

在现代化电子战场中,对截获到的目标雷达调制信号实现精确识别,是雷达侦察技术有效实施的关键一环,具有十分重要的作用.随着深度学习理论的快速发展,其在人脸识别[1]、目标检测[2]和自然语言处理[3]领域取得重大突破,用深度学习的方法解决调制信号识别问题也成为一个研究热点.文献[4]中提出一种首先使用残差网络进行去噪,然后基于Inception-v4网络进行特征提取的调制信号识别方法,在 -10 dB 信噪比下,识别率仍然可以达到90%以上.文献[5]中提出基于双通道卷积神经网络的雷达信号脉内调制方式识别方法,在信噪比为 -10 dB 时,整体识别准确率能达到95%以上.文献[6]中利用迁移学习和特征融合的识别方法实现雷达调制信号的准确识别.文献[7]中提出双卷积神经网络串联的网络结构,当雷达信号调制参数不固定时,依然可以进行分类识别,信噪比为0 dB时,识别率在95%以上.文献[8]中利用卷积神经网络和长短时记忆网络分别提取信号的空间特征与时间特征,并进行特征融合与分类,识别率达到91%.文献[9]中将信号的高阶积累量作为深度置信网络的输入,实现了4ASK、BPSK、QPSK、2FSK和4FSK共5种信号的分类,信噪比为0 dB时,识别率能够达到95%以上.文献[10]中在卷积神经网络中引入了信号失真校正模块,有效提高了信号识别率.文献[11]中利用稀疏自编码器进行无监督学习,然后通过softmax分类器实现对信号的分类.
随着深度学习的发展,逐渐应用于未知信号类别(未经过网络训练的信号类别)识别领域,未知信号的有效识别在军事领域和民用领域都发挥着重要作用.在战场环境中,对敌方的通信系统进行监听和干扰需要识别出敌方信号的调制方式,若敌方采用新的调制方式的信号进行通信时,我方需要识别出该未知调制类型的信号,才能进一步分析和估计该信号的各个参数,从而采取相应的侦察和反侦察措施.在民用通信中,通信管理部门需要完成识别信号、识别干扰以及监测频谱等任务,不仅需要监视合法电台是否符合自身的标准工作参数,更重要的是识别非法电台的源头.文献[12]中提出一种基于引入中心损失函数、交叉熵损失函数以及重构损失函数共3种损失函数的SR2CNN网络实现未知信号识别.文献[13]中利用开集识别分类重构学习网络(Classification-Reconstruction learning for Open-Set Recognition, CROSR)对提取到的特征进行了重构,保留了能够辨别出已知类别和未知类别的有用信息,使经过训练的网络可以从输入数据中识别出未知类别.文献[14]中提出一种改进的无监督异常值检测自编码器来进行未知信号检测.文献[15]中通过改变已知信号类别的类属性和未知信号类别的类属性,用二元分类器实现未知信号的识别.然而,现阶段大部分基于深度学习的未知信号识别方法只考虑到如何对未知信号进行识别,却没有兼顾到对已知信号的识别,以及无法判断检测出的未知信号有几种类别.
因此,本文提出基于多流ConvNeXt网络[16]和马氏距离度量(MDM)[17]结合(ConvNeXt-MDM)的未知信号增量识别方法.首先,为了使已知信号的属性特征与未知信号的属性特征有较大的差异性以及不同类别信号属性特征的区分度更加显著,采用多流ConvNeXt网络对信号进行特征提取.其次,针对闭集识别网络无法正确识别未知信号类别的问题,引入基于异常值检测思想的距离度量判决方法,通过对提取的属性特征进行距离度量判决将信号分成已知信号和未知信号两大类别.最后,针对现有的大部分未知信号识别模型只检测出了未知信号,却无法判断检测出未知信号有几种类别的问题,引入增量学习的思想,使识别模型能够根据增加的新的未知类别信号更新模型参数,使识别模型具备自我进化的能力,实现未知信号类型的增量识别.
在实际应用方面,面对日益复杂的电磁环境,对设备的小型化、智能化提出了更高的要求.本文使用的识别网络具有深度可分离卷积结构,降低了网络参数量,能够部署在更加小型化的识别设备上;并且,本文提出的识别方法能够实现未知信号的增量识别,避免了识别设备重复训练历史数据,提高了学习新数据的时效性,更适合部署在移动设备上以适应复杂的电磁环境.
1 识别算法
1.1 未知信号增量识别算法整体结构
本文提出的未知信号增量识别方法整体结构如图1所示,分为4个模块,分别是“信号属性特征提取”模块、“已知信号与未知信号二分类”模块、“已知信号识别”模块和“未知信号增量识别”模块.
图1
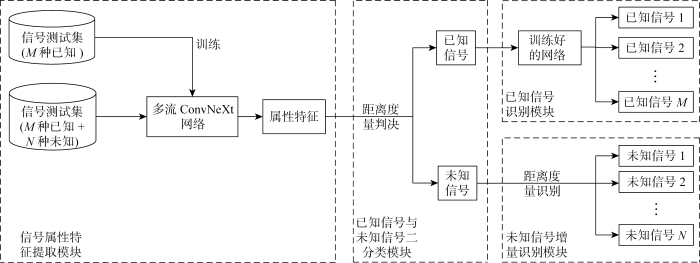
首先,使用多流ConvNeXt网络提取信号的属性特征;其次通过引入异常值检测思想的马氏距离度量判决方法对属性特征进行距离度量判决,实现已知信号和未知信号的二分类;再次,当信号被判决为未知信号时,将已知信号发送到只由全连接层组成的闭集识别网络中进行闭集识别;最后,当信号被判决为未知信号时,则通过距离度量判决方法对检测出的未知信号进行增量识别.
1.2 改进的多流ConvNeXt网络
ConvNeXt网络是Facebook人工智能研究院 (Facebook AI Research,FAIR)在2022年提出的一种纯卷积神经网络.ConvNeXt以ResNet[18]网络为基础,借鉴了Swim-Transform[19]网络及Transformer架构中的各种先进方法,同时也借鉴了其他一些优化神经网络的先进思想,在训练方法、宏观设计和微观设计等方面进行改进.其中具体包括引入深度可分离卷积(Depthwise Separable Convolution)来提升模型的计算速度, 使用逆瓶颈层结构(Inverted Bottleneck)有效避免了信息流失,用层标准化(Layer Normalization, LN)层替换批标准化(Batch Normalization, BN)层来解决BN在样本量过少的时候归一化统计量偏差过大的问题并使用更少的归一化层,使用GELU激活函数代替ReLU激活函数并减少激活函数的数量、使用AdamW优化器、改变区块(block)比例以及改变卷积核尺寸大小及通道数目等.ConvNeXt网络集上述设计思想于一体,在多个计算机视觉基准上有效提高了准确性和可扩展性,达到了目前纯卷积模型的极限.
已知信号与未知信号的属性特征有较大差别时,可以提高二分类的准确率.尺寸不同的卷积核能够提取到的感受野的特征不同,从而丰富网络提取的特征类型,使网络提取到的属性特征类间距离更大,类内距离更小,进而使不同类别信号属性特征的区分度更加显著,有利于提高信号的识别率.更重要的是,随着网络宽度的增加,网络对特征局部信息变化的适应能力也随之增强,使已知信号的属性特征与未知信号的属性特征之间有了较大的差异性.因此用多尺度卷积并行处理的方式改进ConvNeXt网络,形成多流ConvNeXt网络,网络结构如图2所示.图中:h表示输入数据尺寸的高度;w表示输入数据尺寸的宽度;dim表示维度;Conv2d表示二维卷积操作;s表示卷积操作的步长;p表示卷积操作填充的大小;Layer Scale表示对数据进行缩放;Drop Path表示正则化;Concat表示将不同卷积操作的输出进行合并;Downsample表示下采样操作;Linear表示全连接层.通过多流ConvNeXt网络基本单元进行多次的特征提取后,再对提取的特征进行下采样操作以此降低特征尺寸和调节特征通道数,最终得到理想的特征.
图2
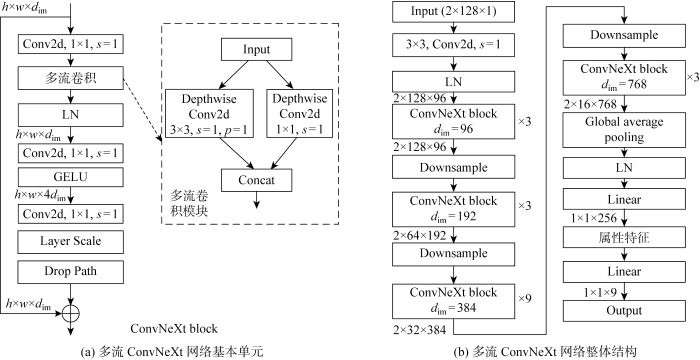
从多流ConvNeXt网络结构可以看出,网络全局平均池化层(Global Average Pooling)的输出经过全连接层获得256维的属性特征.通过第1次距离度量判决实现信号的二分类后,当信号被判决为未知信号时,将该信号的256维属性特征进行第2次距离度量判决;当信号被判决为已知信号时,则将该信号的256维属性特征直接送入下一层的全连接层进行闭集识别.
1.3 距离度量算法
使用距离度量算法识别未知信号需要进行两次距离度量判决.第1次距离度量判决针对闭集识别网络无法正确识别未知信号类别的问题,引入异常值检测的思想,通过对提取的属性特征进行判决将输入的信号分成已知信号和未知信号两大类别,然后根据已知信号和未知信号的特点采取针对性的识别方法,提高了识别模型的灵活性.
在第1次距离度量判决中首先要计算出输入信号τ的属性特征F(τ)与每类已知类型信号属性特征中心的马氏距离:
式中:k=1, 2, …, M,M为已知信号的类别数量;Φk为第k类已知信号的协方差矩阵;Sk为第k类信号的属性特征中心,
n为全部训练样本的数量;δ为单位脉冲函数;yi为第i个样本的标签;F(xi)为第i个样本的属性特征.然后从M个马氏距离中选择出最小的距离d1=min(d(F(τ), Sk)),若d1的值小于事先设置好的距离度量阈值则将输入的信号判决为已知信号,否则将其判决为未知信号.
为了使模型能够识别出不断增加的新的未知信号类别,在第2次距离度量判决中引入了增量学习的思想,不断更新属性特征中心以此来实现未知信号的增量识别.例如,当输入的信号被判决为未知信号时,若在这之前已经识别出两种未知信号类型,接下来则需要计算出该输入信号的属性特征与两种未知信号属性特征中心的距离,并取出两个距离中最小的一个距离,若该距离大于事先设置好的距离度量阈值,则将其判决为第3种未知信号.
两次距离度量判决成功的关键在于两个距离度量阈值的设置,根据3σ准则,将第1次距离度量阈值设置为
式中:p为输入样本的个数;α1为第1次距离度量阈值系数,其最优值根据下文的实验仿真结果确定.经过第1次距离度量检测出未知信号后,第2次距离度量不再是计算测试信号的属性特征与M种已知信号的属性中心之间的距离d(F(τ), Sk),而是需要计算F(τ)与未知信号的属性特征中心之间的距离d(F(τ), Su),Su为第u类未知信号的属性特征中心.为了获取第2次距离度量阈值,需要先计算出F(τ)与每类已知类型信号属性特征中心Sk的平均距离dave,根据以往的距离判决经验,在前文中所提到的d1与dave对第2次距离度量阈值的设置有十分重要的参考意义并且应该尽量使第2次距离度量阈值大于d1但不能大于dave.根据仿真实验结果确定,当第2次距离度量阈值设置在d1与dave之间时,对检测出的未知信号进行增量识别有着很高的正确率.因此将第2次距离度量阈值设置为
式中:α2为第2次距离度量阈值系数.通过调节α2的值来调整距离度量阈值η2,但始终使η2介于d1与dave之间.
1.4 识别算法流程
图3
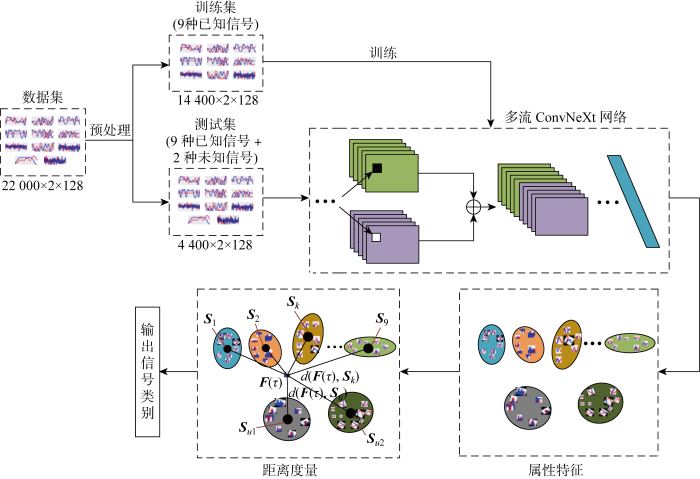
图3
基于多流ConvNeXt-MDM的未知信号识别模型
Fig.3
Unknown signal recognition model based on multi-flow ConvNeXt-MDM
图4
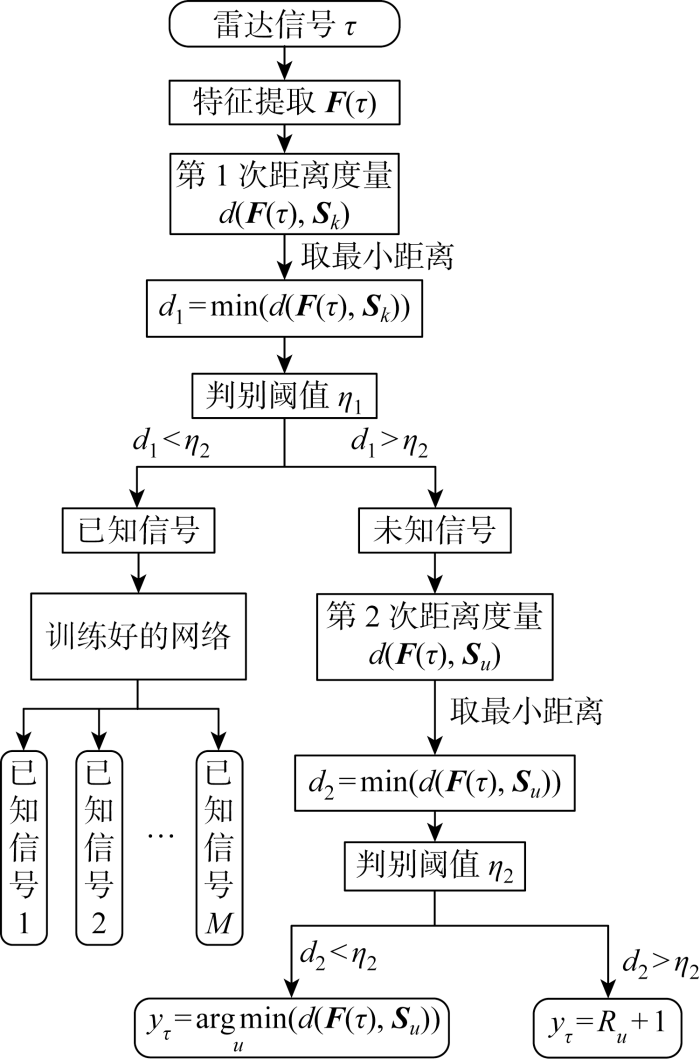
算法详细流程如下.
步骤1 使用多流ConvNeXt网络对输入的调制信号τ进行特征提取,得到属性特征F(τ).
步骤2 分别计算F(τ)与M种已知信号属性特征中心Sk的马氏距离d(F(τ), Sk),并从M个马氏距离中选择出最小的一个d1.
步骤3 进行第1次马氏距离度量判决,若d1大于判决阈值η1,则将输入信号τ判定为未知信号,否则将输入信号τ判定为已知信号.
步骤4 当输入信号τ被判定为已知信号时,将输入信号τ输入训练好的网络中输出对应的已知信号类别.当输入信号τ被判定为未知信号时,进行第2次马氏距离度量识别,分别计算F(τ)与u种未知信号属性特征中心Su的马氏距离d(F(τ), Su),并从u个马氏距离中选择出最小的一个d2.
步骤5 若d2小于判决阈值η2,则将输入信号τ判定为在测试阶段已被检测到的未知信号,并将输入信号τ识别为yτ=arg
在未知信号增量识别的过程中,若第1次从输入信号中检测出未知信号,则不需要对该未知信号进行增量识别,可以直接将其判决成未知信号1,并将其属性特征作为未知信号1的属性特征中心.直到第2次从输入信号中检测出未知信号,此时需要对该信号进行增量识别,首先对该信号进行第2次距离度量判决,即计算该信号的属性特征与未知信号1的属性特征中心之间的距离.若该距离小于第2次距离度量阈值,则将该信号判决为未知信号1并更新未知信号1的属性特征中心;若该距离大于第2次距离度量阈值,则将该未知信号判决为新的未知信号,即未知信号2;以此类推,直到识别出所有的未知信号类别.
2 仿真结果与分析
2.1 实验条件和数据处理
实验软硬件环境配置如表1所示.
表1 实验软硬件环境
Tab.1
| 配置 | 型号 | 参数 |
|---|---|---|
| 处理器及内存 | Intel(R) Xeon(R) Silver 4110 | 2.1 GHz 32 GB内存 |
| 操作系统 | Ubuntu 18.04.1 | 64位 |
| 显卡 | NVIDIA Tesla T4 | 15 GB显存 |
| 语言 | Python | 3.7.9 |
| 框架 | Pytorch | 1.7.1 |
| 运算平台 | CUDA | 10.1 |
本文所用的数据集是来自于文献[23]中公开的RML2016.10a数据集, 该数据集包含8PSK、AM-DSB、AM-SSB、BPSK、CPFSK、GFSK、PAM4、QAM16、QAM64、QPSK、WBFM共11种调制信号,每种调制信号有 20 000 个样本.数据集信噪比以2 dB间隔从 -20 dB 到18 dB上近似均匀分布,一共20种信噪比,即每种调制信号的一种信噪比的样本为 1 000 个.RML2016.10a数据集由同相分量和正交分量两路数据组成,维数为2×128,2对应同相分量和正交分量这两路信号,128对应128个采样点,因此数据集中全部的样本数量为 220 000 个,每个样本的维数为2×128.数据集中的信号样本是在衰落、多径和加性高斯白噪声等信道条件下使用真实的语音和文本信号获得的,因此接近真实的场景数据.
因为本文的研究目标是未知调制信号识别,所以要尽量排除噪声的影响,选择16 dB和18 dB信噪比最高的共 22 000 个样本作为本文仿真实验所用的数据集.选取8PSK、AM-DSB、BPSK、CPFSK、PAM4、QAM16、QAM64、QPSK、WBFM共9种调制信号共18 000个样本作为已知调制信号,选取GFSK、AM-SSB两种调制信号共 4 000 个样本作为未知调制信号.同时,从已知调制信号中的每一类中各随机选取80%共 14 400 个样本作为训练数据集,剩下的20%与从未知调制信号的每一类中随机选取出的20%加一起共 4 400 个样本作为测试数据集.即训练数据集由9种已知信号组成,每种信号包含 1 600 个样本,共 14 400 个样本;测试数据由9种经过网络训练过的已知信号和2种未经过网络训练过的未知信号组成,每种信号包含400个样本,共 4 400 个样本.
2.2 识别效果分析
在本文中,从输入的测试样本中正确检测出未知信号是信号识别的前提.未知信号检测可等价于二分类问题,如表2所示,将已知信号视为正样本P(Positive),未知信号视为负样本N(Negative).其中,TP(True Positive)表示真实的已知信号被正确预测为已知信号的数量;FN(False Negative)表示真实的已知信号被错误预测为未知信号的数量;FP(False Positive)表示真实的未知信号被错误预测为已知信号的数量;TN(True Negative)表示真实的未知信号被正确预测为未知信号的数量.
TP与TN是负相关的.本文提出的多流ConvNeXt-MDM方法在不同的第1次距离度量阈值系数下的二分类结果如图5所示,其中横坐标为第1次距离度量阈值系数,纵坐标为信号二分类的识别率,已知信号的识别率RTK (True Known Rate)和未知信号的识别率RTU (True Unknown Rate)的计算表达式如下:
图5
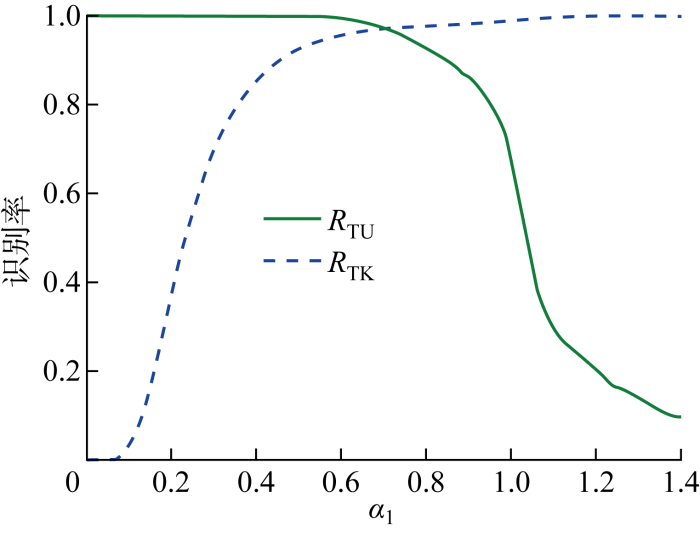
图5
不同距离度量阈值系数下的识别结果
Fig.5
Recognition results at different distance metric threshold coefficients
由图5可知,第1次距离度量阈值越大,RTK越大,RTU越小,越容易将未知信号误判为已知信号;第1次距离度量阈值越小,RTK越小,RTU越大,越容易将已知信号误判为未知信号.
不同第1次距离度量阈值下的二分类实验结果具体数值如表3所示.为了兼顾已知信号的识别率和未知信号的识别率,第1次距离度量阈值系数取值为0.66时,RTK的值和RTU的值均为97%以上,分别为97.2%和98.9%,这说明本文提出的方法能够以较高的准确率实现已知信号和未知信号的二分类.
表3 二分类实验结果
Tab.3
| α1 | TP | FN | TN | FP | RTK | RTU |
|---|---|---|---|---|---|---|
| 0.00 | 0 | 3 600 | 800 | 0 | 0 | 1 |
| 0.33 | 2 664 | 936 | 798 | 2 | 0.740 | 0.998 |
| 0.66 | 3 500 | 100 | 791 | 9 | 0.972 | 0.989 |
| 1.00 | 3 564 | 36 | 504 | 296 | 0.990 | 0.630 |
第1次距离度量检测出未知信号后,通过第2次距离度量对检测出的未知信号进行增量识别,最终实验识别结果如表4所示.本文提出的方法对已知信号和未知信号都有较高的识别率.其中AM-SSB信号与GFSK信号是没有在网络中训练过的信号类别,是未知信号.在此强调本次实验中对已知信号和未知信号的定义:已知信号类别在训练阶段被送入网络中训练,未知信号类别未曾被网络训练过,只在测试阶段与已知信号一同送入被已知信号训练好网络中进行识别,更重要的是已知信号的类别与未知信号的类别没有交集.
表4 识别结果
Tab.4
| 实际信号 | 预测信号 | 识别率/% | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 8PSK | AM-DSB | BPSK | CPFSK | PAM4 | QAM16 | QAM64 | QPSK | WBFM | 未知信号 | ||
| 8PSK | 385 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 12 | 96.3 |
| AM-DSB | 0 | 213 | 0 | 0 | 0 | 0 | 0 | 0 | 167 | 20 | 53.3 |
| BPSK | 2 | 0 | 374 | 0 | 0 | 0 | 0 | 2 | 0 | 22 | 93.5 |
| CPFSK | 0 | 0 | 0 | 394 | 0 | 0 | 0 | 0 | 0 | 6 | 98.5 |
| PAM4 | 0 | 0 | 0 | 0 | 391 | 0 | 0 | 0 | 0 | 9 | 97.8 |
| QAM16 | 8 | 0 | 0 | 0 | 0 | 342 | 23 | 2 | 0 | 25 | 85.5 |
| QAM64 | 3 | 0 | 0 | 0 | 0 | 31 | 339 | 1 | 0 | 26 | 84.8 |
| QPSK | 0 | 0 | 1 | 0 | 0 | 0 | 2 | 386 | 0 | 11 | 96.5 |
| WBFM | 0 | 57 | 0 | 0 | 0 | 0 | 0 | 0 | 324 | 19 | 81.0 |
| AM-SSB | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 399 | 99.8 |
| GFSK | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 392 | 98.0 |
对检测出的未知信号进行增量识别,结果如表5所示.本次实验的测试集数据共包含两种类别的未知信号,却识别出6种未知信号类别,这是由于第2次距离度量阈值设置的过低而造成的.根据1.3节中关于第2次距离度量判决过程的具体描述可知,若第2次距离度量阈值设置过高,会导致将检测出的未知信号全部识别为同一种未知信号,降低未知信号的平均识别率;若第2次距离度量阈值设置过低,则会导致识别出类别更多的未知信号,同样会降低未知信号的平均识别率.
表5 未知信号识别结果
Tab.5
| 实际信号 | 预测信号 | |||||
|---|---|---|---|---|---|---|
| 未知1 | 未知2 | 未知3 | 未知4 | 未知5 | 未知6 | |
| 8PSK | 4 | 3 | 1 | 3 | 0 | 1 |
| AM-DSB | 10 | 5 | 0 | 2 | 3 | 0 |
| BPSK | 2 | 8 | 3 | 7 | 2 | 0 |
| CPFSK | 0 | 3 | 3 | 0 | 0 | 0 |
| PAM4 | 0 | 3 | 5 | 1 | 0 | 0 |
| QAM16 | 7 | 9 | 6 | 2 | 1 | 0 |
| QAM64 | 1 | 6 | 12 | 2 | 4 | 1 |
| QPSK | 0 | 1 | 8 | 0 | 2 | 0 |
| WBFM | 0 | 13 | 0 | 3 | 2 | 1 |
| AM-SSB | 395 | 3 | 0 | 0 | 1 | 0 |
| GFSK | 2 | 386 | 1 | 2 | 1 | 0 |
经过实验论证,当第2次距离度量阈值系数设置为1.02时,模型对未知信号的识别结果如表5所示,此时模型对两种未知信号类别的识别率分别为98.75%和96.50%.
2.3 识别性能对比
本文使用多卷积并行处理方法改进ConvNeXt网络,形成多流ConvNeXt网络,使用该网络提取的属性特征进行距离度量判决可以更加准确地检测出未知信号.为了对其进行验证,用改进之前的网络和改进之后的网络分别对输入信号进行属性特征提取,对两种网络提取的属性特征进行第1次马氏距离度量判决,实现已知信号和未知信号的二分类.二分类效果可由RTK和RFK (False Known Rate)绘制成图6所示的受试者工作特征(Receiver Operating Characteristic,ROC)曲线表示,其中RFK表示真实的未知信号被错误预测为已知信号的概率,其计算公式如下:
图6
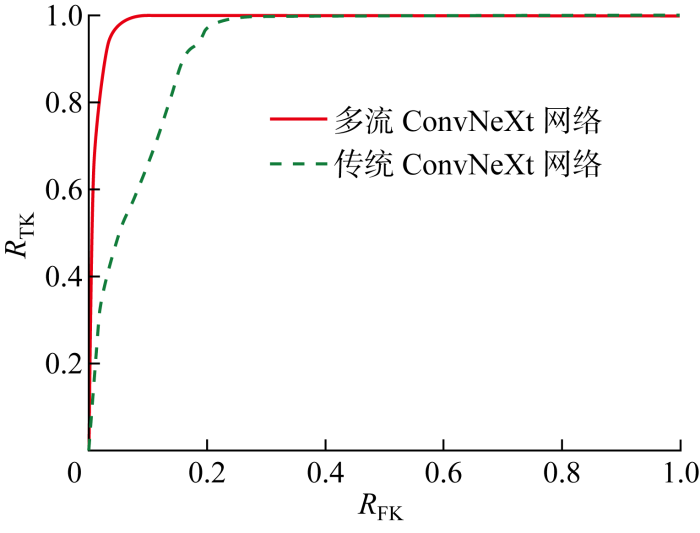
从图6中可以看出,利用多卷积并行处理改进的ConvNeXt网络提取的属性特征进行二分类的ROC曲线有更高的曲线下面积(Area Under Curve,AUC)值,即使用本文提出的多流ConvNeXt网络可以更加准确地检测出未知信号.
表6 识别性能对比
Tab.6
| 识别参数 类型 | 识别率/% | |||
|---|---|---|---|---|
| 本文算法 | SR2CNN | Inception-v4 | MobileNetV3 | |
| 8PSK | 96.3 | 85.5 | 85.7 | 87.5 |
| AM-DSB | 53.3 | 73.5 | 65.0 | 72.3 |
| BPSK | 93.5 | 95.5 | 94.5 | 88.5 |
| CPFSK | 98.6 | 99.0 | 87.0 | 89.8 |
| PAM4 | 97.8 | 94.5 | 85.2 | 87.0 |
| QAM16 | 85.5 | 49.3 | 71.7 | 36.5 |
| QAM64 | 84.8 | 44.0 | 72.3 | 44.5 |
| QPSK | 96.5 | 90.5 | 89.0 | 91.2 |
| WBFM | 81.0 | 32.0 | 66.1 | 22.5 |
| 平均识别率 | 87.5 | 73.7 | 79.6 | 68.8 |
| RTK | 97.2 | 95.9 | 92.9 | 91.4 |
| RTU | 98.8 | 99.5 | 97.8 | 92.6 |
为了保证在第2次距离度量判决中对检测出的未知信号进行增量识别的准确率,需要在第1次距离度量判决中尽量提高RTU的值,因此第1次距离度量阈值系数设置的不宜过大,才能降低未知信号被误判决为已知信号的概率.同时为了保证已知信号的识别率,第1次距离度量阈值系数设置的也不宜过小,而使RTK的值过低.经过实验结果确定,将4种模型的第1次距离度量阈值系数分别设置为0.66(多流ConvNeXt-MDM网络)、0.56(SR2CNN网络)、0.34(Inception-v4网络)和0.3(MobileNetV3网络)时,在进行第1次距离度量判决后,得到的RTK与RTU值都在90%以上.由表6可以看出,RTK在90%以上的情况下,本文提出的算法对已知信号的平均识别率最高,达到了87.5%,验证了多流ConvNeXt网络对信号进行特征提取的有效性.
为了进一步验证本文识别模型对检测出的未知信号进行增量识别的有效性,将上述4种识别模型检测出的未知信号的属性特征进行第2次距离度量判决.本文使用的数据集含有两种未知信号类别,由1.4节中对识别流程的具体介绍可知,若第2次距离度量阈值过小,容易将相同类别的未知信号误判决成多种不同类别的未知信号,造成识别模型最终识别出的未知信号类别远大于两种.相反,若第2次距离度量阈值过大,容易将不同类别的未知信号误判决为同一种信号.
图7
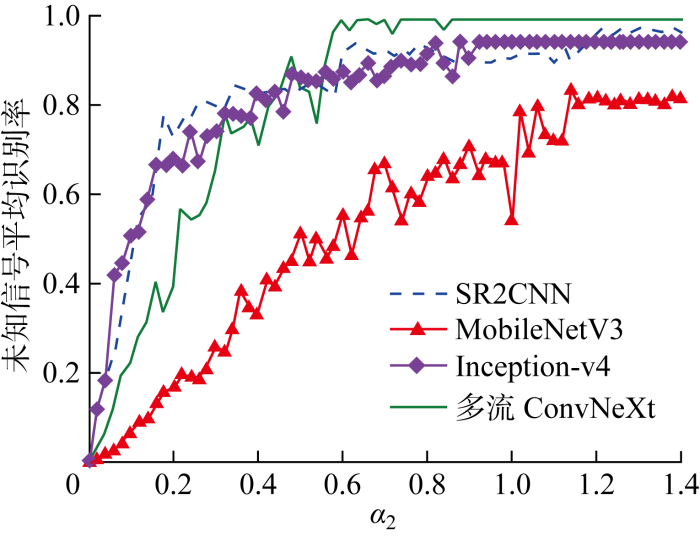
图7
不同算法下的未知信号平均识别率
Fig.7
Average recognition rate of unknown signal of different algorithms
通过与SR2CNN网络、MobileNetV3网络和Inception-v4网络进行对比,发现本文提出的多流ConvNeXt网络的在阈值系数大于0.6以后,识别效果最好.这是因为用多流ConvNeXt网络提取的相同未知信号类别属性特征聚集度更高,不同未知信号类别属性特征中心之间的距离更大,当度量阈值过小,与该未知信号类别的属性特征中心过近,造成信号的误判,随着度量阈值的系数增加,尤其是大于0.6以后,判决的准确率迅速提高,对未知信号的平均识别率达到97%以上.验证了多流ConvNeXt网络对信号进行特征提取的优越性,也进一步验证了本文提出的多流ConvNeXt-MDM未知信号增量识别方法的有效性.
然而,通过上述实验结果和分析可以看出,只有取得较高的RTK值与RTU值时,已知信号的闭集识别和未知信号的增量识别才能取得较高的准确率.此外,RTK和RTU是负相关的,导致已知信号和未知信号的识别率也是负相关的.当第1次距离度量阈值设置较低时可以提高未知信号的识别率,但会降低已知信号的识别率;反之亦然,当第1次距离度量阈值设置较高时可以提高已知信号的识别率,但会降低未知信号的识别率.因此,度量阈值设置的不合理会直接导致识别结果出错.
3 结语
针对现有的信号识别方法无法对类别不断增加的未知信号进行有效识别的问题,提出了基于多流ConvNeXt-MDM的方法实现了未知信号的增量识别.首先,在ConvNeXt网络基础上引入多尺度卷积并行处理的思想,形成多流ConvNeXt网络,提高了网络在未知信号识别方面的特征提取能力.其次,利用引入异常值检测思想的马氏距离度量判决检测出未知信号,实现了已知信号和未知信号的二分类.最后,为了使模型能够识别出不断增加的不同的未知信号类别,在距离度量判决中加入了增量学习的思想,使识别模型能够根据增加的新的未知类别信号更新出专门识别该类未知信号的模型参数,使识别模型具备自我进化的能力,从而可以识别出不断增加的新的未知信号类别.实验结果表明,该方法能够将已知信号维持在较高识别率的前提下,对未知信号的平均识别率依然达到97%以上,具备良好的未知识别效果,并在复杂的电磁环境中使识别设备更加小型化、智能化,为未知信号识别提供了新的方案.
参考文献
A new method for face recognition using convolutional neural network
[J].
Apple detection during different growth stages in orchards using the improved YOLO-V3 model
[J].DOI:10.1016/j.compag.2019.01.012 URL [本文引用: 1]
Natural language processing (NLP) in management research: A literature review
[J].DOI:10.1080/23270012.2020.1756939 URL [本文引用: 1]
基于去噪卷积神经网络的雷达信号调制类型识别
[J].
Radar signal modulation type recognition based on denoising convolutional neural network
[J].
基于双通道卷积神经网络的雷达信号识别
[J].
DOI:10.16183/j.cnki.jsjtu.2021.209
[本文引用: 1]

为解决在低信噪比下特征提取困难、雷达信号识别率低的问题,提出了一种基于Choi-Williams分布(CWD)和多重同步压缩变换(MSST)的双通道卷积神经网络模型.模型通过对雷达信号进行CWD和MSST时频分析,分别获取二维时频图像并进行预处理,然后送入双通道卷积神经网络进行深度特征提取,最后将两路通道获取的特征进行融合,通过卷积神经网络分类器实现对雷达信号的分类识别.仿真结果表明:在信噪比为 -10 dB时,所提模型整体识别准确率能达到96%以上,其在低信噪比下表现优异.
Radar signal recognition based on dual channel convolutional neural network
[J].
Radar signal recognition based on transfer learning and feature fusion
[J].DOI:10.1007/s11036-019-01360-1 [本文引用: 1]
基于双CNN的雷达信号调制类型识别方法
[J].
Radar signal modulation type recognition based on double CNN
[J].
基于信噪比分类网络的调制信号分类识别算法
[J].
Modulation signal classification and recognition algorithm based on signal to noise ratio classification network
[J].
Modulation recognition of digital signals based on deep belief network
[J].
DOI:10.1088/1757-899X/563/5/052009
[本文引用: 1]
A modulation pattern recognition method for digital modulation signals, 4ASK, BPSK, QPSK, 2FSK and 4FSK digital modulation signals, which is based on deep learning model of deep belief network is proposed. The modulation signal is pre-processed and its high order cumulants are calculated as input training features. Solutions to the problem that the same high Modulation signals are generated in different SNR environments. Using the semi-supervised learning characteristics of deep confidence network, data sets are obtained to train the parameters of deep Confidence network layer by layer for feature extraction and recognition of modulation modes. The simulation results show that the recognition rate of this method is ideal.
A learnable distortion correction module for modulation recognition
[J].DOI:10.1109/LWC.2018.2855749 URL [本文引用: 1]
Automatic modulation classification of digital modulation signals with stacked autoencoders
[J].DOI:10.1016/j.dsp.2017.09.005 URL [本文引用: 1]
SR2CNN: Zero-shot learning for signal recognition
[J].DOI:10.1109/TSP.2021.3070186 URL [本文引用: 2]
Classification-reconstruction learning for open-set recognition
[C]//
Improved autoencoder for unsupervised anomaly detection
[J].DOI:10.1002/int.v36.12 URL [本文引用: 1]
Counterfactual zero-shot and open-set visual recognition
[C]//
A ConvNet for the 2020s
[C]//
Mahalanobis distance
[J].
Deep residual learning for image recognition
[C]//
Swin transformer: Hierarchical vision transformer using shifted windows
[C]//
Person re-identification over camera networks using multi-task distance metric learning
[J].
DOI:10.1109/TIP.2014.2331755
PMID:24956368
[本文引用: 1]
Person reidentification in a camera network is a valuable yet challenging problem to solve. Existing methods learn a common Mahalanobis distance metric by using the data collected from different cameras and then exploit the learned metric for identifying people in the images. However, the cameras in a camera network have different settings and the recorded images are seriously affected by variability in illumination conditions, camera viewing angles, and background clutter. Using a common metric to conduct person reidentification tasks on different camera pairs overlooks the differences in camera settings; however, it is very time-consuming to label people manually in images from surveillance videos. For example, in most existing person reidentification data sets, only one image of a person is collected from each of only two cameras; therefore, directly learning a unique Mahalanobis distance metric for each camera pair is susceptible to over-fitting by using insufficiently labeled data. In this paper, we reformulate person reidentification in a camera network as a multitask distance metric learning problem. The proposed method designs multiple Mahalanobis distance metrics to cope with the complicated conditions that exist in typical camera networks. We address the fact that these Mahalanobis distance metrics are different but related, and learned by adding joint regularization to alleviate over-fitting. Furthermore, by extending, we present a novel multitask maximally collapsing metric learning (MtMCML) model for person reidentification in a camera network. Experimental results demonstrate that formulating person reidentification over camera networks as multitask distance metric learning problem can improve performance, and our proposed MtMCML works substantially better than other current state-of-the-art person reidentification methods.
Decomposition-based transfer distance metric learning for image classification
[J].
DOI:10.1109/TIP.2014.2332398
PMID:24968169
[本文引用: 1]
Distance metric learning (DML) is a critical factor for image analysis and pattern recognition. To learn a robust distance metric for a target task, we need abundant side information (i.e., the similarity/dissimilarity pairwise constraints over the labeled data), which is usually unavailable in practice due to the high labeling cost. This paper considers the transfer learning setting by exploiting the large quantity of side information from certain related, but different source tasks to help with target metric learning (with only a little side information). The state-of-the-art metric learning algorithms usually fail in this setting because the data distributions of the source task and target task are often quite different. We address this problem by assuming that the target distance metric lies in the space spanned by the eigenvectors of the source metrics (or other randomly generated bases). The target metric is represented as a combination of the base metrics, which are computed using the decomposed components of the source metrics (or simply a set of random bases); we call the proposed method, decomposition-based transfer DML (DTDML). In particular, DTDML learns a sparse combination of the base metrics to construct the target metric by forcing the target metric to be close to an integration of the source metrics. The main advantage of the proposed method compared with existing transfer metric learning approaches is that we directly learn the base metric coefficients instead of the target metric. To this end, far fewer variables need to be learned. We therefore obtain more reliable solutions given the limited side information and the optimization tends to be faster. Experiments on the popular handwritten image (digit, letter) classification and challenge natural image annotation tasks demonstrate the effectiveness of the proposed method.
Kernelized evolutionary distance metric learning for semi-supervised clustering
[J].DOI:10.3233/IDA-184283 URL [本文引用: 1]
Convolutional radio modulation recognition networks
[C]//
Searching for mobilenetv3
[C]//
Inception-v4, Inception-ResNet and the impact of residual connections on learning
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}