

输电线路通道经常面临风筝、鸟巢和周围大型施工车辆、山火等安全隐患,极易造成线路断线、短路甚至引起电气火灾[1-2],严重威胁电网的安全运行和人民的生命财产安全.近年来,随着深度学习技术的快速发展,目标检测算法在输电线路通道检测中得到了广泛应用[3-4].例如,文献[5]中基于快速区域卷积神经网络(fast region-based convolutional network,Fast R-CNN)实现了线路通道中入侵工程车辆的识别和定位,但快速区域卷积神经网络提取单层特征,分辨率较小,对于多尺度和小目标问题检测效果不佳.文献[6]中利用多尺度卷积神经网络,结合定向边界框回归和尺度直方图匹配策略,使异物识别精度达到88.1%,但检测速度较慢,难以满足实时检测的需求.文献[7]中通过残差神经网络实现了绝缘子和鸟巢检测,但存储成本过高,难以实际部署.文献[8]中利用轻量级卷积神经网络改进的快速区域卷积神经网络实现绝缘子检测,但没有考虑复杂背景的干扰.文献[9]中使用单次多边框检测(single shot multibox detector,SSD)网络实现了绝缘子的检测,但经过较深的卷积层后,小目标信息丢失严重.
目标检测任务很难兼顾精度、速度、模型体积3个方面[10-11].YOLOv5是一种出色的目标检测模型,具有较高的检测精度、快速推理速度和简单而强大的架构[12-13],为该领域的发展提供了有利条件.文献[14]中将YOLOv5网络与特征平衡模块和特征增强模块相结合,实现了线路鸟巢的检测,鸟巢精度达到88.59%.文献[15]中基于YOLOv5实现了绝缘子掉串实时检测,改进双向特征金字塔网络提升了特征融合能力,检测精度提升3.91%.文献[16]中在YOLOv5主干特征提取网络最后一层添加了注意力机制,并对模型进行剪枝操作,但轻量化检测速度提升的同时检测精度较差.文献[17]中在YOLOv5网络中增加了更大规模的检测层,并添加了注意力机制提升特征融合能力.文献[18]中在YOLOv5网络基础上引入压缩和激励(SE)模块和卷积注意力模块(CBAM),遮挡目标检测精度有一定的提升,但使参数量增大,检测速度下降.综上所述,目前基于深度学习的输电线路通道异物检测还存在以下缺陷:小目标特征提取能力较差,易出现误检漏检;检测精度较低,难以满足输电线路通道入侵异物实际检测任务的需要;检测速度较慢;数据集局限较大,仅检测鸟巢、工程车辆等目标中的一种,无法全方面覆盖入侵安全隐患.
针对以上实际应用中存在的问题,本文提出一种基于窗口注意力机制与YOLOv5融合的输电线路通道异物检测算法.首先,将YOLOv5主干网络替换为窗口自注意力(Swin Transformer,S-T)网络,通过自注意力机制提升模型对复杂背景下小目标的特征提取能力,降低小目标漏检率.其次,将YOLOv5的颈部网络替换为自适应空间特征融合(adaptive spatial feature fusion,ASFF)方法,通过ASFF自适应地按照不同权重将不同层级的特征进行融合,为不同尺度目标提供更为全面和丰富的特征表示,以提高检测精度.然后,将广义交并比(GIoU)损失函数替换为对尺度和形状变化更加敏感的结构相似性交并比(SIoU)损失函数,增强目标定位准确度,进一步提升入侵目标检测精度.最后,建立包含导线异物、塔吊、烟火、防尘网4类目标的入侵异物数据集,丰富目标检测类别,覆盖多方面入侵安全隐患.
1 YOLOv5算法原理及局限性分析
1.1 YOLOv5算法原理
YOLOv5基于深度学习中的卷积神经网络,通过从输入图像中提取出不同层次和尺度的特征,结合先验框的信息来预测每个目标框的位置和类别等信息,从而实现目标检测的任务.相较于以往的YOLO版本,YOLOv5提供了更高的性能、更小的模型尺寸和更快的推理速度.
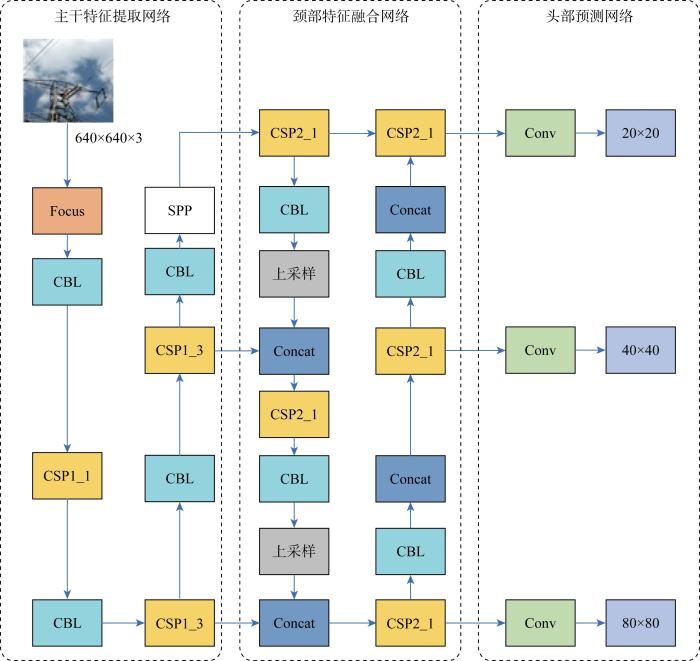
YOLOv5的结构主要包括3个部分:主干网络(backbone)、 颈部网络(neck)和头部网络(head).其框架如图1所示,图中:SPP为空间金字塔池化模块,Focus为聚焦模块,CBL为卷积块层,CSP为跨连接层,Concat为连接层.主干网络使用CSPDarknet53网络结构,并在其基础上添加了跨阶段连接和多层残差块等技术,以提高特征表达的能力和网络的深度.颈部网络使用特征金字塔网络(feature pyramid network,FPN)将来自不同层级的特征图进行融合.头部网络使用锚框的方法来进行目标检测,并结合GIoU函数预测检测框的置信度和类别得分,然后利用非极大值抑制(non-maximum suppression,NMS)将检测结果进行筛选,最终权矩阵中只保留最高得分的检测结果.
图1
1.2 YOLOv5算法局限性分析
YOLOv5算法相较于YOLOv4算法在检测精度和检测速度方面有了较大提升,但对输电线路通道异物的检测场景还存在以下缺陷.
(1) YOLOv5算法的原始主干网络使用CSPDarknet53网络结构,通过一系列的CSP模块和SPP模块进行多尺度特征提取和特征融合,但CSP模块中的池化操作容易导致小目标特征信息的丢失,进而导致小目标检测精度下降.
(2) YOLOv5网络的颈部网络使用特征金字塔融合不同尺度的特征,不同尺度特征之间具有不一致性,FPN采用启发式引导的特征选择,通常大目标与较高特征图相关联,小目标与较低特征图相关联.而输电线路通道图像目标尺寸、数目具有不确定性,当图像中既含有大目标又含有小目标时,不同层级特征之间存在冲突;并且FPN级联式连接容易导致信息流失和信息瓶颈,无法充分利用多尺度的目标特征,进而影响模型的检测精度.
(3) YOLOv5使用GIoU损失函数,GIoU比较依赖于交并比(IoU)项,当预测的边界框是水平或垂直时,需要多次迭代才能收敛,导致收敛速度慢,并且GIoU对于真实框和预测框的不匹配方向不敏感,目标定位不准确.
2 算法改进
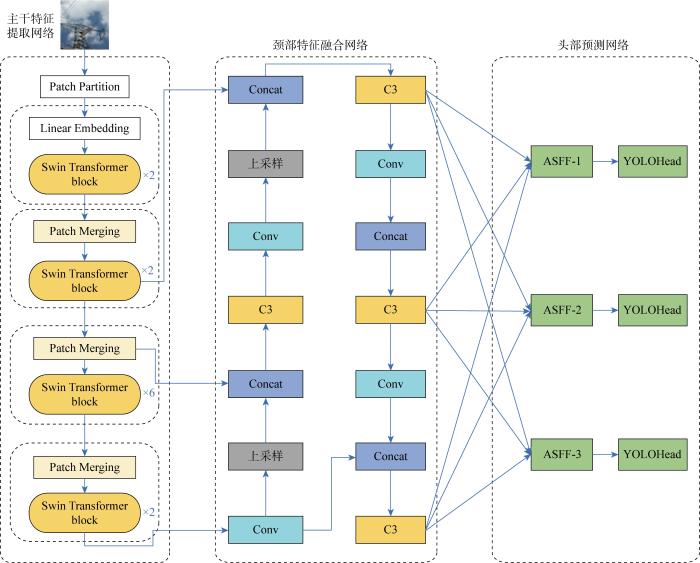
针对YOLOv5在输电线路通道检测场景实际应用所存在的问题,本文进行了如下改进.首先,将S-T网络融入YOLOv5的主干网络中,以提高全局和局部上下文信息的捕捉能力,从而避免丢失特征信息,提高了小目标检测能力.其次,设计自适应空间特征融合模块,基于ASFF处理不同尺度的特征图,自适应调整特征权重,为不同尺度目标提供更丰富的特征表示.最后,使用SIoU损失函数替换GIoU损失函数,充分考虑所需回归之间的向量角度,提高目标定位准确性以及检测精度.将融入S-T网络、ASFF、SIoU损失函数的YOLOv5算法称为YOLOv5-Swin Transformer-ASFF-SIoU算法,简称YOLOv5-SAS算法,其结构如图2所示.图中:C3层包含3个卷积,用于提取深度图像的特征;Patch Partition为切片模块;Linear Embedding为线性嵌入层;Patch Merging为图像块合并层;YOLOHead为YOLO预测头.
图2
2.1 基于S-T的特征提取网络改进策略
为解决YOLOv5在复杂背景下对小目标特征提取能力不足的问题,使用S-T替换主干网络.通过窗口自注意力机制在感受野内捕捉全局和局部上下文信息,从而能够更好地理解复杂的视觉场景.
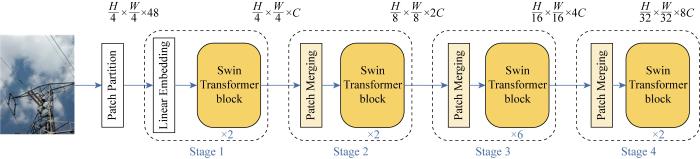
S-T网络结构如图3所示,图中H、W、C分别为图像的高度、宽度和通道数.网络架构主要包含图像块嵌入(Patch Embedding)和转换块(Transformer block)两个核心模块.首先通过切片模块对输入图像进行分块,将输入图片H×W×3划分为不重合的图像块(patch)集合,其中每个图像块尺寸为 4×4,那么每个图像块的特征维度为4×4×3=48,数量为
图3
两个连续的转换块基本结构如图4所示,主要由基于窗口的多头自注意力机制(window-based multi-head self-attention,W-MSA)、基于移动窗口的多头自注意力机制(shifted window-based multi-head self-attention,SW-MSA)、归一化层(layer normalization,LN)和两层感知机模型(multi-layer perception,MLP)组成.其中,W-MSA 层通过一个由多个头部组成的注意力矩阵输入特征图,并被划分成若干个窗口,在每个窗口内执行多头自注意力计算.SW-MSA在W-MSA的基础上引入位移操作,通过在窗口内部引入位移来增强特征图的局部性,从而更好地捕捉特征直接的相关性.通过局部和全局注意力机制学习全局特征和局部特征之间的相互依存关系,并通过跨层连接和残差结构进行信息的传递,实现特征的融合[21-22].MLP层则通过两个全连接层对特征向量进行前向传播,实现特征的变换和提取.注意力的计算限制在每个窗口内,并加入相对位置偏差B,进而减少了计算量,计算公式如下所示:
式中:Q为查询矩阵;K为键矩阵;V为值矩阵;d为Q和K的维度.
图4
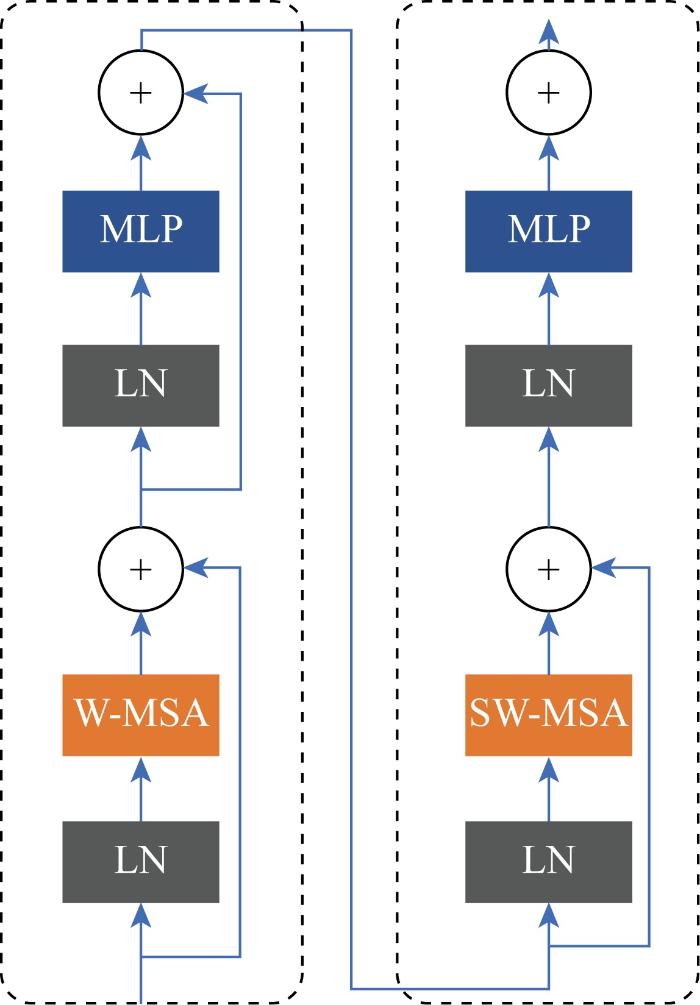
图5

2.2 基于ASFF的特征融合网络改进策略
为解决FPN不同层级特征的冲突和对复杂背景下小目标的感知能力较差的问题,引入 ASFF 方法,其结构如图6所示.
图6
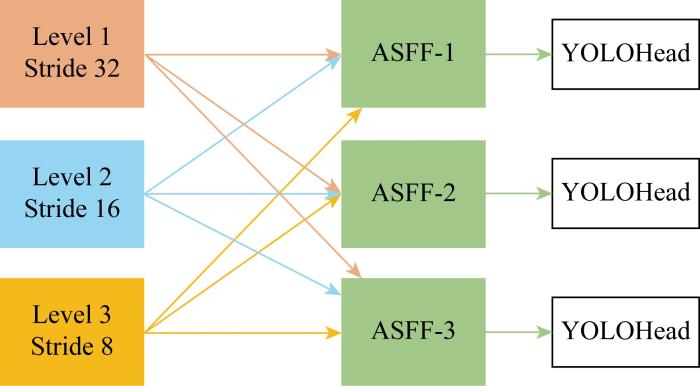
FPN可以生成多个尺度的特征层,每个尺度的特征层具有不同的分辨率和语义信息,即图6中的 Level 1、Level 2、Level 3,3个特征图的下采样倍数分别为32、16和8.ASFF自适应地调整特征权重,在其他级别上对特征进行空间滤波,可以有效解决FPN不同层级特征的冲突问题.具体融合过程如下:
式中:
对添加ASFF模块前后的模型进行特征可视化,特征图对比结果如图7所示.显然,添加ASFF模块后的算法特征图更为清晰,小目标的轮廓、结构信息更明显.ASFF自适应调整特征权重的方法避免因特征多级级联模型而导致的特征表达不充分,有效增强多尺度特征融合能力,提升小目标检测精度.
图7

2.3 基于SIoU的损失函数改进策略
为了解决GIoU损失函数收敛慢、目标预测框定位不准确的问题,采用SIoU损失函数替换GIoU损失函数.SIoU通过优化IoU来度量预测框和真实框之间的相似度,可以有效利用相似度度量的梯度信息,更好地指导模型的训练过程,提升检测精度和定位准确度.SIoU损失函数由角度损失Λ(angle cost)、距离损失Δ (distance cost)、形状损失Ω(shape cost)和交并比损失U(intersection over union)4个损失函数组成,参数示意图如图8所示.图中:B和Bgt分别为预测框中心点及真实框中心点;cw、ch分别为点B和Bgt横坐标与纵坐标之差;ϕ为两点连线与水平线的夹角;(bcx,bcy)为预测框中心坐标;(
图8
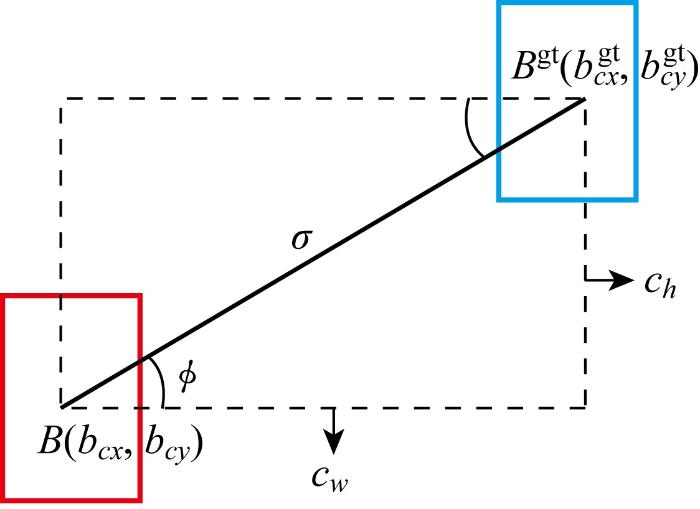
角度损失:
根据定义的角度损失,重新定义距离损失:
ρx=
形状损失:
ωw=
式中:w和h为真实框的宽和高;wgt和hgt为预测框的宽和高;θ为控制对形状损失的关注程度.
SIoU损失函数为
式中:fIoU为IoU损失函数.
图9

3 实验结果及分析
3.1 实验环境
实验使用Pytorch框架,软硬件平台配置如表1所示.
表1 实验硬件软件环境配置
Tab.1
| 配置名称 | 版本信息 |
|---|---|
| 系统 | Windows11操作系统 |
| 处理器 | Intel(R) Core(TM) i9-10900K |
| 显卡 | NVIDIA GeForce RTX 3070 8 GB内存 |
| Cuda版本 | 11.3 |
| CUDNN版本 | 8.2.1 |
| Python版本 | 3.8.13 |
| Torch版本 | 1.12.1 |
| Torchvision版本 | 0.13.1 |
| Numpy版本 | 1.23.1 |
3.2 数据集的建立
本实验使用的数据集由北京智芯微电子科技有限公司提供,包括10、110、220、500 kV交流架空线路以及 ±800 kV、±1 000 kV 特高压交直流架空线路.检测目标分为4类:塔吊、烟火、导线异物、防尘网,其中导线异物包括风筝、鸟巢、树枝等悬挂物.图10所示为4类目标示意,完整数据集包含 22 808 张图像.为了提高模型的泛化性,在数据增强方面采用Mosaic数据增强、图片翻转、平移色调增强以及饱和度增强等策略.使用Labelimg软件对数据集进行标注,并按9∶1的比例划分为训练集和测试集.测试样本共 6 429 张图像,其中塔吊目标 3 983 张,导线异物目标845张,烟雾目标533张,防尘网目标 1 068 张.
图10

3.3 性能评价指标
式中:PmA为平均精度均值;NTP为算法检测到的正样本中实际为正的样本数量;NFP为算法检测到的负样本中实际为正的样本数量;NFN为算法未能检测到的正样本中实际为正的样本数量;N为目标检测类别数,本文中为4.
3.4 模型训练
本文数据集图像大小为640像素×480像素×3,图像预处理阶段将输入图像统一缩放到640像素×640像素×3.网络模型训练时训练方法采用异步随机梯度下降法,动量大小参数取为0.937,每一批训练的批大小(batch size)为16[25].训练轮次为150轮,前100轮训练,学习率设置为0.01;后50轮训练,学习率为0.001.训练达到150轮时,精确率和损失趋近稳定,从而获得网络的训练权重.
图11
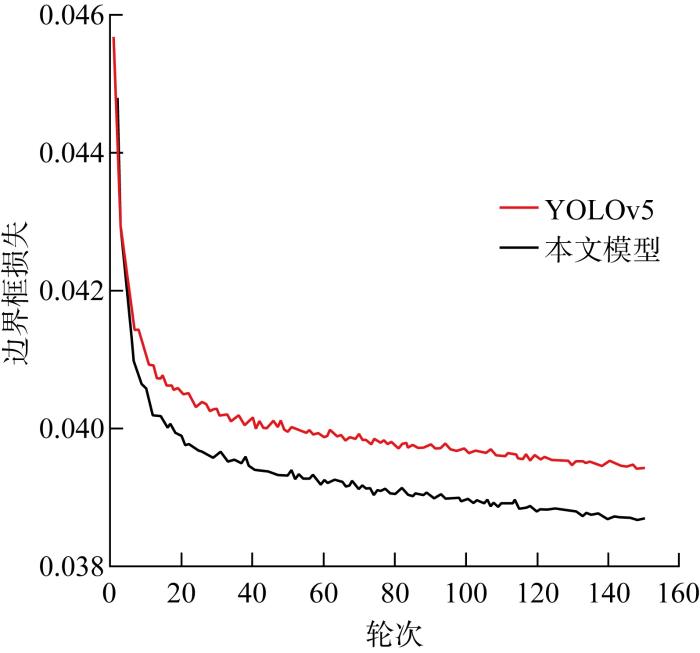
图11
本文模型与YOLOv5模型边界框损失对比
Fig.11
Comparison of box loss between the proposed model and YOLOv5 model
图12
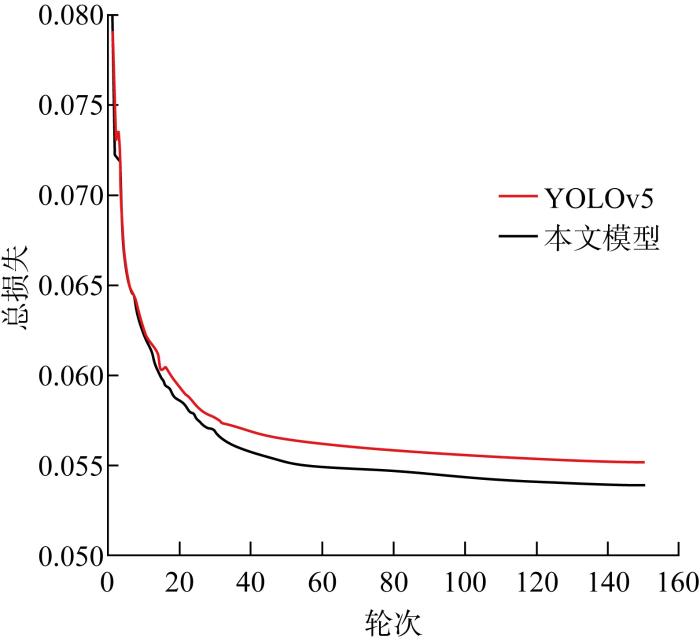
图12
本文模型与YOLOv5模型总损失对比
Fig.12
Comparison of total loss between the proposed model and YOLOv5 model
3.5 算法性能比较
3.5.1 改进前后对比实验
图13
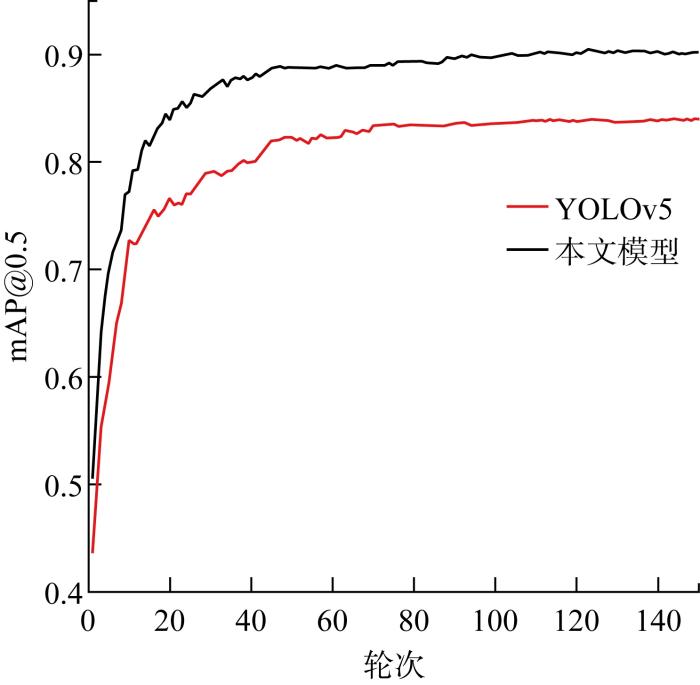
图13
本文模型与YOLOv5模型mAP@50%对比
Fig.13
Comparison of mAP@50% between the proposed model and YOLOv5 model
3.5.2 消融实验
为了评估改进策略对YOLOv5检测性能的影响,在相同数据集和训练策略的前提下进行了消融实验,结果如表2所示.
表2 消融实验结果对比
Tab.2
| 名称 | S-T | ASFF | SIOU | F1/% | mAP@50% | FPS/(帧·s-1) | 模型大小/MB |
|---|---|---|---|---|---|---|---|
| YOLOv5 | 76.7 | 83.9 | 57 | 25.2 | |||
| YOLOv5-S | √ | 81.1 | 87.5 | 52 | 26.1 | ||
| YOLOv5-A | √ | 80.6 | 86.2 | 54 | 25.7 | ||
| YOLOv5-SA | √ | √ | 83.1 | 89.6 | 46 | 27.6 | |
| YOLOv5-SAS | √ | √ | √ | 84.4 | 90.2 | 48 | 27.6 |
从表2可知,YOLOv5-S将主干网络换为S-T,增强了对复杂背景下小目标特征提取能力,更全面地挖掘图像信息,提高检测精度,其F1提升了4.4百分点,mAP提升了3.6百分点,检测速度和模型大小基本持平.YOLOv5-A添加了ASFF自适应特征融合模块,充分利用特征信息融合不同尺度的特征图,其F1提升了3.9百分点,mAP提升了2.3百分点,检测速度和模型大小基本持平.YOLOv5-SA替换主干网络的同时添加了ASFF模块,对于特征提取网络和特征融合网络效果提升明显,其F1提升了6.4百分点,mAP提升了5.7百分点,检测速度和模型大小略有增加.YOLOv5-SAS在YOLOv5-SA的基础上使用SIoU优化损失函数,其F1提升了7.7百分点,mAP提升了6.3百分点,检测速度和模型大小略有增加.综上所述,在输电线路通道异物检测任务中,YOLOv5-SAS模型在检测速度、模型大小基本持平的情况下,F1和mAP均有较大提升,充分说明本文针对性改进策略的有效性.
3.5.3 主流目标检测算法对比实验
为了验证YOLOv5-SAS模型的有效性,与目标检测中主流的单阶段和双阶段模型进行比较,检测结果如表3所示.
表3 主流检测方法对比
Tab.3
| 检测方法 | F1/% | mAP/% | FPS/(帧·s-1) | 模型大小/MB |
|---|---|---|---|---|
| SSD | 62.5 | 73.4 | 45 | 86.7 |
| Fast R-CNN | 69.3 | 77.2 | 15 | 207 |
| YOLOv4 | 73.6 | 80.3 | 43 | 55.4 |
| YOLOv5 | 76.7 | 83.9 | 57 | 25.2 |
| YOLOv5-SAS | 84.4 | 90.2 | 48 | 27.6 |
可以看出,双阶段的目标检测算法如快速区域卷积神经网络,推理速度较慢、模型较大,且检测精度较低.YOLOv4和SSD 在精确度和处理速度之间取得了一定的平衡,但精确度相对较低.本文YOLOv5-SAS算法相较于原始YOLOv5算法F1提升了7.7百分点,mAP提升了6.3百分点,同时保证了与原始YOLOv5相当的模型大小,检测速度可以满足实时检测的需求.
3.6 复杂场景检测性能分析
图14

4 结语
基于窗口自注意力网络与YOLOv5融合模型实现了输电线路通道入侵异物的快速准确识别.使用S-T优化主干网络,可以应对复杂的背景和遮挡干扰,更好地提取小目标特征信息.加入自适应加权特征融合模块ASFF,并且将矩形框损失改进为考虑真实框与预测框不匹配方向的SIoU,可以解决待测目标大小不均衡的问题,使得待测目标多尺度特征有效融合,提升了检测精度和定位准确性.实验结果表明,YOLOv5-SAS算法F1提升了7.7百分点,达到84.4%;mAP提升了6.3百分点,达到90.2%;检测速度为48帧/s,模型大小为27.6 MB,可以实时监测输电线路通道入侵异物,指导运维人员及时排除隐患,大幅提高运维效率.
在未来研究中,将结合实际的输电线路场景和监测需求对目标检测算法进行优化和改进,并进一步丰富数据集的种类.此外,还可以将电气信号、温度等不同的信号类型与目标检测技术相结合,建立智能化输电线路多模态检测模型.
致谢
感谢北京智芯微电子科技有限公司为本文提供输电线路通道实拍图像数据支持.
参考文献
基于深度学习的输电线路视觉检测方法研究进展
[J].
Research progress of vision detection methods based on deep learning for transmission lines
[J].
Object detection with deep learning: A review
[J].
面向架空输电线路的挂载无人机电力巡检技术研究综述
[J].
Review on mounted UAV for transmission line inspection
[J].
Environment perception technologies for power transmission line inspection robots
[J].
Engineering vehicles detection based on modified faster R-CNN for power grid surveillance
[J].
A deep learning method to detect foreign objects for inspecting power transmission lines
[J].
Intelligent fault detection of high voltage line based on the Faster R-CNN
[J].
基于改进Faster-RCNN的输电线路巡检图像检测
[J].
Transmission line inspection image detection based on improved Faster-RCNN
[J].
Detection method of insulator based on single shot MultiBox detector
[J].
多尺度目标检测的深度学习研究综述
[J].
Deep learning for multi-scale object detection: A survey
[J].
Complex ISAR target recognition using deep adaptive learning
[J].
基于计算机视觉的架空输电线路机器人巡检技术综述
[J].
Survey of inspection technology of overhead transmission line robot based on computer vision
[J].
基于深度学习的YOLO目标检测综述
[J].
A review of YOLO object detection based on deep learning
[J].
基于改进YOLOv5的输电线路鸟巢检测方法研究
[J].
Bird nest detection method for transmission lines based on improved YOLOv5
[J].
基于无人机航拍的绝缘子掉串实时检测研究
[J].
DOI:10.16183/j.cnki.jsjtu.2021.416
[本文引用: 1]

由无人机代替人工进行电力绝缘子巡检具有重要意义,针对无人机的上位机算力和存储资源有限的问题,提出一种适用于绝缘子掉串故障检测的实时目标检测改进算法.以YOLOv5s检测网络为基础,将颈部结构中路径聚合网络替换为双向特征金字塔网络,以提升特征融合能力;使用DIoU优化损失函数,对模型进行γ系数的通道剪枝和微调,总体上提升检测网络的精度、速度和部署能力;在网络输出处进行图像增强以提升算法可用性.在特殊扩增的绝缘子故障数据集下测试,相较于原始的YOLOv5s算法,改进算法在精度平均值上提升了3.91%,速度提升了25.6%,模型体积下降了59.1%.
Real-time detection of insulator drop string based on UAV aerial photography
[J].
基于轻量化改进型YOLOv5s的可见光绝缘子缺陷检测算法
[J].
Defect detection algorithm based on lightweight and improved YOLOv5s for visible light insulators
[J].
Research on object detection of overhead transmission lines based on optimized YOLOv5s
[J].
基于改进YOLOv5在电力巡检中的目标检测算法研究
[J].
Research on target detection algorithm based on improved YOLOv5 in power patrol inspection
[J].
基于窗口自注意力网络的单图像去雨算法
[J].
DOI:10.16183/j.cnki.jsjtu.2022.032
[本文引用: 1]
单图像去雨研究旨在利用退化的雨图恢复出无雨图像,而现有的基于深度学习的去雨算法未能有效地利用雨图的全局性信息,导致去雨后的图像损失部分细节和结构信息.针对此问题,提出一种基于窗口自注意力网络 (Swin Transformer) 的单图像去雨算法.该算法网络主要包括浅层特征提取模块和深度特征提取网络两部分.前者利用上下文信息聚合输入来适应雨痕分布的多样性,进而提取雨图的浅层特征.后者利用Swin Transformer捕获全局性信息和像素点间的长距离依赖关系,并结合残差卷积和密集连接强化特征学习,最后通过全局残差卷积输出去雨图像.此外,提出一种同时约束图像边缘和区域相似性的综合损失函数来进一步提高去雨图像的质量.实验表明,与目前单图像去雨表现优秀的算法MSPFN、 MPRNet相比,该算法使去雨图像的峰值信噪比提高0.19 dB和2.17 dB,结构相似性提高3.433%和1.412%,同时网络模型参数量下降84.59%和34.53%,前向传播平均耗时减少21.25%和26.67%.
A single image deraining algorithm based on Swin Transformer
[J].
SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer
[J].
SwinSUNet: Pure transformer network for remote sensing image change detection
[J].
基于注意力机制与跨尺度特征融合的YOLOv5输电线路故障检测
[J].
YOLOv5 transmission line fault detection based on attention mechanism and cross-scale feature fusion
[J].
Dynamic coarse-to-fine ISAR image blind denoising using active joint prior learning
[J].
Robot target recognition using deep federated learning
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}