雨、雪等恶劣天气下采集的图片会发生严重退化,进而影响后续的语义分割、目标检测等[1 -2 ] 计算机视觉算法的表现.现有多数基于深度学习的算法仅能去除单一天气,对于不同的退化无法直接迁移扩展.因此,多天气退化图像恢复凭借其仅需一次训练便可同时去除多种天气退化的优势而逐渐受到关注.例如,Li等[3 ] 利用多天气编码器和单输出解码器的结构首次提出多天气退化图像恢复网络All-in-One.Valanarasu等[4 ] 将任务查询向量引入视觉Transformer (Vision Transformer, ViT) 模型来得到干净背景图像.
图像生成模型具有强大的表征能力和丰富的解空间,自出现起便在图像生成领域表现出显著优势,如生成对抗网络 (generative adversarial network, GAN)[5 ] 、变分自编码器 (variational auto-encoder, VAE)[6 ] .其中,GAN利用对抗训练来提高视觉保真度,但存在训练不稳定、模式崩溃和图像伪影等问题;VAE通过最大化证据下界来优化数据的对数似然性,但平衡问题和变量崩溃现象限制其实际生成表现.近年来,去噪扩散概率模型 (denoising diffusion probability model, DDPM)[7 ] 在多个下游计算机视觉任务上表现出巨大优势.DDPM的主要原理为先连续添加高斯噪声来破坏原始数据,再进行反向采样来恢复图像.基于此,提出一种用于多天气退化图像恢复的自注意力扩散模型 (Transformer-based diffusion model for All-in-One weather-degraded image restoration, AWIR-TDM),以退化图像作为条件来引导反向采样.
目前,基于DDPM的计算机视觉算法[7 -8 ] 在噪声估计网络部分均采用类似U-Net的卷积网络结构.然而,Peebles等[9 ] 的工作表明,采用ViT的类条件扩散模型可以取得相比于常用U-Net架构更好的图像生成表现.但是,ViT中自注意力 (self-attention, SA) 的计算负担与输入特征分辨率呈平方关系,无法直接应用于高分辨率的多天气图像恢复任务.对此,Wang等[10 ] 基于Swin Transformer提出用于多种图像恢复任务的统一型图像恢复算法Uformer,在分割的窗口中分别计算自注意力来减少计算负担;Zamir等[11 ] 利用转置自注意力 (transposed self-attention, TSA) 强化特征学习,即将原自注意力的表征从空间维度转移到通道维度,在去雨、去噪等任务上取得良好表现.然而,以上方法未依据自注意力的内积特点来进一步优化自注意力的表征,导致其训练和推理均需要大量时间.于DDPM而言,本身训练和采样均需要大量时间,如果在噪声估计网络部分直接使用计算负担巨大的ViT会加剧对硬件环境的要求.同时,文献[12 ]中表明自注意力和TSA具有接近的表现.因此,提出一种次空间转置自注意力噪声估计网络 (subspace transposed Transformer for noise estimation, NE-STT). NE-STT先将输入特征映射到次空间,再利用TSA构成次空间转置自注意力 (subspace transposed self-attention, STSA) 来强化特征学习并显著减少计算负担.同时,STSA不需要将输入特征分割为多个不重叠的窗口,而是直接从输入特征得到分辨率水平较低的查询向量Q 和键向量K 来进一步计算自注意力,相比Swin Transformer分割窗口更符合自注意力机制提取特征全局信息的初衷.同时,文献[11 ]和文献[13 ]中的工作表明,门控机制能够有效提高ViT中前馈网络 (feed-forward network, FFN) 的非线性表征能力从而提升视觉自注意力网络ViT的整体表现.基于此,提出双分组门控前馈网络 (dual grouped gated feed-forward network, DGGFFN),其在ViT中前馈网络FFN的深度可分离卷积后采用双分组门控机制来提高非线性表征能力.
综上所述,本文提出一种用于多种天气退化图像恢复的自注意力扩散模型AWIR-TDM,是去噪扩散概率模型DDPM和视觉自注意力网络ViT在多天气退化图像恢复任务上的有效探索.另外,提出NE-STT,其包括次空间转置自注意力STSA和双分组门控前馈网络DGGFFN.NE-STT一方面在次空间计算自注意力来减少计算负担,另一方面采用双分组门控机制来提高前馈网络的非线性表征能力,从而令噪声估计网络NE-STT估计出更加准确的噪声分布.相比常见的天气退化图像恢复算法,AWIR-TDM针对当前关注较少的多天气退化图像恢复任务,更加具有实际应用前景,并在去雪、去雨雾和去雨滴3个天气退化去除任务上取得超越现有算法的表现.
1 天气退化图像恢复
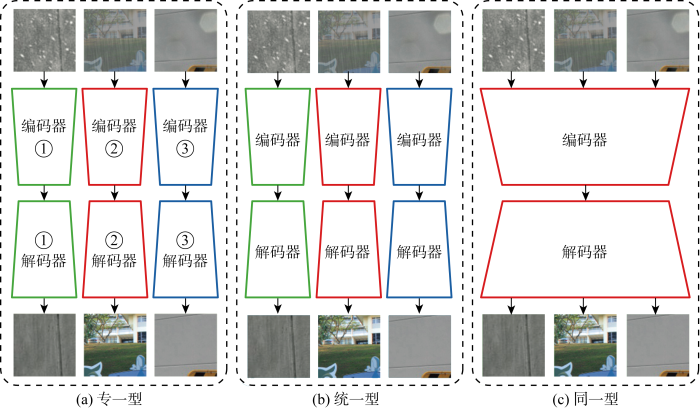
如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同.
图1
图1
不同天气退化图像恢复网络架构示意图
Fig.1
Diagram of different network architectures for weather-degraded image restoration
2 本文方法
2.1 去噪扩散概率模型
去噪扩散概率模型DDPM包括前向扩散过程和反向采样过程.前向扩散过程被定义为马尔可夫链,在连续的节点不断加入高斯噪声来获得有噪声的样本,进而逐步将高斯噪声分布转换为生成模型所训练的数据分布.具体而言,给定一个数据样本x 0 ~q (x 0 ),在多天气退化图像恢复任务中,x 0 即为无退化的干净背景,q (x 0 )为干净背景图像对应的原始分布,前向加噪过程定义为
(1) q(x1: T |x0 )= ∏ t = 1 T t |xt -1 )
式中:xt 为t 时刻的加噪数据;T 为加噪次数,t ∈{0,1,…,T }. 先验分布q (xt |xt -1 )的数学形式为
(2) q(xt |xt -1 )=N(xt ; 1 - β t t , β t I)
式中:N 为高斯分布;I 为单位矩阵;βt 为噪声调节因子,其在前向扩散过程中线性地从 0. 000 1 增大到0. 02. 则状态xt 可以用xt -1 表示为
(3) xt = 1 - β t t -1 + β t t , ε t ~N(0,I)
式中:εt 为t 时刻的噪声分布. 根据马尔可夫性,进一步得到xt 与x 0 的关系为
(4) q(xt |x0 )=N(xt ; α - t 0 , (1- α - t
式中:αt =1-βt ,α - t ∏ i = 0 t αt . 也可以表示为
(5) xt = α - t 0 + 1 - α - t
式中:ε 为标准高斯分布,即在前向扩散过程中每一步添加的噪声均是标准高斯噪声.前向扩散过程的结果是得到一个近乎服从高斯分布的数据,反向采样过程即学习一个参数化的后验分布pθ (xt -1 |xt )通过xt 生成前一个状态xt -1 . 初始后验分布满足p (xT )=N (xT ; 0, I ),则反向采样过程定义为
(6) pθ (x0: T )=p(xT ) ∏ t = 1 T θ (xt -1 |xt )
(7) pθ (xt -1 |xt )=N(xt -1 ; μ θ (xt ,x0 ), σ t 2
高斯分布中参数化估计均值μθ (xt , x 0 )和方差σ t 2
(8) μ θ ( x t , t ) = 1 α t x t - β t 1 - α - t ε θ ( x t , t ) σ t 2 = 1 - α - t 1 - α - t β t
εθ (xt , t )为噪声估计网络 (noise estimation network, NE-Net) 预测所得t 时刻的噪声分布εt ,其定义为εθ (xt ,t )=ρθ (xt ,t ),ρθ 为NE-Net的参数.网络训练的目的是令t 时刻实际的噪声分布与预测的噪声分布误差最小,最终优化所得的参数可以定义为
(9) $ \begin{matrix}{l} \theta=\underset{\theta}{\operatorname{argmin}} L(\theta)= \\ \quad\left\|\boldsymbol{\varepsilon}-\rho_{\theta}\left(\sqrt{\bar{\alpha}_{t}} \boldsymbol{x}_{0}+\sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\varepsilon}, t\right)\right\|_{2}^{2} \end{matrix}$
随后,反向采样过程中t -1时刻的状态xt -1 可以用t 时刻的状态xt 表示为
(10) xt -1 = 1 α t x t - β t 1 - α - t ε θ ( x t , t ) t ε
由此利用噪声估计网络来逐步反向采样出干净的背景图像.
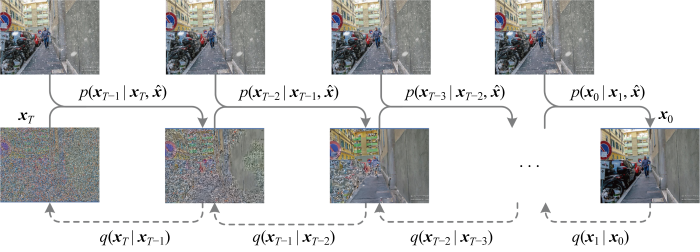
2.2 图像条件扩散模型
如图2 所示,条件扩散模型即在去噪扩散概率模型DDPM的反向采样过程中引入类别或图像来引导生成目标图像,不影响前向扩散过程.对于多天气退化图像恢复而言,将退化的图像作为条件引入采样过程,则反向采样过程变为
(11) p(x0: T | x ^ T ) ∏ t = 1 T t -1 |xt , x ^
式中:x ^ . 此时xt -1 ~pθ (xt -1 |xt , x ^ ) ,根据文献[8 ]中的条件反向采样过程为
(12) $ \begin{matrix} \boldsymbol{x}_{t-1}= & \sqrt{\bar{\alpha}_{t-1}}\left(\frac{\boldsymbol{x}_{t}-\sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\varepsilon}_{\theta}\left(\boldsymbol{x}_{t}, \hat{\boldsymbol{x}}, t\right)}{\sqrt{\bar{\alpha}_{t}}}\right)+ \\ & \sqrt{1-\bar{\alpha}_{t-1}} \boldsymbol{\varepsilon}_{\theta}\left(\boldsymbol{x}_{t}, \hat{\boldsymbol{x}}, t\right) \end{matrix}$
(13) εθ (xt , t)→εθ (xt , x ^ θ (xt , x ^
图2
图2
图像条件扩散模型的前向扩散和反向采样示意图
Fig.2
Overview of forward diffusion and reverse sampling in image conditional diffusion model
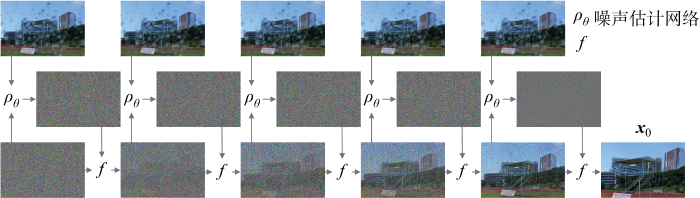
即利用引入图像条件的噪声估计网络NE-STT来逐步反向采样得到去除天气退化的图像,如图3 所示,图中f 表示式(12).采用图像条件扩散模型中常用的通道维度拼接来引入图像条件.
图3
图3
以天气退化图像为条件来引导反向采样过程的示意图
Fig.3
Diagram of reverse sampling process guided by weather-degraded image
2.3 噪声估计网络
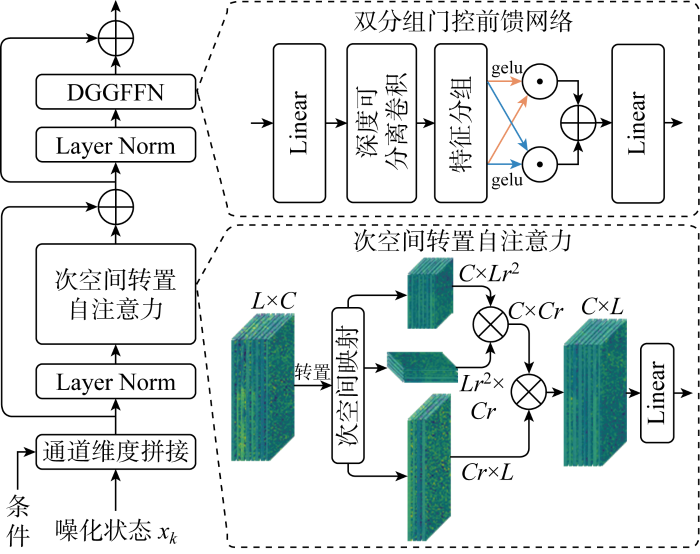
在目前基于去噪扩散概率模型DDPM的图像恢复任务中,噪声估计网络NE-Net均采用以卷积神经网络CNN为核心的U-Net架构.文献[9 ]中表明视觉自注意力网络ViT的全局特性或架构设计相比CNN在建模特征依赖上更具优势.然而,ViT中自注意力巨大的计算负担和扩散模型本身更长的反向采样时间限制了其在多天气退化图像恢复任务AIR上的实际应用.为此,提出计算负担更小且噪声估计表现更好的NE-STT,如图4 所示.
图4
图4
NE-STT示意图
Fig.4
Overview of NE-STT
图中:Layer Norm为层归一化操作;gelu为激活函数;C 、L 分别为输入特征的维数和长度;r 为次空间变换系数;Linear为线性层.
认为Swin Transformer这种分割窗口的操作提取的是局部的全局性信息,而非全局的全局性信息.因此,所提噪声估计网络NE-STT利用次空间变换系数将输入特征映射到特征次空间,再在次空间特征上表征自注意力.同时,为避免Swin Transformer由于窗口不重叠而必须不断进行窗口移位的现象,采用3个重叠卷积层对应Q 、K 和V 来分别进行次空间映射 (subspace pProjection, SP).然而,实验发现空间维度的计算负担是通道维度的数倍.因此,NE-STT仅采用转置自注意力来强化特征学习,从而进一步减少计算负担和反向采样时长.次空间转置自注意力可以公式化为
(14) $ \begin{array}{l} Q_{L \times r^{2}, c}, \boldsymbol{K}_{L \times r_{r}{ }^{2}, c \times_{r}}, \boldsymbol{V}_{L, \propto_{r}}=\operatorname{SP}\left(\boldsymbol{X}^{L \times C}\right) \\ \operatorname{STSA}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\left(\boldsymbol{Q}^{\mathrm{T}} \otimes \boldsymbol{K} / \alpha\right) \otimes \boldsymbol{V}^{\mathrm{T}} \end{array}$
表1 是不同自注意力计算方式的计算量定量对比.其中,次空间变换系数r 设为0.5,输入特征值得结构定义为 (64×64, 32),即L =64×64,C =32.如表1 所示,TSA相比标准自注意力计算方式在计算量上下降3个数量级,而所提次空间转置自注意力相比TSA在乘法计算量上下降68.77%, 在加法计算量上下降69.85%.
此外,Zamir等[11 ] 和Chen等[13 ] 的研究表明,在视觉自注意力网络ViT的前馈网络FFN中采用门控机制可以进一步提升其非线性表达能力.受其启发,提出双分组门控前馈网络DGGFFN,其在FFN中深度可分离卷积层后利用双分组门控机制来强化特征学习.具体而言,DGGFFN将深度可分离卷积所得特征按照通道维度分为两组,再对两组特征分别利用另一组特征进行门控增强,最后将所得结果相加得到门控输出.双分组门控机制可以公式化为
(15) $ \begin{array}{l} \boldsymbol{X}^{l}=\left[\boldsymbol{X}_{1}: \boldsymbol{X}_{2}\right] \\ \boldsymbol{X}^{l+1}=\boldsymbol{X}_{1} \cdot \operatorname{gelu}\left(\boldsymbol{X}_{2}\right)+\boldsymbol{X}_{2} \cdot \operatorname{gelu}\left(\boldsymbol{X}_{1}\right) \end{array}$
式中:X 1 、X 2 表示将输入特征Xl 分为两组;Xl 、Xl +1 分别为双分组门控机制的输入和输出.在估计噪声分布时,NE-STT以退化图像为条件并将其与前一次噪声状态按通道维度拼接作为输入,进而得到受退化图像条件引导的噪声分布.
3 实验与分析
3.1 实现细节
本文算法在NVIDIA Tesla A100显卡上训练,在NVIDIA RTX 3090 显卡上分析.训练迭代次数为 100 万次,每次参与训练的图像对数量为16.网络参数优化器选择Adam,其学习率设置为常数1×10-4 ,参数β 1 =0.5,β 2 =0.999.扩散步数为 2 000.在噪声估计网络NE-STT中,次空间变换系数在特征编码阶段分别为0.25、0.5、0.5、1,自注意力头的个数对应分别为1、2、4、8.
3.2 数据集设置
Allweather:根据文献[3 ]将Snow100K[14 ] 、Out-door Rain[20 ] 和Raindrop[17 ] 数据集组合而成,其包括18 069对图像用来训练多天气退化图像恢复算法.
Snow100K:来自文献[14 ],训练集包括5万对图像,测试集根据雪的大小分为Snow100K-L、Snow100K-M和Snow100K-S这3个数据集,其中分别包括16 611、16 588和16 801对图像用来评估算法的去雪性能.
Out-door Rain:雨雾共存的数据集[20 ] ,训练集包括 9 000 对图像.采用其中名为Test1的子集作为测试集,图像对的数量为750.
Raindrop:包括861对训练图像和两个图像对数量分别为58和249的测试数据集.实验采用的测试集为Raindrop-A[17 ] .
此外,为验证算法恢复自然天气退化图像的表现,选用文献[14 ]中提供的雪数据集Snow,其中包括1 329幅自然雪图,同时还选用来自文献[21 ]的雨滴数据集Raindrop、雨雾数据集RainMist和雨痕数据集RainStreak,其分别包括67、13和185幅自然天气退化图像.
3.3 算法对比
3.3.1 合成天气退化图像恢复
为了验证本文算法的有效性,实验对比本文算法AWIR-TDM 与近期表现良好的统一型图像恢复方法Uformer [10 ] 、Restormer [11 ] 和多天气退化图像恢复方法All-in-One [3 ] 、TransWeather [4 ] 在数据集Allweather 上经过一次训练后分别在雪、雨雾和雨滴测试数据集上的表现. 选取常用的有监督图像质量评价指标峰值信噪比 (peak signal noise ratio , PSNR ) 和结构相似性 (structural similarity , SSIM ) 进行定量对比. 峰值信噪比的计算公式如下:
(16) $ \begin{aligned} m_{\mathrm{PSNR}}= & \frac{1}{S} \sum_{i=1}^{S} \frac{1}{M_{i}} \sum_{j=1}^{M_{i}} 20 \times \\ & \lg \left(v_{\max } / \sqrt{g_{\mathrm{mse}}\left(\boldsymbol{X}_{i, j}, \boldsymbol{Y}_{i, j}\right)}\right) \end{aligned}$
式中:S 为测试集的个数,S =1时即代表计算单个测试集结果的指标;Mi 为第i 个测试集中图像对的数量;v max 为图像的像素值的最大值,一般取1或255;g mse (Xi , j Yi , j i 个测试集中第j 对图像Xi , j Yi , j
(17) $ \begin{array}{l} m_{\mathrm{SSIM}}=\frac{1}{S} \sum_{i=1}^{S} \\ \quad \frac{1}{M_{i}} \sum_{j=1}^{M_{i}} \frac{\left(2 \mu_{X_{i, j}} \mu_{Y_{i, j}}+C_{1}\right)\left(2 \sigma_{X_{i, j}} Y_{i, j}+C_{2}\right)}{\left(\mu_{X_{i, j}}^{2} \mu_{Y_{i, j}}^{2}+C_{1}\right)\left(\sigma_{\mathbf{X}_{i, j}}^{2} \sigma_{Y_{i, j}}^{2}+C_{2}\right)} \end{array}$
式中:μ X i , j μ Y i , j Xi , j Yi , j σ X i , j σ Y i , j Xi , j Yi , j σ X i , j Y i , j Xi , j Yi , j C 1 =(K 1 v max )2 ,C 2 =(K 2 v max )2 ,其中K 1 =0. 01, K 2 =0. 03.
不同算法的多天气图像恢复表现定量对比如表2 所示,其中数据由原文复现或源代码所得.另外,表中加粗、双下划线和单下划线数据分别对应测试集指标最高、统一型恢复方法恢复算法效果排名第二和同一型恢复算法效果排名第二;空白表示不适用,下同.由表可见,所提AWIR-TDM在图像恢复质量上均高于对比方法.具体而言,本文算法相比 Restormer 和TransWeather,在Snow100K的测试集上分别平均提升1.87和3.39 dB,在雨雾共存测试集Test1上分别提升1.98和3.18 dB,在雨滴退化数据集Raindrop-A上分别提升1.23和 2.12 dB.值得注意的是,Uformer在雨雾共存的测试集Test1上表现最差,这说明现有的统一型图像恢复算法不能简单应用到多天气退化图像恢复任务.
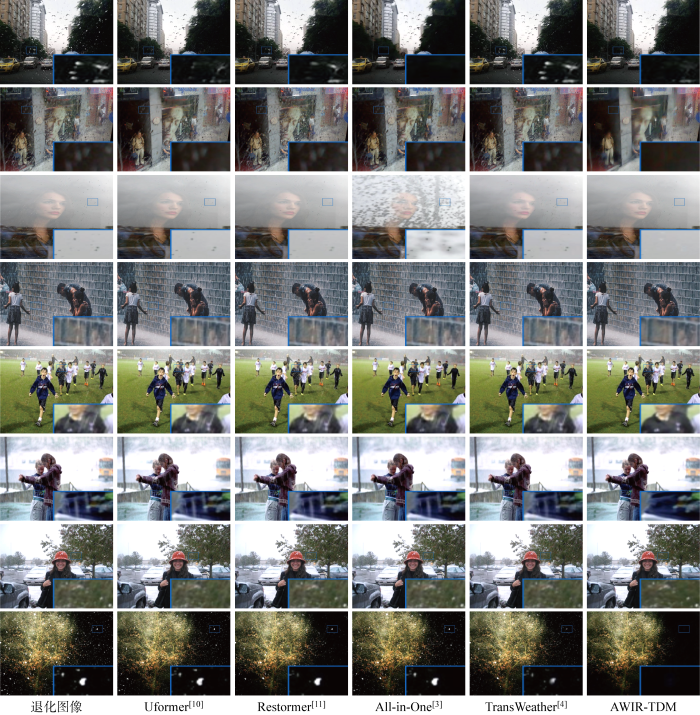
不同算法所得恢复图像的视觉对比如图5 ~7 所示,分别为退化图像经过去雨滴、去雨雾和去雪后所得的恢复图像.在图5 中,相比其他算法,AWIR-TDM方法能够有效去除较大雨滴并得到与无退化图像接近的结果.如第1行对比图像中Uformer和All-in-One未能去除雨滴,Restormer和TransWeather所得恢复图像中仍存在明显痕迹,而本文算法能够彻底去除雨滴.在图6 去雨雾视觉对比中,所有算法均能有效去除雨水痕迹,但相比本文算法,其他算法无法有效恢复图像的细节信息.如第1行对比图像中,本文算法能够得到清晰的指示牌字符,而其他算法所得字符已经无法辨认.特别地,发现Uformer处理雨雾图像时未能去除图像边缘的雨雾.在图7 第一行对比图像中,本文算法能够有效去除上衣口袋上的雪痕迹,而Uformer、All-in-One和TransWeather的结果中出现明显残留.尽管Restormer的结果中没有明显的雪痕迹,但却得不到清晰的细节纹理,而本文算法得到的纹理更接近真实背景图像.
图5
图5
不同算法在雨滴数据集Raindrop-A上的视觉对比
Fig.5
Visual comparison of different methods on Raindrop-A dataset
图6
图6
不同算法在雨雾数据集Test1上的视觉对比
Fig.6
Visual comparison of different methods on Test1 dataset
图7
图7
不同算法在雪数据集Snow100K上的视觉对比
Fig.7
Visual comparison of different methods on Snow100K dataset
此外,实验还进一步将本文算法用于统一型天气退化图像恢复任务,并分别进行对应的训练与测试,实验所得定量对比结果如表3 ~5 所示.结果表明,AWIR-TDM算法取得优于现有统一型图像恢复算法的表现.具体而言, 相比现有图像去雪算法,
本文算法在Snow100K的测试集上平均PSNR高出1.81~7.09 dB; 相比现有图像去雨雾算法,本文算法在Test1测试集上平均PSNR高出0.69~11.51 dB;相比现有去雨滴算法,本文算法在Raindrop-A测试集上平均PSNR高出0.79~4.82 dB.因此,本文算法不仅可以作为多天气退化图像恢复算法,还可以作为统一型天气退化图像恢复方法,并且在两种情况下均超越现有表现良好的方法.
3.3.2 自然天气退化图像恢复
为验证本文算法在自然天气退化图像恢复中的表现,实验选择自然度图像质量评估器 (naturalness image quality evaluator, NIQE)、空间光谱熵质量 (spatial-spectral entropy quality, SSEQ) 和神经图像评估 (neural image assessment, NIMA) 3个无监督指标来定量对比恢复图像的自然度.其中,NIQE 和 SSEQ 两指标的值越小表示图像自然度越高,NIMA 反之.表6 为对比方法与本文算法在自然天气退化图像数据集上的定量对比结果.结果表明,在4个真实天气退化图像数据集上,本文算法AWIR-TDM均取得第一或者第二的表现,其中在RainMist和RainDrop数据集上,本文算法所得恢复图像的定量指标均为最高.在Snow和RainStreak数据集上,本文算法所得恢复图像的NIQE指标和SSEQ指标分别排名第二,而其他指标均为所有对比算法中最高.
此外,不同算法所得的自然天气退化图像恢复视觉对比如图8 所示.其中,在处理第1~3幅雨滴图像时,AWIR-TDM能有效去除雨滴痕迹,同时得到更符合视觉感知特点的纹理特征.如第1行对比图像中,All-in-One所得结果中除天空部分残留的雨滴外其他雨滴被彻底去除,但树枝原有纹理被破坏,从而导致视觉效果较差.在处理第4~6幅雨图时,本文算法有效去除退化图像中的雨水痕迹,而其他算法所得结果中均存在明显的雨痕残留.如第5行对比图像中,Uformer、Restormer等算法均无法去除肩膀处的雨痕.第7、8幅退化图像为雪图,其中第7幅图中由于雪的运动出现大量雪痕,第8幅图中存在大小不一的雪花颗粒,本文算法均有效去除雪痕和雪花,而其他算法无法适应不同的雪特点.如最后一行对比图像中,All-in-One和TransWeather等算法无法同时去除多样的雪花颗粒.
图8
图8
不同算法在自然天气退化图像数据集上的视觉对比
Fig.8
Visual comparison of different methods on natural weather-degraded image dataset
3.4 消融分析
为验证所提NE-STT各组件的有效性,利用实验对其进行消融分析.实验中,以去噪扩散概率模型DDPM中采用残差块 (residual block, ResBlock) 和空间自注意力的架构作为基线网络Baseline;随后分别对比采用ViT架构、TSA、STSA、FFN、单门控前馈网络 (single gated feed-forward network, SGFFN)和DGGFFN对最终恢复效果的影响以及模型的单步噪声估计用时.扩散模型采样耗时,因此实验选择图像数量较少的测试集Raindrop-A.表7 为NE-STT各部分组件的消融实验结果.其中,单步估计用时为噪声估计网络NE-STT处理100张大小为6像素×64像素×64像素的图像输入时所需时间的平均值.
由表可见,噪声估计网络NE-STT中双分组门控前馈网络DGGFFN的使用较未加门控机制增强的噪声估计网络在单步估计用时上增加 0.011 9 s,但相比基线网络Baseline和其他网络结构耗时均明显减少.具体而言,AWIR-TDM单步估计用时分别为Baseline和ViT的61.50%和38.04%.同时,在Raindrop-A数据集上,AWIR-TDM相比Baseline和ViT在平均PSNR上分别提升3.16和 2.47 dB.STSA相比SA在平均PSNR上提升0.68 dB,相比TSA在平均PSNR上降低1.05 dB,但在单步估计用时上减少53.96%.随后,再通过DGGFFN进一步提升1.84 dB,从而相比采用TSA的ViT结构提升0.79 dB.实验表明,噪声估计网络NE-STT中包括的次空间转置自注意力机制和双分组门控前馈网络DGGFFN是有效的,并且显著减少噪声估计用时.
4 结语
针对多天气退化图像恢复任务,本文提出一种有效的算法AWIR-TDM,利用去噪扩散概率模型DDPM和视觉自注意力网络ViT来条件获取高质量的恢复图像.具体而言,AWIR-TDM利用天气退化图像来条件引导DDPM的噪声估计,逐步反向采样得到干净背景图像.在噪声估计网络NE-Net中,提出一种更加快速且噪声估计更加准确的次空间转置自注意力噪声估计网络NE-STT.其中包括次空间转置自注意力STSA和双分组门控前馈网络DGGFFN.STSA利用次空间变换系数将输入特征映射到次分辨率空间,进而再利用计算量更低的转置自注意力TSA强化特征学习,其能有效学习输入特征的全局性依赖.DGGFFN在前馈网络FFN中的深度可分离卷积后采用双分组门控机制,相比无门控或单门控FFN,其能够进一步提高前馈网络的非线性表征能力.实验表明,AWIR-TDM所得恢复图像在定量指标和视觉效果上优于现有多天气退化图像恢复算法.然而,本文算法处理退化图像时缺乏实时性.因此,未来将致力于研究如何加速用于多天气退化图像恢复的扩散模型.
参考文献
View Option
[1]
高涛 , 文渊博 , 陈婷 , 等 . 基于窗口自注意力网络的单图像去雨算法
[J]. 上海交通大学学报 2023 , 57 (5 ): 613 -623 .
DOI:10.16183/j.cnki.jsjtu.2022.032
URL
[本文引用: 1]
单图像去雨研究旨在利用退化的雨图恢复出无雨图像,而现有的基于深度学习的去雨算法未能有效地利用雨图的全局性信息,导致去雨后的图像损失部分细节和结构信息.针对此问题,提出一种基于窗口自注意力网络 (Swin Transformer) 的单图像去雨算法.该算法网络主要包括浅层特征提取模块和深度特征提取网络两部分.前者利用上下文信息聚合输入来适应雨痕分布的多样性,进而提取雨图的浅层特征.后者利用Swin Transformer捕获全局性信息和像素点间的长距离依赖关系,并结合残差卷积和密集连接强化特征学习,最后通过全局残差卷积输出去雨图像.此外,提出一种同时约束图像边缘和区域相似性的综合损失函数来进一步提高去雨图像的质量.实验表明,与目前单图像去雨表现优秀的算法MSPFN、 MPRNet相比,该算法使去雨图像的峰值信噪比提高0.19 dB和2.17 dB,结构相似性提高3.433%和1.412%,同时网络模型参数量下降84.59%和34.53%,前向传播平均耗时减少21.25%和26.67%.
GAO Tao WEN Yuanbo CHEN Ting et al A single image deraining algorithm based on Swin Transformer
[J]. Journal of Shanghai Jiao Tong University 2023 , 57 (5 ): 613 -623 .
URL
[本文引用: 1]
[2]
黄鹤 , 胡凯益 , 李战一 , 等 . 融合MCAP和GRTV正则化的无人机航拍建筑物图像去雾方法
[J]. 上海交通大学学报 2023 , 57 (3 ): 613 -623 .
[本文引用: 1]
HUANG He HU Kaiyi LI Zhanyi et al An image dehazing method for UAV aerial photography to buildings combining MCAP and GRTV regularization
[J]. Journal of Shanghai Jiao Tong University 2023 , 57 (3 ): 613 -623 .
[本文引用: 1]
[3]
LI R ROBBY T T LOONG-FAH C All in one bad weather removal using architectural search
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2020 : 3175 -3185 .
[本文引用: 6]
[4]
VALANARASU J M J YASARLA R PATEL V M Transweather: Transformer-based restoration of images degraded by adverse weather conditions
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2022 : 2353 -2363 .
[本文引用: 6]
[5]
GOODFELLOW I POUGET-ABADIE J MIRZA M et al Generative adversarial networks
[J]. Communications of the ACM 2020 , 63 (11 ): 139 -144 .
[本文引用: 1]
[6]
KINGMA D P WELLING M Auto-encoding variational bayes
[DB/OL]. (2013-12-20 )[2023-02-06 ]. https://arxiv.org/abs/1312.6114.
URL
[本文引用: 1]
[7]
HO J JAIN A ABBEEL P Denoising diffusion probabilistic models
[J]. Advances in Neural Information Processing Systems 2020 , 33 : 6840 -6851 .
[本文引用: 2]
[8]
DHARIWAL P NICHOL A Diffusion models beat gans on image synthesis
[J]. Advances in Neural Information Processing Systems 2021 , 34 : 8780 -8794 .
[本文引用: 2]
[9]
PEEBLES W XIE S Scalable diffusion models with Transformers
[DB/OL]. (2022-12-19 )[2023-02-06 ]. https://arxiv.org/abs/2212.09748.
URL
[本文引用: 2]
[10]
WANG Z CUN X BAO J et al Uformer: A general u-shaped transformer for image restoration
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2022 : 17683 -17693 .
[本文引用: 5]
[11]
ZAMIR S W ARORA A KHAN S et al Restormer: Efficient transformer for high-resolution image restoration
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2022 : 5728 -5739 .
[本文引用: 8]
[12]
YAO T LI Y PAN Y et al Dual vision transformer
[DB/OL]. (2022-07-11 ) [2023-02-06 ]. https://arxiv.org/abs/2207.04976.
URL
[本文引用: 1]
[13]
CHEN L CHU X ZHANG X et al Simple baselines for image restoration
[C]// Proceedings of the European Conference on Computer Vision Israel : Springer , 2022 : 17 -33 .
[本文引用: 2]
[14]
LIU Y F JAW D W HUANG S C et al DesnowNet: Context-aware deep network for snow removal
[J]. IEEE Transactions on Image Processing 2018 , 27 (6 ): 3064 -3073 .
[本文引用: 5]
[15]
鲍先富 , 强赞霞 , 杨关 . 功能解耦和谱特征融合的雪霾消除模型
[J]. 计算机工程与应用 2023 , 59 (13 ): 211 -219 .
DOI:10.3778/j.issn.1002-8331.2203-0566
[本文引用: 1]
针对车载相机受雪花、雾霾影响,导致采集图像出现雪花遮挡和雾霾面纱效应问题,基于图像边缘纹理和图像色彩分离重建的思想,提出功能解耦、双重监督的雪霾消除网络。所提算法通过对图像边缘纹理和色彩信息进行分离重建,将雪霾消除任务解耦为背景纹理修复与色彩重建两个子任务,并用双生成对抗网络分别进行边缘纹理和色彩特征的协同重建。算法在SRRS-6000数据集上进行消融测试,验证了双重监督对网络加速收敛的有效性和噪声消除的显著效果,模型在Snow100K-S、Snow100K-M、Snow100K-L、I&O-Haze数据集上进行测试,峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)分别达到33.29?dB和0.94、32.8?dB和0.931?6、30.13?dB和0.93、25.88?dB和0.82。实验结果表明,通过对图像去噪任务进行解耦和双重监督,取得了高效的雪花、雾霾消除效果,增强了无人驾驶辅助系统在复杂天气条件下的适应性。
BAO Xianfu QIANG Zanxia YANG Guan Generative adverbial network for function decoupling and edge feature fusion for snow and haze elimination
[J]. Computer Engineering & Applications 2023 , 59 (13 ):211 -219 .
[本文引用: 1]
[16]
柴国强 , 王大为 , 芦宾 , 等 . 基于注意机制的轻量化稠密连接网络单幅图像去雨
[J]. 北京航空航天大学学报 2022 , 48 (11 ): 2186 -2192 .
[本文引用: 1]
CHAI Guoqiang WANG Dawei LU Bin et al Lightweight densely connected network based on attention mechanism for single-image deraining
[J]. Journal of Beijing University of Aeronautics & Astronautics 2022 , 48 (11 ): 2186 -2192 .
[本文引用: 1]
[17]
QIAN R TAN R T YANG W et al Attentive generative adversarial network for raindrop removal from a single image
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2018 : 2482 -2491 .
[本文引用: 4]
[18]
CHEN H WANG Y GUO T et al Pre-trained image processing transformer
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Malaysia : IEEE , 2021 : 12299 -12310 .
[本文引用: 1]
[19]
LI B LIU X HU P et al All-in-one image restoration for unknown corruption
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2022 : 17452 -17462 .
[本文引用: 1]
[20]
LI R CHEONG L F TAN R T Heavy rain image restoration: Integrating physics model and conditional adversarial learning
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2019 : 1633 -1642 .
[本文引用: 3]
[21]
LI S ARAUJO I B REN W et al Single image deraining: A comprehensive benchmark analysis
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2019 : 3838 -3847 .
[本文引用: 1]
[22]
LI X WU J LIN Z et al Recurrent squeeze-and-excitation context aggregation net for single image deraining
[C]// Proceedings of the European Conference on Computer Vision USA : Springer , 2018 : 254 -269 .
[本文引用: 1]
[23]
WANG T YANG X XU K et al Spatial attentive single-image deraining with a high quality real rain dataset
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2019 : 12270 -12279 .
[本文引用: 1]
[24]
CHEN W FANG H DING J et al JSTASR: Joint size and transparency-aware snow removal algorithm based on modified partial convolution and veiling effect removal
[C]// Proceedings of the European Conference on Computer Vision UK : Springer , 2020 : 754 -770 .
[本文引用: 1]
[25]
LIANG J CAO J SUN G et al Swinir: Image restoration using swin transformer
[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Montreal, canada : IEEE , 2021 : 1833 -1844 .
[本文引用: 3]
[26]
ZHANG K LI R YU Y et al Deep dense multi-scale network for snow removal using semantic and depth priors
[J]. IEEE Transactions on Image Processing 2021 , 30 : 7419 -7431 .
[本文引用: 1]
[27]
ZHU J Y PARK T ISOLA P et al Unpaired image-to-image translation using cycle-consistent adversarial networks
[C]// Proceedings of the IEEE International Conference on Computer Vision Italy : IEEE , 2017 : 2223 -2232 .
[本文引用: 1]
[28]
ISOLA P ZHU J Y ZHOU T et al Image-to-image translation with conditional adversarial networks
[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Italy : IEEE , 2017 : 1125 -1134 .
[本文引用: 2]
[29]
JIANG K WANG Z YI P et al Rain-free and residue hand-in-hand: A progressive coupled network for real-time image deraining
[J]. IEEE Transactions on Image Processing 2021 , 30 : 7404 -7418 .
[本文引用: 1]
[30]
ZAMIR S W ARORA A KHAN S et al Multi-stage progressive image restoration
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Malaysia : IEEE , 2021 : 14821 -14831 .
[本文引用: 1]
[31]
LIU X SUGANUMA M SUN Z et al Dual residual networks leveraging the potential of paired operations for image restoration
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition USA : IEEE , 2019 : 7007 -7016 .
[本文引用: 1]
[32]
QUAN Y DENG S CHEN Y et al Deep learning for seeing through window with raindrops
[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Seoul Korea : IEEE , 2019 : 2463 -2471 .
[本文引用: 1]
[33]
QUAN R YU X LIANG Y et al Removing raindrops and rain streaks in one go
[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Malaysia : IEEE , 2021 : 9147 -9156 .
[本文引用: 1]
[34]
XIAO J FU X LIU A et al Image de-raining transformer
[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence 2022 : 1 -18 .
[本文引用: 1]
基于窗口自注意力网络的单图像去雨算法
1
2023
... 雨、雪等恶劣天气下采集的图片会发生严重退化,进而影响后续的语义分割、目标检测等[1 -2 ] 计算机视觉算法的表现.现有多数基于深度学习的算法仅能去除单一天气,对于不同的退化无法直接迁移扩展.因此,多天气退化图像恢复凭借其仅需一次训练便可同时去除多种天气退化的优势而逐渐受到关注.例如,Li等[3 ] 利用多天气编码器和单输出解码器的结构首次提出多天气退化图像恢复网络All-in-One.Valanarasu等[4 ] 将任务查询向量引入视觉Transformer (Vision Transformer, ViT) 模型来得到干净背景图像. ...
A single image deraining algorithm based on Swin Transformer
1
2023
... 雨、雪等恶劣天气下采集的图片会发生严重退化,进而影响后续的语义分割、目标检测等[1 -2 ] 计算机视觉算法的表现.现有多数基于深度学习的算法仅能去除单一天气,对于不同的退化无法直接迁移扩展.因此,多天气退化图像恢复凭借其仅需一次训练便可同时去除多种天气退化的优势而逐渐受到关注.例如,Li等[3 ] 利用多天气编码器和单输出解码器的结构首次提出多天气退化图像恢复网络All-in-One.Valanarasu等[4 ] 将任务查询向量引入视觉Transformer (Vision Transformer, ViT) 模型来得到干净背景图像. ...
融合MCAP和GRTV正则化的无人机航拍建筑物图像去雾方法
1
2023
... 雨、雪等恶劣天气下采集的图片会发生严重退化,进而影响后续的语义分割、目标检测等[1 -2 ] 计算机视觉算法的表现.现有多数基于深度学习的算法仅能去除单一天气,对于不同的退化无法直接迁移扩展.因此,多天气退化图像恢复凭借其仅需一次训练便可同时去除多种天气退化的优势而逐渐受到关注.例如,Li等[3 ] 利用多天气编码器和单输出解码器的结构首次提出多天气退化图像恢复网络All-in-One.Valanarasu等[4 ] 将任务查询向量引入视觉Transformer (Vision Transformer, ViT) 模型来得到干净背景图像. ...
An image dehazing method for UAV aerial photography to buildings combining MCAP and GRTV regularization
1
2023
... 雨、雪等恶劣天气下采集的图片会发生严重退化,进而影响后续的语义分割、目标检测等[1 -2 ] 计算机视觉算法的表现.现有多数基于深度学习的算法仅能去除单一天气,对于不同的退化无法直接迁移扩展.因此,多天气退化图像恢复凭借其仅需一次训练便可同时去除多种天气退化的优势而逐渐受到关注.例如,Li等[3 ] 利用多天气编码器和单输出解码器的结构首次提出多天气退化图像恢复网络All-in-One.Valanarasu等[4 ] 将任务查询向量引入视觉Transformer (Vision Transformer, ViT) 模型来得到干净背景图像. ...
All in one bad weather removal using architectural search
6
2020
... 雨、雪等恶劣天气下采集的图片会发生严重退化,进而影响后续的语义分割、目标检测等[1 -2 ] 计算机视觉算法的表现.现有多数基于深度学习的算法仅能去除单一天气,对于不同的退化无法直接迁移扩展.因此,多天气退化图像恢复凭借其仅需一次训练便可同时去除多种天气退化的优势而逐渐受到关注.例如,Li等[3 ] 利用多天气编码器和单输出解码器的结构首次提出多天气退化图像恢复网络All-in-One.Valanarasu等[4 ] 将任务查询向量引入视觉Transformer (Vision Transformer, ViT) 模型来得到干净背景图像. ...
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
... Allweather:根据文献[3 ]将Snow100K[14 ] 、Out-door Rain[20 ] 和Raindrop[17 ] 数据集组合而成,其包括18 069对图像用来训练多天气退化图像恢复算法. ...
... 为了验证本文算法的有效性,实验对比本文算法AWIR-TDM 与近期表现良好的统一型图像恢复方法Uformer [10 ] 、Restormer [11 ] 和多天气退化图像恢复方法All-in-One [3 ] 、TransWeather [4 ] 在数据集Allweather 上经过一次训练后分别在雪、雨雾和雨滴测试数据集上的表现. 选取常用的有监督图像质量评价指标峰值信噪比 (peak signal noise ratio , PSNR ) 和结构相似性 (structural similarity , SSIM ) 进行定量对比. 峰值信噪比的计算公式如下: ...
... Quantitative comparison of different methods in all-in-one weather-degraded image restoration tasks
Tab.2 方法 源 Snow100K-L Snow100K-M Snow100K-S Test1 Raindrop-A Uformer[10 ] CVPR 2022 26.24/0.8680 32.11/0.9316 34.00/0.9445 16.32/0.7565 30.33/0.9335 Restormer[11 ] CVPR 2022 29.57 = 0.9106 = 33.71 = 0.9490 = 35.43 = 0.9583 = 29.81 = 0.9208 = 31.10 = 0.9337 = All-in-One[3 ] CVPR 2020 28.14/0.8901 30.96/0.9290 32.63/0.9392 25.87/ 0.8996 _ 31.35 _ 0.9299 _ TransWeather[4 ] CVPR 2022 29.15 _ 0.8930 _ 32.02 _ 0.9343 _ 32.98 _ 0.9447 _ 28.61 _ 30.21/0.9179 AWIR-TDM 31.69/0.9240 35.47/0.9565 37.16/0.9642 31.68/0.9347 32.33/0.9429
不同算法所得恢复图像的视觉对比如图5 ~7 所示,分别为退化图像经过去雨滴、去雨雾和去雪后所得的恢复图像.在图5 中,相比其他算法,AWIR-TDM方法能够有效去除较大雨滴并得到与无退化图像接近的结果.如第1行对比图像中Uformer和All-in-One未能去除雨滴,Restormer和TransWeather所得恢复图像中仍存在明显痕迹,而本文算法能够彻底去除雨滴.在图6 去雨雾视觉对比中,所有算法均能有效去除雨水痕迹,但相比本文算法,其他算法无法有效恢复图像的细节信息.如第1行对比图像中,本文算法能够得到清晰的指示牌字符,而其他算法所得字符已经无法辨认.特别地,发现Uformer处理雨雾图像时未能去除图像边缘的雨雾.在图7 第一行对比图像中,本文算法能够有效去除上衣口袋上的雪痕迹,而Uformer、All-in-One和TransWeather的结果中出现明显残留.尽管Restormer的结果中没有明显的雪痕迹,但却得不到清晰的细节纹理,而本文算法得到的纹理更接近真实背景图像. ...
... Quantitative comparison of different methods on natural weather-degraded image dataset
Tab.6 方法 Snow RainMist RainStreak Raindrop Uformer[10 ] 3.395/28.31/2.644 4.021/26.88/3.289 3.771/27.19/3.376 4.792/34.06/4.260 Restormer[11 ] 3.267/27.90/2.570 3.912/ 24.30 _ 3.874 _ 3.694 _ 3.480 _ 4.658/ 30.72 _ 4.317 _ All-in-One[3 ] 3.561/29.62/2.384 4.253/25.20/3.419 3.895/27.03/3.352 5.000 _ TransWeather[4 ] 3.020/ 27.78 _ 2.793 _ 3.791 _ 3.765/27.11/3.282 4.702/31.81/4.213 AWIR-TDM 3.134 _ 3.752/24.23/3.965 3.636/ 26.75 _ 4.647/30.46/4.328
此外,不同算法所得的自然天气退化图像恢复视觉对比如图8 所示.其中,在处理第1~3幅雨滴图像时,AWIR-TDM能有效去除雨滴痕迹,同时得到更符合视觉感知特点的纹理特征.如第1行对比图像中,All-in-One所得结果中除天空部分残留的雨滴外其他雨滴被彻底去除,但树枝原有纹理被破坏,从而导致视觉效果较差.在处理第4~6幅雨图时,本文算法有效去除退化图像中的雨水痕迹,而其他算法所得结果中均存在明显的雨痕残留.如第5行对比图像中,Uformer、Restormer等算法均无法去除肩膀处的雨痕.第7、8幅退化图像为雪图,其中第7幅图中由于雪的运动出现大量雪痕,第8幅图中存在大小不一的雪花颗粒,本文算法均有效去除雪痕和雪花,而其他算法无法适应不同的雪特点.如最后一行对比图像中,All-in-One和TransWeather等算法无法同时去除多样的雪花颗粒. ...
Transweather: Transformer-based restoration of images degraded by adverse weather conditions
6
2022
... 雨、雪等恶劣天气下采集的图片会发生严重退化,进而影响后续的语义分割、目标检测等[1 -2 ] 计算机视觉算法的表现.现有多数基于深度学习的算法仅能去除单一天气,对于不同的退化无法直接迁移扩展.因此,多天气退化图像恢复凭借其仅需一次训练便可同时去除多种天气退化的优势而逐渐受到关注.例如,Li等[3 ] 利用多天气编码器和单输出解码器的结构首次提出多天气退化图像恢复网络All-in-One.Valanarasu等[4 ] 将任务查询向量引入视觉Transformer (Vision Transformer, ViT) 模型来得到干净背景图像. ...
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
... 为了验证本文算法的有效性,实验对比本文算法AWIR-TDM 与近期表现良好的统一型图像恢复方法Uformer [10 ] 、Restormer [11 ] 和多天气退化图像恢复方法All-in-One [3 ] 、TransWeather [4 ] 在数据集Allweather 上经过一次训练后分别在雪、雨雾和雨滴测试数据集上的表现. 选取常用的有监督图像质量评价指标峰值信噪比 (peak signal noise ratio , PSNR ) 和结构相似性 (structural similarity , SSIM ) 进行定量对比. 峰值信噪比的计算公式如下: ...
... Quantitative comparison of different methods in all-in-one weather-degraded image restoration tasks
Tab.2 方法 源 Snow100K-L Snow100K-M Snow100K-S Test1 Raindrop-A Uformer[10 ] CVPR 2022 26.24/0.8680 32.11/0.9316 34.00/0.9445 16.32/0.7565 30.33/0.9335 Restormer[11 ] CVPR 2022 29.57 = 0.9106 = 33.71 = 0.9490 = 35.43 = 0.9583 = 29.81 = 0.9208 = 31.10 = 0.9337 = All-in-One[3 ] CVPR 2020 28.14/0.8901 30.96/0.9290 32.63/0.9392 25.87/ 0.8996 _ 31.35 _ 0.9299 _ TransWeather[4 ] CVPR 2022 29.15 _ 0.8930 _ 32.02 _ 0.9343 _ 32.98 _ 0.9447 _ 28.61 _ 30.21/0.9179 AWIR-TDM 31.69/0.9240 35.47/0.9565 37.16/0.9642 31.68/0.9347 32.33/0.9429
不同算法所得恢复图像的视觉对比如图5 ~7 所示,分别为退化图像经过去雨滴、去雨雾和去雪后所得的恢复图像.在图5 中,相比其他算法,AWIR-TDM方法能够有效去除较大雨滴并得到与无退化图像接近的结果.如第1行对比图像中Uformer和All-in-One未能去除雨滴,Restormer和TransWeather所得恢复图像中仍存在明显痕迹,而本文算法能够彻底去除雨滴.在图6 去雨雾视觉对比中,所有算法均能有效去除雨水痕迹,但相比本文算法,其他算法无法有效恢复图像的细节信息.如第1行对比图像中,本文算法能够得到清晰的指示牌字符,而其他算法所得字符已经无法辨认.特别地,发现Uformer处理雨雾图像时未能去除图像边缘的雨雾.在图7 第一行对比图像中,本文算法能够有效去除上衣口袋上的雪痕迹,而Uformer、All-in-One和TransWeather的结果中出现明显残留.尽管Restormer的结果中没有明显的雪痕迹,但却得不到清晰的细节纹理,而本文算法得到的纹理更接近真实背景图像. ...
... Quantitative comparison of different methods on Snow100K dataset
Tab.3 方法 源 Snow100K-L Snow100K-M Snow100K-S 平均指标 RESCAN[22 ] ECCV 2018 26.08/0.8108 29.95/0.8860 31.51/0.9032 29.28/0.8667 SPANet[23 ] CVPR 2019 23.70/0.7930 28.06/0.8680 29.92/0.8260 27.23/0.8290 DesnowNet[14 ] TIP 2018 27.17/ 0.8983 _ 30.87/0.9409 32.33/0.9500 30.12/ 0.9300 _ JSTASR[24 ] ECCV 2020 25.32/0.8076 29.11/0.8843 31.40/0.9012 28.61/0.8644 SwinIR[25 ] CVPR 2021 28.18/0.8800 31.42/0.9284 33.96/ 0.9567 _ 31.19/0.9217 DDMSNet[26 ] TIP 2021 28.85/0.8772 32.89/0.9330 34.34/0.9445 32.03/0.9182 TransWeather[4 ] CVPR 2022 29.21 _ 33.41 _ 0.9416 _ 34.92 _ 32.51 _ AWIR-TDM 30.64/0.9193 35.26/0.9472 37.05/0.9680 34.32/0.9448
10.16183/j.cnki.jsjtu.2023.043.T0004 表4 不同算法在雨雾数据集Test1上的定量对比 ...
... Quantitative comparison of different methods on natural weather-degraded image dataset
Tab.6 方法 Snow RainMist RainStreak Raindrop Uformer[10 ] 3.395/28.31/2.644 4.021/26.88/3.289 3.771/27.19/3.376 4.792/34.06/4.260 Restormer[11 ] 3.267/27.90/2.570 3.912/ 24.30 _ 3.874 _ 3.694 _ 3.480 _ 4.658/ 30.72 _ 4.317 _ All-in-One[3 ] 3.561/29.62/2.384 4.253/25.20/3.419 3.895/27.03/3.352 5.000 _ TransWeather[4 ] 3.020/ 27.78 _ 2.793 _ 3.791 _ 3.765/27.11/3.282 4.702/31.81/4.213 AWIR-TDM 3.134 _ 3.752/24.23/3.965 3.636/ 26.75 _ 4.647/30.46/4.328
此外,不同算法所得的自然天气退化图像恢复视觉对比如图8 所示.其中,在处理第1~3幅雨滴图像时,AWIR-TDM能有效去除雨滴痕迹,同时得到更符合视觉感知特点的纹理特征.如第1行对比图像中,All-in-One所得结果中除天空部分残留的雨滴外其他雨滴被彻底去除,但树枝原有纹理被破坏,从而导致视觉效果较差.在处理第4~6幅雨图时,本文算法有效去除退化图像中的雨水痕迹,而其他算法所得结果中均存在明显的雨痕残留.如第5行对比图像中,Uformer、Restormer等算法均无法去除肩膀处的雨痕.第7、8幅退化图像为雪图,其中第7幅图中由于雪的运动出现大量雪痕,第8幅图中存在大小不一的雪花颗粒,本文算法均有效去除雪痕和雪花,而其他算法无法适应不同的雪特点.如最后一行对比图像中,All-in-One和TransWeather等算法无法同时去除多样的雪花颗粒. ...
Generative adversarial networks
1
2020
... 图像生成模型具有强大的表征能力和丰富的解空间,自出现起便在图像生成领域表现出显著优势,如生成对抗网络 (generative adversarial network, GAN)[5 ] 、变分自编码器 (variational auto-encoder, VAE)[6 ] .其中,GAN利用对抗训练来提高视觉保真度,但存在训练不稳定、模式崩溃和图像伪影等问题;VAE通过最大化证据下界来优化数据的对数似然性,但平衡问题和变量崩溃现象限制其实际生成表现.近年来,去噪扩散概率模型 (denoising diffusion probability model, DDPM)[7 ] 在多个下游计算机视觉任务上表现出巨大优势.DDPM的主要原理为先连续添加高斯噪声来破坏原始数据,再进行反向采样来恢复图像.基于此,提出一种用于多天气退化图像恢复的自注意力扩散模型 (Transformer-based diffusion model for All-in-One weather-degraded image restoration, AWIR-TDM),以退化图像作为条件来引导反向采样. ...
Auto-encoding variational bayes
1
... 图像生成模型具有强大的表征能力和丰富的解空间,自出现起便在图像生成领域表现出显著优势,如生成对抗网络 (generative adversarial network, GAN)[5 ] 、变分自编码器 (variational auto-encoder, VAE)[6 ] .其中,GAN利用对抗训练来提高视觉保真度,但存在训练不稳定、模式崩溃和图像伪影等问题;VAE通过最大化证据下界来优化数据的对数似然性,但平衡问题和变量崩溃现象限制其实际生成表现.近年来,去噪扩散概率模型 (denoising diffusion probability model, DDPM)[7 ] 在多个下游计算机视觉任务上表现出巨大优势.DDPM的主要原理为先连续添加高斯噪声来破坏原始数据,再进行反向采样来恢复图像.基于此,提出一种用于多天气退化图像恢复的自注意力扩散模型 (Transformer-based diffusion model for All-in-One weather-degraded image restoration, AWIR-TDM),以退化图像作为条件来引导反向采样. ...
Denoising diffusion probabilistic models
2
2020
... 图像生成模型具有强大的表征能力和丰富的解空间,自出现起便在图像生成领域表现出显著优势,如生成对抗网络 (generative adversarial network, GAN)[5 ] 、变分自编码器 (variational auto-encoder, VAE)[6 ] .其中,GAN利用对抗训练来提高视觉保真度,但存在训练不稳定、模式崩溃和图像伪影等问题;VAE通过最大化证据下界来优化数据的对数似然性,但平衡问题和变量崩溃现象限制其实际生成表现.近年来,去噪扩散概率模型 (denoising diffusion probability model, DDPM)[7 ] 在多个下游计算机视觉任务上表现出巨大优势.DDPM的主要原理为先连续添加高斯噪声来破坏原始数据,再进行反向采样来恢复图像.基于此,提出一种用于多天气退化图像恢复的自注意力扩散模型 (Transformer-based diffusion model for All-in-One weather-degraded image restoration, AWIR-TDM),以退化图像作为条件来引导反向采样. ...
... 目前,基于DDPM的计算机视觉算法[7 -8 ] 在噪声估计网络部分均采用类似U-Net的卷积网络结构.然而,Peebles等[9 ] 的工作表明,采用ViT的类条件扩散模型可以取得相比于常用U-Net架构更好的图像生成表现.但是,ViT中自注意力 (self-attention, SA) 的计算负担与输入特征分辨率呈平方关系,无法直接应用于高分辨率的多天气图像恢复任务.对此,Wang等[10 ] 基于Swin Transformer提出用于多种图像恢复任务的统一型图像恢复算法Uformer,在分割的窗口中分别计算自注意力来减少计算负担;Zamir等[11 ] 利用转置自注意力 (transposed self-attention, TSA) 强化特征学习,即将原自注意力的表征从空间维度转移到通道维度,在去雨、去噪等任务上取得良好表现.然而,以上方法未依据自注意力的内积特点来进一步优化自注意力的表征,导致其训练和推理均需要大量时间.于DDPM而言,本身训练和采样均需要大量时间,如果在噪声估计网络部分直接使用计算负担巨大的ViT会加剧对硬件环境的要求.同时,文献[12 ]中表明自注意力和TSA具有接近的表现.因此,提出一种次空间转置自注意力噪声估计网络 (subspace transposed Transformer for noise estimation, NE-STT). NE-STT先将输入特征映射到次空间,再利用TSA构成次空间转置自注意力 (subspace transposed self-attention, STSA) 来强化特征学习并显著减少计算负担.同时,STSA不需要将输入特征分割为多个不重叠的窗口,而是直接从输入特征得到分辨率水平较低的查询向量Q 和键向量K 来进一步计算自注意力,相比Swin Transformer分割窗口更符合自注意力机制提取特征全局信息的初衷.同时,文献[11 ]和文献[13 ]中的工作表明,门控机制能够有效提高ViT中前馈网络 (feed-forward network, FFN) 的非线性表征能力从而提升视觉自注意力网络ViT的整体表现.基于此,提出双分组门控前馈网络 (dual grouped gated feed-forward network, DGGFFN),其在ViT中前馈网络FFN的深度可分离卷积后采用双分组门控机制来提高非线性表征能力. ...
Diffusion models beat gans on image synthesis
2
2021
... 目前,基于DDPM的计算机视觉算法[7 -8 ] 在噪声估计网络部分均采用类似U-Net的卷积网络结构.然而,Peebles等[9 ] 的工作表明,采用ViT的类条件扩散模型可以取得相比于常用U-Net架构更好的图像生成表现.但是,ViT中自注意力 (self-attention, SA) 的计算负担与输入特征分辨率呈平方关系,无法直接应用于高分辨率的多天气图像恢复任务.对此,Wang等[10 ] 基于Swin Transformer提出用于多种图像恢复任务的统一型图像恢复算法Uformer,在分割的窗口中分别计算自注意力来减少计算负担;Zamir等[11 ] 利用转置自注意力 (transposed self-attention, TSA) 强化特征学习,即将原自注意力的表征从空间维度转移到通道维度,在去雨、去噪等任务上取得良好表现.然而,以上方法未依据自注意力的内积特点来进一步优化自注意力的表征,导致其训练和推理均需要大量时间.于DDPM而言,本身训练和采样均需要大量时间,如果在噪声估计网络部分直接使用计算负担巨大的ViT会加剧对硬件环境的要求.同时,文献[12 ]中表明自注意力和TSA具有接近的表现.因此,提出一种次空间转置自注意力噪声估计网络 (subspace transposed Transformer for noise estimation, NE-STT). NE-STT先将输入特征映射到次空间,再利用TSA构成次空间转置自注意力 (subspace transposed self-attention, STSA) 来强化特征学习并显著减少计算负担.同时,STSA不需要将输入特征分割为多个不重叠的窗口,而是直接从输入特征得到分辨率水平较低的查询向量Q 和键向量K 来进一步计算自注意力,相比Swin Transformer分割窗口更符合自注意力机制提取特征全局信息的初衷.同时,文献[11 ]和文献[13 ]中的工作表明,门控机制能够有效提高ViT中前馈网络 (feed-forward network, FFN) 的非线性表征能力从而提升视觉自注意力网络ViT的整体表现.基于此,提出双分组门控前馈网络 (dual grouped gated feed-forward network, DGGFFN),其在ViT中前馈网络FFN的深度可分离卷积后采用双分组门控机制来提高非线性表征能力. ...
... 式中: x ^ . 此时xt -1 ~pθ (xt -1 |xt , x ^ ) ,根据文献[8 ]中的条件反向采样过程为 ...
Scalable diffusion models with Transformers
2
... 目前,基于DDPM的计算机视觉算法[7 -8 ] 在噪声估计网络部分均采用类似U-Net的卷积网络结构.然而,Peebles等[9 ] 的工作表明,采用ViT的类条件扩散模型可以取得相比于常用U-Net架构更好的图像生成表现.但是,ViT中自注意力 (self-attention, SA) 的计算负担与输入特征分辨率呈平方关系,无法直接应用于高分辨率的多天气图像恢复任务.对此,Wang等[10 ] 基于Swin Transformer提出用于多种图像恢复任务的统一型图像恢复算法Uformer,在分割的窗口中分别计算自注意力来减少计算负担;Zamir等[11 ] 利用转置自注意力 (transposed self-attention, TSA) 强化特征学习,即将原自注意力的表征从空间维度转移到通道维度,在去雨、去噪等任务上取得良好表现.然而,以上方法未依据自注意力的内积特点来进一步优化自注意力的表征,导致其训练和推理均需要大量时间.于DDPM而言,本身训练和采样均需要大量时间,如果在噪声估计网络部分直接使用计算负担巨大的ViT会加剧对硬件环境的要求.同时,文献[12 ]中表明自注意力和TSA具有接近的表现.因此,提出一种次空间转置自注意力噪声估计网络 (subspace transposed Transformer for noise estimation, NE-STT). NE-STT先将输入特征映射到次空间,再利用TSA构成次空间转置自注意力 (subspace transposed self-attention, STSA) 来强化特征学习并显著减少计算负担.同时,STSA不需要将输入特征分割为多个不重叠的窗口,而是直接从输入特征得到分辨率水平较低的查询向量Q 和键向量K 来进一步计算自注意力,相比Swin Transformer分割窗口更符合自注意力机制提取特征全局信息的初衷.同时,文献[11 ]和文献[13 ]中的工作表明,门控机制能够有效提高ViT中前馈网络 (feed-forward network, FFN) 的非线性表征能力从而提升视觉自注意力网络ViT的整体表现.基于此,提出双分组门控前馈网络 (dual grouped gated feed-forward network, DGGFFN),其在ViT中前馈网络FFN的深度可分离卷积后采用双分组门控机制来提高非线性表征能力. ...
... 在目前基于去噪扩散概率模型DDPM的图像恢复任务中,噪声估计网络NE-Net均采用以卷积神经网络CNN为核心的U-Net架构.文献[9 ]中表明视觉自注意力网络ViT的全局特性或架构设计相比CNN在建模特征依赖上更具优势.然而,ViT中自注意力巨大的计算负担和扩散模型本身更长的反向采样时间限制了其在多天气退化图像恢复任务AIR上的实际应用.为此,提出计算负担更小且噪声估计表现更好的NE-STT,如图4 所示. ...
Uformer: A general u-shaped transformer for image restoration
5
2022
... 目前,基于DDPM的计算机视觉算法[7 -8 ] 在噪声估计网络部分均采用类似U-Net的卷积网络结构.然而,Peebles等[9 ] 的工作表明,采用ViT的类条件扩散模型可以取得相比于常用U-Net架构更好的图像生成表现.但是,ViT中自注意力 (self-attention, SA) 的计算负担与输入特征分辨率呈平方关系,无法直接应用于高分辨率的多天气图像恢复任务.对此,Wang等[10 ] 基于Swin Transformer提出用于多种图像恢复任务的统一型图像恢复算法Uformer,在分割的窗口中分别计算自注意力来减少计算负担;Zamir等[11 ] 利用转置自注意力 (transposed self-attention, TSA) 强化特征学习,即将原自注意力的表征从空间维度转移到通道维度,在去雨、去噪等任务上取得良好表现.然而,以上方法未依据自注意力的内积特点来进一步优化自注意力的表征,导致其训练和推理均需要大量时间.于DDPM而言,本身训练和采样均需要大量时间,如果在噪声估计网络部分直接使用计算负担巨大的ViT会加剧对硬件环境的要求.同时,文献[12 ]中表明自注意力和TSA具有接近的表现.因此,提出一种次空间转置自注意力噪声估计网络 (subspace transposed Transformer for noise estimation, NE-STT). NE-STT先将输入特征映射到次空间,再利用TSA构成次空间转置自注意力 (subspace transposed self-attention, STSA) 来强化特征学习并显著减少计算负担.同时,STSA不需要将输入特征分割为多个不重叠的窗口,而是直接从输入特征得到分辨率水平较低的查询向量Q 和键向量K 来进一步计算自注意力,相比Swin Transformer分割窗口更符合自注意力机制提取特征全局信息的初衷.同时,文献[11 ]和文献[13 ]中的工作表明,门控机制能够有效提高ViT中前馈网络 (feed-forward network, FFN) 的非线性表征能力从而提升视觉自注意力网络ViT的整体表现.基于此,提出双分组门控前馈网络 (dual grouped gated feed-forward network, DGGFFN),其在ViT中前馈网络FFN的深度可分离卷积后采用双分组门控机制来提高非线性表征能力. ...
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
... 为了验证本文算法的有效性,实验对比本文算法AWIR-TDM 与近期表现良好的统一型图像恢复方法Uformer [10 ] 、Restormer [11 ] 和多天气退化图像恢复方法All-in-One [3 ] 、TransWeather [4 ] 在数据集Allweather 上经过一次训练后分别在雪、雨雾和雨滴测试数据集上的表现. 选取常用的有监督图像质量评价指标峰值信噪比 (peak signal noise ratio , PSNR ) 和结构相似性 (structural similarity , SSIM ) 进行定量对比. 峰值信噪比的计算公式如下: ...
... Quantitative comparison of different methods in all-in-one weather-degraded image restoration tasks
Tab.2 方法 源 Snow100K-L Snow100K-M Snow100K-S Test1 Raindrop-A Uformer[10 ] CVPR 2022 26.24/0.8680 32.11/0.9316 34.00/0.9445 16.32/0.7565 30.33/0.9335 Restormer[11 ] CVPR 2022 29.57 = 0.9106 = 33.71 = 0.9490 = 35.43 = 0.9583 = 29.81 = 0.9208 = 31.10 = 0.9337 = All-in-One[3 ] CVPR 2020 28.14/0.8901 30.96/0.9290 32.63/0.9392 25.87/ 0.8996 _ 31.35 _ 0.9299 _ TransWeather[4 ] CVPR 2022 29.15 _ 0.8930 _ 32.02 _ 0.9343 _ 32.98 _ 0.9447 _ 28.61 _ 30.21/0.9179 AWIR-TDM 31.69/0.9240 35.47/0.9565 37.16/0.9642 31.68/0.9347 32.33/0.9429
不同算法所得恢复图像的视觉对比如图5 ~7 所示,分别为退化图像经过去雨滴、去雨雾和去雪后所得的恢复图像.在图5 中,相比其他算法,AWIR-TDM方法能够有效去除较大雨滴并得到与无退化图像接近的结果.如第1行对比图像中Uformer和All-in-One未能去除雨滴,Restormer和TransWeather所得恢复图像中仍存在明显痕迹,而本文算法能够彻底去除雨滴.在图6 去雨雾视觉对比中,所有算法均能有效去除雨水痕迹,但相比本文算法,其他算法无法有效恢复图像的细节信息.如第1行对比图像中,本文算法能够得到清晰的指示牌字符,而其他算法所得字符已经无法辨认.特别地,发现Uformer处理雨雾图像时未能去除图像边缘的雨雾.在图7 第一行对比图像中,本文算法能够有效去除上衣口袋上的雪痕迹,而Uformer、All-in-One和TransWeather的结果中出现明显残留.尽管Restormer的结果中没有明显的雪痕迹,但却得不到清晰的细节纹理,而本文算法得到的纹理更接近真实背景图像. ...
... Quantitative comparison of different methods on natural weather-degraded image dataset
Tab.6 方法 Snow RainMist RainStreak Raindrop Uformer[10 ] 3.395/28.31/2.644 4.021/26.88/3.289 3.771/27.19/3.376 4.792/34.06/4.260 Restormer[11 ] 3.267/27.90/2.570 3.912/ 24.30 _ 3.874 _ 3.694 _ 3.480 _ 4.658/ 30.72 _ 4.317 _ All-in-One[3 ] 3.561/29.62/2.384 4.253/25.20/3.419 3.895/27.03/3.352 5.000 _ TransWeather[4 ] 3.020/ 27.78 _ 2.793 _ 3.791 _ 3.765/27.11/3.282 4.702/31.81/4.213 AWIR-TDM 3.134 _ 3.752/24.23/3.965 3.636/ 26.75 _ 4.647/30.46/4.328
此外,不同算法所得的自然天气退化图像恢复视觉对比如图8 所示.其中,在处理第1~3幅雨滴图像时,AWIR-TDM能有效去除雨滴痕迹,同时得到更符合视觉感知特点的纹理特征.如第1行对比图像中,All-in-One所得结果中除天空部分残留的雨滴外其他雨滴被彻底去除,但树枝原有纹理被破坏,从而导致视觉效果较差.在处理第4~6幅雨图时,本文算法有效去除退化图像中的雨水痕迹,而其他算法所得结果中均存在明显的雨痕残留.如第5行对比图像中,Uformer、Restormer等算法均无法去除肩膀处的雨痕.第7、8幅退化图像为雪图,其中第7幅图中由于雪的运动出现大量雪痕,第8幅图中存在大小不一的雪花颗粒,本文算法均有效去除雪痕和雪花,而其他算法无法适应不同的雪特点.如最后一行对比图像中,All-in-One和TransWeather等算法无法同时去除多样的雪花颗粒. ...
Restormer: Efficient transformer for high-resolution image restoration
8
2022
... 目前,基于DDPM的计算机视觉算法[7 -8 ] 在噪声估计网络部分均采用类似U-Net的卷积网络结构.然而,Peebles等[9 ] 的工作表明,采用ViT的类条件扩散模型可以取得相比于常用U-Net架构更好的图像生成表现.但是,ViT中自注意力 (self-attention, SA) 的计算负担与输入特征分辨率呈平方关系,无法直接应用于高分辨率的多天气图像恢复任务.对此,Wang等[10 ] 基于Swin Transformer提出用于多种图像恢复任务的统一型图像恢复算法Uformer,在分割的窗口中分别计算自注意力来减少计算负担;Zamir等[11 ] 利用转置自注意力 (transposed self-attention, TSA) 强化特征学习,即将原自注意力的表征从空间维度转移到通道维度,在去雨、去噪等任务上取得良好表现.然而,以上方法未依据自注意力的内积特点来进一步优化自注意力的表征,导致其训练和推理均需要大量时间.于DDPM而言,本身训练和采样均需要大量时间,如果在噪声估计网络部分直接使用计算负担巨大的ViT会加剧对硬件环境的要求.同时,文献[12 ]中表明自注意力和TSA具有接近的表现.因此,提出一种次空间转置自注意力噪声估计网络 (subspace transposed Transformer for noise estimation, NE-STT). NE-STT先将输入特征映射到次空间,再利用TSA构成次空间转置自注意力 (subspace transposed self-attention, STSA) 来强化特征学习并显著减少计算负担.同时,STSA不需要将输入特征分割为多个不重叠的窗口,而是直接从输入特征得到分辨率水平较低的查询向量Q 和键向量K 来进一步计算自注意力,相比Swin Transformer分割窗口更符合自注意力机制提取特征全局信息的初衷.同时,文献[11 ]和文献[13 ]中的工作表明,门控机制能够有效提高ViT中前馈网络 (feed-forward network, FFN) 的非线性表征能力从而提升视觉自注意力网络ViT的整体表现.基于此,提出双分组门控前馈网络 (dual grouped gated feed-forward network, DGGFFN),其在ViT中前馈网络FFN的深度可分离卷积后采用双分组门控机制来提高非线性表征能力. ...
... 来进一步计算自注意力,相比Swin Transformer分割窗口更符合自注意力机制提取特征全局信息的初衷.同时,文献[11 ]和文献[13 ]中的工作表明,门控机制能够有效提高ViT中前馈网络 (feed-forward network, FFN) 的非线性表征能力从而提升视觉自注意力网络ViT的整体表现.基于此,提出双分组门控前馈网络 (dual grouped gated feed-forward network, DGGFFN),其在ViT中前馈网络FFN的深度可分离卷积后采用双分组门控机制来提高非线性表征能力. ...
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
... 此外,Zamir等[11 ] 和Chen等[13 ] 的研究表明,在视觉自注意力网络ViT的前馈网络FFN中采用门控机制可以进一步提升其非线性表达能力.受其启发,提出双分组门控前馈网络DGGFFN,其在FFN中深度可分离卷积层后利用双分组门控机制来强化特征学习.具体而言,DGGFFN将深度可分离卷积所得特征按照通道维度分为两组,再对两组特征分别利用另一组特征进行门控增强,最后将所得结果相加得到门控输出.双分组门控机制可以公式化为 ...
... 为了验证本文算法的有效性,实验对比本文算法AWIR-TDM 与近期表现良好的统一型图像恢复方法Uformer [10 ] 、Restormer [11 ] 和多天气退化图像恢复方法All-in-One [3 ] 、TransWeather [4 ] 在数据集Allweather 上经过一次训练后分别在雪、雨雾和雨滴测试数据集上的表现. 选取常用的有监督图像质量评价指标峰值信噪比 (peak signal noise ratio , PSNR ) 和结构相似性 (structural similarity , SSIM ) 进行定量对比. 峰值信噪比的计算公式如下: ...
... Quantitative comparison of different methods in all-in-one weather-degraded image restoration tasks
Tab.2 方法 源 Snow100K-L Snow100K-M Snow100K-S Test1 Raindrop-A Uformer[10 ] CVPR 2022 26.24/0.8680 32.11/0.9316 34.00/0.9445 16.32/0.7565 30.33/0.9335 Restormer[11 ] CVPR 2022 29.57 = 0.9106 = 33.71 = 0.9490 = 35.43 = 0.9583 = 29.81 = 0.9208 = 31.10 = 0.9337 = All-in-One[3 ] CVPR 2020 28.14/0.8901 30.96/0.9290 32.63/0.9392 25.87/ 0.8996 _ 31.35 _ 0.9299 _ TransWeather[4 ] CVPR 2022 29.15 _ 0.8930 _ 32.02 _ 0.9343 _ 32.98 _ 0.9447 _ 28.61 _ 30.21/0.9179 AWIR-TDM 31.69/0.9240 35.47/0.9565 37.16/0.9642 31.68/0.9347 32.33/0.9429
不同算法所得恢复图像的视觉对比如图5 ~7 所示,分别为退化图像经过去雨滴、去雨雾和去雪后所得的恢复图像.在图5 中,相比其他算法,AWIR-TDM方法能够有效去除较大雨滴并得到与无退化图像接近的结果.如第1行对比图像中Uformer和All-in-One未能去除雨滴,Restormer和TransWeather所得恢复图像中仍存在明显痕迹,而本文算法能够彻底去除雨滴.在图6 去雨雾视觉对比中,所有算法均能有效去除雨水痕迹,但相比本文算法,其他算法无法有效恢复图像的细节信息.如第1行对比图像中,本文算法能够得到清晰的指示牌字符,而其他算法所得字符已经无法辨认.特别地,发现Uformer处理雨雾图像时未能去除图像边缘的雨雾.在图7 第一行对比图像中,本文算法能够有效去除上衣口袋上的雪痕迹,而Uformer、All-in-One和TransWeather的结果中出现明显残留.尽管Restormer的结果中没有明显的雪痕迹,但却得不到清晰的细节纹理,而本文算法得到的纹理更接近真实背景图像. ...
... Quantitative comparison of different methods on Test1 dataset
Tab.4 方法 源 Test1 PSNR/SSIM CycleGAN[27 ] ICCV 2017 17.62/0.6560 pix2pix[28 ] CVPR 2017 19.09/0.7100 HRGAN[20 ] CVPR 2019 21.56/0.8550 SwinIR[25 ] CVPR 2021 23.23/0.8685 PCNet[29 ] TIP 2021 26.19/0.9015 MPRNet[30 ] CVPR 2021 28.03/0.9192 Restormer[11 ] CVPR 2022 28.44 _ 0.9263 _ AWIR-TDM 29.13/0.9428
10.16183/j.cnki.jsjtu.2023.043.T0005 表5 不同算法在雨滴数据集Raindrop-A上的定量对比 ...
... Quantitative comparison of different methods on natural weather-degraded image dataset
Tab.6 方法 Snow RainMist RainStreak Raindrop Uformer[10 ] 3.395/28.31/2.644 4.021/26.88/3.289 3.771/27.19/3.376 4.792/34.06/4.260 Restormer[11 ] 3.267/27.90/2.570 3.912/ 24.30 _ 3.874 _ 3.694 _ 3.480 _ 4.658/ 30.72 _ 4.317 _ All-in-One[3 ] 3.561/29.62/2.384 4.253/25.20/3.419 3.895/27.03/3.352 5.000 _ TransWeather[4 ] 3.020/ 27.78 _ 2.793 _ 3.791 _ 3.765/27.11/3.282 4.702/31.81/4.213 AWIR-TDM 3.134 _ 3.752/24.23/3.965 3.636/ 26.75 _ 4.647/30.46/4.328
此外,不同算法所得的自然天气退化图像恢复视觉对比如图8 所示.其中,在处理第1~3幅雨滴图像时,AWIR-TDM能有效去除雨滴痕迹,同时得到更符合视觉感知特点的纹理特征.如第1行对比图像中,All-in-One所得结果中除天空部分残留的雨滴外其他雨滴被彻底去除,但树枝原有纹理被破坏,从而导致视觉效果较差.在处理第4~6幅雨图时,本文算法有效去除退化图像中的雨水痕迹,而其他算法所得结果中均存在明显的雨痕残留.如第5行对比图像中,Uformer、Restormer等算法均无法去除肩膀处的雨痕.第7、8幅退化图像为雪图,其中第7幅图中由于雪的运动出现大量雪痕,第8幅图中存在大小不一的雪花颗粒,本文算法均有效去除雪痕和雪花,而其他算法无法适应不同的雪特点.如最后一行对比图像中,All-in-One和TransWeather等算法无法同时去除多样的雪花颗粒. ...
Dual vision transformer
1
... 目前,基于DDPM的计算机视觉算法[7 -8 ] 在噪声估计网络部分均采用类似U-Net的卷积网络结构.然而,Peebles等[9 ] 的工作表明,采用ViT的类条件扩散模型可以取得相比于常用U-Net架构更好的图像生成表现.但是,ViT中自注意力 (self-attention, SA) 的计算负担与输入特征分辨率呈平方关系,无法直接应用于高分辨率的多天气图像恢复任务.对此,Wang等[10 ] 基于Swin Transformer提出用于多种图像恢复任务的统一型图像恢复算法Uformer,在分割的窗口中分别计算自注意力来减少计算负担;Zamir等[11 ] 利用转置自注意力 (transposed self-attention, TSA) 强化特征学习,即将原自注意力的表征从空间维度转移到通道维度,在去雨、去噪等任务上取得良好表现.然而,以上方法未依据自注意力的内积特点来进一步优化自注意力的表征,导致其训练和推理均需要大量时间.于DDPM而言,本身训练和采样均需要大量时间,如果在噪声估计网络部分直接使用计算负担巨大的ViT会加剧对硬件环境的要求.同时,文献[12 ]中表明自注意力和TSA具有接近的表现.因此,提出一种次空间转置自注意力噪声估计网络 (subspace transposed Transformer for noise estimation, NE-STT). NE-STT先将输入特征映射到次空间,再利用TSA构成次空间转置自注意力 (subspace transposed self-attention, STSA) 来强化特征学习并显著减少计算负担.同时,STSA不需要将输入特征分割为多个不重叠的窗口,而是直接从输入特征得到分辨率水平较低的查询向量Q 和键向量K 来进一步计算自注意力,相比Swin Transformer分割窗口更符合自注意力机制提取特征全局信息的初衷.同时,文献[11 ]和文献[13 ]中的工作表明,门控机制能够有效提高ViT中前馈网络 (feed-forward network, FFN) 的非线性表征能力从而提升视觉自注意力网络ViT的整体表现.基于此,提出双分组门控前馈网络 (dual grouped gated feed-forward network, DGGFFN),其在ViT中前馈网络FFN的深度可分离卷积后采用双分组门控机制来提高非线性表征能力. ...
Simple baselines for image restoration
2
2022
... 目前,基于DDPM的计算机视觉算法[7 -8 ] 在噪声估计网络部分均采用类似U-Net的卷积网络结构.然而,Peebles等[9 ] 的工作表明,采用ViT的类条件扩散模型可以取得相比于常用U-Net架构更好的图像生成表现.但是,ViT中自注意力 (self-attention, SA) 的计算负担与输入特征分辨率呈平方关系,无法直接应用于高分辨率的多天气图像恢复任务.对此,Wang等[10 ] 基于Swin Transformer提出用于多种图像恢复任务的统一型图像恢复算法Uformer,在分割的窗口中分别计算自注意力来减少计算负担;Zamir等[11 ] 利用转置自注意力 (transposed self-attention, TSA) 强化特征学习,即将原自注意力的表征从空间维度转移到通道维度,在去雨、去噪等任务上取得良好表现.然而,以上方法未依据自注意力的内积特点来进一步优化自注意力的表征,导致其训练和推理均需要大量时间.于DDPM而言,本身训练和采样均需要大量时间,如果在噪声估计网络部分直接使用计算负担巨大的ViT会加剧对硬件环境的要求.同时,文献[12 ]中表明自注意力和TSA具有接近的表现.因此,提出一种次空间转置自注意力噪声估计网络 (subspace transposed Transformer for noise estimation, NE-STT). NE-STT先将输入特征映射到次空间,再利用TSA构成次空间转置自注意力 (subspace transposed self-attention, STSA) 来强化特征学习并显著减少计算负担.同时,STSA不需要将输入特征分割为多个不重叠的窗口,而是直接从输入特征得到分辨率水平较低的查询向量Q 和键向量K 来进一步计算自注意力,相比Swin Transformer分割窗口更符合自注意力机制提取特征全局信息的初衷.同时,文献[11 ]和文献[13 ]中的工作表明,门控机制能够有效提高ViT中前馈网络 (feed-forward network, FFN) 的非线性表征能力从而提升视觉自注意力网络ViT的整体表现.基于此,提出双分组门控前馈网络 (dual grouped gated feed-forward network, DGGFFN),其在ViT中前馈网络FFN的深度可分离卷积后采用双分组门控机制来提高非线性表征能力. ...
... 此外,Zamir等[11 ] 和Chen等[13 ] 的研究表明,在视觉自注意力网络ViT的前馈网络FFN中采用门控机制可以进一步提升其非线性表达能力.受其启发,提出双分组门控前馈网络DGGFFN,其在FFN中深度可分离卷积层后利用双分组门控机制来强化特征学习.具体而言,DGGFFN将深度可分离卷积所得特征按照通道维度分为两组,再对两组特征分别利用另一组特征进行门控增强,最后将所得结果相加得到门控输出.双分组门控机制可以公式化为 ...
DesnowNet: Context-aware deep network for snow removal
5
2018
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
... Allweather:根据文献[3 ]将Snow100K[14 ] 、Out-door Rain[20 ] 和Raindrop[17 ] 数据集组合而成,其包括18 069对图像用来训练多天气退化图像恢复算法. ...
... Snow100K:来自文献[14 ],训练集包括5万对图像,测试集根据雪的大小分为Snow100K-L、Snow100K-M和Snow100K-S这3个数据集,其中分别包括16 611、16 588和16 801对图像用来评估算法的去雪性能. ...
... 此外,为验证算法恢复自然天气退化图像的表现,选用文献[14 ]中提供的雪数据集Snow,其中包括1 329幅自然雪图,同时还选用来自文献[21 ]的雨滴数据集Raindrop、雨雾数据集RainMist和雨痕数据集RainStreak,其分别包括67、13和185幅自然天气退化图像. ...
... Quantitative comparison of different methods on Snow100K dataset
Tab.3 方法 源 Snow100K-L Snow100K-M Snow100K-S 平均指标 RESCAN[22 ] ECCV 2018 26.08/0.8108 29.95/0.8860 31.51/0.9032 29.28/0.8667 SPANet[23 ] CVPR 2019 23.70/0.7930 28.06/0.8680 29.92/0.8260 27.23/0.8290 DesnowNet[14 ] TIP 2018 27.17/ 0.8983 _ 30.87/0.9409 32.33/0.9500 30.12/ 0.9300 _ JSTASR[24 ] ECCV 2020 25.32/0.8076 29.11/0.8843 31.40/0.9012 28.61/0.8644 SwinIR[25 ] CVPR 2021 28.18/0.8800 31.42/0.9284 33.96/ 0.9567 _ 31.19/0.9217 DDMSNet[26 ] TIP 2021 28.85/0.8772 32.89/0.9330 34.34/0.9445 32.03/0.9182 TransWeather[4 ] CVPR 2022 29.21 _ 33.41 _ 0.9416 _ 34.92 _ 32.51 _ AWIR-TDM 30.64/0.9193 35.26/0.9472 37.05/0.9680 34.32/0.9448
10.16183/j.cnki.jsjtu.2023.043.T0004 表4 不同算法在雨雾数据集Test1上的定量对比 ...
功能解耦和谱特征融合的雪霾消除模型
1
2023
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
Generative adverbial network for function decoupling and edge feature fusion for snow and haze elimination
1
2023
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
基于注意机制的轻量化稠密连接网络单幅图像去雨
1
2022
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
Lightweight densely connected network based on attention mechanism for single-image deraining
1
2022
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
Attentive generative adversarial network for raindrop removal from a single image
4
2018
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
... Allweather:根据文献[3 ]将Snow100K[14 ] 、Out-door Rain[20 ] 和Raindrop[17 ] 数据集组合而成,其包括18 069对图像用来训练多天气退化图像恢复算法. ...
... Raindrop:包括861对训练图像和两个图像对数量分别为58和249的测试数据集.实验采用的测试集为Raindrop-A[17 ] . ...
... Quantitative comparison of different methods on Raindrop-A dataset
Tab.5 方法 源 Raindrop-A PSNR/SSIM pix2pix[28 ] CVPR 2017 28.02/0.8547 Attn. GAN[17 ] CVPR 2018 31.59/0.9170 DuRN[31 ] CVPR 2019 31.24/0.9259 RaindropAttn[32 ] ICCV 2019 31.44/0.9263 SwinIR[25 ] CVPR 2021 30.82/0.9035 CCN[33 ] CVPR 2021 31.34/ 0.9500 _ IDT[34 ] TPAMI 2022 31.87 _ AWIR-TDM 32.84/0.9571
本文算法在Snow100K的测试集上平均PSNR高出1.81~7.09 dB; 相比现有图像去雨雾算法,本文算法在Test1测试集上平均PSNR高出0.69~11.51 dB;相比现有去雨滴算法,本文算法在Raindrop-A测试集上平均PSNR高出0.79~4.82 dB.因此,本文算法不仅可以作为多天气退化图像恢复算法,还可以作为统一型天气退化图像恢复方法,并且在两种情况下均超越现有表现良好的方法. ...
Pre-trained image processing transformer
1
2021
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
All-in-one image restoration for unknown corruption
1
2022
... 如图1 所示,目前用于天气退化图像恢复的算法可以分为3类,即专一型、统一型和同一型.其中,专一型[14 ⇓ ⇓ -17 ] 为不同任务设计专门的网络结构,模型架构与参数均不相同;统一型[10 -11 ] 为不同任务设计统一的网络结构,模型架构一致但参数不相同;同一型[3 -4 ,18 -19 ] 根据不同天气退化的相似特点设计同一的多天气退化图像恢复网络,在同时存在多种天气退化因素的数据集上训练, 对于不同天气退化图像恢复任务模型的架构和参数相同. ...
Heavy rain image restoration: Integrating physics model and conditional adversarial learning
3
2019
... Allweather:根据文献[3 ]将Snow100K[14 ] 、Out-door Rain[20 ] 和Raindrop[17 ] 数据集组合而成,其包括18 069对图像用来训练多天气退化图像恢复算法. ...
... Out-door Rain:雨雾共存的数据集[20 ] ,训练集包括 9 000 对图像.采用其中名为Test1的子集作为测试集,图像对的数量为750. ...
... Quantitative comparison of different methods on Test1 dataset
Tab.4 方法 源 Test1 PSNR/SSIM CycleGAN[27 ] ICCV 2017 17.62/0.6560 pix2pix[28 ] CVPR 2017 19.09/0.7100 HRGAN[20 ] CVPR 2019 21.56/0.8550 SwinIR[25 ] CVPR 2021 23.23/0.8685 PCNet[29 ] TIP 2021 26.19/0.9015 MPRNet[30 ] CVPR 2021 28.03/0.9192 Restormer[11 ] CVPR 2022 28.44 _ 0.9263 _ AWIR-TDM 29.13/0.9428
10.16183/j.cnki.jsjtu.2023.043.T0005 表5 不同算法在雨滴数据集Raindrop-A上的定量对比 ...
Single image deraining: A comprehensive benchmark analysis
1
2019
... 此外,为验证算法恢复自然天气退化图像的表现,选用文献[14 ]中提供的雪数据集Snow,其中包括1 329幅自然雪图,同时还选用来自文献[21 ]的雨滴数据集Raindrop、雨雾数据集RainMist和雨痕数据集RainStreak,其分别包括67、13和185幅自然天气退化图像. ...
Recurrent squeeze-and-excitation context aggregation net for single image deraining
1
2018
... Quantitative comparison of different methods on Snow100K dataset
Tab.3 方法 源 Snow100K-L Snow100K-M Snow100K-S 平均指标 RESCAN[22 ] ECCV 2018 26.08/0.8108 29.95/0.8860 31.51/0.9032 29.28/0.8667 SPANet[23 ] CVPR 2019 23.70/0.7930 28.06/0.8680 29.92/0.8260 27.23/0.8290 DesnowNet[14 ] TIP 2018 27.17/ 0.8983 _ 30.87/0.9409 32.33/0.9500 30.12/ 0.9300 _ JSTASR[24 ] ECCV 2020 25.32/0.8076 29.11/0.8843 31.40/0.9012 28.61/0.8644 SwinIR[25 ] CVPR 2021 28.18/0.8800 31.42/0.9284 33.96/ 0.9567 _ 31.19/0.9217 DDMSNet[26 ] TIP 2021 28.85/0.8772 32.89/0.9330 34.34/0.9445 32.03/0.9182 TransWeather[4 ] CVPR 2022 29.21 _ 33.41 _ 0.9416 _ 34.92 _ 32.51 _ AWIR-TDM 30.64/0.9193 35.26/0.9472 37.05/0.9680 34.32/0.9448
10.16183/j.cnki.jsjtu.2023.043.T0004 表4 不同算法在雨雾数据集Test1上的定量对比 ...
Spatial attentive single-image deraining with a high quality real rain dataset
1
2019
... Quantitative comparison of different methods on Snow100K dataset
Tab.3 方法 源 Snow100K-L Snow100K-M Snow100K-S 平均指标 RESCAN[22 ] ECCV 2018 26.08/0.8108 29.95/0.8860 31.51/0.9032 29.28/0.8667 SPANet[23 ] CVPR 2019 23.70/0.7930 28.06/0.8680 29.92/0.8260 27.23/0.8290 DesnowNet[14 ] TIP 2018 27.17/ 0.8983 _ 30.87/0.9409 32.33/0.9500 30.12/ 0.9300 _ JSTASR[24 ] ECCV 2020 25.32/0.8076 29.11/0.8843 31.40/0.9012 28.61/0.8644 SwinIR[25 ] CVPR 2021 28.18/0.8800 31.42/0.9284 33.96/ 0.9567 _ 31.19/0.9217 DDMSNet[26 ] TIP 2021 28.85/0.8772 32.89/0.9330 34.34/0.9445 32.03/0.9182 TransWeather[4 ] CVPR 2022 29.21 _ 33.41 _ 0.9416 _ 34.92 _ 32.51 _ AWIR-TDM 30.64/0.9193 35.26/0.9472 37.05/0.9680 34.32/0.9448
10.16183/j.cnki.jsjtu.2023.043.T0004 表4 不同算法在雨雾数据集Test1上的定量对比 ...
JSTASR: Joint size and transparency-aware snow removal algorithm based on modified partial convolution and veiling effect removal
1
2020
... Quantitative comparison of different methods on Snow100K dataset
Tab.3 方法 源 Snow100K-L Snow100K-M Snow100K-S 平均指标 RESCAN[22 ] ECCV 2018 26.08/0.8108 29.95/0.8860 31.51/0.9032 29.28/0.8667 SPANet[23 ] CVPR 2019 23.70/0.7930 28.06/0.8680 29.92/0.8260 27.23/0.8290 DesnowNet[14 ] TIP 2018 27.17/ 0.8983 _ 30.87/0.9409 32.33/0.9500 30.12/ 0.9300 _ JSTASR[24 ] ECCV 2020 25.32/0.8076 29.11/0.8843 31.40/0.9012 28.61/0.8644 SwinIR[25 ] CVPR 2021 28.18/0.8800 31.42/0.9284 33.96/ 0.9567 _ 31.19/0.9217 DDMSNet[26 ] TIP 2021 28.85/0.8772 32.89/0.9330 34.34/0.9445 32.03/0.9182 TransWeather[4 ] CVPR 2022 29.21 _ 33.41 _ 0.9416 _ 34.92 _ 32.51 _ AWIR-TDM 30.64/0.9193 35.26/0.9472 37.05/0.9680 34.32/0.9448
10.16183/j.cnki.jsjtu.2023.043.T0004 表4 不同算法在雨雾数据集Test1上的定量对比 ...
Swinir: Image restoration using swin transformer
3
2021
... Quantitative comparison of different methods on Snow100K dataset
Tab.3 方法 源 Snow100K-L Snow100K-M Snow100K-S 平均指标 RESCAN[22 ] ECCV 2018 26.08/0.8108 29.95/0.8860 31.51/0.9032 29.28/0.8667 SPANet[23 ] CVPR 2019 23.70/0.7930 28.06/0.8680 29.92/0.8260 27.23/0.8290 DesnowNet[14 ] TIP 2018 27.17/ 0.8983 _ 30.87/0.9409 32.33/0.9500 30.12/ 0.9300 _ JSTASR[24 ] ECCV 2020 25.32/0.8076 29.11/0.8843 31.40/0.9012 28.61/0.8644 SwinIR[25 ] CVPR 2021 28.18/0.8800 31.42/0.9284 33.96/ 0.9567 _ 31.19/0.9217 DDMSNet[26 ] TIP 2021 28.85/0.8772 32.89/0.9330 34.34/0.9445 32.03/0.9182 TransWeather[4 ] CVPR 2022 29.21 _ 33.41 _ 0.9416 _ 34.92 _ 32.51 _ AWIR-TDM 30.64/0.9193 35.26/0.9472 37.05/0.9680 34.32/0.9448
10.16183/j.cnki.jsjtu.2023.043.T0004 表4 不同算法在雨雾数据集Test1上的定量对比 ...
... Quantitative comparison of different methods on Test1 dataset
Tab.4 方法 源 Test1 PSNR/SSIM CycleGAN[27 ] ICCV 2017 17.62/0.6560 pix2pix[28 ] CVPR 2017 19.09/0.7100 HRGAN[20 ] CVPR 2019 21.56/0.8550 SwinIR[25 ] CVPR 2021 23.23/0.8685 PCNet[29 ] TIP 2021 26.19/0.9015 MPRNet[30 ] CVPR 2021 28.03/0.9192 Restormer[11 ] CVPR 2022 28.44 _ 0.9263 _ AWIR-TDM 29.13/0.9428
10.16183/j.cnki.jsjtu.2023.043.T0005 表5 不同算法在雨滴数据集Raindrop-A上的定量对比 ...
... Quantitative comparison of different methods on Raindrop-A dataset
Tab.5 方法 源 Raindrop-A PSNR/SSIM pix2pix[28 ] CVPR 2017 28.02/0.8547 Attn. GAN[17 ] CVPR 2018 31.59/0.9170 DuRN[31 ] CVPR 2019 31.24/0.9259 RaindropAttn[32 ] ICCV 2019 31.44/0.9263 SwinIR[25 ] CVPR 2021 30.82/0.9035 CCN[33 ] CVPR 2021 31.34/ 0.9500 _ IDT[34 ] TPAMI 2022 31.87 _ AWIR-TDM 32.84/0.9571
本文算法在Snow100K的测试集上平均PSNR高出1.81~7.09 dB; 相比现有图像去雨雾算法,本文算法在Test1测试集上平均PSNR高出0.69~11.51 dB;相比现有去雨滴算法,本文算法在Raindrop-A测试集上平均PSNR高出0.79~4.82 dB.因此,本文算法不仅可以作为多天气退化图像恢复算法,还可以作为统一型天气退化图像恢复方法,并且在两种情况下均超越现有表现良好的方法. ...
Deep dense multi-scale network for snow removal using semantic and depth priors
1
2021
... Quantitative comparison of different methods on Snow100K dataset
Tab.3 方法 源 Snow100K-L Snow100K-M Snow100K-S 平均指标 RESCAN[22 ] ECCV 2018 26.08/0.8108 29.95/0.8860 31.51/0.9032 29.28/0.8667 SPANet[23 ] CVPR 2019 23.70/0.7930 28.06/0.8680 29.92/0.8260 27.23/0.8290 DesnowNet[14 ] TIP 2018 27.17/ 0.8983 _ 30.87/0.9409 32.33/0.9500 30.12/ 0.9300 _ JSTASR[24 ] ECCV 2020 25.32/0.8076 29.11/0.8843 31.40/0.9012 28.61/0.8644 SwinIR[25 ] CVPR 2021 28.18/0.8800 31.42/0.9284 33.96/ 0.9567 _ 31.19/0.9217 DDMSNet[26 ] TIP 2021 28.85/0.8772 32.89/0.9330 34.34/0.9445 32.03/0.9182 TransWeather[4 ] CVPR 2022 29.21 _ 33.41 _ 0.9416 _ 34.92 _ 32.51 _ AWIR-TDM 30.64/0.9193 35.26/0.9472 37.05/0.9680 34.32/0.9448
10.16183/j.cnki.jsjtu.2023.043.T0004 表4 不同算法在雨雾数据集Test1上的定量对比 ...
Unpaired image-to-image translation using cycle-consistent adversarial networks
1
2017
... Quantitative comparison of different methods on Test1 dataset
Tab.4 方法 源 Test1 PSNR/SSIM CycleGAN[27 ] ICCV 2017 17.62/0.6560 pix2pix[28 ] CVPR 2017 19.09/0.7100 HRGAN[20 ] CVPR 2019 21.56/0.8550 SwinIR[25 ] CVPR 2021 23.23/0.8685 PCNet[29 ] TIP 2021 26.19/0.9015 MPRNet[30 ] CVPR 2021 28.03/0.9192 Restormer[11 ] CVPR 2022 28.44 _ 0.9263 _ AWIR-TDM 29.13/0.9428
10.16183/j.cnki.jsjtu.2023.043.T0005 表5 不同算法在雨滴数据集Raindrop-A上的定量对比 ...
Image-to-image translation with conditional adversarial networks
2
2017
... Quantitative comparison of different methods on Test1 dataset
Tab.4 方法 源 Test1 PSNR/SSIM CycleGAN[27 ] ICCV 2017 17.62/0.6560 pix2pix[28 ] CVPR 2017 19.09/0.7100 HRGAN[20 ] CVPR 2019 21.56/0.8550 SwinIR[25 ] CVPR 2021 23.23/0.8685 PCNet[29 ] TIP 2021 26.19/0.9015 MPRNet[30 ] CVPR 2021 28.03/0.9192 Restormer[11 ] CVPR 2022 28.44 _ 0.9263 _ AWIR-TDM 29.13/0.9428
10.16183/j.cnki.jsjtu.2023.043.T0005 表5 不同算法在雨滴数据集Raindrop-A上的定量对比 ...
... Quantitative comparison of different methods on Raindrop-A dataset
Tab.5 方法 源 Raindrop-A PSNR/SSIM pix2pix[28 ] CVPR 2017 28.02/0.8547 Attn. GAN[17 ] CVPR 2018 31.59/0.9170 DuRN[31 ] CVPR 2019 31.24/0.9259 RaindropAttn[32 ] ICCV 2019 31.44/0.9263 SwinIR[25 ] CVPR 2021 30.82/0.9035 CCN[33 ] CVPR 2021 31.34/ 0.9500 _ IDT[34 ] TPAMI 2022 31.87 _ AWIR-TDM 32.84/0.9571
本文算法在Snow100K的测试集上平均PSNR高出1.81~7.09 dB; 相比现有图像去雨雾算法,本文算法在Test1测试集上平均PSNR高出0.69~11.51 dB;相比现有去雨滴算法,本文算法在Raindrop-A测试集上平均PSNR高出0.79~4.82 dB.因此,本文算法不仅可以作为多天气退化图像恢复算法,还可以作为统一型天气退化图像恢复方法,并且在两种情况下均超越现有表现良好的方法. ...
Rain-free and residue hand-in-hand: A progressive coupled network for real-time image deraining
1
2021
... Quantitative comparison of different methods on Test1 dataset
Tab.4 方法 源 Test1 PSNR/SSIM CycleGAN[27 ] ICCV 2017 17.62/0.6560 pix2pix[28 ] CVPR 2017 19.09/0.7100 HRGAN[20 ] CVPR 2019 21.56/0.8550 SwinIR[25 ] CVPR 2021 23.23/0.8685 PCNet[29 ] TIP 2021 26.19/0.9015 MPRNet[30 ] CVPR 2021 28.03/0.9192 Restormer[11 ] CVPR 2022 28.44 _ 0.9263 _ AWIR-TDM 29.13/0.9428
10.16183/j.cnki.jsjtu.2023.043.T0005 表5 不同算法在雨滴数据集Raindrop-A上的定量对比 ...
Multi-stage progressive image restoration
1
2021
... Quantitative comparison of different methods on Test1 dataset
Tab.4 方法 源 Test1 PSNR/SSIM CycleGAN[27 ] ICCV 2017 17.62/0.6560 pix2pix[28 ] CVPR 2017 19.09/0.7100 HRGAN[20 ] CVPR 2019 21.56/0.8550 SwinIR[25 ] CVPR 2021 23.23/0.8685 PCNet[29 ] TIP 2021 26.19/0.9015 MPRNet[30 ] CVPR 2021 28.03/0.9192 Restormer[11 ] CVPR 2022 28.44 _ 0.9263 _ AWIR-TDM 29.13/0.9428
10.16183/j.cnki.jsjtu.2023.043.T0005 表5 不同算法在雨滴数据集Raindrop-A上的定量对比 ...
Dual residual networks leveraging the potential of paired operations for image restoration
1
2019
... Quantitative comparison of different methods on Raindrop-A dataset
Tab.5 方法 源 Raindrop-A PSNR/SSIM pix2pix[28 ] CVPR 2017 28.02/0.8547 Attn. GAN[17 ] CVPR 2018 31.59/0.9170 DuRN[31 ] CVPR 2019 31.24/0.9259 RaindropAttn[32 ] ICCV 2019 31.44/0.9263 SwinIR[25 ] CVPR 2021 30.82/0.9035 CCN[33 ] CVPR 2021 31.34/ 0.9500 _ IDT[34 ] TPAMI 2022 31.87 _ AWIR-TDM 32.84/0.9571
本文算法在Snow100K的测试集上平均PSNR高出1.81~7.09 dB; 相比现有图像去雨雾算法,本文算法在Test1测试集上平均PSNR高出0.69~11.51 dB;相比现有去雨滴算法,本文算法在Raindrop-A测试集上平均PSNR高出0.79~4.82 dB.因此,本文算法不仅可以作为多天气退化图像恢复算法,还可以作为统一型天气退化图像恢复方法,并且在两种情况下均超越现有表现良好的方法. ...
Deep learning for seeing through window with raindrops
1
2019
... Quantitative comparison of different methods on Raindrop-A dataset
Tab.5 方法 源 Raindrop-A PSNR/SSIM pix2pix[28 ] CVPR 2017 28.02/0.8547 Attn. GAN[17 ] CVPR 2018 31.59/0.9170 DuRN[31 ] CVPR 2019 31.24/0.9259 RaindropAttn[32 ] ICCV 2019 31.44/0.9263 SwinIR[25 ] CVPR 2021 30.82/0.9035 CCN[33 ] CVPR 2021 31.34/ 0.9500 _ IDT[34 ] TPAMI 2022 31.87 _ AWIR-TDM 32.84/0.9571
本文算法在Snow100K的测试集上平均PSNR高出1.81~7.09 dB; 相比现有图像去雨雾算法,本文算法在Test1测试集上平均PSNR高出0.69~11.51 dB;相比现有去雨滴算法,本文算法在Raindrop-A测试集上平均PSNR高出0.79~4.82 dB.因此,本文算法不仅可以作为多天气退化图像恢复算法,还可以作为统一型天气退化图像恢复方法,并且在两种情况下均超越现有表现良好的方法. ...
Removing raindrops and rain streaks in one go
1
2021
... Quantitative comparison of different methods on Raindrop-A dataset
Tab.5 方法 源 Raindrop-A PSNR/SSIM pix2pix[28 ] CVPR 2017 28.02/0.8547 Attn. GAN[17 ] CVPR 2018 31.59/0.9170 DuRN[31 ] CVPR 2019 31.24/0.9259 RaindropAttn[32 ] ICCV 2019 31.44/0.9263 SwinIR[25 ] CVPR 2021 30.82/0.9035 CCN[33 ] CVPR 2021 31.34/ 0.9500 _ IDT[34 ] TPAMI 2022 31.87 _ AWIR-TDM 32.84/0.9571
本文算法在Snow100K的测试集上平均PSNR高出1.81~7.09 dB; 相比现有图像去雨雾算法,本文算法在Test1测试集上平均PSNR高出0.69~11.51 dB;相比现有去雨滴算法,本文算法在Raindrop-A测试集上平均PSNR高出0.79~4.82 dB.因此,本文算法不仅可以作为多天气退化图像恢复算法,还可以作为统一型天气退化图像恢复方法,并且在两种情况下均超越现有表现良好的方法. ...
Image de-raining transformer
1
2022
... Quantitative comparison of different methods on Raindrop-A dataset
Tab.5 方法 源 Raindrop-A PSNR/SSIM pix2pix[28 ] CVPR 2017 28.02/0.8547 Attn. GAN[17 ] CVPR 2018 31.59/0.9170 DuRN[31 ] CVPR 2019 31.24/0.9259 RaindropAttn[32 ] ICCV 2019 31.44/0.9263 SwinIR[25 ] CVPR 2021 30.82/0.9035 CCN[33 ] CVPR 2021 31.34/ 0.9500 _ IDT[34 ] TPAMI 2022 31.87 _ AWIR-TDM 32.84/0.9571
本文算法在Snow100K的测试集上平均PSNR高出1.81~7.09 dB; 相比现有图像去雨雾算法,本文算法在Test1测试集上平均PSNR高出0.69~11.51 dB;相比现有去雨滴算法,本文算法在Raindrop-A测试集上平均PSNR高出0.79~4.82 dB.因此,本文算法不仅可以作为多天气退化图像恢复算法,还可以作为统一型天气退化图像恢复方法,并且在两种情况下均超越现有表现良好的方法. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}