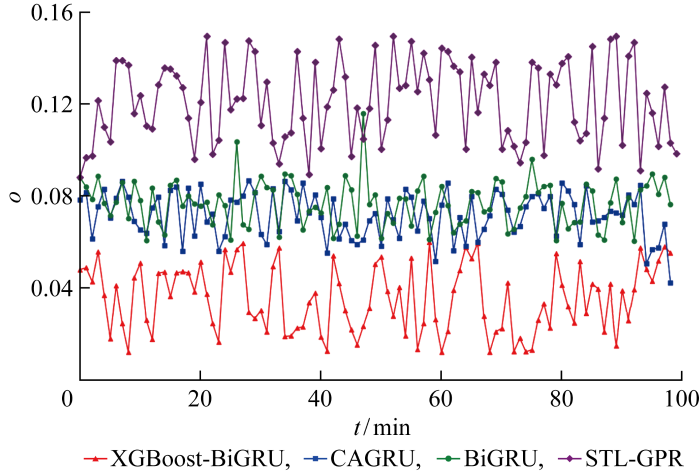
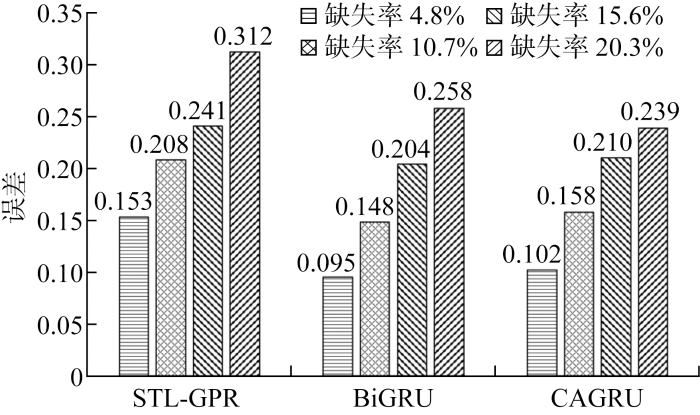
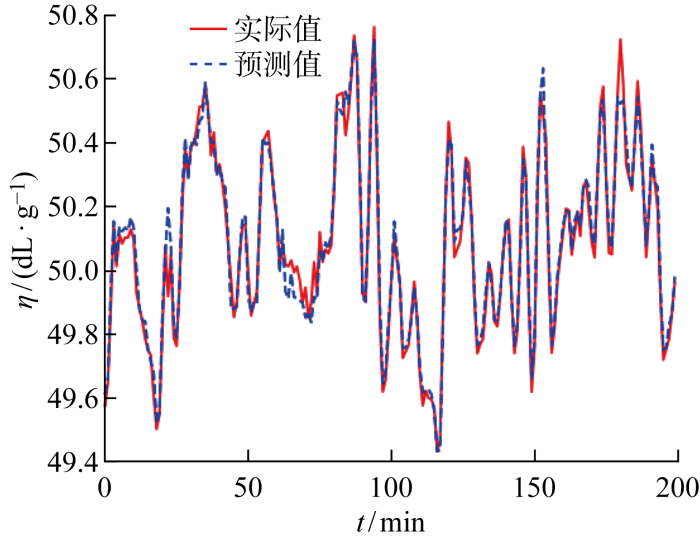
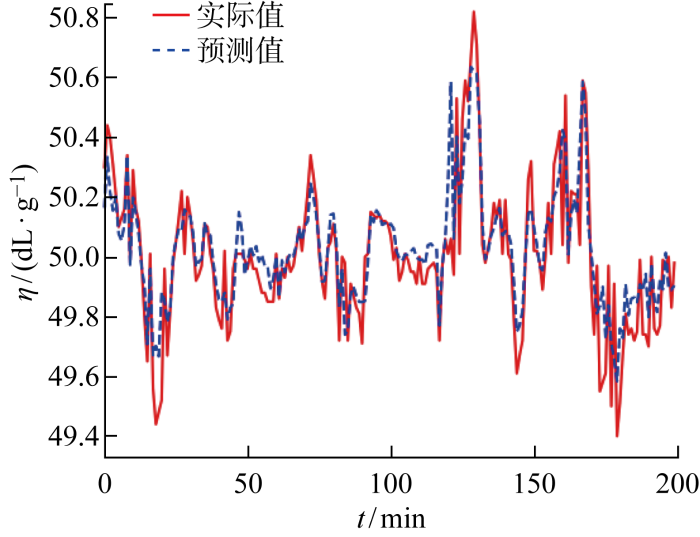
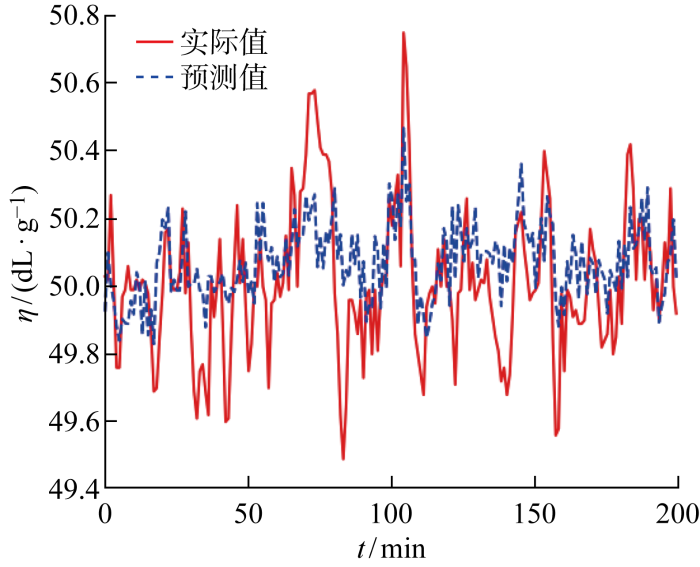
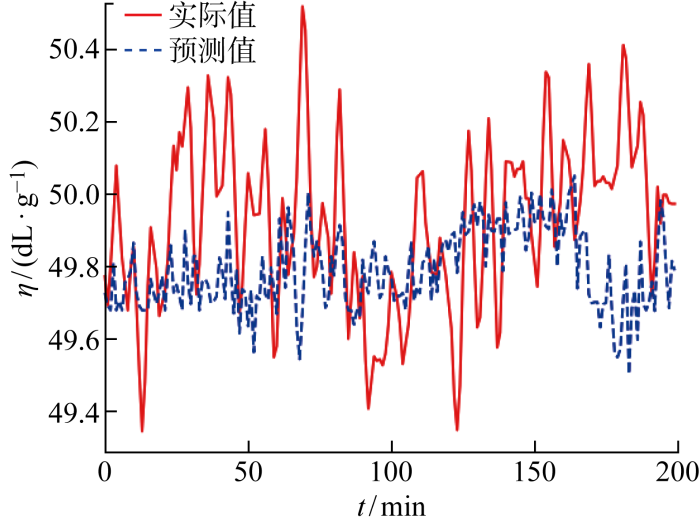
Characteristic viscosity is a key indicator of the quality of polyester melts, whose accurate prediction can help to identify potential quality problems of polyester melts in advance, adjust the process parameters in time and reduce enterprise losses. Considering the data incompleteness, data time series and high dimensional redundancy of the polyester melt production process, a method is proposed to predict the characteristic viscosity of polyester melt under incomplete data. A missing data generative adversarial nets (MDGAN) with a convolutional neural network discriminator and an attention long short-term memory neural network generator is designed to address the data incompleteness problem caused by the extreme production environment of polyester melts, and the missing data is filled by the adversarial generation mechanism. The extreme gradient boosting-bidirectional gated recurrent unit (XGBoost-BiGRU) is designed to predict the viscosity of polyester melts based on high dimensional redundancy and temporal characteristics prediction. The actual data test results of a polyester fiber manufacturer in Zhejiang show that the filling accuracy of the MDGAN algorithm at different missing rate data sets is better than that of data filling algorithms such as KNN,RF,MICE,and GAIN. The XGBoost-BiGRU characteristic viscosity prediction method has significant advantages over STL-GPR, CAGRU, BiGRU. In combination of MDGAN characteristic viscosity prediction, the method proposed can effectively solve the problem of predicting the characteristic viscosity of polyester melts under incomplete data.
目前关于聚酯熔体特性黏度预测的研究主要可以分为基于机理的方法和数据驱动的方法两种[3].基于机理的方法需要分析生产过程中复杂的物化反应,其中反应温度、压力、转速等是影响其质量的主要物理因素.文献[4]中通过反应动力学方程、物料平衡方程和气液平衡方程建立了机理模型,实现了特性黏度预测.但是该方法是基于理想状态下建模的,无法考虑到众多的影响因素,不适合实际复杂生产.数据驱动的方法只需要研究数据与数据之间的关系,随着传感器技术的发展,数据驱动的方法已经成为当前特性黏度预测问题的主流研究方向[5].文献[6]中提出一种基于时间卷积和注意力门控神经网络的特性黏度预测方法,强化了提取时序数据特征能力,挖掘了时序数据长期依赖关系.为了提取聚酯聚合过程的时序关系并兼顾数据非线性特点,Geng等[7]提出一种基于组合核函数的特性黏度预测模型,通过分形维数方法提取特征并且将基于局部加权回归的季节性趋势分解过程(Seasonal-Trend decomposition procedure based on Loess,STL)与核函数相结合来提取时序数据的周期性,最终对特性黏度实现有效预测.文献[8]中提出一种基于双流λ门控递归单元网络的特性黏度预测方法,通过设计λ双因子来改变门控递归单元中存在的线性约束并且丰富了时序特征信息,最终提高了网络模型的预测精度.
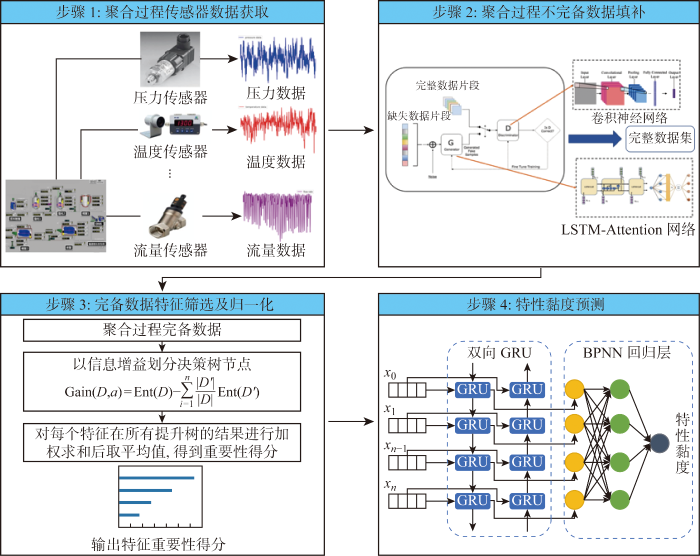
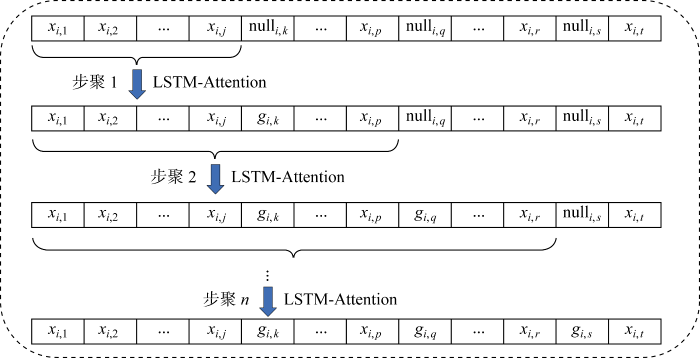
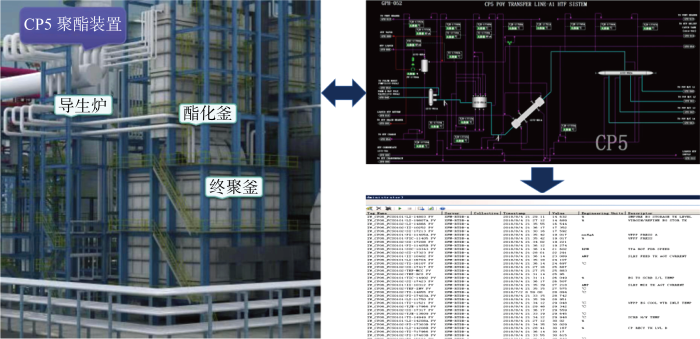
针对聚酯熔体极端生产环境造成的数据不完备,设计了以生成对抗网络为框架的缺失数据填充方法.该方法采用卷积神经网络(Convolutional Neural Network, CNN)作为判别器,利用卷积层强大的特征提取能力实现数据真伪的精确识别;使用注意力长短期记忆(Long Short Term Memory-Attention, LSTM-Attention)神经网络作为生成器,其中LSTM学习时序数据的周期性,Attention机制解决序列过长导致的遗忘问题.最终,通过对抗生成机制实现了缺失数据的填充.
Real-time semi-supervised predictive modeling strategy for industrial continuous catalytic reforming process with incomplete data using slow feature analysis
To address the problem that in the complex urban environment, due to the inevitable interruption of GNSS positioning signal and the accumulation of errors during vehicle driving, the collected vehicle trajectory data was likely to be inaccurate and incomplete.a bidirectional weighted trajectory reconstruction algorithm was proposed based on RNN neural network.The GNSS-OBD trajectory acquisition device was used to collect vehicle trajectory information, and multi-source data fusion was adopted to achieve bidirectional weighted trajectory reconstruction.Furthermore, the neural arithmetic logic unit (NALU) was leveraged with the purpose of enhancing the extrapolation ability of deep network and ensuring the accuracy of trajectory reconstruction.For the evaluation, real-world experiments were conducted to evaluate the performance of the proposed method in comparison with existing methods.The root mean square error (RMSE) indicator shows the algorithm accuracy and the reconstructed trajectory is visually displayed through Google Earth.Experimental results validate the effectiveness and reliability of the proposed algorithm.
WANGM, ZHOUT, WANGH, et al.
Chinese power dispatching text entity recognition based on a double-layer BiLSTM and multi-feature fusion
Deep transfer model with source domain segmentation for polyester esterification processes
1
2022
... 目前关于聚酯熔体特性黏度预测的研究主要可以分为基于机理的方法和数据驱动的方法两种[3].基于机理的方法需要分析生产过程中复杂的物化反应,其中反应温度、压力、转速等是影响其质量的主要物理因素.文献[4]中通过反应动力学方程、物料平衡方程和气液平衡方程建立了机理模型,实现了特性黏度预测.但是该方法是基于理想状态下建模的,无法考虑到众多的影响因素,不适合实际复杂生产.数据驱动的方法只需要研究数据与数据之间的关系,随着传感器技术的发展,数据驱动的方法已经成为当前特性黏度预测问题的主流研究方向[5].文献[6]中提出一种基于时间卷积和注意力门控神经网络的特性黏度预测方法,强化了提取时序数据特征能力,挖掘了时序数据长期依赖关系.为了提取聚酯聚合过程的时序关系并兼顾数据非线性特点,Geng等[7]提出一种基于组合核函数的特性黏度预测模型,通过分形维数方法提取特征并且将基于局部加权回归的季节性趋势分解过程(Seasonal-Trend decomposition procedure based on Loess,STL)与核函数相结合来提取时序数据的周期性,最终对特性黏度实现有效预测.文献[8]中提出一种基于双流λ门控递归单元网络的特性黏度预测方法,通过设计λ双因子来改变门控递归单元中存在的线性约束并且丰富了时序特征信息,最终提高了网络模型的预测精度. ...
Modeling of poly (ethylene terephthalate) reactors: 4. A continuous esterification process
1
1982
... 目前关于聚酯熔体特性黏度预测的研究主要可以分为基于机理的方法和数据驱动的方法两种[3].基于机理的方法需要分析生产过程中复杂的物化反应,其中反应温度、压力、转速等是影响其质量的主要物理因素.文献[4]中通过反应动力学方程、物料平衡方程和气液平衡方程建立了机理模型,实现了特性黏度预测.但是该方法是基于理想状态下建模的,无法考虑到众多的影响因素,不适合实际复杂生产.数据驱动的方法只需要研究数据与数据之间的关系,随着传感器技术的发展,数据驱动的方法已经成为当前特性黏度预测问题的主流研究方向[5].文献[6]中提出一种基于时间卷积和注意力门控神经网络的特性黏度预测方法,强化了提取时序数据特征能力,挖掘了时序数据长期依赖关系.为了提取聚酯聚合过程的时序关系并兼顾数据非线性特点,Geng等[7]提出一种基于组合核函数的特性黏度预测模型,通过分形维数方法提取特征并且将基于局部加权回归的季节性趋势分解过程(Seasonal-Trend decomposition procedure based on Loess,STL)与核函数相结合来提取时序数据的周期性,最终对特性黏度实现有效预测.文献[8]中提出一种基于双流λ门控递归单元网络的特性黏度预测方法,通过设计λ双因子来改变门控递归单元中存在的线性约束并且丰富了时序特征信息,最终提高了网络模型的预测精度. ...
Parallel interaction spatiotemporal constrained variational autoencoder for soft sensor modeling
1
2021
... 目前关于聚酯熔体特性黏度预测的研究主要可以分为基于机理的方法和数据驱动的方法两种[3].基于机理的方法需要分析生产过程中复杂的物化反应,其中反应温度、压力、转速等是影响其质量的主要物理因素.文献[4]中通过反应动力学方程、物料平衡方程和气液平衡方程建立了机理模型,实现了特性黏度预测.但是该方法是基于理想状态下建模的,无法考虑到众多的影响因素,不适合实际复杂生产.数据驱动的方法只需要研究数据与数据之间的关系,随着传感器技术的发展,数据驱动的方法已经成为当前特性黏度预测问题的主流研究方向[5].文献[6]中提出一种基于时间卷积和注意力门控神经网络的特性黏度预测方法,强化了提取时序数据特征能力,挖掘了时序数据长期依赖关系.为了提取聚酯聚合过程的时序关系并兼顾数据非线性特点,Geng等[7]提出一种基于组合核函数的特性黏度预测模型,通过分形维数方法提取特征并且将基于局部加权回归的季节性趋势分解过程(Seasonal-Trend decomposition procedure based on Loess,STL)与核函数相结合来提取时序数据的周期性,最终对特性黏度实现有效预测.文献[8]中提出一种基于双流λ门控递归单元网络的特性黏度预测方法,通过设计λ双因子来改变门控递归单元中存在的线性约束并且丰富了时序特征信息,最终提高了网络模型的预测精度. ...
2
2022
... 目前关于聚酯熔体特性黏度预测的研究主要可以分为基于机理的方法和数据驱动的方法两种[3].基于机理的方法需要分析生产过程中复杂的物化反应,其中反应温度、压力、转速等是影响其质量的主要物理因素.文献[4]中通过反应动力学方程、物料平衡方程和气液平衡方程建立了机理模型,实现了特性黏度预测.但是该方法是基于理想状态下建模的,无法考虑到众多的影响因素,不适合实际复杂生产.数据驱动的方法只需要研究数据与数据之间的关系,随着传感器技术的发展,数据驱动的方法已经成为当前特性黏度预测问题的主流研究方向[5].文献[6]中提出一种基于时间卷积和注意力门控神经网络的特性黏度预测方法,强化了提取时序数据特征能力,挖掘了时序数据长期依赖关系.为了提取聚酯聚合过程的时序关系并兼顾数据非线性特点,Geng等[7]提出一种基于组合核函数的特性黏度预测模型,通过分形维数方法提取特征并且将基于局部加权回归的季节性趋势分解过程(Seasonal-Trend decomposition procedure based on Loess,STL)与核函数相结合来提取时序数据的周期性,最终对特性黏度实现有效预测.文献[8]中提出一种基于双流λ门控递归单元网络的特性黏度预测方法,通过设计λ双因子来改变门控递归单元中存在的线性约束并且丰富了时序特征信息,最终提高了网络模型的预测精度. ...
... 目前关于聚酯熔体特性黏度预测的研究主要可以分为基于机理的方法和数据驱动的方法两种[3].基于机理的方法需要分析生产过程中复杂的物化反应,其中反应温度、压力、转速等是影响其质量的主要物理因素.文献[4]中通过反应动力学方程、物料平衡方程和气液平衡方程建立了机理模型,实现了特性黏度预测.但是该方法是基于理想状态下建模的,无法考虑到众多的影响因素,不适合实际复杂生产.数据驱动的方法只需要研究数据与数据之间的关系,随着传感器技术的发展,数据驱动的方法已经成为当前特性黏度预测问题的主流研究方向[5].文献[6]中提出一种基于时间卷积和注意力门控神经网络的特性黏度预测方法,强化了提取时序数据特征能力,挖掘了时序数据长期依赖关系.为了提取聚酯聚合过程的时序关系并兼顾数据非线性特点,Geng等[7]提出一种基于组合核函数的特性黏度预测模型,通过分形维数方法提取特征并且将基于局部加权回归的季节性趋势分解过程(Seasonal-Trend decomposition procedure based on Loess,STL)与核函数相结合来提取时序数据的周期性,最终对特性黏度实现有效预测.文献[8]中提出一种基于双流λ门控递归单元网络的特性黏度预测方法,通过设计λ双因子来改变门控递归单元中存在的线性约束并且丰富了时序特征信息,最终提高了网络模型的预测精度. ...
Fractal-based combined kernel function model for the polyester polymerization process
2
2021
... 目前关于聚酯熔体特性黏度预测的研究主要可以分为基于机理的方法和数据驱动的方法两种[3].基于机理的方法需要分析生产过程中复杂的物化反应,其中反应温度、压力、转速等是影响其质量的主要物理因素.文献[4]中通过反应动力学方程、物料平衡方程和气液平衡方程建立了机理模型,实现了特性黏度预测.但是该方法是基于理想状态下建模的,无法考虑到众多的影响因素,不适合实际复杂生产.数据驱动的方法只需要研究数据与数据之间的关系,随着传感器技术的发展,数据驱动的方法已经成为当前特性黏度预测问题的主流研究方向[5].文献[6]中提出一种基于时间卷积和注意力门控神经网络的特性黏度预测方法,强化了提取时序数据特征能力,挖掘了时序数据长期依赖关系.为了提取聚酯聚合过程的时序关系并兼顾数据非线性特点,Geng等[7]提出一种基于组合核函数的特性黏度预测模型,通过分形维数方法提取特征并且将基于局部加权回归的季节性趋势分解过程(Seasonal-Trend decomposition procedure based on Loess,STL)与核函数相结合来提取时序数据的周期性,最终对特性黏度实现有效预测.文献[8]中提出一种基于双流λ门控递归单元网络的特性黏度预测方法,通过设计λ双因子来改变门控递归单元中存在的线性约束并且丰富了时序特征信息,最终提高了网络模型的预测精度. ...
Data-driven modeling based on two-stream λ gated recurrent unit network with soft sensor application
1
2019
... 目前关于聚酯熔体特性黏度预测的研究主要可以分为基于机理的方法和数据驱动的方法两种[3].基于机理的方法需要分析生产过程中复杂的物化反应,其中反应温度、压力、转速等是影响其质量的主要物理因素.文献[4]中通过反应动力学方程、物料平衡方程和气液平衡方程建立了机理模型,实现了特性黏度预测.但是该方法是基于理想状态下建模的,无法考虑到众多的影响因素,不适合实际复杂生产.数据驱动的方法只需要研究数据与数据之间的关系,随着传感器技术的发展,数据驱动的方法已经成为当前特性黏度预测问题的主流研究方向[5].文献[6]中提出一种基于时间卷积和注意力门控神经网络的特性黏度预测方法,强化了提取时序数据特征能力,挖掘了时序数据长期依赖关系.为了提取聚酯聚合过程的时序关系并兼顾数据非线性特点,Geng等[7]提出一种基于组合核函数的特性黏度预测模型,通过分形维数方法提取特征并且将基于局部加权回归的季节性趋势分解过程(Seasonal-Trend decomposition procedure based on Loess,STL)与核函数相结合来提取时序数据的周期性,最终对特性黏度实现有效预测.文献[8]中提出一种基于双流λ门控递归单元网络的特性黏度预测方法,通过设计λ双因子来改变门控递归单元中存在的线性约束并且丰富了时序特征信息,最终提高了网络模型的预测精度. ...
Energy consumption prediction of a CNC machining process with incomplete data
Real-time semi-supervised predictive modeling strategy for industrial continuous catalytic reforming process with incomplete data using slow feature analysis





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}