

依据预测结果的形式,光伏功率预测分为点预测和区间预测.点预测是一种确定性预测,结果较为直观,但是难以表征光伏出力的不确定性;区间预测可以得到一定置信度水平下光伏功率的上下限,对于含光伏电力系统的风险评估、不确定性评估具有重要参考价值.Delta法[12-13]是一种构造预测区间的方法,需假定数据噪声同质且满足标准正态分布;事实上,噪声在很多情况下难以满足这个假设,因此Delta法得到的预测区间与实际情况可能有较大差距.文献[14-15]中使用贝叶斯法构造预测区间,但是Hessian矩阵的求取使得此方法的计算负担过重.文献[16-17]中使用Bootstrap法进行区间预测,得到认知不确定性和偶然不确定性分别对应的预测区间后进行叠加,其结果可以表征总体不确定性;Bootstrap法虽易于实现,但当数据样本较多时,计算效率低.边界估值(Lower Upper Bound Estimation, LUBE)理论[18]根据预测区间评估指标,利用启发式算法对神经网络参数进行寻优,可以得到满足可信度和准确度要求的神经网络区间预测模型.文献[18]中通过多个算例分析说明:与Delta法、贝叶斯法、Bootstrap法相比,LUBE法得到的区间预测模型性能更为稳定,且预测区间可信度较高.传统前馈神经网络多采用梯度下降法,训练时间较长,容易陷入局部最优,且学习率具有选择敏感的特点.极限学习机(Extreme Learning Machine, ELM)可克服上述缺陷,具有更快的学习速度和更优的泛化能力,被广泛应用于预测领域[19].文献[20]中使用ELM模型来进行光伏电站功率区间预测,ELM模型隐层输入权重与偏置可以随机生成,而隐层输出权重通过求解最优化问题确定,进而得到预测区间.然而,ELM模型也存在缺点[21]:当数据样本自变量过多时,模型的稳定性与泛化能力会受到不利影响;原始数据集中若存在离群点,可能会导致模型预测性能不佳;此外,模型的隐层输入权重与偏置参数随机生成,其预测精度仍有提升空间.
针对现有研究存在的问题,提出一种考虑ELM训练集优化与参数寻优的光伏功率区间预测技术.利用相关性分析对ELM的输入参数进行筛选,剔除无关历史信息,仅保留与因变量具有较高相关性的自变量;提出基于加权欧氏距离指标的ELM训练集选取方法,在去除异常离群点、提高训练效率的同时,使得训练集样本和待预测样本具有较高的相似度,从而避免过拟合,提升预测的可信度和准确度;提出一种ELM参数混合寻优算法,在根据预测区间评估与优化准则设定适应度函数后,采用精英保留策略遗传算法(Elitist Strategy Genetic Algorithm, ESGA)优化ELM隐层的输入权重与偏置取值,同时使用分位数回归方法优化ELM的隐层输出权重,生成评价指标最优的预测区间,有效降低模型预测随机性.将提出的预测方法应用于实际算例,并与其他方法进行比较,以证明本文方法在光伏功率区间预测上的优越性.
1 光伏功率区间预测
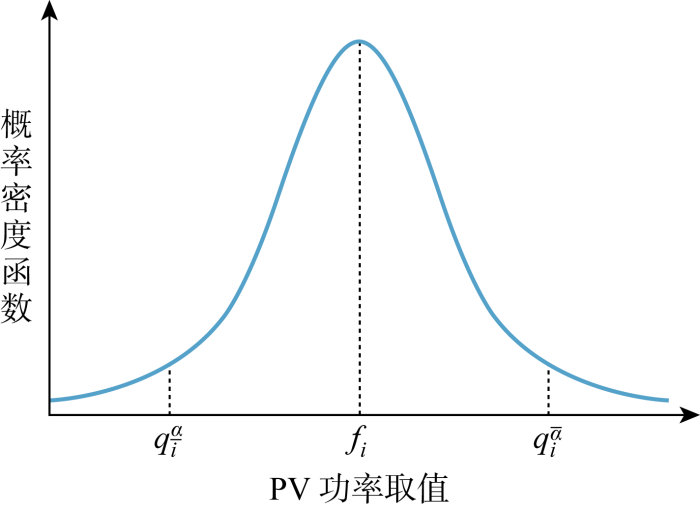
1.1 光伏功率预测区间定义
光伏功率是一个随机变量,利用区间预测可以得到其在一定条件下的取值区间,在工程实际中比点预测具有更高参考价值.
式中:Pr(·)为概率;fi为预测的变量值.
图1
1.2 光伏功率预测区间评估指标
分别采用可信度与准确度衡量区间预测性能.首先,预测区间覆盖率(Prediction Interval Coverage Probability, PICP)可以表征预测区间可信度,即
式中:Ntot为预测样本总数;
此外,如果PICP非常高,但是预测区间宽度非常大,则区间预测结果没有参考价值.预测区间归一化平均带宽(Prediction Interval Normalized Average Width, PINAW)可以表征预测区间准确度,即
在PINC一定的情况下,PINAW越小,说明预测区间平均宽度越窄,准确度越高.
2 ELM
2.1 ELM原理
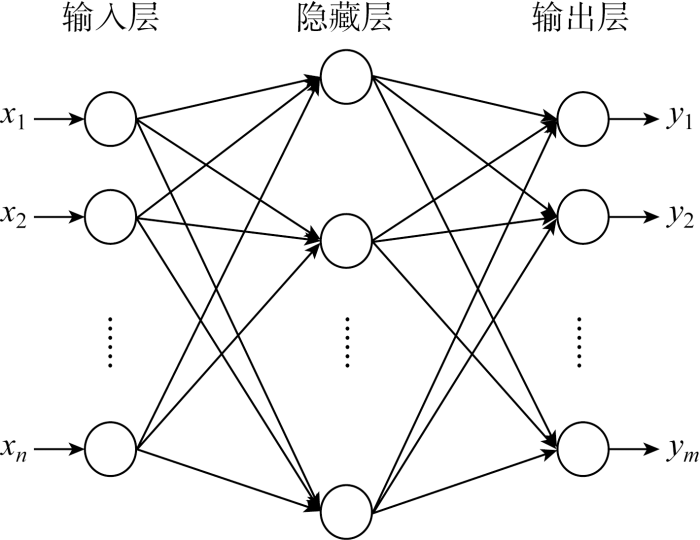
具有n个输入层神经元、L个隐藏层神经元、m个输出层神经元的ELM结构如图2所示.对于N个离散训练样本
式中:yi=[yi1yi2 … yim]T∈Rm为第i个训练样本的输入xi经ELM处理后的输出;βj=[βj1βj2 … βjm]T∈Rm为第j个隐藏层神经元的输出权重;g(·)为激励函数;ωj=[ωj1ωj2 … ωjn]T∈Rn为第j个隐藏层神经元的输入权重;bj为第j个隐藏层神经元的偏置.
图2
由于ELM能够以极小误差逼近训练样本,所以训练样本的目标输出可表示为
相应的矩阵形式为
式中:T∈RN×m为目标输出矩阵;H∈RN×L为隐藏层输出矩阵;β∈RL×m为隐藏层输出权重矩阵.
当隐藏层输入权重和偏置生成后,H为常数矩阵.因此,β的求解可以视为求解线性系统的最小二乘特解问题,即寻找β的最优值使代价函数,ELM模型输出和目标输出之差的模最小,如下式所示:
由广义逆理论可得,β的最小二乘特解可以表示为
式中:H†为H的Moore-Penrose广义逆.
ELM被广泛应用于基于数据驱动的变量预测,并能取得较为理想的预测结果.在训练前,通常将样本数据归一化,并使用ELM预测光伏电站功率.
2.2 ELM参数优化与预测区间生成
为了使ELM区间预测获得更优结果,从两个方面对ELM进行改进.第一,提出加权欧氏距离指标,对历史样本进行筛选以获得ELM训练集,使得训练集样本和待预测日各时刻的样本具有较高程度的相似性;第二,提出ELM参数混合寻优算法,使用ESGA对ELM隐藏层输入权重ωhid与偏置bhid进行寻优,在每次迭代中,对于给定的ωhid和bhid,选取分位数回归方法优化ELM隐藏层输出权重的参数值和对应预测区间,并计算个体适应度,最终确定使ELM预测性能最优的隐藏层输入权重与偏置值.
2.2.1 ELM训练集选取
提出加权欧氏距离指标来衡量待预测样本与历史样本自变量数值之间的相似度.加权欧氏距离越小,表示相似度越高.为充分考虑不同自变量对因变量影响程度的差异性,首先应进行相关性分析.考虑光伏出力数据具有周期性等特征,采用Spearman相关系数描述数据间相关程度.根据定义,变量x与y间的Spearman相关系数计算如下:
式中:xi、yi分别为变量x与y的第i项样本数据,即气象因素与PV功率时间序列的第i项历史数据;t为变量中的样本总数;
变量间距离度量方面,传统欧氏距离主要计算变量间的真实距离,描述样本间不相似程度.对应元素较多时,为充分考虑各元素对累积相似性的影响,可采用加权欧氏距离描述气象特征对光伏出力的影响情况.设x1, x2, …,
式中:hi为历史数据中某样本单元的自变量数值向量;xp为某待预测样本单元的自变量预报值向量;1/ωk为自变量k的权重,Spearman相关系数绝对值越大,ωk越大,距离权重赋值越小.ωk的计算公式如下:
加权欧氏距离可充分考虑各因素对累积相似性的重要程度,通过各因素相关性决定变量权值系数,使变量间的欧氏距离标准化.对于待预测的各样本单元,在历史数据中筛选与其加权欧氏距离最小的若干个样本单元,构成最终的ELM训练集.
2.2.2 ELM隐藏层输入权重与偏置混合寻优
由于ELM的参数会对其预测性能产生影响,而随机生成的ELM隐藏层输入权重与偏置可能导致预测模型无法获得最优的预测区间,所以有必要确定ELM参数的最优值.生成ELM训练集后,将 ESGA 与分位数回归相结合,对ELM的隐藏层输入权重与偏置进行混合寻优.
预测区间的优化需要构建相应准则,以判断个体的优劣.综合考虑PICP和PINAW,定义适应度函数为
式中:β(ωhid, bhid)为布尔类型指示函数,其具体数值由隐藏层输入权重及偏置矩阵决定,当pPINC>pPICP时,β(ωhid, bhid)=0,否则,β(ωhid, bhid)=1;M为惩罚系数,此时取较大值;平均覆盖率误差是PINC和PICP的差值,用dACE(ωhid, bhid)表示.
ESGA优化ELM隐藏层输入权重与偏置具体流程可概括如下:
(1) 生成mc个待优化隐藏层输入权重及偏置组合(ωhid, bhid),构成初始种群.
(2) 根据适应度函数ffit(ωhid, bhid)计算结果进行个体评价,其中适应度最高的mcfit个个体(ωhid, bhid)保留为精英个体.
(3) 除精英个体外,通过选择、交叉、变异等遗传操作构建新的子代种群,并计算子代个体适应度.
(4) 用保留的精英个体替换子代种群中适应度最低的个体,并将精英个体更新为子代种群中适应度最高的mcfit个个体.
(5) 若达到最大迭代次数,则退出循环,输出最优个体对应的隐藏层权重与偏置参数;否则,返回步骤(3).
在ESGA的每一次迭代中,对于每个个体对应的ELM隐藏层输入权重与偏置,利用分位数回归法得到ELM隐藏层输出权重最优值与预测区间,然后计算个体适应度.个体适应度越大,说明相应ωhid和bhid的取值越优,ELM的区间预测性能越优.
2.2.3 预测区间生成
通常情况下,历史数据中仅包含随机变量的观测值,而不含取值区间上下限,无法通过直接训练ELM对变量的取值区间进行预测.因此,采用分位数回归理论[25]生成光伏出力预测区间.
对于随机变量yrand,分布函数用F(yrand)表示.yrand的第τ分位数定义为
式中:τ是位于0~1之间的数;inf
令
式中:
在优化问题中引入辅助变量,可以将原问题转化为线性规划问题[25].令{
式中:
3 光伏功率区间预测流程
3.1 数据获取
基于数据驱动的光伏功率预测需要分析大量历史数据,通过模型训练来构建光伏功率与外部因素之间的关系.已有研究表明光伏功率特性存在季节性变化特征,即不同季节对应的光伏功率预测模型有差异[26].确定待预测日的日期后,需要分别从光伏站和气象站获取此季节各个时刻的光伏功率数据与气象历史数据,构成历史样本单元.
3.2 数据预处理
获得历史样本单元后,需要对数据进行预处理,得到可供模型训练的数据集.第一,剔除存在缺失或异常数据点的历史样本单元,以免对模型训练造成不利影响.第二,使用Spearman相关系数量化气象因素对光伏功率的影响程度,从中筛选出与光伏出力相关性较高的气象因素作为ELM的输入.第三,基于Spearman相关系数值,根据式(10)~(11)计算待预测日样本单元与历史样本单元间的加权欧氏距离;对于待预测日的每个时刻,选取与其相距最近的若干个历史样本单元,共同构成ELM的训练集.
3.3 模型训练
确定训练集后,需要进行模型训练.首先,应确定ELM的结构.通过相关性分析确定n个与光伏出力具有较高相关程度的气象因素后,相应地,ELM输入层的神经元个数为n;因ELM的输出是光伏功率上下限,故输出层神经元个数为2;隐藏层神经元个数的选取需要保证预测模型的回归性能稳定,不能过少,同时也应当避免过多,否则会加重计算负担,且对提升ELM预测性能无益.交叉验证法[27]是一种常用的确定神经网络结构的方法,采用此法确定ELM的隐藏层神经元个数:将ELM训练集样本随机均分为5个部分,对同一隐藏层神经元个数,依次取其中4个部分进行训练以确定ELM区间预测模型,并将最后一部分评估最终区间预测性能,然后将5次预测区间评估指标取均值.分析不同隐藏层神经元数量下预测区间评估指标均值,便可以确定隐藏层神经元数目优化结果.优化ELM结构之后,为了获得使模型预测性能最佳的ELM参数,使用 ESGA 和分位数回归对ELM进行参数寻优,确定ELM隐藏层输入权重与偏置的最优值,形成ELM预测模型.
3.4 区间预测
得到ELM预测模型后,输入待预测日各时刻经相关性分析筛选后的气象因素预报值,通过分位数回归,获得相应置信水平下光伏功率的预测区间.
4 算例分析
4.1 数据介绍
为验证所提光伏功率区间预测方法的适用性,选取2018年澳大利亚昆士兰大学露西亚校区的光伏出力数据与气象站数据进行算例分析.光伏装机容量为433 kW,监测的气象因素包括风向角、风速、温度、相对湿度、海平面气压、降雨量和太阳辐照度.光伏功率和气象数据的采样间隔均为1 min.光伏在夜晚出力恒为0,仅对白天光伏出力大于0的时刻进行光伏功率区间预测,选取时间步长为15 min[27].在指定光伏功率待预测日后,通过对之前若干邻近日光伏出力起止时刻的拟合分析,可确定待预测日中光伏出力大于0的时间段.
剔除历史数据中数据缺失或异常的样本后,分别计算四季光伏功率与各项因素的Spearman相关系数.根据相关系数绝对值的计算结果,太阳辐照度与光伏功率相关系数绝对值为最高水平,始终维持于0.96以上;四季相对湿度与光伏功率相关系数绝对值分布于0.46~0.66;温度与光伏功率相关系数绝对值分布于0.39~0.60,略低于相对湿度;其他因素如风向角、风速等与光伏功率的相关系数绝对值总体维持较低水平,低于0.2,因此该类因素的影响忽略不计.
由于光伏出力特性与天气类型相关[28],为测试所提预测方法在各种天气类型下是否均能实现高性能的光伏功率区间预测,选择2018年7月1日(阴雨天)、8月3日(多云天)和9月10日(晴天)的数据,分别在PINC为95%、90%、85%和80%的情况下预测光伏功率区间,并计算指标值评估预测结果.2018年夏季(6~8月)与秋季(9~11月)数据中分别剔除7月1日、8月3日与9月10日数据后,作为3次区间预测中ELM训练集的待选集.对于待预测日的每一个样本单元,计算其与待选训练集中每一个样本单元的加权欧氏距离,选取其中相似度最高的50个样本单元,组成ELM训练集.
4.2 预测结果
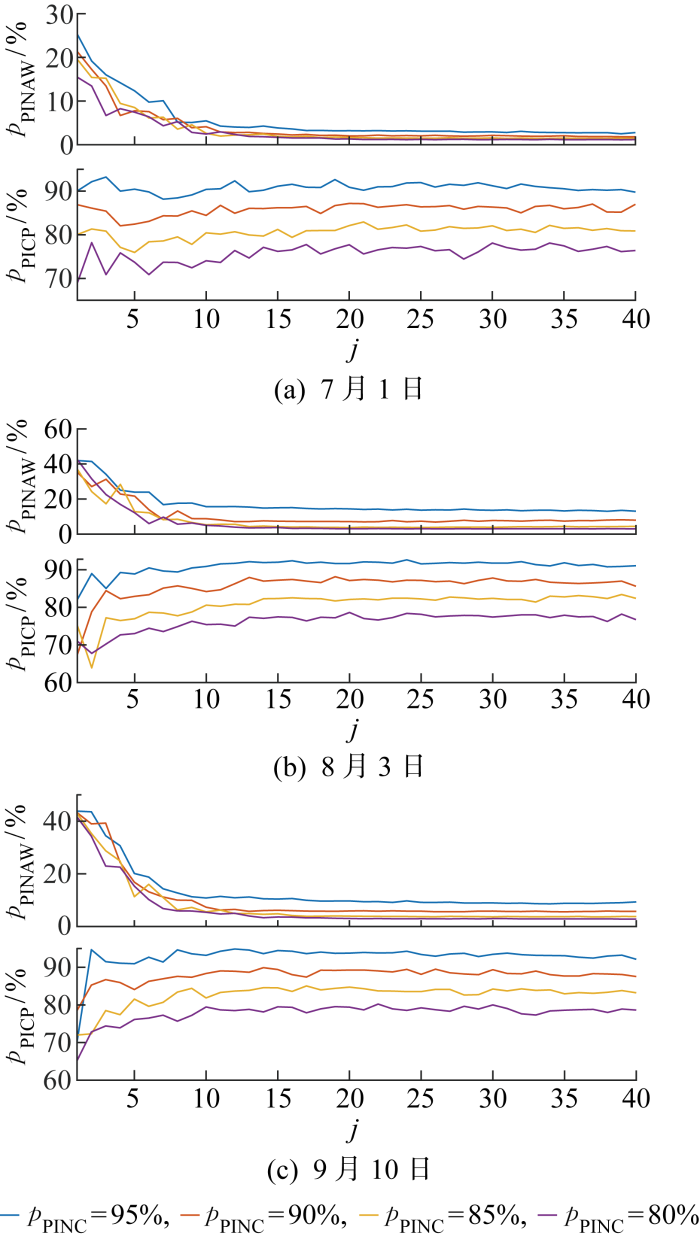
考虑到光照时间,对于7月1日、8月3日、9月10日3个典型日,确定ELM训练集后,需要通过交叉验证选取ELM隐藏层神经元数量.交叉验证结果如图3(a)~3(c)所示.由于交叉验证时ELM隐藏层输入权重与偏置的生成是随机的,所以得到的预测区间并非最优区间,但评估指标随ELM隐藏层神经元个数增加所呈现的变化趋势可以为隐藏层神经元个数的选取提供重要依据.由图3可知,在各情况下,当隐藏层神经元个数达到20后,ELM的预测性能趋于稳定.因此,在算例分析中选用的隐藏层神经元节点数为20.
图3
4.2.1 阴雨天区间预测结果
图4
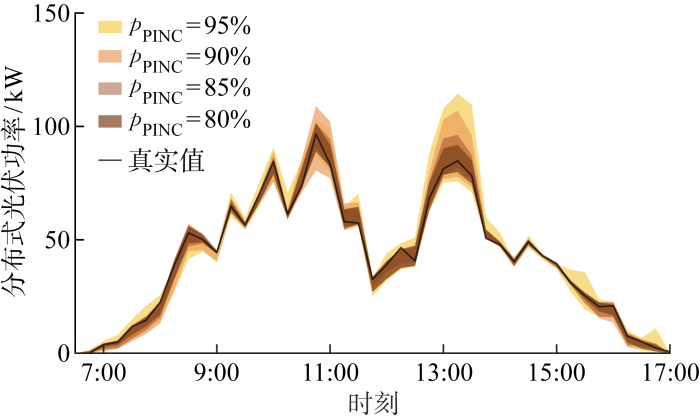
表1 7月1日预测区间评估指标
Tab.1
| pPINC/% | pPICP/% | pPINAW/% |
|---|---|---|
| 95 | 95.12 | 2.69 |
| 90 | 95.12 | 1.93 |
| 85 | 92.68 | 1.48 |
| 80 | 87.80 | 1.18 |
4.2.2 多云天区间预测结果
图5
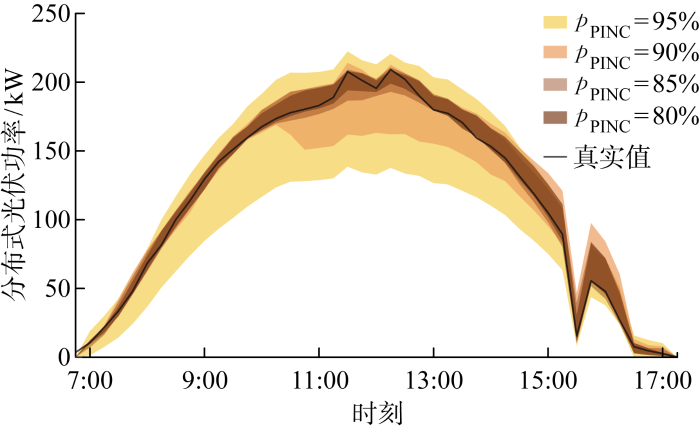
表2 8月3日预测区间评估指标
Tab.2
| pPINC /% | pPICP/% | pPINAW/% |
|---|---|---|
| 95 | 100 | 12.87 |
| 90 | 100 | 6.23 |
| 85 | 97.56 | 3.67 |
| 80 | 90.24 | 3.03 |
4.2.3 晴天区间预测结果
图6
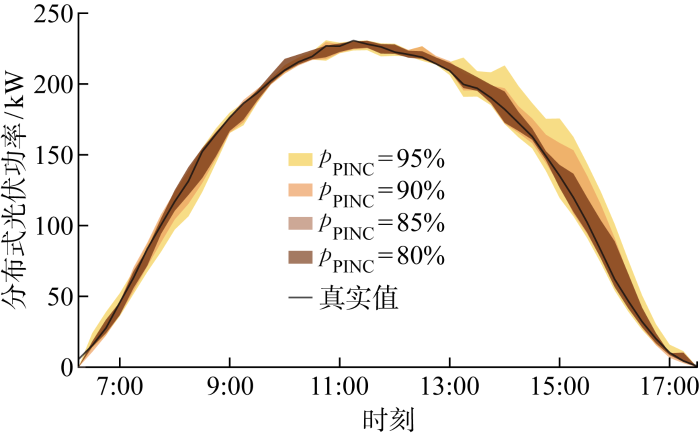
图6
不同PINC下9月10日预测区间
Fig.6
Prediction intervals on September 10 at different PINCs
表3 9月10日预测区间评估指标
Tab.3
| pPINC /% | pPICP/% | pPINAW/% |
|---|---|---|
| 95 | 97.73 | 7.87 |
| 90 | 97.73 | 4.85 |
| 85 | 95.45 | 3.36 |
| 80 | 90.91 | 2.67 |
4.2.4 光伏功率区间预测结果分析
从图4~6可以看出,光伏功率在不同天气类型下呈现出不同特性.阴雨天太阳辐照度较小,光伏功率也较小;多云天的光伏功率也可能具有较大峰值,但由于云层移动和遮挡,光伏功率曲线存在剧烈波动;晴天的光伏功率曲线较为平滑,且峰值较大.在3种天气类型下,预测区间上下限的变化趋势和实际光伏功率变化趋势均能保持一致.随着PINC减小,图4~6中预测区间覆盖率降低,且预测区间宽度也变小.表1~3中PICP与PINAW的数值更加直观地描述了这一现象.数据显示,在3种天气类型下,本文方法得到的光伏功率区间预测结果均能满足可信度要求,即PICP均高于PINC.以8月3日为例,PINC为95%及90%对应的预测区间能够完全覆盖预测时间段内实际的光伏功率点,PICP高达100%,而95%预测区间是4种置信水平下最宽的,PINAW达到12.87%,意味着预测结果可信度高,但较为保守.将PINC由95%减小为80%,实际的PICP也在逐渐减小;在牺牲预测区间可信度的同时,预测区间准确度提高,PINAW最小可以低至3.03%.在PINC取值不同的情况下,预测区间的可信度均满足置信水平要求,PICP明显高于PINC.
4.3 不同区间预测方法结果对比
为验证本文光伏功率区间预测方法的优越性,使用其他预测方法对同一算例进行光伏功率区间预测.各方法说明如下:
(1) 方法 I 为本文所提光伏功率区间预测法.
(2) 方法 II 使用普通欧氏距离指标对ELM训练集进行选取,即式(10)中距离权重恒为1,其他步骤均与方法I相同.
(3) 方法 III 不含基于加权欧氏距离指标的ELM训练集选取这一步骤,其他步骤均与方法 I 相同.
(4) 方法 IV 为ELM模型的隐藏层输入权重与偏置随机生成,其他步骤均与方法I相同.
方法 I 与方法 II、方法 III、方法 IV 的对比可以分别体现出加权欧氏距离指标、ELM训练集选取以及隐藏层输入权重与偏置优化对预测区间性能的影响.考虑到方法 IV 中ELM隐藏层输入权重与偏置的随机性,使用方法 IV 进行10次ELM训练,并取10次预测区间评估指标的期望值与其他方法的结果进行对比.
由于历史数据样本庞大,为避免训练时间过长,同时为了控制训练集相同,以排除无关因素的影响,方法 IV 的训练集由本文提出的加权欧氏距离指标确定.方法 III 的训练集在历史样本单元中随机抽样生成,且训练集样本规模与其他方法相同.不同方法区间预测结果对比如表4所示.
表4 不同方法区间预测结果对比
Tab.4
| 日期 | pPINC/% | 方法I | 方法II | 方法III | 方法IV | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pPICP/% | pPINAW/% | pPICP/% | pPINAW/% | pPICP/% | pPINAW/% | pPICP/% | pPINAW/% | |||||
| 7月1日 | 95 | 95.12 | 2.69 | 95.12 | 2.78 | 97.56 | 7.82 | 93.90 | 3.00 | |||
| 7月1日 | 90 | 95.12 | 1.93 | 92.68 | 1.95 | 97.56 | 4.50 | 88.78 | 2.01 | |||
| 7月1日 | 85 | 92.68 | 1.48 | 92.68 | 1.60 | 95.12 | 4.42 | 86.83 | 1.51 | |||
| 7月1日 | 80 | 87.80 | 1.18 | 87.80 | 1.21 | 90.24 | 3.91 | 85.37 | 1.23 | |||
| 8月3日 | 95 | 100.00 | 12.87 | 100.00 | 14.31 | 100.00 | 14.35 | 99.76 | 14.27 | |||
| 8月3日 | 90 | 100.00 | 6.23 | 100.00 | 6.95 | 97.56 | 7.11 | 99.27 | 6.93 | |||
| 8月3日 | 85 | 97.56 | 3.67 | 95.12 | 3.71 | 95.12 | 4.66 | 97.07 | 3.81 | |||
| 8月3日 | 80 | 90.24 | 3.03 | 90.24 | 3.11 | 95.12 | 3.99 | 92.44 | 3.12 | |||
| 9月10日 | 95 | 97.73 | 7.87 | 100.00 | 8.52 | 100.00 | 22.30 | 97.50 | 9.28 | |||
| 9月10日 | 90 | 97.73 | 4.85 | 100.00 | 4.97 | 100.00 | 8.92 | 96.14 | 5.47 | |||
| 9月10日 | 85 | 95.45 | 3.36 | 93.18 | 3.64 | 95.45 | 8.46 | 95.68 | 3.64 | |||
| 9月10日 | 80 | 90.91 | 2.67 | 88.64 | 2.77 | 95.45 | 5.37 | 92.56 | 2.91 | |||
方法I和方法II在各种情况下的对比结果显示,两种方法得到的预测区间PICP较为接近,但加权欧氏距离指标与普通欧氏距离指标相比,采用前者选择出的ELM训练集可获得更窄的PINAW,即可有效提高光伏功率区间预测的准确度.这是因为权重的设置充分考虑不同气象因素与光伏功率之间的相关性大小,选择出的ELM训练集与待预测样本相似程度更高.
从方法I和方法 III 的对比可得出,两者的PICP均能满足置信水平要求,某些情况下方法III结果的PICP甚至略优于方法I.但从准确度角度来看,方法 I 结果的PINAW在不同情况下均明显小于方法 III.此对比结果说明,ELM训练集筛选可以大大提高预测准确度.
从表4数据中可以看出,在可信度与准确度两方面,方法 I 得到的预测区间评估指标在各个情况下均优于方法 IV 结果相应指标的期望值,说明ELM隐藏层输入权重与偏置的寻优可以降低随机生成参数给预测结果带来的不稳定性,有效提高预测区间的可信度与准确度.
5 结论
光伏功率区间预测相较于点预测而言,可以提供更加丰富的信息.所提考虑ELM模型优化的光伏功率区间预测技术可对光伏出力区间进行高可信度和准确度的预测.
(1) 加权欧氏距离指标充分考虑光伏功率与气象因素的相关性,在数量庞大的历史数据中筛选出和待预测样本气象因素有较高相似度的样本,减少ELM训练时间的同时,可大大提高准确度.
(2) 采用ESGA优化ELM隐藏层输入权重与偏置参数,消除ELM参数生成的随机性给预测结果带来的不确定影响,提高光伏功率区间预测准确性,使得预测模型性能更加稳定.
参考文献
考虑概率电压不平衡度越限风险的共享储能优化运行方法
[J].
DOI:10.16183/j.cnki.jsjtu.2021.455
[本文引用: 1]

可再生能源单相分布式接入和发电不确定性提高了配电网的电压不平衡越限风险,随着可再生能源发电渗透率的不断提高,研究如何降低间歇性可再生能源发电对配电网电压不平衡越限风险的影响具有重要意义.提出了基于全局灵敏度分析(GSA)的共享储能配置策略与优化运行方法.首先,构建了基于反向传播神经网络的配电网概率电压不平衡度计算模型,定义了配电网概率电压不平衡度越限风险指标,快速、准确量化可再生能源发电不确定性对配电网概率电压不平衡度越限风险的影响.然后,提出了基于Wasserstein距离的GSA方法,辨识影响配电网电压不平衡度的关键可再生能源机组.最后,提出了基于GSA的共享储能配置策略与基于滚动预测优化的共享储能优化运行方法.通过IEEE 123节点配电网的仿真计算,验证了所提方法的有效性.
A shared energy storage optimal operation method considering the risk of probabilistic voltage unbalance factor limit violation
[J].
大规模光伏发电对电力系统影响综述
[J].
A review on the effect of large-scale PV generation on power systems
[J].
光伏发电出力预测技术研究综述
[J].
Review of photovoltaic power output prediction technology
[J].
An ARMAX model for forecasting the power output of a grid connected photovoltaic system
[J].DOI:10.1016/j.renene.2013.11.067 URL [本文引用: 1]
基于多维时间序列局部支持向量回归的微网光伏发电预测
[J].
Photovoltaic generation forecast based on multidimensional time-series and local support vector regression in microgrids
[J].
Multi-site solar power forecasting using gradient boosted regression trees
[J].DOI:10.1016/j.solener.2017.04.066 URL [本文引用: 1]
Enhanced support vector regression based forecast engine to predict solar power output
[J].DOI:10.1016/j.renene.2018.04.067 URL [本文引用: 1]
A comparative study on short-term PV power forecasting using decomposition based optimized extreme learning machine algorithm
[J].
频域分解和深度学习算法在短期负荷及光伏功率预测中的应用
[J].
Application of frequency domain decomposition and deep learning algorithm in short-term load and photovoltaic power prediction
[J].
基于互信息理论与递归神经网络的短期风速预测模型
[J].
DOI:10.16183/j.cnki.jsjtu.2020.433
[本文引用: 1]
风速的波动性和随机性为风电并网造成安全隐患,提高风速预测精度对于风电系统的稳定和风能发展十分重要.提出一种基于互信息(MI)理论和递归神经网络(RNN)的短期风速预测组合新模型(MI-RNN).该模型利用MI理论选择最优的历史风速序列长度(τ),通过每τ步预测下一时间点风速的方式,将历史风速数据输入RNN中进行模型训练,并由训练后的RNN模型输出最终的风速预测结果.将MI-RNN模型应用于风电场的风速数据集中,与传统机器学习风速预测模型进行比较,以验证模型的预测精度.结果显示,MI-RNN模型的预测精度更高,预测稳定性更强,并且能够准确预测未来风向,有望应用于含空间维度的风电场的风速预测.
Short-term wind speed forecasting model based on mutual information and recursive neural network
[J].
Prediction intervals to account for uncertainties in travel time prediction
[J].DOI:10.1109/TITS.2011.2106209 URL [本文引用: 1]
Comprehensive review of neural network-based prediction intervals and new advances
[J].
DOI:10.1109/TNN.2011.2162110
PMID:21803683
[本文引用: 1]
This paper evaluates the four leading techniques proposed in the literature for construction of prediction intervals (PIs) for neural network point forecasts. The delta, Bayesian, bootstrap, and mean-variance estimation (MVE) methods are reviewed and their performance for generating high-quality PIs is compared. PI-based measures are proposed and applied for the objective and quantitative assessment of each method's performance. A selection of 12 synthetic and real-world case studies is used to examine each method's performance for PI construction. The comparison is performed on the basis of the quality of generated PIs, the repeatability of the results, the computational requirements and the PIs variability with regard to the data uncertainty. The obtained results in this paper indicate that: 1) the delta and Bayesian methods are the best in terms of quality and repeatability, and 2) the MVE and bootstrap methods are the best in terms of low computational load and the width variability of PIs. This paper also introduces the concept of combinations of PIs, and proposes a new method for generating combined PIs using the traditional PIs. Genetic algorithm is applied for adjusting the combiner parameters through minimization of a PI-based cost function subject to two sets of restrictions. It is shown that the quality of PIs produced by the combiners is dramatically better than the quality of PIs obtained from each individual method.
基于动态贝叶斯网络的光伏发电短期概率预测
[J].
Short-term photovoltaic output forecast based on dynamic Bayesian network theory
[J].
Bayesian rules and stochastic models for high accuracy prediction of solar radiation
[J].DOI:10.1016/j.apenergy.2013.09.051 URL [本文引用: 1]
Constructing optimal prediction intervals by using neural networks and bootstrap method
[J].
Probabilistic forecasting of wind power generation using extreme learning machine
[J].DOI:10.1109/TPWRS.2013.2287871 URL [本文引用: 1]
Lower upper bound estimation method for construction of neural network-based prediction intervals
[J].
DOI:10.1109/TNN.2010.2096824
PMID:21189235
[本文引用: 3]
Prediction intervals (PIs) have been proposed in the literature to provide more information by quantifying the level of uncertainty associated to the point forecasts. Traditional methods for construction of neural network (NN) based PIs suffer from restrictive assumptions about data distribution and massive computational loads. In this paper, we propose a new, fast, yet reliable method for the construction of PIs for NN predictions. The proposed lower upper bound estimation (LUBE) method constructs an NN with two outputs for estimating the prediction interval bounds. NN training is achieved through the minimization of a proposed PI-based objective function, which covers both interval width and coverage probability. The method does not require any information about the upper and lower bounds of PIs for training the NN. The simulated annealing method is applied for minimization of the cost function and adjustment of NN parameters. The demonstrated results for 10 benchmark regression case studies clearly show the LUBE method to be capable of generating high-quality PIs in a short time. Also, the quantitative comparison with three traditional techniques for prediction interval construction reveals that the LUBE method is simpler, faster, and more reliable.
考虑风电-光伏功率相关性的因子分析-极限学习机聚合方法
[J].
Factor analysis-extreme learning machine aggregation method considering correlation of wind power and photovoltaic power
[J].
Probabilistic forecasting of photovoltaic generation: An efficient statistical approach
[J].DOI:10.1109/TPWRS.2016.2608740 URL [本文引用: 1]
A novel wavelet-based ensemble method for short-term load forecasting with hybrid neural networks and feature selection
[J].DOI:10.1109/TPWRS.2015.2438322 URL [本文引用: 1]
基于粒子群优化的核极限学习机模型的风电功率区间预测方法
[J].
Prediction intervals forecasts of wind power based on PSO-KELM
[J].
Extreme learning machine: A new learning scheme of feedforward neural networks
[C]//
Extreme learning machine: Theory and applications
[J].DOI:10.1016/j.neucom.2005.12.126 URL [本文引用: 1]
应用改进马尔科夫链的光伏出力时间序列模拟
[J].
Time series simulation of photovoltaic output using improved Markov chain
[J].
超短期光伏出力区间预测算法及其应用
[J].
Interval prediction algorithm for ultra-short-term photovoltaic output and its application
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}