

光伏电站作为太阳能的主要来源,其发电效率与整个光伏产业的效能息息相关.光伏组件是太阳能光伏系统的核心部件,但由于我国西北地区风沙大,其表面容易积累灰尘,削弱发电效率,需要移动清洁机器人及时进行清扫作业.清洁机器人能够准确识别光伏电站道路区域是机器人执行光伏电站清扫作业的前提.我国西北地区的光伏电站道路两侧多被杂草及碎石覆盖,路面不平整,且有光伏组件阻碍,给清洁机器人的道路识别带来很大困难.因此,针对光伏电站完全非结构化道路识别研究尤其重要.
上述方法的分割评价多聚集在像素分割精度指标上,而清洁机器人完成清洁任务不仅需要高精度的识别,也需要模型参数量小和算法实时性好.因此,提出一种基于DeepLabv3+基础模型的光伏电站道路识别方法.采用优化的轻量级MobileNetv2网络替换原DeepLabv3+模型的主干网络Xception,减小模型参数量,加快运行速度;利用异感受野融合和空洞深度可分离卷积结合的策略改进空洞空间金字塔池化(ASPP)结构, 提高不同感受野信息间的相关性,扩张率卷积层的信息利用率及模型训练效率;在编码器部分引入卷积注意力模块(CBAM),保留更多有效的图像边缘特征信息,提高特征提取准确性,实现对光伏电站道路的分割.此外,对于光伏电站完全非结构化道路,改进后的DeepLabv3+模型对其分割效果很好,且模型兼顾了分割精度和实时性,可以应用到其他非结构化道路及结构化道路场景图像识别中,如田间道路、高速公路等,为其提供技术支持.
1 DeepLabv3+基础模型
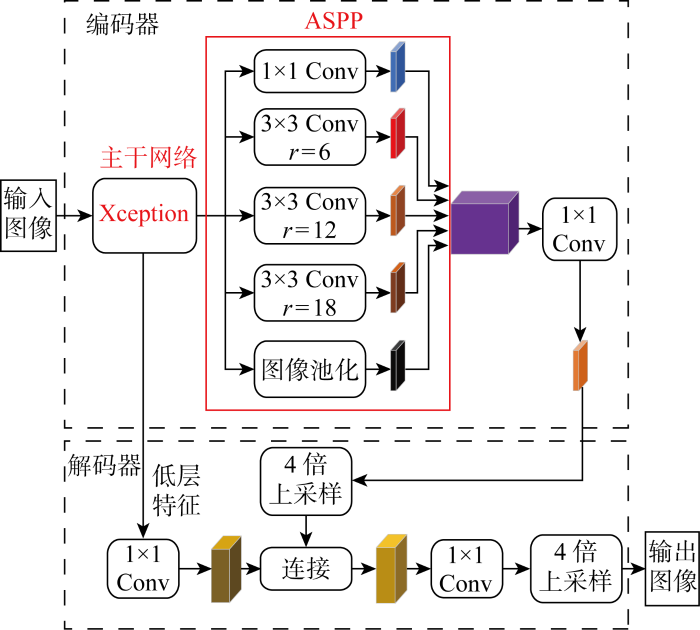
DeepLabv3+模型基于DeepLabv3增加了解码器,构建编解码(Encoder-Decoder)网络模型,将Xception作为主干网络.在编码器中,原始图像先输入到主干网络中提取特征信息,将低层特征传入解码器,高层特征输入ASPP结构中,然后经过1×1卷积(Conv),以及不同扩张率的带孔卷积和平均池化后得到的特征图拼接融合,再利用1×1卷积减少特征通道数目.在解码器中,将编码器中获得的高层特征进行4倍上采样,与主干网络提取到的低层特征融合,经过3×3卷积和4倍上采样,输出模型分割后的图像,DeepLabv3+基础模型的网络结构如图1所示,其中r表示空洞卷积各元素的间隔.
图1
2 改进DeepLabv3+模型
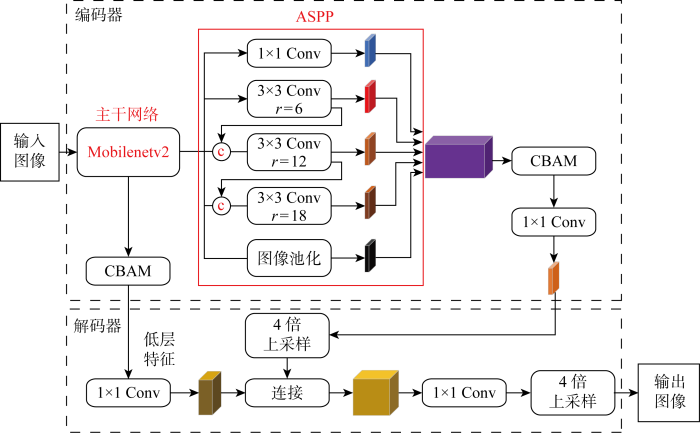
从以下3方面对DeepLabv3+基础模型进行改进.①将原DeepLabv3+的主干网络Xception替换为优化的MobileNetv2网络,降低模型参数量;②利用异感受野融合和空洞深度可分离卷积结合的策略改进ASPP结构,提高其信息利用率和模型训练效率;③引入注意力机制CBAM, 提升模型识别精度,改进DeepLabv3+模型的网络结构如图2所示,训练参数及性能见附录A.
图2
2.1 MobileNetv2网络优化
利用MobileNetv2原始网络结构,仅采用MobileNetv2的前8层,减少计算资源的消耗.此外,第7和第8层采用空洞卷积提取特征,并将第7层的步长设为1,提高MobileNetv2网络分割的准确性,优化的MobileNetv2网络结构如表1所示.其中:t表示通道倍数;c表示通道大小;n表示重复次数;s表示步长.
表1 优化的MobileNetv2网络结构
Tab.1
| 输入 | 网络层 | 输出步长 | t | c | n | s | r |
|---|---|---|---|---|---|---|---|
| 224×224×3 | conv2d | 2 | — | 32 | 1 | 2 | 1 |
| 112×112×32 | bottleneck | 2 | 1 | 16 | 1 | 1 | 1 |
| 112×112×16 | bottleneck | 4 | 6 | 24 | 2 | 2 | 1 |
| 56×56×24 | bottleneck | 8 | 6 | 32 | 3 | 2 | 1 |
| 28×28×32 | bottleneck | 16 | 6 | 64 | 4 | 2 | 1 |
| 28×28×64 | bottleneck | 16 | 6 | 96 | 3 | 1 | 1 |
| 14×14×96 | bottleneck | 16 | 6 | 160 | 3 | 1 | 2 |
| 7×7×160 | bottleneck | 16 | 6 | 320 | 1 | 1 | 4 |
2.2 异感受野融合与空洞深度可分离卷积结合改进的ASPP结构
在DeepLabv3+基础模型的ASPP结构中引入深度可分离卷积,使空洞卷积替换为空洞深度可分离卷积.同时,利用ASPP中上一级扩张率卷积层输出的特征图和原特征图通道拼接后,输入到下一级扩张率卷积层提取特征的方式,实现异感受野融合,提高不同感受野信息间的相关性及卷积层的信息利用率,异感受野融合的空洞深度可分离卷积如图3所示,DS表示深度可分离卷积.
图3
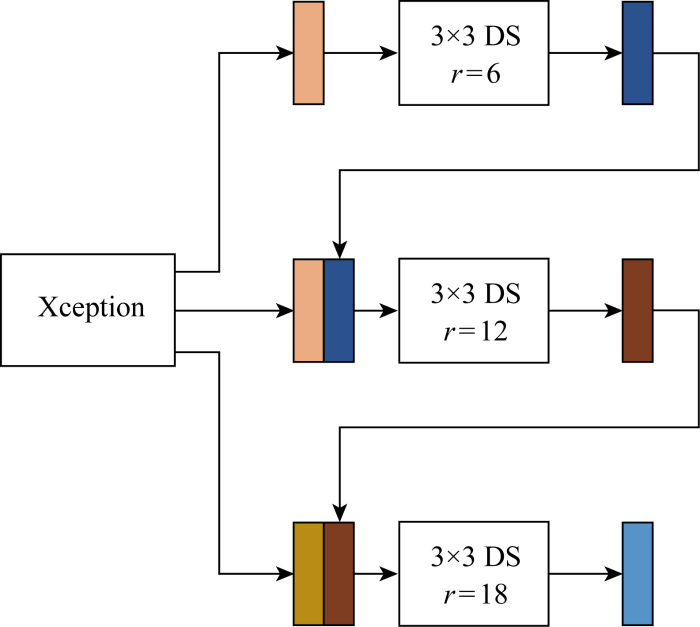
图3
异感受野融合的空洞深度可分离卷积
Fig.3
Empty depth separable convolution of different-sensory field fusion
空洞深度可分离卷积是指空洞卷积利用深度可分离卷积对其通道和空间进行分离计算.深度可分离卷积由深度卷积和逐点卷积组成,具体示意如图4所示.
图4
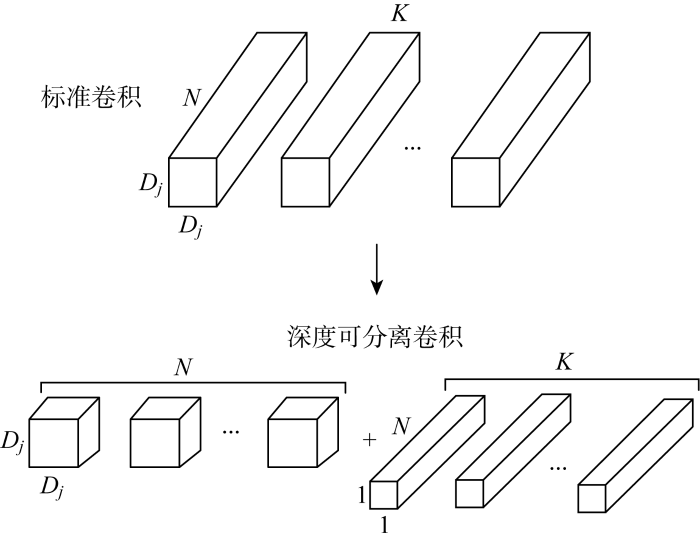
图4
标准卷积与深度可分离卷积
Fig.4
Standard convolution and depthwise separable convolution
假设输入特征图尺寸为Di×Di,通道数为N,卷积核大小为Dj×Dj,输出特征图通道数为K,则标准卷积对应的计算量为
深度可分离卷积对应的计算量为
由此可得Q2和Q1之间的比值为
综合上述推导,可以发现深度可分离卷积的计算量更少.利用异感受野融合与空洞深度可分离卷积结合的策略改进ASPP结构,不仅可以使其具有足够的感受野以及密集地利用多尺度信息,而且具有更少的参数量和更好的特征表达能力.
2.3 引入注意力机制的DeepLabv3+编码器模块
图5

通道注意力模块(CAM)是对输入特征F分别平均池化(AvgPool)和最大池化(MaxPool),得到特征
空间注意力模块(SAM)沿着通道维度对特征F'平均池化和最大池化,得到通道描述
CBAM的通道和空间注意力模块可以对提取的特征进行过滤,使得编码阶段保留的信息更有利于分割的准确性.CAM突出对网络有重大影响的通道信息的学习,SAM能够更好地获取位置关系信息,从而提高网络学习能力.在DeepLabv3+模型的编码器模块中加入CBAM后,网络可以很好地学习光伏电站道路场景图像的特征,抑制冗余信息,并有助于提取道路边缘特征,使DeepLabv3+编码器部分的特征提取更加高效和准确.
3 实验与结果
3.1 数据集建立
本文所用图片采集于甘肃武威某光伏电站,使用照相机从不同位置和角度对光伏电站道路场景拍摄所得,图像分辨率为 1280 像素×720像素,共实地采集图片 1600 张.为了提高网络模型的泛化能力,采用改变亮度、对比度及旋转的方式对光伏电站道路场景数据集扩充,最后得到 2400 张图像的增强数据集,训练集与测试集分别为 1680 张和720张图像,并且使用开源标注软件Labelme对每张图像需要识别的道路区域进行手动标注.
3.2 实验环境配置及参数设置
实验所用硬件平台为AMD R7-5800H 3.2 GHz处理器、NVIDIA Geforce RTX 3060显卡、16 GB内存, 软件环境为win10 cuda10.0 tensorflow1.13.2 keras2.1.5 anaconda3 python3.7.网络模型训练时,初始学习率设置为 0.000 1,批大小(batchsize)设置为4,损失函数采用交叉熵损失函数.
3.3 评价指标
为了客观评价网络模型在光伏电站道路识别中的性能,采用平均像素准确率(MPA)和平均交并比(MIoU)作为评价指标.假设有n+1个类(n个目标类,1个背景类),mjj表示分类正确的像素数量,mjk表示属于第j类却被分到第k类的像素数量,mkj表示属于第k类却被分到第j类的像素数量.
(1) MPA.分别计算每个类别分类正确的像素数占所有预测为该类别像素数的比例,并累加求平均,计算公式为
(2) MIoU.对每个类别预测的结果和真实值的交集与并集的比值,求和再取平均值,计算公式为
3.4 结果与分析
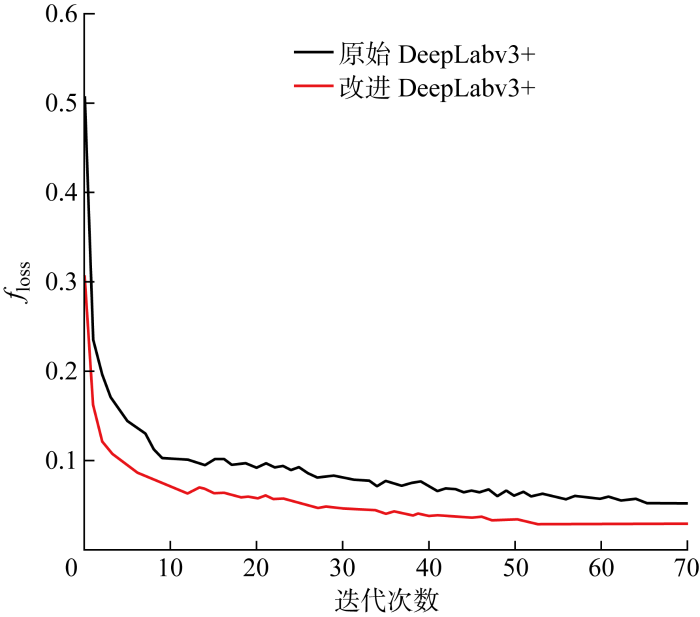
为验证改进DeepLabv3+模型对比DeepLabv3+基础模型的优势性, 分别对改进前后DeepLabv3+模型以同样的训练参数和数据集进行训练,其损失函数(floss)的变化曲线如图6所示.总体来看,两个模型训练集的损失值都随着迭代次数的不断增大而逐渐稳定,但改进DeepLabv3+模型收敛性更强,后期波动小.
图6
训练完成后,取光伏电站道路场景数据集中的测试集图片测试改进前后模型的分割效果,改进DeepLabv3+模型与基础模型的分割效果对比如图7所示.由图可见,DeepLabv3+基础模型在光伏电站道路场景图像分割上出现了漏分割和错分割,并且对图像边缘的分割不够理想.改进DeepLabv3+模型具备更好的道路区域分割效果,保留了道路更多的细节特征,边缘识别更加清晰准确.
图7

图7
改进DeepLabv3+模型与基础模型的分割效果对比
Fig.7
Comparison of segmentation effect between improved DeepLabv3+ model and basic model
为了进一步评价改进的DeepLabv3+对于光伏电站道路分割的性能,使用SegNet模型、UNet模型、原始的DeepLabv3+在光伏电站道路场景数据集上进行训练后,然后在测试集上进行测试得到MPA、MIoU和推理时间,并与本文提出的改进DeepLabv3+模型进行对比,以比较不同的语义分割模型在光伏电站道路识别时的精度、参数量和时间复杂度,对比结果如表2所示.
表2 不同模型的精度、参数量和推理时间对比
Tab.2
| 模型 | MPA/% | MIoU/% | 单张图片 推理时间/ms | 总参数量× 10-6 |
|---|---|---|---|---|
| SegNet | 93.84 | 91.42 | 121 | 14.86 |
| UNet | 94.73 | 92.05 | 125 | 17.30 |
| 原始Deeplabv3+ | 96.27 | 93.48 | 156 | 41.25 |
| 改进Deeplabv3+ | 98.06 | 95.92 | 112 | 2.28 |
由表2结果可知,改进后DeepLabv3+模型进行光伏电站道路分割时在平均像素准确率方面比SegNet、UNet、原始DeepLabv3+分别提高了4.22个百分点、3.33个百分点、1.79个百分点.在平均交并比方面,分别提高了4.50个百分点、3.87个百分点、2.44个百分点.同时,改进后DeepLabv3+模型参数量压缩了原DeepLabv3+的94%,比SegNet小了84%,比UNet压缩了86%,并且平均每张图片的网络推理时间最少.
4 结语
为了实现移动清洁机器人对光伏电站道路的精确识别,提出改进DeepLabv3+目标识别模型.采用优化的MobileNetv2网络替换Xception作为主干网络,减小模型的参数量;通过异感受野融合和空洞深度可分离卷积结合的策略改进ASPP结构,提高对不同扩张率卷积层的信息利用率和训练速度;引入CBAM,保留道路更多的边缘信息,提升模型的识别精度.分别从训练集损失值变化、道路场景预测效果、MIoU、MPA、模型参数量和单张图片推理时间方面,对改进后模型和其他模型进行对比.在光伏电站道路场景数据集上的实验结果表明,改进后模型的MIoU和MPA分别为95.92%、98.06%,均优于对比模型,并且模型参数量和平均每张图片的网络推理时间最少,具有优秀的识别效果.下一步工作将考虑解决光伏电站道路存在大石、深坑或运维人员等障碍物时的多类别分割问题,标注更多复杂的光伏电站道路场景数据,通过增加训练数据量进一步提高改进DeepLabv3+模型的鲁棒性,并将成果应用于移动清洁机器人道路识别中.
附录见本刊网络版(xuebao.sjtu.edu.cn/article/2024/1006-2467/1006-2467-58-05-0776.shtml)
参考文献
General road detection from a single image
[J].
DOI:10.1109/TIP.2010.2045715
PMID:20371404
[本文引用: 1]

Given a single image of an arbitrary road, that may not be well-paved, or have clearly delineated edges, or some a priori known color or texture distribution, is it possible for a computer to find this road? This paper addresses this question by decomposing the road detection process into two steps: the estimation of the vanishing point associated with the main (straight) part of the road, followed by the segmentation of the corresponding road area based upon the detected vanishing point. The main technical contributions of the proposed approach are a novel adaptive soft voting scheme based upon a local voting region using high-confidence voters, whose texture orientations are computed using Gabor filters, and a new vanishing-point-constrained edge detection technique for detecting road boundaries. The proposed method has been implemented, and experiments with 1003 general road images demonstrate that it is effective at detecting road regions in challenging conditions.
基于颜色和纹理特征的道路图像分割
[J].
Segmentation of full vision images based on colour and texture features
[J].
基于RGB熵和改进区域生长的非结构化道路识别方法
[J].
Unstructured road detection method based on RGB entropy and improved region growing
[J].
Fully convolutional networks for semantic segmentation
[J].
DOI:10.1109/TPAMI.2016.2572683
PMID:27244717
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional networks achieve improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
SegNet: A deep convolutional encoder-decoder architecture for image segmentation
[J].
DOI:10.1109/TPAMI.2016.2644615
PMID:28060704
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1]. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3], DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
UNet: Convolutional networks for biomedical image segmentation
[C]//
Pyramid scene parsing network
[C]//
Encoder-decoder with atrous separable convolution for semantic image segmentation
[C]//
Rethinking atrous convolution for semantic image segmentation
[EB/OL]. (
Xception: Deep learning with depthwise separable convolutions
[C]//
Semantic scene segmentation in unstructured environment with modified DeepLabV3+
[J].
Semantic segmentation based on Deeplabv3+ and attention mechanism
[C]//
Inverted residuals and linear bottle-necks
[C]//
MobileNets: Efficient convolutional neural networks for mobile vision applications
[EB/OL]. (
CBAM: Convolutional block attention module
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}