为实现碳达峰、碳中和的目标,满足日益增长的能源需求,可再生能源已被广泛应用于能源系统和市场.风力发电(简称风电)是一种在世界范围内储备丰富的可再生能源,已成为许多地区越来越重要的发电来源.截至2021年底,全球风电累计装机容量达到840 GW,并且仍处于快速上升阶段[1 ] .对风力或风电功率时间序列的点和概率性预测是风电预测系统的重要组成部分.然而,对于经济调度这类随机优化问题,点和概率性预测并不能提供充分参考.近年来,场景生成法已成为风电预测的一个新兴研究领域.场景生成指通过构建数学模型,对未来一段时间内风电场的风速或功率做出预测,生成多个符合风电场时间序列和时空特征的场景.生成场景作为经济调度、机组组合等优化决策问题的输入,对合理地求解调度方案、进行电力系统运营相关的决策具有重要意义.在风能场景预测中,一个场景通常指风电场在一个时间段内的风能功率时间序列.
总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化.
现阶段,大规模风力发电源于广阔区域内多个风电场,需要对多个风电场总功率场景做出预测,因此把握风电场之间的空间相关性和风电场内的时间相关性非常重要;同时,具体的场景生成依赖于功率预测值和真实值之间的联合分布,因此准确构建预测值和真实值的条件联合分布是另一重点.当前主流场景生成方法对这两个重点有不同处理方式.Wang等[15 ] 利用核密度估计(Kernel Density Estimation, KDE)法建立功率真实值和预测值间的条件概率函数,并使用R-vine Copula构建风电场间的空间相关性,最后通过条件概率逆变换来得到生成场景.但在R-vine Copula构建过程中,需要依次估计不同风电场间条件概率分布的Copula函数,受风电场数量影响,计算过程繁琐复杂,且只考虑了风电场间的空间相关性,忽视了风电场内时间相关性对建模的影响.Ma等[16 ] 将风能预测值按大小分层,根据不同区间预测功率对应的实际功率构建条件概率分布,并使用指数型协方差函数表示风能时间相关性,但指数协方差函数只考虑了时间相关性,不能反映风电场的空间相关性,只适用于单一或少数风电场.Tan等[17 ] 使用高斯混合模型估计功率真实值和预测值间的条件联合概率分布函数,但对数据分布的要求是混合高斯分布,对预测值和真实值的联合分布的估计不够准确.Deng等[18 ] 利用C-vine Copula构建风电场内部的空间相关性结构,但空间相关性只体现于两个风电场之间,且并未生成具体的每日风电出力场景.
针对目前场景生成方法中存在只考虑风电功率的时间相关性或只考虑空间相关性以及条件概率函数估计不够准确等问题,本文创新在于利用结合经验估计方法的时空协方差函数,准确刻画了多个风电场功率序列的时间和空间相关性特征,同时使用Pair Copula模型准确拟合功率预测值和实际值之间的联合分布,生成具体每日风电出力场景,并通过指标进行评估.此外,为验证生成的风能功率场景在电力系统中的运用价值,介绍一种两阶段的电力系统经济调度模型,并考察模型可行性与可靠性,进一步验证方法生成场景质量.
1 数据集介绍
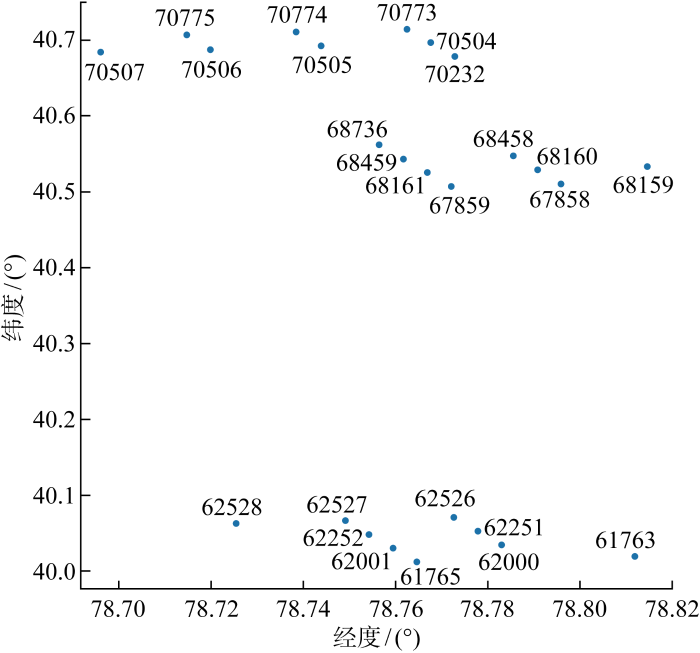
使用美国中东部地区2012—2013年中25个风电场的Wind Toolkit数据集[19 ] ,风电场标号以及空间分布如图1 所示,其中坐标点上方数字为风电场标号.该数据集包含了每个风电场的风速和功率数据,每个风电场额定功率为10~16 MW.功率数据集由100 m轮毂高度处的风力数据和适合站点位置的风力发电机功率曲线创建,考虑风力发电机间的唤醒效应以估算每个站点产生的功率,分辨率为5 min.为减少计算量,取分辨率为1 h.利用长短期记忆(Long Short-Term Memory, LSTM)神经网络的方法进行训练和预测得到预测数据集,均方根误差为1.71 MW.
图1
图1
25个风电场的地理位置
Fig.1
Geographical location of 25 wind farms
2 基于时空协方差函数场景生成方法
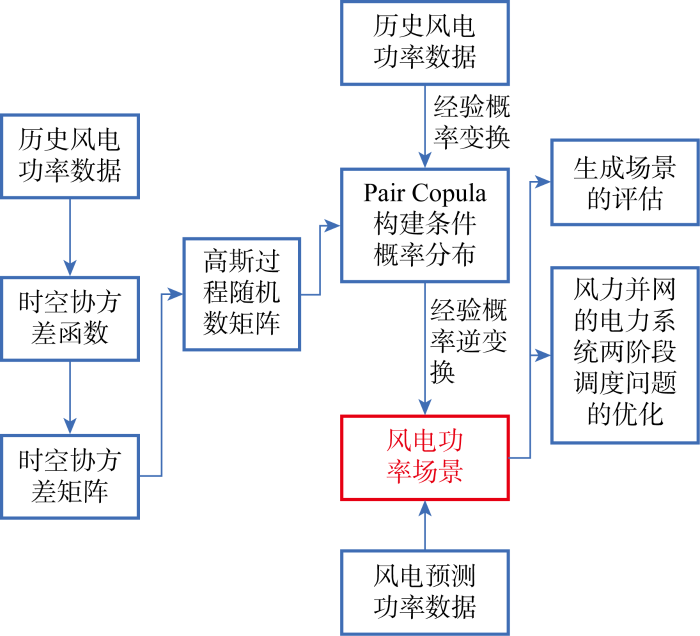
总体方法框架如图2 所示,首先介绍场景生成方法所需数学知识,然后具体介绍时空协方差函数构建方法即Pair Copula构建方法,最后给出场景生成具体步骤.
图2
图2
本文方法总体框架图
Fig.2
Overall framework of method in this paper
2.1 预备知识
2.1.1 时空协方差函数
设x (h 1 , u 1 ), x (h 2 , u 2 )为发生在时刻u 1 , u 2 和位置h 1 , h 2 的两个时空过程,其相关性可由时空协方差函数刻画.Gneiting[20 ] 提出不可分割的时空协方差函数反映时空过程的联系.时空协方差函数一般如下式所示:
(1) C (h ;u )= σ 2 ( a | u | 2 α + 1 ) τ - c ‖ h ‖ 2 γ ( a | u | 2 α + 1 ) β γ
式中:u , h 分别为时间间隔和空间距离;σ 2 为整体数据的方差;a , c 为时间和空间距离的尺度参数;α , γ 分别为时间协方差和空间协方差的平滑参数;β ∈[0,1]为时空协方差的关联,当β =0时,表示时间协方差和空间协方差分割;参数τ ≥β 表示对时间协方差做出调整.不可分割的时空协方差函数优势在于可以针对使用的数据集进行灵活的参数调整,从而提高描述时空过程相关性的准确性.
2.1.2 Kendall秩相关
Kendall秩[21 ] 涉及和谐对概念,设w , z 为两个长度为n 的观测序列,对于分别来自两个序列的两对观测值(wi , zi )和(wj , zj ),若(wi -zi )(wj -zj )≥0,则称这是一个和谐对,反之为非和谐对,Kendall秩相关系数的计算公式如下:
(2) ρ = n 1 - n 2 1 2 n ( n - 1 )
式中:n 1 ,n 2 分别为和谐对和非和谐对数量.Kendall秩相关系数反映了变量间的协变关系,在没有线性假设和数据非正态分布的情况下适用于刻画风电场功率时空相关性情景.而最常见的皮尔逊相关系数则通常应用于刻画线性相关的变量相关性.
2.1.3 Copula理论
在Copula理论中,Sklar定理[22 ] 解释了多元分布函数、Copula函数和边际分布函数之间的关系.假设一个d 维随机变量x =[x 1 x 2 … xd ]T 的边际累积分布函数(Cumulative Distribution Function, CDF)为F 1 , F 2 , …, Fd ,其联合累积分布函数为F ,那么若所有的边际函数都连续,则F 可以被一个特定的Copula函数C 定义:
(3) F (x )=C (F 1 (x 1 ), F 2 (x 2 ), …, Fd (xd ))
概率密度函数(Probability Density Function,PDF)表示为
(4) f (x )=c (F 1 (x 1 ), F 2 (x 2 ), …, Fd (xd )) ∏ i = 1 d i (xi )
式中:c (·)为Copula的概率密度函数;fi (·)为边际概率密度函数.
2.2 时空协方差函数的参数估计
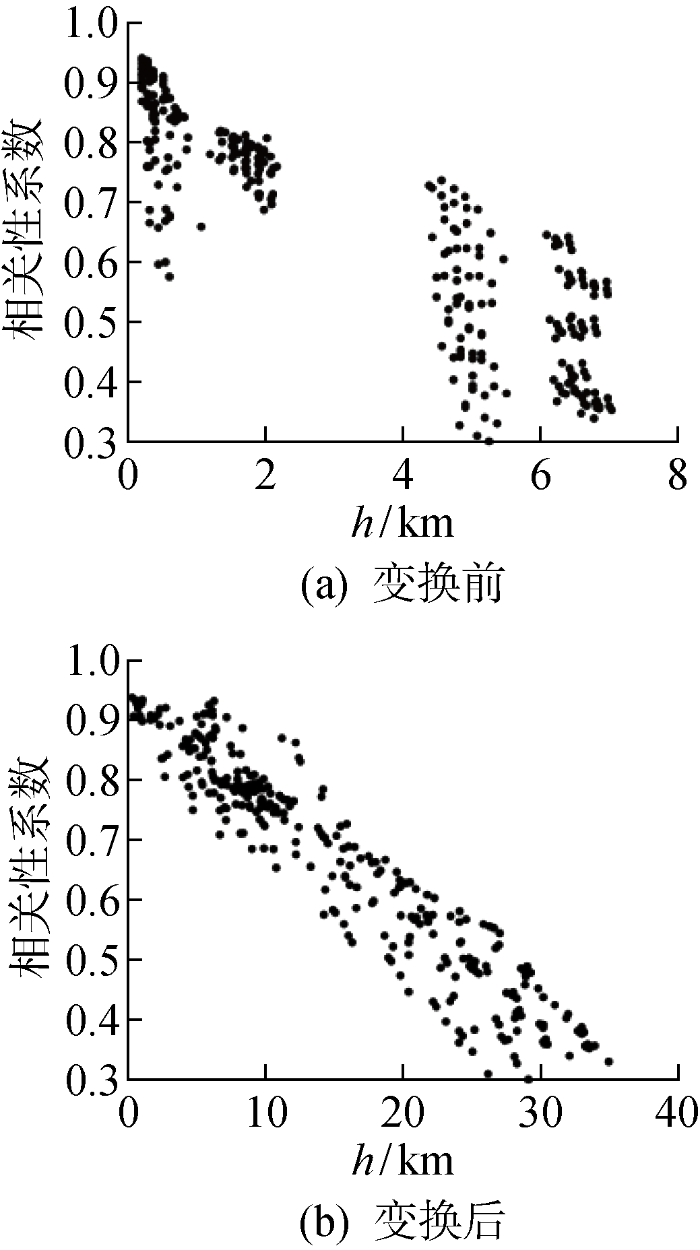
在计算时空协方差矩阵之前,需要对数据的时空平稳性进行检验,以保证时空协方差函数效果.首先通过通过增广Dickey-Fuller(Augmented Dickey-Fuller, ADF)检验验证时间序列平稳性.对于空间平稳性,在缺少空间平稳性假设时需要进行多维标度变换[23 -24 ] 使序列空间平稳.根据文献[23 ],本文用新坐标取代原始经纬度坐标表征风电场间空间相关性,在变换后的平面中,空间相关性仅通过距离表示,其空间相关性与原始平面中一致,且变换坐标后的数据具有时空平稳性假设,为后续时空协方差函数估计做好铺垫.坐标变换前后风电场间距离和相关系数的散点图如图3 所示,反映变换前空间距离(h )和空间相关性的负相关关系并不明显,但经过多维标度变换后空间距离和空间相关性呈现明显负相关关系,便于时空协方差函数更好地捕捉时空相关性.
图3
图3
坐标变换前后风电场间距离和相关性系数的散点图
Fig.3
Scatter plots of spatial distances between wind farms and correlation coefficients at different coordinates
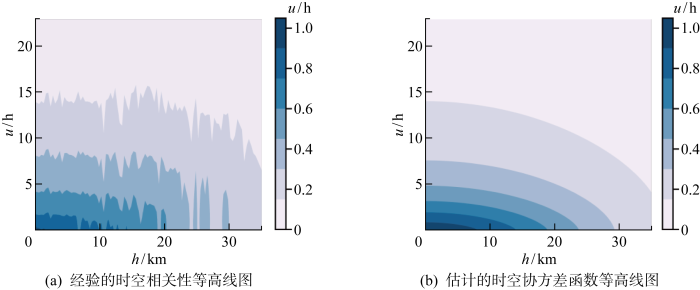
采用经验调优加局部搜索的方式求时空协方差函数参数.将25个风电场中每个风电场实际功率的时间序列数据记为p (j , t ),代表第j 个风电场第t 时的数据. 然后依次计算p (j , t ), p (j' , t' )(0≤t , t' ≤23 h, 1≤j , j' ≤25)的Kendall秩相关系数, 代表在空间距离为c o o r d j - c o o r d j ' 2 t -t' |处的时空协方差值,其中coor dj 为风电场j 的新坐标.最后使用插值法求得更多位置的Kendall秩相关系数,通过这些数据绘制经验的时空相关性图,如图4(a) 所示.
图4
图4
不同方法的等高线图
Fig.4
Contour plots of different methods
根据文献[20 ]参数设置,在协方差函数参数中,σ 2 , γ , τ 均取为1. 在进行ξ ={a , c , α , β }估计时,通过对比经验的时空相关性等高线图调整参数.在调整后的参数附近,对目标函数:
(5) m i n ξ ∑ h ∑ u 2
进行优化,使用网格搜索法对参数进行微调.最终求得时空协方差函数等高线图如图4(b) 所示.
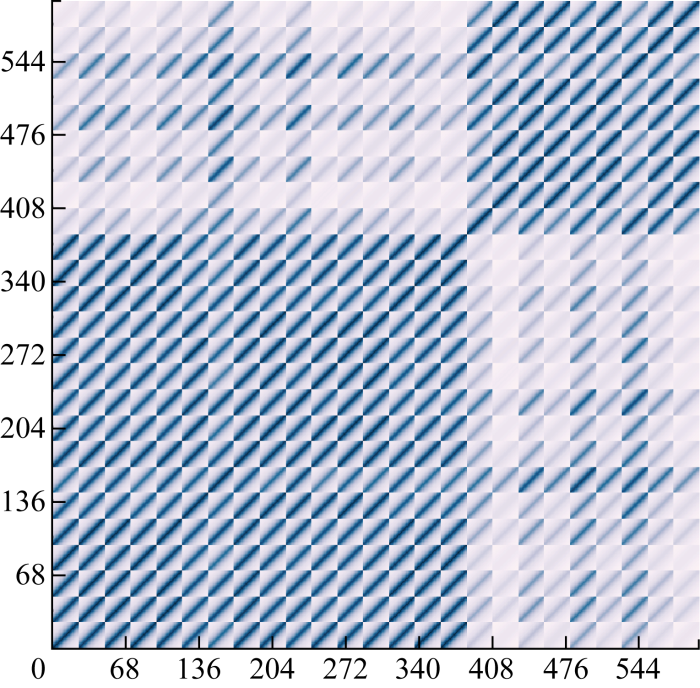
将不同时间间隔和空间距离代入协方差函数,可以得到表示25个风电场24 h实际功率的时空相关性协方差矩阵Σ ,矩阵维度为600×600,热力图如图5 所示,其中位于(24j 1 +t 1 , 24j 2 +t 2 )的小格代表j 1 风电场第t 1 小时的功率与j 2 风电场第t 2 小时的功率的协方差(0≤t 1 , t 2 ≤23 h, 1≤j 1 , j 2 ≤25). 当j 1 =j 2 时,热力图表示同一风电场的协方差矩阵,可以看出在同一风电场中,时间越接近则协方差越大,时间相关性越强;当j 1 ≠j 2 时,热力图显示不同风电场间的协方差,因为地理位置上25个风电场主要分成两个簇(见图1 ),所以协方差矩阵的热力图具有两个深色区块为前16个风电场和后9个风电场,在同一区块中的风电场距离接近,协方差较大,时空相关性较强.
图5
图5
协方差矩阵热力图
Fig.5
Heatmap of covariance matrix
2.3 基于Pair Copula模型联合概率分布估计
时空协方差函数捕捉时空过程相关性,但不能直接生成具体场景.风电功率具体场景的生成依赖于实际功率和预测功率之间的关系.条件的联合概率分布反映了已知功率预测值时实际功率取值的分布情况,因此快速准确估计功率预测值和实际值间的联合概率分布对后续的场景生成尤为重要.
根据Copula理论,利用Copula函数构建实际功率和预测功率联合概率分布.由于只有实际功率和预测功率两组数据,所以使用连接两个变量的Pair Copula函数来连接两者的分布最合适.常见的Pair Copula函数有Gaussian Copula、t -Copula以及Archimedean Copula族中的Frank Copula、Gumbel Copula、Clayton Copula等,该类Copula能够对包括非对称依赖性在内的复杂依赖性结构进行建模.
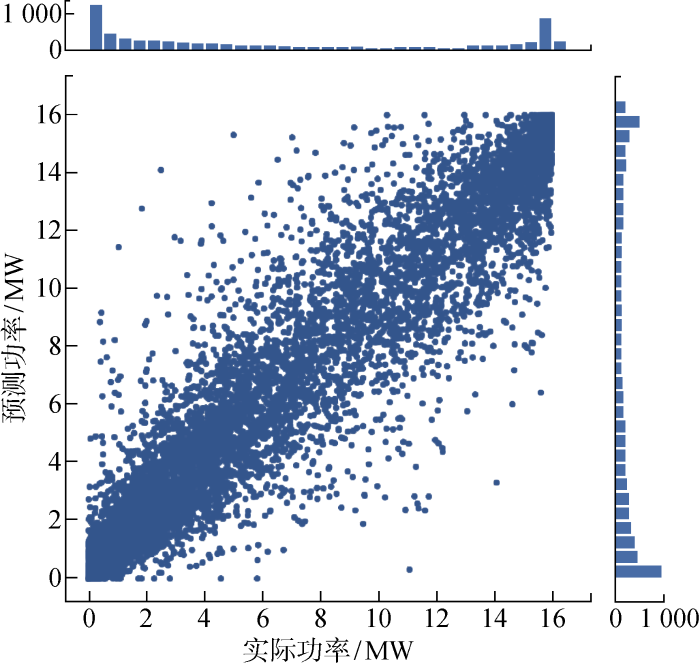
以68736号风电场2012年的实际功率数据和预测功率数据为例,其联合分布形式如图6 所示.可以看到功率的实际值和预测值在极值附近联合分布密集,其他区域分布相对稀疏,且大致对称,符合Frank Copula概率密度函数的分布特点,因此采用Frank Copula构建联合概率分布.
图6
图6
68736号风电场2012年风电实际功率和预测功率的散点图
Fig.6
Scatter plot of actual and predicted wind power of No. 68736 wind farm in 2012
设v 1 , v 2 为两个随机变量,θ 为待求参数,Frank Copula的函数表达式如下:
(6) c (v 1 , v 2 )= - θ ( e - θ - 1 ) e - θ ( v 1 + v 2 ) [ ( e - θ v 1 - 1 ) ( e - θ v 2 - 1 ) + e - θ - 1 ] 2
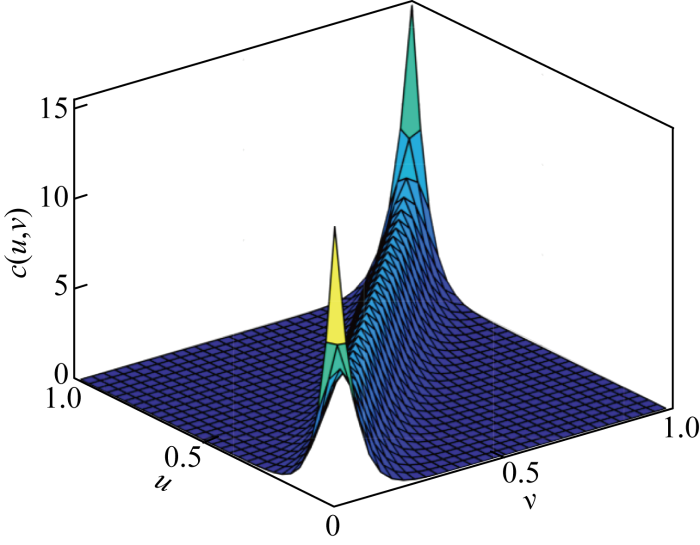
在具体计算过程中,需要先将数据转化为累计分布函数值.设p r 和p f 分别为某一风电场j 每小时的功率实际值和预测值,v 1 和v 2 为对应的经验累积分布函数(Empirical Cumulative Distribution Function, ECDF)值,则v 1 =F ECD (p r ),v 2 =F ECD (p f ),联合概率密度函数fj =cj (v 1 , v 2 ),累积概率分布函数的边际概率为均匀分布,概率密度为1.Frank Copula只含一个参数,在使用极大似然估计时较为方便.图7 为θ =23.055时,68736号风电场数据估计的Frank Copula概率密度函数.
图7
图7
68736号风电场数据的Frank Copula概率密度函数
Fig.7
Frank Copula probability density function plot of the data of No. 68736 wind farm
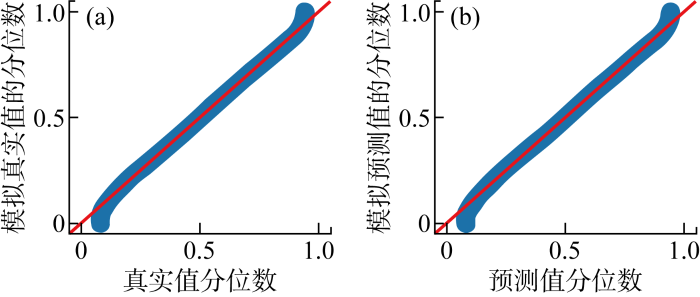
为验证Frank Copula的准确性,选取同为单参数的Gumbel Copula和Clayton Copula进行对比,指标为相对于经验Copula的平方距离(d 2 ),如表1 所示.可知Frank Copula与经验Copula距离最小,准确性最高.同时由该Copula函数随机抽样生成真实值与预测值联合分布模拟值,得到对应分位数-分位数图如图8 所示,可知模拟值与原始值的分布情况基本一致,证明了Frank Copula的准确性.
图8
图8
真实值和预测值与其模拟值的分位数-分位数图
Fig.8
Quantile-quantile plots of measured values and predicted values with their simulated data
2.4 场景生成步骤
对于典型多维高斯过程,可以使用随机生成多维高斯分布随机数模拟.通常,风电功率的分布是非正态的、风电功率的相关性也是非线性的[25 ] ,但可以通过基于时空协方差函数的高斯过程生成风电功率的条件概率值,最后通过逆变换求得具体场景值,具体步骤如下:
(1) 生成多维高斯分布矩阵.设生成的场景数为N s ,随机地生成均值为0、协方差矩阵为Σ 的多维高斯分布随机数矩阵M rand .因为考虑Nj 个风电场未来24 h的场景,则矩阵维度为24Nj ×N s .再求随机数矩阵的每个元素M 24 j + t , n r a n d F 24 j + t , n 0 Φ (M 24 j + t , n r a n d ) ,其中j =1, 2, …, Nj ,t =1, 2, …, 24 h,n =1, 2, …, Ns . 此处的累积概率分布值等于风电功率条件分布的累积概率分布值F 1 ,即F 24 j + t , n 1 F 24 j + t , n 0 .
(2) 通过经验分布的条件概率逆变换得到具体场景值.设F 24 j + t , n 1 j 个风电场第t 时第n 个场景的功率条件概率累积分布. 设场景生成日期的第t 时的功率预测值为V 2 ,由经验累积概率分布得到V 2 对应的分位数v* =FECD (V ),然后利用已求出的cj (v 1 , v 2 )得到条件概率密度函数为
(7) f V 1 ∣ V 2 1 ∣v2 )= f ( v 1 , v 2 = v 2 * ) f V ( v 2 = v 2 * ) c j ( v 1 , v 2 * ) 1 j (v1 , v 2 *
然后求积分I =∫ 0 v 1 * f V 1 ∣ V 2 ( v 1 ∣v 2 )dv 1 的积分上限v 1 * I =F 24 j + t , n 1 v 1 * . 最后通过经验概率逆变换求得实际场景的功率为F E C D - 1 ( u* ),代表第j 个风电场当天第t 时的功率场景.
(3) 对于j =1, 2, …, Nj ,t =1, 2, …, 24 h,n =1, 2, …, Ns ,重复步骤(2),得到每个风电场24 h的所有场景.将一个风电场每小时的对应场景值组合,得到每日的一个场景,不同风电场的场景值累加得到累积场景X .
3 场景评估方法与算例结果对比分析
首先介绍几种常用的场景评估指标,然后利用数据集提供的历史数据生成7个风电场90 d的场景,最后评估与分析不同场景生成方法所生成的场景.
3.1 场景评估方法介绍
3.1.1 能量得分
能量得分(Energy Score, ES)是针对多变量情况设计的连续分级概率评分(Continuous Ranked Probability Score, CRPS)[26 ] 的延伸,提供了一种评估确定性预测的直接方法,反映了生成场景相对于真实场景平均偏离程度以及生成场景的波动.在生成场景自身波动一定时,越小的能量得分代表生成场景相对于真实场景的差异越小,精度越高.假设真实值为X real ,第k 个场景值为X ( k ) ,X t ( k ) k 个场景中第t 时的风电功率预测值(k =1, 2, …, Ns , 0≤t ≤23 h),能量得分的表达式为
(8) SE = 1 N s ∑ j = 1 N s X ( j ) - X r e a l 1 2 N s 2 ∑ i = 1 N s ∑ j = 1 N s X ( i ) - X ( j )
3.1.2 变异函数得分
变异函数得分(Variogram Scoring, VS)既反映生成场景相对于真实值的精度,又可以用于展示不同场景生成方法对时空相关性的捕捉能力[27 ] ,变异函数得分越小表示该方法捕捉时空相关性能力越强.p 阶VS计算真实值与生成场景值的变差函数之间的差异定义为
(9) $\begin{aligned} S_{\mathrm{V}}= \sum_{i=1}^{24} \sum_{j=1}^{24} w_{i j}\left(\left|X_{\text {real }_{i}}-X_{\text {real }_{j}}\right|^{p}-\right. \left.\frac{1}{N_{\mathrm{s}}} \sum_{k=1}^{N_{\mathrm{s}}}\left|X_{i}^{(k)}-X_{j}^{(k)}\right|^{p}\right)^{2} \end{aligned}$
3.1.3 覆盖概率
覆盖概率(Coverage Probability, CP)表示生成的场景值包含真实值的概率,反映了场景值能否捕捉极端情况的发生的能力,表达式如下:
(10) Pc = 1 24 ∑ t = 1 24 1 X r e a l t ∈ [ X _ t , X - t ]
式中:X _ t X - t t 时的最小值和最大值. 如果真实值在场景值的区间内,则1 X r e a l t ∈ [ X _ t , X - t ]
3.1.4 场景区间宽度
场景区间宽度(b SI )反映场景值相对于真实值的集中程度,可以用于评估场景生成方法捕捉不同风电场间的空间相关性的能力.场景区间宽度由平均区间宽度(b AI )和带系数λ 的平均区间偏差(b AW )组成,b AI 表示了场景值高估或低估真实值的误差,在经济调度问题中,越低的b AI 意味着功率预留量越低,为应对电力系统运行中因为预测误差而分配的向上和向下功率储备所造成的浪费,b AI 越小越好,相关表达式为
(11) b A I = 1 24 ∑ t = 1 24 X - t - X _ t b A W t = X r e a l t - X - t , X r e a l t > X - t 0 , X _ t ≤ X r e a l t ≤ X - t X _ t - X r e a l t , X r e a l t < X _ t b S I = b A I + λ 1 24 ∑ t = 1 24 b A W t
3.2 场景生成结果与对比分析
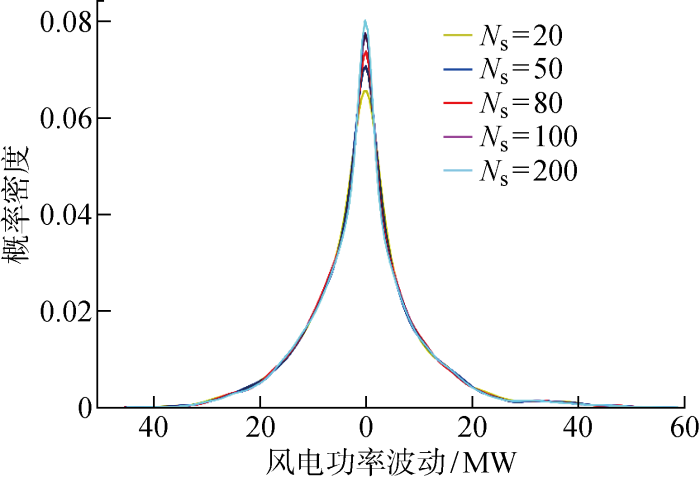
选取25个风电场中的7个风电场进行研究,编号分别为68736、70232、70504、70773、61763、61765和62000.这7个风电场具有明显的空间差异,可以检验本文方法捕捉空间相关性的能力.对2013年1月1日至3月31日共90 d的场景进行生成,每日每个风电场生成N s 个场景,并将7个风电场每日每小时对应的场景累加,得到累积场景X s u m a ( a =1, 2, …, 90),X s u m a Ns ×24,并在计算场景评估指标时取各指标在所有时间的均值.生成场景数量值得探讨,文献[16 ]使用风电功率波动的分布情况选取生成场景的数量,认为生成200个场景足以反映生成场景对风电功率波动情况的捕捉能力,其中风电功率波动X t r a m p X t r a m p X t ( k ) - X t - 1 ( k ) . 本文分别取N s =20, 50, 80, 100, 200进行场景生成,对场景波动的分布用核密度估计,得到不同场景数量下风电功率波动情况的分布,
如图9 所示.场景数量为100时波动的分布与场景数量为200时波动的分布已足够接近.利用Kolmogorov-Smirnov(KS)检验来判断两组数据在95%的置信度下是否同分布,得到p =0.99,认定两组数据同分布,因此本文取N s =100.
图9
图9
不同场景生成数量下的风电功率波动情况的核密度估计
Fig.9
Kernel density estimation of wind power fluctuations with different scenario numbers
同时采取其他3个场景生成方法作为基准进行对比,本文提出的方法记作M1,文献[15 ]提出的Vine-Copula以及加权核密度估计拟合联合分布记作M2,文献[16 ]提出的根据预测功率分别构建条件概率分布记作M3,文献[17 ]提出的协方差函数和高斯混合模型估计联合概率分布记作M4,但未根据功率波动情况进行聚类与场景削减.使用Python语言编程,计算在配置为Intel(R) Core(TM) 2.60 GHz CPU和16 GB内存的个人计算机上进行.M1~M4生成未来24 h每小时100个场景的平均用时分别为74、65、34、52 s.由于是对未来1 d的场景进行预测,1 min左右的场景生成时间相对于实际24 h调度周期在可接受范围,4种场景生成方法均具备时间效率,所以不在计算时间上比较优劣.
各风电场的场景评估指标计算值如表2 所示,其中加粗数值为各方法中的最优指标.可知,本方法所求得S E =25.480,可理解为90 d内每日所生成的100个场景与真实值修正后的平均欧氏距离平均值,相当于每小时的距离为( 25.480 M W ) 2 / 24 S E 指标上分别减少了5.94%、5.35%、9.97%,在S V 指标上分别减少了5.00%、6.45%、8.62%,说明本方法生成的场景精度较高、捕捉时空相关性较好.在P c 指标上本方法位于第三,但4个方法较为接近,说明均能较好地覆盖到极端情景.相较于其他方法,本方法在b AI 指标上分别降低了17.22%、34.13%、33.72%,在b SI 指标上分别降低了17.18%、34.08%,33.85%,说明本方法在捕捉空间相关性上的优越性.M3方法的b SI 最大,这是因为其使用的指数型协方差函数没有考虑空间上的变化.
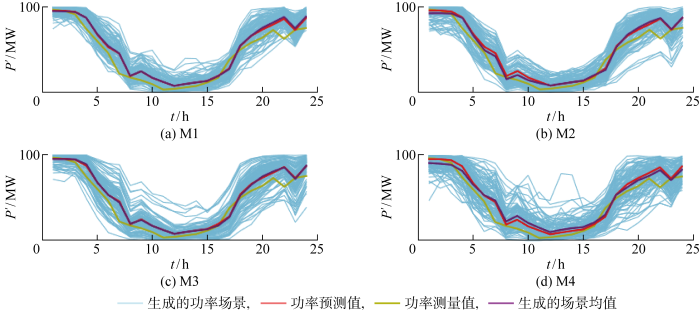
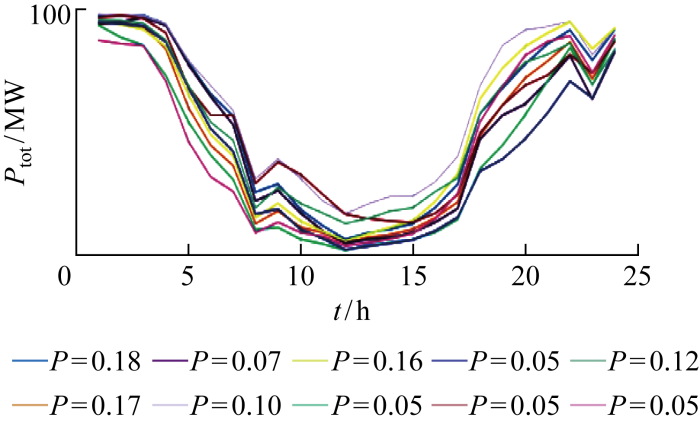
为直观展示本文方法的效果,随机选取某日(2013年1月21日)生成的场景进行绘图.如图10 所示,本方法生成的场景能够准确捕捉到实际功率(P ')的变动趋势,距离真实值的分布相较于其他方法更紧密.在生成的每日100个场景的基础上,本文通过场景削减方法提取出10个典型的场景,其中聚类数量可以选择.具体方法为通过K -means聚类算法,将100个场景聚集成10个类别,每个类别取类内均值作为一个典型场景,每个类别的概率等于该类别所包含的场景数量的1/100.2013年1月21日的10个典型场景如图11 所示,其中P 为每个典型场景的概率,P tot 为风电场总功率.
图10
图10
2013年1月21日4种方法生成的风电场总功率场景
Fig.10
Total wind power scenarios generated by four methods on January 21, 2013
图11
图11
2013年1月21日10个典型的风电场总功率场景及其概率
Fig.11
10 typical total wind power scenarios and their probabilities on January 21, 2013
4 场景生成的应用
介绍生成的风能场景在现实的工业背景中的应用方法,包括电力系统经济调度中的一种两阶段优化模型,构建相关的机组组合混合整数规划模型,求解以本方法生成的场景在某日调度中的优化结果并进行分析.以4种方法生成的场景分别作为输入,对90 d调度计划的平均成本进行计算与对比.
4.1 两阶段联合调度问题介绍
电力系统经济调度指在满足安全和电能质量的前提下,合理利用能源和设备,以最低的发电成本或燃料费用保证对用户可靠供电的一种调度方法.传统的电力系统依赖燃煤或燃气等发电单位来平衡供给和需求.然而,当风电使用水平提高时,由于风电的错峰性和不可调节性,所以系统需要更多备用容量或灵活资源调度来应对不确定性.从发电方面来看,灵活发电技术[28 ] 、区域储备优化[29 -30 ] 和储能[31 ] 是常见选择.本文主要考虑灵活发电技术中对可调控机组的调度问题,在该问题中,系统运营商协调调度常规燃煤或燃气机组以应对风电波动.通常以整体运营成本最小为目标,以可调控的燃煤或燃气机组等发电机组每小时的出力大小、机组的启停状态、风电削减量以及缺负荷量等可以人为调控的参数为决策变量,以机组运行、供需平衡等限制为约束进行优化求解.主要的决策变量为发电机组的出力情况,且决策变量既包含发电单位的启停状态这类整数变量又包含出力大小这类连续型变量,因此此类问题被称作电力系统的机组组合问题,需通过建立混合整数规划模型求解.
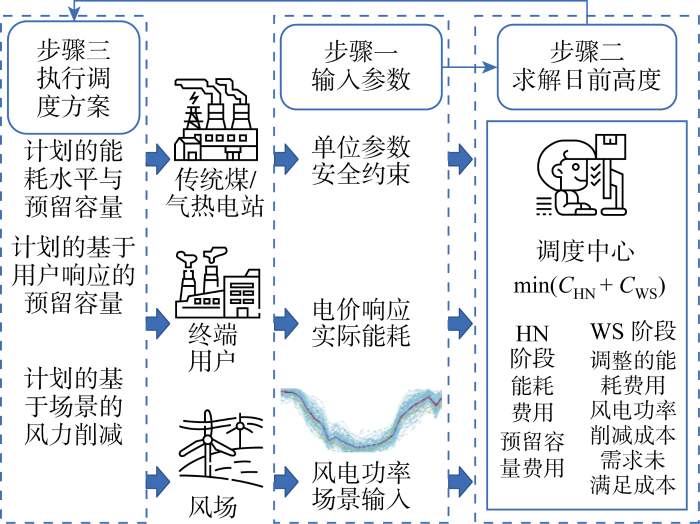
一种常见的联合调度的总体框架如图12 所示.图中调度考虑了用户响应,即通过阶梯电价策略调控用户用电需求,产生虚拟发电效果.出于问题简化的考虑忽视了用户响应,考虑调度中心对传统热电站的实时出力和预留功率调度,以及不同风电场景下的风电削减和非自愿用户用电削减问题,这种联合调度可被分为两阶段优化:第一阶段为日前调度,调度员根据风电功率和负载的预测值确定备用容量和发电机组启停状态以及大致的出力,其中备用容量指未来1 d实际场景的波动在每一时段预留的发电功率容量;第二阶段对应于未来1 d日内操作期间的部署,即根据实际用电量和实际风电场发电量实时调整热电站的出力.在日前调度中,调度员根据当前的预测值做出第一阶段决策,因此将其定义为此时此地(Here and Now, HN)阶段.第二阶段当风电实际出力、实际负荷等不确定的参数给出时,调度员在原有的调度计划基础上做出必要调整,因此称其为等待和观望(Wait and See, WS)阶段.
图12
图12
电力系统两阶段联合调度框架图
Fig.12
Framework of two-stage joint dispatching of power system
在一个典型的电力系统联合调度问题中,优化目标为最小化调度过程的两个阶段的总成本:
Ctotal =min(CHN +CWS )
其中:C HN 为第一阶段的成本;C WS 为第二阶段的成本,且
(12) CHN =Cfuel +Csetup +CRUD
(13) CWS = ∑ n = 1 N s n (C A F n C L S n C W C n
式中:C fuel 为能耗成本;C setup 为启动成本;C RUD 为预留容量成本;ρn 为每个场景出现的概率;C A F n C L S n C W C n 32 ].
4.2 两阶段联合调度问题求解与分析
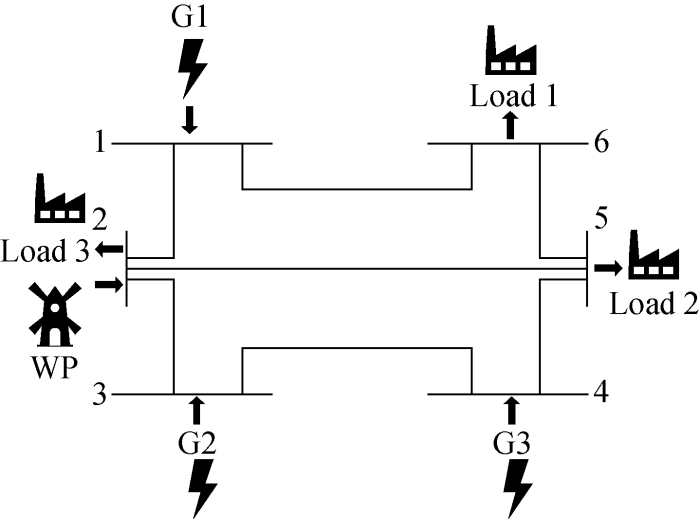
本系统将IEEE 6总线系统的一个热电机组替换为风电场,如图13 所示.其中G1、G2、G3代表3个可调控的热电机组,WP代表风电场,Load 1、Load 2、Load 3代表负载.3个热电机组的最大有功功率分别设置为250、250、200 MW,负载每小时的总功率在300~600 MW区间波动,在每个场景中,负载功率仅发生轻微波动.因为生成的场景能够合理反映风电的实际波动情况,所以将生成的大量场景作为第二日的实际风电情况输入至模型,以验证模型的可行性和可靠性.首先对单日优化调度进行计算与分析,然后对比4种场景生成方法生成的场景输入90 d调度中的求解结果.使用Gurobi 9.1.1对以上混合整数规划问题进行求解,精度设为0.1%.
图13
图13
调整后的IEEE 6总线系统示意图
Fig.13
Schematic diagram of adjusted IEEE 6-bus system
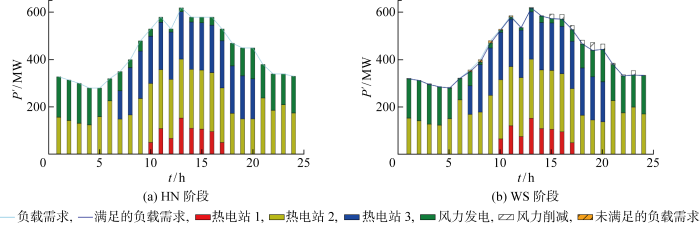
风电的一大特性是错峰性,风电功率的波峰通常出现在夜间即负荷较少的时刻,选用2013年1月21日这一典型错峰出现的日期生成场景.取每个场景出现的概率ρn =1/Ns ,带入相关参数进行求解.模型总求解时间为3.42 s,证明了模型的潜在可行性.第一阶段的求解结果如图14(a) 所示,第二阶段的求解结果随机抽取一个场景作为展示如图14(b) 所示.由图14(a) 可知,在第一阶段中需求较小时,仅需要开启一个热电机组配合风电进行供给;在需求较大时,需开启多台机组.从4号场景的WS阶段调度方案可以看出,此场景在7~11 h内,风能比预期较少,已开启的两个机组已经满功率运行,因此出现需求未满足的情况;15~20 h内此场景下风能较多,出现了风力削减的情况.
图14
图14
电力系统两阶段调度求解结果
Fig.14
Two-stage scheduling solution results of power system
4.3 不同场景生成方法的应用与对比
参照4.2节的设置,分别将4种场景生成方法在2013年1月1日至3月31日90 d内生成的场景作为两阶段调度计划的输入进行求解,并计算各项成本的均值,结果如表3 所示.
可知,燃料成本和机组启停成本基本一致,原因为其仅和两阶段联合调度的第一阶段有关;但在燃料调整成本、风力削减成本、需求未满足成本等项目上,本文方法具有明显优势,原因为本文预测场景值与真实值更接近,场景的分布更紧凑,第一阶段的调度策略则更精准有效,减少了第二阶段的调整与浪费以及由预留容量造成的损失.就总成本而言,本方法相较于方法M2~M4分别减少了3.61%、3.16%和5.40%,体现了解决大规模的风电并网的电力系统调度问题的经济性.
5 结论
针对风电功率场景生成现存的时空相关性刻画不全面、联合条件概率分布描述不准确等问题,提出一种基于时空协方差函数、Pair Copula以及高斯过程概率逆变换的场景生成方法,通过在Wind Toolkit数据集上的应用以及在不同指标上的结果对比,得出以下结论:
(1) 时空协方差函数能够同时对多个风电场功率的时空相关性进行有效建模,具有运用方便灵活的特点.
(2) 在Pair Copula中,单参数的Frank Copula能够较准确地建立实际功率和预测功率之间的条件概率函数.
(3) 本方法生成的场景准确把握了实际场景的变化趋势,相较于其他方法,在多项场景评估指标上均有较好表现,表明本方法能准确抓住多个风电场功率的时空相关性,具有捕捉极端场景的能力,并能通过聚类缩减为少数几个典型场景,在风能场景预测问题上具有应用价值.
风能场景的生成最终需要应用于电力系统中,作为经济调度、机组组合等决策优化问题的输入,生成场景有助于电力系统操作员为未来的调度方案做出决策.建立了未来24 h的两阶段电力调度的混合整数规划模型.通过对比实验,验证了方法的成本优势,并证明了本文场景生成方法在风电并网的实际问题中具有潜在应用价值.出于计算方便考虑,该模型对部分情况进行简化,未来将考虑更符合实际的电力调度模型,考虑多种新能源的场景生成方法,并在具有更复杂机制的经济调度模型中应用.
参考文献
View Option
[1]
GWEC . GWEC global wind report 2022
[EB/OL]. (2022-04-04 )[2022-04-04 ]. https://gwec.net/global-wind-report-2022.
URL
[本文引用: 1]
[2]
CHEN P Y PEDERSEN T BAK-JENSEN B et al ARIMA-based time series model of stochastic wind power generation
[J]. IEEE Transactions on Power Systems 2010 , 25 (2 ): 667 -676 .
DOI:10.1109/TPWRS.2009.2033277
URL
[本文引用: 1]
[3]
DÍAZ G GÓMEZ-ALEIXANDRE J COTO J Wind power scenario generation through state-space specifications for uncertainty analysis of wind power plants
[J]. Applied Energy 2016 , 162 : 21 -30 .
DOI:10.1016/j.apenergy.2015.10.052
URL
[本文引用: 1]
[4]
董骁翀 , 孙英云 , 蒲天骄 . 基于条件生成对抗网络的可再生能源日前场景生成方法
[J]. 中国电机工程学报 2020 , 40 (17 ): 5527 -5536 .
[本文引用: 1]
DONG Xiaochong SUN Yingyun PU Tianjiao Day-ahead scenario generation of renewable energy based on conditional GAN
[J]. Proceedings of the CSEE 2020 , 40 (17 ): 5527 -5536 .
[本文引用: 1]
[5]
肖白 , 于龙泽 , 刘洪波 , 等 . 基于生成虚拟净负荷的多能源电力系统日前优化调度
[J]. 中国电机工程学报 2021 , 41 (21 ): 7237 -7249 .
[本文引用: 1]
XIAO Bai YU Longze LIU Hongbo et al Day ahead optimal dispatch of multi-energy power system based on generating virtual net load
[J]. Proceedings of the CSEE 2021 , 41 (21 ): 7237 -7249 .
[本文引用: 1]
[6]
CHEN Y Z WANG Y S KIRSCHEN D et al Model-free renewable scenario generation using generative adversarial networks
[C]// 2019 IEEE Power & Energy Society General Meeting USA : IEEE , 2019 : 1 .
[本文引用: 1]
[7]
ZHANG Y F AI Q XIAO F et al Typical wind power scenario generation for multiple wind farms using conditional improved Wasserstein generative adversarial network
[J]. International Journal of Electrical Power & Energy Systems 2020 , 114 : 105388 .
DOI:10.1016/j.ijepes.2019.105388
URL
[本文引用: 1]
[8]
PINSON P MADSEN H NIELSEN H A et al From probabilistic forecasts to statistical scenarios of short-term wind power production
[J]. Wind Energy 2009 , 12 (1 ): 51 -62 .
DOI:10.1002/we.v12:1
URL
[本文引用: 1]
[9]
唐锦 , 张书怡 , 吴秋伟 , 等 . 基于Copula函数与等概率逆变换的风电出力场景生成方法
[J]. 电力工程技术 2021 , 40 (6 ): 86 -94 .
[本文引用: 1]
TANG Jin ZHANG Shuyi WU Qiuwei et al Wind power output scenario generation method based on Copula function and equal probability inverse transformation
[J]. Electric Power Engineering Technology 2021 , 40 (6 ): 86 -94 .
[本文引用: 1]
[10]
CAI D F SHI D Y CHEN J F Probabilistic load flow computation with polynomial normal transformation and Latin hypercube sampling
[J]. IET Generation, Transmission & Distribution 2013 , 7 (5 ): 474 -482 .
DOI:10.1049/gtd2.v7.5
URL
[本文引用: 1]
[12]
赵鉴 , 袁渤巽 , 于浩 , 等 . 基于风光不确定性和相关性的场景生成
[J]. 能源与节能 2021 (8 ): 8 -12 .
[本文引用: 1]
ZHAO Jian YUAN Boxun YU Hao et al Scene generation based on uncertainty and correlation of wind and photovoltaic power
[J]. Energy and Energy Conservation 2021 (8 ): 8 -12 .
[本文引用: 1]
[13]
LI J H ZHU D L Combination of moment-matching, Cholesky and clustering methods to approximate discrete probability distribution of multiple wind farms
[J]. IET Renewable Power Generation 2016 , 10 (9 ): 1450 -1458 .
DOI:10.1049/rpg2.v10.9
URL
[本文引用: 1]
[14]
LI B H SEDZRO K FANG X et al A clustering-based scenario generation framework for power market simulation with wind integration
[J]. Journal of Renewable and Sustainable Energy 2020 , 12 (3 ): 036301 .
DOI:10.1063/5.0006480
URL
[本文引用: 1]
[15]
WANG Z WANG W S LIU C et al Forecasted scenarios of regional wind farms based on regular vine copulas
[J]. Journal of Modern Power Systems and Clean Energy 2019 , 8 (1 ): 77 -85 .
DOI:10.35833/MPCE.2017.000570
URL
[本文引用: 3]
[16]
MA X Y SUN Y Z FANG H L Scenario generation of wind power based on statistical uncertainty and variability
[J]. IEEE Transactions on Sustainable Energy 2013 , 4 (4 ): 894 -904 .
DOI:10.1109/TSTE.2013.2256807
URL
[本文引用: 3]
[17]
TAN J WU Q W ZHANG M L et al Wind power scenario generation with non-separable spatio-temporal covariance function and fluctuation-based clustering
[J]. International Journal of Electrical Power & Energy Systems 2021 , 130 : 106955 .
DOI:10.1016/j.ijepes.2021.106955
URL
[本文引用: 2]
[21]
ABDI H The Kendall rank correlation coefficient
[C]// SALKIND N J. Encyclopedia of Measurement and Statistics USA : Sage , 2006 : 508 -510 .
[本文引用: 1]
[22]
SKLAR A Random variables, joint distribution functions, and copulas
[J]. Kybernetika 1973 , 9 (6 ): 449 -460 .
[本文引用: 1]
[24]
KRUSKAL J B WISH M Multidimensional scaling [M]. London : Sage , 1978 .
[本文引用: 1]
[27]
SCHEUERER M HAMILL T M Variogram-based proper scoring rules for probabilistic forecasts of multivariate quantities
[J]. Monthly Weather Review 2015 , 143 (4 ): 1321 -1334 .
DOI:10.1175/MWR-D-14-00269.1
URL
[本文引用: 1]
Proper scoring rules provide a theoretically principled framework for the quantitative assessment of the predictive performance of probabilistic forecasts. While a wide selection of such scoring rules for univariate quantities exists, there are only few scoring rules for multivariate quantities, and many of them require that forecasts are given in the form of a probability density function. The energy score, a multivariate generalization of the continuous ranked probability score, is the only commonly used score that is applicable in the important case of ensemble forecasts, where the multivariate predictive distribution is represented by a finite sample. Unfortunately, its ability to detect incorrectly specified correlations between the components of the multivariate quantity is somewhat limited. In this paper the authors present an alternative class of proper scoring rules based on the geostatistical concept of variograms. The sensitivity of these variogram-based scoring rules to incorrectly predicted means, variances, and correlations is studied in a number of examples with simulated observations and forecasts; they are shown to be distinctly more discriminative with respect to the correlation structure. This conclusion is confirmed in a case study with postprocessed wind speed forecasts at five wind park locations in Colorado.
[28]
HOLTTINEN H TUOHY A MILLIGAN M et al The flexibility workout: Managing variable resources and assessing the need for power system modification
[J]. IEEE Power and Energy Magazine 2013 , 11 (6 ): 53 -62 .
DOI:10.1109/MPE.2013.2278000
URL
[本文引用: 1]
[29]
江婷 , 邓晖 , 陆承宇 , 等 . 电能量和旋转备用市场下电-热综合能源系统低碳优化运行
[J]. 上海交通大学学报 2021 , 55 (12 ): 1650 -1662 .
[本文引用: 1]
JIANG Ting DENG Hui LU Chengyu et al Low-carbon optimal operation of an integrated electricity-heat energy system in electric energy and spinning reserve market
[J]. Journal of Shanghai Jiao Tong University 2021 , 55 (12 ): 1650 -1662 .
[本文引用: 1]
[31]
NASROLAHPOUR E KAZEMPOUR J ZAREIPOUR H et al A bilevel model for participation of a storage system in energy and reserve markets
[J]. IEEE Transactions on Sustainable Energy 2018 , 9 (2 ): 582 -598 .
DOI:10.1109/TSTE.2017.2749434
URL
[本文引用: 1]
[32]
ZHANG M L AI X M FANG J K et al A systematic approach for the joint dispatch of energy and reserve incorporating demand response
[J]. Applied Energy 2018 , 230 : 1279 -1291 .
DOI:10.1016/j.apenergy.2018.09.044
URL
[本文引用: 1]
GWEC global wind report 2022
1
... 为实现碳达峰、碳中和的目标,满足日益增长的能源需求,可再生能源已被广泛应用于能源系统和市场.风力发电(简称风电)是一种在世界范围内储备丰富的可再生能源,已成为许多地区越来越重要的发电来源.截至2021年底,全球风电累计装机容量达到840 GW,并且仍处于快速上升阶段[1 ] .对风力或风电功率时间序列的点和概率性预测是风电预测系统的重要组成部分.然而,对于经济调度这类随机优化问题,点和概率性预测并不能提供充分参考.近年来,场景生成法已成为风电预测的一个新兴研究领域.场景生成指通过构建数学模型,对未来一段时间内风电场的风速或功率做出预测,生成多个符合风电场时间序列和时空特征的场景.生成场景作为经济调度、机组组合等优化决策问题的输入,对合理地求解调度方案、进行电力系统运营相关的决策具有重要意义.在风能场景预测中,一个场景通常指风电场在一个时间段内的风能功率时间序列. ...
ARIMA-based time series model of stochastic wind power generation
1
2010
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
Wind power scenario generation through state-space specifications for uncertainty analysis of wind power plants
1
2016
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
基于条件生成对抗网络的可再生能源日前场景生成方法
1
2020
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
基于条件生成对抗网络的可再生能源日前场景生成方法
1
2020
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
基于生成虚拟净负荷的多能源电力系统日前优化调度
1
2021
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
基于生成虚拟净负荷的多能源电力系统日前优化调度
1
2021
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
Model-free renewable scenario generation using generative adversarial networks
1
2019
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
Typical wind power scenario generation for multiple wind farms using conditional improved Wasserstein generative adversarial network
1
2020
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
From probabilistic forecasts to statistical scenarios of short-term wind power production
1
2009
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
基于Copula函数与等概率逆变换的风电出力场景生成方法
1
2021
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
基于Copula函数与等概率逆变换的风电出力场景生成方法
1
2021
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
Probabilistic load flow computation with polynomial normal transformation and Latin hypercube sampling
1
2013
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
MCMC for wind power simulation
1
2008
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
基于风光不确定性和相关性的场景生成
1
2021
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
基于风光不确定性和相关性的场景生成
1
2021
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
Combination of moment-matching, Cholesky and clustering methods to approximate discrete probability distribution of multiple wind farms
1
2016
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
A clustering-based scenario generation framework for power market simulation with wind integration
1
2020
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
Forecasted scenarios of regional wind farms based on regular vine copulas
3
2019
... 总体而言,场景生成方法包含预测、抽样以及优化方法等.预测方法中常用的预测模型如自回归和移动平均(Auto Regressive and Moving Average, ARMA)[2 -3 ] 是用于刻画序列线性相关性的参数化工具,在预测单一风电场时往往具有较好效果,但难以刻画多个地点间的非线性关系;另一预测方法是机器学习,其包含的神经网络模型如生成对抗网络(Generative Adversarial Network, GAN)[4 ⇓ -6 ] 和Wasserstein 生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[7 ] 等方法无需考虑原始数据分布的统计假设,理论上数据样本越多,生成场景的质量越高,但对于训练样本的规模和质量依赖较大.抽样方法中Copula建模[8 ⇓ -10 ] 、拉丁超立方抽样[11 ] 、蒙特卡洛马尔可夫链抽样[12 ] 较为常见,其中Copula是一种普遍使用的概率分布建模方法,可对单一风电场的时间相关性、对多个风电场的空间相关性进行建模,也可构建风电和其他可再生能源之间的关系[13 ] ,但受构建的概率密度是否可逆、维度灾难等问题影响,此方法计算负担大.优化抽样方法是场景生成的延伸,它通过矩匹配[14 ] 或距离匹配[15 ] 来削减场景,应用于场景生成后的进一步优化. ...
... 现阶段,大规模风力发电源于广阔区域内多个风电场,需要对多个风电场总功率场景做出预测,因此把握风电场之间的空间相关性和风电场内的时间相关性非常重要;同时,具体的场景生成依赖于功率预测值和真实值之间的联合分布,因此准确构建预测值和真实值的条件联合分布是另一重点.当前主流场景生成方法对这两个重点有不同处理方式.Wang等[15 ] 利用核密度估计(Kernel Density Estimation, KDE)法建立功率真实值和预测值间的条件概率函数,并使用R-vine Copula构建风电场间的空间相关性,最后通过条件概率逆变换来得到生成场景.但在R-vine Copula构建过程中,需要依次估计不同风电场间条件概率分布的Copula函数,受风电场数量影响,计算过程繁琐复杂,且只考虑了风电场间的空间相关性,忽视了风电场内时间相关性对建模的影响.Ma等[16 ] 将风能预测值按大小分层,根据不同区间预测功率对应的实际功率构建条件概率分布,并使用指数型协方差函数表示风能时间相关性,但指数协方差函数只考虑了时间相关性,不能反映风电场的空间相关性,只适用于单一或少数风电场.Tan等[17 ] 使用高斯混合模型估计功率真实值和预测值间的条件联合概率分布函数,但对数据分布的要求是混合高斯分布,对预测值和真实值的联合分布的估计不够准确.Deng等[18 ] 利用C-vine Copula构建风电场内部的空间相关性结构,但空间相关性只体现于两个风电场之间,且并未生成具体的每日风电出力场景. ...
... 同时采取其他3个场景生成方法作为基准进行对比,本文提出的方法记作M1,文献[15 ]提出的Vine-Copula以及加权核密度估计拟合联合分布记作M2,文献[16 ]提出的根据预测功率分别构建条件概率分布记作M3,文献[17 ]提出的协方差函数和高斯混合模型估计联合概率分布记作M4,但未根据功率波动情况进行聚类与场景削减.使用Python语言编程,计算在配置为Intel(R) Core(TM) 2.60 GHz CPU和16 GB内存的个人计算机上进行.M1~M4生成未来24 h每小时100个场景的平均用时分别为74、65、34、52 s.由于是对未来1 d的场景进行预测,1 min左右的场景生成时间相对于实际24 h调度周期在可接受范围,4种场景生成方法均具备时间效率,所以不在计算时间上比较优劣. ...
Scenario generation of wind power based on statistical uncertainty and variability
3
2013
... 现阶段,大规模风力发电源于广阔区域内多个风电场,需要对多个风电场总功率场景做出预测,因此把握风电场之间的空间相关性和风电场内的时间相关性非常重要;同时,具体的场景生成依赖于功率预测值和真实值之间的联合分布,因此准确构建预测值和真实值的条件联合分布是另一重点.当前主流场景生成方法对这两个重点有不同处理方式.Wang等[15 ] 利用核密度估计(Kernel Density Estimation, KDE)法建立功率真实值和预测值间的条件概率函数,并使用R-vine Copula构建风电场间的空间相关性,最后通过条件概率逆变换来得到生成场景.但在R-vine Copula构建过程中,需要依次估计不同风电场间条件概率分布的Copula函数,受风电场数量影响,计算过程繁琐复杂,且只考虑了风电场间的空间相关性,忽视了风电场内时间相关性对建模的影响.Ma等[16 ] 将风能预测值按大小分层,根据不同区间预测功率对应的实际功率构建条件概率分布,并使用指数型协方差函数表示风能时间相关性,但指数协方差函数只考虑了时间相关性,不能反映风电场的空间相关性,只适用于单一或少数风电场.Tan等[17 ] 使用高斯混合模型估计功率真实值和预测值间的条件联合概率分布函数,但对数据分布的要求是混合高斯分布,对预测值和真实值的联合分布的估计不够准确.Deng等[18 ] 利用C-vine Copula构建风电场内部的空间相关性结构,但空间相关性只体现于两个风电场之间,且并未生成具体的每日风电出力场景. ...
... 选取25个风电场中的7个风电场进行研究,编号分别为68736、70232、70504、70773、61763、61765和62000.这7个风电场具有明显的空间差异,可以检验本文方法捕捉空间相关性的能力.对2013年1月1日至3月31日共90 d的场景进行生成,每日每个风电场生成N s 个场景,并将7个风电场每日每小时对应的场景累加,得到累积场景 X s u m a ( a =1, 2, …, 90), X s u m a Ns ×24,并在计算场景评估指标时取各指标在所有时间的均值.生成场景数量值得探讨,文献[16 ]使用风电功率波动的分布情况选取生成场景的数量,认为生成200个场景足以反映生成场景对风电功率波动情况的捕捉能力,其中风电功率波动 X t r a m p X t r a m p X t ( k ) - X t - 1 ( k ) . 本文分别取N s =20, 50, 80, 100, 200进行场景生成,对场景波动的分布用核密度估计,得到不同场景数量下风电功率波动情况的分布, ...
... 同时采取其他3个场景生成方法作为基准进行对比,本文提出的方法记作M1,文献[15 ]提出的Vine-Copula以及加权核密度估计拟合联合分布记作M2,文献[16 ]提出的根据预测功率分别构建条件概率分布记作M3,文献[17 ]提出的协方差函数和高斯混合模型估计联合概率分布记作M4,但未根据功率波动情况进行聚类与场景削减.使用Python语言编程,计算在配置为Intel(R) Core(TM) 2.60 GHz CPU和16 GB内存的个人计算机上进行.M1~M4生成未来24 h每小时100个场景的平均用时分别为74、65、34、52 s.由于是对未来1 d的场景进行预测,1 min左右的场景生成时间相对于实际24 h调度周期在可接受范围,4种场景生成方法均具备时间效率,所以不在计算时间上比较优劣. ...
Wind power scenario generation with non-separable spatio-temporal covariance function and fluctuation-based clustering
2
2021
... 现阶段,大规模风力发电源于广阔区域内多个风电场,需要对多个风电场总功率场景做出预测,因此把握风电场之间的空间相关性和风电场内的时间相关性非常重要;同时,具体的场景生成依赖于功率预测值和真实值之间的联合分布,因此准确构建预测值和真实值的条件联合分布是另一重点.当前主流场景生成方法对这两个重点有不同处理方式.Wang等[15 ] 利用核密度估计(Kernel Density Estimation, KDE)法建立功率真实值和预测值间的条件概率函数,并使用R-vine Copula构建风电场间的空间相关性,最后通过条件概率逆变换来得到生成场景.但在R-vine Copula构建过程中,需要依次估计不同风电场间条件概率分布的Copula函数,受风电场数量影响,计算过程繁琐复杂,且只考虑了风电场间的空间相关性,忽视了风电场内时间相关性对建模的影响.Ma等[16 ] 将风能预测值按大小分层,根据不同区间预测功率对应的实际功率构建条件概率分布,并使用指数型协方差函数表示风能时间相关性,但指数协方差函数只考虑了时间相关性,不能反映风电场的空间相关性,只适用于单一或少数风电场.Tan等[17 ] 使用高斯混合模型估计功率真实值和预测值间的条件联合概率分布函数,但对数据分布的要求是混合高斯分布,对预测值和真实值的联合分布的估计不够准确.Deng等[18 ] 利用C-vine Copula构建风电场内部的空间相关性结构,但空间相关性只体现于两个风电场之间,且并未生成具体的每日风电出力场景. ...
... 同时采取其他3个场景生成方法作为基准进行对比,本文提出的方法记作M1,文献[15 ]提出的Vine-Copula以及加权核密度估计拟合联合分布记作M2,文献[16 ]提出的根据预测功率分别构建条件概率分布记作M3,文献[17 ]提出的协方差函数和高斯混合模型估计联合概率分布记作M4,但未根据功率波动情况进行聚类与场景削减.使用Python语言编程,计算在配置为Intel(R) Core(TM) 2.60 GHz CPU和16 GB内存的个人计算机上进行.M1~M4生成未来24 h每小时100个场景的平均用时分别为74、65、34、52 s.由于是对未来1 d的场景进行预测,1 min左右的场景生成时间相对于实际24 h调度周期在可接受范围,4种场景生成方法均具备时间效率,所以不在计算时间上比较优劣. ...
A new wind speed scenario generation method based on spatiotemporal dependency structure
1
2021
... 现阶段,大规模风力发电源于广阔区域内多个风电场,需要对多个风电场总功率场景做出预测,因此把握风电场之间的空间相关性和风电场内的时间相关性非常重要;同时,具体的场景生成依赖于功率预测值和真实值之间的联合分布,因此准确构建预测值和真实值的条件联合分布是另一重点.当前主流场景生成方法对这两个重点有不同处理方式.Wang等[15 ] 利用核密度估计(Kernel Density Estimation, KDE)法建立功率真实值和预测值间的条件概率函数,并使用R-vine Copula构建风电场间的空间相关性,最后通过条件概率逆变换来得到生成场景.但在R-vine Copula构建过程中,需要依次估计不同风电场间条件概率分布的Copula函数,受风电场数量影响,计算过程繁琐复杂,且只考虑了风电场间的空间相关性,忽视了风电场内时间相关性对建模的影响.Ma等[16 ] 将风能预测值按大小分层,根据不同区间预测功率对应的实际功率构建条件概率分布,并使用指数型协方差函数表示风能时间相关性,但指数协方差函数只考虑了时间相关性,不能反映风电场的空间相关性,只适用于单一或少数风电场.Tan等[17 ] 使用高斯混合模型估计功率真实值和预测值间的条件联合概率分布函数,但对数据分布的要求是混合高斯分布,对预测值和真实值的联合分布的估计不够准确.Deng等[18 ] 利用C-vine Copula构建风电场内部的空间相关性结构,但空间相关性只体现于两个风电场之间,且并未生成具体的每日风电出力场景. ...
The wind integration national dataset (WIND) toolkit
1
2015
... 使用美国中东部地区2012—2013年中25个风电场的Wind Toolkit数据集[19 ] ,风电场标号以及空间分布如图1 所示,其中坐标点上方数字为风电场标号.该数据集包含了每个风电场的风速和功率数据,每个风电场额定功率为10~16 MW.功率数据集由100 m轮毂高度处的风力数据和适合站点位置的风力发电机功率曲线创建,考虑风力发电机间的唤醒效应以估算每个站点产生的功率,分辨率为5 min.为减少计算量,取分辨率为1 h.利用长短期记忆(Long Short-Term Memory, LSTM)神经网络的方法进行训练和预测得到预测数据集,均方根误差为1.71 MW. ...
Nonseparable, stationary covariance functions for space-time data
2
2002
... 设x (h 1 , u 1 ), x (h 2 , u 2 )为发生在时刻u 1 , u 2 和位置h 1 , h 2 的两个时空过程,其相关性可由时空协方差函数刻画.Gneiting[20 ] 提出不可分割的时空协方差函数反映时空过程的联系.时空协方差函数一般如下式所示: ...
... 根据文献[20 ]参数设置,在协方差函数参数中,σ 2 , γ , τ 均取为1. 在进行ξ ={a , c , α , β }估计时,通过对比经验的时空相关性等高线图调整参数.在调整后的参数附近,对目标函数: ...
The Kendall rank correlation coefficient
1
2006
... Kendall秩[21 ] 涉及和谐对概念,设w , z 为两个长度为n 的观测序列,对于分别来自两个序列的两对观测值(wi , zi )和(wj , zj ),若(wi -zi )(wj -zj )≥0,则称这是一个和谐对,反之为非和谐对,Kendall秩相关系数的计算公式如下: ...
Random variables, joint distribution functions, and copulas
1
1973
... 在Copula理论中,Sklar定理[22 ] 解释了多元分布函数、Copula函数和边际分布函数之间的关系.假设一个d 维随机变量x =[x 1 x 2 … xd ]T 的边际累积分布函数(Cumulative Distribution Function, CDF)为F 1 , F 2 , …, Fd ,其联合累积分布函数为F ,那么若所有的边际函数都连续,则F 可以被一个特定的Copula函数C 定义: ...
Nonparametric estimation of nonstationary spatial covariance structure
2
1992
... 在计算时空协方差矩阵之前,需要对数据的时空平稳性进行检验,以保证时空协方差函数效果.首先通过通过增广Dickey-Fuller(Augmented Dickey-Fuller, ADF)检验验证时间序列平稳性.对于空间平稳性,在缺少空间平稳性假设时需要进行多维标度变换[23 -24 ] 使序列空间平稳.根据文献[23 ],本文用新坐标取代原始经纬度坐标表征风电场间空间相关性,在变换后的平面中,空间相关性仅通过距离表示,其空间相关性与原始平面中一致,且变换坐标后的数据具有时空平稳性假设,为后续时空协方差函数估计做好铺垫.坐标变换前后风电场间距离和相关系数的散点图如图3 所示,反映变换前空间距离(h )和空间相关性的负相关关系并不明显,但经过多维标度变换后空间距离和空间相关性呈现明显负相关关系,便于时空协方差函数更好地捕捉时空相关性. ...
... 使序列空间平稳.根据文献[23 ],本文用新坐标取代原始经纬度坐标表征风电场间空间相关性,在变换后的平面中,空间相关性仅通过距离表示,其空间相关性与原始平面中一致,且变换坐标后的数据具有时空平稳性假设,为后续时空协方差函数估计做好铺垫.坐标变换前后风电场间距离和相关系数的散点图如图3 所示,反映变换前空间距离(h )和空间相关性的负相关关系并不明显,但经过多维标度变换后空间距离和空间相关性呈现明显负相关关系,便于时空协方差函数更好地捕捉时空相关性. ...
1
1978
... 在计算时空协方差矩阵之前,需要对数据的时空平稳性进行检验,以保证时空协方差函数效果.首先通过通过增广Dickey-Fuller(Augmented Dickey-Fuller, ADF)检验验证时间序列平稳性.对于空间平稳性,在缺少空间平稳性假设时需要进行多维标度变换[23 -24 ] 使序列空间平稳.根据文献[23 ],本文用新坐标取代原始经纬度坐标表征风电场间空间相关性,在变换后的平面中,空间相关性仅通过距离表示,其空间相关性与原始平面中一致,且变换坐标后的数据具有时空平稳性假设,为后续时空协方差函数估计做好铺垫.坐标变换前后风电场间距离和相关系数的散点图如图3 所示,反映变换前空间距离(h )和空间相关性的负相关关系并不明显,但经过多维标度变换后空间距离和空间相关性呈现明显负相关关系,便于时空协方差函数更好地捕捉时空相关性. ...
Wind power distributions: A review of their applications
1
2010
... 对于典型多维高斯过程,可以使用随机生成多维高斯分布随机数模拟.通常,风电功率的分布是非正态的、风电功率的相关性也是非线性的[25 ] ,但可以通过基于时空协方差函数的高斯过程生成风电功率的条件概率值,最后通过逆变换求得具体场景值,具体步骤如下: ...
Decomposition of the continuous ranked probability score for ensemble prediction systems
1
2000
... 能量得分(Energy Score, ES)是针对多变量情况设计的连续分级概率评分(Continuous Ranked Probability Score, CRPS)[26 ] 的延伸,提供了一种评估确定性预测的直接方法,反映了生成场景相对于真实场景平均偏离程度以及生成场景的波动.在生成场景自身波动一定时,越小的能量得分代表生成场景相对于真实场景的差异越小,精度越高.假设真实值为X real ,第k 个场景值为X ( k ) , X t ( k ) k 个场景中第t 时的风电功率预测值(k =1, 2, …, Ns , 0≤t ≤23 h),能量得分的表达式为 ...
Variogram-based proper scoring rules for probabilistic forecasts of multivariate quantities
1
2015
... 变异函数得分(Variogram Scoring, VS)既反映生成场景相对于真实值的精度,又可以用于展示不同场景生成方法对时空相关性的捕捉能力[27 ] ,变异函数得分越小表示该方法捕捉时空相关性能力越强.p 阶VS计算真实值与生成场景值的变差函数之间的差异定义为 ...
The flexibility workout: Managing variable resources and assessing the need for power system modification
1
2013
... 电力系统经济调度指在满足安全和电能质量的前提下,合理利用能源和设备,以最低的发电成本或燃料费用保证对用户可靠供电的一种调度方法.传统的电力系统依赖燃煤或燃气等发电单位来平衡供给和需求.然而,当风电使用水平提高时,由于风电的错峰性和不可调节性,所以系统需要更多备用容量或灵活资源调度来应对不确定性.从发电方面来看,灵活发电技术[28 ] 、区域储备优化[29 -30 ] 和储能[31 ] 是常见选择.本文主要考虑灵活发电技术中对可调控机组的调度问题,在该问题中,系统运营商协调调度常规燃煤或燃气机组以应对风电波动.通常以整体运营成本最小为目标,以可调控的燃煤或燃气机组等发电机组每小时的出力大小、机组的启停状态、风电削减量以及缺负荷量等可以人为调控的参数为决策变量,以机组运行、供需平衡等限制为约束进行优化求解.主要的决策变量为发电机组的出力情况,且决策变量既包含发电单位的启停状态这类整数变量又包含出力大小这类连续型变量,因此此类问题被称作电力系统的机组组合问题,需通过建立混合整数规划模型求解. ...
电能量和旋转备用市场下电-热综合能源系统低碳优化运行
1
2021
... 电力系统经济调度指在满足安全和电能质量的前提下,合理利用能源和设备,以最低的发电成本或燃料费用保证对用户可靠供电的一种调度方法.传统的电力系统依赖燃煤或燃气等发电单位来平衡供给和需求.然而,当风电使用水平提高时,由于风电的错峰性和不可调节性,所以系统需要更多备用容量或灵活资源调度来应对不确定性.从发电方面来看,灵活发电技术[28 ] 、区域储备优化[29 -30 ] 和储能[31 ] 是常见选择.本文主要考虑灵活发电技术中对可调控机组的调度问题,在该问题中,系统运营商协调调度常规燃煤或燃气机组以应对风电波动.通常以整体运营成本最小为目标,以可调控的燃煤或燃气机组等发电机组每小时的出力大小、机组的启停状态、风电削减量以及缺负荷量等可以人为调控的参数为决策变量,以机组运行、供需平衡等限制为约束进行优化求解.主要的决策变量为发电机组的出力情况,且决策变量既包含发电单位的启停状态这类整数变量又包含出力大小这类连续型变量,因此此类问题被称作电力系统的机组组合问题,需通过建立混合整数规划模型求解. ...
电能量和旋转备用市场下电-热综合能源系统低碳优化运行
1
2021
... 电力系统经济调度指在满足安全和电能质量的前提下,合理利用能源和设备,以最低的发电成本或燃料费用保证对用户可靠供电的一种调度方法.传统的电力系统依赖燃煤或燃气等发电单位来平衡供给和需求.然而,当风电使用水平提高时,由于风电的错峰性和不可调节性,所以系统需要更多备用容量或灵活资源调度来应对不确定性.从发电方面来看,灵活发电技术[28 ] 、区域储备优化[29 -30 ] 和储能[31 ] 是常见选择.本文主要考虑灵活发电技术中对可调控机组的调度问题,在该问题中,系统运营商协调调度常规燃煤或燃气机组以应对风电波动.通常以整体运营成本最小为目标,以可调控的燃煤或燃气机组等发电机组每小时的出力大小、机组的启停状态、风电削减量以及缺负荷量等可以人为调控的参数为决策变量,以机组运行、供需平衡等限制为约束进行优化求解.主要的决策变量为发电机组的出力情况,且决策变量既包含发电单位的启停状态这类整数变量又包含出力大小这类连续型变量,因此此类问题被称作电力系统的机组组合问题,需通过建立混合整数规划模型求解. ...
Day-ahead optimal dispatch for wind integrated power system considering zonal reserve requirements
1
2017
... 电力系统经济调度指在满足安全和电能质量的前提下,合理利用能源和设备,以最低的发电成本或燃料费用保证对用户可靠供电的一种调度方法.传统的电力系统依赖燃煤或燃气等发电单位来平衡供给和需求.然而,当风电使用水平提高时,由于风电的错峰性和不可调节性,所以系统需要更多备用容量或灵活资源调度来应对不确定性.从发电方面来看,灵活发电技术[28 ] 、区域储备优化[29 -30 ] 和储能[31 ] 是常见选择.本文主要考虑灵活发电技术中对可调控机组的调度问题,在该问题中,系统运营商协调调度常规燃煤或燃气机组以应对风电波动.通常以整体运营成本最小为目标,以可调控的燃煤或燃气机组等发电机组每小时的出力大小、机组的启停状态、风电削减量以及缺负荷量等可以人为调控的参数为决策变量,以机组运行、供需平衡等限制为约束进行优化求解.主要的决策变量为发电机组的出力情况,且决策变量既包含发电单位的启停状态这类整数变量又包含出力大小这类连续型变量,因此此类问题被称作电力系统的机组组合问题,需通过建立混合整数规划模型求解. ...
A bilevel model for participation of a storage system in energy and reserve markets
1
2018
... 电力系统经济调度指在满足安全和电能质量的前提下,合理利用能源和设备,以最低的发电成本或燃料费用保证对用户可靠供电的一种调度方法.传统的电力系统依赖燃煤或燃气等发电单位来平衡供给和需求.然而,当风电使用水平提高时,由于风电的错峰性和不可调节性,所以系统需要更多备用容量或灵活资源调度来应对不确定性.从发电方面来看,灵活发电技术[28 ] 、区域储备优化[29 -30 ] 和储能[31 ] 是常见选择.本文主要考虑灵活发电技术中对可调控机组的调度问题,在该问题中,系统运营商协调调度常规燃煤或燃气机组以应对风电波动.通常以整体运营成本最小为目标,以可调控的燃煤或燃气机组等发电机组每小时的出力大小、机组的启停状态、风电削减量以及缺负荷量等可以人为调控的参数为决策变量,以机组运行、供需平衡等限制为约束进行优化求解.主要的决策变量为发电机组的出力情况,且决策变量既包含发电单位的启停状态这类整数变量又包含出力大小这类连续型变量,因此此类问题被称作电力系统的机组组合问题,需通过建立混合整数规划模型求解. ...
A systematic approach for the joint dispatch of energy and reserve incorporating demand response
1
2018
... 式中:C fuel 为能耗成本;C setup 为启动成本;C RUD 为预留容量成本;ρn 为每个场景出现的概率; C A F n C L S n C W C n 32 ]. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}