to solve the problem of non-orientation of the optimization algorithm, a data sharing method is proposed. Then, in order to further improve the prediction accuracy, AdaBoost algorithm is used to build the outer framework, and the prediction accuracy and prediction time are balanced by controlling the number of weak predictors. Finally, compared with five neural network prediction methods in a period of more frequent changes in the trajectory prediction, the results show that the proposed method can meet the requirements of accuracy and time.
Focal loss for dense object detection
[C]//
YOLOv3: An incremental improvement
[DB/OL]. (

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}