

近年来,上海城市轨道交通建设迅猛发展,运营里程和客运量均位居全国榜首,截至2022年9月底,上海地铁运营线路条数共计20条,运营里程达 825 km,客运量超过2.7亿人次.随着上海地铁运营里程的不断增长,地铁隧道的长期养护工作开始受到广泛关注.上海地铁大部分线路为地下盾构隧道,面临着结构老化及外界复杂环境的不利影响,随着服役时间的增加,其结构表面将不可避免地出现裂缝、渗漏水、剥落等表观病害.若不及时检测到这些病害,其严重程度会逐渐加剧,将严重威胁地铁的运营安全,因此有必要对地铁盾构隧道表观病害检测方法进行广泛研究.
目前,常用的地铁盾构隧道表观病害检测方法是人工巡检,该方法结果主观,无法在短时间内获得隧道整体健康状态,导致实际决策可靠性低.基于深度学习的检测方法已经被广泛研究,然而当前深度学习在土木工程领域的研究主要针对单一裂缝病害检测,同时应用场景主要为桥梁、路面、建筑等混凝土结构,对地铁盾构隧道应用场景的多病害识别检测研究较少.Ni等[1]提出了一种基于卷积神经网络的框架,该框架通过多尺度融合,在照相机采集的800张裂缝图像数据集上实现了混凝土结构裂缝像素级分类自动检测任务.Yang等[2]实现了一种名为完全卷积网络(FCN)的新型深度学习技术,通过800张从网上和实际拍摄得到的图片,将路面和建筑的裂缝检测提高到像素级.Liang[3]基于FCN的变体在解码器中加入上采样层的参考索引,用于分割人工采集的436张局部桥梁损伤小型数据集,实现了局部损伤定位层次的桥梁性能智能评估.Liu等[4]基于扩展的FCN以及深度监督网络提出一种DeepCrack的深层卷积神经网络(CNN),构建了一个537张人工标注的裂缝图像数据集(包括路面、桥梁和建筑结构),该方法在其数据集上实现了先进的性能.刘凡等[5]提出一种加入并行注意力机制的 UNet 方法即PA-UNet用于裂缝检测,解决了裂缝图像中的干扰因素而造成的检测偏差,从而获得了更具融合性的裂缝特征.虽然以上研究都体现了深度学习方法在土木工程结构病害自动检测方面的优势,但只是针对单一病害类型的小型数据集,尚未对多病害进行全面有效的检测.
然而,真实的隧道结构往往伴随多种病害,目前,一些学者也进行了多病害检测的研究.Zhou等[6]对YOLOv4算法进行改进,实现了用适当大小的矩形框架确定病害位置,有效提升了公路隧道多种表观病害的识别精度和效率.Cha等[7]使用基于区域的CNN方法进行结构缺陷自动检测,提出了一种改进的Faster RCNN架构,并在自主创建的包括混凝土裂缝等5种类型病害的图片数据集上实现了较好的检测精度,但无法实现像素级识别.Xue等[8]提出了基于区域FCN的分类框架对自行拍摄的隧道内部图像进行分类,结果显示,文中提出的模型性能表现较好,能够精准识别隧道衬砌渗漏、裂缝等病害类型,但同样无法实现像素级分类.饶勇成等[9]提出一种Res-Unet网络,实现了房屋、桥梁等混凝土结构像素级的病害检测,对于混凝土裂缝、泛碱、剥落、露筋、空洞等病害有较好的检测效果.这些模型可以实现混凝土结构多病害检测,但仍然存在着无法实现像素级识别或者病害像素检测精度不高,边缘特征丢失和鲁棒性较差等问题.
因此,本文提出一种结合改进的ResNet残差网络以及U-Net++网络的多病害语义分割模型 SU-ResNet++,采集并构建了地铁盾构隧道表观多病害语义分割数据集,通过数据集对模型进行训练、验证和测试,实现了一个泛化能力强且识别精度高的地铁盾构隧道表观多病害自动识别检测方法.
1 SU-ResNet++语义分割模型
1.1 SU-ResNet++网络模型
本文提出了一种改进的SU-ResNet++网络,其结构如图1所示,它基于U-Net++模型[10]编码器-解码器架构,使用深度监督学习并嵌套不同深度的U-Net网络模型,与原始U-Net++网络相比,本文所提改进U-Net++网络具有两个重要的结构特征.首先,将经过迁移学习预训练的SE-ResNet50卷积单元作为主干网络(Backbone),即用其替换原U-Net++编码器中的卷积块,以提升对地铁盾构隧道表观多病害分割任务的识别效果.其次,改进SU-ResNet++网络继承U-Net++网络通过重新设计的跳跃连接(skip connection)方式,以聚合不同尺度的抽象语义信息,同时也可传递下采样过程中的丢失信息,保证复杂目标检测的准确性,并在最终分割中保留低级特征,使得网络的分割精度更高.其中跳跃路径的形式是: xi,j 表示节点 Xi,j的输出,i 沿编码器索引下采样层,j 沿跳跃路径索引密集块的卷积层.特征图xi,j可通过以下数学公式计算:
式中:H{·}表示卷积函数;D(·) 和U(·)分别表示下采样和上采样操作;[]表示级联层.以顶层的跳跃路径为例,其中解码器块 X0,4是由 X0,0,X0,1,X0,2,X0,3和通过上采样操作的X1,3级联而成,故重新设计的跳跃路径在解码器处实现了平滑的特征融合,集成了低、中、高级特征,提高了多尺度目标分割精度.
图1
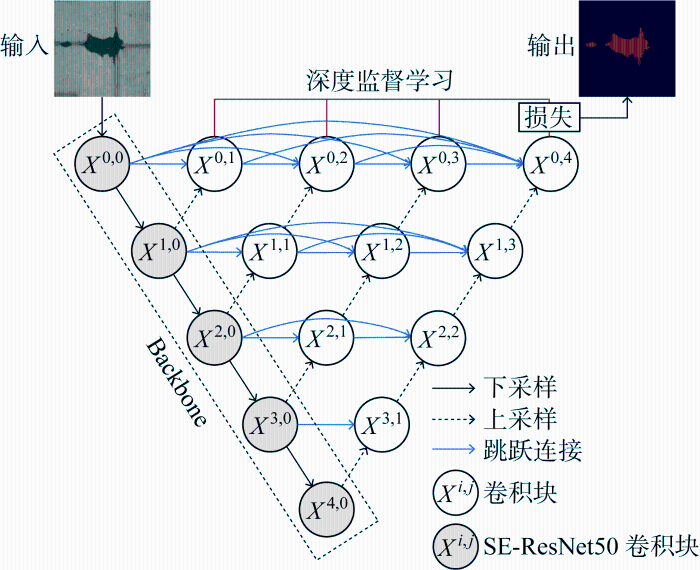
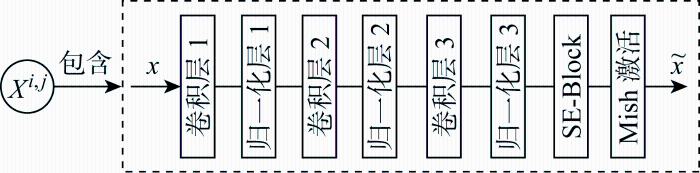
因此,改进SU-ResNet++集成了 U-Net++、ResNet残差模块和压缩激励(SE)注意力机制三者优点,具有以下3个优势:① U-Net++弥合了编码器和解码器特征映射之间的语义差异;② ResNet残差模块保留了完整的浅层特征并解决了深层网络带来的精确度退化问题;③ SE-block模块可以更好地提取语义特征,从而提高网络的准确性.另外,本文的语义分割模型采用编码器-解码器深度学习框架.其中,编码器通过卷积提取输入图像的语义信息,将输入转化为特征图;解码器通过上采样/反卷积恢复图像细节和维度,实现像素级别语义分割的输出.编码器及解码器的具体设计如下所述.
1.2 SE-ResNet50 预编码器设计
本文编码器采用ResNet深度残差网络[11],残差网络层数选用50层,并将SE通道注意力机制即SE-block模块[12](squeeze-and-excitation block)嵌入到ResNet50残差模块中,形成SE-ResNet50编码器结构,如图2 所示.图中:h为特征图的高度;w为特征图的宽度;c为特征图的通道数;r为降维系数.其中,SE-block模块先沿通道做全局池化(global pooling)作为压缩(squeeze)操作,得到一维向量;紧接着进行激发(excitation)操作对一维向量进行两次全连接(fully connected,FC),每一次都跟着激活函数,最后与原输入通道对应相乘,完成缩放(reweight).SE通道注意力机制通过显式地建模网络特征通道之间的相互依赖关系,使网络更加精准地识别和利用有用的信息,同时也可以有效地抑制不必要的信息,从而提升网络的整体性能.
图2

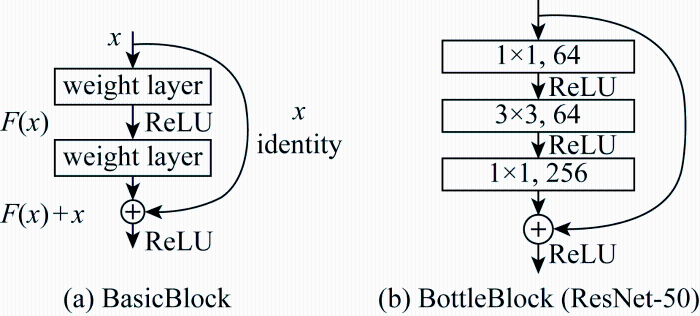
此外,本文采用基于迁移学习的训练策略[13],SE-ResNet50编码器选用经ImageNet数据集[14]预训练得到的初始化模型权重,以提升模型训练全新数据集的学习效率.深度神经网络层数越深,提取特征的等级就越高,并且可以很好地将低、中、高层次的特征以端到端的形式整合起来.由于实际工程中需要考虑计算效率以节省成本,50层的ResNet结构即可达到很好的工程检测需求,无需再加深网络结构,所以选择ResNet50网络.ResNet 残差模块如图3所示.其中,ResNet 网络的常规残差模块(BasicBlock)结构如图3(a)所示,其输入为x,在非线性层通过优化理想映射H(x)与x之间的残差F(x),输出最佳模型F(x)+x.假设H(x)为所需的底层映射,那么待学习的H(x)就转化为更容易学习的F(x),降低了网络的优化难度,解决了退化问题.针对50层及以上的深层网络结构,ResNet50使用如图3(b)所示的瓶颈残差模块(BottleBlock),该模块通过两个 1×1 卷积实现对特征图通道的降维和恢复操作,中间的3×3 卷积实现特征提取,以达到节省算力的目的.
图3
1.3 解码器设计
图4
2 精细化语义分割数据集构建
2.1 隧道图像采集
为了支持SU-ResNet++分割算法在包含表观多病害目标地铁盾构隧道场景中的应用,以上海地铁隧道为研究对象,分别采集三类典型的隧道表观病害图片,包括裂缝、剥落和渗漏水.检测车搭载 Canon 照相机(Canon DIGITAL IXUS 100 IS)作为图片采集设备,具体参数为:曝光时间 1/60 s;光圈值5.06 EV(f/5.8);ISO速度等级400;焦距 17.9 mm.本文共采集1 765张分辨率为4 000 像素×3 000 像素的原始图片,能够体现地铁盾构隧道在服役期间不同干扰下的真实病害环境.
2.2 数据预处理
基于所采集的原始图像,设计数据预处理及人工标注标准化流程,详细描述如下.
(1) 数据筛选:对采集后的原始数据,从数据集应用角度对数据进行重新筛选,以确保其中没有缺失值、噪声或重复数据.人工剔除无学习价值图像,以避免无效标注以及人力成本浪费.
(2) 人工标注:在深度学习模型的训练过程中,人工标注的图像标签质量的好坏与否是一个重要因素,它决定了模型从图像中提取出病害特征的效果.采用Labelme软件进行病害数据集精细化语义标注,并按照沿着目标外轮廓尽可能多的点线平滑包围目标病害并最大程度地减少像素标注误差的标注准则.
(3) 数据剪裁:将原始图片裁剪成605 像素×605 像素子图像,对图像尺寸进行均一化,以减少计算成本.数据裁剪在人工标注过程之后实施,目的是尽可能确保标注的精度.
(4) 图片扩增:为确保图像样本充足,防止产生过拟合,对图像执行镜像、旋转、高斯模糊和噪声等操作,实现数据扩增为原来的7倍,图像数量达到 12 355 张.数据增强效果以裂缝图像为例,如图5所示.
图5

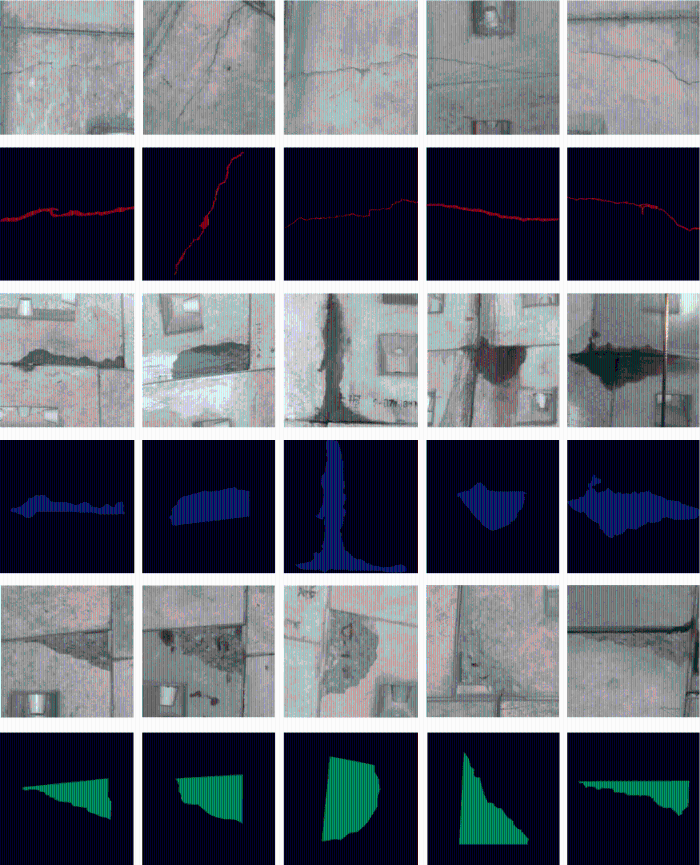
综上,本文所构建的数据样本及其标注示例如图6所示,其中红色标注裂缝,蓝色标注渗漏水,绿色标注剥落.为了评估模型的泛化能力,确保每类病害样本数据量均衡,每个病害类别选取1 500张有代表性的病害图像,共计4 500张图像,其中80%作为训练和验证集(训练集和验证集的比例为9∶1),20%作为测试集.
图6
3 实验与结果分析
3.1 实验环境和训练参数
本文所有实验在配置有图形处理器(GPU)的工作站上执行(CPU为AMD® Ryzen9 5950 x 16-core processor× 32@3.4 GHz, GPU为iGame GeForce RTX3090 24 GB),实验的深度学习框架在基于Linux系统中的 Pytorch 下执行.
本文深度学习模型初始参数使用经过预训练的 SE-ResNet50 进行初始化,以4幅图像的批量大小、0.9的动量和 0.000 5 的权重衰减训练300次迭代(300个epoch).使用Adam优化器进行参数更新,初始学习率为1×10-4,学习率下降时模拟cos函数下降,以初始学习率为最大学习率,最小学习率为最大学习率的1%.在模型训练过程中,每50次迭代记录平均损失,以平滑损失输出,并且每20次迭代验证并保存训练模型权重.
3.2 损失函数和评估指标
本文网络优化采用交叉熵损失函数,其计算公式如下:
式中:M表示类别的数量;yic表示符号函数,如果样本i的真实类别为c取1,否则取0;Pic 表示样本i属于类别c的预测概率.
当前评估像素级标注法在任务上的表现常用的语义分割指标是平均精确度(mean precision, MPrecision)、平均召回率(mean recall, MRecall)和平均交并比(mean intersection over union, MIoU), 其值越高代表模型的语义分割效果越好.本文采用MPrecision、MRecall和MIoU评价指标验证模型效果.定义k+1为预测类别的个数;puv 为类别u预测属于类别v的像素数量,即puu表示真正例,pvv表示真负例,而puv和pvu 分别表示假正例和假负例.
精确度(precision)是指被准确分类为正类的样本数与所有被分类为正类的样本数之比,意味着预测结果是正类的样本里具体有多少个样本真的是正类.平均精确度(MPrecision,P)是对每一类别精确度求和平均的结果.其计算公式如下:
召回率(recall)是指分类器在测试数据集中能够正确召回多少原本应该被分类为正类的样本.平均召回率(MRecall,R)是对每一类召回率求和平均的结果.其计算公式如下:
交并比(intersection over union, IoU)是指目标像素的真实值与预测值的交集与并集之比,一个类别像素预测结果的交并比越大,则说明预测的边界与真实边界越接近.平均交并比(MIoU,I)就是分别计算每个类别的IoU,然后再对所有类别IoU求均值.其计算公式如下:
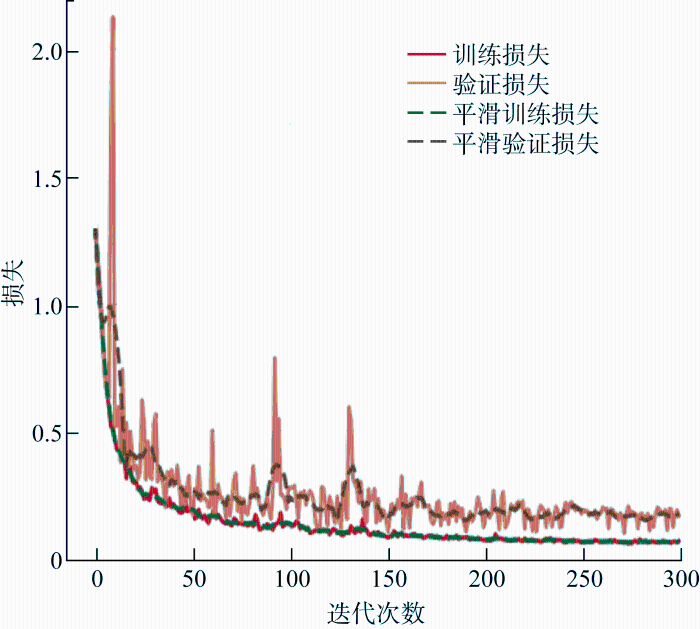
图7为本文所提出模型的训练和验证损失,可以看到训练损失在前50次迭代过程中迅速减小,之后的迭代过程中逐渐平稳,最终在0.1附近收敛.进行定量分析,本文模型经过训练实现了高精度的评价指标,最终在测试集上的P达到了95.72%,R达到了85.86%,I达到了81.34%.
图7
进行定性分析,测试集表观病害预测结果示例如图8所示,可见本文模型预测病害图像素连续且边缘平滑度高,相较于人工标签图达到了更精细的识别效果.
图8

3.3 结果与分析
(1) 消融实验.为了验证本文方法的有效性,进行消融实验,将本文构建的数据库用于分别训练U-Net++ 和ResNet50模型.实验测试集评估指标结果如表1所示,可见所提出的SU-ResNet++模型与ResNet50和U-Net++相比较,模型精确度分别提高了7.34百分点和3.46百分点.消融实验结果表明,集成U-Net++、ResNet残差模块和SE注意力机制的SU-ResNet++模型的评估指标大大提高.
表1 消融实验评价指标
Tab.1
| 模型 | P/% | R/% | I/% |
|---|---|---|---|
| U-Net++ | 92.26 | 81.92 | 80.86 |
| ResNet50 | 88.38 | 78.64 | 72.19 |
| SU-ResNet++ | 95.72 | 85.86 | 81.34 |
实验测试集评估指标结果如表2所示,可以看到本文方法展现出了比其他网络更好的性能.因此,本文改进的SU-ResNet++方法在地铁盾构隧道表观多病害检测问题中表现出更好的分割效果.
表2 对比实验评价指标
Tab.2
| 模型 | P/% | R/% | I/% |
|---|---|---|---|
| U-Net | 90.12 | 79.86 | 72.98 |
| VGG19 | 87.72 | 78.88 | 70.05 |
| AlexNet | 85.59 | 75.50 | 66.63 |
| SU-ResNet++ | 95.72 | 85.86 | 81.34 |
3.4 工程应用
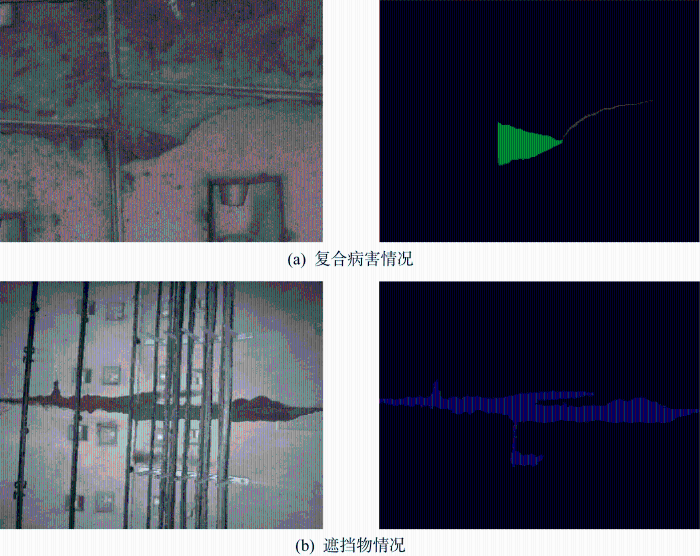
将所提出的算法进行实际工程病害检测,验证方法在新的识别任务中的效果.将在某地铁盾构隧道区间内采集到的两张典型表观病害图像输入算法进行预测,其中包括渗漏水、裂缝和剥落3种病害,得到的预测结果如图9所示.其中,图9(a)为剥落和裂缝两种病害复合的情况,图9(b)为有管线遮挡的渗漏水病害情况,可见本文方法对全新数据的病害图像也可以较为完整地识别,能达到工程需要的复杂背景下的高精度像素级病害识别需求,也证明了所提出的盾构隧道多病害检测方法有良好的泛化能力.需要注意的是,在实际应用中模型的性能和精度可能会受到各种因素的影响,如图像质量、模型训练数据集的质量和应用场景等,因此需要根据实际情况对模型和数据库不断进行调整和优化,以提高其识别准确率.总体而言,在应用过程中本文方法可以较好地完成隧道表观裂缝、剥落、渗漏水病害的无接触式识别,这表明该方法具有较高的可靠性和实用性,可以应用于实际工程病害检测任务.
图9
4 结论
本文提出了一种基于深度学习的地铁盾构隧道表观多病害自动检测方法,用于检测盾构隧道裂缝、剥落和渗漏水3种病害类型,主要结论如下:
(1) 提出的盾构隧道表观多病害分割改进方法SU-ResNet++基于U-Net++编码器-解码器结构.其中,编码器采用经迁移学习预训练的 SE-ResNet50 替换,解码器加入SE注意力机制并采用Mish 激活函数.
(2) 构建的精细化隧道表观多病害语义分割数据集,解决了盾构隧道多病害识别算法训练的样本稀缺问题,将模型与常用的语义分割方法在数据集上进行消融实验和对比实验,结果表明所提方法得到了更高的评价指标.
(3) 本文方法在实际工程检测应用中实现了复杂背景下良好的病害检测效果,证明了数据集的有效性和模型的泛化能力,提高了病害检测的效率,解决了传统人工巡检方法的不足,具有实际工程应用价值.
参考文献
Pixel level crack delineation in images with convolutional feature fusion
[J].
Automatic pixel-level crack detection and measurement using fully convolutional network
[J].
Image-based post-disaster inspection of reinforced concrete bridge systems using deep learning with Bayesian optimization
[J].
DeepCrack: A deep hierarchical feature learning architecture for crack segmentation
[J].
基于并行注意力UNet的裂缝检测方法
[J].
Crack detection method based on parallel attention UNet
[J].
Automatic detection method of tunnel lining multi-defects via an enhanced You Only Look Once network
[J].
Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types
[J].
A fast detection method via region-based fully convolutional neural networks for shield tunnel lining defects
[J].
基于深度学习的混凝土结构多病害检测
[J].
Multiple disease detection of concrete structures based on deep learning
[J].
UNet++: A nested U-Net architecture for medical image segmentation
[C]
Deep residual learning for image recognition
[C]
Squeeze-and-Excitation Networks
[J].
DOI:10.1109/TPAMI.2019.2913372
PMID:31034408
[本文引用: 1]

The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the "Squeeze-and-Excitation" (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251 percent, surpassing the winning entry of 2016 by a relative improvement of ∼ 25 percent. Models and code are available at https://github.com/hujie-frank/SENet.
How transferable are features in deep neural networks
[C]
ImageNet:A largescale hierarchical image database
[C]
Study on the evaluation method of sound phase cloud maps based on an improved YOLOv4 algorithm
[J].
U-Net: Convolutional networks for biomedical image segmentation
[DB/OL]. (
Very deep convolutional networks for large-scale image recognition
[DB/OL]. (
ImageNet classification with deep convolutional neural networks
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}