

在工业生产过程中,焊接工艺被广泛运用,是工业制造过程的重要一环[1].由于焊接操作不当及焊件本身材料特性等原因,焊缝表面及内部可能会产生一定的缺陷,焊缝内部缺陷包括气孔、裂纹、焊穿及未熔合等[2],这些缺陷会严重影响焊接部位的疲劳强度和使用寿命[3],进而降低产品的整体质量,带来较大的安全隐患,因此需要对焊接部位进行严格的质量检测.焊缝内部缺陷常用的检测方法有射线探测法[4],为了更精准地了解焊缝内部缺陷情况,可以对焊缝横截面处的金相组织进行缺陷检测[5].许多场景都需要对焊缝进行缺陷分类,但目前对金相组织图片进行自动化缺陷分类的研究较少,而对焊缝X射线图片进行缺陷分类的研究已有一定基础[6⇓-8],这些缺陷分类方法也可较好地应用于金相组织图片分类.
传统焊缝缺陷分类通常由人工完成,劳动强度大、效率低且易因视觉疲劳造成一定的误检[9].随着机器学习及计算机视觉技术的快速发展, 基于机器学习的计算机视觉技术已被广泛运用于焊缝缺陷分类,极大提高了缺陷分类的效率及准确度.罗爱民等[10]将二叉树与支持向量机(SVM)结合,对6类且每类含130张图片的焊缝X射线图像进行分类,最终每类的分类准确度均在87%以上;Duan等[6]利用机器学习之自适应增强(AdaBoost)对5类焊缝X射线图像缺陷进行分类,取得了85.5%的分类准确度和91.66%的真阳性率(True Positive Rate);刘欢等[11]提出了CC-ResNet对焊缝X射线图像进行缺陷分类,将ResNet每一层卷积变为两个不同尺度的卷积,将结果在深度方向进行拼接,充分利用多尺度信息,取得了98.52%的平均召回率及95.23%的平均准确度;谷静等[12]提出了SINet模型,将Inception模块和SE模块进行组合,以提高网络对特征的提取及组合能力,最终得到了96.77%的分类准确度.上述论文中的训练数据均较多且不平衡程度较低,模型能有足够的数据学习相应的缺陷特征.
因焊缝金相组织图像数据中缺陷样本数量很少、图片分辨率较高且缺陷较为复杂,故很难通过生成对抗网络(GAN)模型进行数据扩充.针对这些问题,使用泊松融合的方法合成新的缺陷样本,从而达到数据增强的目的.同时,在ResNet18分类网络模型的基础上进行改进,提出ResNet18_PRO网络模型.具体安排如下:首先,具体介绍泊松融合的相关原理;其次,介绍ResNet18网络模型结构及ResNet18_PRO的相关设计,在此基础上阐述相关实验,包括缺陷样本合成实验及缺陷分类实验,并对实验结果进行相应分析,以此验证该数据增强方法对分类效果的提升作用,通过对ResNet18_PRO网络模型进行消融实验,分析网络各改进部分对分类效果的影响以验证各改进部分的有效性;最后,将ResNet18_PRO网络模型运用于其他工业缺陷数据集,以验证该模型的鲁棒性.
1 研究方法与原理
1.1 泊松融合原理
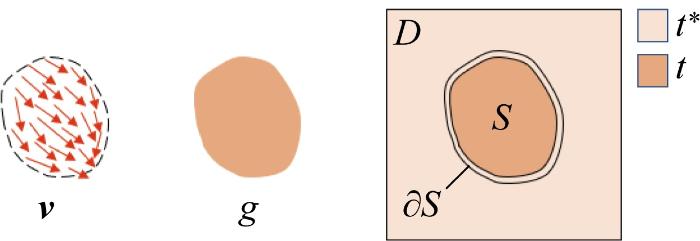
泊松融合主要利用融合区域的散度与源图像的散度相等及融合区域边界的像素值与目标图像在边界处的像素值相等两个条件,通过拉普拉斯算子构建相应的拉普拉斯方程,利用方程的解对融合区域各位置进行插值,如图1所示.图中,g为源图像函数(已知);v为g的引导场;D为合成后的整体图像区域;S为融合区域;∂S为融合区域边界;t为S区域的图像函数(未知待求);t*为目标图像在区域(D-S)的函数(已知).为使融合区S尽可能保持原来图像g的纹理信息,需要最小化S区域的梯度与v之间的差距.由于图像梯度可以较好地反映图像纹理信息,所以以g的梯度场Δg作为引导场,同时为保证融合区边界无明显过渡痕迹,使t*与t在边界∂S处保持相等,得到方程[18]如下:
图1
为便于表示,定义J=
式(2)的最优解t必须满足相应的欧拉-拉格朗日方程[19]:
得到最优解t满足的条件[18]为
由式(4)可知,要使S区域纹理信息与g中的纹理信息保持一致,两者的散度需要保持相等.图像f在(x,y)位置处的散度Δf(x,y)的计算公式为
缺陷融合具体步骤如下.
(1) 求解梯度场:求解目标图像和源图像的梯度场.
(2) 重建梯度场:用源图像梯度场对目标图像在融合位置处的梯度场进行置换,得到重建的梯度场.
(3) 重建散度场:对重建的梯度场进行求导,得到相应的散度场.
(4) 构建拉普拉斯方程:根据式(5)在融合区域用待求的像素值计算散度,与散度场中的值建立等式关系,同时令融合边界上的像素值直接等于目标区域在边界上的像素值,构建拉普拉斯方程.
(5) 对融合区域进行插值:求解拉普拉斯方程,并将方程的解赋值到融合区域的相应位置,得到融合图像.
1.2 ResNet18网络原理
图2
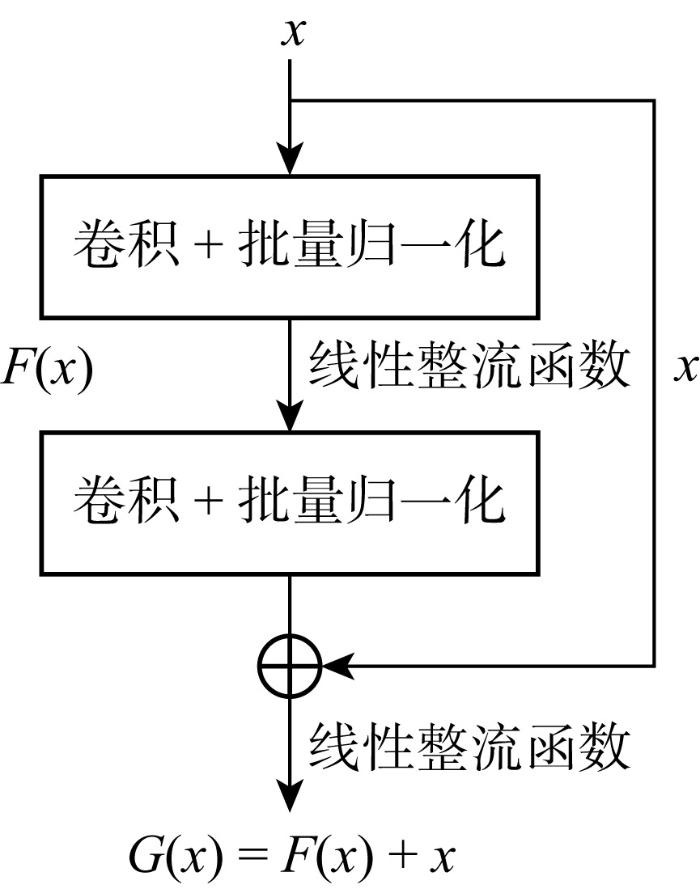
1.3 可学习的双池化结构
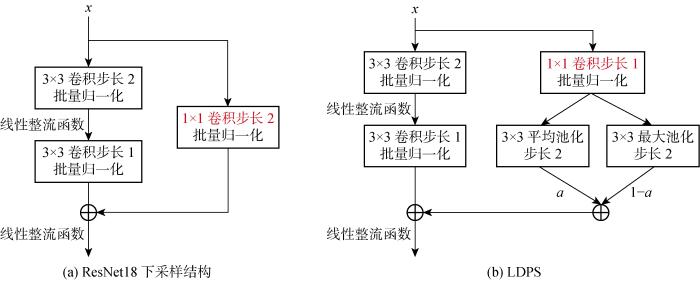
如图3中的红色虚线所示,每个层之间都需要对上一层输出的特征进行下采样以降低特征图尺寸,具体结构如图4(a)所示.Shortcut连接部分通过核尺寸(kernel size)为1×1的卷积并设置卷积步长(stride)为2来达到下采样目的,此过程中会损失较多细节信息,一定程度上会影响分类效果.为减少下采样过程中的信息损失,提出了LDPS.将原下采样中卷积操作步长改为1,通过核尺寸为3×3且步长为2的平均池化和最大池化操作实现下采样,如图4(b)所示,使被下采样特征层的所有位置信息都能被使用,进而极大减少了下采样过程中的信息损失.由于平均池化主要反映整体特征信息,而最大池化主要反映局部特征信息,所以通过两个可学习的向量对平均池化和最大池化所得的结果进行选择性利用,向量的长度与池化所得特征通道数相同,两向量对应元素的和为1,即对两个池化结果中对应的每一个通道进行线性组合,提高网络对局部特征和整体特征捕获能力,从而向下传递更有用的信息.
图3
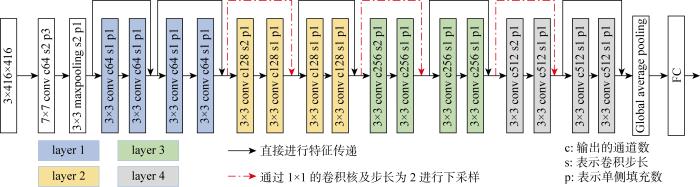
图4
1.4 改进的空间金字塔池化结构
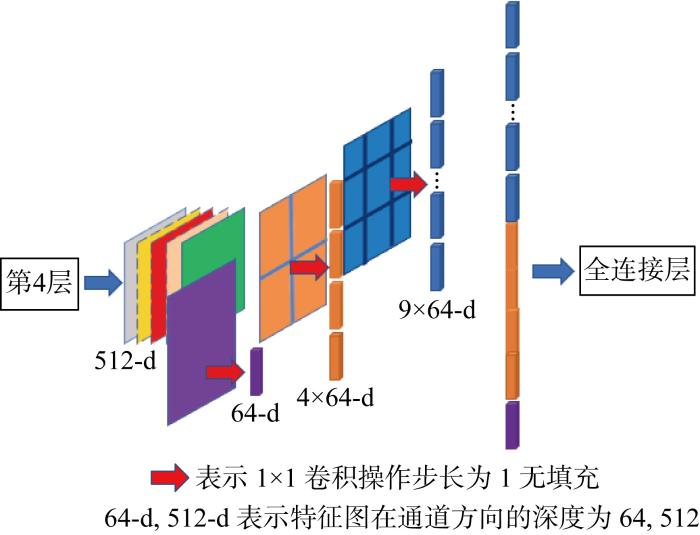
对于缺陷分类而言,由于缺陷本身的尺寸变化较大,所以要提高对缺陷的分类准确度,需提高网络对缺陷尺寸变化的捕获能力和整合能力.通过对下采样结构进行改进,减少下采样过程中的信息损失,综合利用局部特征和整体特征信息,提高网络对尺度变化的捕获能力.对于提高多尺度信息的整合能力,在网络末端增加了改进的空间金字塔池化(ISPP)结构.ISPP主要将空间金字塔池化(SPP)结构与1×1卷积相结合,从而提高对网络末端多尺度特征信息的聚合能力,如图5所示.首先使用SPP结构对第4层输出的特征进行多尺度池化, 共包含输出尺寸为1×1、2×2及3×3的3种平均池化操作,用于提高对多尺度特征信息的提取能力[21],后通过1×1卷积对池化所得结果的各通道进行线性组合并将通道数从512压缩至64,对各通道提取的特征信息进行整合,从而提取更丰富的特征信息,通道数的减少能极大地降低全连接层的计算量[22].
图5
2 实验与结果分析
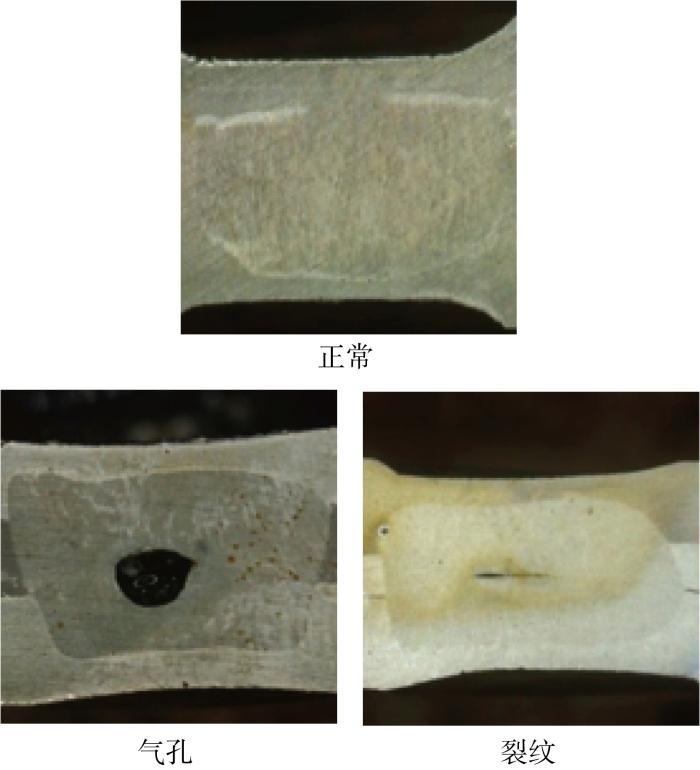
2.1 原始实验数据集
图6
2.2 缺陷样本合成实验
图7
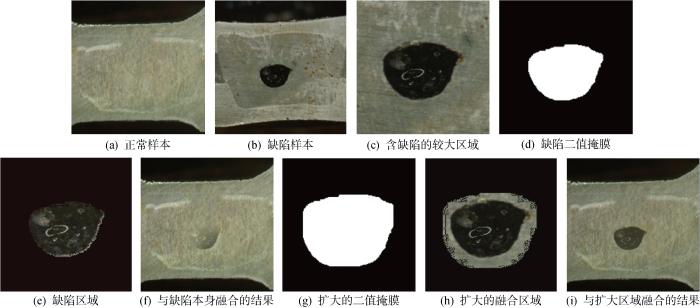
(1) 将含缺陷的较大区域转变为灰度图像.
(2) 对该灰度图像进行二值分割.
(3) 利用形态学中的开操作去除细小毛刺,再通过闭操作消除相应的孔洞.
(4) 最终得到二值掩膜图像,如图7(d)所示.
将所有的缺陷区域与正常样本进行随机融合,并对缺陷大小、融合位置以及缺陷旋转角度进行随机变化以增加生成样本的多样性,极大地扩充了缺陷样本数量,具体生成策略如下.
(1) 对正常样本进行灰度处理及二值化处理得到相应的黑白二值图像,记为“bin_img”.
(2) 从“bin_img”顶部中间位置wmid,由上至下依次探测得到金相组织区域上下边界的位置h1及h2,由此计算出金相组织区域中心处的大体高度位置hmid=(h1+h2)/2.
(3) 以(wmid,hmid)为起始中心点,通过增加相应的偏移量得到随机中心点(wmid+Δw, hmid+Δh),以该点作为融合位置的中心点.
(4) 每个正常样本最多融合两个不同的缺陷.
若只融合一个缺陷:
若同时融合两个缺陷:
其中:W为整个图片的宽度;H为金相组织区域的高度,H=h2-h1.
(5) 对于待融合的缺陷图片,则通过缩放变换(缩放比例范围为[0.8,1.2])、翻转变换、旋转变换(角度变化范围为[-30°,30°])及融合缺陷数量变化 (范围为[1,2])等操作进行处理.
(6) 最终得到相应的合成图片.
由于正常样本数量是固定不变的966份,为使正常、气孔及裂纹3种类型的图片数量保持平衡,分别从合成得到的大量气孔和裂纹样本中均匀采样部分缺陷样本(约950份)用于后续实验,最终各缺陷样本数量变化如表1所示.
表1 数据增强后样本数量变化
Tab.1
| 图片类型 | 原始样本数 | 增强后的样本数 |
|---|---|---|
| 气孔 | 81 | 950 |
| 裂纹 | 26 | 946 |
| 正常 | 966 | 966 |
2.3 实验环境及相关参数设置
实验环境为windows10操作系统,深度学习框架为Pytorch 1.8.0版本,硬件设备为Nvidia GEFORCE RTX 2070 Super,8GB显存.少部分实验由于本地设备显存不足,故使用了华为昇腾平台进行训练.为验证在原始数据不足的情况下,使用泊松融合方法进行数据增强对缺陷分类效果的影响,共设置了两组对比实验,分别为利用原始数据以及扩充之后的数据进行实验.实验对比了4个深度神经网络模型VGG13、GoogLeNet、ResNet18、ResNet18_PRO,以探究合成数据对模型的鲁棒性及对分类效果的提升作用.缺陷分类实验中,训练集、验证集及测试集的比例为7∶2∶1,批量大小(Batch Size)设为32,采用Adam优化器进行参数优化, 权重衰减(weight decay)设置为5×10-4,为使模型能进一步学到最优解空间,采用指数衰减学习率(Exponential LR, ELR)策略,初始学习率为10-3,伽马(gamma)参数设置为0.95.
在分类任务中,需要根据分类的侧重点选择相应的评价指标,合适的评价指标能更准确地反映模型真实分类效果.常见的评价指标包括准确度(Accuracy)、精确率(Precision)、召回率(Recall)及F1分数,如表2所示.式中,NTP表示预测为阳性且预测正确;NTN表示预测为阴性且预测正确;NFP表示预测为阳性但预测错误;NFN表示预测为阴性但预测错误.在多分类任务中,准确度主要针对所有类型的样本,表示所有被检测样本中检测正确的样本所占的比例;而精确率和召回率主要针对特定的类别来计算,精确率表示预测为该类别的所有样本中被正确预测的样本所占的比例,精确率越高,表明该类别的误检率越低;召回率表示所有该类别的真实样本中被正确检测的比例,召回率越高,表示该类别的漏检率越低;F1分数为精确率和召回率的调和平均值,兼顾了误检率和漏检率.
在平衡的数据中,以上指标都能较好地反映模型的分类效果,但在不平衡的数据中,准确度容易受到样本数据分布的影响,会更倾向于样本数量较多的类别而忽略样本较少的类别,因此可能会得到次优模型,并可能产生错误结论[24-25].F1分数可以兼顾误检率和漏检率,可针对某一个特定的类别进行度量,且受其他类别样本影响较小,因此使用F1分数作为评价指标.同时与准确度进行对比,一方面可以更准确地反映真实的分类效果;另一方面可以更好地展示数据增强前后分类效果的变化,以便进行相关分析.金相组织数据有正常、气孔、裂纹3类图片,为了更好地反映模型对每类图片具体的分类效果及3类图片整体的分类效果,分别计算每一类缺陷相应的F1分数值及相应的宏平均值,如下式所示:
式中:
2.4 原始数据分类实验结果与分析
原始数据缺陷分类实验中,由于数据量较少且正常、气孔、裂纹样本数量之比约为45∶4∶1,各类型的样本数量极不平衡.为了更加充分地利用数据,进行5折交叉验证,即取5次验证结果的平均值作为最终结果数据,使结果更加可靠,避免偶然性,得到验证集分类准确度随训练过程的变化曲线,如图8所示.
图8
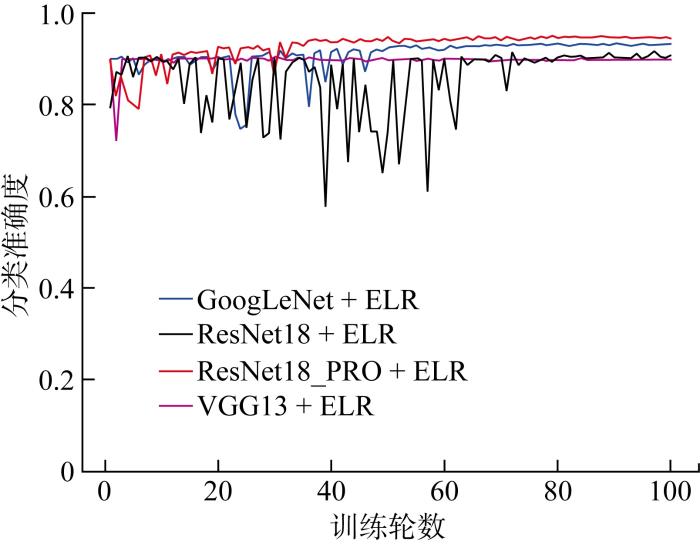
图8
各模型在验证集上分类准确度变化(原始数据)
Fig.8
Accuracy curve of all models on validation dataset (original dataset)
由图9可知,正常图片分类的F1分数远高于气孔和裂纹两者分类的F1分数,而反映整体分类效果的bar{F}_{1}^{ma}较低.由此可知,各分类器对正常图片的分类效果很好,而对其余两类图片分类效果较差,从而导致整体分类效果较差.这是因为在不平衡的数据下,分类效果会极大地受到数量最大的一类样本影响,而正常样本数量约占总样本数的90%,所以会使分类器在分类时向正常样本倾斜,而减少对另外两类样本的关注,导致模型更容易将其他缺陷的样本预测为正常样本.这种分类倾斜也是各模型所得分类准确度均在90%以上的主要原因,假设分类器将所有样本均预测为正常样本,也能得到90%的分类准确度.因此在该不平衡的数据中,
图9
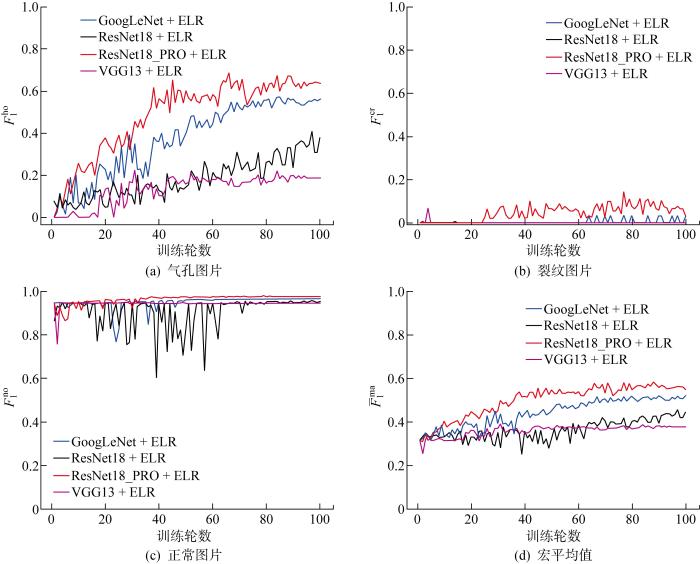
图9
各模型在验证集上F1分数变化(原始数据)
Fig.9
F1-score of all models on validation dataset (original data)
由图9(a)~(c)可知,在4个模型中,ResNet18_PRO对正常、气孔及裂纹图片的分类效果均优于其余3个分类模型;由9(d)可知,ResNet18_PRO的总体分类效果也为最优.主要由于ResNet18_PRO 模型在ResNet18的基础上使用了LDPS 结构,减少了下采样过程中的信息损失,并选择了对分类结果更有利的信息进行传递.同时在网络末端增加了ISPP结构,增强了网络对多尺度特征的提取和整合能力,因此ResNet18_PRO模型的分类效果优于其余3个模型.但由于气孔和裂纹缺陷的样本数过少,ResNet18_PRO不能充分学习相应的特征信息,所以分类效果仍然较差,由此可知训练数据量的不足会限制分类模型性能的发挥.
表3 各模型在测试集上的结果(原始数据)
Tab.3
| 模型 | 准确度 | bar{F}_{1}^{ma} | |||
|---|---|---|---|---|---|
| VGG13+ELR | 34.45 | 2.25 | 0.00 | 50.30 | 17.71 |
| GoogLeNet+ELR | 59.88 | 68.37 | 0.00 | 74.33 | 47.57 |
| ResNet18+ELR | 35.08 | 7.49 | 0.00 | 50.60 | 19.36 |
| ResNet18_Pro+ELR | 64.30 | 66.81 | 2.11 | 86.62 | 51.85 |
2.5 数据增强后分类实验与结果分析
通过泊松融合数据增强以后,气孔和裂纹样本数量均有较大的提升,各类型图片的样本数量大致相同,因此消除了数据不平衡现象.用4个分类模型分别对样本扩充后的数据进行训练,得到各模型对验证集的分类准确度随训练过程的变化如图10所示.
图10
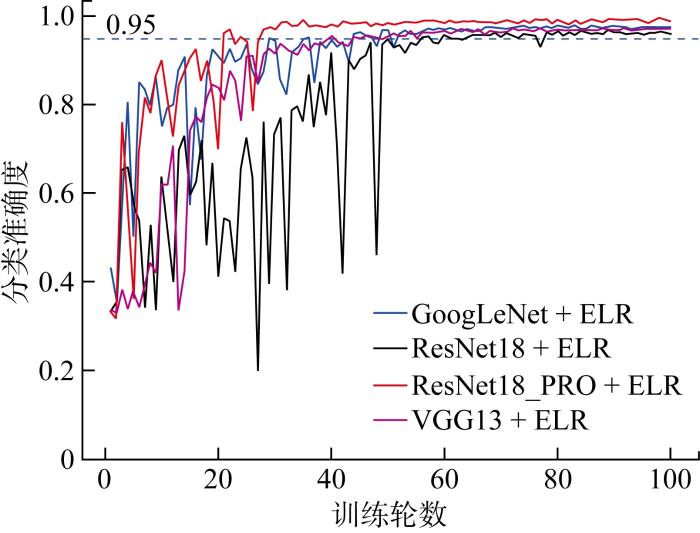
图10
各模型在验证集上分类准确度变化(数据增强后)
Fig.10
Accuracy curve of all models on validation dataset (after data augmentation)
图11
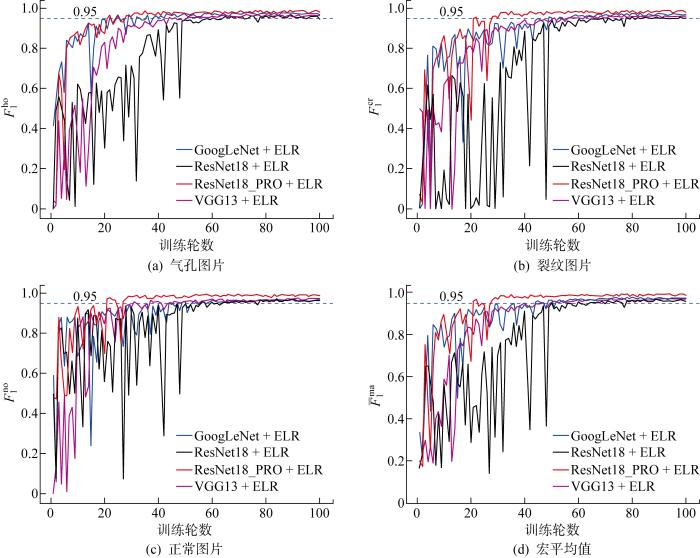
图11
各模型在验证集上F1分数变化(数据增强后)
Fig.11
F1-score of all models on validation dataset (after data augmentation)
由图11可知,各模型对3类图片分类的F1分数值均在95%以上,相较于原始数据上的分类效果有了显著提升,尤其是对于气孔和裂纹缺陷的提升更加明显.这表明数据增强后,各缺陷样本数量增多且较为均衡,使分类效果得到较大提升.同时,ResNet18_PRO模型对各类缺陷的分类效果在4个模型中均为最优,进一步验证了该模型性能的优越性及稳定性.
表4 各模型在测试集上的结果(数据增强后)
Tab.4
| 模型 | 准确度 | ||||
|---|---|---|---|---|---|
| VGG13+ELR | 95.78 | 95.61 | 92.63 | 98.33 | 95.52 |
| GoogLeNet+ELR | 97.85 | 97.74 | 96.56 | 99.07 | 97.86 |
| ResNet18+ELR | 96.56 | 96.91 | 94.57 | 97.61 | 96.36 |
| ResNet18_PRO+ELR | 98.83 | 98.88 | 97.96 | 99.45 | 98.76 |
为进一步分析ResNet18_PRO的分类性能,对测试过程中的部分成功案例进行分析.如图12所示,图12(a)、12(b)的真实标签分别为气孔和裂纹,4个模型得到的分类结果如表5所示.由表5可知,该两张图片在ResNet18_PRO模型上分类正确, 而在其余3个模型上分类错误.主要原因可能是图12(a)中的气孔边界处为黑色,而气孔内部大部分区域的颜色与金相图片本身的颜色十分接近,使另外3个模型在检测过程中将气孔内部误认为是正常区域,所以只对缺陷边界的上半周进行检测,使得模型将其误认为是细长的裂纹.图12(b)由于裂纹位置周围的颜色也较深,与裂纹本身的颜色较为接近,使其余3个模型没有检测到裂纹,而将其误判为正常图片.ResNet18_PRO模型由于减少了下采样过程中的信息损失,同时在网络末端加强了对信息的整合,能捕捉到更多的信息,使其得到正确的分类结果.
图12

表5 成功案例测试结果
Tab.5
| 来源 | 真实标签 | VGG13+ELR | GoogLeNet+ELR | ResNet18+ELR | ResNet18_PRO+ELR |
|---|---|---|---|---|---|
| 气孔 | 裂纹 | 裂纹 | 裂纹 | 气孔 | |
| 裂纹 | 正常 | 正常 | 正常 | 裂纹 |
与传统人工检测相比,采用该模型进行缺陷分类,既能得到较高的分类准确度也具有较快的检测速度,如表6所示.由表中可知,该模型在图形处理器(GPU)上的检测速度为100帧/s,远大于人工分类速度,能满足大部分工业相机的拍摄速度,可实现实时检测.
表6 人工分类与算法分类对比
Tab.6
| 分类方法 | 准确度/% | 分类速度/(帧·s-1) |
|---|---|---|
| 人工分类 | 99 | 约1 |
| ResNet18_PRO | 98.83 | GPU:约100 CPU:约10 |
2.6 ResNet18_PRO消融实验
为了验证ResNet18_PRO网络各改进部分及训练策略改进对分类效果的影响,通过控制变量思想对ResNet18_PRO进行消融实验,实验数据为样本扩充后的数据,训练集、验证集及测试集的比例仍为7∶2∶1,最终各模型在测试集上的结果如表7所示.验证网络结构改进时,为避免训练策略所带来的影响,训练均采用了0.001的固定学习率.
表7 消融实验结果
Tab.7
| 类型 | 模型 | 准确度 | ||||
|---|---|---|---|---|---|---|
| Baseline | ResNet18 | 85.31 | 77.39 | 80.92 | 95.30 | 84.54 |
| 结构改进 | + ISPP | 93.67(+8.36) | 93.01(+15.62) | 90.02(+9.10) | 97.68(+2.38) | 93.57(+9.03) |
| +LDPS | 96.37(+11.06) | 95.97(+18.58) | 94.72(+13.80) | 97.49(+2.19) | 96.06(+11.52) | |
| + ISPP +LDPS (ResNet18_PRO) | 97.34(+12.03) | 96.19(+18.83) | 96.24(+15.32) | 98.57(+3.27) | 97.00(+12.46) | |
| 策略改进 | ResNet18 +ELR | 96.56(+11.25) | 96.91(+19.52) | 94.57(+13.65) | 97.61(+2.31) | 96.36(+11.82) |
| ResNet18_PRO+ELR | 98.83(+13.52) | 98.88(+21.49) | 97.96(+17.04) | 99.45(+4.15) | 98.76(+14.22) |
通过表7可知,相较于基线(Baseline)模型ResNet18的分类效果,LDPS和ISPP均能较好地提高模型的分类准确度和F1分数,表明两个改进均较有效,其中LDPS对分类效果的提升更为明显.这是由于ResNet18网络浅层部分有较多的信息损失,导致网络末端所提取的信息有效性减弱,而ISPP主要对网络末端的信息进行整合,其效果依赖于末端信息的质量,所以单纯增加ISPP对分类效果的提升并不明显.而LDPS较大减少了下采样过程中的信息损失,并将更有用的信息进行传递,使网络能提取更多更有效的信息,因此LDPS带来的效果提升更好.同时,经LDPS改进后,网络末端所得到的信息更有效,质量更高,此时再与ISPP结合,使ISPP能对更有效的信息进行整合,因此能进一步提升分类效果.由于已经验证了网络结构的有效性,所以对于训练策略的影响,直接用ResNet18和ResNet18_PRO两个模型进行验证,即在训练时使用动态学习率ELR.结果表明,两模型使用ELR后,分类效果得到进一步提升,其中ResNet18模型分类效果提升更大.这是由于在本实验中ResNet18模型本身的分类性能一般,通过动态学习率可以让分类器进一步接近最优解空间,而ResNet18_PRO本身由于结构改进取得了较好的分类性能,与最优解空间较近,所以运用ELR之后,分类效果有提升,但不如ResNet18网络提升明显.
2.7 模型鲁棒性验证
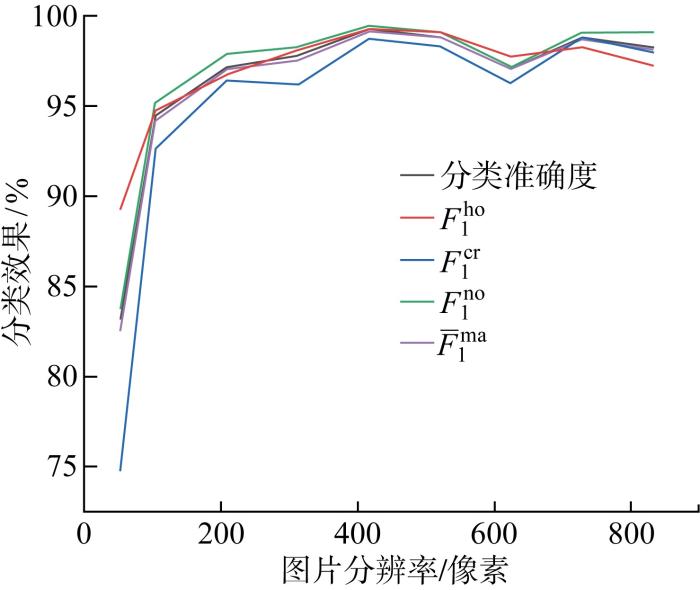
为验证ResNet18_PRO模型的鲁棒性,分别探究了图片的分辨率及缺陷数据集类型对模型分类效果的影响.探究分辨率对模型分类效果的影响时,通过图像处理的方法改变金相组织图片的分辨率,得到宽高均为52、104、208、312、416、520、624、728、832像素等9种不同分辨率的图片,然后对以上图片分别进行训练和测试,结果如图13所示.由此可知,随着分辨率的增加,各类型图片的F1分数及分类准确度先增加后趋于动态稳定,当分辨率小于104像素×104像素时,各类型缺陷的分类效果明显下降,其中裂纹的分类效果下降更为明显.主要因为分辨率越低,图片所携带的有效信息越少,使模型不能提取到较充足的特征信息,从而影响模型的分类性能.对于裂纹缺陷,由于本身缺陷特征为细长形状,缺陷特征不如气孔明显,所以低分辨率下裂纹的分类效果下降更多.
图13
使用ResNet18_PRO模型解决了三分类问题,取得了较好的分类效果.为探究该模型对含更多类别的数据的分类效果,使用了东北大学公开的热轧钢带表面缺陷数据集进行训练和测试,该数据集共有6类,每类有300张图片,图片分辨率被调整为224像素×224像素,如图14所示.
图14

表8 东北大学表面缺陷数据集测试结果
Tab.8
| 模型 | 分类准确度/% | \bar{F}_{1}^{ma}/% |
|---|---|---|
| VGG13+ELR | 94.90 | 97.43 |
| GoogLeNet+ELR | 97.48 | 98.62 |
| ResNet18+ELR | 98.53 | 98.27 |
| ResNet18_PRO+ELR | 98.96 | 99.21 |
3 结语
针对缺陷样本数量较少的金相组织图像缺陷分类问题,通过泊松融合的方法将缺陷区域与正常样本进行融合,扩充缺陷样本数量,从而达到数据增强的目的,改善了缺陷样本数据不平衡的问题.在ResNet18的基础上进行改进,提出了LDPS用于减少下采样过程中的信息损失,同时在网络末端增加了ISPP结构用于整合多尺度的特征信息,显著提高了缺陷分类精度.实验方面,通过多个分类模型对数据增强前后的分类效果进行对比,验证了泊松融合数据增强方法及ResNet18_PRO网络模型的有效性,并通过消融实验验证了模型各改进部分及训练策略的有效性.最终该模型在增强后的数据上取得了98.83%的平均分类精度及98.76%的平均F1分数.使用该模型对其他工业缺陷数据集进行训练和测试,取得了98.96%的平均分类准确度及99.21%的平均F1分数,表明该分类模型对不同的缺陷数据具有较好的鲁棒性.以上结论表明,该数据增强方法及网络模型具有较好的实际应用价值.
参考文献
焊缝X射线检测及其结果的评判方法综述
[J].
Research on defect detection and evaluation in WeldS with X-rays
[J].
X射线焊缝图像缺陷检测算法综述
[J].
Summary of defect detection algorithms for X-ray weld image
[J].
焊缝缺陷检测现状与展望综述
[J].
Review of status and prospect of weld defect detection
[J].
焊丝种类对6082-T6铝合金激光-电弧复合焊接焊缝质量的影响研究
[J].
Study on the influence of weld wire types on the quality of 6082-T6 aluminum alloy laser-arc composite weld welds
[J].
Automatic welding defect detection of X-ray images by using cascade AdaBoost with penalty term
[J].DOI:10.1109/Access.6287639 URL [本文引用: 2]
Automatic detection of welding defects using deep neural network
[J].DOI:10.1088/1742-6596/933/1/012006 URL [本文引用: 1]
Using deep learning for defect classification on a small weld X-ray image dataset
[J].
基于改进二叉树多分类SVM的焊缝缺陷分类方法
[J].
Method of multi-classification by improved binary tree based on SVM for welding defects recongnition
[J].
基于复合卷积层神经网络结构的焊缝缺陷分类技术
[J].
Weld defect classification technology based on compound convolution neural network structure
[J].
基于卷积神经网络的焊缝缺陷图像分类研究
[J].
DOI:10.5768/JAO202041.0302007
[本文引用: 1]

为有效地对焊缝缺陷进行分类,从而判断焊接质量的等级,对传统卷积神经网络进行改进,提出一种多尺度压缩激励网络模型(SINet)。将4组两两串联的3×3卷积模块与Inception模块、压缩激励模块(SE block)相结合。通过多尺度压缩激励模块(SI module)将卷积层中的特征进行多尺度融合和特征重标定以提高分类准确率,并用全局平均池化层代替全连接层减少模型参数。此外考虑到焊接缺陷数量不平衡对准确率的影响,采用深度卷积对抗生成网络(DCGAN)进行数据集的平衡处理,并在该数据集上验证模型的有效性。与传统卷积神经网络相比,该模型具有良好的性能,在测试集上准确率达到96.77%,同时模型的参数个数也明显减少。结果表明该方法对焊缝缺陷图像能进行有效地分类。
Research on weld defect image classification based on convolutional neural network
[J].
DOI:10.5768/JAO202041.0302007
[本文引用: 1]
In order to effectively classify the weld defects and judge the grade of the welding quality, a multi-scale squeeze-and-excitation network model (SINet) was proposed to improve the traditional convolutional neural network. Combined 4 groups of 3×3 convolutional modules in series with Inception module and squeeze-and-excitation block (SE block). By means of the multi-scale squeeze-and-excitation module (SI module), the multi-scale fusion and the feature re-calibration were carried out of the features in convolutional layer to improve the classification accuracy, and the global average pooling layer was used instead of the fully connected layer to reduce the model parameters. In addition, considering the influence of the unbalance in the number of weld defects on the accuracy, a deep convolutional adversarial generation network (DCGAN) method was used to balance the data set, and the validity of the model was verified on the data set. Compared with the traditional convolutional neural network, this model has good performance with an accuracy rate on the test of 96.77%, and the number of the model parameters is also greatly reduced. The results show that this method can effectively classify the weld defect images.
小样本困境下的深度学习图像识别综述
[J].
Survey on deep learning image recognition in dilemma of small samples
[J].
基于小样本学习的钢板表面缺陷检测技术
[J].
Surface defect detection for steel plate with small dataset
[J].
SMOTE: Synthetic minority over-sampling technique
[J].
DOI:10.1613/jair.953
URL
[本文引用: 1]
An approach to the construction of classifiers from imbalanced datasets is described. A dataset is imbalanced if the classification categories are not approximately equally represented. Often real-world data sets are predominately composed of ``normal'' examples with only a small percentage of ``abnormal'' or ``interesting'' examples. It is also the case that the cost of misclassifying an abnormal (interesting) example as a normal example is often much higher than the cost of the reverse error. Under-sampling of the majority (normal) class has been proposed as a good means of increasing the sensitivity of a classifier to the minority class. This paper shows that a combination of our method of over-sampling the minority (abnormal) class and under-sampling the majority (normal) class can achieve better classifier performance (in ROC space) than only under-sampling the majority class. This paper also shows that a combination of our method of over-sampling the minority class and under-sampling the majority class can achieve better classifier performance (in ROC space) than varying the loss ratios in Ripper or class priors in Naive Bayes. Our method of over-sampling the minority class involves creating synthetic minority class examples. Experiments are performed using C4.5, Ripper and a Naive Bayes classifier. The method is evaluated using the area under the Receiver Operating Characteristic curve (AUC) and the ROC convex hull strategy.
基于小样本学习的LCD产品缺陷自动检测方法
[J].
An automatic small sample learning-based detection method for LCD product defects
[J].
Poisson image editing
[J].
DOI:10.1145/882262.882269
URL
[本文引用: 2]
Using generic interpolation machinery based on solving Poisson equations, a variety of novel tools are introduced for seamless editing of image regions. The first set of tools permits the seamless importation of both opaque and transparent source image regions into a destination region. The second set is based on similar mathematical ideas and allows the user to modify the appearance of the image seamlessly, within a selected region. These changes can be arranged to affect the texture, the illumination, and the color of objects lying in the region, or to make tileable a rectangular selection.
Deep residual learning for image recognition
[DB/OL]. (
Spatial pyramid pooling in deep convolutional networks for visual recognition
[J].
DOI:10.1109/TPAMI.2015.2389824
PMID:26353135
[本文引用: 1]
Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224 × 224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip the networks with another pooling strategy, "spatial pyramid pooling", to eliminate the above requirement. The new network structure, called SPP-net, can generate a fixed-length representation regardless of image size/scale. Pyramid pooling is also robust to object deformations. With these advantages, SPP-net should in general improve all CNN-based image classification methods. On the ImageNet 2012 dataset, we demonstrate that SPP-net boosts the accuracy of a variety of CNN architectures despite their different designs. On the Pascal VOC 2007 and Caltech101 datasets, SPP-net achieves state-of-the-art classification results using a single full-image representation and no fine-tuning. The power of SPP-net is also significant in object detection. Using SPP-net, we compute the feature maps from the entire image only once, and then pool features in arbitrary regions (sub-images) to generate fixed-length representations for training the detectors. This method avoids repeatedly computing the convolutional features. In processing test images, our method is 24-102 × faster than the R-CNN method, while achieving better or comparable accuracy on Pascal VOC 2007. In ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014, our methods rank #2 in object detection and #3 in image classification among all 38 teams. This manuscript also introduces the improvement made for this competition.
Network in network
[DB/OL]. (
A survey of predictive modeling on imbalanced domains
[J].
Classification of imbalanced data: A review
[J].
DOI:10.1142/S0218001409007326
URL
[本文引用: 1]
Classification of data with imbalanced class distribution has encountered a significant drawback of the performance attainable by most standard classifier learning algorithms which assume a relatively balanced class distribution and equal misclassification costs. This paper provides a review of the classification of imbalanced data regarding: the application domains; the nature of the problem; the learning difficulties with standard classifier learning algorithms; the learning objectives and evaluation measures; the reported research solutions; and the class imbalance problem in the presence of multiple classes.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}