热力系统具有部件众多、结构复杂和工况多变等特点,设备故障的耦合性强且排故成本高[1 ] .为了提高系统的全寿命健康管理水平,如何通过系统的历史运行参数预测系统未来一段时间内的运行状态,并将得到的预测结果作为系统运行管理策略和装备维修的参考,已成为当前热力系统科学管理的重要研究方向之一[2 -3 ] .
热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大.
基于上述研究提出一种热力系统单参数时序预测模型,由MREMD、WTD、基于奇异值分解和排列熵的K -means聚类算法(SVD-PE-KCA)和ARIMA共4部分组成,简称MWSA.利用对原始信号的分解、降噪和趋势提取,使预测结果更加精确,可为热力系统的运行管理、控制优化和维修保障研究提供底层输入,具有一定的理论创新和工程应用价值.
1 预测步骤和算法
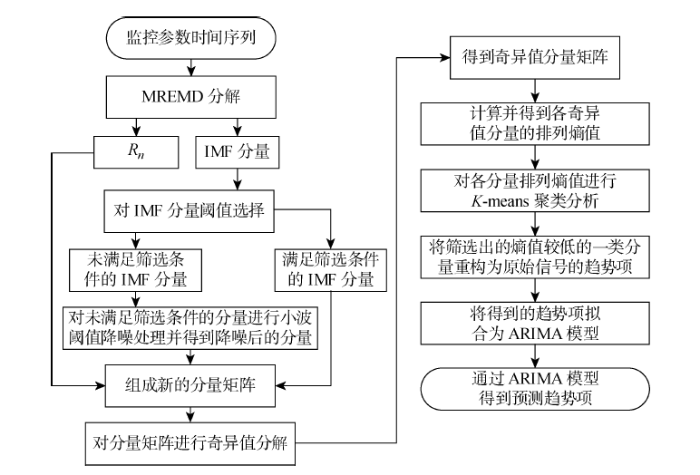
图1
图1
基于MWSA的单参数时序预测流程图
Fig.1
Flow chart of single parameter sequential prediction method based on MWSA
首先,利用MREMD算法将历史运行参数的时序数据信号分解为若干个IMF分量和1个残余分量(Rn );其次,计算各个IMF分量与原信号的互相关系数和均方根误差,筛选出不符合阈值条件的分量进行WTD,并将去噪后的IMF分量与原本符合筛选条件的分量以及残余分量重组成新的IMF分量;再次,利用SVD将重组后的新IMF分量分解,重构成按照奇异值升序排列的奇异值分量,并采用基于优化参数的PE算法计算各个IMF分量的熵值,利用K -means聚类算法针对各IMF分量熵值进行分类;最后,选取熵值较低的一类IMF分量重构为当前运行参数的变化趋势项,并采用ARIMA模型对其进行预测.
1.1 MREMD分解
MREMD采用自回归(AR)模型对信号端点延拓,并用优化包络线拟合的方法改善了EMD算法中的“端点效应”问题,具体步骤和算法如下.
步骤一 对于长度为N的初始时间序列x0 (t),采用如下式所示的p阶AR 模型对x(t)的左右端点进行预测延拓,即x(t)为延拓后的新序列,使左右端点处于延拓后时间序列的相邻两个极值点之间.
(1) xt =ϕ0 +ϕ1 xt-1 +ϕ2 xt-2 +…+ϕp xt-p +μt
式中:xt (t=p+1, p+2, …, N)为均值点;ϕ0 ,ϕ1 ,…,ϕp 为p+1个实数;μt 为零均值的白噪声序列.
步骤二 计算延拓后新时序中相邻极值点间的均值,得到初始信号x0 (t)的均值点序列{x m 1,0 x m 2,0 x m k , 0 0 (t)的信号均值序列m1,0 (t),由x0 (t)-m1,0 (t)得到x0 (t)的1阶信号分量为
(2) h1,0 (t)=x0 (t)-m1,0 (t)
步骤三 将计算得到的信号分量h1,0 (t)作为原始信号,重复步骤一和步骤二进行迭代计算,直到经过l次迭代后的信号分量h1,l (t)满足如下式所示的终止条件.
(3) σ * = σ l - 1 - σ l X M σ ≤ 0.2 P { ϑ l | ϑ l ≤ ϑ 0 } ≥ 95 %
式中:σ* 为归一化标准差;σl-1 和σl 分别为第l-1次迭代后信号分量h1,l-1 (t)和第l次迭代后信号分量h1, l (t)的均值点序列标准差;P为条件概率;根据Sigma 原则[12 ] 定义X M σ 0 (t)中极值点绝对值的有义值;ϑ0 和ϑl 为初始信号和第l次迭代后的信号均值点与X M σ
(4) $\begin{array}{l}P\left\{\left|x_{z}\right| \mid\left(\left|x_{z}\right| \leqslant X_{\sigma}^{\mathrm{M}}\right),\right. \\\quad z=1,2, \cdots, k+1\} \geqslant 68.5 \%\end{array}$
(5) ϑ 0 = x m 1,0 X M σ , x m 2,0 X M σ , … , x m k , 0 X M σ ϑ l = x m 1 , l X M σ , x m 2 , l X M σ , … , x m k , l X M σ
式中:xz 为延拓后新序列的第z 个极值点;x m 1,0 x m 2,0 x m k , 0 0 (t)的均值点;x m 1 , l x m 2 , l x m k , l 1,l-1 (t)的均值点.
步骤四 将h1,l (t)作为1阶本征模态函数(即I1 分量)输出,x0 (t)-I1 得到分量R1 ,并将R1 作为原始信号重复步骤一至步骤四,直到残余信号成为单调函数或分离不出新的IMF分量为止,残余信号提取过程表示为
(6) R 1 = x 0 ( t ) - I 1 R 2 = R 1 - I 2 ︙ R n = R n - 1 - I n
经过上述分解后,原始信号x 0 (t )可表示为所有IMF分量和最终残余分量之和,表达式为
(7) x0 (t)= ∑ i = 1 n i +Rn
1.2 IMF分量选取
对于MREMD分解后的IMF分量,噪声主要集中在高频分量中,在工程实际应用时一般通过舍弃高频分量的方法来达到降噪的目的,但这同样也会丢弃部分的信号信息,使得分析结果产生误差.此外,虽然低频分量通常包含了较多的信息成分,但同样也存在一些噪声,仅靠舍弃高频分量的方法并不能够实现完全降噪的目的.为此,本文采用王彬蓉等[13 ] 提出的IMF分量筛选方法对所有分量进行筛选,在降噪的同时尽可能多地保留原始信号的信息,具体步骤和算法如下.
步骤一 计算各阶IMF分量与原始信号的相关系数ci 和均方根误差RMSEi
(8) c i = ∑ j = 1 N ( x 0 ( t ) - x - 0 ( t ) ) ( I i - I - i ) ∑ j = 1 N ( x 0 ( t ) - x - 0 ( t ) ) 2 ∑ j = 1 N ( I i - I - i ) 2 R M S E i = 1 N ∑ j = 1 N ( x 0 ( t ) - I i ) 2
式中:x - 0 ( t)和I - i 0 (t)和各阶IMF分量的均值.其中,相关系数值越大,各分量与原始信号的相关度越高;均方根误差值越小,各分量与原始信号的密切程度越高.
步骤二 计算IMF分量相关系数筛选阈值和均方差筛选阈值,表达式为
(9) λ I M F = 1 n - 1 ∑ j = 1 n - 1 c i δ I M F = 1 n - 1 ∑ j = 1 n - 1 R M S E i
步骤三 选取满足如下条件的IMF分量,进行小波阈值降噪为
(10) ci ≤λIMF RMSE i ≥δIMF
1.3 WTD
WTD是利用小波变换将原始信号分解成多层近似系数和细节系数,由于经过小波变换后的噪声信息主要集中在绝对值较小的细节系数中,所以可通过将绝对值小于规定阈值的细节系数设置为0,并将剩余小波系数(即分解得到的近似系数和保留的细节系数)通过小波逆变换重构回原始信号的方法,以达到去除噪声的目的,具体步骤和算法如下.
步骤一 阈值选取.传统WTD的阈值选取方法有固定阈值法、自适应阈值法、启发式阈值法和极大极小阈值法等[14 ] .本文采用改进的固定阈值法,通过细节系数对每一层的噪声进行估计,同时利用系数ln(j +1)逐层降低细节系数的阈值[15 ] ,从而尽可能多地保留蕴含在高频分量中的真实信号,其阈值选取准则为
(11) λj = 2.1 m e d i a n ( d ( j ) ) l n N l n ( j + 1 )
式中:λj 为第j层小波细节系数的噪声阈值;d(j) 为第j层小波细节系数;median为中间值函数,即将每层系数按照降序排列后,取其中间数的值(当系数个数为奇数时)或中间两个数的均值(当系数个数为偶数时).
步骤二 阈值处理.常用阈值处理函数有硬阈值函数、软阈值函数和复合阈值函数[16 ] 等,依次表示为
d ^ ( j ) d ( j ) , d ( j ) ≥ λ j 0 , d ( j ) < λ j
d ^ ( j ) ( d ( j ) - λ j ) s i g n d ( j ) , d ( j ) ≥ λ j 0 , d ( j ) < λ j
d ^ ( j ) ( d ( j ) - a λ j ) s i g n d ( j ) , d ( j ) ≥ λ j 0 , d ( j ) < λ j
式中:d ^ ( j ) 0,1 d ^ ( j ) d ^ ( j )
1.4 趋势项提取
采用SVD、PE和K -means聚类算法的组合以实现信号的进一步降噪和趋势项的提取,具体步骤和算法如下.
步骤一 SVD分解.将经过小波阈值降噪处理后的n 个IMF分量I 1 ~In 和残余分量Rn 去均值,然后以列向量的形式组成矩阵AN ×( n +1) ,并计算其协方差矩阵B ( n +1)×( n +1) :
(12) AN ×( n +1) =(I1 - I - 1 2 - I - 2 n - I - n n - R - n
(13) B( n +1)×( n +1) =U( n +1)×( n +1) Λ( n +1)×( n +1) U T ( n + 1 ) × ( n + 1 )
式中:Λ =diag(λ 1 λ 2 λ n + 1 ) 为B 的奇异值组成的对角阵,其中,λ 1 ,λ 2 ,…,λn +1 为按照降序排列的矩阵B 对应的特征值;U 为B 的特征值对应的特征向量组成的矩阵.
将矩阵U 和A 中0特征值所对应的向量去掉,重构后的K 个奇异值分量表示为
(14) IN × K AN × K UK × K P 1 P 2 … PK )
步骤二 PE 计算. 利用延迟相空间重构法[17 ] 对IN × K P 1 重构表示为
(15) IN × K = p 1 , 1 p 1 , 1 + τ … p 1 , 1 + ( m - 1 ) τ p 1 , 2 p 1 , 2 + τ … p 1 , 2 + ( m - 1 ) τ … … ⋱ … p 1 , l p 1 , l + τ … p 1 , l + ( m - 1 ) τ
式中:l =N -(m -1)τ ;p 1, i i =1, 2, …, N )为第1个奇异值分量的第i 个元素;m 为嵌入维数;τ 为延迟时间.
将重构矩阵的每行元素按升序排列,得到每行元素的索引值,然后将每行元素的索引值组成索引向量并构成索引矩阵. 索引矩阵中每行元素的排列方式共有m !种可能,假设第b 种排列方式在索引矩阵中的出现次数为ub ,统计其出现的频率为
(16) fb =ub /m !, b ∈(1, K )
(17) PEi =- ∑ b = 1 m ! b lb fb
步骤三 K-means 聚类. 根据计算得到的排列熵值对IMF 分量进行聚类,选取熵值较低的分量重构原始信号的趋势项. 首先,任意选取其中1个点ρ 1 作为1个类别中心,并选择与ρ 1 距离最远的ρ 2 点为另1个类别中心,计算熵值序列中其余对象点x 与ρ 1 和ρ 2 的距离为
(18) d (ρ , x )=|x -ρ |
然后,把其余各点划分到与两个类别中心距离近的一类,将两类点的均值作为新的类别中心进行分类,重复上述步骤,直至两个类别中心不再发生变化为止. 最后,将两类熵值点中平均熵值较低一类所对应的奇异值分量筛选出来[18 ] ,重构为原始信号的趋势项为
(19) TN ×1 =∑(EN × K +SN × K Q T K × K
式中:EN × K IMF 分量取均值扩展后的矩阵,未选取分量对应的均值用N ×1替换;SN × K N ×1替换;Q T K × K U T K × K K ×1替换后的矩阵.
1.5 ARIMA预测模型
ARIMA常用于差分平稳时间序列的拟合和预测,具体步骤和算法如下.
步骤一 对式(19)计算得到的趋势项TN ×1 进行平稳性(Phillips-Perron )检验[19 ] ,然后对检验结果为非平稳的时间序列作差分平稳化处理,表示为
(20) T ^ N × 1 D (difff (TN ×1 ))
式中:T ^ N × 1 L 为延迟算子;D 为延迟阶数;difff f 次差分.
步骤二 对经过平稳化处理后的趋势项的T ^ N × 1 AIC )定阶[20 ] ,其定阶准则表示为
(21) AIC(s, q)=ln σ ^ a 2 2 r N
式中:s 和q 分别为模型的自回归系数多项式阶数和移动平均系数多项式阶数;σ ^ a 2 r 为模型的独立参数个数.
步骤三 经过AIC 检验得到模型的自回归系数多项式阶数s 和移动平均系数多项式阶数q ,并拟合ARIMA (s, d, q)模型表达为
(22) yt =c +a 1 yt -1 +…+as yt - s εt - b 1 εt -1 -…-bq εt - q
式中:d 为非平稳序列经差分变为平稳序列的差分次数;a 1 ~as 为AR模型系数;b 1 ~bq 为MA模型系数;εt - q ~εt c 为常数;yt - s ~ yt T ^ N × 1 .
步骤四 对ARIMA 模型的残差序列进行LB (Ljung-Box )统计量检验[21 ] ,表示为
(23) RLB =N(N+2) ∑ i = 1 k ' ε ^ i N - i 2 (k')
式中:N ∈[1, k' ]且为整数;R LB 为残差序列的Ljung-Box统计量值;ε ^ i k' 为残差个数;χ 2 为卡方分布.
2 预测案例
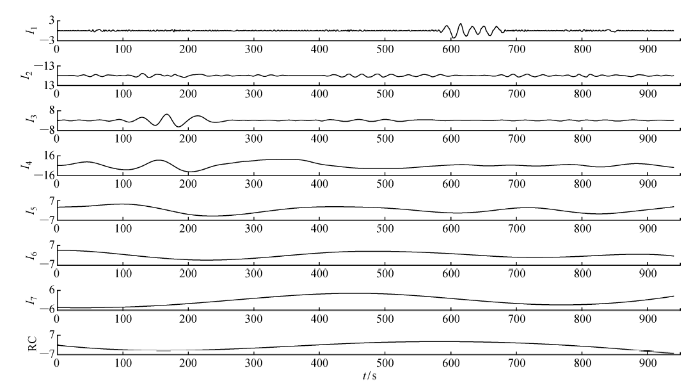
以某型船舶蒸汽动力系统的除氧器水位为案例,对上述基于MWSA 的热力系统单参数时序预测方法进行验证. 按1. 1节的步骤和算法,对一段时间内监控系统采集的实际水位数据进行MREMD 分解,得到7个IMF 分量和1个残余分量,如图2 所示.
图2
图2
分解得到的IMF分量和RC
Fig.2
Decomposed IMF component and RC
对于分解得到的分量,根据式(8)计算其与原始信号的相关系数和均方根误差,如表1 所示.
根据式(9)计算得到IMF 分量相关系数的筛选阈值λIMF . 301 7,均方差的筛选阈值δIMF . 314 1,符合条件的分量有I4 ~ I7 . 按1. 3节的具体步骤和算法对I1 ~ I3 进行小波阈值降噪,经反复测试,选取Sym 4小波基,分解层数为3层. 采用固定阈值选取方法,根据式(11)计算各层的噪声阈值. 采用不同阈值函数处理后的各IMF 分量的信噪比及均方根误差,如表2 所示.
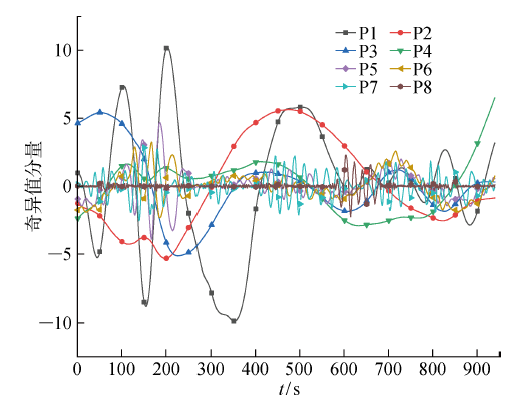
由表2 可知,对于高频的I1 分量,采用复合阈值降噪的信噪比更高,均方差更小.但对于较低频的I2 和I3 分量,采用硬阈值降噪的效果更佳.按1.4节的步骤和算法,将降噪后的I1 ~ I3 与I4 ~ I7 及残余分量Rn 一起进行SVD分解,得到8个奇异值分量即P1~P8,如图3 所示.
图3
图3
SVD分解后的奇异值分量
Fig.3
Singular value components after SVD decomposition
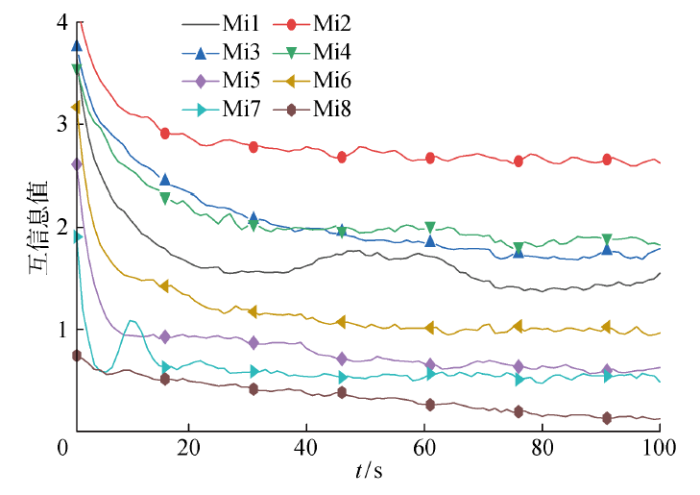
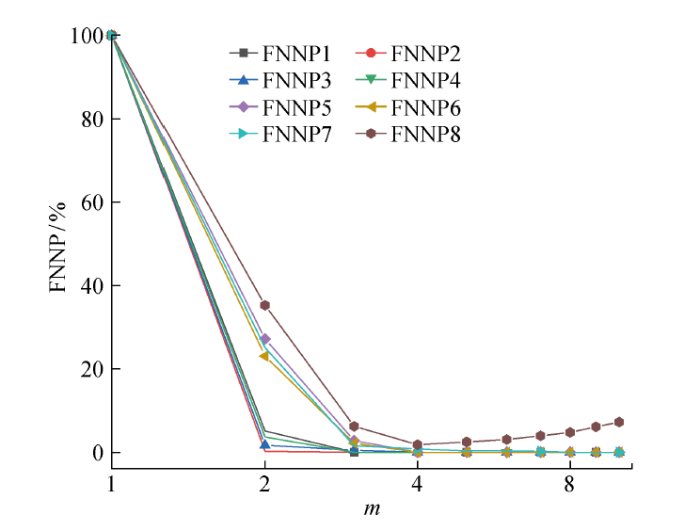
根据式(15)~(17)计算各奇异值分量的排列熵值.在相空间重构时,运用互信息法[22 ] 选取最佳延迟时间,在1~100 s的延迟时间范围内,各奇异值分量的互信息值Mi1~Mi8变化如图4 所示.采用伪近邻法[23 ] 计算最佳嵌入维数,在1~10的嵌入维数变化范围内,各奇异值分量的伪近邻率FNNP1~FNNP8随嵌入维数m 的变化如图5 所示.
图4
图4
各分量互信息值随延迟时间的变化曲线
Fig.4
Variation curve of mutual information value with delay time
图5
图5
各分量伪近邻率随嵌入维数的变化曲线
Fig.5
Variation of pseudo nearest neighbor rate with embedding dimension
取图4 中互信息值随时间变化曲线的第一个极值点为各奇异值分量的最佳延迟时间τ opt ;取图5 中伪近邻率小于5%时的嵌入维数为各奇异值分量的最佳嵌入维数m opt ;然后将其代入式(15),并通过式(16)和式(17)计算得到各分量的排列熵值,如表3 所示.
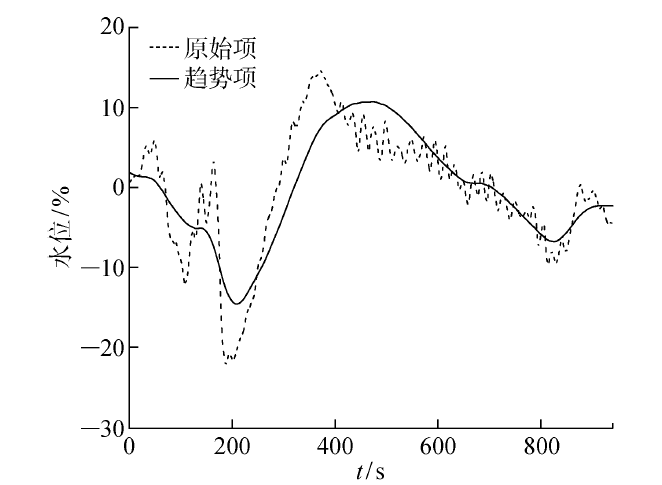
对各分量的排列熵值进行K -means聚类,选取P2、P3和P4共3个分量进行趋势项重构,结果如图6 所示.
图6
图6
除氧器水位的原始项与趋势项
Fig.6
Original item and trend item of deaerator water level
根据1.5节的步骤和算法,对除氧器水位进行拟合和预测.首先,对如图6 所示的趋势项进行Phillips-Perron检验,结果为非平稳序列,再经过4次差分计算后转换为平稳序列;然后,对差分平稳化后的序列进行AIC,得到自回归系数多项式阶数s 以及移动平均系数多项式阶数q 分别为1和3;在经过4次反差分计算和LB统计量检验后,拟合得到如式(22)所示的ARIMA(1, 4, 3)模型.
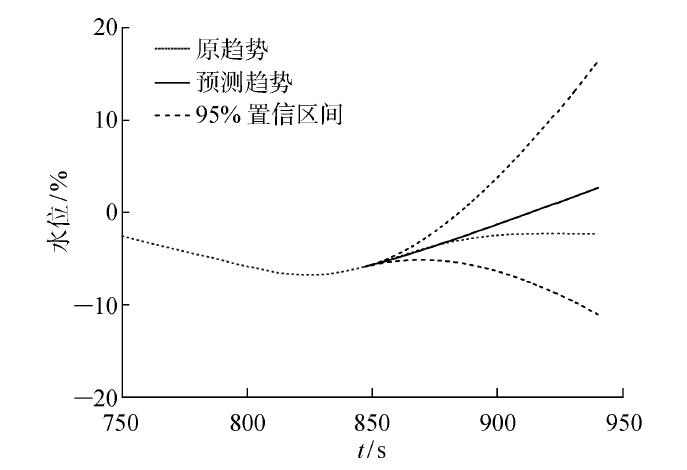
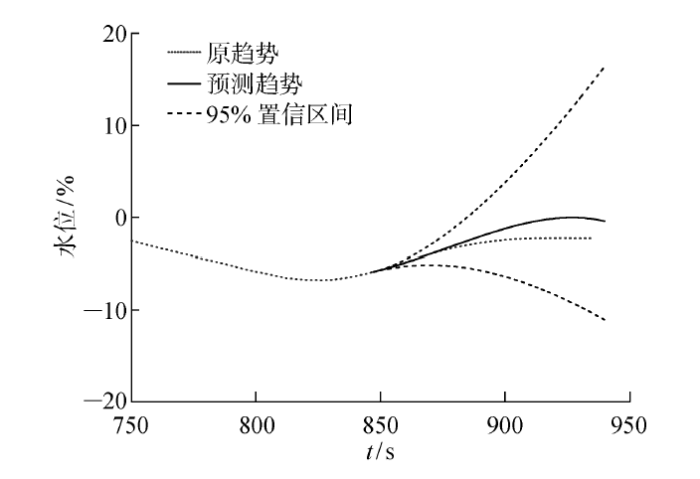
取实际运行数据的前90%为训练数据,取后10%为检验数据,预测除氧器水位在未来94 s的变化趋势,结果如图7 所示.而在相同数据输入下,采用文献[23 ]中提出的无降噪处理的算法(MSOP)得到的预测结果如图8 所示.
图7
图7
基于MOSP的除氧器水位趋势项与预测项
Fig.7
Trend and prediction of deaerator water level based on MSOP
图8
图8
基于MWSA的除氧器水位的趋势项与预测项
Fig.8
Trend and prediction of deaerator water level based on MWSA
由图7 和图8 可知,随着预测时长的增加,两种方法的预测误差都会增大.经计算,在采用MWSA方法时,预测结果与实际数据(检验数据)的均方差为1.388 7;而文献[23 ]中提出的方法其预测结果与实际数据(检验数据)的均方差为2.133 4.可知,本文预测方法的准确度更高.
3 结语
提出一种基于MWSA的热力系统单参数时序预测方法,并以某型号船舶蒸汽动力系统的除氧器水位为例,根据实际运行数据预测其在未来一段时间内的变化趋势.通过与基于MSOP的时序预测方法对比,证明所提方法的预测误差较小,预测结果较为准确.该算法完全基于基本物理规律,利用纯数学推导得出,在推导过程中未加入任何约束条件或有关具体设备的辅助方程,在数学上具有本质的普适性.利用滑动数据采集窗口可以对其他时段的数据进行分析验证,亦可通过添加其他设备的数据接口,对其他热力参数进行分析和预测.研究成果可用于热力系统的运行管理、控制优化和维修保障研究,达到优化运行管理和控制策略,合理安排维修保障资源、减少设备故障和延长系统使用寿命的目的.
参考文献
View Option
[1]
倪何 , 覃海波 , 郑奕杨 . 考虑给水泄漏的锅炉升负荷仿真及其可靠性
[J]. 上海交通大学学报 , 2021 , 55 (4 ): 444 -454 .
[本文引用: 1]
NI He QIN Haibo ZHENG Yiyang . Simulation and performance reliability of boiler load raising process considering leakage of feed water
[J]. Journal of Shanghai Jiao Tong University , 2021 , 55 (4 ): 444 -454 .
[本文引用: 1]
[2]
秦文学 , 王嘉兴 , 王继强 , 等 . 基于ARMA模型的燃煤机组主蒸汽压力控制策略
[J]. 热力发电 , 2020 , 49 (9 ): 127 -132 .
[本文引用: 1]
QIN Wenxue WANG Jiaxing WANG Jiqiang , et al Control strategy of main steam pressure of coal-fired unit based on ARMA model
[J]. Thermal Power Generation , 2020 , 49 (9 ): 127 -132 .
[本文引用: 1]
[3]
朱少民 , 夏虹 , 吕新知 , 等 . 基于ARIMA和LSTM组合模型的核电厂主泵状态预测
[J]. 核动力工程 , 2022 , 43 (2 ): 246 -253 .
[本文引用: 1]
ZHU Shaomin XIA Hong LYU Xinzhi , et al Condition prediction of reactor coolant pump in nuclear power plants based on the combination of ARIMA and LSTM
[J]. Nuclear Power Engineering , 2022 , 43 (2 ): 246 -253 .
[本文引用: 1]
[4]
RUIZ-AGUILAR J J TURIAS I GONZÁLEZ-ENRIQUE J , et al A permutation entropy-based EMD-ANN forecasting ensemble approach for wind speed prediction
[J]. Neural Computing and Applications , 2021 , 33 (7 ): 2369 -2391 .
DOI:10.1007/s00521-020-05141-w
URL
[本文引用: 1]
[5]
陈亮 , 刘宏立 , 郑倩 , 等 . 基于EEMD-SVD-PE的轨道波磨趋势项提取
[J]. 哈尔滨工业大学学报 , 2019 , 51 (5 ): 171 -177 .
[本文引用: 1]
CHEN Liang LIU Hongli ZHENG Qian , et al An EEMD-SVD-PE approach to extract the trend of track irregularity
[J]. Journal of Harbin Institute of Technology , 2019 , 51 (5 ): 171 -177 .
[本文引用: 1]
[6]
YANG Z J LING B W K BINGHAM C . Joint empirical mode decomposition and sparse binary programming for underlying trend extraction
[J]. IEEE Transactions on Instrumentation and Measurement , 2013 , 62 (10 ): 2673 -2682 .
DOI:10.1109/TIM.2013.2265451
URL
[本文引用: 1]
[7]
梁兵 , 汪同庆 . 基于HHT的振动信号趋势项提取方法
[J]. 电子测量技术 , 2013 , 36 (2 ): 119 -122 .
[本文引用: 1]
LIANG Bing WANG Tongqing . Method of vibration signal trend extraction based on HHT
[J]. Electronic Measurement Technology , 2013 , 36 (2 ): 119 -122 .
[本文引用: 1]
[8]
刘海江 , 刘世高 , 李敏 . 换挡加速度信号的EMD和小波阈值降噪方法
[J]. 噪声与振动控制 , 2018 , 38 (2 ): 198 -203 .
[本文引用: 1]
LIU Haijiang LIU Shigao LI Min . EMD and wavelet threshold denoising method of gear-shift acceleration signals
[J]. Noise and Vibration Control , 2018 , 38 (2 ): 198 -203 .
[本文引用: 1]
[9]
黄礼敏 . 海浪中非平稳非线性舰船运动在线预报研究 [D]. 哈尔滨 : 哈尔滨工程大学 , 2016 .
[本文引用: 1]
HUANG Limin . On-line prediction of non-stationary and nonlinear ship motions at sea [D]. Harbin : Harbin Engineering University , 2016 .
[本文引用: 1]
[10]
BEHERA A P GAURISARIA M K RAUTARAY S S , et al Predicting future call volume using ARIMA models [C]//2021 5th International Conference on Intelligent Computing and Control Systems. Madurai, India : IEEE , 2021 : 1351 -1354 .
[本文引用: 1]
[11]
仇琦 , 杨兰 , 丁旭 , 等 . 基于改进EMD-ARIMA的光伏发电系统短期功率预测
[J]. 电力科学与工程 , 2020 , 36 (8 ): 42 -50 .
DOI:1672-0792(2020)08-0042-09
[本文引用: 1]
光伏发电功率的准确预测对于提高电网和微电网的供电质量和降低运行成本具有重要意义。针对光伏发电时间序列的非线性和非平稳特征,在传统基于经验模态分解(EMD)方法的基础上,加入白噪声检验环节,提出一种基于改进EMD和差分自回归移动平均(ARIMA)相结合的光伏发电系统短期功率预测方法。首先利用EMD将原始光伏发电系统功率序列分解为多个具有不同频率的固有模态函数(IMF)分量,并对各IMF分量进行白噪声检验,筛选出不含白噪声的IMF分量;然后,对分量进行平稳性检验,对非平稳分量进行平稳化处理;最后对平稳的分量序列分别建立ARIMA预测模型,将各分量预测值进行叠加得到最终预测值。为验证方法的有效性,利用实证系统对3种天气条件下共15天的光伏发电功率进行了预测,并与传统的ARIMA、EMD-AR和EMD-ARIMA等方法进行了对比。误差统计结果表明,在相同样本数据量的前提下,该方法预测误差普遍低于其它方法。
QIU Qi YANG Lan DING Xu , et al An improved short-term power prediction method of PV power generation system based on EMD-ARIMA model
[J]. Electric Power Science and Engineering , 2020 , 36 (8 ): 42 -50 .
DOI:1672-0792(2020)08-0042-09
[本文引用: 1]
The accurate prediction of photovoltaic power generation is of great significance to improve the power supply quality of the power grid and microgrid and reduce operating costs. Aiming at the non-linear and non-stationary characteristics of photovoltaic power generation time series, based on the traditional empirical mode decomposition (EMD) method, this study introduces the white noise test link and proposes a short-term power prediction method based on improved empirical mode decomposition (EMD) and auto regressive integrated moving average (ARIMA) model. Firstly, the original PV output sequence is decomposed into multiple Intrinsic Mode Function (IMF) components with different frequencies by EMD, and white noise test on each IMF component is performed to filter out IMF components without white noise. Then, the components are tested for stationarity, and those non-stationary components are smoothed. Finally, the stationary component sequences are reconstructed by ARIMA prediction models, respectively, and the final prediction result is obtained by superimposing prediction value of each component. In order to verify the effectiveness of the method, a demonstrated system is used to predict the PV output for a total of 15 days under three weather conditions and the result is compared with the three methods of traditional ARIMA, EMD-AR, and EMD-ARIMA. The error statistics show that the prediction error of this method is generally lower than the other three methods under the premise of the same sample data volume.
[12]
尤保健 . 基于六西格玛理论的轴流泵叶轮水力效率影响因子分析
[J]. 水电能源科学 , 2020 , 38 (2 ): 168 -171 .
[本文引用: 1]
YOU Baojian . Influencing factors analysis of hydraulic efficiency of axial flow pump impeller based on six sigma theory
[J]. Water Resources and Power , 2020 , 38 (2 ): 168 -171 .
[本文引用: 1]
[13]
王彬蓉 , 王维博 , 周超 , 等 . 基于EMD自适应重构的心音信号特征筛选及分类
[J]. 航天医学与医学工程 , 2020 , 33 (6 ): 533 -541 .
[本文引用: 1]
WANG Binrong WANG Weibo ZHOU Chao , et al Feature selection and classification of heart sound based on EMD adaptive reconstruction
[J]. Space Medicine & Medical Engineering , 2020 , 33 (6 ): 533 -541 .
[本文引用: 1]
[14]
崔公哲 , 张朝霞 , 杨玲珍 , 等 . 一种改进的小波阈值去噪算法
[J]. 现代电子技术 , 2019 , 42 (19 ): 50 -53 .
[本文引用: 1]
CUI Gongzhe ZHANG Zhaoxia YANG Lingzhen , et al An improved wavelet threshold denoising algorithm
[J]. Modern Electronics Technique , 2019 , 42 (19 ): 50 -53 .
[本文引用: 1]
[15]
CHANG F X HONG W X ZHANG T , et al Research on wavelet denoising for pulse signal based on improved wavelet thresholding [C]//2010 First International Conference on Pervasive Computing, Signal Processing and Applications. New York, USA : IEEE , 2010 : 564 -567 .
[本文引用: 1]
[16]
徐晨 , 赵瑞珍 , 甘小冰 . 小波分析应用算法 [M]. 北京 : 科学出版社 , 2016 .
[本文引用: 1]
XU Chen ZHAO Ruizhen GAN Xiaobing . Application algorithm of wavelet analysis [M]. Beijing : Science Press , 2016 .
[本文引用: 1]
[17]
谢忠玉 , 张立 . 相空间重构参数选择方法的研究
[J]. 中国科技信息 , 2009 (16 ): 42 -43 .
[本文引用: 1]
XIE Zhongyu ZHANG Li . Selection of embedding parameters in phase space reconstruction
[J]. China Science and Technology Information , 2009 (16 ): 42 -43 .
[本文引用: 1]
[18]
杨恒岳 , 刘青荣 , 阮应君 . 基于k-means聚类算法的分布式能源系统典型日冷热负荷选取
[J]. 热力发电 , 2021 , 50 (3 ): 84 -90 .
[本文引用: 1]
YANG Hengyue LIU Qingrong RUAN Yingjun . Selection of typical daily cooling and heating load of CCHP system based on k-means clustering algorithm
[J]. Thermal Power Generation , 2021 , 50 (3 ): 84 -90 .
[本文引用: 1]
[19]
田行宇 , 李传金 . PP检验对异方差时间序列的伪检验
[J]. 统计与决策 , 2018 , 34 (17 ): 74 -76 .
[本文引用: 1]
TIAN Xingyu LI Chuanjin . Spurious tests to he-teroscedastic time series with PP test
[J]. Statistics & Decision , 2018 , 34 (17 ): 74 -76 .
[本文引用: 1]
[20]
李国春 , 王恩龙 , 王丽梅 , 等 . 基于AIC准则判断锂电池最优模型
[J]. 汽车工程学报 , 2019 , 9 (5 ): 352 -358 .
[本文引用: 1]
LI Guochun WANG Enlong WANG Limei , et al Evaluating optimal models of lithium battery based on AIC
[J]. Chinese Journal of Automotive Engineering , 2019 , 9 (5 ): 352 -358 .
[本文引用: 1]
[21]
李颖若 , 韩婷婷 , 汪君霞 , 等 . ARIMA时间序列分析模型在臭氧浓度中长期预报中的应用
[J]. 环境科学 , 2021 , 42 (7 ): 3118 -3126 .
[本文引用: 1]
LI Yingruo HAN Tingting WANG Junxia , et al Application of ARIMA model for mid-and long-term forecasting of ozone concentration
[J]. Environmental Science , 2021 , 42 (7 ): 3118 -3126 .
DOI:10.1021/es8002603
URL
[本文引用: 1]
[22]
饶国强 , 冯辅周 , 司爱威 , 等 . 排列熵算法参数的优化确定方法研究
[J]. 振动与冲击 , 2014 , 33 (1 ): 188 -193 .
[本文引用: 1]
RAO Guoqiang FENG Fuzhou SI Aiwei , et al Method for optimal determination of parameters in permutation entropy algorithm
[J]. Journal of Vibration and Shock , 2014 , 33 (1 ): 188 -193 .
[本文引用: 1]
[23]
郑奕扬 , 倪何 , 金家善 . 基于MSOP的蒸汽动力系统单参数运行稳定性评估方法
[J]. 上海交通大学学报 , 2021 , 55 (11 ): 1438 -1444 .
[本文引用: 3]
ZHENG Yiyang NI He JIN Jiashan . An operation stability assessment method of a single-parameter in steam power system based on MSOP
[J]. Journal of Shanghai Jiao Tong University , 2021 , 55 (11 ): 1438 -1444 .
[本文引用: 3]
考虑给水泄漏的锅炉升负荷仿真及其可靠性
1
2021
... 热力系统具有部件众多、结构复杂和工况多变等特点,设备故障的耦合性强且排故成本高[1 ] .为了提高系统的全寿命健康管理水平,如何通过系统的历史运行参数预测系统未来一段时间内的运行状态,并将得到的预测结果作为系统运行管理策略和装备维修的参考,已成为当前热力系统科学管理的重要研究方向之一[2 -3 ] . ...
考虑给水泄漏的锅炉升负荷仿真及其可靠性
1
2021
... 热力系统具有部件众多、结构复杂和工况多变等特点,设备故障的耦合性强且排故成本高[1 ] .为了提高系统的全寿命健康管理水平,如何通过系统的历史运行参数预测系统未来一段时间内的运行状态,并将得到的预测结果作为系统运行管理策略和装备维修的参考,已成为当前热力系统科学管理的重要研究方向之一[2 -3 ] . ...
基于ARMA模型的燃煤机组主蒸汽压力控制策略
1
2020
... 热力系统具有部件众多、结构复杂和工况多变等特点,设备故障的耦合性强且排故成本高[1 ] .为了提高系统的全寿命健康管理水平,如何通过系统的历史运行参数预测系统未来一段时间内的运行状态,并将得到的预测结果作为系统运行管理策略和装备维修的参考,已成为当前热力系统科学管理的重要研究方向之一[2 -3 ] . ...
基于ARMA模型的燃煤机组主蒸汽压力控制策略
1
2020
... 热力系统具有部件众多、结构复杂和工况多变等特点,设备故障的耦合性强且排故成本高[1 ] .为了提高系统的全寿命健康管理水平,如何通过系统的历史运行参数预测系统未来一段时间内的运行状态,并将得到的预测结果作为系统运行管理策略和装备维修的参考,已成为当前热力系统科学管理的重要研究方向之一[2 -3 ] . ...
基于ARIMA和LSTM组合模型的核电厂主泵状态预测
1
2022
... 热力系统具有部件众多、结构复杂和工况多变等特点,设备故障的耦合性强且排故成本高[1 ] .为了提高系统的全寿命健康管理水平,如何通过系统的历史运行参数预测系统未来一段时间内的运行状态,并将得到的预测结果作为系统运行管理策略和装备维修的参考,已成为当前热力系统科学管理的重要研究方向之一[2 -3 ] . ...
基于ARIMA和LSTM组合模型的核电厂主泵状态预测
1
2022
... 热力系统具有部件众多、结构复杂和工况多变等特点,设备故障的耦合性强且排故成本高[1 ] .为了提高系统的全寿命健康管理水平,如何通过系统的历史运行参数预测系统未来一段时间内的运行状态,并将得到的预测结果作为系统运行管理策略和装备维修的参考,已成为当前热力系统科学管理的重要研究方向之一[2 -3 ] . ...
A permutation entropy-based EMD-ANN forecasting ensemble approach for wind speed prediction
1
2021
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
基于EEMD-SVD-PE的轨道波磨趋势项提取
1
2019
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
基于EEMD-SVD-PE的轨道波磨趋势项提取
1
2019
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
Joint empirical mode decomposition and sparse binary programming for underlying trend extraction
1
2013
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
基于HHT的振动信号趋势项提取方法
1
2013
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
基于HHT的振动信号趋势项提取方法
1
2013
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
换挡加速度信号的EMD和小波阈值降噪方法
1
2018
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
换挡加速度信号的EMD和小波阈值降噪方法
1
2018
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
1
2016
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
1
2016
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
1
2021
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
基于改进EMD-ARIMA的光伏发电系统短期功率预测
1
2020
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
基于改进EMD-ARIMA的光伏发电系统短期功率预测
1
2020
... 热力系统的运行参数大多为非平稳时间序列.在非平稳时间序列趋势项的提取方面,文献[4 ]对风速时序数据进行预测并基于排列熵(PE)的经验模态分解(EMD)趋势项提取算法,结合人工神经网络(ANN)的预测模型对提取的趋势进行预测,通过计算预测数据与实际数据的相关系数来验证预测精度,相比未引入排列熵算法的EMD结合ANN的EMD-ANN算法具有更好的预测效果;陈亮等[5 ] 提出基于集合经验模态分解(EEMD)和奇异值分解(SVD)的排列熵非平稳时序趋势提取方法,并通过与文献[6 ]和文献[7 ]中的方法进行对比,验证了该算法的优越性,但由于EEMD分解后的各个本征模态函数(IMF)含噪信息不一,且在分解后的噪声分量和信号分量的分界问题方面选择直接去掉最高频分量的方法而未做量化分析,导致最高频IMF分量中的信号信息丢失,其余分量未进行降噪处理,使后续趋势提取误差增加;刘海江等[8 ] 提出利用EMD结合小波阈值去噪(WTD)的降噪方法,在保留原信号信息的基础上对噪声进行了更有效地消除,但因EMD算法中的“端点效应”问题导致重构信号误差较大;黄礼敏[9 ] 在EMD算法的基础上提出了中值回归经验模态分解(MREMD)方法,有效解决了EMD分解过程中的“端点效应”问题,并且优化了包络线生成方式,但同样未对分解后的IMF分量进行定量分界,导致后续计算结果误差较大.Behera等[10 ] 利用整合滑动平均自回归(ARIMA)模型,通过对公共部门每天接到的电话次数进行预测,并与实际数据对比分析,验证了模型的有效性,其预测结果可作为部门管理层规划员工日常工作量的参考.但由于热力系统中的参数历史数据中包含较多干扰,直接采用ARIMA模型预测误差较大;仇琦等[11 ] 在ARIMA预测模型的基础上提出了基于EMD结合ARIMA的EMD-ARIMA算法预测模型,通过对光电功率信号经EMD分解后的预测验证了模型的有效性,但这两种方法都未对原始非平稳信号的趋势进行提取,导致预测干扰较大. ...
基于六西格玛理论的轴流泵叶轮水力效率影响因子分析
1
2020
... 式中:σ* 为归一化标准差;σl-1 和σl 分别为第l-1次迭代后信号分量h1,l-1 (t)和第l次迭代后信号分量h1, l (t)的均值点序列标准差;P为条件概率;根据Sigma 原则[12 ] 定义 X M σ 0 (t)中极值点绝对值的有义值;ϑ0 和ϑl 为初始信号和第l次迭代后的信号均值点与 X M σ
基于六西格玛理论的轴流泵叶轮水力效率影响因子分析
1
2020
... 式中:σ* 为归一化标准差;σl-1 和σl 分别为第l-1次迭代后信号分量h1,l-1 (t)和第l次迭代后信号分量h1, l (t)的均值点序列标准差;P为条件概率;根据Sigma 原则[12 ] 定义 X M σ 0 (t)中极值点绝对值的有义值;ϑ0 和ϑl 为初始信号和第l次迭代后的信号均值点与 X M σ
基于EMD自适应重构的心音信号特征筛选及分类
1
2020
... 对于MREMD分解后的IMF分量,噪声主要集中在高频分量中,在工程实际应用时一般通过舍弃高频分量的方法来达到降噪的目的,但这同样也会丢弃部分的信号信息,使得分析结果产生误差.此外,虽然低频分量通常包含了较多的信息成分,但同样也存在一些噪声,仅靠舍弃高频分量的方法并不能够实现完全降噪的目的.为此,本文采用王彬蓉等[13 ] 提出的IMF分量筛选方法对所有分量进行筛选,在降噪的同时尽可能多地保留原始信号的信息,具体步骤和算法如下. ...
基于EMD自适应重构的心音信号特征筛选及分类
1
2020
... 对于MREMD分解后的IMF分量,噪声主要集中在高频分量中,在工程实际应用时一般通过舍弃高频分量的方法来达到降噪的目的,但这同样也会丢弃部分的信号信息,使得分析结果产生误差.此外,虽然低频分量通常包含了较多的信息成分,但同样也存在一些噪声,仅靠舍弃高频分量的方法并不能够实现完全降噪的目的.为此,本文采用王彬蓉等[13 ] 提出的IMF分量筛选方法对所有分量进行筛选,在降噪的同时尽可能多地保留原始信号的信息,具体步骤和算法如下. ...
一种改进的小波阈值去噪算法
1
2019
... 步骤一 阈值选取.传统WTD的阈值选取方法有固定阈值法、自适应阈值法、启发式阈值法和极大极小阈值法等[14 ] .本文采用改进的固定阈值法,通过细节系数对每一层的噪声进行估计,同时利用系数ln(j +1)逐层降低细节系数的阈值[15 ] ,从而尽可能多地保留蕴含在高频分量中的真实信号,其阈值选取准则为 ...
一种改进的小波阈值去噪算法
1
2019
... 步骤一 阈值选取.传统WTD的阈值选取方法有固定阈值法、自适应阈值法、启发式阈值法和极大极小阈值法等[14 ] .本文采用改进的固定阈值法,通过细节系数对每一层的噪声进行估计,同时利用系数ln(j +1)逐层降低细节系数的阈值[15 ] ,从而尽可能多地保留蕴含在高频分量中的真实信号,其阈值选取准则为 ...
1
2010
... 步骤一 阈值选取.传统WTD的阈值选取方法有固定阈值法、自适应阈值法、启发式阈值法和极大极小阈值法等[14 ] .本文采用改进的固定阈值法,通过细节系数对每一层的噪声进行估计,同时利用系数ln(j +1)逐层降低细节系数的阈值[15 ] ,从而尽可能多地保留蕴含在高频分量中的真实信号,其阈值选取准则为 ...
1
2016
... 步骤二 阈值处理.常用阈值处理函数有硬阈值函数、软阈值函数和复合阈值函数[16 ] 等,依次表示为 ...
1
2016
... 步骤二 阈值处理.常用阈值处理函数有硬阈值函数、软阈值函数和复合阈值函数[16 ] 等,依次表示为 ...
相空间重构参数选择方法的研究
1
2009
... 步骤二 PE 计算. 利用延迟相空间重构法[17 ] 对IN × K P 1 重构表示为 ...
相空间重构参数选择方法的研究
1
2009
... 步骤二 PE 计算. 利用延迟相空间重构法[17 ] 对IN × K P 1 重构表示为 ...
基于k-means聚类算法的分布式能源系统典型日冷热负荷选取
1
2021
... 然后,把其余各点划分到与两个类别中心距离近的一类,将两类点的均值作为新的类别中心进行分类,重复上述步骤,直至两个类别中心不再发生变化为止. 最后,将两类熵值点中平均熵值较低一类所对应的奇异值分量筛选出来[18 ] ,重构为原始信号的趋势项为 ...
基于k-means聚类算法的分布式能源系统典型日冷热负荷选取
1
2021
... 然后,把其余各点划分到与两个类别中心距离近的一类,将两类点的均值作为新的类别中心进行分类,重复上述步骤,直至两个类别中心不再发生变化为止. 最后,将两类熵值点中平均熵值较低一类所对应的奇异值分量筛选出来[18 ] ,重构为原始信号的趋势项为 ...
PP检验对异方差时间序列的伪检验
1
2018
... 步骤一 对式(19)计算得到的趋势项TN ×1 进行平稳性(Phillips-Perron )检验[19 ] ,然后对检验结果为非平稳的时间序列作差分平稳化处理,表示为 ...
PP检验对异方差时间序列的伪检验
1
2018
... 步骤一 对式(19)计算得到的趋势项TN ×1 进行平稳性(Phillips-Perron )检验[19 ] ,然后对检验结果为非平稳的时间序列作差分平稳化处理,表示为 ...
基于AIC准则判断锂电池最优模型
1
2019
... 步骤二 对经过平稳化处理后的趋势项的 T ^ N × 1 AIC )定阶[20 ] ,其定阶准则表示为 ...
基于AIC准则判断锂电池最优模型
1
2019
... 步骤二 对经过平稳化处理后的趋势项的 T ^ N × 1 AIC )定阶[20 ] ,其定阶准则表示为 ...
ARIMA时间序列分析模型在臭氧浓度中长期预报中的应用
1
2021
... 步骤四 对ARIMA 模型的残差序列进行LB (Ljung-Box )统计量检验[21 ] ,表示为 ...
ARIMA时间序列分析模型在臭氧浓度中长期预报中的应用
1
2021
... 步骤四 对ARIMA 模型的残差序列进行LB (Ljung-Box )统计量检验[21 ] ,表示为 ...
排列熵算法参数的优化确定方法研究
1
2014
... 根据式(15)~(17)计算各奇异值分量的排列熵值.在相空间重构时,运用互信息法[22 ] 选取最佳延迟时间,在1~100 s的延迟时间范围内,各奇异值分量的互信息值Mi1~Mi8变化如图4 所示.采用伪近邻法[23 ] 计算最佳嵌入维数,在1~10的嵌入维数变化范围内,各奇异值分量的伪近邻率FNNP1~FNNP8随嵌入维数m 的变化如图5 所示. ...
排列熵算法参数的优化确定方法研究
1
2014
... 根据式(15)~(17)计算各奇异值分量的排列熵值.在相空间重构时,运用互信息法[22 ] 选取最佳延迟时间,在1~100 s的延迟时间范围内,各奇异值分量的互信息值Mi1~Mi8变化如图4 所示.采用伪近邻法[23 ] 计算最佳嵌入维数,在1~10的嵌入维数变化范围内,各奇异值分量的伪近邻率FNNP1~FNNP8随嵌入维数m 的变化如图5 所示. ...
基于MSOP的蒸汽动力系统单参数运行稳定性评估方法
3
2021
... 根据式(15)~(17)计算各奇异值分量的排列熵值.在相空间重构时,运用互信息法[22 ] 选取最佳延迟时间,在1~100 s的延迟时间范围内,各奇异值分量的互信息值Mi1~Mi8变化如图4 所示.采用伪近邻法[23 ] 计算最佳嵌入维数,在1~10的嵌入维数变化范围内,各奇异值分量的伪近邻率FNNP1~FNNP8随嵌入维数m 的变化如图5 所示. ...
... 取实际运行数据的前90%为训练数据,取后10%为检验数据,预测除氧器水位在未来94 s的变化趋势,结果如图7 所示.而在相同数据输入下,采用文献[23 ]中提出的无降噪处理的算法(MSOP)得到的预测结果如图8 所示. ...
... 由图7 和图8 可知,随着预测时长的增加,两种方法的预测误差都会增大.经计算,在采用MWSA方法时,预测结果与实际数据(检验数据)的均方差为1.388 7;而文献[23 ]中提出的方法其预测结果与实际数据(检验数据)的均方差为2.133 4.可知,本文预测方法的准确度更高. ...
基于MSOP的蒸汽动力系统单参数运行稳定性评估方法
3
2021
... 根据式(15)~(17)计算各奇异值分量的排列熵值.在相空间重构时,运用互信息法[22 ] 选取最佳延迟时间,在1~100 s的延迟时间范围内,各奇异值分量的互信息值Mi1~Mi8变化如图4 所示.采用伪近邻法[23 ] 计算最佳嵌入维数,在1~10的嵌入维数变化范围内,各奇异值分量的伪近邻率FNNP1~FNNP8随嵌入维数m 的变化如图5 所示. ...
... 取实际运行数据的前90%为训练数据,取后10%为检验数据,预测除氧器水位在未来94 s的变化趋势,结果如图7 所示.而在相同数据输入下,采用文献[23 ]中提出的无降噪处理的算法(MSOP)得到的预测结果如图8 所示. ...
... 由图7 和图8 可知,随着预测时长的增加,两种方法的预测误差都会增大.经计算,在采用MWSA方法时,预测结果与实际数据(检验数据)的均方差为1.388 7;而文献[23 ]中提出的方法其预测结果与实际数据(检验数据)的均方差为2.133 4.可知,本文预测方法的准确度更高. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}