在能源转型及“双碳”背景下,能源的高效利用和可持续发展引起全球广泛关注和高度重视.综合能源系统(Integrated Energy System,IES)兼具多能耦合、协同供应的优势,在提高能源利用效率的同时满足多样化用能需求,是能源领域的重要发展趋势之一[1 ] .在工业生产领域,IES的表现形式为集合园区电、气、热等能源形式的园区IES(Park-Level Integrated Energy System,PIES).PIES在能源综合利用[2 ] 、节能减排[3 ] 、可再生能源就地消纳[4 ] 等方面具有重要意义.
IES具备大规模区域互联的特性,并逐渐形成大型高维系统,风光等不确定出力的新能源和以分布式储能设备为代表的柔性负荷的接入进一步加强了IES的复杂动态特性[5 ] .此外,能源多样性和多能间存在复杂多变的耦合特性也使现代化能源管理面临巨大挑战[6 ] .
传统的IES能量管理方法,诸如混合整数规划[7 ] 、非线性规划[8 ] 、线性规划[9 ] ,都基于模型驱动,是充分运用系统成熟机理的优化调度方法.高比例可再生能源的接入提高了系统实时调度决策的性能需求.此外,系统的源荷不确定性使机理建模面临困境,即使针对此类问题进行随机规划[10 ] 、鲁棒优化[11 ] ,依旧无法摆脱不确定性因素的刻画,模型驱动方法因而陷入瓶颈.
为了摆脱机理建模的制约,并通过离线训练缩短实时调度决策时间,引入数据驱动,采用无模型的强化学习(Reinforcement Learning,RL)方法.强化学习通过智能体与环境的迭代交互,依靠奖励回报自适应学习生成最优策略,不受精确的模型信息和预测准确性的制约.此外,强化学习还可以与具备良好数据处理能力的深度学习相结合形成较传统优化算法更易实现的深度强化学习(Deep Reinforcement Learning,DRL)[12 ] 算法.
许多专家学者已经开始利用DRL来处理IES管理问题并取得一定研究成果.文献[13 ]中采用深度Q网络建立微网能源系统优化管理模型,管理电、热、冷3种能源系统的能源生产、转换与存储操作,实现微网经济调度.文献[14 ]中提出一种基于柔性行动器-评判器的强化学习框架,解决电气IES的多能流协同优化问题.文献[15 ]中提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法求解电气IES优化调度问题.文献[16 ]中采用一种改进型深度确定性策略梯度(DDPG-AD)算法来优化文中所提分布式清洁能源发电系统模型的发电效率.
此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护.
以工业园区为研究场景构建一个包含3个供能子系统的电热IES模型,同时基于DDPG算法设计一种能兼容于3个异构供能子系统的能量管理模型.对于3个异构供能子系统,该模型能够综合考虑园区实时电负荷、热负荷、分时电价,朝着经济效益最大化方向自适应地对供能子系统内部各设备的出力进行调整.此外,提出一种基于联邦学习框架的DDPG算法(Federated-Deep Deterministic Policy Gradient,F-DDPG)对园区IES能量进行管理.在F-DDPG框架中,各供能子系统利用内部数据,独立地对DDPG能量管理模型进行训练.在模型训练过程中,F-DDPG采用联邦学习算法交互各供能子系统能量管理模型的梯度参数,协同优化各子系统能量管理模型训练速度.最后,通过算例仿真验证了所构建基于联邦强化学习的园区IES能量管理方法对系统经济效益的显著提升.
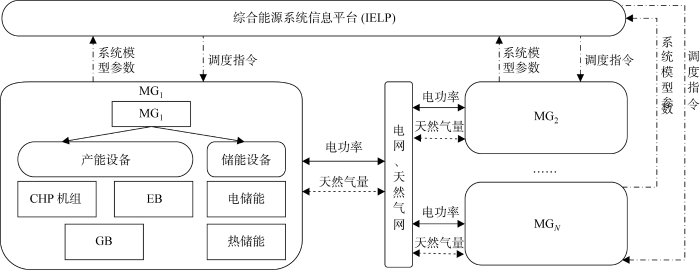
1 园区IES结构及设备模型
园区IES内部通常包含多个供能子系统,其典型架构如图1 所示.各供能子系统分别用MG1 、MG2 、MGN
图1
图1
园区IES结构
Fig.1
Structure of IES for the park
各供能子系统内部设置智能体,负责收集本系统内部可再生能源出力、电热负荷需求以及各设备状态信息,并调节各可控设备出力.各智能体可通过数据传输链路实现与IEIP的信息交互,各智能体上传能源系统模型参数等信息,经IELP分析处理后,平台下发调度指令.
各供能子系统既可实现本系统内部自治,又可协作运行.一方面,各智能体都包含策略网络和价值网络,可实现各供能子系统的就地数据处理;另一方面,各智能体上传各网络特征参数至IELP,最终通过IELP的调度实现协同优化.该架构避免了调度过程中大量隐私数据传输.
1.1 供能子系统设备模型
(1) CHP模型.CHP机组作为IES的核心设备,以天然气为主要燃料,可输出热、电能,具有较高的综合用能效率.
(1) P C H P ( t ) = V C H P ( t ) H N G η C H P
式中:V C H P ( t ) 为 t H NG 为天然气的热值;η CHP 为CHP机组的发电效率.
(2) P C H P m i n ≤ P C H P ( t ) ≤ P C H P m a x
式中:P C H P m i n P C H P m a x
此外,CHP机组在输出电能的同时,也会放出大量热能.CHP机组输出热功率与电功率比值为热电比β ,CHP机组t 时段输出热功率可表示为
(3) H C H P ( t ) = β P C H P ( t ) η H E
(2) 燃气锅炉模型.燃气锅炉消耗天然气为IES提供热能,其输出热功率为
(4) H G B ( t ) = η G B H N G V G B ( t )
式中:η GB 为燃气锅炉的效率;V GB (t )为t 时段内燃气锅炉的单位时间天然气消耗量.
(5) H G B m i n ≤ H G B ( t ) ≤ H G B m a x
式中:H G B m i n H G B m a x
(3) 电锅炉模型.电锅炉消耗电能为IES提供热能,其输出热功率为
(6) H E B ( t ) = P E B ( t ) η E B
式中:P E B ( t ) 为 t η EB 为制热电锅炉的制热效率.
(7) H E B m i n ≤ H E B ( t ) ≤ H E B m a x
式中:H E B m i n H E B m a x
(4) 电储能模型.电储能设备作为IES的重要组成部分,可在一定程度上对IES中源荷不确定性进行缓解.建立典型电储能设备-蓄电池的数学模型.蓄电池的储电状态受上一时段储电状态和充放电功率影响,满足以下公式:
(8) B s o c ( t ) = B s o c ( t - 1 ) - η B A P B A ( t ) Δ t Q B A
式中:Bsoc (t )为蓄电池在t 时段的储电状态;PBA (t )为蓄电池的运行功率,为正时表示其处于放电状态,为负时表示其处于充电状态;Q BA 为蓄电池的最大容量;η BA 为蓄电池的充放电系数,表示为
(9) η B A = η c h , P B A < 0 1 / η d i s , P B A ≥ 0
式中:η ch ∈(0, 1]为蓄电池的充电系数;η dis ∈(0, 1]为蓄电池的放电系数.
(10) P B A m i n ≤ P B A ( t ) ≤ P B A m a x
式中:P B A m i n P B A m a x
(5) 热储能模型.热储能设备与电储能设备同为IES的重要组成部分,对IES的意义与作用与电储能设备一致.以蓄热罐为典型热储能设备为例进行建模.蓄热罐t 时段的储热状态满足下式:
(11) Q H S ( t ) = Q H S ( t - 1 ) ( 1 - σ x ) + η H S P H S ( t ) Δ t
式中:PHS (t )为蓄热罐的运行功率,为正时表示其处于放热状态,为负时表示其处于吸热状态;σx 为蓄热罐的自损率;η HS 为蓄热罐的吸放热系数,表示为
(12) η H S = η c h r , P H S < 0 1 / η d c h , P H S ≥ 0
式中:η chr ∈(0, 1]为蓄热罐的放热功率;η dch ∈(0, 1]为蓄热罐的吸热效率.
1.2 约束条件
IES的约束条件分为各设备自身约束条件和热电功率平衡约束条件,设备的自身约束如1.1节所示.根据IES结构,供能子系统能源平衡约束如下.
(13) P M G ( t ) + P N E ( t ) + P B A ( t ) + P C H P ( t ) = P E B ( t ) + P l o a d ( t )
式中:PMG (t )、PNE (t )分别为t 时段电网流入IES的电功率、新能源发电功率; P load (t )为电负荷.
(14) H C H P ( t ) + H G B ( t ) + H E B ( t ) + H H S ( t ) = H l o a d ( t )
式中:Hload (t )为t 时段热负荷;HHS (t )为t 时段蓄热罐的热功率.
(3) 外部能源供应约束.t 时段电网流入IES的电功率满足以下约束条件:
(15) P M G m i n < P M G ( t ) < P M G m a x
式中:P M G m i n P M G m a x
t 时段天然气供应商对IES的天然气供应量满足以下约束条件:
(16) v N G ( t ) = V C H P ( t ) + V G B ( t )
(17) v N G m i n ≤ v N G ≤ v N G m a x
式中:vNG (t )为t 时段供应商天然气供应总量;v N G m i n v N G m a x
1.3 目标函数
在电热IES中,系统运行成本主要包括购电成本、购气成本、弃风弃光成本.奖励函数只考虑购能成本以及弃风弃光成本,忽略设备启停成本和维护成本.以最小化系统运行成本为目标,日前经济调度的运行成本为
(18) m i n C ( t ) = C E ( t ) + C N E ( t )
(19) C E ( t ) = λ M G P M G ( t ) + λ N G P C H P ( t ) η C H P H N G + H G B ( t ) η G B H N G
式中:λMG (t )为t 时段电价;λNG (t )为天然气的单位热量价格;PMG (t )为正表示系统向主电网购电,为负表示系统向主电网售电,产生弃风弃光行为.
(20) C N = ∑ t = 1 T c N c u r t P N c u r t ( t )
式中:T 为日前调度的时间段数;c Ncurt 为弃光成本系数;P Ncurt (t )为弃风弃光量.
2 供能子系统系统的DDPG能量管理模型
2.1 DDPG能量管理模型
基于DDPG算法构建一种能自适应地对供能子系统设备出力进行调整的优化管理模型.各供能子系统中,DDPG能量管理模型观测电负荷需求、热负荷需求以及各设备运行状态等信息并汇总至子系统,由子系统对各设备出力的动作进行调整.DDPG能量管理模型基于子系统内是否存在弃风弃光等情况,对子系统所执行策略的经济效果进行量化分析,并通过迭代寻优不断更新策略.
2.2 状态空间
电热IES模型中,智能体观测的环境信息为新能源发电功率、负荷需求、蓄电池的荷电状态、蓄热罐的储热状态.任意时段t 下,3种能源系统的状态空间定义为
S i = ( P N E i ( t ) , P l o a d i ( t ) , H l o a d i ( t ) , H H S i ( t ) , P M G i ( t ) )
其中:P N E i ( t )为i 系统新能源在t 时段的输出功率;P l o a d i ( t )为i 系统内t 时段电负荷; H l o a d i ( t )为i 系统在t 时段热负荷;H H S i ( t )为i 系统在t 时段蓄热罐的热功率; P M G i ( t )为i 系统在t 时段与电网交换的功率.
2.3 动作空间
智能体收集到环境状态后,经由策略集π 进行决策,执行动作空间A 内存储的一个动作. 在时段t ,选用设备的出力情况表示IES中的动作. 由于PCHP (t )确定后,HCHP (t )可由式(3)计算得到;PEB (t )确定后,HEB (t )可根据式(6)确定,此外,HGB (t )确定后,HHS (t )可由式(14)确定;进而PMG (t )也通过式(13)计算确定. 即在PCHP (t )、PEB (t )、HGB (t )、PBA (t )确定后,其他量可以迅速得到.故IES的动作可表示为
A i = ( P C H P i ( t ) , P E B i ( t ) , H G B i ( t ) , P B A i ( t ) )
2.4 奖励函数
经济运行成本的最小化是电热IES的最终目标.强化学习算法中,将最小化问题转换成最大化奖励函数问题,因此,智能体i 在时段t 输出的奖励表示为
在IES某一确定状态si 下,可通过动作-值函数Qπ (si , ai )[23 ] 对动作ai 的优劣程度进行评估,其目标是找到最优策略π 以最大化状态-动作值函数:
Q π ( s i , a i ) = E π ( R i ( s i , r i ) ) π = a r g m a x a ∈ A Q π ( s i , a i )
3 基于F-DDPG的系统能量管理方法
3.1 基于MADDPG的系统能量管理
传统的强化学习方法在解决单智能体问题时都能取得较好的学习效果,但当面对多智能体相互合作或竞争的环境时,由于状态与动作空间随着智能体的增加而成倍增长,模型无法有效学习,所以引入多智能体DDPG(Multi-Agent Deep Deterministic Policy Gradient,MADDPG).
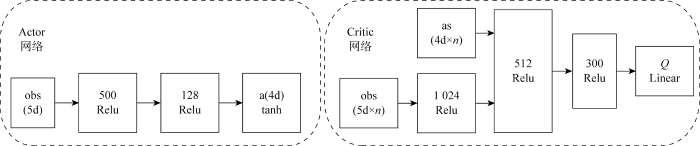
在MADDPG模型内,各智能体分为观测全局环境状态的评论家(Critic)网络和观测局部环境状态的演员(Actor)网络[24 ] .MADDPG算法依托集中训练的Critic网络来应对环境的非稳定状态,在训练阶段,Critic网络传递全局信息至各智能体,同步各智能体策略状态,保证MADDPG的训练稳定性.Actor网络和Critic网络均为采用线性整流函数激活的多层全连接网络.建立的Actor和Critic网络的结构如图2 所示.obs用来表示输入层的五维(5d)观测值,Actor网络经过两个神经元分别为500、128的隐藏层后在输出层输出四维(4d)的决策值,并采用双曲正切函数tanh作为激活函数控制动作输出,避免过大或过小的动作值对系统的影响.n 为数组个数.
图2
图2
Actor网络和Critic网络结构
Fig.2
Structure of Actor network and Critic network
Critic网络则分别经过 1024、512、300的隐藏层,最后Linear即全连接层输出网络评估参数Q 值,各隐藏层通过选取整流函数Relu作为激活函数来应对训练过程中梯度消失对神经网络学习率的冲击.
建立的园区IES模型中,各供能子系统赋能为智能体,单独计算子系统收益.各智能体由Actor网络、Critic网络、目标Actor网络、目标Critic网络构成.在训练阶段,Critic网络观测全局信息并基于此评估当前联合状态和联合动作的价值,对Actor网络的策略进行调整;训练好的Actor网络仅利用局部观测信息即可输出最优动作.各网络参数更新方法如下所示:
(1) Critic网络参数更新.Actor网络通过最小化损失函数以更新网络参数,即
(21) m i n L k ( θ k , i Q ) = 1 B ∑ i ( y k i - Q k ( s k i , a i | θ k Q ) ) 2
式中:L k ( θ k , i Q ) B 来表征均方误差损失函数形式,即时间差分误差值的累计平方值的均值;Q k ( s k i , a i | θ k Q ) y k i 为 目 标 Q
(22) y k i = r k i + γ Q ' k ( s k i + 1 , a i + 1 | θ k Q ' ) | a i + 1 = μ ' k ( s k i + 1 )
式中:r k i γ 为联合状态动作价值的权重;$Q^{\prime}{ }_{k}\left(s_{k}^{i+1}, a^{i+1} \mid \theta_{k}^{Q^{\prime}}\right)$为Critic目标网络输出的下一步联合状态动作价值;μ'k 表示目标网络当前时段的策略,即Critic网络下一步的动作与状态.
(23) Δ θ k , i Q = 2 B ( y k i - Q k ( s k i , a i ) | θ k Q )
(24) θ k + 1 , i Q = θ k , i Q + α Δ θ k , i Q
(2) Actor网络参数更新.训练过程中,Actor网络更新其参数J ( μ k | θ k μ )
(25) Δ θ k μ J ( μ k | θ k μ ) = 1 B [ ∑ i Δ a k Q k ( s k i , a i | θ k Q ) × Δ θ k μ μ k ( s k i | θ k μ ) ] | a i = μ k ( s k i )
(26) θ k + 1 , i μ = θ k , i μ + μ Δ θ k , i μ
(3) 目标网络参数更新.利用软更新技术更新目标网络的参数来进一步保证学习过程的稳定性[25 ] :
(27) θ k μ ' ← τ θ k μ + ( 1 - τ ) θ k μ '
(28) θ k Q ' ← τ θ k Q + ( 1 - τ ) θ k Q '
MADDPG算法中引入Ornstein-Uhlenbeck噪声来强化供能子系统训练过程中算法探索环境的能力,从而输出更优的动态调度策略.
3.2 基于F-DDPG的系统能量管理
将DDPG算法扩展到FRL,用于解决连续动作任务,称为F-DDPG.DDPG算法训练过程的关键在于通过训练Critic网络来估计准确的长期回报,进而指导Actor网络调整策略获取良好的回报.F-DDPG的主要目的在于提供一个全局的Critic网络指导智能体调整策略以获取最优整体回报.采用F-DDPG算法的单供能子系统与采用MADDPG算法单供能子系统以及采用传统DDPG方法的独立供能子系统相比,具有更好的通信效率和计算效率.
相较于MADDPG,F-DDPG的Critic网络参数更新中,由于r k i Δ θ k , i Q
(29) [ [ G ] ] = ∑ i [ [ Δ θ k , i Q ] ] 3
式中:[[·]]表示Paillier加密;G 为3个系统聚合后的平均梯度.在F-DDPG算法中,Paillier加密的引入保证各子系统都不能在交互损失函数时,获得其它子系统的损失函数信息.该项措施有效保证园区IES在进行 F-DDPG能量优化管理过程中的数据隐私.
中央服务器下发全局梯度至各智能体,更新本地Critic网络参数,如下所示:
(30) θ k + 1 , i Q = θ k , i Q + G
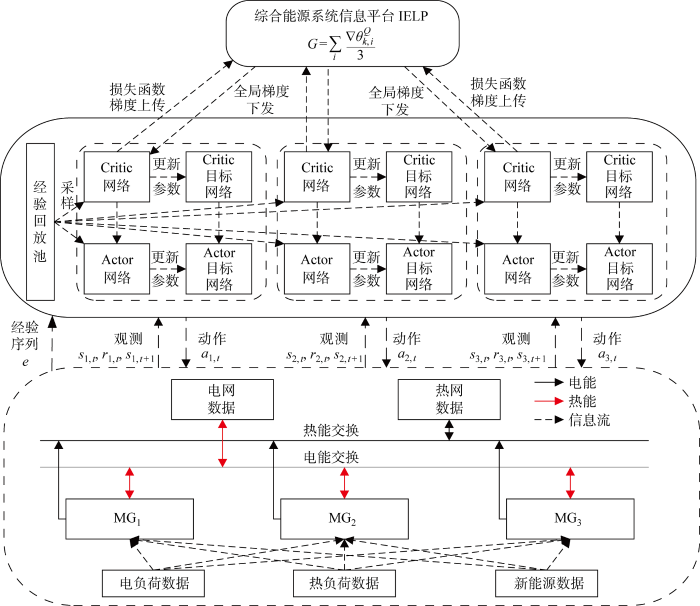
建立基于F-DDPG算法的IES能量管理框架如图3 所示.
图3
图3
基于F-DDPG的IES能量管理框架
Fig.3
Energy management framework of IES based on F-DDPG
该算法通过经验回放机制,采用历史的电负荷、热负荷、新能源出力、蓄热罐运行功率及入网电功率数据作为系统状态输入,离线训练F-DDPG算法网络.离线训练结束后得到的F-DDPG算法参数直接代入IES的能量管理问题进行求解.在调度执行阶段,各智能体观测当前系统状态信息并输入训练好的F-DDPG算法网络,迭代寻优后经由内部Actor网络输出调度策略.随后,执行策略并更新环境状态,输出当前策略奖励值.然后输入时段t +1系统的状态信息,并做出该时段的决策.不断迭代最终输出动态调度动作.
4 算例分析
以某一台区下的园区IES为例对所提基于FRL的电热IES能量管理策略的有效性进行验证,该园区可分为3个供能子系统,各供能子系统内具体设备信息如表1 所示.
园区各设备运行参数如表2 所示,并基于开源的CREST模型[26 ] 生成各用能子系统的热负荷、电负荷及新能源出力数据.该模型经由拉夫堡大学研究团队提出并通过有效性验证,现已被大规模使用[27 -28 ] .系统以15 min为间隔将调度时段划分为96个时隙.
系统与主电网交换功率的范围为 [-1.5 MW,3.0 MW],其他参数如表3 所示.园区电价为分时电价如表4 所示,峰时段为12:00—16:00、19:00—22:00,谷时段为0:00—8:00,平时段为8:00—12:00、16:00—19:00、22:00—24:00.天然气价格固定为0.450 元/(kW·h).
以CREST模型生成的5月份和6月份的历史数据作为训练数据.在进行系统动态能量管理之前,预先对联邦强化学习网络进行训练,确定网络参数.为了展现所提方法的收敛性能,给出智能体训练过程中每100个周期的平均奖励值曲线如图4 所示.该算法经过约 20000 个周期后收敛,得到最优动态经济调度策略.在日内调度开始前,智能体观测供能子系统的新能源发电功率、用能需求,随后依据前文所述的训练过程输出奖励值,并朝着最大化奖励值方向不断调整执行策略.如图4 所示,可观测到在训练过程中奖励值出现振荡,其振荡受各周期中的日训练数据中如负荷数据和光伏发电数据的变化影响.
图4
图4
奖励函数收敛曲线
Fig.4
Convergence curve of reward function
4.1 动态调度结果
调度开始前,F-DDPG算法网络经由历史数据进行离线训练,调整网络性能,训练好的算法网络用于调度阶段系统的动态能量管理.为了更好地阐释系统的动态能量管理结果,基于所提F-DDPG算法输出的PCHP (t )、vGB (t )、PBA (t )、HGB (t )以及相应计算得到的HCHP (t )、HEB (t )、HHS (t )、PMG (t ),以该园区2016年6月15日的调度情况为例进行分析.
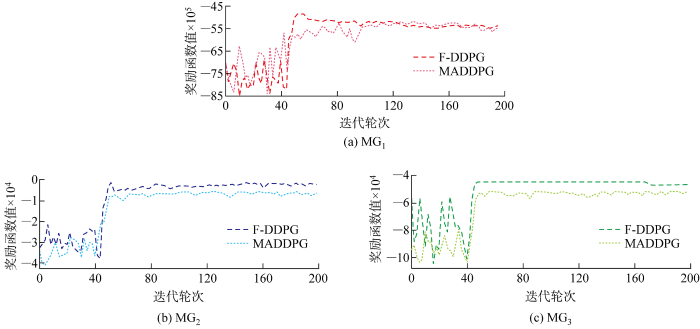
首先验证3种供能子系统DDPG能量管理模型的奖励函数收敛性,以及F-DDPG 方法对3种供能子系统DDPG能量管理模型奖励函数收敛曲线的改善效果.3种供能子系统的 DDPG能量管理模型在各训练回合下的奖励函数收敛曲线如图5 所示.由图可见,各供能子系统能量管理模型奖励函数都在迭代训练过程中实现收敛.由于所提算法在各DDPG能量管理模型训练过程中经由联邦学习加密,所以利用交互各能源系统的损失函数来计算园区IES的综合损失函数,从而对各DDPG能量管理模型的训练水平进行量化;此外,F-DDPG方法通过计算各DDPG能量管理模型对于当前园区IES损失函数的梯度信息,独立地更新和优化各DDPG能量管理模型的评估网络参数.因此所提F-DDPG方法能够有效提升各供能子系统的DDPG能量管理模型训练效率.
图5
图5
各供能子系统能量管理模型奖励函数收敛曲线
Fig.5
Convergence curves of reward function of energy management model of each energy supply subsystem
此外,F-DDPG依托Paillier全同态加密算法,减轻了各供能子系统DDPG能量管理模型梯度信息以及子系统原始数据的泄露风险.因此,F-DDPG方法能够有效打破异构供能子系统之间数据壁垒,在保护数据隐私的前提下协同训练各供能子系统能量管理模型.
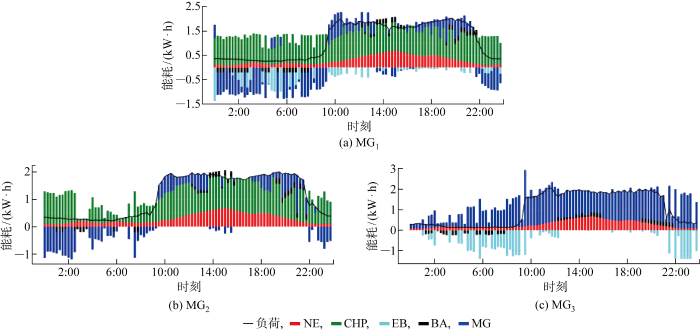
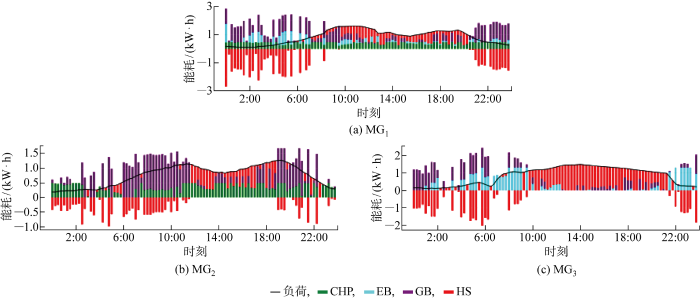
模型训练完成后,DDPG能量管理模型所决策的各设备出力情况如图6 和图7 所示.其中,图6 为电功率调度结果,图7 为热功率调度结果.
图6
图6
基于F-DDPG算法的电功率调度结果
Fig.6
Result of electrical power scheduling based on F-DDPG algorithm
图7
图7
基于F-DDPG算法的热功率调度结果
Fig.7
Result of thermal power scheduling based on F-DDPG algorithm
由图6 可见,MG1 、MG2 、MG3 子系统内整体趋势为:主要由CHP机组、蓄电池产生电能,其中蓄电池受分时电价引导充放电.以MG1为例,蓄电池在谷电价且电负荷较小时充电以备后续的高峰时段,如 1:15—2:45、5:30—6:45 等时段;在峰电价且电负荷较高时放电以减少运行成本,如 12:00—13:00、14:00—15:00 等时段.在谷电价时电能出力供电热锅炉消耗,反向向电网售电;平电价阶段,系统向主电网购电以满足用电需求.
由图7 可见,MG1 、MG2 、MG3 整体趋势为:蓄热罐受分时电价影响,谷电价和平电价时蓄热为后续的高峰时刻做准备,如 0:00—2:00、4:45—5:00 等时段,在峰电价且热负荷较高时放热以减少运行成本.MG1 中,CHP机组持续供热,在谷电价且热需求高于0.5 MW时,机组制热不能满足热负荷需求,采用电热锅炉购电制热以及燃气锅炉制热进行补充.峰电价时CHP机组、蓄热罐、燃气锅炉以及少量电热锅炉制热满足热负荷需求.MG2 中,CHP机组持续供热,在谷电价且热需求高于0.5 MW时,机组制热无法满足热负荷需求,采用燃气锅炉制热进行补充.峰电价时CHP机组、蓄热罐、燃气锅炉制热满足热负荷需求.平电价时,CHP机组和燃气锅炉联合供热满足热需求和供蓄热罐吸热.MG3 中,谷电价且低负荷时主要由电热锅炉制热,当热需求高于0.9 MW时,电锅炉制热不能满足热负荷需求,燃气锅炉制热进行补充,如 4:45—5:15 等时段;峰电价时主要由蓄热罐放热,少量燃气锅炉、电热锅炉制热满足热负荷需求.
综上,所提基于F-DDPG算法的能量管理策略能够在满足用能需求的前提下不断调整各子系统设备出力以提升系统经济效益.
4.2 对比分析
为进一步对所提算法有效性进行验证,首先选取传统的基于模型预测控制的调度方法与所提基于F-DDPG的调度方法进行对比.此外,如文献[12 ]所述,对于多主体系统,直接使用传统DDPG进行独立训练和决策,其面对的环境不稳定,这种不稳定打破了强化学习算法所遵循的马尔可夫假设[29 ] ,无法输出稳定的策略,因此额外采用基于MADDPG的调度方法进行对比.
表5 给出3种能量管理方法的经济效益和有效训练时长.有效训练时长指利用相同数据集开展100次实验,不忽略管理模型所出现的不收敛、过拟合等不成功训练情况, 统计其成功训练收敛的平均用时.
由表可见,对于上述园区IES,采用所提方法计算结果优于传统调度方法与MADDPG算法,验证了该方法的求解有效性;同时该算法的有效训练时长远小于上述两种算法,表明F-DDPG算法具有较高的计算效率.
在传统调度方法中,在IES管理的各时隙下,都需要针对热、电负荷与新能源出力进行精准预测并基于预测结果重新计算系统在后续1 h的管理方案;而所提算法无需对源荷信息进行预测,只需要将源荷信息作为智能体观察到的状态信息输入算法网络,大大缩短有效训练时间.此外,相较于所提算法,传统调度方法对各部分数据进行集中处理因而无法保证数据隐私.相较于MADDPG算法,所提 F-DDPG 方法基于联邦学习技术,在训练过程中通过各供能子系统模型梯度参数的交互而相互影响,使各智能体的模型训练效率和效果朝着更优的方向提升,更快速、更高效地实现系统的优化调度.
5 结论
面向工业园区电热IES,本文提出一种基于联邦强化学习的园区IES能量管理方法.F-DDPG算法通过在3个供能子系统中分别构建DDPG能量管理模型来管理各系统内设备的实时出力值.同时 F-DDPG 方法采用间接交互各子系统DDPG能量管理模型的梯度信息替代原始数据的直接交互,协作进行能量管理.最后,通过算例仿真对F-DDPG方法的有效性进行验证,并得到以下主要结论:
(1) 基于DDPG构建的供能子系统能量管理模型,综合考虑供能子系统内的新能源出力、实时热、电负荷、分时电价,动态地管理3个供能子系统在日内各状态下的设备出力.
(2) 所提基于联邦强化学习的园区IES能量管理方法能够使各供能子系统DDPG能量管理模型的训练效率和效果朝着更优的方向提升,并收获优良的经济效益.
(3) 由于能量管理过程中,各供能子系统避免了原始数据的直接交互,所提F-DDPG方法能够有效地对各供能子系统内部用能数据隐私进行保护.
参考文献
View Option
[1]
苏慧玲 , 杨世海 , 陈铭明 . 考虑能源效率的综合能源系统多目标优化调度
[J]. 电力系统及其自动化学报 2022 , 34 (2 ): 130 -136 .
[本文引用: 1]
SU Huiling YANG Shihai CHEN Mingming . Multi-objective optimal scheduling of integrated energy system considering energy efficiency
[J]. Proceedings of the CSU-EPSA 2022 , 34 (2 ): 130 -136 .
[本文引用: 1]
[2]
董文杰 , 田廓 , 陈云斐 , 等 . 能源互联网下基于博弈与证据理论的综合能源系统评价方法研究
[J]. 智慧电力 2020 , 48 (7 ): 73 -80 .
[本文引用: 1]
DONG Wenjie TIAN Kuo CHEN Yunfei , et al Evaluation method of comprehensive energy system based on game theory & evidence theory under energy Internet
[J]. Smart Power 2020 , 48 (7 ): 73 -80 .
[本文引用: 1]
[3]
朱志芳 , 许苑 , 岑海凤 , 等 . 考虑需求侧响应的园区综合能源系统优化配置
[J]. 智慧电力 2022 , 50 (1 ): 37 -44 .
[本文引用: 1]
ZHU Zhifang XU Yuan CEN Haifeng , et al Optimal configuration of park-level integrated energy system considering demand response
[J]. Smart Power 2022 , 50 (1 ): 37 -44 .
[本文引用: 1]
[4]
李驰宇 , 高红均 , 刘友波 , 等 . 多园区微网优化共享运行策略
[J]. 电力自动化设备 2020 , 40 (3 ): 29 -36 .
[本文引用: 1]
LI Chiyu GAO Hongjun LIU Youbo , et al Optimal sharing operation strategy for multi park-level microgrid
[J]. Electric Power Automation Equipment 2020 , 40 (3 ): 29 -36 .
[本文引用: 1]
[5]
熊珞琳 , 毛帅 , 唐漾 , 等 . 基于强化学习的综合能源系统管理综述
[J]. 自动化学报 2021 , 47 (10 ): 2321 -2340 .
[本文引用: 1]
XIONG Luolin MAO Shuai TANG Yang , et al Reinforcement learning based integrated energy system management: A survey
[J]. Acta Automatica Sinica 2021 , 47 (10 ): 2321 -2340 .
[本文引用: 1]
[6]
CARLI R DOTOLI M . Decentralized control for residential energy management of a smart users microgrid with renewable energy exchange
[J]. CAA Journal of Automatica Sinica 2019 , 6 (3 ): 641 -656 .
[本文引用: 1]
[7]
FARROKHIFAR M AGHDAM F H ALAHYARI A , et al Optimal energy management and sizing of renewable energy and battery systems in residential sectors via a stochastic MILP model
[J]. Electric Power Systems Research 2020 , 187 : 106483 .
[本文引用: 1]
[8]
ALIPOUR M ZARE K ABAPOUR M . MINLP probabilistic scheduling model for demand response programs integrated energy hubs
[J]. IEEE Transactions on Industrial Informatics 2018 , 14 (1 ): 79 -88 .
[本文引用: 1]
[9]
MOSER A MUSCHICK D GÖLLES M , et al A MILP-based modular energy management system for urban multi-energy systems: Performance and sensitivity analysis
[J]. Applied Energy 2020 , 261 : 114342 .
[本文引用: 1]
[10]
杨家豪 . 区域综合能源系统冷-热-电-气概率多能流计算
[J]. 电网技术 2019 , 43 (1 ): 74 -82 .
[本文引用: 1]
YANG Jiahao . Calculation of cold-heat-electricity-gas probabilistic multi-energy flow in regional comprehensive energy system
[J]. Power System Technology 2019 , 43 (1 ): 74 -82 .
[本文引用: 1]
[11]
翟晶晶 , 吴晓蓓 , 傅质馨 , 等 . 考虑需求响应与光伏不确定性的综合能源系统鲁棒优化
[J]. 中国电力 2020 , 53 (8 ): 9 -18 .
[本文引用: 1]
ZHAI Jingjing WU Xiaobei FU Zhixin , et al Robust optimization of integrated energy systems considering demand response and photovoltaic uncertainty
[J]. Electric Power 2020 , 53 (8 ): 9 -18 .
[本文引用: 1]
[12]
孙长银 , 穆朝絮 . 多智能体深度强化学习的若干关键科学问题
[J]. 自动化学报 2020 , 46 (7 ): 1301 -1312 .
[本文引用: 2]
SUN Changyin MU Chaoxu . Important scientific problems of multi-agent deep reinforcement learning
[J]. Acta Automatica Sinica 2020 , 46 (7 ): 1301 -1312 .
[本文引用: 2]
[13]
刘俊峰 , 陈剑龙 , 王晓生 , 等 . 基于深度强化学习的微能源网能量管理与优化策略研究
[J]. 电网技术 2020 , 44 (10 ): 3794 -3803 .
[本文引用: 1]
LIU Junfeng CHEN Jianlong WANG Xiaosheng , et al Research on energy management and optimization strategy of micro-energy network based on deep reinforcement learning
[J]. Power System Technology 2020 , 44 (10 ): 3794 -3803 .
[本文引用: 1]
[14]
乔骥 , 王新迎 , 张擎 , 等 . 基于柔性行动器-评判器深度强化学习的电-气综合能源系统优化调度
[J]. 中国电机工程学报 2021 , 41 (3 ): 819 -832 .
[本文引用: 1]
QIAO Ji WANG Xinying ZHANG Qing , et al Optimal dispatching of electric-gas integrated energy system based on flexible actuator-judge deep reinforcement learning
[J]. Proceedings of the CSEE 2021 , 41 (3 ): 819 -832 .
[本文引用: 1]
[15]
ZHANG B HU W H LI J H , et al Dynamic energy conversion and management strategy for an integrated electricity and natural gas system with renewable energy: Deep reinforcement learning approach
[J]. Energy Conversion & Management 2020 , 220 : 113063
[本文引用: 1]
[16]
XI L YU L XU Y C , et al A novel multi-agent DDQN-AD method-based distributed strategy for automatic generation control of integrated energy systems
[J]. IEEE Transactions on Sustainable Energy 2020 , 11 (4 ): 2417 -2426 .
[本文引用: 1]
[17]
陈明昊 , 孙毅 , 胡亚杰 , 等 . 基于纵向联邦强化学习的居民社区综合能源系统协同训练与优化管理方法
[J]. 中国电机工程学报 2022 , 42 (15 ): 5535 -5549 .
[本文引用: 1]
CHEN Minghao SUN Yi HU Yajie , et al The collaborative training and management-optimized method for residential integrated energy system based on vertical federated reinforcement learning
[J]. Proceedings of the CSEE 2022 , 42 (15 ): 5535 -5549 .
[本文引用: 1]
[18]
SAPUTRA Y M HOANG D T NGUYEN D N , et al Energy demand prediction with federated learning for electric vehicle networks
[C]//2019 IEEE Global Communications Conference . Waikoloa , USA : IEEE , 2019 : 1 -6 .
[本文引用: 1]
[19]
LEE S CHOI D H . Federated reinforcement learning for energy management of multiple smart homes with distributed energy resources
[J]. IEEE Transactions on Industrial Informatics 2022 , 18 (1 ): 488 -497 .
[本文引用: 1]
[20]
周长城 , 马溪原 , 郭晓斌 , 等 . 基于主从博弈的工业园区综合能源系统互动优化运行方法
[J]. 电力系统自动化 2019 , 43 (7 ): 74 -80 .
[本文引用: 1]
ZHOU Changcheng MA Xiyuan GUO Xiaobin , et al Leader-follower game based optimized operation method for interaction of integrated energy system in industrial park
[J]. Automation of Electric Power Systems 2019 , 43 (7 ): 74 -80 .
[本文引用: 1]
[21]
吕佳炜 , 张沈习 , 程浩忠 . 计及热惯性和运行策略的综合能源系统可靠性评估方法
[J]. 电力系统自动化 2018 , 42 (20 ): 9 -16 .
[本文引用: 1]
LYU Jiawei ZHANG Shenxi CHENG Haozhong . Reliability evaluation of integrated energy system considering thermal inertia and operation strategy
[J]. Automation of Electric Power Systems 2018 , 42 (20 ): 9 -16 .
[本文引用: 1]
[22]
白庆林 , 张培山 , 张林江 , 等 . 城市燃气SCADA及信息管理系统设计
[J]. 自动化与仪表 2009 , 24 (4 ): 47 -50 .
[本文引用: 1]
BAI Qinglin ZHANG Peishan ZHANG Linjiang , et al Design of information management system for urban natural gas SCADA system
[J]. Automation & Instrumentation 2009 , 24 (4 ): 47 -50 .
[本文引用: 1]
[23]
杨挺 , 赵黎媛 , 刘亚闯 , 等 . 基于深度强化学习的综合能源系统动态经济调度
[J]. 电力系统自动化 2021 , 45 (5 ): 39 -47 .
[本文引用: 1]
YANG Ting ZHAO Liyuan LIU Yachuang , et al Dynamic economic dispatch for integrated energy system based on deep reinforcement learning
[J]. Automation of Electric Power Systems 2021 , 45 (5 ): 39 -47 .
[本文引用: 1]
[24]
LOWE R WU Y TAMAR A , et al Multi-agent actor-critic for mixed cooperative-competitive environments
[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems . Long Beach, California , USA : ACM , 2017 : 6382 -6393 .
[本文引用: 1]
[25]
KOBAYASHI T ILBOUDO W E L . T-soft update of target network for deep reinforcement learning
[J]. Neural Networks 2021 , 136 : 63 -71 .
DOI:10.1016/j.neunet.2020.12.023
PMID:33450653
[本文引用: 1]
This paper proposes a new robust update rule of target network for deep reinforcement learning (DRL), to replace the conventional update rule, given as an exponential moving average. The target network is for smoothly generating the reference signals for a main network in DRL, thereby reducing learning variance. The problem with its conventional update rule is the fact that all the parameters are smoothly copied with the same speed from the main network, even when some of them are trying to update toward the wrong directions. This behavior increases the risk of generating the wrong reference signals. Although slowing down the overall update speed is a naive way to mitigate wrong updates, it would decrease learning speed. To robustly update the parameters while keeping learning speed, a t-soft update method, which is inspired by Student-t distribution, is derived with reference to the analogy between the exponential moving average and the normal distribution. Through the analysis of the derived t-soft update, we show that it takes over the properties of the Student-t distribution. Specifically, with a heavy-tailed property of the Student-t distribution, the t-soft update automatically excludes extreme updates that differ from past experiences. In addition, when the updates are similar to the past experiences, it can mitigate the learning delay by increasing the amount of updates. In PyBullet robotics simulations for DRL, an online actor-critic algorithm with the t-soft update outperformed the conventional methods in terms of the obtained return and/or its variance. From the training process by the t-soft update, we found that the t-soft update is globally consistent with the standard soft update, and the update rates are locally adjusted for acceleration or suppression.Copyright © 2020 Elsevier Ltd. All rights reserved.
[26]
MCKENNA E THOMSON M . High-resolution stochastic integrated thermal-electrical domestic demand model
[J]. Applied Energy 2016 , 165 : 445 -461 .
[本文引用: 1]
[27]
THOMAS D D’HOOP G DEBLECKER O , et al An integrated tool for optimal energy scheduling and power quality improvement of a microgrid under multiple demand response schemes
[J]. Applied Energy 2020 , 260 : 114314 .
[本文引用: 1]
[28]
AYYADI S BILIL H MAAROUFI M . Optimal charging of Electric Vehicles in residential area
[J]. Sustainable Energy, Grids & Networks 2019 , 19 : 100240 .
[本文引用: 1]
[29]
SUTTON R S BARTO A G . Reinforcement learning: an introduction [M]. 2nd ed. Cambridge, Massachusetts : The MIT Press , 2018 .
[本文引用: 1]
考虑能源效率的综合能源系统多目标优化调度
1
2022
... 在能源转型及“双碳”背景下,能源的高效利用和可持续发展引起全球广泛关注和高度重视.综合能源系统(Integrated Energy System,IES)兼具多能耦合、协同供应的优势,在提高能源利用效率的同时满足多样化用能需求,是能源领域的重要发展趋势之一[1 ] .在工业生产领域,IES的表现形式为集合园区电、气、热等能源形式的园区IES(Park-Level Integrated Energy System,PIES).PIES在能源综合利用[2 ] 、节能减排[3 ] 、可再生能源就地消纳[4 ] 等方面具有重要意义. ...
Multi-objective optimal scheduling of integrated energy system considering energy efficiency
1
2022
... 在能源转型及“双碳”背景下,能源的高效利用和可持续发展引起全球广泛关注和高度重视.综合能源系统(Integrated Energy System,IES)兼具多能耦合、协同供应的优势,在提高能源利用效率的同时满足多样化用能需求,是能源领域的重要发展趋势之一[1 ] .在工业生产领域,IES的表现形式为集合园区电、气、热等能源形式的园区IES(Park-Level Integrated Energy System,PIES).PIES在能源综合利用[2 ] 、节能减排[3 ] 、可再生能源就地消纳[4 ] 等方面具有重要意义. ...
能源互联网下基于博弈与证据理论的综合能源系统评价方法研究
1
2020
... 在能源转型及“双碳”背景下,能源的高效利用和可持续发展引起全球广泛关注和高度重视.综合能源系统(Integrated Energy System,IES)兼具多能耦合、协同供应的优势,在提高能源利用效率的同时满足多样化用能需求,是能源领域的重要发展趋势之一[1 ] .在工业生产领域,IES的表现形式为集合园区电、气、热等能源形式的园区IES(Park-Level Integrated Energy System,PIES).PIES在能源综合利用[2 ] 、节能减排[3 ] 、可再生能源就地消纳[4 ] 等方面具有重要意义. ...
Evaluation method of comprehensive energy system based on game theory & evidence theory under energy Internet
1
2020
... 在能源转型及“双碳”背景下,能源的高效利用和可持续发展引起全球广泛关注和高度重视.综合能源系统(Integrated Energy System,IES)兼具多能耦合、协同供应的优势,在提高能源利用效率的同时满足多样化用能需求,是能源领域的重要发展趋势之一[1 ] .在工业生产领域,IES的表现形式为集合园区电、气、热等能源形式的园区IES(Park-Level Integrated Energy System,PIES).PIES在能源综合利用[2 ] 、节能减排[3 ] 、可再生能源就地消纳[4 ] 等方面具有重要意义. ...
考虑需求侧响应的园区综合能源系统优化配置
1
2022
... 在能源转型及“双碳”背景下,能源的高效利用和可持续发展引起全球广泛关注和高度重视.综合能源系统(Integrated Energy System,IES)兼具多能耦合、协同供应的优势,在提高能源利用效率的同时满足多样化用能需求,是能源领域的重要发展趋势之一[1 ] .在工业生产领域,IES的表现形式为集合园区电、气、热等能源形式的园区IES(Park-Level Integrated Energy System,PIES).PIES在能源综合利用[2 ] 、节能减排[3 ] 、可再生能源就地消纳[4 ] 等方面具有重要意义. ...
Optimal configuration of park-level integrated energy system considering demand response
1
2022
... 在能源转型及“双碳”背景下,能源的高效利用和可持续发展引起全球广泛关注和高度重视.综合能源系统(Integrated Energy System,IES)兼具多能耦合、协同供应的优势,在提高能源利用效率的同时满足多样化用能需求,是能源领域的重要发展趋势之一[1 ] .在工业生产领域,IES的表现形式为集合园区电、气、热等能源形式的园区IES(Park-Level Integrated Energy System,PIES).PIES在能源综合利用[2 ] 、节能减排[3 ] 、可再生能源就地消纳[4 ] 等方面具有重要意义. ...
多园区微网优化共享运行策略
1
2020
... 在能源转型及“双碳”背景下,能源的高效利用和可持续发展引起全球广泛关注和高度重视.综合能源系统(Integrated Energy System,IES)兼具多能耦合、协同供应的优势,在提高能源利用效率的同时满足多样化用能需求,是能源领域的重要发展趋势之一[1 ] .在工业生产领域,IES的表现形式为集合园区电、气、热等能源形式的园区IES(Park-Level Integrated Energy System,PIES).PIES在能源综合利用[2 ] 、节能减排[3 ] 、可再生能源就地消纳[4 ] 等方面具有重要意义. ...
Optimal sharing operation strategy for multi park-level microgrid
1
2020
... 在能源转型及“双碳”背景下,能源的高效利用和可持续发展引起全球广泛关注和高度重视.综合能源系统(Integrated Energy System,IES)兼具多能耦合、协同供应的优势,在提高能源利用效率的同时满足多样化用能需求,是能源领域的重要发展趋势之一[1 ] .在工业生产领域,IES的表现形式为集合园区电、气、热等能源形式的园区IES(Park-Level Integrated Energy System,PIES).PIES在能源综合利用[2 ] 、节能减排[3 ] 、可再生能源就地消纳[4 ] 等方面具有重要意义. ...
基于强化学习的综合能源系统管理综述
1
2021
... IES具备大规模区域互联的特性,并逐渐形成大型高维系统,风光等不确定出力的新能源和以分布式储能设备为代表的柔性负荷的接入进一步加强了IES的复杂动态特性[5 ] .此外,能源多样性和多能间存在复杂多变的耦合特性也使现代化能源管理面临巨大挑战[6 ] . ...
Reinforcement learning based integrated energy system management: A survey
1
2021
... IES具备大规模区域互联的特性,并逐渐形成大型高维系统,风光等不确定出力的新能源和以分布式储能设备为代表的柔性负荷的接入进一步加强了IES的复杂动态特性[5 ] .此外,能源多样性和多能间存在复杂多变的耦合特性也使现代化能源管理面临巨大挑战[6 ] . ...
Decentralized control for residential energy management of a smart users microgrid with renewable energy exchange
1
2019
... IES具备大规模区域互联的特性,并逐渐形成大型高维系统,风光等不确定出力的新能源和以分布式储能设备为代表的柔性负荷的接入进一步加强了IES的复杂动态特性[5 ] .此外,能源多样性和多能间存在复杂多变的耦合特性也使现代化能源管理面临巨大挑战[6 ] . ...
Optimal energy management and sizing of renewable energy and battery systems in residential sectors via a stochastic MILP model
1
2020
... 传统的IES能量管理方法,诸如混合整数规划[7 ] 、非线性规划[8 ] 、线性规划[9 ] ,都基于模型驱动,是充分运用系统成熟机理的优化调度方法.高比例可再生能源的接入提高了系统实时调度决策的性能需求.此外,系统的源荷不确定性使机理建模面临困境,即使针对此类问题进行随机规划[10 ] 、鲁棒优化[11 ] ,依旧无法摆脱不确定性因素的刻画,模型驱动方法因而陷入瓶颈. ...
MINLP probabilistic scheduling model for demand response programs integrated energy hubs
1
2018
... 传统的IES能量管理方法,诸如混合整数规划[7 ] 、非线性规划[8 ] 、线性规划[9 ] ,都基于模型驱动,是充分运用系统成熟机理的优化调度方法.高比例可再生能源的接入提高了系统实时调度决策的性能需求.此外,系统的源荷不确定性使机理建模面临困境,即使针对此类问题进行随机规划[10 ] 、鲁棒优化[11 ] ,依旧无法摆脱不确定性因素的刻画,模型驱动方法因而陷入瓶颈. ...
A MILP-based modular energy management system for urban multi-energy systems: Performance and sensitivity analysis
1
2020
... 传统的IES能量管理方法,诸如混合整数规划[7 ] 、非线性规划[8 ] 、线性规划[9 ] ,都基于模型驱动,是充分运用系统成熟机理的优化调度方法.高比例可再生能源的接入提高了系统实时调度决策的性能需求.此外,系统的源荷不确定性使机理建模面临困境,即使针对此类问题进行随机规划[10 ] 、鲁棒优化[11 ] ,依旧无法摆脱不确定性因素的刻画,模型驱动方法因而陷入瓶颈. ...
区域综合能源系统冷-热-电-气概率多能流计算
1
2019
... 传统的IES能量管理方法,诸如混合整数规划[7 ] 、非线性规划[8 ] 、线性规划[9 ] ,都基于模型驱动,是充分运用系统成熟机理的优化调度方法.高比例可再生能源的接入提高了系统实时调度决策的性能需求.此外,系统的源荷不确定性使机理建模面临困境,即使针对此类问题进行随机规划[10 ] 、鲁棒优化[11 ] ,依旧无法摆脱不确定性因素的刻画,模型驱动方法因而陷入瓶颈. ...
Calculation of cold-heat-electricity-gas probabilistic multi-energy flow in regional comprehensive energy system
1
2019
... 传统的IES能量管理方法,诸如混合整数规划[7 ] 、非线性规划[8 ] 、线性规划[9 ] ,都基于模型驱动,是充分运用系统成熟机理的优化调度方法.高比例可再生能源的接入提高了系统实时调度决策的性能需求.此外,系统的源荷不确定性使机理建模面临困境,即使针对此类问题进行随机规划[10 ] 、鲁棒优化[11 ] ,依旧无法摆脱不确定性因素的刻画,模型驱动方法因而陷入瓶颈. ...
考虑需求响应与光伏不确定性的综合能源系统鲁棒优化
1
2020
... 传统的IES能量管理方法,诸如混合整数规划[7 ] 、非线性规划[8 ] 、线性规划[9 ] ,都基于模型驱动,是充分运用系统成熟机理的优化调度方法.高比例可再生能源的接入提高了系统实时调度决策的性能需求.此外,系统的源荷不确定性使机理建模面临困境,即使针对此类问题进行随机规划[10 ] 、鲁棒优化[11 ] ,依旧无法摆脱不确定性因素的刻画,模型驱动方法因而陷入瓶颈. ...
Robust optimization of integrated energy systems considering demand response and photovoltaic uncertainty
1
2020
... 传统的IES能量管理方法,诸如混合整数规划[7 ] 、非线性规划[8 ] 、线性规划[9 ] ,都基于模型驱动,是充分运用系统成熟机理的优化调度方法.高比例可再生能源的接入提高了系统实时调度决策的性能需求.此外,系统的源荷不确定性使机理建模面临困境,即使针对此类问题进行随机规划[10 ] 、鲁棒优化[11 ] ,依旧无法摆脱不确定性因素的刻画,模型驱动方法因而陷入瓶颈. ...
多智能体深度强化学习的若干关键科学问题
2
2020
... 为了摆脱机理建模的制约,并通过离线训练缩短实时调度决策时间,引入数据驱动,采用无模型的强化学习(Reinforcement Learning,RL)方法.强化学习通过智能体与环境的迭代交互,依靠奖励回报自适应学习生成最优策略,不受精确的模型信息和预测准确性的制约.此外,强化学习还可以与具备良好数据处理能力的深度学习相结合形成较传统优化算法更易实现的深度强化学习(Deep Reinforcement Learning,DRL)[12 ] 算法. ...
... 为进一步对所提算法有效性进行验证,首先选取传统的基于模型预测控制的调度方法与所提基于F-DDPG的调度方法进行对比.此外,如文献[12 ]所述,对于多主体系统,直接使用传统DDPG进行独立训练和决策,其面对的环境不稳定,这种不稳定打破了强化学习算法所遵循的马尔可夫假设[29 ] ,无法输出稳定的策略,因此额外采用基于MADDPG的调度方法进行对比. ...
Important scientific problems of multi-agent deep reinforcement learning
2
2020
... 为了摆脱机理建模的制约,并通过离线训练缩短实时调度决策时间,引入数据驱动,采用无模型的强化学习(Reinforcement Learning,RL)方法.强化学习通过智能体与环境的迭代交互,依靠奖励回报自适应学习生成最优策略,不受精确的模型信息和预测准确性的制约.此外,强化学习还可以与具备良好数据处理能力的深度学习相结合形成较传统优化算法更易实现的深度强化学习(Deep Reinforcement Learning,DRL)[12 ] 算法. ...
... 为进一步对所提算法有效性进行验证,首先选取传统的基于模型预测控制的调度方法与所提基于F-DDPG的调度方法进行对比.此外,如文献[12 ]所述,对于多主体系统,直接使用传统DDPG进行独立训练和决策,其面对的环境不稳定,这种不稳定打破了强化学习算法所遵循的马尔可夫假设[29 ] ,无法输出稳定的策略,因此额外采用基于MADDPG的调度方法进行对比. ...
基于深度强化学习的微能源网能量管理与优化策略研究
1
2020
... 许多专家学者已经开始利用DRL来处理IES管理问题并取得一定研究成果.文献[13 ]中采用深度Q网络建立微网能源系统优化管理模型,管理电、热、冷3种能源系统的能源生产、转换与存储操作,实现微网经济调度.文献[14 ]中提出一种基于柔性行动器-评判器的强化学习框架,解决电气IES的多能流协同优化问题.文献[15 ]中提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法求解电气IES优化调度问题.文献[16 ]中采用一种改进型深度确定性策略梯度(DDPG-AD)算法来优化文中所提分布式清洁能源发电系统模型的发电效率. ...
Research on energy management and optimization strategy of micro-energy network based on deep reinforcement learning
1
2020
... 许多专家学者已经开始利用DRL来处理IES管理问题并取得一定研究成果.文献[13 ]中采用深度Q网络建立微网能源系统优化管理模型,管理电、热、冷3种能源系统的能源生产、转换与存储操作,实现微网经济调度.文献[14 ]中提出一种基于柔性行动器-评判器的强化学习框架,解决电气IES的多能流协同优化问题.文献[15 ]中提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法求解电气IES优化调度问题.文献[16 ]中采用一种改进型深度确定性策略梯度(DDPG-AD)算法来优化文中所提分布式清洁能源发电系统模型的发电效率. ...
基于柔性行动器-评判器深度强化学习的电-气综合能源系统优化调度
1
2021
... 许多专家学者已经开始利用DRL来处理IES管理问题并取得一定研究成果.文献[13 ]中采用深度Q网络建立微网能源系统优化管理模型,管理电、热、冷3种能源系统的能源生产、转换与存储操作,实现微网经济调度.文献[14 ]中提出一种基于柔性行动器-评判器的强化学习框架,解决电气IES的多能流协同优化问题.文献[15 ]中提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法求解电气IES优化调度问题.文献[16 ]中采用一种改进型深度确定性策略梯度(DDPG-AD)算法来优化文中所提分布式清洁能源发电系统模型的发电效率. ...
Optimal dispatching of electric-gas integrated energy system based on flexible actuator-judge deep reinforcement learning
1
2021
... 许多专家学者已经开始利用DRL来处理IES管理问题并取得一定研究成果.文献[13 ]中采用深度Q网络建立微网能源系统优化管理模型,管理电、热、冷3种能源系统的能源生产、转换与存储操作,实现微网经济调度.文献[14 ]中提出一种基于柔性行动器-评判器的强化学习框架,解决电气IES的多能流协同优化问题.文献[15 ]中提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法求解电气IES优化调度问题.文献[16 ]中采用一种改进型深度确定性策略梯度(DDPG-AD)算法来优化文中所提分布式清洁能源发电系统模型的发电效率. ...
Dynamic energy conversion and management strategy for an integrated electricity and natural gas system with renewable energy: Deep reinforcement learning approach
1
2020
... 许多专家学者已经开始利用DRL来处理IES管理问题并取得一定研究成果.文献[13 ]中采用深度Q网络建立微网能源系统优化管理模型,管理电、热、冷3种能源系统的能源生产、转换与存储操作,实现微网经济调度.文献[14 ]中提出一种基于柔性行动器-评判器的强化学习框架,解决电气IES的多能流协同优化问题.文献[15 ]中提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法求解电气IES优化调度问题.文献[16 ]中采用一种改进型深度确定性策略梯度(DDPG-AD)算法来优化文中所提分布式清洁能源发电系统模型的发电效率. ...
A novel multi-agent DDQN-AD method-based distributed strategy for automatic generation control of integrated energy systems
1
2020
... 许多专家学者已经开始利用DRL来处理IES管理问题并取得一定研究成果.文献[13 ]中采用深度Q网络建立微网能源系统优化管理模型,管理电、热、冷3种能源系统的能源生产、转换与存储操作,实现微网经济调度.文献[14 ]中提出一种基于柔性行动器-评判器的强化学习框架,解决电气IES的多能流协同优化问题.文献[15 ]中提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法求解电气IES优化调度问题.文献[16 ]中采用一种改进型深度确定性策略梯度(DDPG-AD)算法来优化文中所提分布式清洁能源发电系统模型的发电效率. ...
基于纵向联邦强化学习的居民社区综合能源系统协同训练与优化管理方法
1
2022
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
The collaborative training and management-optimized method for residential integrated energy system based on vertical federated reinforcement learning
1
2022
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
Energy demand prediction with federated learning for electric vehicle networks
1
2019
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
Federated reinforcement learning for energy management of multiple smart homes with distributed energy resources
1
2022
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
基于主从博弈的工业园区综合能源系统互动优化运行方法
1
2019
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
Leader-follower game based optimized operation method for interaction of integrated energy system in industrial park
1
2019
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
计及热惯性和运行策略的综合能源系统可靠性评估方法
1
2018
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
Reliability evaluation of integrated energy system considering thermal inertia and operation strategy
1
2018
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
城市燃气SCADA及信息管理系统设计
1
2009
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
Design of information management system for urban natural gas SCADA system
1
2009
... 此外,当前机器学习模型构建多依托集中式框架进行分布式学习优化,需要各智能体之间进行信息交互,随着IES规模的不断扩大,数据隐私的地位逐步提高.伴随着用户对数据隐私的重视,分布式学习的隐私保护逐步成为当前研究重点.国内外学者提出联邦强化学习方法来解决此类问题.在联邦强化学习中,各智能体通过向聚合中心发送模型参数替代数据,进而保护了用户的隐私安全.文献[17 ]中将纵向联邦学习与深度强化学习算法相结合,协同优化电、热、气3种能源系统实时管理能力的同时保护各参与方的数据安全.文献[18 ]中将联邦学习与能源需求学习相结合,有效保护用户数据隐私的同时预测电动汽车的能源需求.文献[19 ]中提出一种联邦强化学习(Federated Reinforcement Learning,FRL)方法用于多智能家庭的能源管理.当前,针对IES的能量管理过程中的隐私问题,多采用多智能体强化学习方法,尚缺乏联邦强化学习的研究与应用.FRL框架中,各参与方间交互DRL模型中间参数,协同优化各参与方DRL模型的训练速度[20 ⇓ -22 ] .此外,FRL在各参与方中采用间接交互模型中间参数的方式替代了原始数据的直接交换,使各参与方的数据隐私得到有效保护. ...
基于深度强化学习的综合能源系统动态经济调度
1
2021
... 在IES某一确定状态si 下,可通过动作-值函数Qπ (si , ai )[23 ] 对动作ai 的优劣程度进行评估,其目标是找到最优策略π 以最大化状态-动作值函数: ...
Dynamic economic dispatch for integrated energy system based on deep reinforcement learning
1
2021
... 在IES某一确定状态si 下,可通过动作-值函数Qπ (si , ai )[23 ] 对动作ai 的优劣程度进行评估,其目标是找到最优策略π 以最大化状态-动作值函数: ...
Multi-agent actor-critic for mixed cooperative-competitive environments
1
2017
... 在MADDPG模型内,各智能体分为观测全局环境状态的评论家(Critic)网络和观测局部环境状态的演员(Actor)网络[24 ] .MADDPG算法依托集中训练的Critic网络来应对环境的非稳定状态,在训练阶段,Critic网络传递全局信息至各智能体,同步各智能体策略状态,保证MADDPG的训练稳定性.Actor网络和Critic网络均为采用线性整流函数激活的多层全连接网络.建立的Actor和Critic网络的结构如图2 所示.obs用来表示输入层的五维(5d)观测值,Actor网络经过两个神经元分别为500、128的隐藏层后在输出层输出四维(4d)的决策值,并采用双曲正切函数tanh作为激活函数控制动作输出,避免过大或过小的动作值对系统的影响.n 为数组个数. ...
T-soft update of target network for deep reinforcement learning
1
2021
... (3) 目标网络参数更新.利用软更新技术更新目标网络的参数来进一步保证学习过程的稳定性[25 ] : ...
High-resolution stochastic integrated thermal-electrical domestic demand model
1
2016
... 园区各设备运行参数如表2 所示,并基于开源的CREST模型[26 ] 生成各用能子系统的热负荷、电负荷及新能源出力数据.该模型经由拉夫堡大学研究团队提出并通过有效性验证,现已被大规模使用[27 -28 ] .系统以15 min为间隔将调度时段划分为96个时隙. ...
An integrated tool for optimal energy scheduling and power quality improvement of a microgrid under multiple demand response schemes
1
2020
... 园区各设备运行参数如表2 所示,并基于开源的CREST模型[26 ] 生成各用能子系统的热负荷、电负荷及新能源出力数据.该模型经由拉夫堡大学研究团队提出并通过有效性验证,现已被大规模使用[27 -28 ] .系统以15 min为间隔将调度时段划分为96个时隙. ...
Optimal charging of Electric Vehicles in residential area
1
2019
... 园区各设备运行参数如表2 所示,并基于开源的CREST模型[26 ] 生成各用能子系统的热负荷、电负荷及新能源出力数据.该模型经由拉夫堡大学研究团队提出并通过有效性验证,现已被大规模使用[27 -28 ] .系统以15 min为间隔将调度时段划分为96个时隙. ...
1
2018
... 为进一步对所提算法有效性进行验证,首先选取传统的基于模型预测控制的调度方法与所提基于F-DDPG的调度方法进行对比.此外,如文献[12 ]所述,对于多主体系统,直接使用传统DDPG进行独立训练和决策,其面对的环境不稳定,这种不稳定打破了强化学习算法所遵循的马尔可夫假设[29 ] ,无法输出稳定的策略,因此额外采用基于MADDPG的调度方法进行对比. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}