

新能源开发逐渐成为各个国家的核心目标,而风能是目前技术最成熟的清洁能源,其中风力发电机是实现循环利用风能发电的主要设备[1].风力发电机具有系统复杂、多学科综合、批量小、周期长的特点,装配工艺非常复杂,高度依赖专家知识,且在产品迭代的过程中会产生大量历史装配工艺信息,以碎片化、多源异构、多种模态的形式存储于数据库中.一方面,需要工艺设计人员在数据库中反复对跨系统、多模态数据进行查询、判断和学习,不仅容易产生纰漏,效率低下,而且设计经验和能力难以共享和传承;另一方面,数据库中大量历史装配工艺数据难以得到有效管理和运用,造成数据维护效率低、成本高、资源浪费[2].因此,如何将风力发电机装配过程中产生的碎片化、多源异构、多种模态的工艺知识转化为统一的、有组织的、可以传播并重用的知识[3],对提高风力发电机装配效率和历史工艺数据管理维护水平具有十分重要的意义.
目前,工艺知识建模领域分为面向对象建模、基于流程建模、基于本体建模和基于知识图谱建模.面向对象建模方面,Xu等[4]将复杂产品中的装配关系定义为类,以有效减少组合爆炸情况;Song等[5]从组织角度描述众包对象之间的信息传递,完成复杂产品协同设计.基于流程建模方面,董晨阳等[6]将流程信息与资源信息融为一体,分析解决制造资源实时变化问题;Rudnitckaia等[7]结合过程挖掘和价值流方法对燃气表组装过程进行分析管理.基于本体建模方面,Das等[8]和施昭等[9]都采用基于网络本体语言的本体建模方法实现了机械工艺知识模型构建.基于知识图谱建模在本体建模基础上强化了结构化知识组织和表达能力,以三元组的形式组织信息,能够更高效地处理具有复杂语义关系的多源异构数据.李秀玲等[10]依据国际标准构建工艺知识图谱,提出基于知识图谱的工艺重用方法;吴闯等[11]提出针对航空发动机润滑系统的故障知识图谱建模方法,实现知识驱动的故障诊断策略;顾星海等[12]提出一种基于知识图谱的面向装配语义信息建模方法,有效提升不同类型装配语义信息之间的关联性.
然而,上述4类工艺知识建模方法在风力发电机装配中仍存一些缺陷.风力发电机产品研发数据与工艺数据中存在多个系统,且数据多源异构,存在三维模型、自然文本、图像等多模态数据形式.面向对象建模方法侧重于类的结构,缺乏对相关关系的描述;基于流程建模方法对于各类数据可集成统一管理,但对于语义和时序关系的描述较弱;基于本体建模和知识图谱建模仅针对单一模态,而在工艺知识库中存在大量自然文本、图像、三维模型等多种模态数据,因而构建多模态的知识图谱可能对于工艺知识融合效果更好[13].例如Kannan等[14]对出版刊物进行多模态知识提取与知识图谱构建,李星原等[15]构建针对癫痫病医疗知识的多模态知识图谱,都取得了比单模态图谱更优的效果.
综上所述,面向风力发电机多源异构装配数据,开展多模态知识图谱建模方法研究.首先,描述风力发电机多模态知识图谱(Multi-Modal Process Knowledge Graph of Wind Turbine, MPKG-WT)的定义、数据格式及构建流程;然后,结合不同模态的风力发电机装配数据介绍建模方法;最后,以某风力发电机公司的产品装配数据为例,验证该模型框架及构建方法的可行性.
1 风力发电机多模态工艺知识来源
在风力发电机装配中,知识来源于作业指导书、安装手册、维修记录、工艺文档、模型文件、维护手册等多源异构数据,而其中单一数据来源也可能存在文本、图像、模型等多模态的工艺知识,如图1所示.例如,作业指导书与安装手册以word文档形式存储,存在文本和图像信息;装配模型由多个子零件构成;JSON工艺文档以半结构化的方式记录工艺信息.因此,对各模态数据进行分类,能够帮助多模态知识图谱的快速构建.
图1

图1
部分多源异构数据示例(截图)
Fig.1
Some examples of multi-source heterogeneous data (capture)
为保证风力发电机装配工艺知识的有效获取,通过分析其数据特点,将其划分为以下3种主要模态的数据:
(1) 文本模态工艺知识.文本模态的工艺知识是利用自然语言描述的装配工艺操作语句,主要来源于各作业指导书、装配工艺文档等.文本模态的工艺知识包含丰富的装配工艺信息,是多模态图谱构建的重要基础.
(2) 图像模态工艺知识.图像模态的工艺知识主要包括辅助理解装配工艺语句的图像、装配工艺流程中所涉及的工具或零部件图像等.图像模态的工艺知识较为形象,能够更好地帮助操作人员理解装配工艺语句中的抽象概念,并更迅捷地锁定某零部件.
(3) 三维模型模态工艺知识.三维模型模态的工艺知识蕴含于待装配机械零件的三维模型中,主要展现装配工艺中的空间几何特征及层级关系信息,如零部件间的组成关系、装配特征间的配合关系等.对于工艺设计从业者,三维模型能够帮助他们有效且迅速地制定一套装配工艺.
2 风力发电机多模态图谱建模方法
2.1 多模态工艺图谱建模总体流程
MPKG-WT是一个以风力发电机多模态工艺数据为节点,以它们之间各种语义关系为边的结构化语义网络,其建模流程主要包括4个步骤,如图2所示.
图2
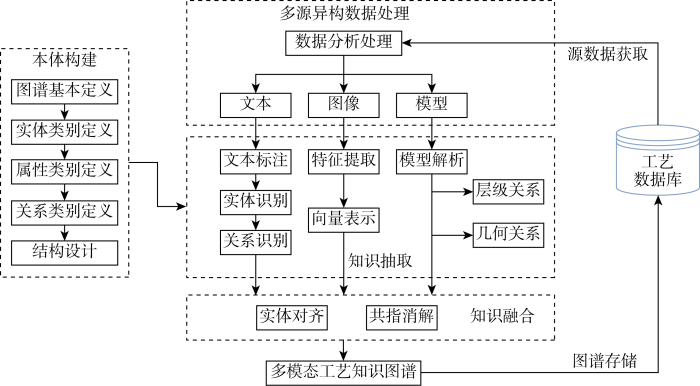
第一步:本体构建.首先,给出风力发电机多模态工艺知识图谱的相关定义;其次,针对不同模态的知识给出各自属性类别;最后,得出风力发电机多模态工艺知识图谱模式层.
第二步:多源异构数据处理.通过利用数据分析技术对多源异构的数据进行解析,从中分离出对应文本、图像、模型类的工艺知识,并获得3种模态之间的对应关系.
第三步:知识抽取.在模式层的引导下,对各个模态知识采用实体关系抽取相关技术以获得知识图谱的组成单元三元组,从而完成数据层的构建.
第四步:知识融合.在上述工作的基础之上,对3种模态知识之间进行实体对齐和共指消歧,最终完成风力发电机多模态工艺知识图谱的构建,实现跨模态知识的统一表示.
2.2 本体构建
为形式化规范风力发电机多模态工艺知识图谱中的多模态实体及关系类别,首先给出图谱的本体结构定义.
定义1 MPKG-WT在传统知识图谱的基础上加入其他模态知识,可表示为
其中:E为所有实体集;R为所有关系集;A为所有属性集;TW为文本类工艺知识三元组集合;TV为图像类工艺知识三元组集合;TM为三维模型类工艺知识三元组集合.每一个三元组可以表示为T={(s, p, o)|Ti∈(TW∪TV∪TM),i =1, 2, …, b},s、p、o分别代表主语、谓语、宾语.
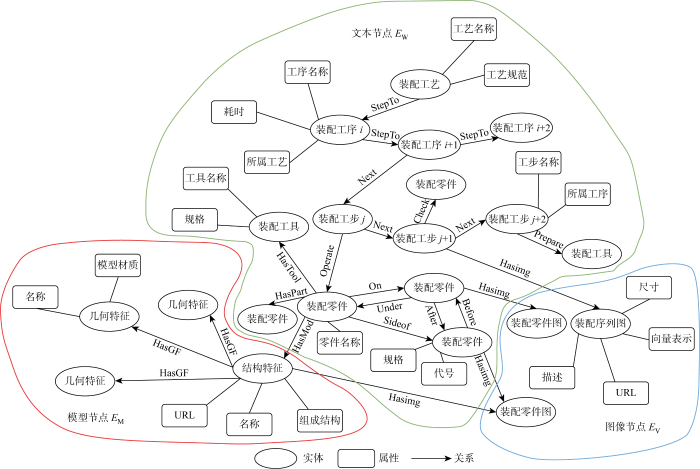
对于实体集E,根据风力发电机数据的主要模态,进一步细分为3类:文本实体EW、图像实体EV、三维模型实体EM.EW通常包含装配工艺AC、装配工序AP、装配工步AS、装配零件AE、装配工具AT,即EW={SAC∪SAP∪SAS∪SAE∪SAT};EV通常包含装配零件图VC、装配序列图VS,即EV={SVC∪SVS};EM通常包含结构特征MS和几何特征MF,即EM={SMS∪SMF};S表示对应的集合.主要实体及其定义如表1所示.
表1 多模态实体的类和定义
Tab.1
| 多模态实体类型 | 实体类别 | 实体定义 |
|---|---|---|
| EW | AC | 利用工具对原材料或半成品按照设计预期要求进行加工及处理的方法和过程 |
| EW | AP | 在同一地点利用同一设备完成的装配工作 |
| EW | AS | 在同一位置用同一工具,不改变工作方法完成的装配工作 |
| EW | AE | 组成装配机器或产品的最小单元 |
| EW | AT | 装配过程中用到的工具 |
| EV | VC | 可视化装配零件的图像 |
| EV | VS | 指导装配过程的图像 |
| EM | MS | 三维模型自身及其层级结构 |
| EM | MF | 三维模型的几何组成单元 |
对于关系集R,根据装配工艺数据的特点分为结构关系Rst、时序关系Rtm和操作关系Rop,即R={Rst∪Rtm∪Rop}.结构关系Rst代表节点之间存在的固有联系,时序关系Rtm代表不同节点之间隐含的先后顺序关系,操作关系Rop代表工艺具体操作.主要关系及其定义如表2所示.其中,“HasImg”、“Has-Mod”等关系在图谱中形成跨模态实体间的关联.
表2 关系的类和定义
Tab.2
| 关系类型 | 关系类别 | 关系定义 | 联结的模态 |
|---|---|---|---|
| Rst | HasImg | 表示文本实体具有的相关图像 | 文本-图像 |
| Rst | HasMod | 表示文本或图像实体具有的相关三维模型 | 文本或图像-模型 |
| Rst | HasGF | 三维模型具有几何特征 | 模型-模型 |
| Rst | HasPart | 产品的装配关系,表示某装配体包含子装配体或是零件 | 模型-模型 |
| Rtm | StepTo | 表示同一工艺下不同工序之间的先后关系 | 文本-文本 |
| Rtm | Next | 表示同一工序下不同工步之间的先后关系 | 文本-文本 |
| Rop | Prepare | 表示进入工作之前需要准备的零件、工具 | 文本-文本 |
| Rop | HasTool | 表示操作过程中需要用到某种工具 | 文本-文本 |
| Rop | Check | 表示操作过程中的检查步骤 | 文本-文本 |
| Rop | Operate | 动作统一表示,表示对零件采取某种动作 | 文本-文本 |
| Rop | On/ Under/ Before/ After/Sideof | 位置关系表示,表示不同装配实体之间的相对位置 | 文本-文本 |
对于属性集,其作为一种固有特性能够对实体与关系作出语义补充,强化表示能力,基本格式为(实体,属性名,属性值),属性值可以是常见的数值类型、日期类型、或者文本类型.主要实体对应属性如表3所示.表中:URL为统一资源定位符.
表3 实体-属性类别
Tab.3
| 实体类别 | 属性名 |
|---|---|
| AC | 工艺名称;工艺规范 |
| AP | 工序名称;耗时;所属工艺 |
| AS | 工步名称;所属工序 |
| AE | 零件名称;规格;代号 |
| AT | 工具名称;规格 |
| VC | URL;尺寸;描述;向量表示 |
| VS | URL;尺寸;描述;向量表示 |
| MS | URL;名称;组成结构 |
| MF | 名称;模型材质 |
基于上述风力发电机多模态图谱及其各类实体-关系-属性定义,可构建MPKG-WT本体模型框架,如图3所示.
图3
2.3 多源异构数据处理
风力发电机多模态知识图谱所需信息通常有多种来源,且这些不同来源的数据结构也各不相同,如半结构化的JSON工艺文档,非结构化的风力发电机作业指导书、机械安装手册、设备维修记录、维护手册以及模型文件等.对于半结构化文件,可直接读取其中相关信息并进行使用;模型文件可打包成文件名-模型文件格式后用于后续模型解析利用.而非结构化的文件在企业中通常以word文档形式保存,其中蕴含大量文本和图像两种模态的工艺信息.对此,将具体提取这两种模态信息,提取算法如算法一所示,其流程如图4所示.算法首先分析word文档中各类内容并进行归类存储到JSON文档相应位置,再对XML文档解析获取图像信息.图中:jsonFile、imgFile分别为JSON、Img文件.
图4
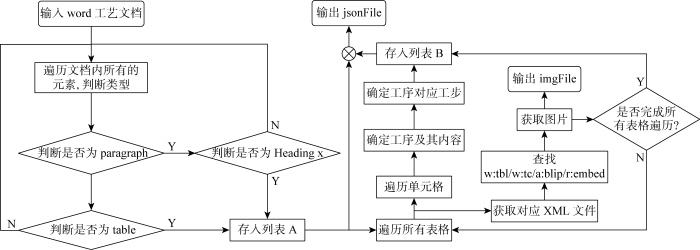
算法一:模态信息提取算法
Input:以word文档形式保存的工艺文件
Output:文本类知识文件和图片类知识文件
1. for each e in wordFile: //遍历文档内所有元素
2. if e’s type is paragraph:
3. if e’s style is ‘Heading x’:
4. create and save (e’s text, ‘Heading x’) to list A //确定标题级别并且存入列表A
5. if e’s type is table:
6. create and save (e’s andress, ‘table’) to list A //存入表格地址到列表A
7. end for
8. for each table in tables: //遍历所有表格
9. for each cell in table: //遍历表格中所有单元格
10. if cell’s text is ‘工序’:
11. find ‘工序’ content behind cell
//确定工序位置及内容
12. find ‘工步’ content in cell where is under ‘工序’ cell //确定工序对应工步的内容
13. save (‘工序’: content, ‘工步’: content) to list B //将内容保存到列表B
14. end for
15. combine list A and B, save to jsonFile
//整合A和B的内容存入json文件中
16. open relevant xmlFile in compressive wordFile //打开对应xml文件
17. find w: tbl/w: tc/a: blip/r: embed in xml:
18. get and save img to imgFile //在xml文件中确定各个图片的位置及内容,并保存到相应图片文件夹中
19. end for
20. return jsonFile and imgFile
2.4 知识抽取
为进一步从多模态信息中抽取相应的知识以构建知识图谱,基于前述本体定义,针对各模态分别设计风力发电机工艺知识抽取方法.
2.4.1 文本模态知识抽取
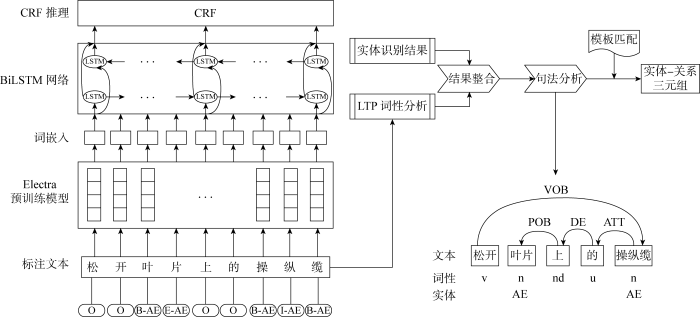
文本模态的知识抽取操作主要包括实体识别和关系抽取,其主要流程如图5所示.图中:CRF表示条件随机场;LSTM表示长短期记忆神经网络;LTP为开源工具语言技术平台(Language Technology Platform);VOB、POB、DE、ATT分别表示句法中的动宾、介宾、“的”字、定中结构;AE代表名词短语;v、n、nd、u分别表示动词、名词、方位词、助词.
图5
Electra模型在BERT模型的基础上进行了一定改进和创新,有效减少模型体积、提高模型运算效率,通过充分学习文本字符间以及上下文的关系将风力发电机工艺文本转为相应稠密向量表示.Electra模型主要由生成器和判别器两部分组成,生成器与判别器的损失分别如下式所示:
式中:x为输入单词序列;xt为t时刻下的输入单词序列;x'为x所有可能的后验状态;e为单词向量;h为上下文表示向量;W为权重矩阵;sigmoid为激活函数.在模型训练完成后,仅使用判别器部分即可获取文本稠密向量表示.
BiLSTM-CRF模型通过接收Electra输出的字向量进行实体类别的划分,其中BiLSTM能将从输入的稠密向量提取的语义特征与保存的双向隐层状态进行融合,更好地解决风力发电机文本中存在的较长距离语义依赖问题.CRF模型主要用于序列标注任务的判别,在实体识别模型中接收BiLSTM网络的输出并经过特征函数确定实体最终符合的特征类.
实体标注方法采用BIOES 序列标注法,B(begin)、I(inside)、E(end)分别表示这个词是一个实体的开始、内部、结束,O(outside)表示这个词不是实体,S(single)表示这个词本身就是一个实体.
为了便于现场安装工人理解,风力发电机工艺文本通常较为简练,文本句法结构简单.因此在关系抽取的部分,采用语句词性分析与实体识别结果相结合的依存语句分析法,并进一步结合句法模板匹配以提高关系识别的准确度.其中,词性分析采用开源工具LTP,得到词性结果将其与实体识别结果进行整合.依存句法包含主谓(SBV)、动宾(VOB)、间宾(IOB)、前宾(FOB)、兼语(DBL)、定中(ATT)、状中(ADV)、动补(CMP)、并列(COO)、介宾(POB)、左附加(LAD)、右附加(RAD)、独立结构(IS)、核心(HED)等14种类型.句法模板规则如表4所示.
表4 句法匹配模板
Tab.4
| 组合类别 | 图谱关系 |
|---|---|
| AE/AT,AE/AT + POB ATT | On/Under/Before/After/Sideof |
| AS/AE,AT + SBV/IOB/FOB | HasTool |
| AS,AE + SBV/IOB/FOB | Operate |
| AC,AP或AP,AP | StepTo |
| AP,AS或AS,AS | Next |
| v:准备/预备/备用/筹备 | Prepare |
| v:检查/检测/核验/查验/查看+ | Check |
| nd:上/顶部+ POB | On |
| nd:下/底部+ POB | Under |
| nd:前+ POB | Before |
| nd:后+ POB | After |
| nd:旁边/周围/一侧/一边+ POB | Sideof |
由图5可见,经过句法分析后,“松开”与实体“操纵缆”之间有“VOB”句法关系,“松开”为操作动作,两者间即有“Operate”关系,两个实体“叶片”和“操纵缆”存在“POB”和“ATT”的句法关系,即有位置上关系,经过模板匹配方法将“POB”中的“上”归类为“On”,则两个实体之间存在相对位置为上下的关系.
2.4.2 图像模态知识抽取
风力发电机领域存在诸多专有名词,在实际环境中,通常辅以解释说明的图像.加入图像后,其视觉特征比文本所描述的知识能更直观、更形象地刻画实体的外观和方位特点,使复杂的工艺知识变得更易理解和学习.因此,图像数据作为多模态知识图谱的重要组成部分,如何在图谱中表征和关联此类视觉特征将非常重要.
借助计算机视觉处理技术对图像模态进行表征,其流程如图6所示.
图6
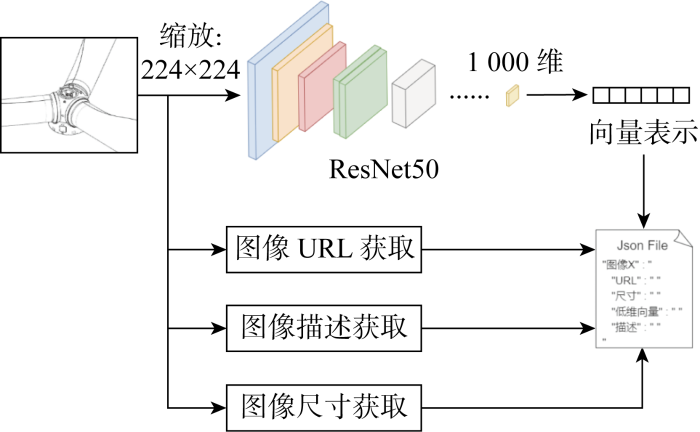
具体地,使用预训练的50层ResNet模型作为主干网络,作为图像的特征提取器.ResNet提出使用残差块进行残差学习的思想,让层数的加深不会让网络效果变差,能使网络一直保存最优层的输出结果,从而解决了深度网络的退化问题[18].图像将统一缩放到224像素×224像素大小,微调ResNet50,在最后的全连接层与softmax层之间添加一个输出为15维的全连接层以对应机舱、主轴、滑轨、偏航电机、叶片等15种风力发电机装配零件图类别,并冻结所有全连接层之前的参数,加入训练图片进行装配零件图的分类使模型更适应风力发电机领域的工艺图像,在测试集上平均正确率达到95%以上.
使用去除最后softmax层和所添加全连接层的模型输出的 1 000 维特征向量来表示图像,并作为图片实体的一项属性而存在.在图谱构建过程中,特征向量可直接用于两张图像的相似度计算,帮助去除图谱中的重复图像节点.此外,特征向量亦可为图像模态检索提供基础,对所有入库的图像提前进行向量提取即可避免每次图像模态检索对所有图像都要进行一次模型计算,可极大提升图像搜索效率.
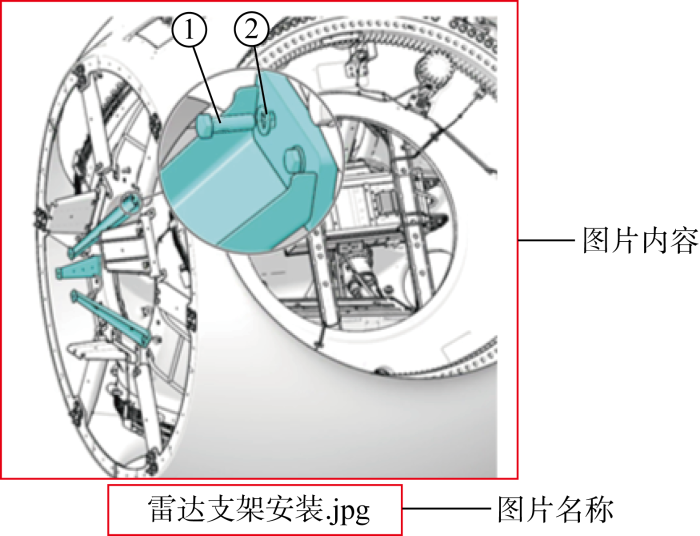
此外,在风力发电机专业领域中,存储于数据库中的工业图像还需要遵循一定的命名规则,即需要对图像内容进行简要、规范描述,如图7所示.在进行图片属性提取时,名称及其与图像的对应关系,将作为建立跨模态关系“HasImg”的重要依据.
图7
除图像向量表示和描述外,图像还存在其他属性,如图像存储地址、图像尺寸.图像存储地址指真实图像所存储的位置,是图谱中图像可视化的基础,图像尺寸能作为图像基本信息给使用者一定参考作用.在提取图像特征向量、图像描述、图像地址、图像尺寸后,存入构建的JSON文件中.
2.4.3 三维模型数据知识抽取
图8
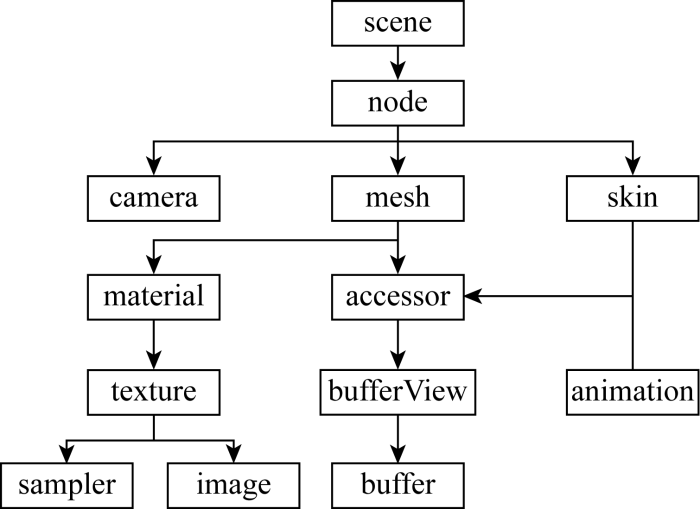
模型语义主要存在于节点(node)、网格(mesh)、访问器(accessor)、缓冲视图(bufferView)、缓冲(buffer)中,其中scene代表整个场景的入口点,由node构成树结构组成,每个node可以索引到相应的子节点位置,对其进行解析可提取模型结构特征.meshes通过accessor来访问其真实的几何数据,accessor指访问器,是从buffer获取二进制数据的入口,其指向buffer和bufferView,通过解析meshes节点可获取构成模型的几何语义,buffer包含用于三维模型、外观几何学的数据,bufferView是指buffer的切片, 整个处理流程如图9所示.
图9

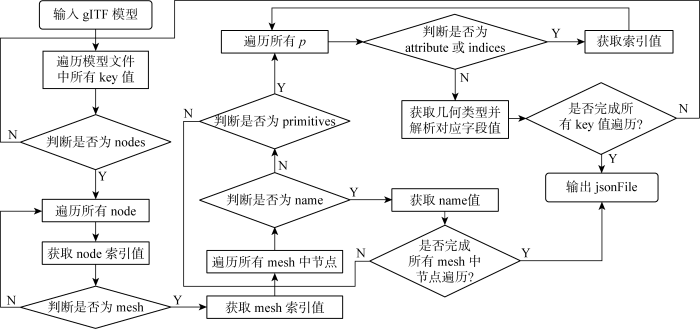
glTF文件中的几何语义包含装配元素之间的实体名字和连接关系.这些信息需要通过模型语义抽取算法抽取出来存入JSON文件中,glTF模型语义解析算法如算法二所示,其流程如图10所示.
图10
算法二:glTF模型语义解析算法
Input:glTF模型
Output:具有模型几何语义的JSON格式文件
1. for each k in key: //遍历gITF文件的key值k,
2. if k=nodes:
3. for each n in N: //遍历所有节点n,N为所有节点集合
4. get index of n
5. if n=mesh:
6. get index of n //获取节点的索引值
7. for each m in M: //遍历所有面m,M为所有面集合
8. if m=name:
9. get and save value of m to jsonFile
//获取面的name并存入文档
10. if m=primitives:
11. for each p in m: //遍历所有primitive
12. if p=attributes or indices:
13. get value and index of p
//获取attribute对应值和索引
14. else
15. get and save type of p, value of bufferView and buffer to jsonFile
//获取几何元素类型并通过解析将对应字段值存入文档
16. end for
17. end for
18. end for
19. end for
20. return jsonFile
2.5 知识融合
利用上述方法从工艺文档中抽取到的知识可能存在大量同义异形、重复描述的数据,因此需要进行知识融合,其目的就是将所有实体有效融合统一,提高整个图谱的质量.本文中知识融合[20]主要包括各模态内部的共指消解和跨模态的实体对齐.
共指消解是指多种表达方式对应同一实体对象的问题,例如,“激测仪”“激光测量仪”均对应“激光测量仪”这一个单元实体;模型标签中,“测风仪”和“风速计”指代同一部件.尤其在人工撰写的报告中,这种使用简化语句的现象比较普遍,因此需要统一规范的实体名称.而工业图像中也存在同一图像裁切、旋转、重新配色等冗余表达.因此,本文3种模态各自都需进行共指消解.
图11
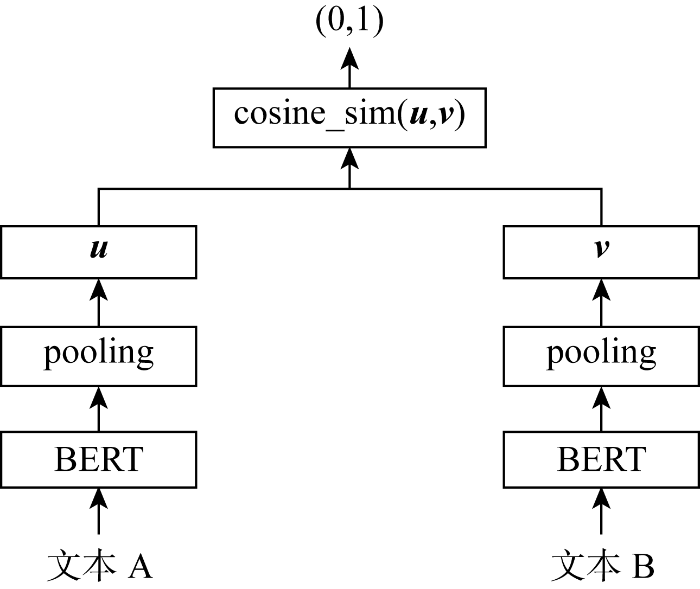
Sentence-BERT模型借鉴孪生网络模型的框架,将不同句子输入到两个共享参数的BERT模型中,然后输出句子向量进行平均池化,在句子长度这个维度上对所有字向量求均值,获取到每个句子的句向量表示,最后将两个句子的向量u和v采用余弦相似度公式计算相似度,公式如下:
当相似度结果大于某一阈值,即认为两个表达属于同一实体,可以进行融合.对于图像模态的实体,可利用ResNet模型生成的向量评估图像特征的相似性.即同样利用余弦相似度公式式(3)对所有特征向量进行计算,以降低图像的冗余性.
在完成各模态内部的共指消解之后,跨模态实体对齐将进一步检查和连接图谱中相同实体的不同模态表示.虽然由于风力发电机工业文件特性,大部分跨模态关系包含在文件中,经过2.3节知识抽取流程已经得到,但仍存在少部分未能对齐的情况.因此,对文本-图像、模型-图像两类跨模态情形,将文本与模型的标签通过BERT得到的768维向量与图像通过ResNet50得到的 1 000 维向量进行连接,得到的整个向量表示包含了两种模态的信息,然后送入Multi-Layer Transformer中学习跨模态表示,将跨模态表示中两部分的头部状态向量联合送入Classifier中,最后通过Classifier输出“HasImg”或“None”结果以判断两种模态之间是否存在联系,跨模态对齐模型结构如图12所示.图中:IMG、CLS、SEP分别为图像标识、分类标识、分割标识.
图12
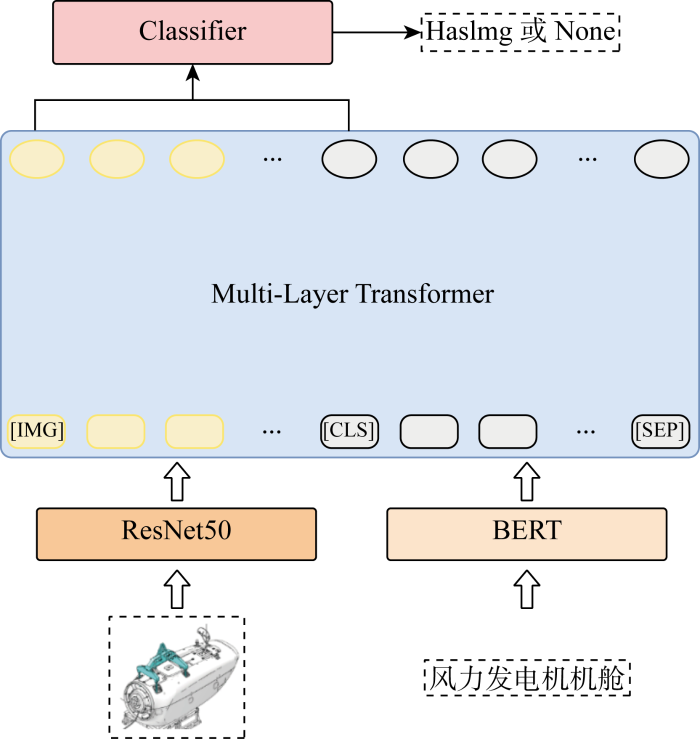
文本-模型跨模态对齐仅发生于描述零件的场景,因此将以零件文本与零件图像、零件模型与零件图像之间对应存在文本-图像、模型-图像关系为前提,配合模型标签与文本所含实体的最大Sentence-BERT相似度检查,在零件文本和零件模型间添加“HasMod”关系,从而完成跨模态关系的补充.
3 风力发电机多模态图谱构建实例及应用
3.1 实验数据介绍
以某企业风力发电机作业指导书33份、机械安装手册6份、设备维修记录8份、JSON工艺文档22份、完整装配模型文件24份、维护手册7份等共100个文件为基础数据,所含内容涉及多种模态信息,利用所提方法进行数据提取,共有353张图像、102个三维模型、4 346 条文本语句,之后进行人工标注并构建MPKG-WT.
实验使用Windows 11操作系统,NVIDIA GeForce RTX 3060 Laptop GPU 6 GB显卡,Intel© Corporation i7-12700H处理器,16 GB内存,编程语言为Python和JavaScript,数据库使用MongoDB和Neo4j进行存储,实验参数设置如表5所示.
表5 实验参数设置
Tab.5
| 模型 | 实验参数 | 取值 |
|---|---|---|
| Electra-BiLSTM-CRF | 词嵌入维度 | 768 |
| Electra-BiLSTM-CRF | 迭代次数 | 60 |
| Electra-BiLSTM-CRF | 学习率 | 0.0001 |
| Electra-BiLSTM-CRF | DropOut | 0.5 |
| Electra-BiLSTM-CRF | Batch Size | 32 |
| Electra-BiLSTM-CRF | 最大句长 | 256 |
| Resnet50 | 迭代次数 | 30 |
| Resnet50 | 学习率 | 0.001 |
| Resnet50 | Batch Size | 32 |
| 跨模态对齐模型 | 迭代次数 | 80 |
| 跨模态对齐模型 | 输入嵌入维度 | 1768 |
| Sentence-BERT | 相似度阈值 | 0.6 |
3.2 图谱评估及构建结果
对于文本实体识别和关系,抽取模型均按照 8∶1∶1的比例划分标注语料为训练集、验证集和测试集自动进行测试,其他模态实体由于直接提取,取10%与文本实体测试数据汇总为总实体.对于跨模态之间的关系,抽取10%进行人为核验,将结果和文本关系测试数据汇总为总关系,抽取结果准确性的评价分别从实体和关系两方面采用F1-Score进行评估[10],其计算公式如下:
图13
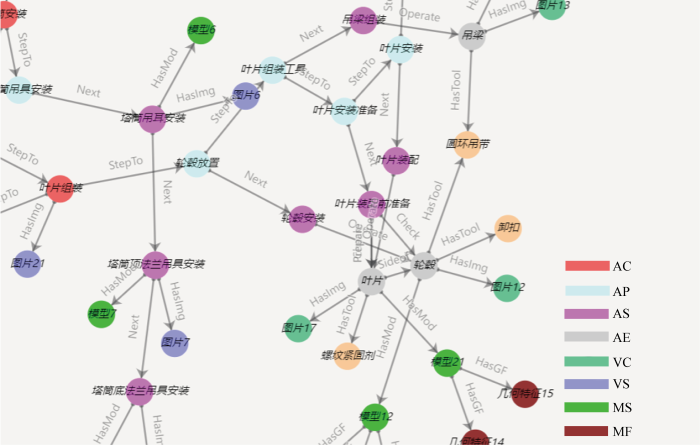
图14
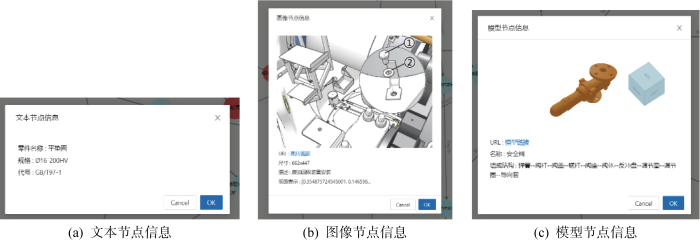
图14
不同模态节点信息可视化示例(截图)
Fig.14
Examples of visual information in different modal modes (capture)
表7 实体关系数量统计
Tab.7
| 实体类别 | 实体数量 | 关系类别 | 关系数量 |
|---|---|---|---|
| AC | 42 | HasImg | 482 |
| AP | 192 | HasMod | 122 |
| AS | 537 | HasGF | 229 |
| AE | 125 | HasPart | 21 |
| AT | 34 | StepTo | 192 |
| VC | 113 | Next | 609 |
| VS | 184 | Prepare | 374 |
| MS | 77 | HasTool | 341 |
| MF | 229 | Check | 146 |
| MF | 229 | Operate | 629 |
| MF | 229 | On/Under/Before/ After/Sideof | 237 |
3.3 基于图谱的辅助工艺设计应用
MPKG-WT中包含大量工艺路线,利用知识图谱可以辅助设计人员进行工艺重用以及工艺的快速设计,从而提高工艺设计效率.如图15所示为辅助工艺设计系统界面.工程师进行工艺设计时,可以利用知识检索框进行相似历史工艺的检索和复用,并且可以输入图像进行检索相似图像所属工艺.若要对知识图谱补充和更新,则可以将完成的新工艺上传到数据库中进行专家审查,通过审查后新工艺会自动转化成相应节点结构加入图谱,对其进行更新补充.
图15
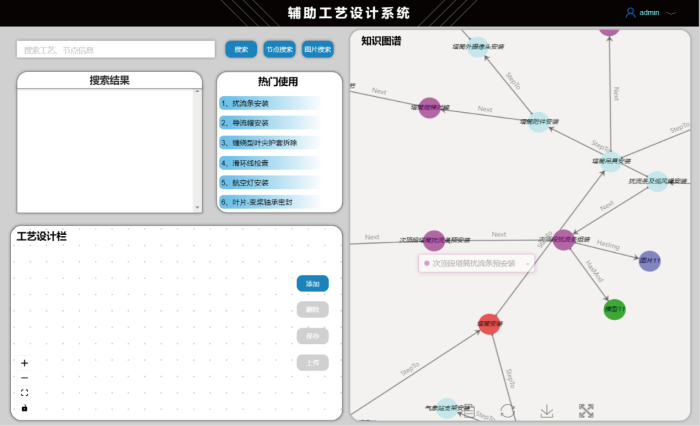
图15
辅助工艺设计系统界面(截图)
Fig.15
Interface of auxiliary system for assembly process design (capture)
为测试和验证多模态知识图谱的效用,以某型号风力发电机塔筒结构的工艺设计任务为应用测试场景,验证工艺知识重用的有效性.在该任务中,针对从塔筒吊具安装到塔底触摸屏安装共16个任务步骤,对每个步骤返回前3个装配工艺搜索结果,并邀请一线设计人员判断该工艺是否对装配任务有帮助,得到工艺重用准确率,即Hit@3.为进一步对比多模态数据为装配工艺图谱带来的跨模态检索和查询能力,将进一步对比去除图像和模型模态的知识图谱.表8为不同模态知识图谱在该工艺设计任务中的表现对比.由表可见,尽管构建多模态图谱将花费更多时间,但单次知识检索耗时并没有太大差距.在实际场景中,由于知识图谱通常预先构建完成,所以并未对设计任务的执行造成较大影响.而从完成工艺设计任务耗时方面来看,多模态知识图谱将起到较大辅助作用,有效缩短设计耗时,提升工艺重用准确率,尤其是包含3种模态的图谱.其具体优势体现在跨模态检索能力.如图16所示,在搜索框中可直接上传“塔筒”相关图片对多模态知识图谱进行搜索.工程师可在搜索结果栏中看到所有与“塔筒”有关的工艺属性信息以帮助工艺的设计.在右侧图谱可视化模块中,也可显示所有“塔筒”相关节点,并且节点信息可显示不同模态的所有信息.在复用历史工艺进行修改时,可选用检索推送出的历史工艺作为复用依据,继承其工艺信息,并在工艺设计栏上显示.也可直接从右侧将关联的文本、图像、模型模态节点信息拖入设计栏中,直接进行所需修改完成工艺设计,因此大幅提升了设计任务中对多模态关联实体的管理和运用效率.
表8 不同模态图谱对比
Tab.8
| 图谱模态 | 构建耗时/ min | 查询耗时/ ms | Hit@3/% | 工艺设计 耗时/min |
|---|---|---|---|---|
| 文本 | 5 | 362 | 72.9 | 20 |
| 文本-图像 | 9 | 371 | 85.4 | 16 |
| 文本-模型 | 13 | 412 | 81.3 | 11 |
| 文本-图像-模型 | 16 | 418 | 87.5 | 8 |
图16
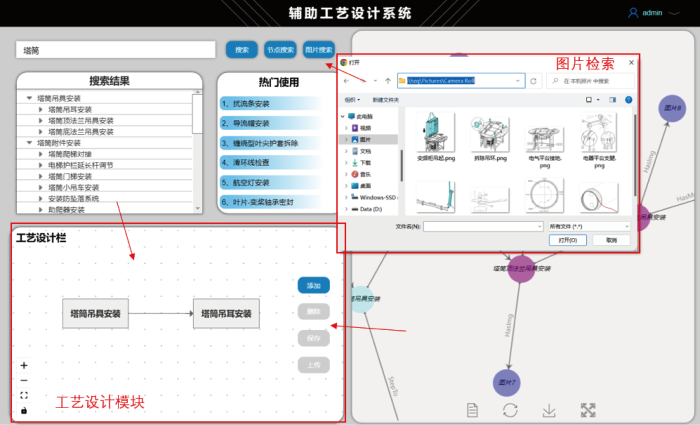
4 结论
风力发电机生产过程中留下的工艺知识通常分散于多源异构工艺文档中,主要包含三维模型、自然文本、图像等多种模态数据,造成数据维护与工艺重用成本高、效率低.为此,提出一种基于多源异构数据的风力发电机多模态工艺图谱建模方法,主要成果和贡献可总结为以下三方面:
(1) 基于风力发电机工艺特点,从多个层次、多种模态角度定义实体类与关系类,以三元组的形式将不同知识互相联系,构建风力发电机多模态工艺图谱本体模型.
(2) 描述了针对不同模态数据所采用的相应模态知识抽取方法,利用实体对齐和共指消解等技术强化跨模态信息之间的关联,实现基于本体模型的图谱自动实例化.
(3) 以企业数据为例实现风力发电机多模态工艺图谱可视化,验证了构建方法的可行性,并设计开发辅助工艺设计系统,证明图谱对于工艺重用的有效性.
后续在所提多模态图谱的基础上会添加更多数据进行扩充,并且会对多模态信息融合进行研究,尝试更多先进的方法提高图谱构建质量.在图谱应用方面,未来将结合图神经网络以探究工艺自动补全生成的可行性.
参考文献
风力发电现状及叶片组成与回收利用综述
[J].
Review on status of wind power generation and composition and recycling of wind turbine blades
[J].
产品装配技术的研究现状、技术内涵及发展趋势
[J].
DOI:10.3901/JME.2018.11.002
[本文引用: 1]

当前国内外精密/超精密加工技术的快速发展,使得零部件加工精度和一致性得到显著提高,装配环节对产品性能的保障作用正日益凸显,相关研究越来越得到国内外学者的关注。针对目前我国产品装配技术研究相对滞后,缺乏相关研究体系的现状,在总结国内外产品装配技术的研究现状基础上,阐述了其分类和内涵,建立了产品装配技术的研究体系框架,并对其面向装配的设计、装配工艺设计与仿真、装配工艺装备、装配测量与检测、装配车间管理等主要研究方向进行了论述,最后指出了未来产品装配技术的集成化、精密化、微/纳化和智能化的发展趋势。
The state-of-the-art, connotation and developing trends of the products assembly technology
[J].
DOI:10.3901/JME.2018.11.002
[本文引用: 1]
With the rapid development of precision and ultra-precision machining technology at home and abroad, precision and consistency of machined parts have been improved prominently. Hence, the assembly process is playing a more and more important role in assuring the performance of assembled products, and the related research is gaining widespread attention. However, domestic research on the products assembly technology is relatively lagging and lacks a comprehensive research system. Based on the state-of-the-art of the products assembly technology, its classification and connotation is elaborated, and a comprehensive research framework of the products assembly technology is established. Based thereon, the basic research contents of the framework are discussed, including design for assembly, assembly process design and simulation, assembly process equipment, assembly measurement, assembly workshop management, etc. Finally, the developing trends of the products assembly technology, i.e., integration, precision, micro-nano, intelligence, are pointed out.
面向船舶分段制造过程的动态知识图谱建模方法
[J].
DOI:10.16183/j.cnki.jsjtu.2020.241
[本文引用: 1]
在动态性、离散型强的船舶分段制造过程中,缺乏有效的过程资源组织、产品加工不透明等因素导致管理者知识获取成本高、效率低.针对这一问题,提出一种基于加工节拍数据流的知识图谱动态生成和更新方法.通过分析船舶分段的加工流程与工位数据特点,给出加工节拍数据信息模型定义;提出静态资源与加工节拍数据的图映射步骤、模型以及融合连接算法,实现工位动态时序数据与知识图谱的语义关联;利用工位流程与产品结构关系生成车间级动态知识图谱.以某船舶分段生产过程为例,设计开发知识图谱可视化原型系统并进行验证.研究结果表明,所提方法有利于船舶分段制造过程中知识的组织、获取与重用.
Dynamic knowledge graph modeling method for ship block manufacturing process
[J].
Object-oriented templates for automated assembly planning of complex products
[J].
A novel modeling method of the crowdsourcing design process for complex products-based an object-oriented petri net
[J].
基于过程挖掘与复杂网络集成的制造过程资源建模与关键加工节点识别
[J].
DOI:10.3901/JME.2019.03.169
[本文引用: 1]
为了解决多任务复杂制造过程中的工作流变异导致的流程和资源的不确定性,进而导致制造资源模型出现实时变化,提出了基于过程挖掘与复杂网络集成的制造过程资源模型,得到了流程与资源信息集成的资源复杂网络模型与分析方法。首先,从制造过程中实时产生的事件日志出发,提出了一种基于统计α算法的过程挖掘算法,解决了制造过程工作流重构问题,可实时发掘实际制造过程中的工作流模型。接着,通过集成过程挖掘算法和复杂网络理论,构建了集流程信息与资源信息于一体的资源网络模型,提出了资源节点与流程节点的关联性分析方法,识别制造过程中的关键加工节点。最后,结合一个复杂的锥齿轮轴-轴承套组件装配过程实例,全面验证了所提出方法在制造过程工作流重构、资源网络模型建模、资源特性分析与关键加工节点的识别上的有效性。
Resource modeling of manufacturing process and critical nodes recognition based on the integration of process mining and complex network
[J].
DOI:10.3901/JME.2019.03.169
[本文引用: 1]
In order to solve the uncertainty of the resource network caused by the process variation under the multi-tasks complex manufacturing work-flow, a manufacturing resource model that based on the integration of process mining and complex network theory is proposed. Firstly, a manufacturing work-flow reconstruction method that based on process mining statistical α-algorithm is proposed to obtain work-flow model in real time from manufacturing event logs. Secondly, a resource network model that based on the integration of process mining and complex network theory combines process information and resource information, which can be used to analyze the relevance between resource node and process node, and to recognize the critical nodes in manufacturing work-flow. Finally, with the application of an assembly process, the effectiveness of the methods on manufacturing process reconstruction, resource network modeling, resource characteristic analysis and critical nodes recognition is verified.
Screening process mining and value stream techniques on industrial manufacturing processes: Process modelling and bottleneck analysis
[J].
An ontology-based modelling and reasoning framework for assembly process selection
[J].
基于本体的制造知识建模方法及其应用
[J].
Ontology-based modeling method for manufacturing knowledge and its application
[J].
面向工艺重用的工艺知识图谱构建方法
[J].
Process knowledge graph construction method for process reuse
[J].
航空发动机润滑系统故障知识图谱构建及应用
[J].
Construction and application of fault knowledge graph for aero-engine lubrication system
[J].
基于知识图谱的装配语义信息建模
[J].
Assembly semantic information modeling based on knowledge graph
[J].
Multi-modal knowledge graph construction and application: A survey
[J].
Multimodal knowledge graph for deep learning papers and code
[C]//
癫痫病相关论文多模态知识图谱的构建初探
[J].
DOI:10.13190/j.jbupt.2021-187
[本文引用: 1]
癫痫病相关论文缺乏命名实体识别和关系抽取任务的标注数据,命名实体识别和关系抽取模型无法用常规方法训练。为解决该问题,针对癫痫病相关论文的数据特点,改进了命名实体识别和关系抽取模型,提出利用相近领域的医疗数据和预训练模型构建零资源癫痫病领域命名实体识别和关系抽取模型。评估了现有无监督和半监督模型在癫痫病领域论文数据集上的性能,并针对数据集特征引入域对抗网络和关系判别器,有效地提高了命名实体识别和关系抽取模型的性能。将癫痫患者的脑电特征以视觉模态嵌入知识图谱中,在提高脑电分析可解释性的同时,构建了更加直观的多模态知识图谱。
Construction of multi-modal knowledge graph for epilepsy related papers
[J].
ELECTRA: Pre-training text encoders as discriminators rather than generators
[DB/OL]. (
Bidirectional LSTM-CRF models for sequence tagging
[DB/OL]. (
Deep residual learning for image recognition
[C]//
基于MBD模型的工序模型构建方法
[J].
In-process model construction method based on model-based definition model
[J].
Multi-source information fusion based on rough set theory: A review
[J].
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
[C]//
Inter-coder agreement for computational linguistics
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}