

随着新能源和有源化负荷的占比不断提升,电网的动态性和不确定性逐渐增强,给电网运行和系统调度人员带来了新的挑战[1].现有的电网调控手段多集中于发电侧和负荷侧,而电力网络作为电能的传输途径与载体,对其拓扑结构的系统级优化控制在研究和实际中考虑较少.电网实时拓扑优化控制是一种成本低、有前景且未被充分利用的系统缓解措施.由于其对应数学问题的组合和高度非线性等特点,常规的优化算法很难在短时间完成求解.从安全和经济角度来看,最大化系统的可用传输容量(Available Transfer Capability, ATC)对电力系统至关重要,这代表了传输网络的剩余传输容量,可进一步用于新能源消纳和能源交易.从环境和经济方面考虑,今后通过建设新线路的方式来扩大系统传输能力对于电网公司将会越来越难.此外,可再生能源、需求响应、电动汽车和电力电子设备的日益普及导致了更多随机和动态行为,威胁到电网的安全稳定运行[2,3].因此,在满足各种安全约束的同时,考虑到系统的不确定性,开发电网实时拓扑优化控制策略以最大化可用传输容量变得至关重要.
与新建输电通道、减少用电需求和安装增容设备如统一潮流控制器(UPFC)、柔性交流输电系统(FACTS)相比,通过输电线路切换或母线分裂运行来增加系统可用传输容量和缓解阻塞的主动式电网拓扑优化控制是一种低成本的有效解决方案.电网实时拓扑优化控制最初是在20世纪80年代初期提出的,当时进行了多项研究工作以实现多个控制目标,例如成本最小化、电压和线路潮流控制[4,5].考虑到电网运行的复杂性和不确定性,输电线路切换母线或母线分裂运行决策控制本质上是一个很难求解的非线性混合整数优化问题.相关领域已有研究工作开展,Fisher等[6]提出了一种混合整数线性规划(MILP)模型,该模型使用直流潮流对电网进行近似,进而使用广义优化求解器CPLEX来进行求解.Khodaei等[7]电网将拓扑优化问题分解为两个相对简单的子问题,分别为组合优化问题和直流最优潮流,然后利用CPLEX进行求解.Fuller等[8]提出了一种启发式的方法,通过直流最优潮流来求得问题的近似解.Dehghanian等[9,10]也介绍了类似的计算方法,不同点是使用点估计对系统的不确定性进行建模,然后通过最优潮流对解进行校验.
然而,现有方法存在一定的局限性,主要表现在两个方面.首先,现有方法通常使用不考虑安全约束的直流潮流对问题进行近似,这样大大降低解的精度.由于电网的高度非线性特性,使用含安全约束的交流潮流模型将使问题变得非凸,故在不忽略部分(全部)安全约束条件或牺牲求解精度的情况下,常规的优化求解器无法对问题进行直接求解.其次,线路开合和母线分裂运行的排列组合呈指数爆炸性增长,而基于灵敏度的方法容易受到不断变化的系统运行状态的影响,因此,对于大电网,优化问题的求解耗时较久,无法满足拓扑实时优化控制的需求.
1 电网网络拓扑优化控制
1.1 优化目标与约束条件
电网拓扑优化控制的主要目标是在各种运行场景下最大化电网的可用传输容量,每个场景包含多个连续时间断面,断面的时间间隔为5 min,优化问题需要考虑每日负荷变化、日前发电计划和实时发电计划调整、母线电压合格范围、检修计划等.控制决策包括电网网络拓扑调整,即母线的分裂与合母运行、线路的开断和合环以及两者的排列组合.在控制过程中不考虑通过改变发电机出力和切负荷来增加系统可用传输容量.考虑到实际系统的运行情况和调度员操作习惯,在所有运行场景下均需要满足以下硬约束条件:①用电需求在任何时刻都必须得到满足,即发电与负荷实时平衡;②跳闸的发电厂数量不超过1个;③拓扑结构的改变不能在电网中形成孤岛;④系统(交流)潮流应始终收敛.上述4个约束条件在任何时刻如果没有得到满足,则该场景立即结束,即任务“失败”.与此同时,该实时优化控制问题包含1个“软”约束条件,即线路的开合和母线分裂运行操作过程中动作的物理设备要求一定的“冷却时间”,考虑为15 min,在该时间段内设备不能连续动作两次及以上.“软”约束条件没有得到满足,则会导致某些后果,而不是立即“任务失败”.上述硬约束和软约束条件使得待求解问题更加实际,符合实际的应用场景,对电网拓扑优化控制策略进行评判的量化指标如下.
式中:cs、cc及ct分别为单断面分数、单场景分数及总分数;N、ns、nc分别为电网的传输线路个数、断面个数及场景个数;Pi和
1.2 马尔可夫决策过程
图1
智能体在某时刻t动作后获得的奖励可以根据拓扑优化控制目标进行定义:
马尔可夫决策过程的求解目标是得到控制策略π,建立起系统状态与控制动作之间的匹配关系,从而使得策略执行过程中得到的预期回报J(π)最大,亦为马儿可夫决策过程的目标函数,定义为[14]
式中:E为函数的期望值;T为一组时序决策过程中所经历的步数;折扣因子γ∈[0, 1].
1.3 深度强化学习
强化学习是一类特殊的机器学习算法,与监督学习和无监督学习不同,其要解决的问题是智能体在动态变化的环境中如何执行动作以获得最大累计奖励,可用于解决复杂信息物理系统的控制和决策问题.近年来,深度强化学习在多个领域的应用取得突破性进展(如AlphaGo等),为智能电网调度控制提供了启示.目前,存在多种强化学习算法,各有特点和适用范围.一种典型的算法是Q学习算法,利用Q表格来存储系统状态和动作对应的值函数Q(s, a),即系统在某个状态s下采用动作a将得到的累计回报.根据贝尔曼方程[14],累积回报Rt可以表示为预期回报:
式中:St为t时刻的系统状态;At为t时刻采取的控制动作.
为了获得最优动作值Q*(s, a), Q学习算法在状态为st时采取动作at后向前看一步,同时考虑状态st+1时对应的动作at+1,从而最大化预期目标值 rt+γQ*(st+1, at+1).根据贝尔曼方程,该算法可以进行在线更新以控制值朝最优目标方向进行迭代:
式中:α为学习率.为了使用Q表格,系统状态和动作都需要进行离散化处理,因此很难处理状态和动作空间为高维的复杂问题.为了克服这个困难,可以使用深度神经网络来取代Q表格,即深度Q网络(Deep Q Network, DQN)算法.该方法使用神经网络作为函数逼近器对Q(s, a)函数关系进行估计,因此它可以支持求解状态空间为连续量的问题,而无需对状态进行离散化或构建Q表格.深度神经网络的权重θ表示从系统状态到Q值的映射,因此,需要定义一个损耗函数Li(θ)来更新神经网络权重θ及其对应的Q值,可使用下式[14]:
式中:ρ为状态-动作对(s, a)的概率分布;yi为时间差异目标;s'和a'为状态转移后(下一个)系统状态和动作;ε为环境中的系统状态分布.通过对损耗函数求梯度并执行随机梯度下降,便可以迭代方式不断更新智能体的权重[14]:
式中:r为奖励值;
式中:φ为深度神经网络中卷积层的参数;α'和β为深度神经网络中两个全连接层的参数;V为状态值函数;Ad为优势函数(动作值函数与状态值函数的差);
在每个智能体学习过程中都会更新独立的状态值.频繁更新的状态值和偏向优势值可以更好地逼近Q值.竞争深度Q网络可以实现对智能体更加准确和稳定的更新.因此,选择竞争深度Q网络作为基础算法以求实现更好的控制性能.
2 算法的提出
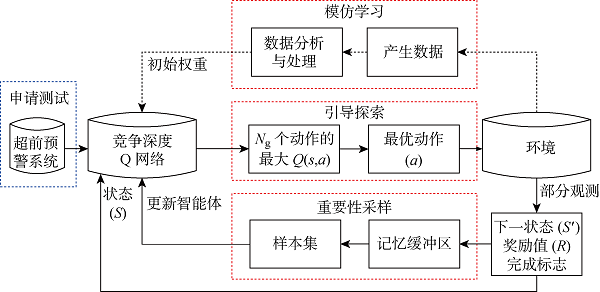
2.1 架构设计
图2
2.2 竞争深度Q网络
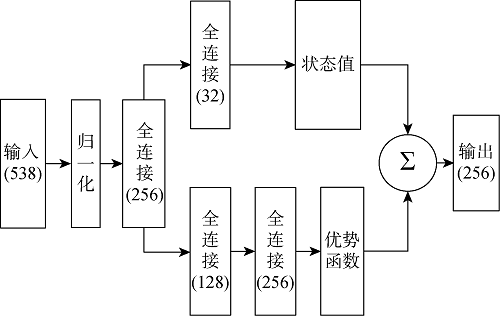
本文使用的竞争Q网络的结构如图3所示,图中括号内数字代表神经元个数.在采用竞争深度Q网络原始结构的基础上,在输入层增加1个归一化层,并根据输入和输出数据的维度计算和设定了隐藏层的神经元数量.竞争架构将单个流解耦为状态价值流和优势流.竞争深度Q网络还使用了DQN中的3个重要技术,包括:①经验回放缓冲区,允许智能体进行离线策略训练并解耦训练数据之间的强相关性;② 使用重要性采样以提升算法学习的效率和最终得到的策略质量[17],通过判断绝对时差误差(TD-error)衡量测量数据的重要性,并在从缓冲区采样过程中给予重要数据更高的优先级;③ 采用双Q网络,周期性更新目标网络从而提升智能体的稳定性.可实现电网拓扑实时优化控制的竞争深度Q网络智能体训练过程如算法1所示.
图3

算法1 电网拓扑优化控制智能体训练流程
1. 从模仿学习结果中读取DQN网络的初始参数
2. 初始化容量为Nd的回放缓存D
3. for:样本个数k'=1, 2, …, 执行
4. for:t =1, 2, … 每一步控制迭代,执行
5. 获取动作价值函数Q(·|st;θ)值并取Q值最高的Ng个动作
6. 在环境中验证所有Ng个动作并找到回报最高的动作at
7. 在环境中执行at并获取下一时刻的系统状态st+1、奖励值rt、结束标志dt
8. 储存元组<st, at, rt, st+1, dt>至回放缓存D中;如果结束标志为真,则多存几次
9. 从回放缓存D中根据重要性采样Nb个小批量样本
10. 按照下述公式计算动作价值函数的目标值,其中θ-为目标网络参数:
yi=
11. 每Ns步通过损耗函数Li(θ)=(yi-Q(st, at;θ))2进行主网络参数的更新
12. 将θ拷贝至θ-
13. 更新系统状态st=st+1
14. end for
15. end for

2.3 模仿学习
模仿学习本质上是一种监督式学习方法,可以用来对智能体进行预训练,从而获得较好的初始化网络参数.本方法利用电网潮流解算器生成用于模仿学习的海量数据集,然后将这些数据进行初步的处理和分析再用于训练DQN智能体.这个过程使得智能体获得针对于不同系统状态的良好的Q(s, a)分布.模仿学习中用于训练智能体的损耗函数可用加权均方误差(MSE)形式定义:
式中:系数μ, σ∈
2.4 引导式探索
模仿学习可为电网单断面数据提供良好的初始策略,然后需使用深度强化学习来继续训练智能体的长期规划能力并获得全局最优策略.对于电网拓扑优化控制问题,传统的ε-贪婪策略效率低下.首先,由于问题对应的动作空间很大,导致马尔可夫链很长.其次,智能体非常容易陷入局部最优解.为解决这个问题,提出一种引导式探索方法,训练过程中在每个时间点选择Ng个Q值最高的动作,对其效果进行模拟和评估.然后,选择奖励最高的动作来实际执行,并将这样的经验存储在回放缓存中.引导式探索有助于智能体进一步提取好的动作.而借助动作模拟功能可以使得训练过程更加稳定,同时将更好的经验进行存储并用于更新智能体.因此,提出的引导式探索显著地提升了训练效率.
2.5 提前预警
电力系统对各种运行条件高度敏感,特别是在拓扑结构发生重大变化时.由于电网拓扑控制在很长一段时间内是连续的,故一个不好的控制动作可能会产生长期的不利影响,影响到接下来多个断面的运行状态和控制决策.由于高比例可再生能源电力系统存在很大的随机性,即使是训练好的智能体也无法完全保证在所有复杂系统运行状态下都能提供良好的控制动作.为解决这个问题,提出了一种早期预警的自适应机制,可以帮助智能体确定开启动作的最佳时机,在线路出现潮流越限情况之前采用合适的控制措施将其消除,以提高系统的容错性和鲁棒性,该机制的流程和操作逻辑如图4所示.
图4

在每个时刻,该机制使用下式定义的告警标志W模拟对电网环境不采取任何行动的后果:
如果线路的负载水平高于预先确定的阈值λ,则告警并将告警标志位设为“是”.之后智能体提供Ng个得分最高的动作以进行进一步的模拟,最后从这些动作中选取得分最高的动作予以执行. 引导式探索和预警机制都提高了本文提出的深度强化学习算法的性能和鲁棒性.
3 实验验证
3.1 开源电网仿真器Pypownet
智能体的训练环境采用开源电网仿真软件Python Power Network (Pypownet)[18],该仿真环境建立在用于模拟电网的MatPower等开源工具的基础之上.Pypowernet能够对大型电网进行建模并仿真各种系统运行状态,同时支持交流和直流潮流求解.Pypownet的框架基于Linux操作系统,接口可以通过自定义方式进行设置,从而可以与强化学习智能体进行交互.通过与Pypownet的大量交互,使用Python脚本训练和调整智能体.此外,Pypownet还提供了可视化模块,供用户实时通过图形界面观测电网的运行状态和智能体的控制动作.Pypownet提供了多个标准测试系统,其中的数据集代表了实际的时间序列运行条件.本文以IEEE 14系统为研究对象,使用开源数据集进行测试,该数据集包含 1000 个场景共28 d的连续电网运行断面数据.每个场景包含 8065 个连续断面,断面间的时间间隔为5 min.使用Pypownet的可视化模块对IEEE 14节点进行可视化的效果如图5所示.
图5
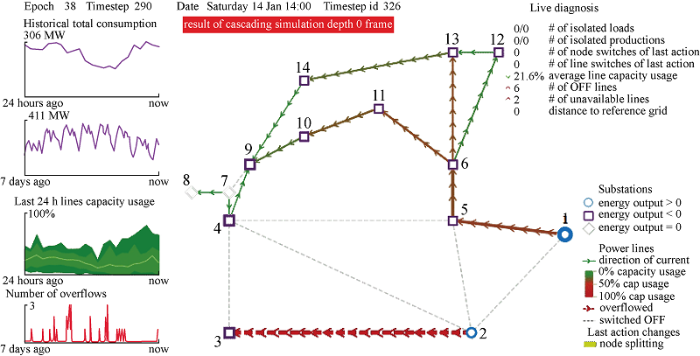
图5
Pypownet环境下IEEE 14节点系统可视化效果
Fig.5
Visualization of IEEE 14-note system in Pypownet
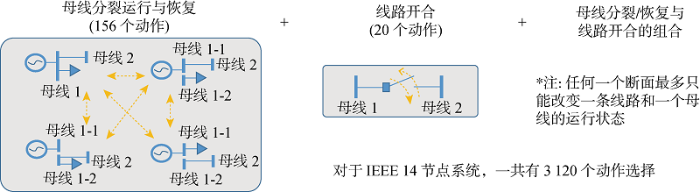
借助Pypownet的开发环境和框架,将提出方法应用至IEEE 14节点系统,针对系统的各种运行状态进行拓扑优化控制,在满足上述系列约束条件的基础上,最大化系统的可用传输容量.针对这个系统,共有156个不同的节点分裂动作和20个线路切换动作,同时考虑两者的排列组合且不能形成孤岛,智能体的动作空间含 3120 个动作.智能体在具有48个CPU内核和128 GB内存的Linux服务器上使用Python 3.6进行训练.
3.2 模仿学习训练结果
首先,在第一个测试中,使用最简单的方法即对智能体的神经网络参数进行随机初始化,并使用完整的含 3120 个动作的动作空间来对智能体进行训练.如预期一致,由于动作空间大和时间序列长,直接使用竞争深度Q网络算法训练出的智能体效果不佳.为解决这个问题,通过大量仿真实验来观察对提升系统ATC和解决线路潮流越限有效的动作,有效缩减系统的动作空间,主要包括:① 155个母线分裂/恢复动作;② 19个线路切换动作;③ 76个母线动作和线路同时动作的结合;④ 1个什么都不做的动作(即“空转”).这样一来,动作空间A就从 3120 个减少到了251个.接下来使用模仿学习训练智能体以获得良好的初始网络参数.从开源数据中选取40个场景,每个场景包含 1000 个连续时间断面用于模仿学习,共产生 40000 个样本对(s, Q(s, a)),然后将这些样本对分成一个训练数据集(90%,36000 个)和测试数据集(10%,4000 个).图6所示为使用模仿学习训练后针对各动作的预测(得分)值rt和对应的标签值,图中ai为控制动作编号,实验中采用均方误差作为损失函数,优化器选择Adam,学习速率为0.001.由图可见,以批量大小为1训练100次后,智能体预测值的加权均方误差MSE下降到0.05左右,说明深度神经网络已经可以捕捉到峰值和趋势,并提供相对有效的动作.
图6
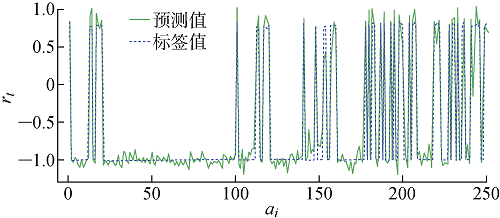
图6
使用模仿学习后深度Q网络的预测值
Fig.6
Predicted value of DQN after using imitation learning
3.3 基于引导式探索的训练结果
为了缩短马尔可夫链的长度,降低训练难度,将开源数据集中连续28 d的场景按天进行划分,每天288个连续时序断面.为了进行比较,图7、8分别为使用ε-贪婪策略和本文的引导式探索训练竞争深度Q网络智能体的训练过程,图中ks为样本编号,J为回报值.
图7
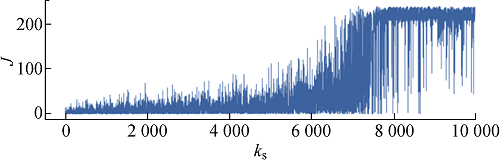
图7
使用ε-贪婪策略训练智能体的过程
Fig.7
Training process of AI agent by using ε-greedy strategy
图8
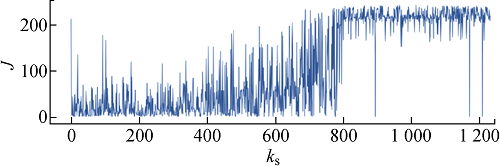
图8
使用提出的引导式探索训练智能体的过程
Fig.8
Training process of AI agent by using proposed guided exploration
由图7可见,使用 ε-贪婪策略,虽然智能体所获奖励值不断增加,但是智能体几乎无法在第 7000 个断面之前连续针对一整天的电网断面进行拓扑优化决策,与电网环境的交互几乎都是以违反约束条件而失败告终.选择Ng=10,与ε-贪婪策略相比,智能体可以在训练过程的早期阶段成功控制更多的电网运行断面,在训练断面次数达到750以上时,基本已经可以自主完成电网拓扑优化控制而不违反约束条件.通过对比可见,本文提出的引导式探索可以提升智能体的训练效率,大大减少训练时间.
3.4 智能体测试与性能比较
表1 智能体性能对比
Tab.1
| 智能体 | 失败 次数 | 平均得分 | 平均得分 (排除失败场景) |
|---|---|---|---|
| 不作为 | 91 | 2471.42 | 4534.72 |
| 仅使用模仿学习训练 | 198 | 38.210 | 3820.63 |
| 使用引导式训练 | 7 | 4269.63 | 442.49 |
| 使用预警机制λ=0.850 | 0 | 4253.40 | 4253.40 |
| 使用预警机制λ=0.875 | 1 | 4347.56 | 4369.41 |
| 使用预警机制λ=0.900 | 0 | 4396.77 | 4396.77 |
| 使用预警机制λ=0.925 | 0 | 4493.27 | 4493.27 |
| 使用预警机制λ=0.950 | 0 | 4492.89 | 4492.89 |
| 使用预警机制λ=0.975 | 2 | 4446.12 | 4491.03 |
4 结论
通过实时优化电网拓扑进而实现电网潮流控制是一种成本低且有效的系统级控制手段.本文提出了一种新的基于人工智能的电网拓扑优化和潮流控制方法,可以在满足系统各种实际约束条件的基础上最大化电网可用传输容量.大量实验结果表明,考虑到系统的不确定性和实际约束,经过充分训练的AI智能体可以掌握电网的拓扑优化和潮流控制问题,同时也表明了基于人工智能的电力系统优化和控制技术具有广阔的应用和发展前景.
未来的研究工作包括:①继续通过参数优化提升智能体的性能;②研究在线学习/训练和在线决策协调配合的方法,保证智能体的长期有效性;③将本文提出的方法用于华东电网实际断面数据的训练,提升工程应用价值.
参考文献
华东电网动态区域控制误差应用分析
[J].
Applications analysis of dynamic ACE in East China power grid
[J].
基于典型运行场景聚类的电力系统灵活性评估方法
[J].
Flexibility evaluation method for power system based on clustering of typical operating scenarios
[J].
Deep-reinforcement-learning-based autonomous voltage control for power grid operations
[J].DOI:10.1109/TPWRS.59 URL [本文引用: 2]
Switching as means of control in the power system
[J].DOI:10.1016/0142-0615(85)90014-6 URL [本文引用: 1]
Corrective control of power system flows by line and bus-bar switching
[J].DOI:10.1109/TPWRS.1986.4334990 URL [本文引用: 1]
Optimal transmission switching
[J].DOI:10.1109/TPWRS.2008.922256 URL [本文引用: 1]
Transmission switching in security-constrained unit commitment
[J].DOI:10.1109/TPWRS.2010.2046344 URL [本文引用: 1]
Fast heuristics for transmission-line switching
[J].
Flexible implementation of power system corrective topology control
[J].DOI:10.1016/j.epsr.2015.07.001 URL [本文引用: 1]
Power grid optimal topology control considering correlations of system uncertainties
[J].
基于互信息理论与递归神经网络的短期风速预测模型
[J].
Short-term wind speed forecasting model based on mutual information and recursive neural network
[J].
基于深度强化学习的区域化视觉导航方法
[J].
A regionalization vision navigation method based on deep reinforcement learning
[J].
Mastering the game of go without human knowledge
[J].DOI:10.1038/nature24270 URL [本文引用: 2]
Deep reinforcement learning with double q-learning
[C]//
Dueling network architectures for deep reinforcement learning
[C]//
Prioritized experience replay
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}