

目前,国内外对用户用能服务需求预测的研究主要侧重于从用电负荷中辨识出典型负荷特性,并结合用户的社会属性信息对用户分类,从而针对不同类型用户提供个性化用能服务[6-7].文献[8]中提出一种基于进化算法的电力客户服务需求特征表征新方法,较好适应电力客户服务随机性和多变性的特点,也可用于完成对客户的进一步分析,包括异常值检测以及行为研究;文献[9]中基于区域商业价值和区域宏观经济角度,使用反向传播神经网络算法建立了电力客户的需求预测模型,取得了良好的预测效果;文献[10]中提出并评估了低压客户典型负载曲线的表征模型,基于聚类分析进行用户行为模式识别;文献[11]中根据电力用户特点和价格套餐的多属性效用,充分考虑用户特征和包装属性对推荐结果的影响,提出了一种混合的电价套餐零售推荐方法;文献[12]中提出基于电力大数据的电网用户立体画像构建方法,能有效提高电力用户多维特征分类精度;文献[13]中提出基于长短时记忆网络-注意力机制融合的电力客户主动服务推荐方法,能较为精准地提取客户潜在服务需求;文献[14]中设计了基于综合学习粒子群优化的K-means聚类算法的电力客户评价细分及定制化增值服务系统,满足电力客户多元差异化的个性需求.
当前,基于电网大数据进行机器学习时效率受制于数据量较大,而精度受制于数据各类别数量不均衡,导致预测算法速度和精度均有待提高;同时,用户用能服务需求预测尚未形成根据用户特征、用户用电需求对用户用能服务需求进行预测的方法,且对于单个用户可能存在的多种服务需求的预测无法有效量化,预测结果相对于用户实际服务需求存在偏差,从而导致服务体验不佳,甚至引发舆论风险.
基于此,本文提出一种新型用户用能服务需求预测算法,具体包括:分析用能服务数据特点,研究数据增强算法来解决数据类不平衡问题,以确保算法模型权重不会过于偏向某一类别;研究基于自动编码器与K-means聚类融合的聚类算法,提高聚类速度;研究基于轻量级梯度提升机(light gradient boosting machine, LightGBM)的特征优选算法,以筛选出有效特征来提高模型训练效率;构建基于注意力机制的双向长短时记忆(bidirectional long short-term memory, BiLSTM)神经网络用户多标签分类算法,以实现对于用户多服务需求的量化.最后以广东电网某地区实际数据为例,对比分析本文算法与其他算法的预测性能效果.
1 数据预处理方法
对用户用能数据进行预处理,以满足后续研究要求.用户用能数据包括以电费、功率因数为代表的数值型数据,也包括以行业类别、位置为代表的字符型数据,数据内容复杂且存在冗余.为此,首先基于用户用能服务数据进行特征组合构造,并根据相关性分析法初步去除冗余特征组合;随后改进合成少数类过采样技术(synthetic minority over-sampling technique, SMOTE)以适应用户用能数据特点,以此进行数据类不平衡处理.
1.1 用户用能数据分析及特征构造
首先进行用户特征矩阵构造,从供电区域、行业类别、需求服务与用电客户之间等多个层级初步构造客户特征矩阵;并针对实收电费、实收附加费合计、电价和功率因数这几个特征,进行统计特征求算,包括均值、方差和中位数,以扩展数据的特征,最终构建了共计27个特征.对业务分类、业务子类、业务类别和申请时间等文本型数据采用LabelEncoder进行编码,LabelEncoder提供了一种简单易用的方法来将分类变量编码为数字,可以保留类别之间的相对关系,并且相比于其他编码方式,LabelEncoder生成的编码通常需要更少的内存空间,这对于处理大规模数据集或内存受限的环境非常重要.完成编码后,将数据进行归一化处理,以统一数据的量纲.
其中归一化采用最小-最大归一化的方法将各特征转化为[0,1]区间上的值,即
式中:xmax为样本数据中的最大值;xmin为样本数据中的最小值;x为样本数据.经过上述处理,最终得到用户用能服务需求特征矩阵.
基于用户用能服务需求特征矩阵进行相关性分析,以明晰特征之间的线性相关系.Pearson相关系数法可以评估两个变量之间的线性相关性,其取值区间为[-1, 1],-1 表示完全负相关,+1表示完全正相关.相关系数法除了可以判断特征与目标之间的线性相关性,还可以用来判断特征是否冗余[15].两个变量X和Y的Pearson相关系数计算公式为
式中:Xi和Yi分别代表任意两个特征值;
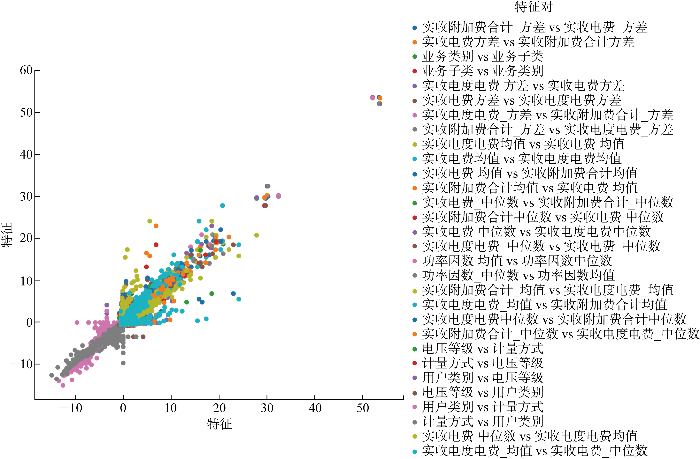
基于Pearson相关系数法进行特征分析并基于阈值进行筛选,如图1所示.可以看出,计量方式与用户类别、用户类别与计量方式、用户类别与电压等级等位于阈值0之下,不作考虑;为了提高精确性,本处仅设置阈值0作为特征筛选条件,后续非线性以及其他因素相关性均通过基于LightGBM的特征优选算法进行筛选.
图1
1.2 数据类不平衡处理
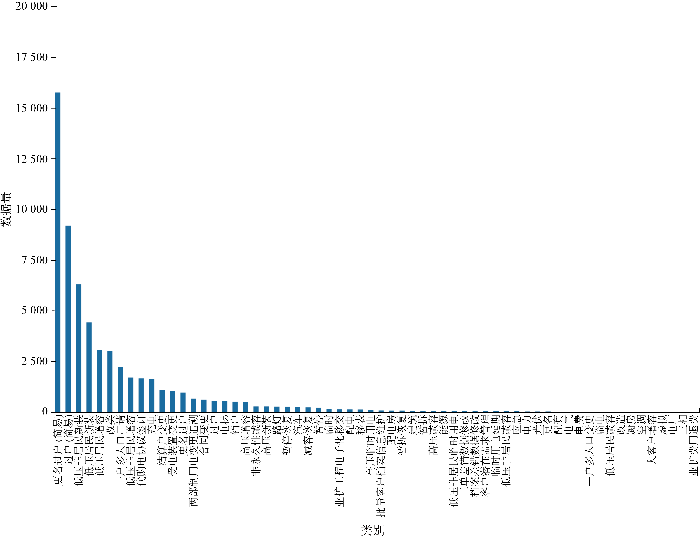
以广东电网下辖某地区为例,选取2019年7万条用户用能服务数据,如图2所示.数据类别分布较为不平衡,从单类来看,用电信息服务需求数据量高于其余类别;从增值服务和基础服务的角度来看,类不平衡率更高,这将极大影响预测准确率.
图2
重复第2步N次,便可获得N个新的样本.但是由于用户用能服务数据中不同业务数量的分布出现极端不平衡,为了保证SMOTE算法的准确性,本文改进SMOTE算法中k近邻法以适应数据特点.具体表现为对于每个少数类样本x,首先找到与x最近的k个邻居样本,定义为Nk(xi),这些邻居样本的选择根据带权重的欧氏距离计算确定.接下来,为每个样本x计算与其邻居样本的距离,并引入权重来调整距离,以使距离计算更关注少数类样本.距离的权重计算公式为
式中:Ai和Bi是样本A和B在第i个特征上的取值;wi是样本的第i个特征的权重.
根据带权重的距离,计算每个邻居样本与样本x的距离.在带权重的距离度量下,这些距离将更加重视邻居样本在重要特征上的相似性.基于这些带权重的距离,可以使用分类决策规则(如多数表决)来决定样本x的类别.例如,可以选择邻居样本中的多数类别作为样本x的类别:
式中:Ci表示一个类别,即一个可能的分类标签;νi表示样本xi的真实类别标签;Cj代表另一个可能的类别;I(νi=Cj)是一个指示函数,如果样本xi的真实类别νi等于Cj,则值为1,否则为0,它表示样本xi是否属于类别Cj.
图3
2 用户用电特性提取及标签库
在进行数据预处理之后,随即进行用户用电特性分析.鉴于用户用能服务数据量较大,基于自动编码器对数据进行降维处理,然后在选取特征和权值的基础上,采用聚类方法对样本进行相似性搜索并分类,基于分类结果进行用户多标签库建立.
2.1 基于自动编码器与K-means聚类算法
图4
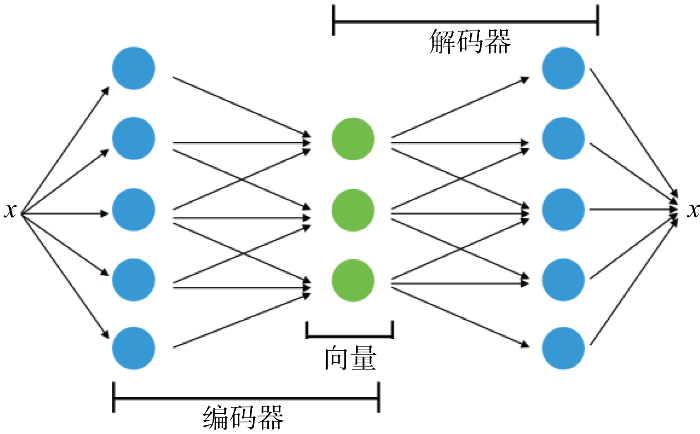
本文使用自动编码器对预处理后的数据进行降维处理,然后进行K-means算法聚类,以提高聚类效率,如图5所示.图中显示的是使用及不使用自动编码器对于聚类速度的对比,其中绿色线是使用了自动编码器的聚类速度,红线是未使用自动编码器的聚类速度,使用自动编码器对于聚类速度有较大提升,速度提升49.2%.
图5
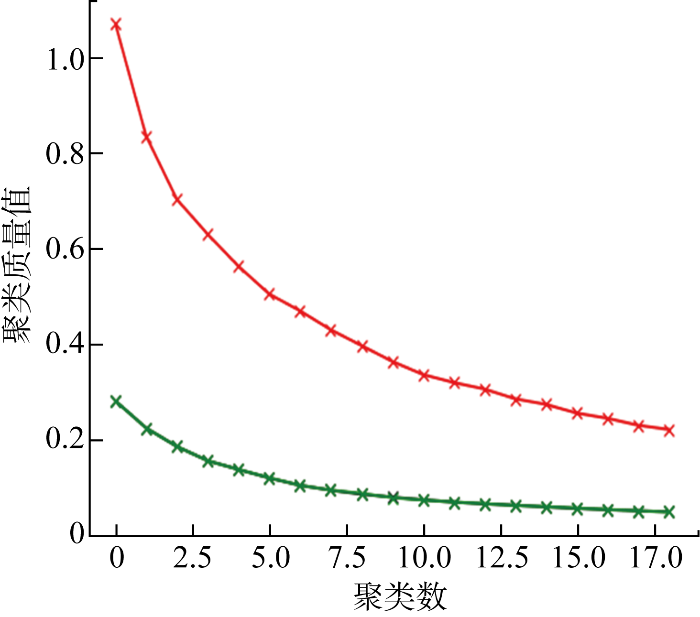
图5
基于自动编码器降维后的速度对比
Fig.5
Speed comparison plot based on autoencoder after dimensionality reduction results
本文基于自动编码器对数据降维处理后再进行K-means算法聚类.选取南方某地区3年数据进行聚类,本处采用肘点法及Silhouette进行聚类效果评判,评判曲线如图6所示.
图6

图6
基于肘点法及Silhouette聚类效果评判
Fig.6
Clustering effectiveness evaluation based on elbow point and Silhouette method
从图6中可以看出,聚类数量小于5时,聚类效果是最佳的,但是考虑到电网以客户视角重新构建形成了23项基础供电服务产品清单及29项增值服务业务,且按电网内部大类分服务类别也分为用电报装、用电变更、渠道服务、电费服务、故障抢修、电能质量这6个基础服务大类,还包括技术服务、能源服务、用电保电这3大类增值业务[19].显然将聚类数量单纯按肘点法及Silhouette得到的聚类效果图来确定是无法满足网公司实际需求的,因此本文在结合图6结果的同时,采用基于LightGBM的阈值确定法来共同确定最优聚类数量.具体步骤为,基于图6和电网公司基础供电服务类别,确定聚类数量的区间为[5,23].基于LightGBM的阈值确定法采用外部评估指标调整兰德指数(adjusted rand index,ARI)将聚类结果与已知的外部标签(真实类别)进行比较,以评估聚类的性能,ARI值的范围为( -1, 1),ARI越接近1,表示聚类结果越好,与真实标签的一致性越高.基于LightGBM的阈值确定法的结果如图7所示.
图7

图7
基于LightGBM的聚类效果评估
Fig.7
Clustering effectiveness evaluation based on LightGBM
从图7可以看出,当聚类数量取12时,ARI分数最高,这代表着当聚类数量取12时,聚类结果与真实标签的相似性较高.因此本文将聚类数量定为12类,以此进行聚类效果展示,后续章节将基于该聚类结果进行分析.
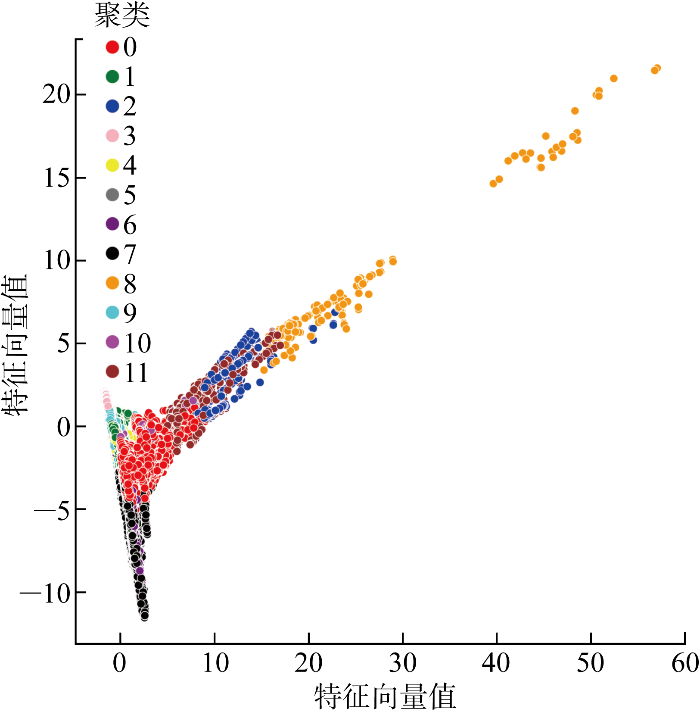
取聚类数量为12的聚类效果图如图8所示,从图中可以看出,聚类结果重叠较多,这在一定程度上表明了每个类别的数据样本可能在其他类别中也存在,即每个样本可能同时具有多个标签.
图8
2.2 用户用能服务多标签建立
实际应用中,某类用能服务所关联的需求特征标签可能并不唯一,因此用户可能对多种服务都具有潜在需求.多标签分类的学习模型如下:F= {f1, f2, …, fd}表示多标签数据d维特征,L= {l1, l2, …, lq}表示给定的标签信息[20].设特征空间为X=[X1X2 … Xn]∈Rn×d表示n个样例d维特征的特征空间,其中Xi表示第i个样本对应的特征向量,一个输入特征空间Xi由d维特征向量[Xi1Xi2 … Xid]构成.设标签空间为Y=[Y1Y2 … Yn] ∈Rn×q表示n个样例q个标签的标签空间,其中Yi表示第i个样本对应的标签向量,Yi是由d维特征向量[Yi1Yi2 … Yiq]构成的一个输出空间,即该数据集中有n个样本,d个特征, q个标签.用(Xi, Yi)表示一个样本,Xi= [Xi1Xi2 … Xid]表示输入向量,Y=[Yi1Yi2 … Yiq]表示输出向量,i ∈ {1, 2, …, n},设D表示训练集,D={(X1, Y1), …, (Xn, Yn)}.那么多标签学习任务的学习过程就是为了得到一个映射函数m:X→Y,对于任意标签未知的输入样本X',可以预测其对应的标签向量Y'.
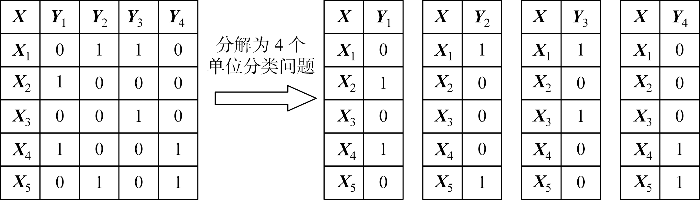
多标签构造应用的前提是二值化,由于数据量较大,本文采用哈希算法进行搜索排序并最终构建二维多标签化.为了满足上述多标签分类的学习模型,在对多标签化的结果进行二值化之后,还需要最终展成多标签数据d维特征,过程如图9所示.
图9
图9
多标签特征矩阵构建流程图
Fig.9
Flow chart for construction of multi-label feature matrix
3 预测模型
完成用户用电特性提取及标签库建立之后,接下来研究用户用能服务需求预测模型.首先构建基于LightGBM的需求预测模型,得到每个特征的重要性排序,分析构建新的特征组合;构建基于注意力机制的BiLSTM神经网络模型,将新的特征组合作为输入,完成模型训练.
3.1 基于LightGBM的特征优选算法
图10
选用不同的机器学习算法作为OVR的基分类器,通过验证其准确率、精准率及召回率来选择最佳基分类器.选择决策树、随机森林以及LightGBM作对比测试,如图11所示.通过图11可以清楚观察到,LightGBM适合用户用能需求数据预测,除了召回率,精准率、准确率均位于领先地位,且可以观察到对应的速度,以LightGBM为基分类器的多标签分类算法,速度分别比决策树(decision tree, DT)快41%,比随机森林(random forest, RF)快25%,对于更大的数据集而言,由于LightGBM使用了一种称为Histogram-based Learning的加速技术,它能够更快地构建树模型,这意味着在大型数据集上,它可以处理成千上万甚至更多的样本和特征,而不会显著增加训练时间,所以LightGBM将会发挥更大优势.
图11

图12
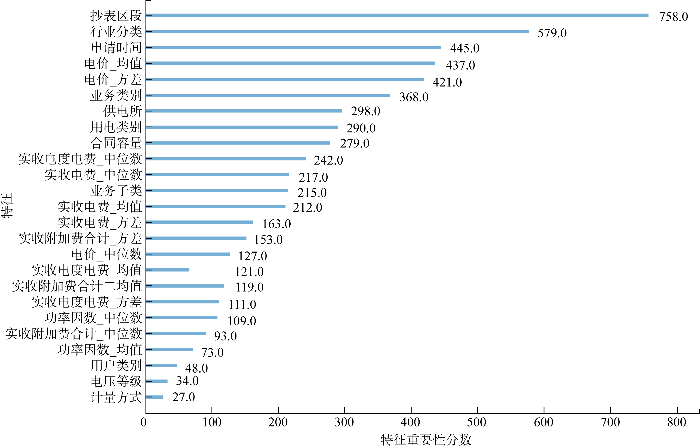
图13

3.2 基于注意力机制的BiLSTM神经网络模型
构建最终预测模型,考虑到用户用能属性的数据如电价、电费等,多与时间相关,在进行研究时需要考虑其时序规律.BiLSTM 由正向、逆向2个长短期记忆 (LSTM)神经网络构成,相比于标准LSTM中状态传输单向的从前往后,BiLSTM同时考虑前后数据的变化规律,展现出了更加优越的性能.BiLSTM结构示意图如图14所示.图中:x为输入序列特征值;y为输出序列值;h表示隐藏状态向量;t为时刻.
图14

鉴于用户用能数据量较大,本文将引入注意力机制(attention mechanism, AM),注意力机制模拟了人脑注意力在特定时刻对特定区域集中的情况,从而有选择性地获取更多有效信息,忽略无用信息[22].注意力机制层的权重系数计算公式可表示为
式中:w为权重矩阵;b为偏置项;u为注意力向量;e为注意力分数;a为注意力权重;s表示上下文向量.
基于分析,构建基于注意力机制的BiLSTM(AM-BiLSTM)网络如图15所示.模型包括输入层,输入为经过特征优选后的前60%的特征,具体见图12;3个LSTM层,每个LSTM层预设为256个隐藏单元,以更深层次和更多的容量捕获上下文信息;注意力机制层,用于动态加权各个时间步的隐藏状态,以生成上下文向量;一共具有60个单元的全连接层进行局部特征整合,即图中di;a代表可选参数,用来在实验中验算多一个特征的有效性;一个softmax层,通过softmax激活函数将其映射到多标签分类的概率分布.在训练过程中,采用Adam优化器,学习率预设为0.001,带动量和学习率衰减以加速收敛,交叉熵损失函数用于多标签分类任务.
图15

图15
AM-BiLSTM用户用能服务需求预测模型
Fig.15
AM-BiLSTM user demand forecasting model for energy services
模型的性能较大程度上取决于超参数的设置,为了保证模型的性能,在模型之外添加贝叶斯超参数优化算法,以此针对不同的数据进行模型的超参数优化.本文采用的贝叶斯优化模型图如图16所示.
图16
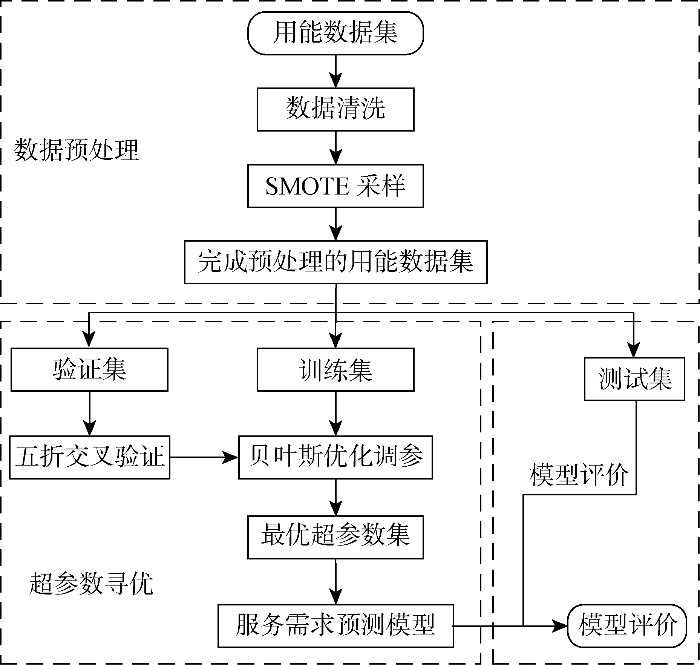
图16
基于贝叶斯优化的模型流程图
Fig.16
Flow chart of the model based on Bayesian optimization
3.3 算例分析
3.3.1 实验设计
为了验证本文算法的有效性,选取广东省某地区2019—2022年共72万条电网工单数据,如表1所示,以用户编号为索引进行整合,使用本文所提算法进行实验验证.所有实验在i7-12400F(2.8 GHz),Windows10 64位操作系统的计算机上进行.
表1 数据集信息
Tab.1
| 序号 | 层级 | 数据来源 | 类型 | 内容 | 采样时间 |
|---|---|---|---|---|---|
| 1 | 区域 | 营销管理系统 | 用户区域 | 抄表区段 | 2019-01—2022-01 |
| 2 | 行业 | 营销管理系统 | 用户类型 | 用户电表类型(工/商/居) | 2019-01—2022-01 |
| 3 | 用户 | 营销管理系统 | 用户信息 | 行业类别、用户编号、电表数 | 2019-01—2022-01 |
| 4 | 用户 | 营销管理系统 | 用户信息 | 用户类别、行业类别 | 2019-01—2022-01 |
| 5 | 用户 | 营销管理系统 | 工单信息 | 业务子类、时间 | 2019-01—2022-01 |
| 6 | 用户 | 智慧营业厅 | 工单信息 | 业务子类、时间 | 2019-01—2022-01 |
| 5 | 电表 | 营销管理系统 | 电表信息 | 报装容量 | 2019-01—2022-01 |
| 6 | 电表 | 计量系统 | 电量电费 | 用户月用电量、电费 | 2019-01—2022-01 |
表2 模型主要参数信息
Tab.2
| 参数 | 取值 |
|---|---|
| 轮数 | 300 |
| 隐藏层 | 256 |
| 学习率 | 0.02 |
| 层数 | 6 |
3.3.2 用户用能服务需求预测
首先对本文所提的特征优选算法进行验证,即选取LightGBM和AM-BiLSTM分别基于特征优选后的数据和未特征优选的数据进行训练对比,从准确率、汉明损失分析特征优选算法对于预测模型准确率的影响,以及从训练速度来验证特征优选算法对于模型训练效率的提升.实验结果如表3所示.
表3 特征优选算法的测试
Tab.3
| 算法 | 准确率 | 汉明损失 | 时间/s |
|---|---|---|---|
| LightGBM(未特征优选) | 0.764 9 | 0.187 8 | 249.43 |
| LightGBM(特征优选) | 0.899 3 | 0.100 7 | 126.32 |
| AM-BiLSTM(未特征优选) | 0.879 6 | 0.102 4 | 227.15 |
| AM-BiLSTM(特征优选) | 0.953 2 | 0.051 1 | 128.95 |
从表3中可以看出,基于LightGBM的预测模型在使用特征优选后的数据进行训练后,准确率为89.93%,相比于未使用特征优选数据的情况,准确率提升17.6%,速度则相比于未使用特征优选数据的模型提升49.4%;基于AM-BiLSTM的预测模型在使用特征优选后的数据进行训练后,准确率为95.32%,相比于未使用特征优选数据的情况下,准确率提升8.3%,速度相比于未使用特征优选数据的模型提升43.2%.由分析可知,本文所提的特征优选算法对于模型的预测性能起到正向作用,且对于模型的训练速度有显著提升,平均提升速度为46%左右.
进行不同算法在相同试验条件下的性能效果对比,即所述模型均采用优选后的数据进行训练以验证本文算法有效性.对比算法包括LightGBM算法、本文所提AM-BiLSTM算法、AM-LSTM算法、BiLSTM、门控神经网络-卷积神经网络(GRU-CNN)以及门控神经网络(GRU).各模型实验结果如表4所示.
表4 各模型性能评价
Tab.4
| 算法 | 准确率 | 汉明损失 | 时间/s |
|---|---|---|---|
| LightGBM | 0.899 3 | 0.100 7 | 126.32 |
| AM-BiLSTM | 0.953 2 | 0.051 1 | 128.95 |
| CNN-GRU | 0.949 5 | 0.051 7 | 289.45 |
| BiLSTM | 0.833 4 | 0.157 9 | 196.85 |
| AM-LSTM | 0.871 2 | 0.193 6 | 243.15 |
| AM-CNN-LSTM | 0.949 8 | 0.051 2 | 279.67 |
结合表4进行分析,本文所提最终模型AM-BiLSTM算法准确率达到95.32%,与机器学习LightGBM相比,准确率提高6.1%,速度相当;与深度学习模型AM-CNN-LSTM准确率相当,但是速度提高53.9%;且本文算法与其他深度学习模型相比,准确率均表现最优,准确率平均提高12.9%,速度平均提高46.3%.此外,本文所提算法的汉明损失始终最低,这验证了本文算法在多标签分类中的单标签准确率也处于领先地位.
4 结语
本文提出了一种基于特征优选的用户用能服务需求预测模型.具体包括:改进数据类不平衡处理方法有效地确保了各类用户用能服务数据的平衡性;提出基于自动编码器的K-means聚类算法可以提高电网大数据下的聚类速度;提出基于LightGBM的特征优选算法提高了模型训练速度,平均提高准确率12.9%、训练速度约46%;进而构建的AM-BiLSTM算法预测准确率高达95.32%,速度平均提高46.3%左右.综上,本文构建的需求预测模型可以在较高的训练效率下提高现代供电服务体系下的用户用能服务需求预测准确率,并具备适应不同维度数据的能力.
参考文献
Artificial intelligence techniques for enabling Big Data services in distribution networks: A review
[J].
智能配电网多元电力用户群体特性精准感知技术综述
[J].
A review of accurate sensing technologies for multiple power user group characteristics in smart distribution networks
[J].
双碳目标驱动的新型低压配电系统技术展望
[J].
Dual-carbon target-driven technology outlook of new low-voltage distribution system
[J].
智能电网电力监控系统网络安全态势感知平台关键技术研究及应用
[J].
DOI:10.16183/j.cnki.jsjtu.2021.S2.017
[本文引用: 1]

网络安全态势感知能全局、动态地感知潜在的网络安全风险,受到越来越多的关注.电力监控系统网络安全态势感知借助机器学习、人工智能、大数据等技术,从长期、海量网络安全态势数据处理过程中学习,洞察数据隐含的内在逻辑关系,对电力业务网络中各种活动实现异常行为辨识、攻击意图理解和行为影响评估,以达到对安全态势的推理性判断和知识性把控.本文首先简述了网络安全态势感知的基本概念和系统框架,然后介绍了电力监控系统网络安全防护的现状和存在的风险.针对这些风险和不足,从实践角度系统阐述了电力监控系统网络安全态势感知平台所涉及的多维度安全事件关联分析模型、基于“基线学习”的异常流量和异常行为检测方法、基于攻击场景的攻击链识别模型和基于“地址自校验”的电力遥控安全技术等关键技术.最后,对电力监控系统态势感知解决方案及其应用进行了总结和展望.
Research and application of key technology of network security situational awareness platform for smart grid power monitoring system
[J].
基于数据驱动的用电行为分析方法及应用综述
[J].
A review of data-driven power usage behaviour analysis methods and applications
[J].
融合外部注意力机制的序列到点非侵入式负荷分解
[J].
DOI:10.16183/j.cnki.jsjtu.2022.534
[本文引用: 1]
非侵入式负荷分解可以深度挖掘用户电力消耗数据蕴含的信息价值,为电力设备故障监测、需求响应等决策分析提供重要参考.为有效解决非侵入式负荷分解算法训练时间成本与分解精度间的冲突,提出一种融合外部注意力机制的序列到点非侵入式负荷分解算法.首先,将总负荷功率消耗序列进行数据清理、标准化等预处理,以固定窗口长度构建训练输入数据,输入数据通过编码层自动提取设备特征;然后,设计外部注意力机制增强重要特征权值;最终,输入到解码层得到负荷分解结果.利用REDD与UK-DALE两种公开数据集进行模型仿真计算,在信号聚合误差、平均绝对误差、标准化分解误差指标、模型分解曲线、特征图和用户耗能等方面进行对比分析,本文模型克服了卷积层注意力分散的缺点,增强了对有效信息的提取与利用能力,在未增加训练时间成本的前提下具有更高的分解精度.
Sequence-to-point non-intrusive load decomposition incorporating external attention mechanisms
[J].
新型电力系统多元用户的用电特征建模与用电负荷预测综述
[J].
A review of power usage characteristics modelling and power load forecasting for multiple users in new power systems
[J].
Customer segmentation based on the electricity demand signature: The Andalusian case
[J].
基于大数据分析的电力客户服务需求预测
[J].
DOI:10.7688/j.issn.1000-1646.2020.04.02
[本文引用: 1]
针对电力市场随机性、多变量和时变性的特点导致电力客户服务需求预测值不准确的问题,提出了一种基于大数据分析的电力客户服务需求预测方法.该方法依托于贵州地区的智能电网大数据,从区域商业价值和区域宏观经济角度来采集数据并通过挖掘其中的关联信息,建立了电力客户的细分模型;并在客户细分模型的基础上,使用BP神经网络算法建立了电力客户的需求预测模型.在Matlab平台上的仿真与测试结果表明,所提出的方法能帮助电网公司更好地理解客户行为和服务需求,制定营销策略.
Electricity customer service demand forecasting based on big data analysis
[J].
DOI:10.7688/j.issn.1000-1646.2020.04.02
[本文引用: 1]
Aiming at the problem of inaccurate forecasting of power customer service demand due to the randomness, multivariate and time-varying characteristics of power market, a service demand forecasting method for power customers based on big data analysis was proposed. The as-proposed method relied on Guizhou smart grid big data, the data were collected from the perspective of regional business value and regional macroeconomy, and a subdivision model for the power customers was established by collecting related information. On the basis of customer subdivision model, a BP neural network algorithm was used to establish a demand forecasting model for power customers. The simulation and test results on the Matlab platform show that the as-proposed method can help the grid company to better understand customer behavior and service needs, so as to develop marketing strategies.
Data mining techniques for electricity customer characterization
[J].
Research on the hybrid recommendation method of retail electricity price package based on power user characteristics and multi-attribute utility in China
[J].
电力客户准确定位与立体画像多维构建研究
[J].
Research on accurate positioning and multi-dimensional construction of three-dimensional portrait of electric power customers
[J].
基于LSTM-Attention融合的电力客户主动服务推荐方法
[J].
A proactive service recommendation method for electric power customers based on LSTM-Attention fusion
[J].
基于CSPSO-K-means算法的电力客户细分及定制化增值服务系统研究
[J].
Research on electricity customer segmentation and customised value-added service system based on CSPSO-K-means algorithm
[J].
考虑多气象因子累积影响的光伏发电功率预测
[J].
Power prediction of photovoltaic power generation considering the cumulative effects of multiple meteorological factors
[J].
利用生成对抗网络实现水下图像增强
[J].
DOI:10.16183/j.cnki.jsjtu.2021.075
[本文引用: 1]
提出一种基于生成对抗模型的水下图像修正与增强算法.该算法将多尺度内核应用于改进的残差模块中,以此构建生成器,实现多感受野特征信息的提取与融合;判别器设计考虑了全局信息与局部细节的关系,建立了全局-区域双判别结构,能够保证整体风格与边缘纹理的一致性;最后,根据人类视觉感官系统设计了无监督损失函数,此部分无需参考图像进行约束,同时其与对抗损失和内容损失一起进行联合优化,能够得到更优的色彩和结构表现.在多个数据集上进行实验分析表明,此算法能较好地修正色偏、对比度,保护细节信息不丢失,在主客观指标上都优于典型对比算法.
Underwater image enhancement using generative adversarial networks
[J].
基于SMOTE算法的船舶结构可靠性优化设计
[J].
DOI:10.16183/j.cnki.jsjtu.2019.01.004
[本文引用: 1]
针对常规船舶结构可靠性优化设计由高度非线性带来的计算效率低、收敛困难的问题,提出了基于SMOTE (Synthetic Minority Oversampling Technique)算法的船舶结构可靠性优化设计方法.利用SMOTE算法建立了改进的BP (Back Propagation)神经网络模型,以较少的样本点完成了极限状态函数的高度近似,克服了以往代理模型不能同时满足精度和效率要求的缺点,并通过数学算例验证了使用SMOTE算法建立BP神经网络模型的可行性和有效性.将改进的BP神经网络模型和模拟退火法嵌入单循环优化策略,并将其用于船舶舱段的可靠性优化设计,验证了所提出的可靠性优化设计方法的求解效率和精度,为大型工程结构的可靠性优化设计提供了思路.
Reliability optimisation design of ship structure based on SMOTE algorithm
[J].
基于去噪自编码器网络特征降维与改进小批优化K均值算法的海量用户用电行为聚类及分析
[J].
Clustering and analysis of massive users’ electricity consumption behaviour based on denoising self-encoder network feature dimensionality reduction and improved small batch optimization K-mean algorithm
[J].
基于组合模型的电力用户用电行为分层分类方法
[J].
A hierarchical classification method for power users’ electricity consumption behaviour based on combinatorial model
[J].
基于特征集重构与多标签分类模型的谐波源定位方法
[J].
Harmonic source localisation method based on feature set reconstruction and multi-label classification model
[J].
基于 LightGBM 和LSTM模型的电力大数据异常用电检测方法研究
[J].
Research on anomalous power usage detection method of electric power big data based on LightGBM and LSTM models
[J].
考虑多维影响因素的改进Transformer-PSO短期电价预测方法
[J].
DOI:10.16183/j.cnki.jsjtu.2023.065
[本文引用: 1]
随着多元化电力市场的建设,电价影响因素日益增加,市场环境变化也更加剧烈.为提高市场短期电价的预测精度,提出一种考虑多种电价影响因素的改进Transformer-粒子群优化(PSO)算法短期电价预测方法.首先,在考虑历史电价、负荷的基础上进一步分析电价形成的相关因素,利用自相关函数分析电价的多周期特性并在此基础上调整输入序列,克服了仅采用历史数据以及经验调整输入序列导致预测精度受限的问题.其次,结合长短期记忆(LSTM)、自注意力机制与多层注意力机制并采用多输入结构建立改进Transformer模型,进一步提升LSTM模型捕获不同时间步信息间的长短期依赖关系的能力,克服LSTM的信息利用瓶颈,适应包括历史电价及多种电价成因的复杂多序列输入.此外,还利用PSO智能算法搜索模型不同学习阶段的最佳学习率克服手动调整学习率的局限性.最后,采用PJM市场电价进行算例分析,结果表明所提短期电价预测模型能应用于电价影响因素多、变化剧烈的市场环境,并有效提升短期电价预测精度.
Improved Transformer-PSO short-term electricity price forecasting method considering multidimensional influencing factors
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}