

光滑粒子流体动力学(Smoothed Particle Hydrodynamics,SPH)对模拟自由表面流动问题具有先天优势,但随着粒子数量的增加,尤其是三维流动问题,计算效率急剧降低,极大限制了该方法在大规模计算中的适用性.利用图形处理器(GPU)众核架构开展多核并行计算的计算机统一设备架构(CUDA)技术,其强大的并行特性非常适合解决大规模的高级计算问题[1],尤其是计算密集型问题.SPH计算能力密集的特性使其能容易地在GPU上实现并行运算,因此一些学者开始尝试将GPU技术应用于SPH方法.Harada等[2]首次描述了SPH方法在GPU上的实现,Crespo等[3]将GPU加速的SPH方法应用于模拟复杂的自由表面流动.他们的研究均表明在单个GPU上的SPH模拟比在单核中央处理器(CPU)上进行的SPH模拟要快两个数量级.目前SPH方法在GPU平台下的计算研究发展迅速,GPU加速的SPH模型已应用于颗粒流体流动的模拟和浅水方程的求解[4-5],并通过结合自适应粒子技术[6]实现了高效计算.国内,徐锋[7]在实现了基于GPU众核架构的并行SPH算法的同时,结合所使用的GPU硬件上的特点,对并行算法进行了优化,将计算效率提高了20倍以上;金善勤等[8]提出一种基于粒子对的并行计算方法并将其与改进的SPH方法结合,实现了超过10的加速比;杨志国等[9]将GPU算法应用于二维溃坝模拟中也获得了数量级的加速效果.
但是,GPU的系统设计理念与CPU正好相反,GPU面对的是类型一致、互不关联的大量数据,其显存的读写对算法求解效率影响很大.随着流场的不断演变,SPH粒子的无序化很容易导致多个线程同时读写同一地址而引起访问冲突,极大地影响了计算效率的稳定性.针对此问题,并行索引排序方法[3,10]、Z索引排序方法[11]及其改进方法[12]相继被提出,这些方法通过优化SPH粒子索引存储方式使同单元粒子在GPU显存中尽可能相邻,一定程度上改善了GPU显存访问的不连续问题,但没有从实质上改变单元粒子的无序化.为此,本文提出了一种粒子重新编号技术,实现了SPH粒子的有序排列和GPU显存的连续访问,并将该方法应用于三维带障碍物溃坝模拟,通过与实验数据比较以及不同硬件设施上不同算法求解效率的对比,验证了本文方法的精确性和高效性.
1 SPH的控制方程
SPH控制方程的离散形式可表示为
式中:
式中:r为两粒子间距离;h为光滑长度;q为粒子间相对距离,
人工黏性为
式中:
α为控制速度耗散强度的系数,通常为0~0.5,取0.015;平均声速
假定流体弱可压缩,采用Monaghan等[14]提出的人工压缩法求解压强:
式中:ρ0为参考密度,取ρ0=1 000 kg/m3;patm为大气压力;γ为常数,γ=7;c0为人工声速,为确保密度波动低于1%ρ0,本文取
2 CUDA-GPU架构下的SPH模型
2.1 并行算法的实现流程
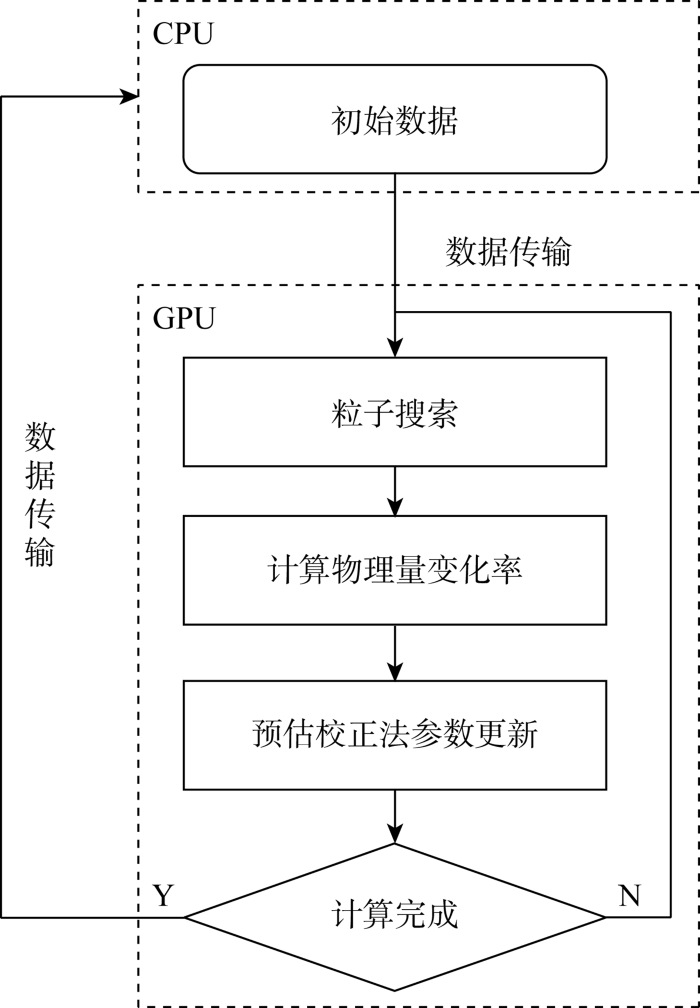
针对现代CUDA-GPU架构设计了一种高效的SPH流体数据,以提高SPH流体模拟在GPU上的数据处理速度.并行代码使用C#语言和CUDA编程语言进行开发,大多数源代码都是CPU和GPU所共有的,可以在CPU或GPU上执行,也可以在没有启用GPU的工作站上运行,只使用CPU实现.并行算法实现的流程如图1所示,粒子信息的初始数据存储在CPU中,将数据传输到GPU中之后,后续的所有计算都在GPU中进行,即所有涉及粒子循环的任务执行都是由GPU的并行结构来完成的.在完成控制方程求解和粒子物理量更新之后,将更新后的粒子物理量从GPU再次传输到CPU进行保存和输出.
图1
2.2 粒子搜索
图2
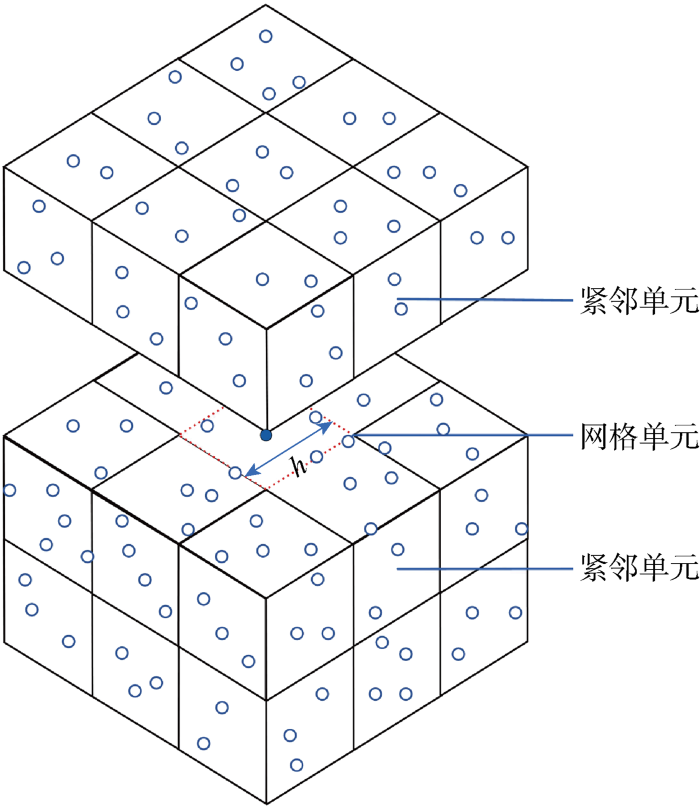
图2
三维相邻粒子链表搜索法示意图
Fig.2
Sketch for three-dimensional neighbor list search method
2.3 粒子重新编号技术
图3

该方法主要包含以下步骤:
(1) 遍历所有SPH粒子,计算每个粒子所在网格索引,统计该索引所在网格存储SPH粒子数量,存储于数组IDCount中.
(2) 创建数组IDBegin,记录新粒子编号中每个网格中首粒子编号,对于网格m有IDBegin[m] = IDBegin[m-1] + IDCount[m-1];
(3) 清空数组IDCount;
(4) 遍历所有SPH粒子,重新统计该索引所在网格存储SPH粒子数量,根据粒子所在网格索引,对其重新编号,如对于某SPH粒子,其对于网格索引为n,其新的粒子编号为IDBegin[n] + IDCount[n],其中IDCount[n]为统计至该粒子时网格n中存储的SPH粒子数量,最终得到的重新粒子编号效果如图3(b)所示.
3 结果验证与分析
以SPH法验证自由表面流动问题的基准测试案例——溃坝问题为研究对象,对三维带障碍物的溃坝进行数值模拟,通过与实验数据进行对比验证本文并行算法的可靠性和有效性.
3.1 溃坝模型
图4
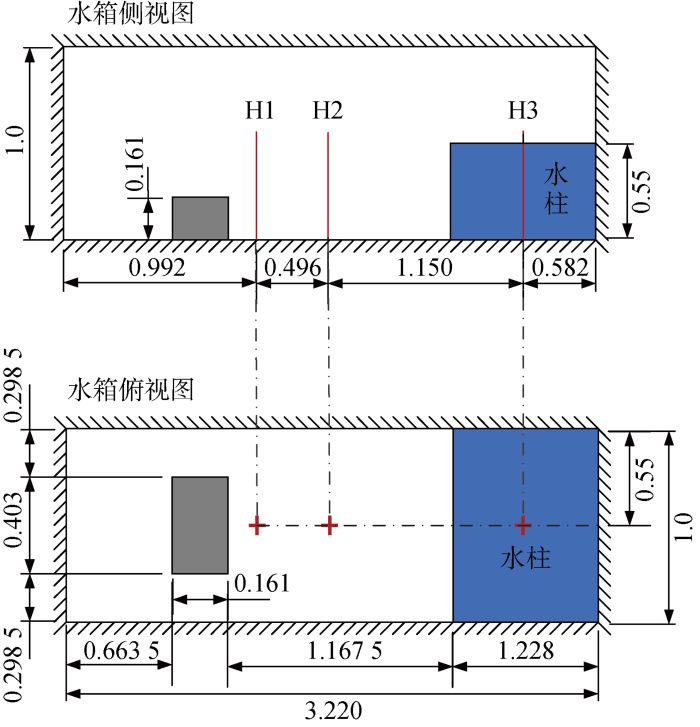
图4
试验配置和试验数据的测量位置(m)
Fig.4
Experimental configuration and measurement position of experimental data (m)
3.2 结果对比
数值模拟选取初始粒子间距为0.01 m、流场实粒子总数为 676 500,时间步长为0.1 ms.为验证本文粒子重新编号方法的准确性,对不同位置处的水深展开比较研究.图5所示为 H1、H2和H3位置处不同时刻的水深粒子重新编号前后计算值和实验值的比较.图中:hw为水柱高度.可见粒子重新编号前后计算值基本一致,不会对精度造成影响;在初始水柱中间(H3)、箱体中部(H2)、障碍物前缘附近(H1),本文计算值与实验值的趋势和大小都很接近.图中H3探头清晰地再现了溃坝的整个过程,在最初的2 s内水柱坍塌,相应地,这段时间的水位也不断下降,而在其他探头中,水流依次到达H2和H1.在1.75 s后,反射的水波撞击左墙后反向移动,第2次撞击障碍物以及右墙,同时,水深达到第2个峰值(H1的水深峰值时刻大概为4.8 s,H2为 4.6 s,H3为3.8 s).本文计算的水深与实验水深随时间的变化趋势大致相同,表明本文方法具有良好的计算精度.
图5
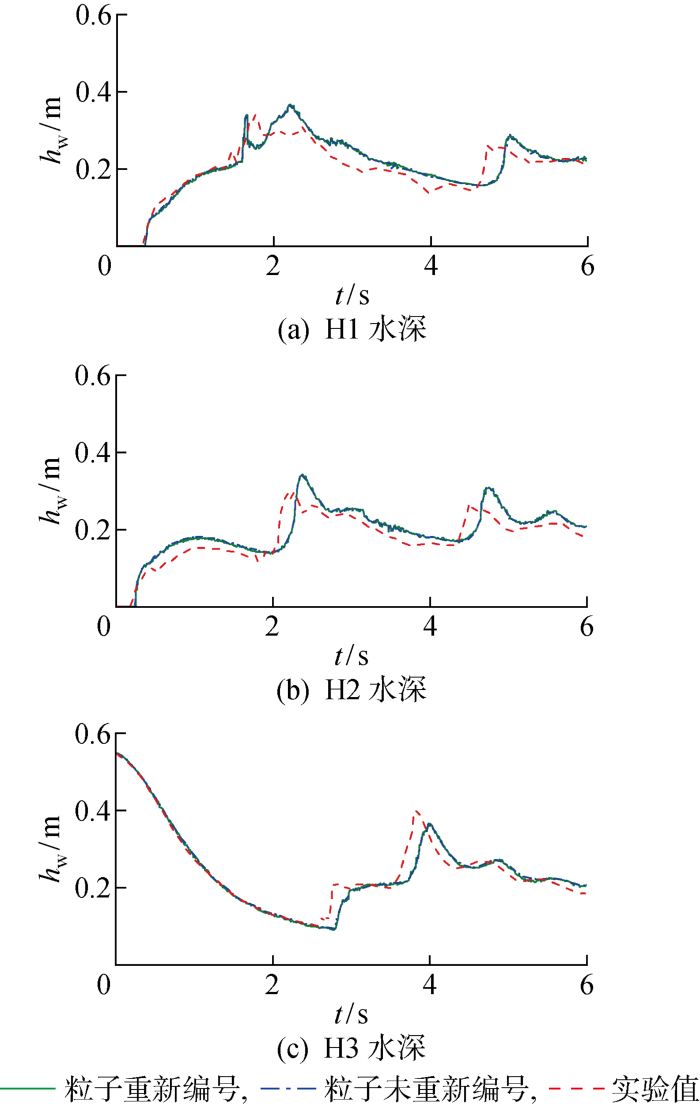
图5
实验测量和本文模拟的探测点处的垂直水柱高度比较
Fig.5
Comparation of vertical water heights at the detection point measured experimentally and simulated in this paper
4 效率测试结果与分析
4.1 测试平台
通过比较CPU串行、CPU并行、GPU并行SPH算法三维带障碍物溃坝数值模拟计算耗时,验证本文所采用GPU算法求解效率.为保证计算结果的适用性,分别在不同的CPU、GPU硬件上运行SPH算法,具体配置如表1所示.
表1 CPU和GPU配置
Tab.1
| 设备类型 | 型号 | 核数 | 主频/GHz |
|---|---|---|---|
| CPU | Intel Core i9-10900F | 10 | 2.8 |
| Xeon®Gold 6268CL | 48 | 2.8 | |
| GPU | GTX 1660 super | 1 408 | 1.785 |
| GeForce RTX 2080 | 2 944 | 1. 4 | |
| GeForce RTX 3080Ti | 10 240 | 1.67 |
4.2 GPU算法粒子重新编号效果对比
图6为实粒子总数676 500时不同硬件条件下粒子重新编号和未重新编号GPU加速SPH算法单步运行时间(ts)对比.图中:sn为计算步数.由图可见,本文采用的粒子重新编号算法在不同硬件上都获得了稳定的单步运行时间,而粒子未重新编号时,随着流场中粒子的无序化导致GPU显存访问冲突,其单步运行时间呈对数增长,算例表明本文所采用的粒子重新编号方法可以保证稳定的单步运行时间,是有效的.
图6
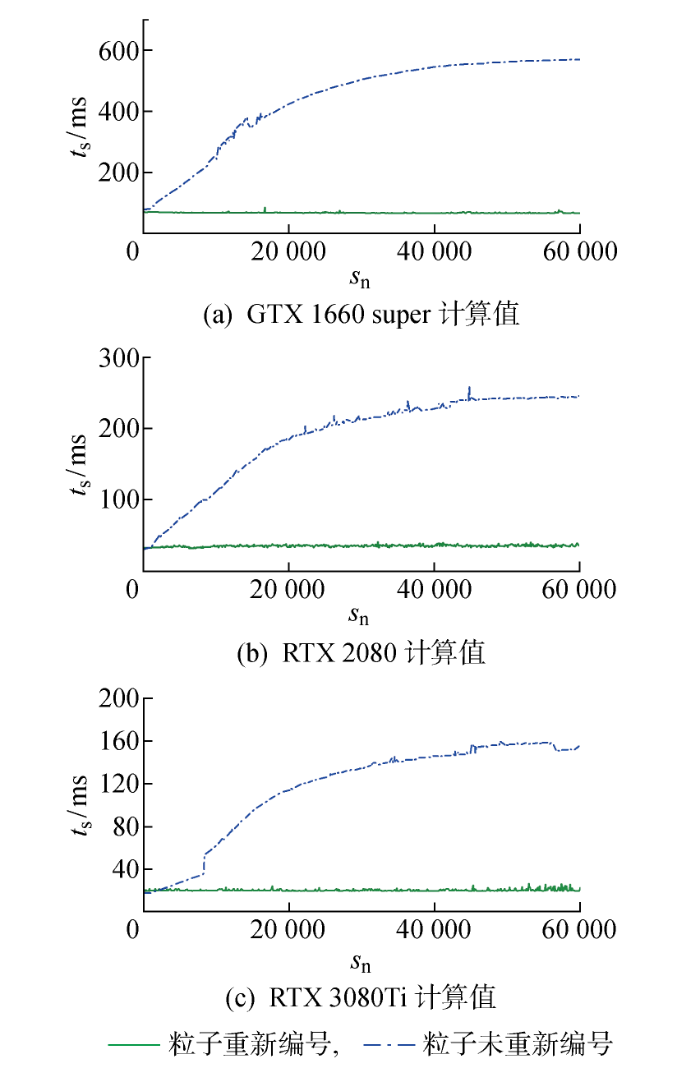
图6
粒子重新编号和未重新编号单步运行时间对比
Fig.6
Comparison of step running time between reorder and non-reorder method
4.3 算法求解效率对比
图7
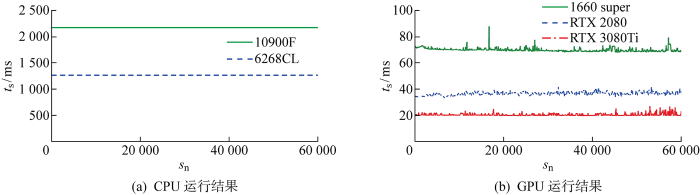
图7
CPU并行和GPU算法单步运行时间对比
Fig.7
Comparison of step running time between CPU parallel and GPU parallel
图8
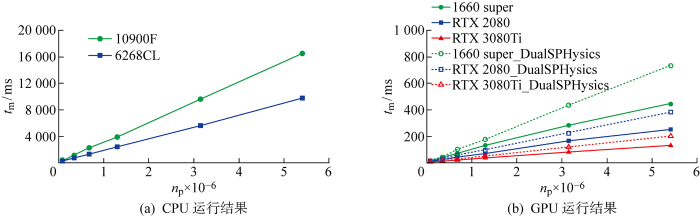
图8
不同实粒子总数下CPU与GPU运行时间的对比
Fig.8
Comparison of running time between CPU and GPU at different number of particles
表2 各硬件核数和效率比
Tab.2
| 硬件 | 核数比 | 效率比 | 核数/效率 |
|---|---|---|---|
| Intel Core i9-10900F | 1 | 1 | 1 |
| Xeon®Gold 6268CL | 4.8 | 1.73 | 2.78 |
| GTX 1660 super | 140.8 | 31.05 | 4.53 |
| GeForce RTX 2080 | 294.4 | 59.04 | 4.99 |
| GeForce RTX 3080Ti | 1 024 | 104.8 | 9.76 |
为进一步验证本文粒子重新编号算法的有效性,对不同实粒子数下GPU算法并行效率与开源软件DualSPHysics进行了对比,如图8(b)所示,可见同实粒子总数、同硬件设备条件下,本文方法平均单步运行时间均小于DualSPHysics软件,算例表明本文粒子重新编号方法具有良好的效率优势.
5 结论
运用粒子重新编号技术开发了一套高效GPU-SPH并行算法,将该算法应用于三维带障碍物溃坝问题,并对算法求解效率进行了比较研究,得到以下结论:
(1) 粒子重新编号前后计算值基本一致,不会对精度造成影响,与试验值的对比表明本文所采用的方法精确有效.
(2) 粒子重新编号技术能够有效解决GPU-SPH算法中的显存访问冲突问题.
(3) GPU并行算法能够大幅提高SPH方法求解效率,随着粒子数量的增加,其大幅缩短计算时间的优势愈发明显.
参考文献
基于GPU 的近场动力学模拟的并行化方法
[J].
Parallel computing method of peridynamic models based on GPU
[J].
Smoothed particle hydrodynamics on GPUs
[C]
GPUs, a new tool of acceleration in CFD: Efficiency and reliability on smoothed particle hydrodynamics methods
[J].
A GPU-based coupled SPH-DEM method for particle-fluid flow with free surfaces
[J].DOI:10.1016/j.powtec.2018.07.043 URL [本文引用: 1]
A GPU-accelerated smoothed particle hydrodynamics (SPH) model for the shallow water equations
[J].
GPU-accelerated adaptive particle splitting and merging in SPH
[J].DOI:10.1016/j.cpc.2013.02.021 URL [本文引用: 1]
基于GPU 并行的改进SPH 方法对黏性流场的模拟
[J].
Viscosity flow simulation using improved SPH method based on GPU parallel calculation
[J].
GPU在SPH方法模拟溃坝问题的应用研究
[J].
The application research of GPU in the SPH method to simulate the dam breaking problem
[J].
GAPI: GPU 加速的移动对象并行索引方法
[J].
DOI:10.3778/j.issn.1673-9418.1608038
[本文引用: 1]

为减少加锁操作对移动对象数据库并行性能的影响并提高其吞吐量,提出一种由GPU加速的网格结合四叉树的索引方法。采用由GPU对出入节点对象进行计数并持续计算节点拆分/合并条件的方式,在不影响CPU计算能力的前提下,将存在性能瓶颈的网格节点转化为四叉树,从而减少对象数据更新时加锁操作造成的其他线程等待时间。该方法结构简单且更适用于对象不均匀分布的场景,避免了现有索引方式或在热点区域存在性能瓶颈,或需花费大量计算资源进行结构平衡等缺点。实验结果表明,该方法与现有移动对象索引方式相比具有数据吞吐量大、响应速度快等特点,在移动对象空间分布不均匀的场景下其优势更为明显。
GAPI: GPU accelerated parallel method for indexing moving objects
[J].
A parallel SPH implementation on multi-core CPUs
[J].DOI:10.1111/j.1467-8659.2010.01832.x URL [本文引用: 1]
Piecewise polynomial, positive definite and compactly supported radial functions of minimal degree
[J].DOI:10.1007/BF02123482 URL [本文引用: 1]
Shock simulation by the particle method SPH
[J].DOI:10.1016/0021-9991(83)90036-0 URL [本文引用: 1]
Particle methods for hydrodynamics
[J].DOI:10.1016/0167-7977(85)90010-3 URL [本文引用: 1]
A volume-of-fluid based simulation method for wave impact problems
[J].DOI:10.1016/j.jcp.2004.12.007 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}