上海交通大学学报 ›› 2021, Vol. 55 ›› Issue (5): 607-614.doi: 10.16183/j.cnki.jsjtu.2020.120
所属专题: 《上海交通大学学报》2021年12期专题汇总专辑; 《上海交通大学学报》2021年“自动化技术、计算机技术”专题
武光利1,2( ), 郭振洲1, 李雷霆1, 王成祥1
), 郭振洲1, 李雷霆1, 王成祥1
收稿日期:2020-04-26
出版日期:2021-05-28
发布日期:2021-06-01
作者简介:武光利(1981-),男,山东省潍坊市人,教授,现主要从事信息内容安全、人工智能等研究.电话(Tel.):0931-7601406;E-mail: 基金资助:
WU Guangli1,2(), GUO Zhenzhou1, LI Leiting1, WANG Chengxiang1
Received:2020-04-26
Online:2021-05-28
Published:2021-06-01
摘要:
针对传统视频异常检测模型的缺点,提出一种融合全卷积神经(FCN)网络和长短期记忆(LSTM)网络的网络结构.该网络结构可以进行像素级预测,并能精确定位异常区域.首先,利用卷积神经网络提取视频帧不同深度的图像特征;然后,把不同的图像特征分别输入记忆网络分析时间序列的语义信息,并通过残差结构融合图像特征和语义信息;同时,采用跳级结构集成多模态下的融合特征并进行上采样,最终获得与原视频帧大小相同的预测图.所提网络结构模型在加州大学圣地亚哥分校(UCSD)异常检测数据集的ped 2子集和明尼苏达大学(UMN)人群活动数据集上进行测试,均取得了较好的结果.在UCSD上的等错误率低至6.6%,曲线下面积达到了98.2%, F1分数达到了94.96%;在UMN上的等错误率低至7.1%,曲线下面积达到了93.7%,F1分数达到了94.46%.
中图分类号:
武光利, 郭振洲, 李雷霆, 王成祥. 融合FCN和LSTM的视频异常事件检测[J]. 上海交通大学学报, 2021, 55(5): 607-614.
WU Guangli, GUO Zhenzhou, LI Leiting, WANG Chengxiang. Video Abnormal Detection Combining FCN with LSTM[J]. Journal of Shanghai Jiao Tong University, 2021, 55(5): 607-614.
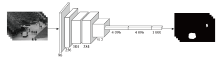
图1
FCN网络结构图
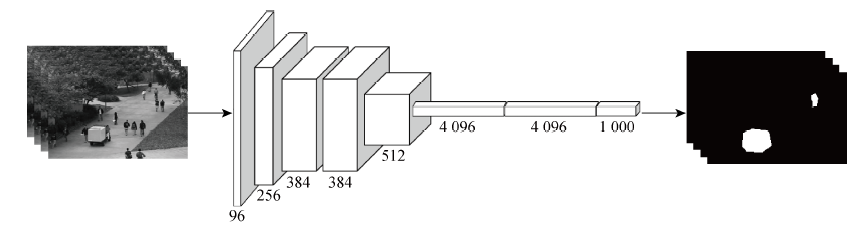

图2
LSTM网络细胞结构图

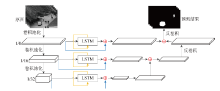
图3
FCN-LSTM模型结构图
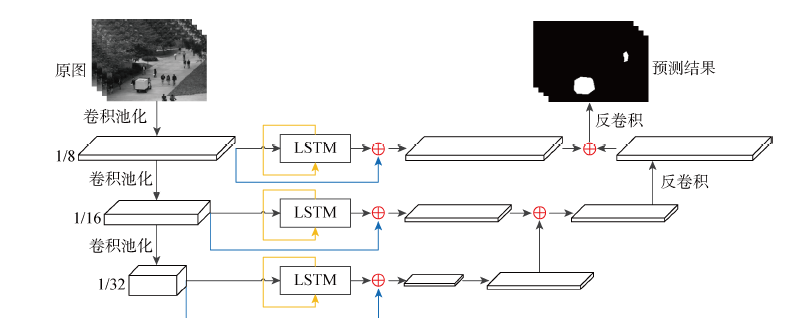

图4
UCSD数据集中的部分异常事件


图5
UMN数据集中的部分异常事件

表1
二分类混淆矩阵
| 真 | 假 | |
|---|---|---|
| 阳 | 真阳例 | 伪阳例 |
| 阴 | 伪阴例 | 真阴例 |
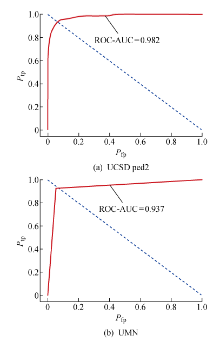
图6
ROC曲线(像素级)
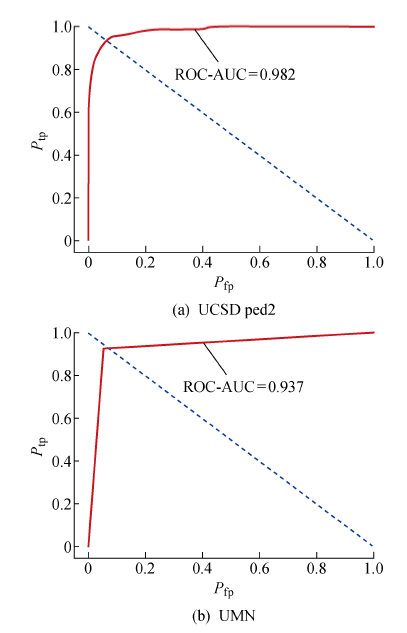
表2
实验结果(像素级)
| 数据集 | e/% | S/% | F1/% |
|---|---|---|---|
| UCSD | 6.6 | 98.2 | 94.96 |
| UMN | 7.1 | 93.7 | 94.66 |
表3
各模型对比分析(像素级)
| 模型 | e/% | S/% |
|---|---|---|
| HOF-HOG[ | - | 90.2 |
| OCELM[ | 17 | 80.1 |
| FCN[ | 15.0 | - |
| GM-FCN[ | 19.2 | 78.2 |
| MT-FRCN[ | 19.4 | 87.3 |
| FCN-LSTM | 6.6 | 98.2 |

图7
两个数据集中的部分预测结果

| [1] | WU G L, LIU L P, ZHANG C, et al. Video abnormal event detection based on ELM [C]//2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP). Piscataway, NJ, USA: IEEE, 2019: 367-371. |
| [2] | 闻辉, 贾冬顺, 严涛, 等. 智能视频异常检测事件研究分析[J]. 信息与电脑(理论版), 2019(12):49-50. |
| WEN Hui, JIA Dongshun, YAN Tao, et al. Research and analysis of intelligent video anomaly detection events[J]. China Computer & Communication, 2019(12):49-50. | |
| [3] | 胡正平, 张乐, 李淑芳, 等. 视频监控系统异常目标检测与定位综述[J]. 燕山大学学报, 2019, 43(1):1-12. |
| HU Zhengping, ZHANG (Le|Yue), LI Shufang, et al. Review of abnormal behavior detection and location for intelligent video surveillance systems[J]. Journal of Yanshan University, 2019, 43(1):1-12. | |
| [4] | MAHADEVAN V, LI W X, BHALODIA V, et al. Anomaly detection in crowded scenes [C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2010: 1975-1981. |
| [5] | 周飞燕, 金林鹏, 董军. 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6):1229-1251. |
| ZHOU Feiyan, JIN Linpeng, DONG Jun. Review of convolutional neural network[J]. Chinese Journal of Computers, 2017, 40(6):1229-1251. | |
| [6] | 何传阳, 王平, 张晓华, 等. 基于智能监控的中小人群异常行为检测[J]. 计算机应用, 2016, 36(6):1724-1729. |
| HE Chuanyang, WANG Ping, ZHANG Xiaohua, et al. Abnormal behavior detection of small and medium crowd based on intelligent video surveillance[J]. Journal of Computer Applications, 2016, 36(6):1724-1729. | |
| [7] | 柳晶晶, 陶华伟, 罗琳, 等. 梯度直方图和光流特征融合的视频图像异常行为检测算法[J]. 信号处理, 2016, 32(1):1-7. |
| LIU Jingjing, TAO Huawei, LUO Lin, et al. Video anomaly detection algorithm combined with histogram of oriented gradients and optical flow[J]. Journal of Signal Processing, 2016, 32(1):1-7. | |
| [8] | 都桂英, 陈铭进. 基于智能视频分析的运动目标异常行为检测算法研究[J]. 电视技术, 2018, 42(12):23-26. |
| DU Guiying, CHEN Mingjin. Research on anomaly detection algorithm of moving objects based on intelligent video analysis[J]. Video Engineering, 2018, 42(12):23-26. | |
| [9] |
CHEN T, HOU C P, WANG Z P, et al. Anomaly detection in crowded scenes using motion energy model[J]. Multimedia Tools and Applications, 2018, 77(11):14137-14152.
doi: 10.1007/s11042-017-5020-3 URL |
| [10] | LUO W X, LIU W, LIAN D Z, et al. Video anomaly detection with sparse coding inspired deep neural networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, PP(99):1. |
| [11] | 雷丽莹, 陈华华. 基于AlexNet的视频异常检测技术[J]. 杭州电子科技大学学报(自然科学版), 2018, 38(6):16-21. |
| LEI Liying, CHEN Huahua. Video anomaly detection based on AlexNet[J]. Journal of Hangzhou Dianzi University (Natural Sciences), 2018, 38(6):16-21. | |
| [12] | 章琳, 袁非牛, 张文睿, 等. 全卷积神经网络研究综述[J]. 计算机工程与应用, 2020, 56(1):25-37. |
| ZHANG Lin, YUAN Feiniu, ZHANG Wenrui, et al. Review of fully convolutional neural network[J]. Computer Engineering and Applications, 2020, 56(1):25-37. | |
| [13] | 周培培, 丁庆海, 罗海波, 等. 视频监控中的人群异常行为检测与定位[J]. 光学学报, 2018, 38(8):97-105. |
| ZHOU Peipei, DING Qinghai, LUO Haibo, et al. Anomaly detection and location in crowded surveillance videos[J]. Acta Optica Sinica, 2018, 38(8):97-105. | |
| [14] |
WANG S, ZHU E, YIN J, et al. Video anomaly detection and localization by local motion based joint video representation and OCELM[J]. Neurocomputing, 2018, 277:161-175.
doi: 10.1016/j.neucom.2016.08.156 URL |
| [15] | RAVANBAKHSH M, NABI M, SANGINETO E, et al. Abnormal event detection in videos using generative adversarial nets [C]//2017 IEEE International Conference on Image Processing (ICIP). Piscataway, NJ, USA: IEEE, 2017: 1577-1581. |
| [16] |
SABOKROU M, FAYYAZ M, FATHY M, et al. Deep-anomaly: Fully convolutional neural network for fast anomaly detection in crowded scenes[J]. Computer Vision and Image Understanding, 2018, 172:88-97.
doi: 10.1016/j.cviu.2018.02.006 URL |
| [17] |
FAN Y X, WEN G J, LI D R, et al. Video anomaly detection and localization via Gaussian mixture fully convolutional variational autoencoder[J]. Computer Vision and Image Understanding, 2020, 195:102920.
doi: 10.1016/j.cviu.2020.102920 URL |
| [18] |
SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4):640-651.
doi: 10.1109/TPAMI.2016.2572683 URL |
| [19] | HINAMI R, MEI T, SATOH S. Joint detection and recounting of abnormal events by learning deep generic knowledge [C]//2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2017: 3639-3647. |
| [1] | 张峻宁, 苏群星, 王成, 徐超, 李一宁. 一种改进变换网络的域自适应语义分割网络[J]. 上海交通大学学报, 2021, 55(9): 1158-1168. |
| [2] | 钟光耀, 邰能灵, 黄文焘, 李然, 傅晓飞, 纪坤华. 基于多维聚类的配变负荷注意力短期预测方法[J]. 上海交通大学学报, 2021, 55(12): 1532-1543. |
| [3] | 姜宇迪, 胡晖, 殷跃红. 基于无监督迁移学习的电梯制动器剩余寿命预测[J]. 上海交通大学学报, 2021, 55(11): 1408-1416. |
| [4] | 蒋兴浩, 赵泽宇, 许可. 基于视觉的飞行器智能目标检测对抗攻击技术[J]. 空天防御, 2021, 4(1): 8-13. |
| [5] | 马波,周越. 一种新的多视角人脸跟踪算法[J]. 上海交通大学学报(自然版), 2010, 44(07): 902-0906. |
| [6] | 应俊豪,张秀彬. 矿石颗粒尺度分布的双圆算法[J]. 上海交通大学学报(自然版), 2010, 44(03): 384-0388. |
| 阅读次数 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
全文 749
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
摘要 1445
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||