

NILD最早由Hart[3]提出,依据电压电流的变化量对负荷进行聚类识别.近几年,随着电力系统转变为以大数据、物联网等技术为支撑的新型电力系统,NILD因可挖掘海量电力消耗数据信息价值的特点成为研究热点[4].NILD作为典型的时间序列分析问题,分为基于暂态特征信号分解和基于稳态特征信号分解两类[5].基于暂态特征信号分解通常对高频采样数据进行分析.如以快速傅里叶变化对电流波形进行变换,实现对各种负荷的识别[6];或考虑暂态波形中电气设备突然切换产生的电气噪声和某些设备在运行时产生的噪声为负荷特征实现负荷识别[7],还有采用最近邻算法、支持向量机算法等机器学习方法对电流谐波进行特征提取实现设备分解准确率的提升[8].但是基于暂态特征信号的负荷分解方法所需要的高频采样数据对传感器性能要求高,且需要手动建立特征数据库,过程繁琐,不适用于实际用户侧的能量分解.
基于稳态特征信号的方法采用低频采样数据,更适用于实际场景下对用户侧进行能量分解.基于低频采样数据的一种方法是利用非负张量分解等预处理算法处理设备用能数据获得最相关特征后对特征进行分离[9].文献[10]中利用主成分分析法对8种典型电器的负荷特征样本降维处理后结合Fisher有监督判别准则将数据投影到一维空间,实现不同类型的负荷分解.文献[11]中利用高斯混合模型与序贯期望最大化在负载状态下建立分类器,并采用在线数据对系统进行自适应微调以实现负荷分类.另一种方法是利用机器学习算法训练模型以进行负荷分解,如采用多层感知机[12]、K-近邻算法[13]、支持向量机[14]等.文献[15]中以负荷电流作为分解特征构建多种模型进行负荷分解.基于稳态特征信号的负荷分解方法对采集设备要求不高,容易实现,并且在精度上能够适应绝大部分场景.因此,基于稳态特征信号的负荷分解方法成为NILD的重要研究领域.
随着深度学习在语音识别[16]、图像处理[17]、自然语言[18]处理等方面展现出巨大优势,有学者将深度学习应用于NILD.新方法在NILD中明显优于先前工作,同时,手动提取特征的过程被省略.Kelly等[19]提出3种应用于NILD的深度学习模型,在后续研究中学者改进了常用的序列到序列(Sequence-to-Sequence, Seq2Seq)框架,提出了更加准确的序列到点(Sequence-to-Point, Seq2Point)框架[20],还有学者为了兼顾效率与精度,引入序列到子序列(Sequence-to-Subsequence, Seq2Subseq)框架[21].深度学习算法特征提取过程是自动的,已有学者为了开发更精确、高效的负载检测和分解策略及算法做出探索.如文献[22]中将数据利用时间向量化[23]处理后嵌入自注意力机制对负荷数据进行分解,取得良好的分解效果.文献[24]中结合卷积块注意力机制和Seq2Seq模型,进一步提高分解精度.注意力机制的引入有助于提高模型分解精度但受限于传统注意力机制发展的影响,计算复杂度是平方级,训练时间成本会大大增加.
1 NILD模型
1.1 NILD分解原理
NILD利用采集到的负荷数据,一般为有功功率,根据模型学习设备用电特征,将其从总负荷数据中分离出来,即通过观测t时刻总负荷数据Y(t),分解得到家庭中第m个用电设备t时刻功率数据Xm(t),NILD原理表示如下:
式中:e(t)为均值为0、方差为
1.2 NILD流程
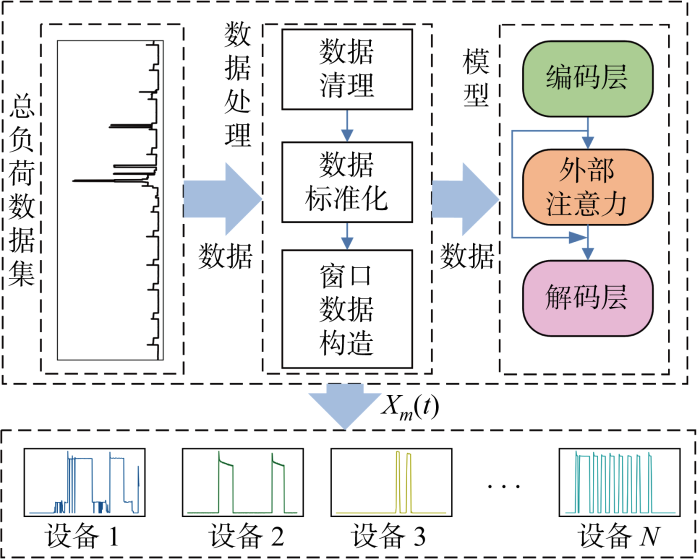
NILD算法整体流程如图1所示,采用相同网络架构对所有N台用电设备进行训练、测试.首先,总负荷数据经过数据处理过程,包括数据清理、数据标准化、窗口数据构造等环节,其目的在于消除无效数据以及降低数据之间的差异性,以固定长度对总表数据进行提取且每次仅移动一个数据点用以构造窗口数据输入到模型中;输入数据经过编码层对设备特征自动进行特征编码后,利用外部注意力模块提升需要关注的局部设备特征;最后,通过解码层输出对应窗口中点分解值,得到第m个设备负荷分解数据Xm(t).
图1
1.3 Seq2Point架构
Seq2Point表示一个神经网络架构,给定时间序列数据作为神经网络输入,输出为输入序列中点值.考虑用电设备在t时刻数据与上下文之间的联系可以更准确地得到t时刻设备运行数据.本文使用的Seq2Point架构中,输入数据为数据序列Yt: t+W-1;输出数据为相应数据序列Xt: t+W-1的中点值xτ,其中τ=t+W/2,W为窗口长度.Yt: t+W-1、Xt: t+W-1为t到t+W-1长度输入、输出数据序列.以上过程可以表示为xτ=f(Yt: t+W-1)+ε,其中,ε为误差,f(·)为将Yt: t+W-1映射到对应输出窗口Xt: t+W-1中间点xτ上的神经网络过程.
基于Seq2Point架构构建输入为窗口长度W,输出为单个数据点的负荷分解模型.用于训练的损失函数为
式中:Lloss为训练损失值;θ为需要训练的网络参数;T为总时间序列长度.Seq2Point架构优点是任意窗口中点值xτ都有单一分解值,比Seq2Seq的准确度更高.
1.4 外部注意力机制
1.4.1 外部注意力结构
采用外部注意力结构如图2所示,外部注意力机制中外部记忆单元M表示输入特征,为了增强其表达能力,将M分成两个不同记忆单元Mk、Mv.其目的是在记忆单元训练过程中,学习整个数据集中最具辨别力的特征,捕获信息量最大部分,以及排除来自其他样本的干扰信息,刻画所有样本之间的共同特征.
图2
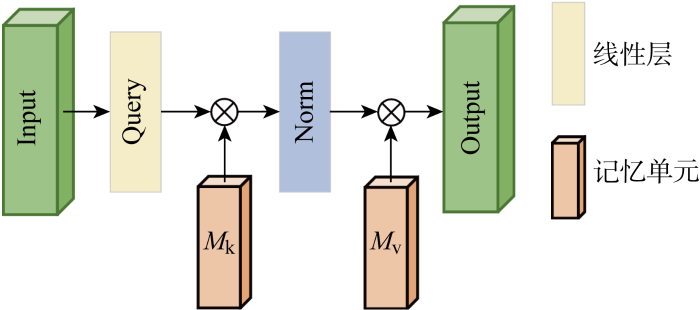
式中:Norm表示标准化过程;A为从数据集中推断出的注意力图,根据A中相似性更新Mk、Mv中参数;Fout为外部注意力模块输出.在相同数据维度d与输入特征规模n下,自注意力机制计算复杂度为O(dn2),而外部注意力单元由线性层构成,其计算复杂度为O(dn).因此,相较自注意力机制二次计算复杂度和忽略样本之间潜在关联的缺点,外部注意力具有线性复杂度可降低训练时间成本和隐式地考虑不同特征图之间关系来增强模型表达能力[27].
1.4.2 标准化过程
式中:
1.4.3 外部注意力计算过程
依据图2和双重标准化过程,所采用外部注意力机制计算过程表示为:设定Input输入F∈RN×C;Query过程为1×1一维卷积层对F进行非线性处理同时可保持F结构不变,交换维度有F∈RC×N;与线性层Mk计算得到
式中:f1×1为1×1的卷积层;Wk∈RN×L、Wv∈RL×N、bk∈RL、bv∈RN分别为线性层Mk、Mv的权重矩阵与偏置矩阵.外部注意力模块可以为本文模型提供一个强大的正则化角色,并能提高模型的泛化能力,且在整个过程中输入数据F与输出数据Fout可保持结构不变,因此外部注意力机制可以方便地嵌入到不同模型之中.
2 模型设置及数据处理
2.1 评价指标
为更准确地评估模型性能,使用信号聚合误差(Signal Aggregate Error, SAE)、平均绝对误差(Mean Absolute Error, MAE)、标准化分解误差(Normalized Disaggregation Error, NDE)3个指标对各种算法进行评估.各个评价指标表达式如下:
式中:
2.2 模型结构
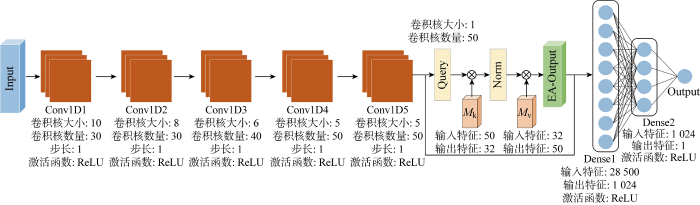
用户的使用习惯决定了用电设备在使用过程中状态变化有限且固定,即设备运行曲线在时间尺度上具有相似性,因此,卷积层保持平移不变性特点非常适合提取用电设备特征.编码层中采用以卷积层构成的编码层对输入序列进行特征编码,解码层利用线性层强大的拟合能力充分地对特征进行融合并输出分解值,编码层解码层之间使用外部注意力模块连接,本文模型采用Seq2Point架构,即设定模型输入长度为窗口长度W,输出数据为相应数据序列中点元素,这种模型称为S2P-EA,模型结构以及参数设置如图3所示.图中:Dense表示密集层.
图3
2.3 数据预处理
实验数据集采用REDD数据集和UK-DALE数据集,REDD数据集记录来自美国6个家庭长达数月的负荷数据,分别在2、3号家庭进行训练,1号家庭进行测试,不同家庭之间跨数据比较可以体现出泛化能力;UK-DALE数据集记录来自英国5个家庭的负荷数据,为验证同一数据集中的性能,仅在1号1户家庭进行训练和测试.鉴于目前智能电表只有低频采样能力,将所有数据集合采样率设为1/8 Hz,并将所有数据对齐时间戳.
在REDD与UK-DALE数据集中,以微波炉、冰箱、洗碗机和洗衣机等典型用电设备作为分解对象.为降低总表功率数据与设备功率数据之间差异,提高训练精度,使用下式对所有数据分别进行标准化处理:
式中:
表1 标准化参数
Tab.1
| 设备 | 平均值/W | 标准差/W |
|---|---|---|
| 主电源 | 522 | 814 |
| 微波炉 | 500 | 800 |
| 冰箱 | 200 | 400 |
| 洗碗机 | 700 | 1000 |
| 洗衣机 | 400 | 700 |
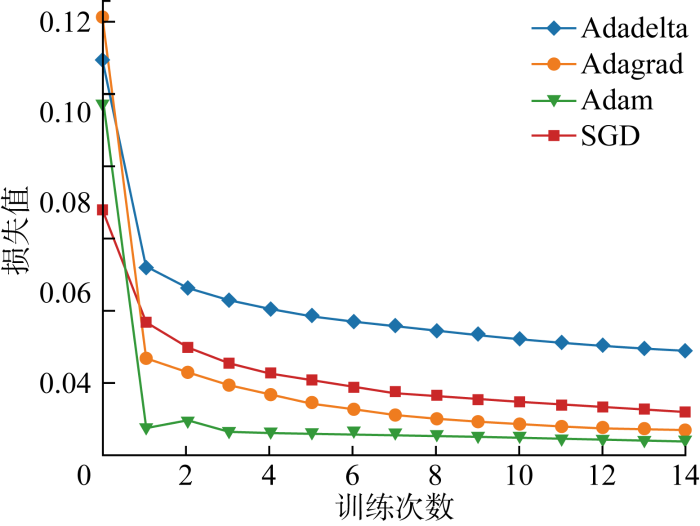
2.4 模型参数设置
图4
3 算例结果与分析
选取REDD、UK-DALE数据集进行实验,采用预处理后全部实测数据进行训练,数据包含预处理、时间戳对齐的全部总电源有功功率数据和用电设备有功功率数据.
3.1 实验软硬件平台
训练硬件环境如下:Intel Xeon Gold 5115 CPU,128 GB DDR4内存,NVIDIA Tesla T4 16 GB,软件平台为Ubuntu 18.04.6 LTS 64位,Python 3.9.7以及Pytroch 1.10.1深度学习框架,采用图3所示模型对微波炉、冰箱、洗碗机和洗衣机4种设备分别进行训练和测试.
3.2 结果分析
3.2.1 分解评价指标对比
表2 REDD数据集各模型对比
Tab.2
| 设备 | ESAE | EMAE | ENDE | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN | T2V | CBAM | 本文 | CNN | T2V | CBAM | 本文 | CNN | T2V | CBAM | 本文 | |||
| 微波炉 | 0.889 | 0.485 | 0.373 | 0.323 | 19.681 | 20.066 | 20.712 | 22.481 | 0.996 | 0.751 | 0.689 | 0.722 | ||
| 冰箱 | 0.219 | 0.209 | 0.159 | 0.092 | 35.69 | 31.076 | 37.603 | 28.494 | 0.338 | 0.279 | 0.345 | 0.231 | ||
| 洗碗机 | 0.478 | 0.643 | 0.395 | 0.358 | 19.142 | 29.610 | 19.476 | 18.365 | 0.505 | 0.872 | 0.437 | 0.431 | ||
| 洗衣机 | 0.053 | 0.095 | 0.089 | 0.045 | 15.106 | 12.427 | 19.065 | 18.622 | 0.199 | 0.139 | 0.172 | 0.174 | ||
| 均值 | 0.410 | 0.358 | 0.254 | 0.205 | 23.450 | 23.295 | 23.421 | 21.991 | 0.510 | 0.510 | 0.411 | 0.390 | ||
表3 UK-DALE数据集合各模型对比
Tab.3
| 设备 | ESAE | EMAE | ENDE | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN | T2V | CBAM | 本文 | CNN | T2V | CBAM | 本文 | CNN | T2V | CBAM | 本文 | |||
| 微波炉 | 0.100 | 0.877 | 0.719 | 0.028 | 5.732 | 10.318 | 7.447 | 6.042 | 0.613 | 0.984 | 0.606 | 0.594 | ||
| 冰箱 | 0.143 | 0.178 | 0.072 | 0.057 | 23.342 | 31.686 | 22.823 | 20.549 | 0.410 | 0.526 | 0.403 | 0.384 | ||
| 洗碗机 | 0.244 | 0.737 | 0.274 | 0.153 | 7.334 | 14.953 | 7.227 | 5.290 | 0.060 | 0.457 | 0.074 | 0.074 | ||
| 洗衣机 | 0.004 | 0.223 | 0.004 | 0.005 | 8.927 | 13.923 | 8.081 | 7.960 | 0.089 | 0.274 | 0.072 | 0.070 | ||
| 均值 | 0.122 | 0.504 | 0.267 | 0.061 | 11.333 | 17.720 | 11.394 | 9.960 | 0.293 | 0.560 | 0.288 | 0.280 | ||
由表2可见,在REDD数据集上进行跨用户对比发现,本文模型多数指标相比其余3种模型提升明显.与CNN模型相比,洗碗机的ESAE降低15.1%;与T2V模型相比,微波炉的ESAE降低33.4%.对比CBAM模型,微波炉的ESAE降低13.4%.SAE表示模型输出聚合值相对真实数据聚合值的偏差,可见本文模型对整体功率的分解输出值相比较其余3种模型更接近用户真实消耗值,这可以为用户关注某一设备消耗能量提供更准确的指导.虽然数据集合来源于不同家庭,本文模型仍可以准确进行识别,这表明本文模型拥有优异的泛化性能.本文模型在多个设备上的EMAE、ENDE指标均值最好,在冰箱、洗碗机的处理中显著优于对比模型.
在UK-DALE数据集中的相同数据集合上进行训练和测试.本文模型在冰箱、洗衣机的处理中相较3种对比模型性能有所提升,在微波炉和洗衣机的处理中对CNN模型保持领先,且在均值上对比其余模型仍具有优势.所提模型对比CNN、T2V以及CBAM模型在多项指标上有明显提升,表明外部注意力机制的引入改善了卷积层注意力分散的缺点.对比同样采用注意力机制的T2V以及CBAM模型,本文所采用的外部注意力模块通过对全体样本的学习关注到不同样本中元素之间的潜在关系,相对于只关注相同样本元素之间关系的注意力机制有更好的性能, 这表明在相同数据集上本文模型仍拥有极高的分解性能.
3.2.2 分解结果与特征图对比分析
图5
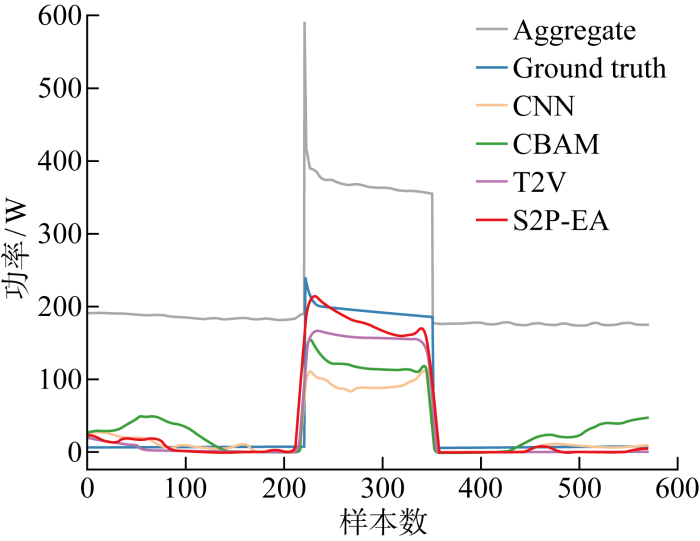
图6
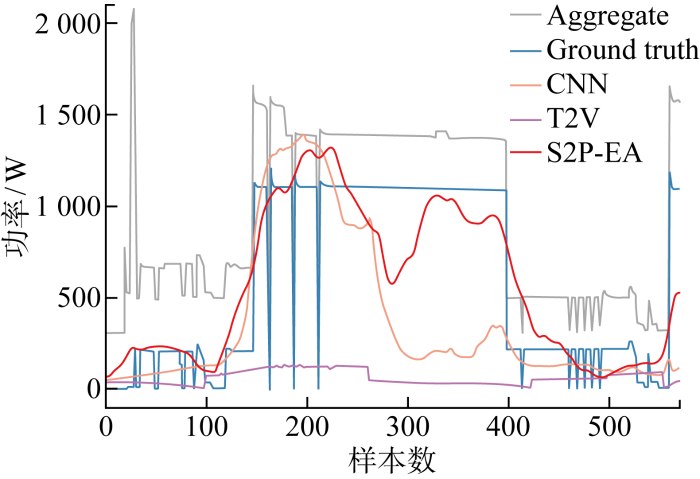
图6
洗碗机各模型分解图
Fig.6
Comparison of dish washer disaggregation of different models
3.2.3 分解机理分析
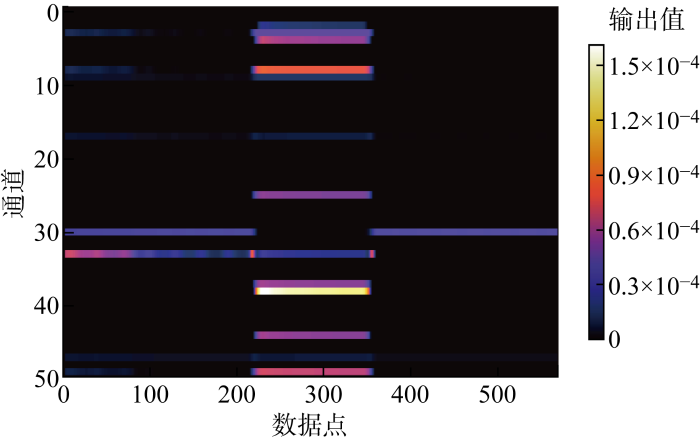
选定一个洗衣机的运行区间,提取相对应窗口序列中点值所对应的特征图共同绘制,如图7所示.图中:Prediction为该窗口对应分解预测中心,Ground-truth为真实数据点,Predict为分解预测数据.可知,在洗衣机功率发生变化时,一部分通道对洗衣机特征进行了识别,且由特征图可见其准确识别洗衣机运行时间区段;在设备未运行区间权重低使得输出值也低,表明对于洗衣机来说关键特征应为设备变化段以及设备运行段,并且在通过移动数据窗口过程中,特征图保持平移不变,这说明卷积层适合提取用电设备的运行特征.
图7
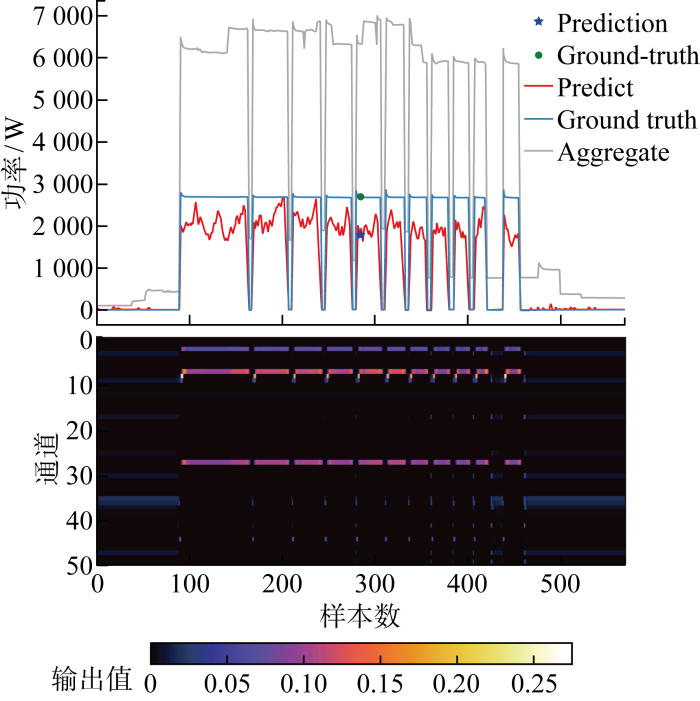
图8
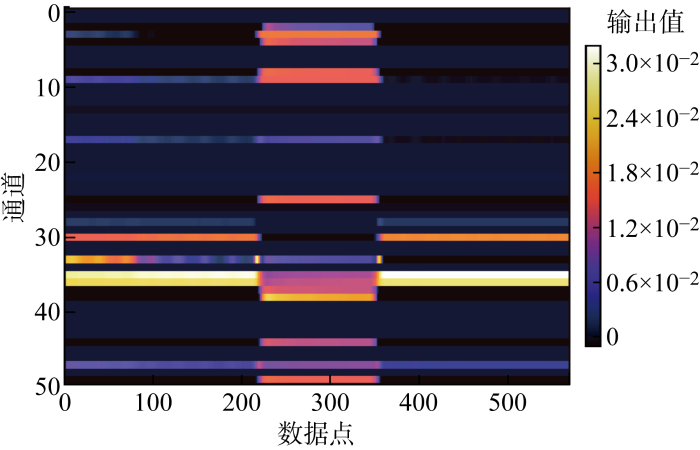
图9
3.2.4 消耗能量对比
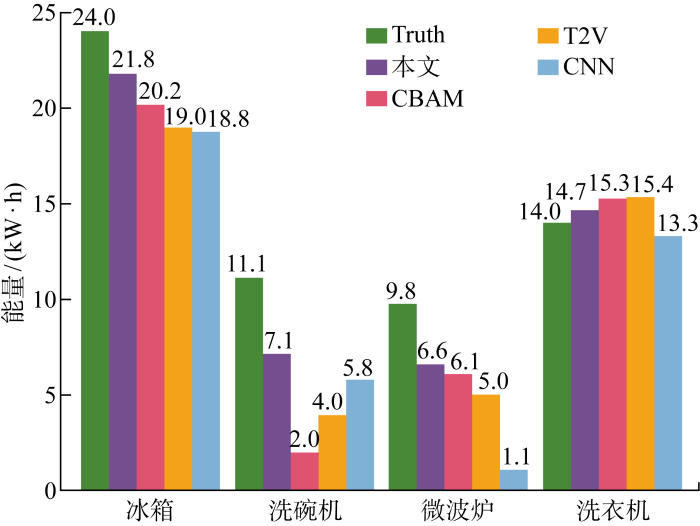
对于用户来说,用电设备负荷分解曲线难以提供直观信息,用户更关心用电设备所消耗能量,绘制REDD测试集中各种设备分解后能量消耗值以及真实设备能量消耗值,如图10所示.图中:Truth表示设备实际消耗能量.由图可见,对比其他模型,本文模型分解后能量消耗值更加接近真实值,反馈给用户所使用的设备能源消耗值更加准确,能更有效地指导用户改变用电行为,降低能耗.
图10
3.2.5 训练时间对比
神经网络中大量参数所需要的训练时间是制约模型部署的关键因素之一,CNN、CBAM以及本文模型的参数总量与训练时间对比如表4所示,训练时间为每个时期所用时间.由表可见,在训练参数量上,3种模型之间相差不大;在训练时间成本上,本文模型与CNN模型相比虽然引入外部注意力模块,但是并没有造成模型训练时间增加,与采用卷积块注意力机制的CBAM模型相比较,训练时间成本降低65.8%.可见本文模型训练更加高效.
表4 模型训练时间对比
Tab.4
| 模型 | 训练参数量 | 训练时间/s |
|---|---|---|
| CNN | 30,708,249 | 123 |
| CBAM | 30,709,748 | 351 |
| 本文 | 29,229,199 | 120 |
4 结语
提出一种外部注意力机制嵌入Seq2Point模型的NILD方法,称为S2P-EA,该方法通过编码层提取设备特征后,再让外部注意力机制进一步增强设备重要特征权值,最后通过解码层解码完成对设备的有效辨识,该模型比其他注意力机制模型有更快的训练速度.在REDD、UK-DALE数据集进行实验,与无注意力机制、采用自注意力机制、采用卷积块注意力机制模型相比较,本文模型在不增加训练时间成本的基础上有效提升模型分解精度,并具有较高负荷分解准确度与泛化性能,具有很好的实用性.在后续研究中,将在减少模型规模与训练成本等方面进行更深入研究.
参考文献
基于负荷分解的用电数据云架构方案及应用场景
[J].
Conceptual cloud solution architecture and application scenarios of power consumption data based on load disaggregation
[J].
非侵入式负荷监测关键技术问题研究综述
[J].
Review on key techniques of non-intrusive load monito-ring
[J].
Nonintrusive appliance load monitoring
[J].
非侵入式负荷监测综述
[J].
A survey on the non-intrusive load monitoring
[J].
非侵入式负荷监测与分解研究综述
[J].
A survey of the research on non-intrusive load monitoring and disaggregation
[J].
Smart metering of variable power loads
[J].
At the flick of a switch: Detecting and classifying unique electrical events on the residential power line (nominated for the best paper award)
[C]
Electrical signal source separation via nonnegative tensor factorization using on site measurements in a smart home
[J].
基于Fisher有监督判别的非侵入式居民负荷辨识方法
[J].
Non-intrusive household appliance load identification method based on fisher supervised discriminant
[J].
Unsupervised adaptive non-intrusive load monitoring system
[C]
RPROP神经网络在非侵入式负荷分解中的应用
[J].
Application of RPROP neural network in nonintrusive load decomposition
[J].
NILMTK: An open source toolkit for non-intrusive load monitoring
[C]
Home electrical signal disaggregation for non-intrusive load monitoring (NILM) systems
[J].
基于监督学习的非侵入式负荷监测算法比较
[J].
Comparison of supervised learning-based non-intrusive load monitoring algorithms
[J].
Thank you for attention: A survey on attention-based artificial neural networks for automatic speech recognition
[DB/OL]. (
Attention is all you need
[C]
Efficient estimation of word representations in vector space
[DB/OL]. (
Neural NILM: Deep neural networks applied to energy disaggregation
[C]
Sequence-to-point learning with neural networks for non-intrusive load monitoring
[C]
Sequence-to-subsequence learning with conditional Gan for power disaggregation
[C]
Nonintrusive residential electricity load decomposition based on transfer learning
[J].
Time2Vec: Learning a vector representation of time
[DB/OL]. (
基于卷积块注意力模型的非侵入式负荷分解算法
[J].
Non-intrusive load disaggregate algorithm based on convolutional block attention module
[J].
REDD: A public data set for energy disaggregation research
[EB/OL]. (
The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes
[J].
Beyond self-attention: External attention using two linear layers for visual tasks
[J].
PCT: Point cloud transformer
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}