

根据是否考虑光波在水中的传播过程,目前的水下图像增强算法可分为两大类:基于物理模型的增强算法和基于非物理模型的增强算法[7].前者需要对成像过程进行具体的数学建模,估算出其中的未知参数,进而反演出去除水体影响的清晰图像.最为经典的暗通道先验(DCP)算法[8],发现了陆上雾感图像与成像模型之间的关系,因此得到光波透射率和大气光的估计值,实现雾感图像的还原.由于水下成像过程与雾化过程类似,DCP算法也可应用于水下失真图像的修正.但是,此算法的适用场景非常有限,且增强结果易出现新的失真问题.更进一步,文献[9]提出了专门针对水下场景的水下暗通道先验 (UDCP)算法,此算法考虑了光波在水中传输的衰减特性,能求解出更准确的透射率分布.然而,由于水下环境复杂多变,难以构建准确普适的成像模型,且参数估计易存在偏差,所以得到的增强结果并不太理想.另一方面,基于非物理模型的增强算法则无需分析图像的成像过程,仅依靠降质图像的像素分布进行增强操作.由于只针对图像本身质量,一些传统的图像处理算法,如直方图均衡化、灰度世界法、小波变换、Retinex算法等,也可应用于水下图像增强.此类算法虽原理简单,但是易产生过度增强、人工噪声等问题.
近几年人工智能技术的发展,极大地推动了神经网络在众多领域的应用,水下图像增强任务也不例外[10].神经网络算法通过数据驱动,自主构建出输入样本与输出样本间的非线性映射函数,进而实现降质图像的修正.由于水下标签数据并不充足,且质量欠佳,现常用的网络类算法多基于半监督模式的生成对抗网络(GAN)[11].此类算法使用灵活多变,在图像的对比度和亮度调整上多有不错的表现.但是,在色偏校正和细节保留问题上,一些算法依然有较大的提升空间.文献[12]设计了一种循环生成对抗网络,通过双向训练方式实现理想清晰图像与水下失真图像的转换.此算法避免了成对水下数据难以获取的问题,能实现高效率的图像增强.然而在处理过程中,其增强结果往往难以与理想清晰情况保持一致,在色度和结构上存在一定的偏差.文献[13]提出了一种简单快速的生成对抗模型,能对水下图像的亮度、颜色等问题进行实时的修正,但是其结果易出现边缘细节的丢失,且无法去除模糊.
针对现有算法的不足,本文提出了一种结合MS-Se-Res(Multi-Scale Senet-Residual)模块[14]和双分支判别器的水下图像增强算法.该算法以GAN网络为基本框架,利用判别器的监督能力缓解对数据的依赖.与传统算法不同的是,本文在生成器部分采用了不同尺寸的Se-Res(Senet-Residual)模块,这种设计能够在提取更多有用特征的同时实现多范围信息的融合.此外,由于传统判别网络采用的单一标量判别图像真伪的判别方式容易丢失图像细节,所以本文在此基础上提出了全局-区域双判别方式,这种方式能够实现全局风格与局部细节的双重把控.在损失函数设计中,本文设计了仅考虑图像本身质量的无监督损失形式,使增强结果不受限于参考图像.同时,与对抗损失和内容感知损失一起共同对模型的优化方向进行约束.针对水下场景复杂多变的问题,本文收集了六类水下数据对算法的性能进行验证,并与典型算法进行比较.通过大量的实验评估,本文算法在主观视觉和客观指标层面都取得了优异的表现.
1 生成对抗网络结构设计
本文提出了一种基于条件生成对抗网络的水下图像增强模型,如图1所示,其主要由两部分组成,生成网络与判别网络.前者用于学习清晰图像的数据分布,并得到水下失真图像与此分布间的非线性变换关系,进而生成去除水体影响的伪清晰图像.生成网络结构如图2所示.其中: ki为i×i的内核尺寸;sj为长度为j的移动步幅;d为空洞卷积中的膨胀率;Conv为卷积运算;Conc为拼接操作.后者则对输入的图像进行真伪判别,清晰参考图像标签为真,而生成网络得到的伪清晰图像标签为伪.另外,判别网络采用双判别形式,能够分别对全局风格和细节边缘进行监督.在损失函数中,本文设计了仅考虑图像本身质量的无监督形式,其与对抗和内容损失一起共同对模型的训练方向进行约束,有助于缓解对数据的依赖.下面将对网络设计进行具体描述.
图1
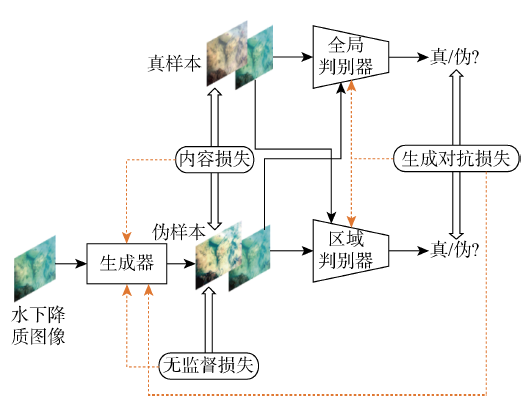
图2
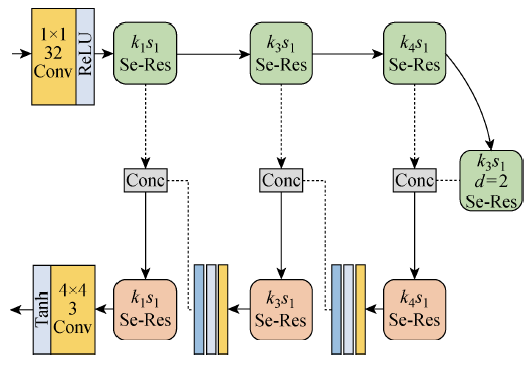
1.1 生成网络设计
网络输入为256像素×256像素×3像素的图像数据经过32通道1×1卷积操作和ReLU激活函数得到256像素×256像素×32像素的特征分布.首先,为了避免梯度稀疏问题,本模型采用基础卷积操作代替原Se-Res模块中的池化层,防止信息丢失,有助于提升网络稳定性.同时,为了实现多尺度特征信息的融合,本文在原始Se-Res模块的基础上,根据卷积位置选用不同尺寸的卷积内核.此外,卷积操作的内核尺寸会影响网络的参数量和计算量,因此,本文在深绿色模块中采用3×3空洞卷积[15]代替7×7的传统卷积,在保证感受野的同时减小了网络的复杂度,d设置为2.经过4个Se-Res模块操作后,在对称位置使用了相同尺寸的卷积处理.同时为了提升信息利用率,防止特征丢失,本文加入了多个直连通道,并利用拼接操作保证低层特征的完整传输.经过拼接后的特征分布为64通道,分别作为最后3个Se-Res模块的输入.除此之外,在拼接操作前,加入3层网络,其中黄、灰、蓝色分别是卷积操作、非线性激活和归一化处理.输出层卷积选择为4×4,激活函数设为Tanh,Tanh激活输出能既起到激活作用,又起到归一化作用.其将计算结果归一化到[-1, 1]之间,能够避免过大或过小的值.训练时将所有图像数据全部归一化到[-1, 1], 生成结果显示时再反向调整为[0, 255],所以Tanh激活函数的值经过调整即作为了输出图像三通道的像素值,由此可以得到最终的增强结果.
1.2 判别网络设计
图3
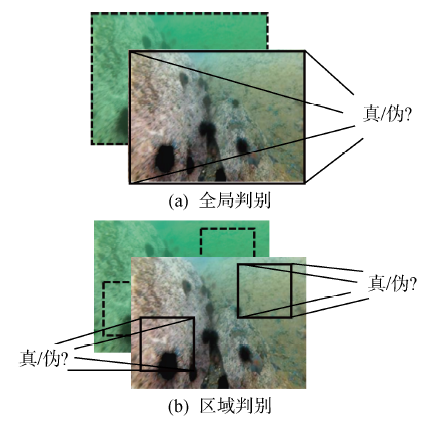
全局判别采用了对整体图像范围的判伪方式,网络中的基本模块采用CLB (ConV-LeaklyReLU-BN) 形式,首先通过步幅大于1的卷积实现图像降维,其次利用带来泄露的非线性函数使小于0的信息顺利传输,最后加入批归一化(BN)层实现分布的修正[17].而区域判别则选取以填充区域为中心的尺寸为256像素×256像素的图像块,再经过4次步长为2的卷积处理后其输出尺寸为16像素×16像素.区域判别采用多分类结果输出形式,每一个数值对应输入图像中的每一个部分.全局、区域判别网络设计相似,其最大区别在于全局判别输出为单一标量,而区域判别输出为16×16矩阵.
1.3 损失函数设计
为了缓解对数据的依赖,弥补样本不足的问题,本文在监督学习的基础上设计了仅考虑生成器输出图像本身质量的无监督学习形式[18].整个网络的损失函数包括三部分:质量驱动目标损失、对抗性目标损失、内容感知损失.
式中:
图4
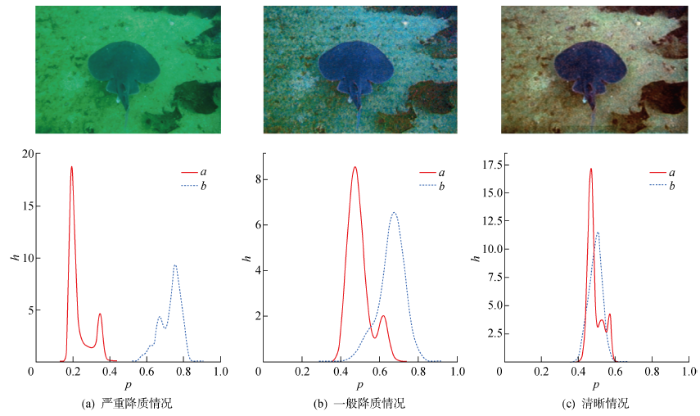
图4
不同质量的水下图像及其Lab分布
Fig.4
Underwater images with different qualities and their Lab distributions
1.3.2 对抗性目标损失 对抗性目标损失能够减少标注数据不足的影响,并更准确地提取融合水下失真图像的特征,其数学表达式如下所示:
式中: pr(x)和pg(x)分别为数据来源真伪的概率分布;t∈{1, 2}分别为全局判别和区域判别;x为输入数据;y为标签图像;G(x)为生成器输出;Dt/(x, y)为判别输出.这种函数形式限制了网络权重的更新方向,保证了整体输出的稳定性.
式中: Hk和Wk分别为经过网络k层处理后的特征图高宽; Ø k(·)为VGG模型前k层的网络参数;Iy,IG(x)为参考图像y和生成器输出图像G(x).
综上所述,本文损失函数整体表达式如下:
式中: ωU、ωGAN和ωC为3个损失函数的权重,分别取为0.3、0.3和0.4.
2 实验设计
2.1 参数设计
本文的实验环境配置是Intel Xeon E5-2640V4处理器,2.4 GHz主频,32 GB缓存空间和GTX 1080Ti GPU.编程语言和模型搭建平台为Python和PyCharm,训练框架基于Tensorflow和Kears.实验采用Adam优化器,初始学习率为 0.0003,一阶矩估计的指数衰减率为0.5.样本的预处理过程分为4个部分:选取小批量数据,修改大小为256像素×256像素,数据增强操作以及标准化处理到(-1,1).数据增强处理主要包括线性插入参考图像、左右翻转和上下翻转,实验采用random函数产生(0,1)之间的任意浮点数.本实验设置翻转概率为0.25.此外,每一迭代批量设置为4,整体循环次数设为200.
2.2 损失函数性能测试
本文从训练过程和训练结果出发,对损失函数进行组合训练与分析.图5和6为各损失函数训练过程对比.其中: Lall为3种损失函数组合;LGAN+C为对抗性目标损失函数与内容感知目标损失函数组合;LGAN+U为对抗性目标损失函数与质量驱动目标损失函数组合; n为迭代次数; l为损失函数值.
图5

图6
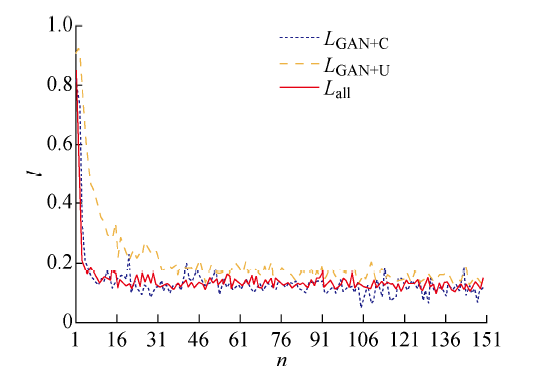
表1 各损失函数评价指标对比
Tab.1
| 损失函数形式 | LGAN | LGAN+U | LGAN+C | Lall |
|---|---|---|---|---|
| PSNR | 23.601 | 23.938 | 24.462 | 24.749 |
| SSIM | 0.711 | 0.732 | 0.745 | 0.764 |
3 实验结果分析
3.1 水下合成数据增强效果对比分析
合成数据集来自于EUVP数据集[13],其通过CycleGAN网络[28]进行对水下场景风格的学习和模拟.各种算法在合成数据集上的增强效果如图7所示.从视觉层面可以看出,图7(b)中的RayleighD算法图像色彩扭曲,出现了严重失真的问题.相对全局直方图拉伸(RGHS)算法增强不足, 使得图7(c)中残存大量水体噪声.图7(e)中Fus_2算法图像整体呈现灰白色,这是由于其过度增强的问题导致图像对比度和饱和度过低.图7(d)中的Fus_1、7(f)中的FGAN、7(g)中的UWCNN算法都引入了新的色偏,使得整体图像效果不佳.综合来看,本文算法的图像处理效果最佳,与参考图像的视觉效果几乎相同,在第1行的图像处理效果上甚至优于参考图像.其对于水体影响去除彻底,图像色彩鲜艳、亮度通透、纹理清晰,有着很好的色彩饱和度和视觉效果.因此从主观视觉来看,本文算法最佳.
图7

图7
各算法在合成数据集上的增强结果对比
Fig.7
Enhancement results comparison of various algorithms on synthetic datasets
表2 各增强算法在合成数据集上的评价指标对比
Tab.2
3.2 在真实数据上的结果对比
水下环境复杂多变,本文设置了偏绿、偏蓝、蓝绿、雾感、亮度不均不足5种不同场景进行验证,并从公开数据集和竞赛中收集真实数据.各算法增强结果如图8所示.由图8可知,在场景1的偏绿场景中,图8(b)中的RayleighD算法图像过度增强,色偏严重;图8(d)中的Fus_1算法图像残存大量水体噪声;图8(e)中的Fus_2算法图像饱和度鲜艳度不足;图8(c)中RGHS、8(f)中FGAN、8(g)中UWCNN算法图像整体分别呈现绿色、黄色、黄绿色,3种算法无法准确修正颜色分布.本文算法在处理绿色残留上效果明显优于其余算法,整体色彩鲜艳,各方面出色.在场景2的偏蓝场景中,其余算法无一能够很好地纠正蓝色主导的颜色分布,只有本文算法能够去除水体影响,还原出清晰图像.在场景3的蓝绿场景与偏绿场景类似,本文算法增强性能最优.在场景4的雾感场景中,除了图8(f)中的FGAN算法外,其余算法都去除了雾感影响,但都出现了色偏问题,只有本文算法输出了无水体色调残留,色彩饱和度高的清晰图像.在场景5的亮度不均不足场景中,由于输入图像质量过低,导致其余算法皆无法很好地还原图像色彩,但是本文算法依然输出了较其他算法更清晰的图像,而且没有出现色调偏离的失真情况.综上,本文算法的水下图像增强效果最好.
图8

图8
不同场景下数据增强结果对比
Fig.8
Comparison of enhancement results on different datasets
为了对增强结果的质量进行客观分析比较,从UIQM、CCF、信息熵3个方面的指标进行定量分析,如表3所示.对于UIQM指标,本文算法能够在所有场景下都得到最高的分值,且得分均匀,没有出现明显得分低的场景,而其余算法得分低且存在明显分值低的场景,浮动较大.从CCF指标来看,本文算法依旧得分最高,远超其余算法.最后从信息熵来看,虽然其余算法色彩变化明显,得分较高,但是本文算法依旧有最高的分值,在处理水下噪声去除方面有明显的优势.综上所述,本文算法有能够实现多场景的增强任务,有着出色的泛化性能.
表3 各增强算法在多场景数据上的评价指标对比
Tab.3
| 算法 | 场景 | UIQM | CCF | 信息熵 |
|---|---|---|---|---|
| 文献[23] | 场景1 | 3.079 | 20.426 | 7.507 |
| 场景2 | 2.420 | 19.494 | 7.051 | |
| 场景3 | 3.032 | 21.242 | 7.343 | |
| 场景4 | 3.382 | 21.134 | 7.454 | |
| 场景5 | 2.898 | 15.489 | 7.233 | |
| 文献[24] | 场景1 | 2.904 | 21.673 | 7.494 |
| 场景2 | 2.011 | 21.904 | 7.168 | |
| 场景3 | 3.059 | 21.286 | 7.519 | |
| 场景4 | 3.293 | 20.427 | 7.329 | |
| 场景5 | 2.690 | 16.985 | 7.305 | |
| 文献[25] | 场景1 | 3.022 | 22.459 | 7.549 |
| 场景2 | 2.623 | 21.427 | 7.247 | |
| 场景3 | 3.050 | 22.523 | 7.625 | |
| 场景4 | 3.340 | 21.842 | 7.472 | |
| 场景5 | 2.875 | 17.364 | 7.357 | |
| 文献[26] | 场景1 | 3.225 | 23.419 | 7.484 |
| 场景2 | 2.505 | 20.444 | 7.232 | |
| 场景3 | 3.121 | 20.302 | 7.532 |
续表3
| 算法 | 场景 | UIQM | CCF | 信息熵 |
|---|---|---|---|---|
| 场景4 | 3.429 | 23.140 | 7.467 | |
| 场景5 | 3.042 | 16.458 | 7.262 | |
| 文献[13] | 场景1 | 2.541 | 17.698 | 6.623 |
| 场景2 | 2.851 | 19.053 | 6.997 | |
| 场景3 | 2.669 | 12.017 | 6.459 | |
| 场景4 | 3.198 | 14.953 | 6.581 | |
| 场景5 | 2.270 | 10.881 | 6.244 | |
| 文献[27] | 场景1 | 2.418 | 12.589 | 6.403 |
| 场景2 | 3.108 | 16.396 | 6.846 | |
| 场景3 | 2.668 | 14.434 | 6.926 | |
| 场景4 | 2.912 | 11.469 | 6.162 | |
| 场景5 | 2.560 | 13.142 | 6.917 | |
| 本文算法 | 场景1 | 3.421 | 25.313 | 7.701 |
| 场景2 | 3.307 | 23.828 | 7.698 | |
| 场景3 | 3.272 | 24.259 | 7.698 | |
| 场景4 | 3.477 | 26.109 | 7.731 | |
| 场景5 | 3.194 | 19.491 | 7.444 |
4 结语
针对水下观测图像存在颜色失真和低对比度等问题,本文提出了一种基于生成对抗模型的水下图像修正与增强算法.该算法在生成部分将多尺度内核应用于Se-Res模块中,实现多感受野特征信息的提取与融合.判别部分设计考虑了全局信息与局部细节的关系,建立了全局-区域双判别结构,能够保证整体风格与边缘纹理的一致性;同时设计了仅考虑图像本身质量的无监督形式,其与有监督损失一起共同对模型的训练方向进行约束能够得到更优的色彩和结构表现.为了验证算法的性能,本文设计了多个对比分析实验,分别从主观视觉和客观指标上进行结果分析.实验结果表明,本文算法能有效提高图像清晰度,增强对比度,修正色偏,保护细节特征不丢失.
(本文编辑:石易文)
参考文献
Long period grating-based optical fibre sensor for the underwater detection of acoustic waves
[J].DOI:10.1016/j.sna.2013.07.017 URL [本文引用: 1]
A gravity gradient differential ratio method for underwater object detection
[J].DOI:10.1109/LGRS.2013.2279485 URL [本文引用: 1]
An experimental-based review of image enhancement and image restoration methods for underwater imaging
[J].DOI:10.1109/Access.6287639 URL [本文引用: 1]
An in-depth survey of underwater image enhancement and restoration
[J].DOI:10.1109/Access.6287639 URL [本文引用: 1]
An underwater image enhancement benchmark dataset and beyond
[J].DOI:10.1109/TIP.83 URL [本文引用: 1]
Single image haze removal using dark channel prior
[J].DOI:10.1109/TPAMI.2010.168 URL [本文引用: 1]
Transmission estimation in underwater single images
[C]//
A deep CNN method for underwater image enhancement
[C]//
Generative adversarial networks
[J].DOI:10.1145/3422622 URL [本文引用: 1]
Unpaired image-to-image translation using cycle-consistent adversarial networks
[C]//
Fast underwater image enhancement for improved visual perception
[J].DOI:10.1109/LSP.2016. URL [本文引用: 6]
SRM-net: An effective end-to-end neural network for single image dehazing
[C]//
Multi-scale context aggregation by dilated convolutions
[EB/OL].(
Globally and locally consistent image completion
[J].
Unsupervised representation learning with deep convolutional generative adversarial networks
[EB/OL].(
Visual-quality-driven learning for underwater vision enhancement
[C]//
Color image quality measures and retrieval
[D].
Statistics of cone responses to natural images: Implications for visual coding
[J].DOI:10.1364/JOSAA.15.002036 URL [本文引用: 1]
Perceptual losses for real-time style transfer and super-resolution
[C]//
Very deep convolutional networks for large-scale image recognition
[EB/OL].(
Underwater image quality enhancement through composition of dual-intensity images and Rayleigh-stretching
[C]//
Shallow-water image enhancement using relative global histogram stretching based on adaptive parameter acquisition[C]//International Conference on Multimedia Modeling
Enhancing underwater images and videos by fusion [C]//2012 IEEE Conference on Computer Vision and Pattern Recognition.
Color balance and fusion for underwater image enhancement
[J].DOI:10.1109/TIP.83 URL [本文引用: 3]
Underwater scene prior inspired deep underwater image and video enhancement
[J].DOI:10.1016/j.patcog.2019.107038 URL [本文引用: 3]
Unpaired image-to-image translation using cycle-consistent adversarial networks [C]//2017 IEEE International Conference on Computer Vision (ICCV)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}