

目前主流的网络压缩方法有参数量化与共享[8]、低秩近似[9]、知识蒸馏[10]、设计轻量级的模型[11⇓⇓⇓⇓-16]和网络剪枝[17⇓⇓⇓⇓⇓⇓⇓⇓-26]等,其中网络剪枝是基于某种准则判断网络参数的重要性,删除冗余参数.针对网络剪枝, Yann等[17]和Hassibi等[18] 最早提出用loss函数的Hessian矩阵来确定网络中的冗余参数,然而Hessian矩阵的计算本身就消耗大量时间.Han等[19]提出根据神经元连接权值的范数大小删除范数值小于阈值的连接.Chen等[20]提出HashedNets模型,该模型使用低成本的哈希函数实现参数剪枝.上述方法都是非结构性剪枝,修剪网络中权重小的不重要连接,得到的网络权值大多为0,因此可以利用稀疏格式存储模型来减少存储空间.然而这些方法只能通过专门的稀疏矩阵操作库或硬件来实现加速,运行时内存节省也非常有限.Li等[21]提出计算滤波器的L1范数,剪掉范数较小的滤波器.Chen等[22]提出使用Eyeriss处理器计算每一层能耗,优先删除能耗较大的层.Liu等[23]提出将批量归一化层(Batch Normalization, BN)的缩放系数γ作为判断滤波器重要性的依据,删除γ值小的滤波器.然而,这些方法只单独使用网络中的一部分参数,可能会导致对冗余参数的判定不够准确.韦越等[24]提出对模型进行稀疏化训练,然后将滤波器权重L1范数和BN层缩放系数γ的乘积作为判定依据.卢海伟等[25]提出将注意力机制和BN层的缩放系数γ相结合来判断滤波器重要性.上述方式可以更加准确地判断滤波器重要性.但相比于L1范数和注意力机制,Liu等[26]使用的稀疏性公式可以准确地表示卷积层中的提取到的参数信息.
为了适用于移动设备,出现了一些构造特殊结构的滤波器、网络层或网络具有存储量小、计算量低和网络性能好等特点的轻量级模型,如Mobile~Net[11⇓-13]、Xception[14]、NestedNet[15]、MicroNet[16]等.其中,谷歌提出的MobileNetV1采用深度可分离卷积结构代替普通卷积操作,在参数量、计算量大幅度减少的同时,在ImageNet数据集上取得与视觉几何组(Visual Geometry Group, VGG)神经网络相当的准确率,得到学界的广泛关注.为提高准确率,MobileNet逐步从MobileNetV1发展到Mobile~NetV3,但模型体积越来越大,所需计算资源也越来越多,对移动设备中的资源要求越来越高.相较于传统DNN,轻量级网络设计更巧妙、结构更紧凑、计算方式更复杂,但可压缩的部分越来越少,给深度学习模型压缩的研究带来新的挑战.另一方面,不同轻量级模型具有不同网络结构特点,如何准确选择冗余结构,是对轻量级网络模型进行压缩的关键,是本文研究的主要目标之一.因此,为了进一步降低Mobile~NetV3对移动设备的硬件资源要求,使其可以部署到低功耗、低延时的应用场景中,基于Mobile~NetV3的网络结构特点提出一种新的模型压缩剪枝方法.
1 MobileNetV3
MobileNetV3[13]是谷歌在2019年提出的轻量级网络架构,除了继承MobileNetV1[11]和MobileNetV2[12]的特性之外,又拥有许多新特性.MobileNetV3使用的网络架构是基于神经网络架构搜索(Neural Architecture Search, NAS)实现的MnasNet,引入V1的深度可分离卷积、V2的具有线性瓶颈的倒残差结构和压缩激励模块(Squeeze and Excite,SE)结构的轻量级注意力模型,使用ReLU6函数和一种新的激活函数h-swish(x),如图1所示.图中:Dwise表示深度卷积,NL表示使用非线性激活函数,FC表示全连接运算,Pool表示下采样,hard-α表示NL激活函数的“hard”形式.该结构首先采用1×1点卷积对输入数据的维度进行扩充,然后进行逐深度卷积,再添加轻量级SE模块提升模型对通道的敏感度,最后使用1×1点卷积对维度进行压缩.其中V1的深度可分离卷积如图2所示,V2具有线性瓶颈的倒残差结构如图3所示.图中:C为滤波器层数(输入);k为卷积核大小;N为滤波器数量.在MobileNetV3-Large中基本网络单元占用大部分参数量计算量,具体如表1所示.MobileNetV3中使用ReLU6激活函数代替常规的线性修正单元(Linear rectification function, ReLU)函数,使激活函数输出参数分布的更加均匀[28],适合使用稀疏性公式进行判别.
图1
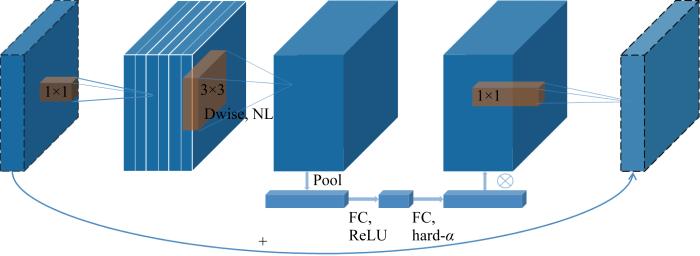
图2
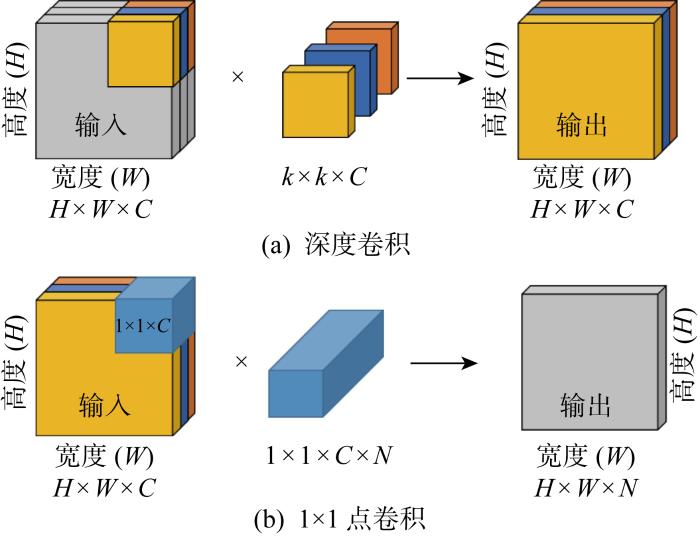
图3
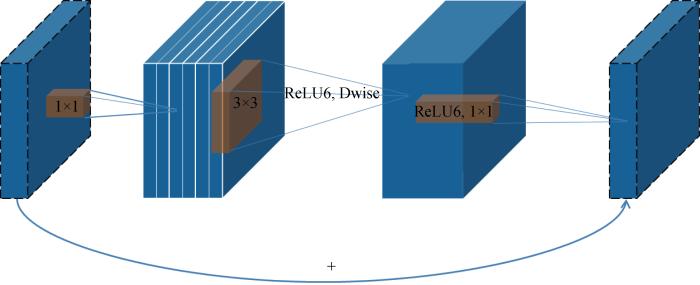
表1 MobileNetV3-Large主要资源占用
Tab.1
| 类型 | 参数占用量/% | 计算量/% |
|---|---|---|
| 网络单元 | 66.84 | 94.14 |
| 其他 | 33.16 | 5.87 |
2 结构化剪枝方法
根据MobileNetV3的结构特点,在不破坏原始网络结构的情况下,减少卷积层滤波器可以大幅度减少网络的计算量和参数量,提高网络运算速度.因此,首先使用L1正则化对模型进行稀疏化训练,再利用卷积层和BN层两层的参数信息对网络进行修剪,提出将缩放系数和稀疏值的乘积作为滤波器重要性的判断标准,对网络进行以滤波器为最小单位的结构化剪枝.
2.1 稀疏训练
由于易于实现且不会对网络引入额外的开销,所以选择L1正则化对神经网络进行稀疏训练,惩罚一些不重要的参数,使得滤波器中的参数稀疏化.使用的损失函数如下:
式中:LCE为交叉熵损失函数,对于特征缩放系数γ,R(γ)=|γ|;λ为一个超参数,λ越大惩罚的参数越多,BN层中的参数就会越接近0.
2.2 特征缩放系数
大多数卷积神经网络都使用BN[27]结构,它是一种可以实现快速收敛和更好泛化能力的标准方式,一般置于卷积层的后一层,对卷积层的输出进行归一化处理.BN层有两个可学习的参数γ和β,可以使特征值学习到每一层的特征分布.BN层输入输出关系如下:
式中:Zin和Zout 分别为输入、输出;μc和σc分别为对应激活通道c的均值和方差;ε为一个添加到小批量方差中的常数,用于数值稳定性;β为对应激活通道的偏移系数.缩放系数γ与通道的激活程度一一对应,间接反映对应滤波器的重要性,可以作为判定滤波器重要性的依据,而且不会给网络带来额外开销.
2.3 稀疏性公式
基于Liu等[26]提出的稀疏性公式,根据下式计算滤波器稀疏值:
式中:n、c、w、h为组成卷积核4维张量的参数,n为滤波器数量(输出),c为滤波器层数(输入),w和h分别为滤波器宽度和长度;n, c, w, h 为正整数且n∈[N], c∈[C], h∈[H], w∈[W];σ(x)为公式Sl(n)中的一个变量,用于计算Sl(n);kl,nchw为卷积核权重.Sl(n)表示第l层中第n个滤波器的稀疏性,如果一个滤波器有越多系数小于该层的平均值Ml,那么Sl(n)越接近0,表示该滤波器与该层的其他滤波器相比更冗余.Ml是一个阈值,式(3)中Ml表示第l层卷积核权重平均值,根据下式计算:
相比于每个滤波器的L1范数平均值,以所有滤波器权重范数和的平均值Ml作为Sl(n)的阈值,计算每个滤波器的稀疏值,更能体现每个滤波器在整个网络中的重要性.前者通过一个滤波器中的参数判定滤波器重要性,后者通过整个网络中所有滤波器的参数来判断一个滤波器对整个网络的影响,后者不仅更加准确,也更适合全局阈值修剪网络的方法.
2.4 滤波器重要性判定依据
利用卷积层的参数Sl(n)和BN层参数γ两部分结合,作为滤波器重要性的判定依据,得出重要性判定函数如下:
式中:mi为第i个滤波器的重要性评分;γi为第i个滤波器对应的BN层缩放系数;Si为利用式(3)计算出的第i个滤波器的稀疏值.
根据重要性判定依据mi对网络进行修剪.图4是本文使用的剪枝方法图,具体步骤如算法1所示,其中d表示权重的维度,一般情况下为4.
图4
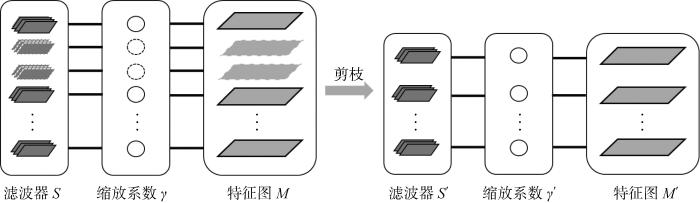
图4
结合Sl(n) 与缩放系数γ的结构化剪枝方法图
Fig.4
Structured pruning method combining Sl(n) and scaling factor γ
算法1 本文使用的剪枝方法
1: 使用随机权重W0∈Rd初始化一个网络,初始化剪枝掩码θ=1d.
2: 作用参数λ训练W0共200次,得到权重W1.
3: 从W1中计算mi,按顺序排列mi得到一个索引index.
4: 当mi<mindex50%时θi=0, 通过计算θ☉W1, 得到稀疏的权重W2.
5: 如果W2中的滤波器权重等于0,则删除滤波器.
6: 得到紧凑的权重参数W3,对应新的网络结构.
7: 重新训练W3共150次,得到最终结果W4.
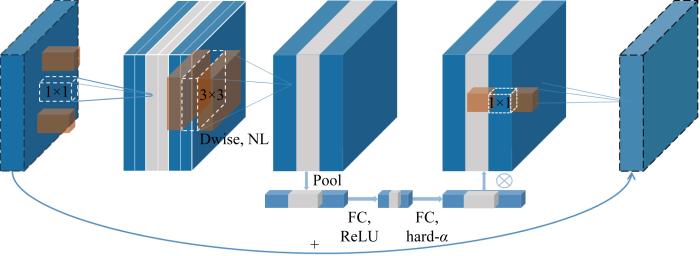
在MobileNetV3特殊的网络结构中,倒置的残差模块占用大部分运算量和内存,因此本文主要对MobileNetV3 的基本网络单元结构进行修剪.由于深度可分离卷积中深度卷积的存在,要求这层卷积运算输入和输出的滤波器个数一致,但直接裁剪会导致输入和输出滤波器个数不一致,网络无法运行,而且深度可分离卷积中主要的计算量和参数量都来自于1×1 点卷积,深度卷积只占用很少的资源,所以只需要裁剪网络单元中的1×1卷积的滤波器,间接影射到深度卷积和后续的运算,就可以最大幅度减少网络的参数量和计算量.具体对模型的裁剪如图5所示,其中虚线部分表示裁剪的滤波器,首先裁剪1×1滤波器的个数,进而影响3×3滤波器维度和最后的1×1滤波器维度,灰色部分为裁剪滤波器后减少的对应特征图.
图5
3 实验
3.1 实验环境
为保证实验的准确性和客观性,使用经典数据集CIFAR-10和CIFAR-100作为实验数据集.CIFAR-10是一个10分类数据集,每个类包含 6 000 张图片,共有 60 000 张彩色图片,其中 50 000 张作为训练集,10 000 张作为测试集,图片分辨率为32像素×32像素,在实验过程中将图片调整大小为224像素×224像素.CIFAR-100是CIFAR-10衍生出来的数据集,区别是CIFAR-100数据集包含100个分类,每个类包括600张图片.使用NVDIA GeForce RTX 3060 6 G显卡,采用Pytorch深度学习框架进行搭建、训练和测试.实验过程中使用Adam优化器,初始学习率为0.001,正则化系数选择 105 对模型MobileNetV3-Large进行稀疏训练,初始训练迭代200次,微调 150次,微调时不进行稀疏训练.
3.2 实验结果与分析
3.2.1 正则化系数的选择
综合考虑准确率和稀疏化效果,为了找出最恰当的正则化系数λ,对网络进行稀疏化训练时,同时设置多个λ,评估不同λ对模型准确率和稀疏化的影响.在实验过程中发现L1正则化系数λ大小不同基本不影响Sl(n)的分布,但会导致BN层参数γ分布不同,如图6所示.当λ=0时,BN层参数γ近似正态分布,当使用γ作为其中一个判定标准对模型进行剪枝时会删除部分有用的参数信息,影响剪枝效果.而随着λ增加,越来越多的参数γ聚集在0附近,对于模型剪枝而言,可以更加准确地判断冗余滤波器.因此,在选择BN层系数作为其中一个滤波器判定标准时,稀疏化训练至关重要.
图6
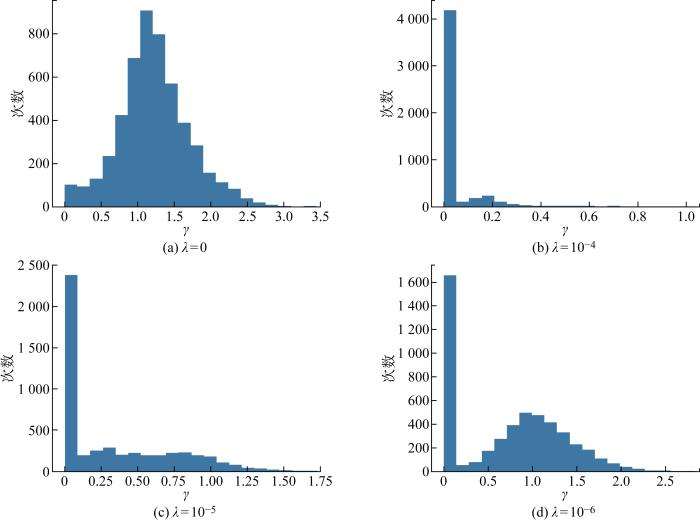
图6
不同正则化系数下的γ值分布图
Fig.6
γ value distribution at different regularization coefficients
不同的正则化系数λ对网络参数的约束程度不相同,网络准确率也不相同.越大的正则化系数会惩罚越多的参数,使滤波器参数越稀疏.但是惩罚过多的参数对网络的准确率也有很大的影响,参数越稀疏,网络准确率也会越低.λ=0,10-3,10-4,10-5,10-6时,对应的准确率分别为88.28%、85.50%、87.22%、88.15%、88.15%.λ大于10-3时,网络中参数过于稀疏,导致模型不收敛;λ小于10-3时,模型精度与稀疏程度会有一个折中.综合准确率和稀疏程度两种指标,选择10-5作为正则化系数,在保持准确率不变的情况下,对滤波器参数进行约束.
3.2.2 重要性评分
图7
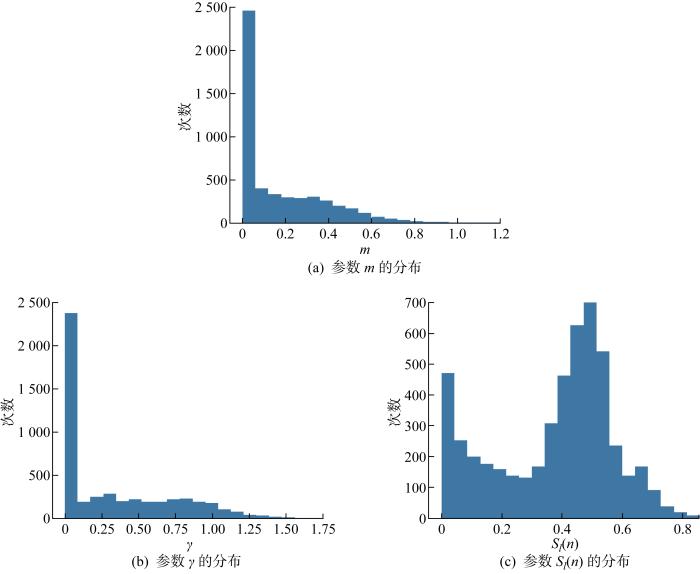
图7
正则化训练后的参数分布(λ=10-5)
Fig.7
Parameter distribution after regularization trainning (λ=10-5)
表2 不同剪枝率下对应的m值及γ和Sl(n)的范围
Tab.2
| 剪枝率/% | m | γ | Sl(n) |
|---|---|---|---|
| 10 | 2.306 4×10-12 | 4.003 9×10-12~4.922 5×10-10 | 0~0.651 8 |
| 20 | 1.072 1×10-11 | 8.369 6×10-17~5.289 2×10-10 | 0.006 3~0.705 4 |
| 30 | 2.904 7×10-11 | 1.814 9×10-11~4.982 8×10-10 | 0.035 7~0.681 2 |
| 40 | 7.888 8×10-11 | 4.654 0×10-11~5.280 5×10-10 | 0.062 5~0.830 4 |
| 50 | 0.070 0 | 1.188 0×10-10~2.804 1×10-01 | 0.071 4~0.794 6 |
| 60 | 0.146 6 | 0.087 5~0.583 8 | 0.187 5~0.830 4 |
3.2.3 剪枝率
使用全局阈值对网络进行一次性剪枝.为了寻找最合适的剪枝率,设置14个不同的剪枝率在CIFAR-10数据集上对MobileNetV3-Large进行测试.由于裁剪到70%时会删除某个层的所有滤波器,导致网络结构被破坏,所以将剪枝率设置在0%~60%.模型在剪枝45%时,重新训练准确率最高达到88.82%,比没有剪枝前稀疏训练的模型高0.67%,比未剪枝未稀疏训练的模型高0.54%,说明本文剪枝方法减少部分影响判断结果的无用参数,减少神经元之间错综复杂的依赖关系,增强模型的泛化能力,提高模型的鲁棒性.不同剪枝率下模型参数量和计算量对比如表3所示.
表3 不同剪枝率下参数量计算量
Tab.3
| 剪枝 率/% | 准确 率/% | 参数 量×10-6 | 参数 减少量/% | 计算量 | 计算 减少量/% |
|---|---|---|---|---|---|
| 0 | 88.28 | 4.22 | 0 | 2.30×108 | 0 |
| 10 | 87.86 | 3.68 | 12.8 | 2.17×108 | 5.7 |
| 20 | 88.26 | 3.26 | 22.7 | 2.00×108 | 13.0 |
| 30 | 88.23 | 2.89 | 31.5 | 1.81×108 | 21.3 |
| 40 | 88.69 | 2.61 | 38.2 | 1.61×108 | 30.0 |
| 50 | 88.55 | 2.34 | 44.5 | 1.38×108 | 40.0 |
| 60 | 87.99 | 2.16 | 48.8 | 9.87×107 | 57.1 |
3.2.4 不同剪枝方法对比
为了进一步说明本文剪枝方法的有效性,在同一实验环境,尽可能压缩网络且保存网络精度的条件下将全局剪枝率设置为50%,在CIFAR-10上测试对比4种剪枝方式, 实验结果如表4所示.在剪枝率相同的情况下,本文剪枝方式准确率略高于其他方式,同时在参数量和计算量上也有很大程度的压缩.在剪枝率50%的情况下,参数量下降44.5%, 计算量下降40.0%, 准确率上升0.4%.
表4 几种剪枝准则在CIFAR-10上的对比(裁剪50%)
Tab.4
实验结果表明,在相同剪枝率的情况下本文的剪枝方法获得较好的剪枝结果,与单独使用BN层参数γ和单独使用卷积层参数相比,本文将两者结合的方法对冗余滤波器判别更加准确,获得更高的准确率和参数压缩率.
3.2.5 剪枝前后模型结构可视化对比
图8
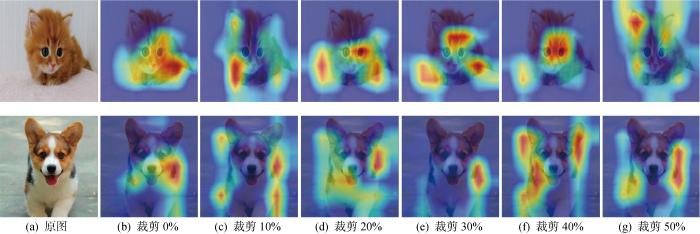
图8
剪枝前后模型结果可视化对比
Fig.8
Comparison of visualization of model result before and after pruning
从结果上来看,裁剪网络结构会减少网络中提取到的部分特征,但使用剩余特征进行网络微调可以让剩余特征学习到比原始网络更多的特征,也即突出了剩余特征.这里的剩余特征也就是最开始网络判定的重要特征.因此网络准确率保持不变甚至优于原始网络,也表明本文剪枝方法可以准确地判断冗余信息.
3.2.6 剪枝后的模型
表5 剪枝前后模型通道数对比
Tab.5
| 输入尺寸 | 模块 | 模块中 通道数 | 模块中通道 数(剪枝后) | 输出 通道数 | 激励模块 | 激活函数 | 步长 |
|---|---|---|---|---|---|---|---|
| 224×224×3 | conv2d | — | — | 16 | — | HS | 2 |
| 112×112×16 | bneck, 3×3 | 16 | 9 | 16 | — | RE | 1 |
| 112×112×16 | bneck, 3×3 | 64 | 49 | 24 | — | RE | 2 |
| 56×56×24 | bneck, 3×3 | 72 | 42 | 24 | — | RE | 1 |
| 56×56×24 | bneck, 5×5 | 72 | 72 | 40 | √ | RE | 2 |
| 28×28×40 | bneck, 5×5 | 120 | 102 | 40 | √ | RE | 1 |
| 28×28×40 | bneck, 5×5 | 120 | 89 | 40 | √ | RE | 1 |
| 28×28×40 | bneck, 3×3 | 240 | 223 | 80 | — | HS | 2 |
| 14×14×80 | bneck, 3×3 | 200 | 144 | 80 | — | HS | 1 |
| 14×14×80 | bneck, 3×3 | 184 | 139 | 80 | — | HS | 1 |
| 14×14×80 | bneck, 3×3 | 184 | 112 | 80 | — | HS | 1 |
| 14×14×80 | bneck, 3×3 | 480 | 209 | 112 | √ | HS | 1 |
| 14×14×112 | bneck, 3×3 | 672 | 38 | 112 | √ | HS | 1 |
| 14×14×112 | bneck, 5×5 | 672 | 540 | 160 | √ | HS | 2 |
| 7×7×160 | bneck, 5×5 | 960 | 484 | 160 | √ | HS | 1 |
| 7×7×160 | bneck, 5×5 | 960 | 255 | 160 | √ | HS | 1 |
| 7×7×160 | conv2d, 1×1 | — | — | 960 | — | HS | 1 |
| 7×7×960 | pool, 7×7 | — | — | — | — | — | 1 |
| 1×1×960 | conv2d, 1×1, NBN | — | — | 1 280 | — | HS | 1 |
| 1×1×1280 | conv2d, 1×1, NBN | — | — | q | — | — | 1 |
3.2.7 在CIFAR-100上进行测试
为了进一步证明本文剪枝方法的有效性,在标准数据集CIFAR-100上进行测试,将剪枝率设置为0%~60%,实验结果如表6所示.
表6 不同剪枝率下参数量计算量(CIFAR-100)
Tab.6
| 剪枝 率/% | 准确 率/% | 参数 量/M | 参数 减少量/% | 计算量 | 计算 减少量/% |
|---|---|---|---|---|---|
| 0 | 61.47 | 4.33 | 0 | 2.30×108 | 0 |
| 10 | 60.81 | 3.59 | 17.1 | 2.18×108 | 5.2 |
| 20 | 61.25 | 3.29 | 24.0 | 2.07×108 | 10.0 |
| 30 | 61.51 | 2.93 | 32.3 | 1.90×108 | 17.4 |
| 40 | 60.92 | 2.62 | 39.5 | 1.70×108 | 26.1 |
| 50 | 61.22 | 2.38 | 45.0 | 1.52×108 | 33.9 |
| 60 | 61.16 | 2.16 | 50.1 | 1.18×108 | 48.7 |
4 结语
基于深度神经网络压缩理论,采用结构化剪枝对轻量级模型MobileNetV3-Large进行压缩.在保证网络精度略有上升的情况下,对模型中的滤波器进行修剪,达到压缩网络的效果.提出一种判断滤波器重要性的方式,利用稀疏性公式和BN层缩放系数γ的乘积作为判断滤波器重要性的准则.实验证明:一方面,计算滤波器的稀疏性信息可以提取到具有判别性的信息;另一方面,特征缩放系数γ也衡量了滤波器重要性.综合两种判断指标,证实本文的判定方式能够更加准确地选取冗余滤波器,在模型准确率基本保持不变的情况下,实现模型最大程度上的压缩,提高网络的泛化能力.
参考文献
ImageNet classification with deep convolutional neural networks
[J].
DOI:10.1145/3065386
URL
[本文引用: 1]

We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes. On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0%, respectively, which is considerably better than the previous state-of-the-art. The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully connected layers with a final 1000-way softmax. To make training faster, we used non-saturating neurons and a very efficient GPU implementation of the convolution operation. To reduce overfitting in the fully connected layers we employed a recently developed regularization method called \"dropout\" that proved to be very effective. We also entered a variant of this model in the ILSVRC-2012 competition and achieved a winning top-5 test error rate of 15.3%, compared to 26.2% achieved by the second-best entry.
基于卷积神经网络的三维物体检测方法
[J].
A convolutional neural network-based method for 3D object detection
[J].
A survey of deep learning-based object detection methods and datasets for overhead imagery
[J].DOI:10.1109/ACCESS.2022.3149052 URL [本文引用: 1]
一种改进变换网络的域自适应语义分割网络
[J].
A domain adaptive semantic segmentation network based on improved transformation network
[J].
深度学习模型压缩与加速综述
[J].
Survey of deep learning model compression and acceleration
[J].
深度神经网络模型压缩综述
[J].
DOI:10.3778/j.issn.1673-9418.2003056
[本文引用: 1]
近年来,随着深度学习的飞速发展,深度神经网络受到了越来越多的关注,在许多应用领域取得了显著效果。通常,在较高的计算量下,深度神经网络的学习能力随着网络层深度的增加而不断提高,因此深度神经网络在大型数据集上的表现非常卓越。然而,由于其计算量大、存储成本高、模型复杂等特性,使得深度学习无法有效地应用于轻量级移动便携设备。因此,压缩、优化深度学习模型成为目前研究的热点。当前主要的模型压缩方法有模型裁剪、轻量级网络设计、知识蒸馏、量化、体系结构搜索等。对以上方法的性能、优缺点和最新研究成果进行了分析总结,并对未来研究方向进行了展望。
Survey of deep neural networks model compression
[J].
MobileNets: Efficient convolutional neural networks for mobile vision applications
[EB/OL]. (
1990. Optimal brain damage
[J].
Compressing neural networks with the hashing trick
[EB/OL]. (
Pruning filters for efficient convNets
[EB/OL]. (
基于稀疏正则化的卷积神经网络模型剪枝方法
[J].
DOI:10.19678/j.issn.1000-3428.0059375
[本文引用: 3]
现有卷积神经网络模型剪枝方法仅依靠自身参数信息难以准确评估参数重要性,容易造成参数误剪且影响网络模型整体性能。提出一种改进的卷积神经网络模型剪枝方法,通过对卷积神经网络模型进行稀疏正则化训练,得到参数较稀疏的深度卷积神经网络模型,并结合卷积层和BN层的稀疏性进行结构化剪枝去除冗余滤波器。在CIFAR-10、CIFAR-100和SVHN数据集上的实验结果表明,该方法能有效压缩网络模型规模并降低计算复杂度,尤其在SVHN数据集上,压缩后的VGG-16网络模型在参数量和浮点运算量分别减少97.3%和91.2%的情况下,图像分类准确率仅损失了0.57个百分点。
Pruning method for convolutional neural network models based on sparse regularization
[J].
DOI:10.19678/j.issn.1000-3428.0059375
[本文引用: 3]
The existing pruning algorithms for Convolutional Neural Network(CNN) models exhibit a low accuracy in evaluating the importance of parameters by relying on their own parameter information, which would easily lead to mispruning and affect the performance of model.To address the problem, an improved pruning method for CNN models is proposed.By training the model with sparse regularization, a deep convolutional neural network model with sparse parameters is obtained.Structural pruning is performed by combining the sparsity of the convolution layer and the BN layer to remove redundant filters.Experimental results on CIFAR-10, CIFAR-100 and SVHN datasets show that the proposed pruning method can effectively compress the network model scale and reduce the computational complexity.Especially on the SVHN dataset, the compressed VGG-16 network model reduces the amount of parameters and FLOPs by 97.3% and 91.2%, respectively, and the accuracy of image classification only loses 0.57 percentage points.
基于滤波器注意力机制与特征缩放系数的动态网络剪枝
[J].结构化剪枝是模型压缩的一种有效方式,裁减掉网络中不重要的滤波器,减小网络的计算量和存储量.然而,仅仅基于滤波器自身的参数信息是无法准确判断该滤波器是否冗余.针对以上问题,提出一种利用卷积层和BN层双层参数信息的动态网络剪枝方法,该方法利用滤波器注意力机制以及BN(Batch Normalization)层缩放系数选择冗余滤波器,并对其进行裁剪.该方法具有三个优势:1)端到端的训练剪枝:训练和剪枝同时进行,训练速度更快.2)更大的优化空间:训练过程中动态调整被裁剪的滤波器,搜索最优的剪枝策略.3)更准确的滤波器选择:运用多重参数信息精确选取冗余的滤波器,提高了网络的泛化性能.实验分别在标准CIFAR-10数据集和CIFAR-100数据集上进行,尤其在CIFAR-10数据集上的实验结果表明,压缩后的ResNet56和ResNet110的浮点运算率减少40%多,但精度比基本网络高.
Dynamic network pruning via filter attention mechanism and feature scaling factor
[J].Structured pruning is an effective way of model compression,which reduces the unimportant filters in the network and reduces the amount of computation and storage of the network..However,it is impossible to accurately determine the filter based on the parameter information of the filter itself.A dynamic pruning method is proposed,which uses the attention mechanism of the filter and the BN layer scaling factor to select a redundant filter and crop it.The method has three advantages:1.End-to-end training pruning:training and pruning are performed at the same time and the training speed is faster.2.Larger optimization space:The training network dynamically adjusts the cropped filter to search for the optimal pruning strategy.3.More accurate filter selection:Multiple parameter information selects redundant filters to ensure the performance of the network.The experiments were carried out on CIFAR-10 and CIFAR-100 respectively.The experimental results on the CIFAR-10 dataset showed that the floating point operations of the compressed ResNet56 and ResNet110 were reduced by more than 40%,but the accuracy was improved.
Computation-performance optimization of convolutional neural networks with redundant filter removal
[J].
Quantization friendly MobileNet (QF-MobileNet) architecture for vision based applications on embedded platforms
[J].DOI:10.1016/j.neunet.2020.12.022 URL [本文引用: 1]
基于稀疏卷积核的卷积神经网络研究及其应用
[J].
Research and application of convolutional neural network based on sparse convolution kernel
[J].
Semantic understanding based on multi-feature kernel sparse representation and decision rules for mangrove growth
[J].DOI:10.1016/j.ipm.2021.102813 URL [本文引用: 1]
A difference-of-convex functions approach for sparse PDE optimal control problems with nonconvex costs
[J].
A sparse optimization problem with hybrid L2-Lp regularization for application of magnetic resonance brain images
[J].DOI:10.1007/s10878-019-00479-x [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}